
AWSでリクガメに詳しいAIエージェントを作る
はじめに
皆様こんにちは、あかいけです。
最近、AWSの生成AI関連サービスを触る機会があり、色々調べていました。
特に2025年12月にGAとなったAmazon S3 Vectorsが気になっており、
ベクトルストアを使って「自分だけの専門家AIエージェント」を作ってみたいなぁと考えていました。
というわけで今回はS3 Vectorsとその他AWSの各種サービスを使って、リクガメに詳しいAIエージェントを構築してみました。
なぜリクガメかって?
それはもう、かわいいからです。

弊社メンバーが日常的に実践するAI駆動開発のナレッジやTipsを共有するために、AI駆動開発 Advent Calendar 2025を開催しています。
投稿時点でクリスマスが終わっており完全に遅刻してしまいましたが、
本ブログはこの企画の21日目の記事になります。
もしAI駆動開発の最先端を知りたい方は、
ぜひ本アドベントカレンダーをチェックしてみてください。
本記事ではTerraformとAWS CLIでリソースを作成しますが、
その中でも主要なリソースのみ抜粋して、記載しています。
コードの全量については以下に格納しているので、ご自由にご利用ください。
今回のゴール
S3 Vectorsをベクトルストアとして使い、リクガメの専門的な知識を持ったAIエージェントを構築します。
例えばユーザーが「ロシアリクガメの適温は?」と聞くと、
AIエージェントが関連情報を検索して回答してくれるイメージです。
使用するサービス
本ブログで使用する主要サービスは以下の通りです。
| サービス | 役割 |
|---|---|
| Amazon S3 | ソースドキュメントの格納 |
| Amazon S3 Vectors | ベクトルデータの格納 |
| Amazon Bedrock Knowledge Bases | RAGによるナレッジベース構築 |
| Amazon Bedrock Agents | フルマネージドなAIエージェントの構築と実行 |
| Amazon Bedrock AgentCore | AIエージェントの本番運用基盤 |
各種サービスについて軽く説明しますが、
「そんなのもう知っているよ!」 という方は 実装してみる まで飛んでください。
Amazon S3 Vectorsとは
2025年12月にGAとなったAmazon S3 Vectorsは、
ベクトルにネイティブ対応しているオブジェクトストレージです。
S3 Vectorsの特徴
- コスト削減: 従来のベクトルデータベースと比較して最大90%のコスト削減
- スケーラビリティ: 1インデックスあたり最大20億ベクター対応
- サーバーレス: インフラ管理不要
- 低レイテンシー: 頻繁なクエリで100ms以下、非頻繁なクエリでも1秒以下
- Bedrock Knowledge Basesとのネイティブ統合
なぜS3 Vectorsを選んだのか
OpenSearch Serverlessなど他のベクトルストアもありますが、
今回S3 Vectorsを選んだ理由は以下の通りです。
- コスト: 個人プロジェクトやPoC用途では圧倒的に安い
- シンプルさ: 最低OCU(OpenSearch Capacity Units)を気にする必要がない
- ユースケースの適合: クエリ頻度が低〜中程度の用途に最適
OpenSearch Serverlessだと最低OCU構成でも月額数百ドル程度かかりますが、
S3 Vectorsは使った分だけの課金なので特に小規模なプロジェクトでは非常に魅力的です。
Amazon Bedrock Knowledge Basesとは
Amazon Bedrock Knowledge Basesは、
RAGを簡単に構築できるマネージドサービスです。
特徴
- フルマネージド: ドキュメントの取り込み、チャンキング、埋め込み生成、ベクトル格納を自動化
- 複数のベクトルストア対応: S3 Vectors、OpenSearch Serverless、Aurora、Neptune Analyticsなど
- 柔軟なチャンキング: 固定サイズ、階層的、セマンティックなど複数の戦略
- Bedrock Agentsとのネイティブ統合
Bedrock Knowledge Basesがやってくれること
まずRAGはベクトルストアを作成するまでの「データ取り込みフェーズ」と、
ユーザーが実際に利用する「検索 / 回答フェーズ」の2段階に大別できます。
どちらのフェーズにおいても、
Bedrock Knowledge Basesを利用することで大幅に構築コストを削減できます。
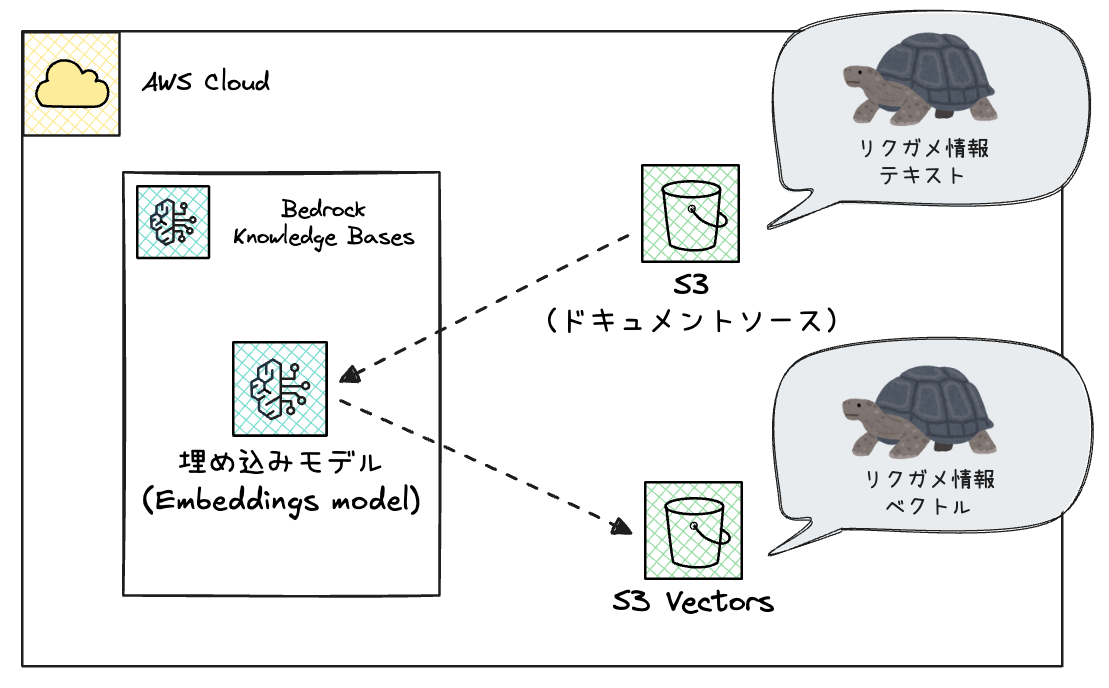
1. データ取り込みフェーズ(事前準備)
ソースドキュメントをS3に格納して、
あとはBedrock Knowledge BasesにてS3 VectorsへSyncするだけでベクトルストアを構築できます。
- 1.ドキュメントをチャンク分割
- 2.各チャンクをベクトル化(Embedding)
- 3.ベクトルストア(S3 Vectors)に格納
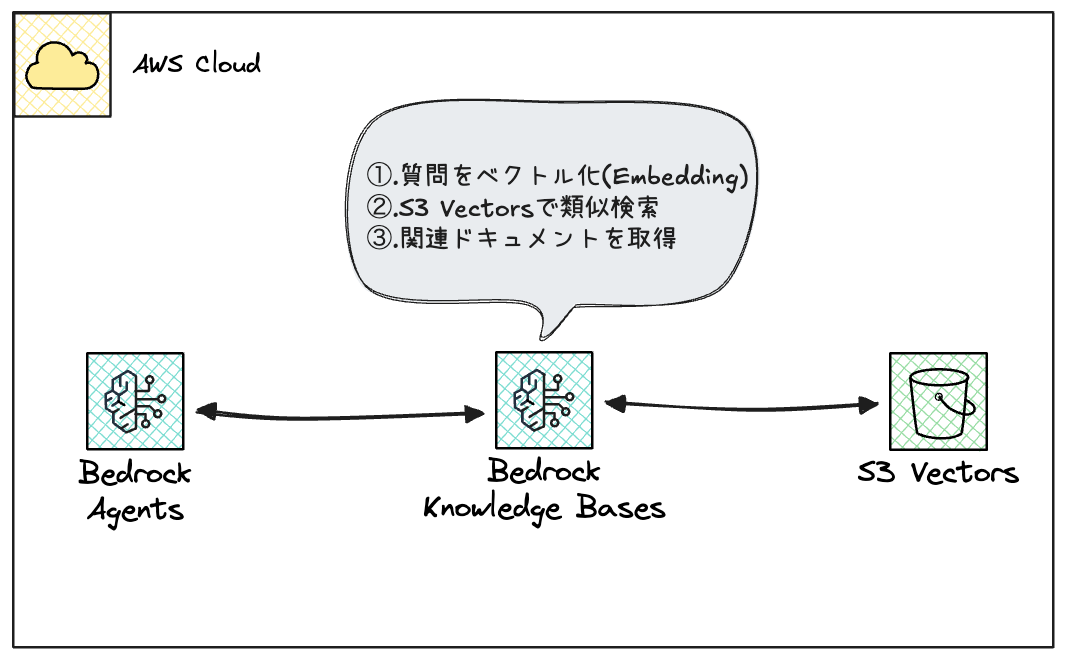
2. 検索・回答フェーズ(ユーザー利用時)
Knowledge Basesを使えば、4の部分をマネージドで実現できます。
AIエージェント側で実装する手間が省けるので、これも実装工数の削減に繋がるのではないでしょうか。
- 1.ユーザーの質問
- 2.Bedrock Agentsが質問を受け取る
- 3.Knowledge Basesに検索をリクエスト
- 4.Knowledge Bases内部処理
- 4-1.質問をベクトル化(Embedding)
- 4-2.S3 Vectorsで類似検索
- 4-3.関連ドキュメントを取得
- 5.Agentsがドキュメント + 質問をLLMに渡す
- 6.回答を生成してユーザーに返す
Amazon Bedrock Agentsとは
Amazon Bedrock Agentsは、
基盤モデルを使ってタスクを自律的に実行するAIエージェントを構築するサービスです。
後述のBedrock AgentCoreと比較するとよりマネージドなサービスなので、
少ない工数でAIエージェントを実装することができます。
特徴
- 自律的なタスク実行: ユーザーの指示を理解し、必要なアクションを判断・実行
- Knowledge Bases連携: ナレッジベースから情報を検索して回答
- Action Groups: Lambda関数を呼び出して外部システムと連携
- メモリ: 複数のセッションにわたって会話のコンテキストを保持
- ガードレール: 不適切な入出力をフィルタリング
Amazon Bedrock AgentCoreとは
Amazon Bedrock AgentCoreは、
AIエージェントを本番環境で安全にスケール運用するためのサービスです。
特徴
- Runtime: サーバーレスでエージェントをデプロイ・スケール(LangGraph、CrewAI、Strands Agents等に対応)
- Memory: エージェントの記憶を管理(セマンティックメモリ、会話要約など)
- Gateway: MCP(Model Context Protocol)サーバーとしてAPIやLambdaをツール化
- Code Interpreter: サンドボックス環境でPythonコードを安全に実行
- Workload Identity: エージェントの認証・認可を管理
Bedrock AgentsとBedrock AgentCoreの違い
どちらもAIエージェントを構築・運用できるサービスですが、目的とアプローチが異なります。
Bedrock Agentsは設定ベースで素早く構築できる一方、AgentCoreはコードベースで高いカスタマイズ性を持つ代わりに実装工数がかかります。
個人的にはプロトタイピングにはBedrock Agentsを使用し、本番環境ではAgentCoreに移行するという使い分けもありかなと思います。
| 観点 | Bedrock Agents | Bedrock AgentCore |
|---|---|---|
| 設計思想 | フルマネージド型エージェントビルダー | フレームワーク/モデル非依存のエージェントプラットフォーム |
| フレームワーク | AWS独自のオーケストレーション | LangGraph、CrewAI、LlamaIndex、Strands Agents等オープンソース対応 |
| モデル選択 | Amazon Bedrock上のモデルのみ | 任意のモデル(Bedrock内外問わず) |
| ツール統合 | Action Groups(Lambda関数) | Gateway(API/Lambda→MCP変換)、Browser Tool、Code Interpreter |
| メモリ機能 | 基本的なメモリ保持 | 短期/長期メモリ、エピソディックメモリ(経験から学習) |
| 実行時間 | 標準的なリクエスト/レスポンス | 最大8時間の長時間実行をサポート |
| オブザーバビリティ | 基本的なトレース | OpenTelemetry対応、外部ツール連携(Datadog、LangSmith等) |
| ガバナンス | Bedrock Guardrails | Policy(自然言語でルール定義)、Evaluations(13種類の評価機能) |
| カスタマイズ性 | 設定ベース(制限あり) | コードベース(高い自由度) |
| ユースケース | 素早いプロトタイピング、シンプルなRAG/タスク自動化 | 既存エージェントの本番移行、複雑なマルチエージェントシステム |
| コード実装 | なし(基本ノーコード) | あり(AIエージェントのコード実装など) |
また今回の実装では、Bedrock Agentsで構築した基本的なAIエージェントに加えて、
AgentCoreのRuntimeを使ってStrands Agentsフレームワークで実装したAIエージェントもデプロイしてみます。
Strands Agentsとは
Strands Agentsは、AWSが開発したオープンソースのAIエージェントのフレームワークです。
シンプルなAPIで、ツール呼び出し、会話の継続、マルチエージェント連携などを実装できます。
特徴
- シンプルなAPI:
@toolデコレータでツールを定義し、Agentクラスで即座にエージェント化 - モデル非依存: Amazon Bedrock、Anthropic API、OpenAI、Ollama等を切り替え可能
- ツールファースト: Function Callingを活用した柔軟なツール定義
- AgentCoreとのネイティブ統合:
BedrockAgentCoreAppクラスでそのままデプロイ可能 - MCP対応: Model Context Protocolをサポートし、外部ツールと連携
なぜStrands Agentsを選んだのか
LangChain、LangGraph、CrewAIなど他のフレームワークもありますが、今回Strands Agentsを選んだ理由は以下の通りです。
直近で出てきたかなり新めのフレームワークですが、実装の手軽さが魅力かなと思います。
- AWS公式: AWSがメンテナンスしているため、Bedrockとの統合がスムーズ
- シンプル: 学習コストが低く、少ないコード量でエージェントを実装可能
- AgentCoreとの親和性:
BedrockAgentCoreAppによりコード実装の工数を削減
ナレッジベースのソースドキュメント
RAGの元となるソースドキュメントは、以下のような構成で用意しました。
メンテナンスの観点から細かめにドキュメントを分割しています。
documents/tortoise-knowledge/
├── 01_overview.md # リクガメの概要・分類
├── 02_species_giant.md # 大型種の解説
├── 03_species_medium.md # 中型種の解説
├── 04_species_small.md # 小型種の解説
├── 05_species_rare.md # 希少種の解説
├── 06_husbandry.md # 飼育環境・設備
├── 07_nutrition.md # 餌・栄養管理
├── 08_health.md # 健康管理・病気
└── 09_regulations_faq.md # 法規制・よくある質問
なお今回の内容はWikipediaから収集・加工したものです。
これらを別のドキュメントに差し替えれば、好きなテーマの専門家AIエージェントを作れます。
なので皆様が利用される際はお好みのものに変えてください。
実装してみる
それでは実装していきましょう。
冒頭に記載した通り、記事中では主要なリソースに関するコードのみ記載しているので、
全量が欲しい方は以下リポジトリをご参照ください。
なお実装にあたり、以下のツールを利用しています。
- Terraform (v1.5以上)
- AWS CLI (v2推奨、クレデンシャル設定済み)
- jq (JSONパース用)
- Python 3.11以上 (Bedrock AgentsCore呼び出しスクリプト用)
- Docker (AgentCoreパターン用)
また、AWSアカウントで以下のBedrock基盤モデルへのアクセスを有効化しています。
- Anthropic Claude 3.5 Sonnet (LLM用)
- Amazon Titan Text Embeddings V2 (ベクトルストア作成用)
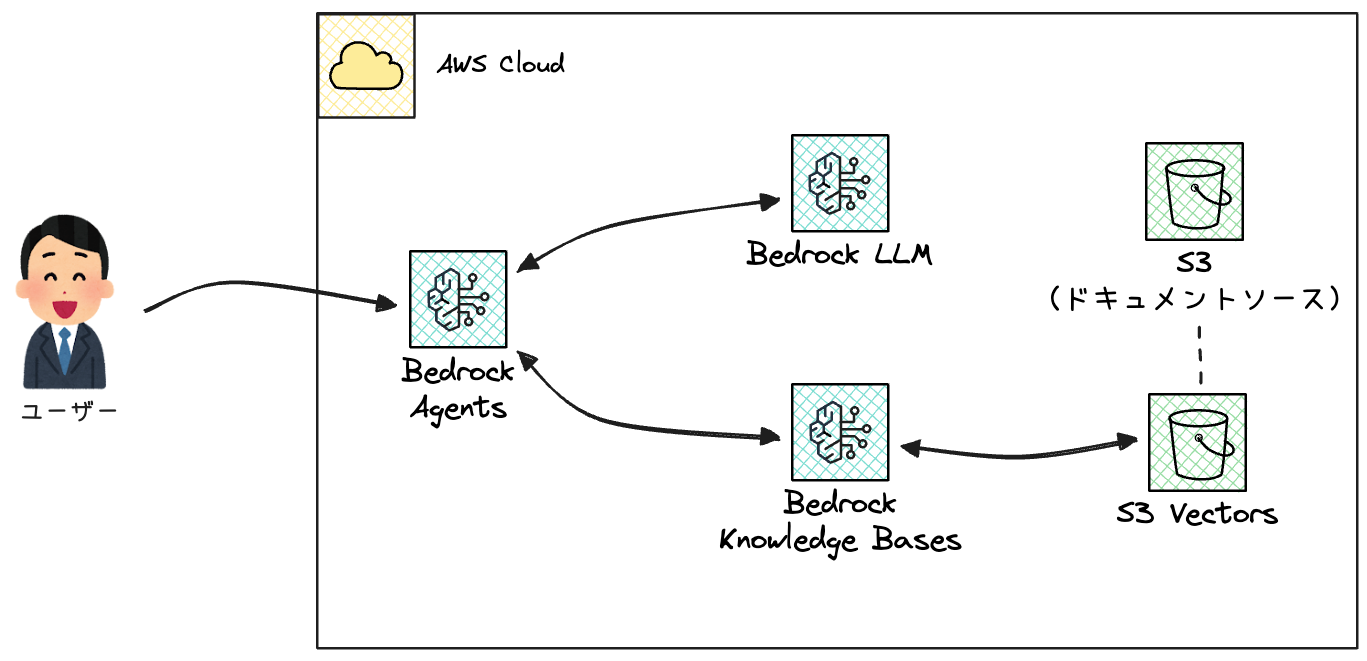
Bedrock Agentsで実装してみる
まずはBedrock Agentsでの実装パターンです。
登場するリソースも少なくハードルが低そうなので、まずはこちらを試してみます。
S3 / S3 Vectors
S3バケット(ソースドキュメント用)と、
S3 Vectorsのバケットおよびインデックスを作成します。
aws_s3vectors_vector_bucketとaws_s3vectors_indexは比較的新しいリソースです。
通常のS3バケット(aws_s3_bucket)とは別物なので注意してください。
# =============================================================================
# S3 Bucket for source documents
# =============================================================================
resource "aws_s3_bucket" "documents" {
bucket = "${var.project_name}-documents"
force_destroy = true
}
resource "aws_s3_object" "documents_prefix" {
bucket = aws_s3_bucket.documents.id
key = "tortoise-knowledge/"
content = ""
}
# =============================================================================
# S3 Vectors
# =============================================================================
resource "aws_s3vectors_vector_bucket" "knowledge_vectors" {
vector_bucket_name = "${var.project_name}-vectors"
}
resource "aws_s3vectors_index" "knowledge_index" {
index_name = "tortoise-agents-knowledge-index"
vector_bucket_name = aws_s3vectors_vector_bucket.knowledge_vectors.vector_bucket_name
# Vector configuration matching Titan Text Embeddings V2
data_type = "float32"
dimension = var.vector_dimension
distance_metric = var.distance_metric
# Metadata configuration for filtering queries
# Bedrock Knowledge Basesが付与するメタデータで2048バイトを超える可能性があるものをnon-filterableに設定し、S3 Vectorsの制限を回避
metadata_configuration {
non_filterable_metadata_keys = [
"AMAZON_BEDROCK_TEXT", # チャンク本体テキスト(最大容量を占める)
"AMAZON_BEDROCK_METADATA", # ソース情報等のメタデータ
"x-amz-bedrock-kb-source-uri",
"x-amz-bedrock-kb-chunk-id",
"x-amz-bedrock-kb-data-source-id"
]
}
}
実装のポイント:
dimension: 埋め込みモデルの出力次元数と一致させる必要があります。Titan Text Embeddings V2では256、384、1024から選択可能で、今回は1024を使用していますdistance_metric: ベクトル間の類似度計算方法を指定します。一般的なRAGではcosine(コサイン類似度)が推奨されますmetadata_configuration: Knowledge Basesが自動付与するメタデータのうち、大きなデータをnon-filterableに設定することで、2048バイト制限を回避します
補足:
S3 Vectorsはフィルタリング可能なメタデータに2048バイトの制限があります。
そしてBedrock Knowledge Basesが付与するAMAZON_BEDROCK_TEXT(チャンク本体テキスト)などがこの制限を超えることがあるため、metadata_configurationでnon_filterable_metadata_keysに設定しておくことをおすすめします。
なお、この設定はインデックス作成時のみ可能で、後から変更する場合はインデックスの再作成が必要です。
Bedrock Knowledge Bases
Bedrock Knowledge BasesでS3 Vectorsをベクトルストアとして指定します。
storage_configurationのtypeにS3_VECTORSを指定し、作成したインデックスのARNを渡すだけで統合できます。
また、aws_bedrockagent_data_sourceリソースでドキュメントのソースとなるS3バケットを定義します。
Knowledge Baseはこのデータソースからドキュメントを取り込み、チャンキング・ベクトル化してS3 Vectorsに格納します。
# Bedrock Knowledge Base with S3 Vectors
resource "aws_bedrockagent_knowledge_base" "tortoise" {
name = "${var.project_name}-kb"
role_arn = aws_iam_role.bedrock_knowledge_base.arn
description = "Knowledge base containing tortoise care information, species details, and health management guidelines."
knowledge_base_configuration {
type = "VECTOR"
vector_knowledge_base_configuration {
# Titan Text Embeddings V2 model
embedding_model_arn = "arn:${data.aws_partition.current.partition}:bedrock:${data.aws_region.current.name}::foundation-model/${var.embedding_model_id}"
embedding_model_configuration {
bedrock_embedding_model_configuration {
dimensions = var.vector_dimension
embedding_data_type = "FLOAT32"
}
}
}
}
# S3 Vectors as the vector store
storage_configuration {
type = "S3_VECTORS"
s3_vectors_configuration {
index_arn = aws_s3vectors_index.knowledge_index.index_arn
}
}
depends_on = [
aws_iam_role_policy.bedrock_kb_s3_access,
aws_iam_role_policy.bedrock_kb_s3vectors_access,
aws_iam_role_policy.bedrock_kb_model_access
]
}
# Data Source - S3 bucket containing tortoise knowledge documents
resource "aws_bedrockagent_data_source" "tortoise_docs" {
knowledge_base_id = aws_bedrockagent_knowledge_base.tortoise.id
name = "${var.project_name}-knowledge-docs"
description = "Source documents containing tortoise care guides, species information, and health management tips."
data_source_configuration {
type = "S3"
s3_configuration {
bucket_arn = aws_s3_bucket.documents.arn
# Specify prefix to limit scope to tortoise-related documents
inclusion_prefixes = ["tortoise-knowledge/"]
}
}
}
実装のポイント:
embedding_model_arn: 埋め込みモデルを指定します。今回はTitan Text Embeddings V2を使用していますが、Cohere Embedなども選択可能ですdimensions: S3 Vectorsのインデックスと同じ次元数(1024)を指定します。異なる値を設定するとエラーになりますinclusion_prefixes: 指定したプレフィックス配下のファイルのみを取り込み対象にします。不要なファイルの取り込みを防ぎ、コストを抑制できます- チャンキング設定: 今回は
vector_ingestion_configurationを省略し、デフォルトのチャンキングを使用しています。ドキュメントの特性に応じてFIXED_SIZE、HIERARCHICAL、SEMANTICなどを選択できます
Bedrock Agents
いよいよエージェントの定義です。
instructionでエージェントの振る舞いを定義しており、日本語と英語の両方に対応できるよう指示を入れておきました。
# Bedrock Agent - Tortoise Expert
resource "aws_bedrockagent_agent" "tortoise_expert" {
agent_name = "${var.project_name}-agent"
agent_resource_role_arn = aws_iam_role.bedrock_agent.arn
foundation_model = var.foundation_model_id
description = "An AI expert specialized in tortoise care, species identification, and health management."
# Session timeout: 30 minutes
idle_session_ttl_in_seconds = 1800
# Agent instruction - defines the agent's behavior and expertise
instruction = <<-EOT
You are an expert AI assistant specialized in tortoises (land-dwelling turtles).
Your knowledge covers:
1. **Species Identification**: You can identify various tortoise species including
Hermann's tortoise, Russian tortoise, Sulcata tortoise, Red-footed tortoise,
Leopard tortoise, and more.
2. **Care Guidelines**: You provide detailed guidance on:
- Proper enclosure setup (indoor and outdoor)
- Temperature and humidity requirements
- Lighting needs (UVB and basking)
- Substrate choices
3. **Nutrition**: You advise on:
- Appropriate diet for different species
- Safe plants and vegetables
- Calcium and vitamin supplementation
- Foods to avoid
4. **Health Management**: You can discuss:
- Common health issues and symptoms
- When to seek veterinary care
- Preventive care measures
- Hibernation/brumation guidance
**Communication Style**:
- Always respond in a friendly and educational manner
- Provide specific, actionable advice
- Include safety warnings when relevant
- Recommend professional veterinary consultation for health concerns
- Support both English and Japanese responses based on user's language
Use the knowledge base to provide accurate and up-to-date information about tortoise care.
EOT
depends_on = [
aws_iam_role_policy.bedrock_agent_model_access
]
}
# Associate Knowledge Base with Agent
resource "aws_bedrockagent_agent_knowledge_base_association" "tortoise" {
agent_id = aws_bedrockagent_agent.tortoise_expert.agent_id
knowledge_base_id = aws_bedrockagent_knowledge_base.tortoise.id
knowledge_base_state = "ENABLED"
description = "Knowledge base containing tortoise care information for the expert agent."
}
resource "null_resource" "prepare_agent" {
triggers = {
agent_id = aws_bedrockagent_agent.tortoise_expert.agent_id
kb_association = aws_bedrockagent_agent_knowledge_base_association.tortoise.id
}
provisioner "local-exec" {
command = "aws bedrock-agent prepare-agent --agent-id ${aws_bedrockagent_agent.tortoise_expert.agent_id} --region ${var.aws_region}"
}
depends_on = [
aws_bedrockagent_agent_knowledge_base_association.tortoise,
aws_iam_role_policy.bedrock_agent_kb_access
]
}
実装のポイント:
instruction: エージェントのペルソナと振る舞いを定義する最も重要な設定です。具体的なタスク、対応可能な範囲、回答スタイルを明確に記述することで、一貫性のある応答が得られますaws_bedrockagent_agent_knowledge_base_association: AgentとKnowledge Baseを紐付けるリソースです。これがないとエージェントはナレッジベースを参照できませんnull_resourceとprepare-agent: Terraformだけではエージェントの「準備」ステップを実行できないため、local-execでaws bedrock-agent prepare-agentコマンドを実行しています。このコマンドを実行しないとエージェントが利用可能な状態になりません
invoke_agent.py
エージェントを呼び出すPythonスクリプトです。
AWS CLIでもBedrock Agentsを呼び出せますが、ストリーミングレスポンスの処理やインタラクティブな対話をより簡単に扱えるよう、Pythonスクリプトを用意しました。
#!/usr/bin/env python3
"""Bedrock Agent Invocation Script"""
import os
import sys
import uuid
import argparse
import boto3
from dotenv import load_dotenv
def load_config() -> dict:
"""Load configuration from environment variables."""
load_dotenv()
required_vars = ["AGENT_ID", "AGENT_ALIAS_ID"]
missing_vars = [var for var in required_vars if not os.getenv(var)]
if missing_vars:
raise ValueError(f"Missing required environment variables: {', '.join(missing_vars)}")
return {
"region": os.getenv("AWS_REGION", "ap-northeast-1"),
"agent_id": os.getenv("AGENT_ID"),
"agent_alias_id": os.getenv("AGENT_ALIAS_ID"),
}
def invoke_agent(
client,
agent_id: str,
agent_alias_id: str,
input_text: str,
session_id: str | None = None,
) -> tuple[str, str]:
"""Invoke a Bedrock Agent with the given input text."""
if session_id is None:
session_id = str(uuid.uuid4())
response = client.invoke_agent(
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=session_id,
inputText=input_text,
)
# ストリーミングレスポンスを処理
completion_text = ""
for event in response.get("completion", []):
if "chunk" in event:
chunk_data = event["chunk"]
if "bytes" in chunk_data:
text = chunk_data["bytes"].decode("utf-8")
completion_text += text
print(text, end="", flush=True)
print()
return completion_text, session_id
def interactive_mode(client, agent_id: str, agent_alias_id: str):
"""Run the agent in interactive conversation mode."""
session_id = str(uuid.uuid4())
print("=" * 60)
print("Tortoise Expert Agent - Interactive Mode")
print("=" * 60)
print(f"Session ID: {session_id}")
print("Type 'quit' or 'exit' to end the conversation.")
print("Type 'new' to start a new session.")
print("=" * 60)
print()
while True:
try:
user_input = input("You: ").strip()
except (EOFError, KeyboardInterrupt):
print("\nGoodbye!")
break
if not user_input:
continue
if user_input.lower() in ["quit", "exit"]:
print("Goodbye!")
break
if user_input.lower() == "new":
session_id = str(uuid.uuid4())
print(f"\nNew session started: {session_id}\n")
continue
print("\nAgent: ", end="")
_, session_id = invoke_agent(
client=client,
agent_id=agent_id,
agent_alias_id=agent_alias_id,
input_text=user_input,
session_id=session_id,
)
print()
def main():
"""Main entry point for the script."""
parser = argparse.ArgumentParser(description="Invoke Amazon Bedrock Agent")
parser.add_argument("query", nargs="?", help="The question to ask the agent")
parser.add_argument("-i", "--interactive", action="store_true", help="Run in interactive mode")
args = parser.parse_args()
config = load_config()
client = boto3.client("bedrock-agent-runtime", region_name=config["region"])
if args.interactive or args.query is None:
interactive_mode(client, config["agent_id"], config["agent_alias_id"])
else:
print("Agent: ", end="")
invoke_agent(client, config["agent_id"], config["agent_alias_id"], args.query)
if __name__ == "__main__":
main()
実装のポイント:
- ストリーミングレスポンス:
invoke_agentのレスポンスはストリーミング形式で返ってきます。response.get("completion", [])をイテレートし、チャンクごとにデコードして出力することでリアルタイムな応答表示を実現しています session_idによるセッション管理: 同じsession_idを使い続けることで、複数のやり取りにわたって会話のコンテキストを保持できます。新しいセッションを開始したい場合は新しいUUIDを生成します- インタラクティブモード:
-iオプションで対話モードに入り、連続して質問できます。newコマンドでセッションをリセットできる機能も実装しています
デプロイ手順
以下の手順でデプロイします。
1. Terraformでインフラを構築
terraform init && terraform apply
2. ドキュメントをS3にアップロード
BUCKET=$(terraform output -json s3_documents_bucket | jq -r '.name')
aws s3 sync ../../documents/tortoise-knowledge/ s3://${BUCKET}/tortoise-knowledge/
3. Bedrock Knowledge Basesを同期
KB_ID=$(terraform output -json knowledge_base | jq -r '.id')
DS_ID=$(terraform output -json data_source | jq -r '.id')
aws bedrock-agent start-ingestion-job --knowledge-base-id ${KB_ID} --data-source-id ${DS_ID}
# ジョブの状態を確認 (STATUSがCOMPLETEになるまで待機)
aws bedrock-agent list-ingestion-jobs --knowledge-base-id ${KB_ID} --data-source-id ${DS_ID}
動作確認
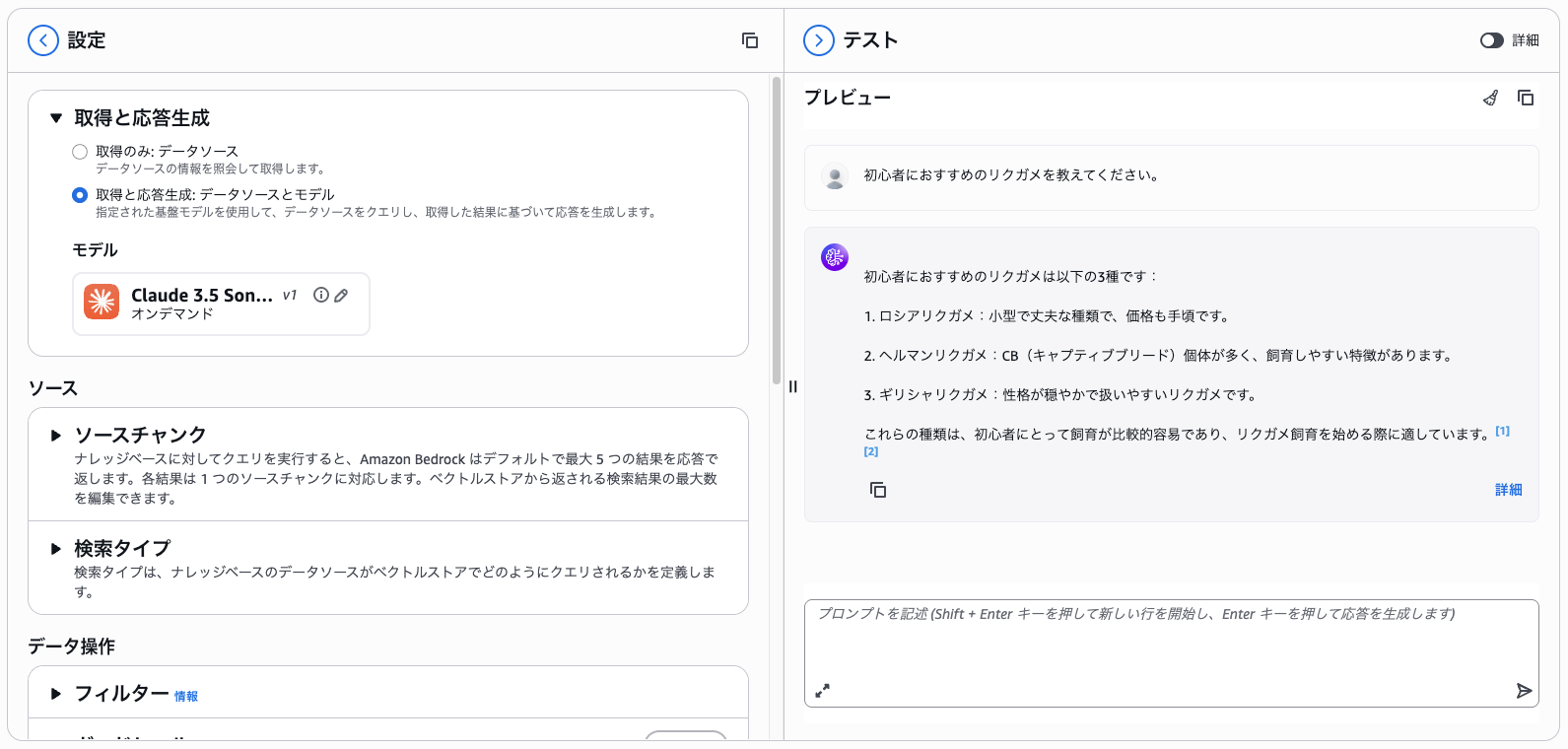
Bedrock Knowledge Basesに直接クエリしてみる
Bedrock Knowledge Basesに対してクエリすることもできるので、まずはテストしてみます。
KB_ID=$(terraform output -json knowledge_base | jq -r '.id')
MODEL_ARN=$(terraform output -json foundation_model | jq -r '.arn')
aws bedrock-agent-runtime retrieve-and-generate \
--input '{"text": "初心者におすすめのリクガメを教えてください。"}' \
--retrieve-and-generate-configuration '{
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "'${KB_ID}'",
"modelArn": "'${MODEL_ARN}'"
}
}'
出力が長いですが、正常に結果が得られます。
{
"citations": [
{
"generatedResponsePart": {
"textResponsePart": {
"span": {
"end": 135,
"start": 0
},
"text": "初心者におすすめのリクガメは以下の3種類です:\n\n1. ロシアリクガメ:小型で丈夫で、価格も手頃なため初心者に適しています。\n\n2. ヘルマンリクガメ:CB個体(繁殖個体)が多く、飼育がしやすい特徴があります。\n\n3. ギリシャリクガメ:性格が穏やかで扱いやすい種類です。"
}
},
"retrievedReferences": [
{
"content": {
"text": "**英名**: Marginated tortoise **特徴**: - 体長: 最大35cm - チチュウカイリクガメ属で最大種 - 原産地: ギリシャ、イタリア南部 - 成体の甲羅後縁が大きく反り返る --- ## 初心者におすすめのリクガメ 以下の3種が初心者におすすめです: 1. **ロシアリクガメ**: 小型で丈夫、価格も手頃 2. **ヘルマンリクガメ**: CB個体が多く飼育しやすい 3. **ギリシャリクガメ**: 性格が穏やかで扱いやすい",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://tortoise-ai-bedrock-agents-documents/tortoise-knowledge/04_species_small.md"
},
"type": "S3"
},
"metadata": {
"x-amz-bedrock-kb-source-file-modality": "TEXT",
"x-amz-bedrock-kb-chunk-id": "a3b203b4-9db0-422d-87c5-16ce29d1ec4f",
"x-amz-bedrock-kb-data-source-id": "GTQQSZFJ7K"
}
},
{
"content": {
"text": "### Q: リクガメは多頭飼いできますか? A: 種類と個体によります: - オス同士は縄張り争いをすることがある - 十分な広さがあれば可能 - 餌の取り合いに注意 - 別々のケージでの飼育が安全 ### Q: 屋
外飼育はできますか? A: 条件が整えば可能です: - 脱走防止の柵 (地中にも埋める) - 日陰と日向の両方を確保 - 雨風を防げるシェルター - 冬季は室内に移動 - 野良猫やカラスなどの天敵対策 ### Q: 初心者におすすめのリクガメは? A:
以下の3種が初心者におすすめです: 1. **ロシアリクガメ**: 小型で丈夫、価格も手頃 2.",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://tortoise-ai-bedrock-agents-documents/tortoise-knowledge/09_regulations_faq.md"
},
"type": "S3"
},
"metadata": {
"x-amz-bedrock-kb-source-file-modality": "TEXT",
"x-amz-bedrock-kb-chunk-id": "d52128ec-69f6-473b-ba38-807422d3239a",
"x-amz-bedrock-kb-data-source-id": "GTQQSZFJ7K"
}
}
]
}
],
"output": {
"text": "初心者におすすめのリクガメは以下の3種類です:\n\n1. ロシアリクガメ:小型で丈夫で、価格も手頃なため初心者に適しています。\n\n2. ヘルマンリクガメ:CB個体(繁殖個体)が多く、飼育がしやすい特徴があります。
\n\n3. ギリシャリクガメ:性格が穏やかで扱いやすい種類です。"
},
"sessionId": "f02c3c2d-092e-498e-89c0-19dff2f8bffe"
}
また同様にマネジメントコンソールからも、モデルを選択してクエリができます。
Bedrock Agentsを使ってみる
次にBedrock Agentsを使ってみます。
実行には前述紹介したテスト用のスクリプト(invoke_agent.py)を使います。
質問してみると以下のような回答を返ってきます。
$ python invoke_agent.py "初心者におすすめのリクガメを教えてください。"
Agent: 初心者におすすめのリクガメは以下の3種類です:
1. ロシアリクガメ:小型で丈夫で、価格も手頃です。
2. ヘルマンリクガメ:CB個体(繁殖個体)が多く、飼育しやすい特徴があります。
3. ギリシャリクガメ:性格が穏やかで扱いやすい種類です。
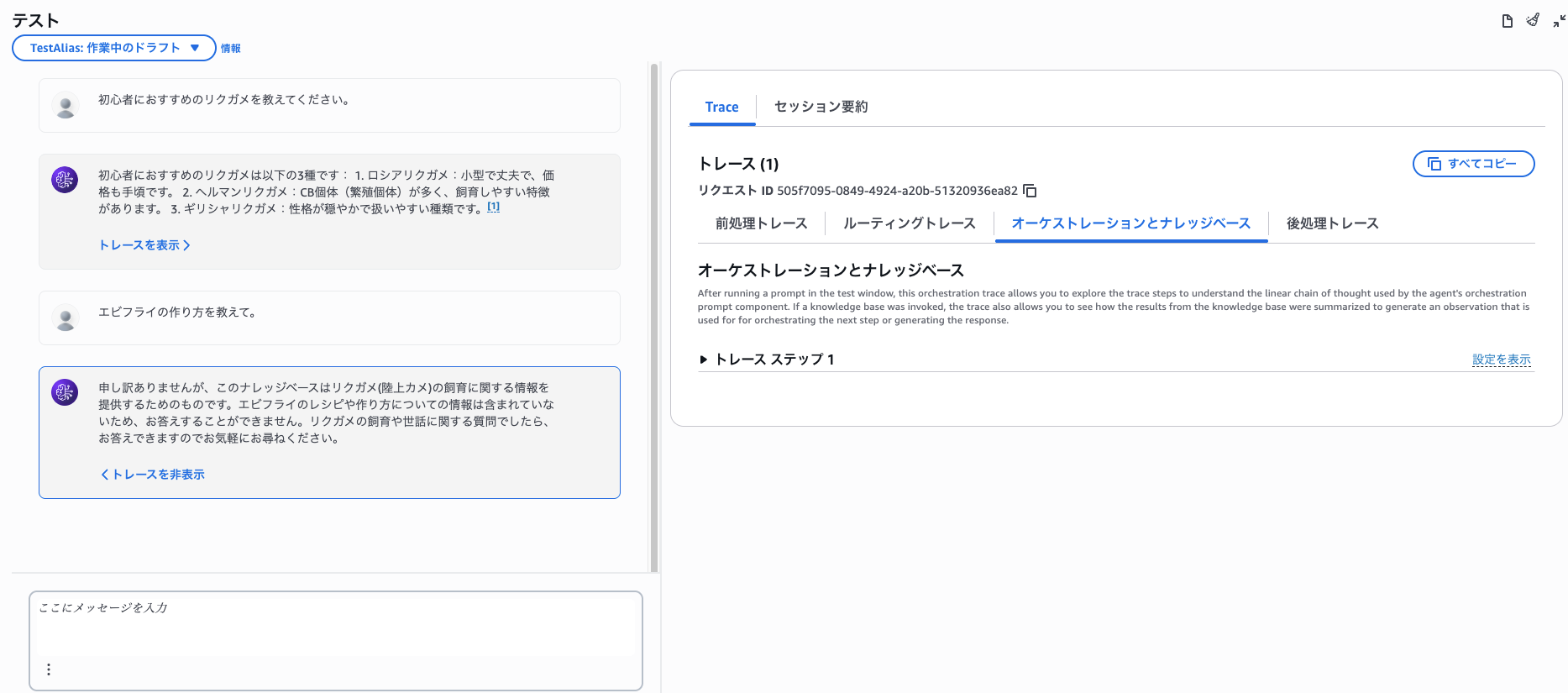
またリクガメに関する質問には答えてくれますが、関係ない質問には回答ができません。
このことからBedrock Knowledge Basesの情報のみ参照できることが確認できます。
$ python invoke_agent.py -i
============================================================
Tortoise Expert Agent - Interactive Mode
============================================================
Session ID: a9f7c3f8-9fb1-4d8e-b9fd-1938f6f5121e
Type 'quit' or 'exit' to end the conversation.
Type 'new' to start a new session.
============================================================
You: 最小のリクガメを教えて。
Agent: シモフリヒラセリクガメ(Chersobius signatus)が世界最小のリクガメで、最大甲長は9.6cmです。これはカメ目全体の中でも最小種となります。
You: エビフライの作り方を教えて。
Agent: 申し訳ありませんが、この知識ベース検索ツールは主にリクガメ(陸亀)のケアに関する情報を提供するものです。エビフライの作り方については、このツールでは適切な情報を提供することができません。
料理のレシピやエビフライの作り方については、料理専門のウェブサイトやレシピ本などを参照していただくことをお勧めします。
同様にマネジメントコンソールからテストすることもできます。
Bedrock AgentCoreで実装してみる
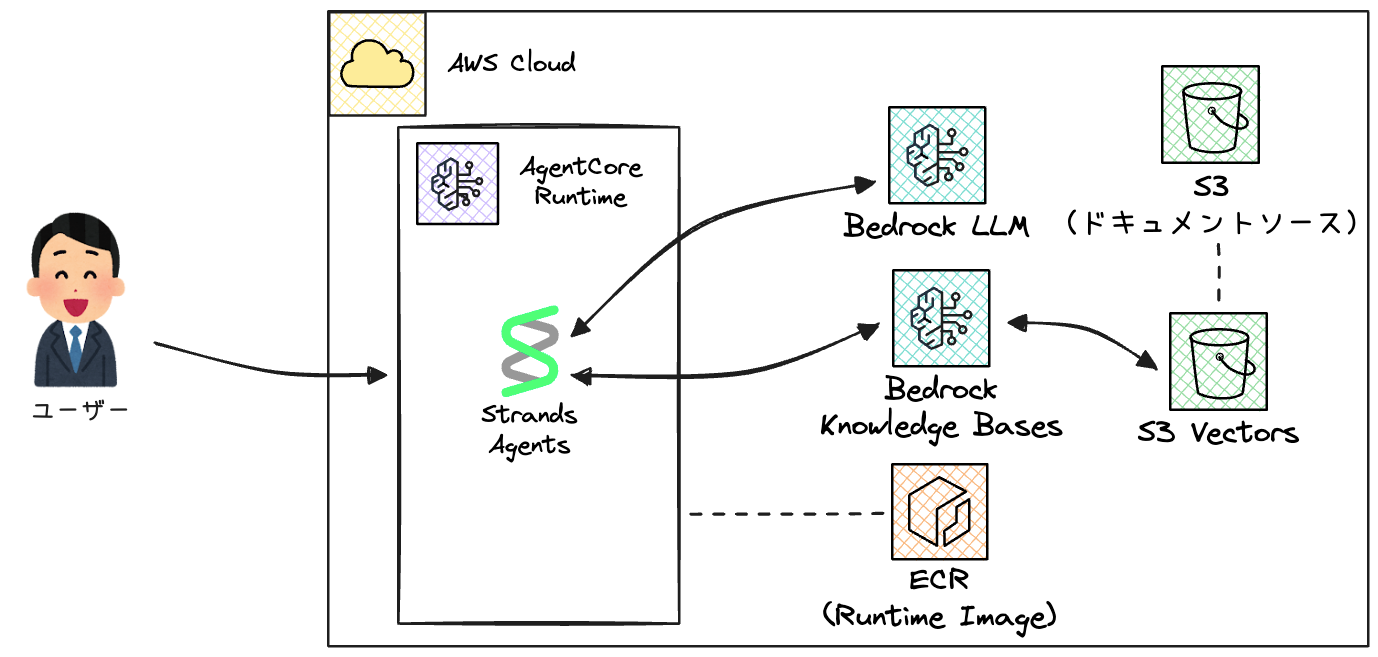
次にBedrock AgentCoreの実装を紹介します。
Bedrock Agentsと比較して設定するリソースが多くなりますが、Bedrock AgentCore以外のリソースはBedrock Agentsのパターンとほぼ同じなので、それらの説明は割愛します。
Bedrock AgentCore
ECRリポジトリとBedrock AgentCoreのリソースを作成します。
それぞれのリソースの役割は以下の通りです。
- ECR: Runtimeにデプロイするコンテナイメージを格納するリポジトリ
- AgentCore Runtime: AIエージェントをホスティングするサーバーレス実行環境
- AgentCore Runtime Endpoint: Runtimeへのアクセスを提供するエンドポイント
# -----------------------------------------------------------------------------
# ECR Repository for Agent Container
# -----------------------------------------------------------------------------
resource "aws_ecr_repository" "agentcore_runtime" {
name = "${var.project_name}-agentcore-runtime"
image_tag_mutability = "MUTABLE"
force_delete = true
image_scanning_configuration {
scan_on_push = true
}
encryption_configuration {
encryption_type = "AES256"
}
tags = {
Name = "${var.project_name}-agentcore-runtime"
}
}
resource "aws_ecr_lifecycle_policy" "agentcore_runtime" {
repository = aws_ecr_repository.agentcore_runtime.name
policy = jsonencode({
rules = [
{
rulePriority = 1
description = "Keep last 5 images"
selection = {
tagStatus = "any"
countType = "imageCountMoreThan"
countNumber = 5
}
action = {
type = "expire"
}
}
]
})
}
# -----------------------------------------------------------------------------
# AgentCore Runtime
# -----------------------------------------------------------------------------
resource "awscc_bedrockagentcore_runtime" "tortoise" {
count = var.agentcore_runtime_image_tag != "" ? 1 : 0
agent_runtime_name = "tortoise_kb_agent_${random_id.suffix.hex}"
description = "Tortoise expert agent using Strands Agents framework with Knowledge Base integration"
role_arn = aws_iam_role.agentcore_runtime.arn
agent_runtime_artifact = {
container_configuration = {
container_uri = "${aws_ecr_repository.agentcore_runtime.repository_url}:${var.agentcore_runtime_image_tag}"
}
}
network_configuration = {
network_mode = "PUBLIC"
}
environment_variables = {
"KNOWLEDGE_BASE_ID" = aws_bedrockagent_knowledge_base.tortoise.id
"AWS_REGION" = var.aws_region
"AWS_DEFAULT_REGION" = var.aws_region
"MODEL_ID" = var.foundation_model_id
}
tags = {
Project = var.project_name
Environment = var.environment
ManagedBy = "terraform"
}
depends_on = [time_sleep.wait_for_runtime_iam]
}
# -----------------------------------------------------------------------------
# AgentCore Runtime Endpoint
# -----------------------------------------------------------------------------
resource "awscc_bedrockagentcore_runtime_endpoint" "tortoise" {
count = var.agentcore_runtime_image_tag != "" ? 1 : 0
name = "tortoise_kb_endpoint_${random_id.suffix.hex}"
description = "Endpoint for tortoise expert agent"
agent_runtime_id = awscc_bedrockagentcore_runtime.tortoise[0].agent_runtime_id
tags = {
Project = var.project_name
Environment = var.environment
ManagedBy = "terraform"
}
}
実装のポイント:
environment_variables: コンテナに渡す環境変数を定義します。KNOWLEDGE_BASE_IDやMODEL_IDなど、エージェントが動作するために必要な設定をここで注入します- 2段階デプロイ:
count条件でagentcore_runtime_image_tagが空の場合はRuntimeを作成しません。これにより、最初のデプロイでECRリポジトリのみを作成し、イメージをプッシュしてから2回目のデプロイでRuntimeを作成する2段階デプロイが可能になります
補足:
awscc_bedrockagentcore_runtimeとawscc_bedrockagentcore_runtime_endpointはAWSCCプロバイダーのリソースです。通常のAWSプロバイダーとは異なり、AWS Cloud Control API経由でリソースを管理します。
Strands Agents
AgentCoreにデプロイするエージェントのコードです。
Strands Agentsフレームワークを使用しています。
"""
Tortoise Expert Agent using Strands Agents Framework with BedrockAgentCoreApp.
This agent uses Amazon Bedrock Knowledge Base to answer questions about tortoises.
It retrieves relevant information from the knowledge base and generates responses
with proper citations.
"""
import json
import os
from typing import Optional
import boto3
from strands import Agent, tool
from bedrock_agentcore.runtime import BedrockAgentCoreApp
# Environment variables
KNOWLEDGE_BASE_ID = os.environ.get("KNOWLEDGE_BASE_ID", "")
AWS_REGION = os.environ.get("AWS_REGION", "ap-northeast-1")
MODEL_ID = os.environ.get("MODEL_ID", "apac.anthropic.claude-3-5-sonnet-20241022-v2:0")
# Initialize BedrockAgentCoreApp
app = BedrockAgentCoreApp()
# Bedrock Agent Runtime client
bedrock_agent_runtime = boto3.client(
"bedrock-agent-runtime",
region_name=AWS_REGION
)
@tool
def kb_search(query: str, max_results: Optional[int] = 5) -> str:
"""
Search the tortoise knowledge base for relevant information.
Args:
query: The search query about tortoises
max_results: Maximum number of results to return (default: 5)
Returns:
JSON string containing search results with content, source URIs, and metadata
"""
if not KNOWLEDGE_BASE_ID:
return json.dumps({"error": "KNOWLEDGE_BASE_ID environment variable is not set"})
try:
response = bedrock_agent_runtime.retrieve(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
retrievalQuery={"text": query},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": max_results,
"overrideSearchType": "SEMANTIC",
}
},
)
results = []
for i, result in enumerate(response.get("retrievalResults", []), 1):
content = result.get("content", {}).get("text", "")
location = result.get("location", {})
score = result.get("score", 0)
# Extract S3 URI if available
s3_location = location.get("s3Location", {})
s3_uri = s3_location.get("uri", "Unknown")
# Extract metadata
metadata = result.get("metadata", {})
results.append({
"rank": i,
"content": content,
"source_uri": s3_uri,
"score": score,
"metadata": metadata,
})
return json.dumps(results, ensure_ascii=False, indent=2)
except Exception as e:
return json.dumps({"error": str(e)})
# System prompt for the tortoise expert agent
SYSTEM_PROMPT = """You are an expert AI assistant specialized in tortoises (land-dwelling turtles).
Your knowledge covers:
1. **Species Identification**: You can identify various tortoise species including
Hermann's tortoise, Russian tortoise, Sulcata tortoise, Red-footed tortoise,
Leopard tortoise, and more.
2. **Care Guidelines**: You provide detailed guidance on:
- Proper enclosure setup (indoor and outdoor)
- Temperature and humidity requirements
- Lighting needs (UVB and basking)
- Substrate choices
3. **Nutrition**: You advise on:
- Appropriate diet for different species
- Safe plants and vegetables
- Calcium and vitamin supplementation
- Foods to avoid
4. **Health Management**: You can discuss:
- Common health issues and symptoms
- When to seek veterinary care
- Preventive care measures
- Hibernation/brumation guidance
**Important Instructions**:
- Use the kb_search tool to find relevant information from the knowledge base before answering
- Always cite your sources using the format: [Source: filename]
- Respond in a friendly and educational manner
- Provide specific, actionable advice
- Include safety warnings when relevant
- Recommend professional veterinary consultation for health concerns
- Support both English and Japanese responses based on user's language
When citing sources, use the following format at the end of your response:
---
**References**:
[1] filename - s3://bucket/path/file
"""
def create_agent() -> Agent:
"""Create and configure the tortoise expert agent."""
agent = Agent(
system_prompt=SYSTEM_PROMPT,
tools=[kb_search],
)
return agent
@app.entrypoint
async def invoke(payload: dict) -> dict:
"""
Main entrypoint for AgentCore Runtime.
Args:
payload: Request payload containing the user's question
Returns:
Response dictionary with the agent's answer
"""
# Extract user message from payload
user_message = payload.get("prompt", payload.get("message", ""))
if not user_message:
return {
"status": "error",
"error": "No prompt or message provided"
}
try:
agent = create_agent()
# Generate response
response = agent(user_message)
response_text = str(response)
return {
"status": "success",
"response": response_text,
"knowledge_base_id": KNOWLEDGE_BASE_ID,
}
except Exception as e:
return {
"status": "error",
"error": str(e)
}
# Entry point for AgentCore Runtime
if __name__ == "__main__":
app.run()
実装のポイント:
@toolデコレータ: Strands Agentsでツールを定義する方法です。関数に@toolを付けるだけで、エージェントが呼び出し可能なツールとして認識されます。docstringがツールの説明として使われるため、適切に記述することが重要ですBedrockAgentCoreApp: AgentCore Runtimeとの統合を担うクラスです。@app.entrypointデコレータで呼び出しエントリポイントを定義し、app.run()でサーバーを起動しますkb_searchツール:bedrock-agent-runtimeのretrieveAPIを呼び出してKnowledge Baseから情報を検索します。overrideSearchType: SEMANTICでセマンティック検索を明示的に指定しています
Dockerfile
# Amazon Bedrock AgentCore Runtime container
# NOTE: AgentCore only supports ARM64 architecture
FROM public.ecr.aws/docker/library/python:3.11-slim
WORKDIR /app
# Install dependencies
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Create non-root user for security
RUN useradd -m -u 1000 bedrock_agentcore
USER bedrock_agentcore
# Expose ports for AgentCore Runtime
EXPOSE 8080
EXPOSE 8000
# Copy application code
COPY . .
# Health check endpoint
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/ping || exit 1
# Entry point with OpenTelemetry instrumentation
CMD ["opentelemetry-instrument", "python", "-m", "agent"]
実装のポイント:
- ARM64アーキテクチャ必須: AgentCore RuntimeはARM64アーキテクチャのみをサポートしています。Intel/AMD CPUのマシンでビルドする場合は
docker-buildxでクロスコンパイルが必要です - 非rootユーザー: セキュリティベストプラクティスとして、
bedrock_agentcoreという非rootユーザーを作成してアプリケーションを実行しています - OpenTelemetry計装:
opentelemetry-instrumentコマンドでアプリケーションを起動することで、自動的にトレーシングやメトリクス収集が有効になります。これにより、AgentCoreのモニタリング機能と連携できます
AgentCoreデプロイ手順
Bedrock Agents同様に以下の手順が必要となりますが、
同じ内容なので割愛します。
-
- Terraformでインフラを構築
-
- ドキュメントをS3にアップロード
-
- Bedrock Knowledge Basesを同期
1. Dockerイメージをビルド・プッシュ
cd docker
ECR_URL=$(cd .. && terraform output -json agentcore_runtime_ecr | jq -r '.repository_url')
# ビルド(docker-buildx利用)
docker-buildx create --use --name agentcore-builder 2>/dev/null || true
docker-buildx build --platform linux/arm64 -t tortoise-agentcore-runtime --load .
# プッシュ
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin ${ECR_URL%%/*}
docker tag tortoise-agentcore-runtime:latest ${ECR_URL}:latest
docker push ${ECR_URL}:latest
補足:
AgentCore RuntimeはARM64アーキテクチャのみサポートしています。
Intel/AMD Macをお使いの場合はdocker-buildxでのクロスコンパイルが必要です。
2. AgentCore Runtimeをデプロイ
terraform apply -var="agentcore_runtime_image_tag=latest"
AgentCore動作確認
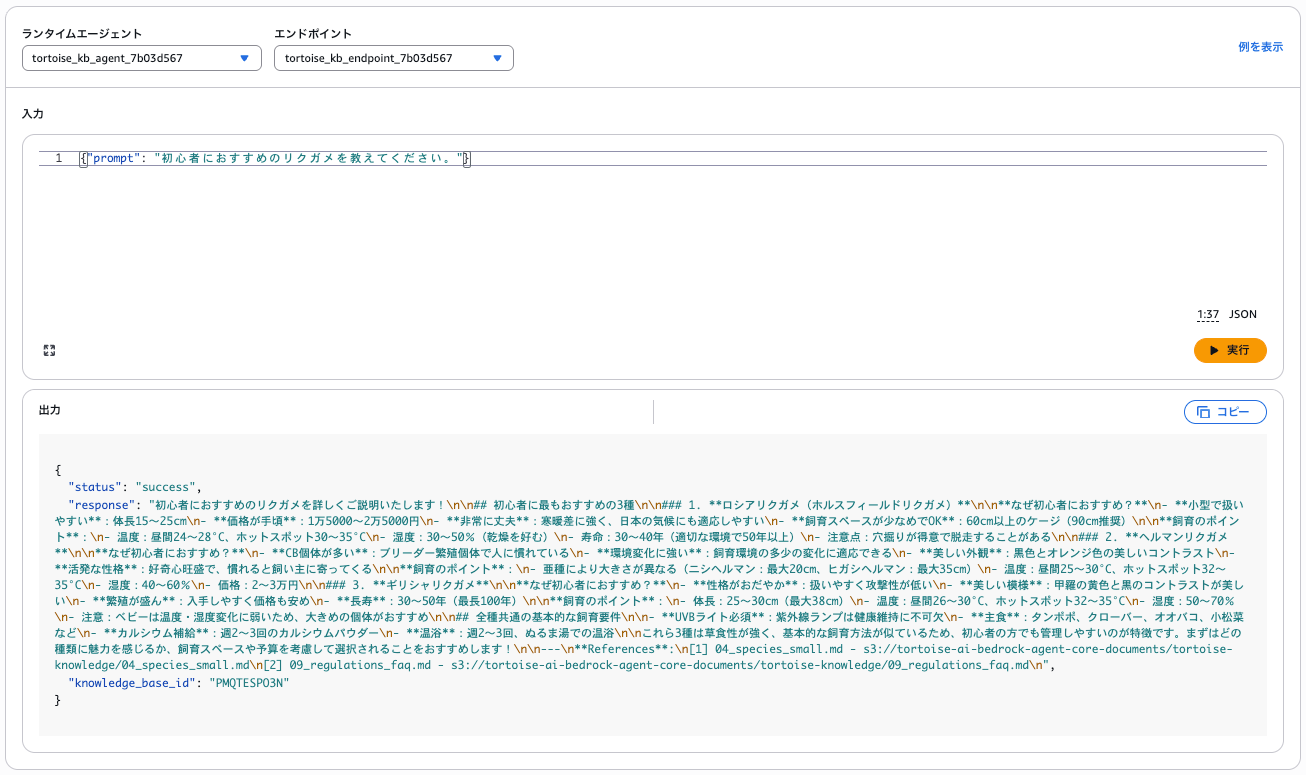
実際に質問してみると、詳細な回答が返ってきます。
Strands Agentsフレームワークで実装したエージェントが、ナレッジベースから情報を検索して詳細な回答を生成してくれています。
RUNTIME_ARN=$(terraform output -json agentcore_runtime | jq -r '.runtime_arn')
aws bedrock-agentcore invoke-agent-runtime \
--agent-runtime-arn ${RUNTIME_ARN} \
--payload fileb://<(echo '{"prompt": "初心者におすすめのリクガメを教えてください。"}') \
--content-type application/json \
/dev/stdout | jq -r '.response'
初心者におすすめのリクガメについて詳しくご説明いたします。
## 初心者におすすめの3種
知識ベースの情報によると、初心者に特におすすめのリクガメは以下の3種です:
### 1. **ロシアリクガメ (Testudo horsfieldii)**
**おすすめポイント:**
- **小型で丈夫**: 成体で15〜25cm、丈夫で飼育しやすい
- **価格が手頃**: 1万5,000〜2万5,000円程度
- **日本の気候に適応しやすい**: 寒暖差に強い
- **寿命**: 30〜40年(適切な環境で50年以上)
**特徴:**
- 4本爪を持つことから「ヨツユビリクガメ」とも呼ばれる
- 乾燥を好む(湿度30〜50%)
- 穴掘りが得意なため、屋外飼育時は脱走に注意
### 2. **ヘルマンリクガメ (Testudo hermanni)**
**おすすめポイント:**
- **CB個体が多く飼育しやすい**: 人工繁殖個体が流通している
- **美しい外観**: 黒色とオレンジ色のコントラストが美しい
- **活発で人懐っこい**: 馴れると飼い主に寄ってくる
**亜種による違い:**
- ニシヘルマン: 甲長平均17cm(最大20cm)
- ヒガシヘルマン: 甲長平均30cm(最大35cm)
**特徴:**
- 寿命: 30〜50年(最長75年)
- 好奇心旺盛で活発な性格
- 甲羅にツヤがある
### 3. **ギリシャリクガメ (Testudo graeca)**
**おすすめポイント:**
- **性格が穏やかで扱いやすい**: 温和な性質
- **繁殖が盛んで価格が安め**: 入手しやすい
- **美しい甲羅模様**: 黄色と黒のコントラストが美しい
**特徴:**
- 体長: 25〜30cm(最大38cm)
- 寿命: 30〜50年(最長100年)
- ギリシャ織のような甲羅の模様が名前の由来
## 飼育の基本要件
これら3種に共通する基本的な飼育要件:
- **UVB照明**: 必須
- **ケージサイズ**: 90cm以上推奨
- **温度管理**: 昼間25〜30°C、ホットスポット32〜35°C
- **餌**: タンポポ、クローバー、小松菜などの野草・野菜
## 注意点
- ベビーは温度・湿度変化に弱いため、ある程度成長した個体の購入がおすすめ
- 冬眠する種類なので、適切な管理が必要
- 屋外飼育時は脱走防止対策が重要
これら3種は比較的丈夫で飼育しやすく、初心者の方が最初に飼うリクガメとして適しています。ご自身の飼育環境や好みに合わせて選択されることをおすすめします。
---
**References**:
[1] 04_species_small.md - s3://tortoise-ai-bedrock-agent-core-documents/tortoise-knowledge/04_species_small.md
[2] 09_regulations_faq.md - s3://tortoise-ai-bedrock-agent-core-documents/tortoise-knowledge/09_regulations_faq.md
[3] 01_overview.md - s3://tortoise-ai-bedrock-agent-core-documents/tortoise-knowledge/01_overview.md
同様にマネジメントコンソールからテストすることもできます。
もし追加で実装するなら?
本ブログはここまでとなりますが、正直今回はRAGを組んでそれをAIエージェントで使っただけになってしまいました...。
もしBedrock AgentCoreを使ったAIエージェントとして機能を拡張させていくのであれば、以下のようなものが考えられます。
- AgentCore Memory
- 会話履歴や学習内容を永続化し、ユーザーごとにパーソナライズされた応答を実現できます。
- 「前回聞いたリクガメの温度設定を教えて」といった文脈を跨いだ質問に対応可能になります
- AgentCore Gateway
- MCPサーバーとしてAPIやLambda関数をツール化できます。
- 例えばWeb検索できる機能を追加して、「東京で販売しているヘルマンリクガメを探す」といったタスクを実行できます
- AgentCore Code Interpreter
- サンドボックス環境でPythonコードを実行できます。
- リクガメの飼育環境シミュレーション(温度・湿度の計算)や、餌のカロリー計算などに活用できそうです
- マルチエージェント構成
- 複数のエージェントを連携させ、「飼育相談エージェント」「健康診断エージェント」「購入アドバイスエージェント」のように役割分担させることも可能です
この辺りも今後触ってみて、何か有益な発見があればブログにします。
さいごに
以上、AWSでリクガメに詳しいAIエージェントを作ってみました。
今回はBedrock AgentsとBedrock AgentCoreの2つのパターンで実装して、それぞれ以下のような所感でした。
- Bedrock Agents
- フルマネージドで手軽にRAGエージェントを構築できる。
- まずはこちらから始めるのがおすすめ。
- Bedrock AgentCore
- Strands Agentsなどのフレームワークを使って柔軟にカスタマイズできる。
- 本番運用や高度な機能が必要な場合におすすめ。
また、S3 Vectorsは2025年12月にGAとなったばかりの新しいサービスですが、Bedrock Knowledge Basesとのネイティブ統合により、RAGアプリケーションの構築が非常に簡単になっています。
OpenSearch Serverlessと比較してコストも抑えられるので、個人プロジェクトやPoCには特におすすめです。
今回はリクガメをテーマにしましたが、同じアーキテクチャで料理レシピ、社内FAQ、技術ドキュメントなど、様々な専門知識を持つAIエージェントを構築できるので、
ぜひ皆様も自分だけの専門家AIを作ってみてください!










