
【セッションレポート】 コスト 40% 減の秘密を公開!Amazon Nova 開発で実証済みの大規模モデル学習ベストプラクティス (AWS-56) #AWSSummit
2025 年 6 月 26 日 (木) 15:50 - 16:30
登壇者:渡辺 啓太 氏
Sr. World Wide Specialist Solutions Architect, Frameworks WWSO
アマゾン ウェブ サービス ジャパン合同会社
概要
Amazon SageMaker HyperPod と EC2 UltraClusters の組み合わせにより、大規模基盤モデルの学習において、高い耐障害性と効率性を実現しました。Amazon Nova の開発の中で実証されたこれらのベストプラクティスを活用することで、コスト削減と学習時間の短縮が可能となります。特に分散学習における 3D パラレリズム(データ並列、テンソル並列、パイプライン並列)の最適な組み合わせと、アシンクロナスチェックポイント生成などの技術が重要な役割を果たしました。

分散学習の進化と課題
従来の GPU 一台で完結していた機械学習から、大規模基盤モデルの登場により、分散学習がもはや必須となっています。

分散学習には3つの主要な並列化手法があります。
- データ並列
複数のモデルレプリカで異なるデータを分割処理 - テンソル並列
MLP や Attention ブロック単位で処理を分散 - パイプライン並列
モデルの各レイヤを分散
しかし、分散学習は状態が密結合しており、一つのノード障害が全体の学習プロセスを停止させる脆弱性を持つという欠点があります。
Amazon SageMaker HyperPod の革新的機能
AWS は、自社生成 AI Amazon Nova を開発する中で得た、分散学習の欠点を克服するための知見を、Amazon SageMaker HyperPod の形で提供しています。HyperPod は大規模分散学習におけるベストプラクティスを反映した基盤モデル開発環境です。
- Resiliency 機能
ノード障害時の自動復旧 - HyperPod Observability
システム不良の可視化 - アシンクロナスチェックポイント生成
学習を中断せずにチェックポイントを作成
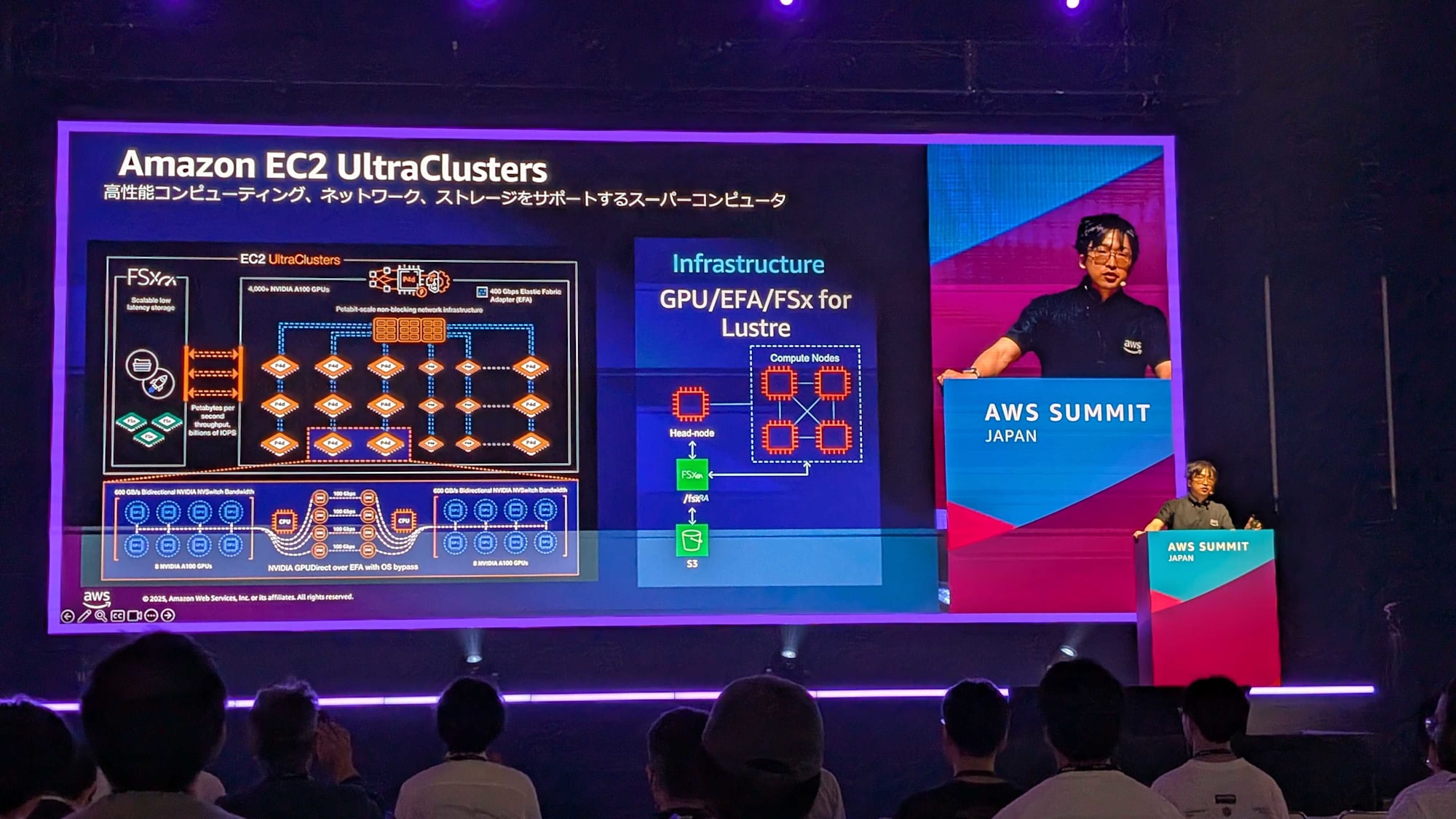
Amazon EC2 UltraClusters の活用
UltraClusters は高性能コンピューティング、ネットワーク、ストレージを統合したスーパーコンピュータ基盤として機能します。
- 高速アクセラレータと大容量デバイスメモリ
- 広帯域インターコネクト
- スケーラブルな分散ファイルストレージ
AWS Deep Learning ソフトウェアスタック
Deep Learning AMI (DLAMI) の形で、モデル開発に必要なライブラリが揃ったマシンイメージを提供しています。
- ML Frameworks
PyTorch、JAX、DDP、FSDP、MegatronLM、DeepSpeed、torch-neuronx - 通信ライブラリ・SDK
NCCL(GPU 間通信に重要) 、AWS OFI NCCL、SMP、SMDDP - ハードウェア・カーネル
アクセラレータドライバ、EFAカーネルドライバ
実証済み事例
- Llama 3.3 Swallow
HyperPod を活用した分散学習のベストプラクティスを採用
感想
AWS の先進的な分散コンピューティングアーキテクチャがもたらす大規模モデル学習の革新性に感銘を受けました。特に、Amazon SageMaker HyperPod と EC2 UltraClusters の組み合わせによる耐障害性と効率性の向上は、今後の AI 開発において大きな競争優位性をもたらすと考えられます。









