AIによるスパイクアクセスを受けたので、 robots.txtの調整など極力AIを排除しない対策を試みてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS WAF のBotControlルールにおいて、AIカテゴリに分類されるスパイクアクセスが発生。
動的生成される記事ページへのリクエストが、1時間あたり5万件、ピーク時には1分間に1500件記録されていました。
当サイトで公開中の5万件強の全記事数に匹敵するリクエストが発生した原因の調査と、実施した対策について紹介します
CloudWatchメトリクス確認
原因を特定するため、AWS WAFのメトリクスを分析しました
bot:category AI の 急増
AIカテゴリのリクエスト数が、1時間あたり5万件まで顕著に増加しました。
他のカテゴリ(search_engine: Google、Bing など、social_media: X、Facebook など)には大きな変動は見られませんでした。
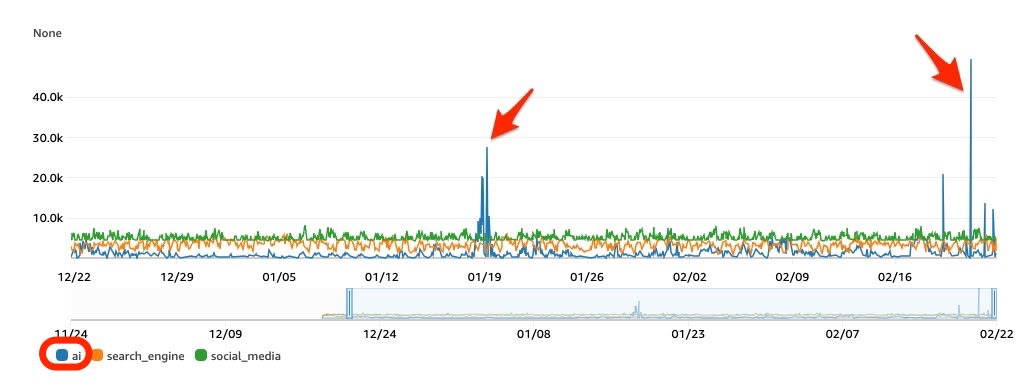
- LabelNamespace="awswaf:managed:aws:bot-control:bot:category"
- LabelName="ai",search_engine, social_media
bot:name claudebot
リクエスト急増時において、「AI」カテゴリと「ClaudeBot」というbot:nameが一致しました。
このことから、Anthropic社からのリクエストが急増したと判断しました。
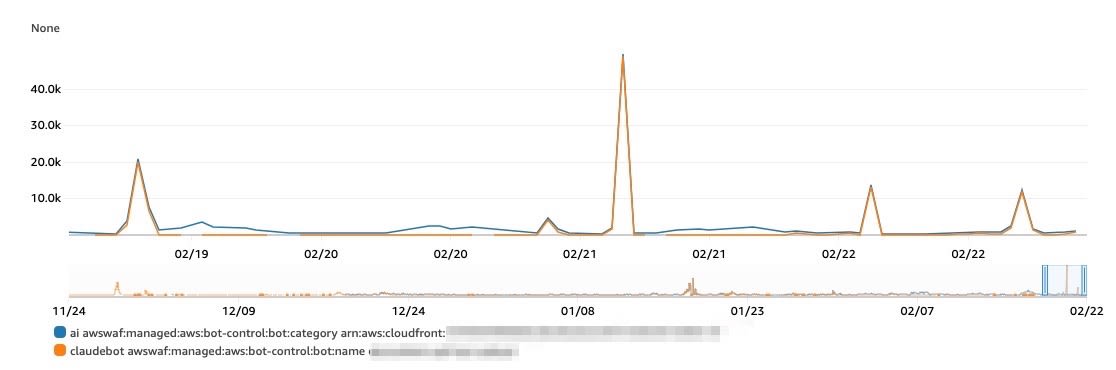
- LabelNamespace="awswaf:managed:aws:bot-control:bot:name"
- LabelName="claudebot"
アクセスログ解析
より詳細な分析と対策の検討を行うため、CloudWatch Logsに保存されたCloudFrontのアクセスログ(標準アクセスログv2)を、Logs Insightsを用いて解析しました。
IP、UserAgent別集計
リクエスト急増時間帯のアクセスログから、ClaudeBot の UserAgent を持つ IP アドレスを求めました。
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"c-ip\":\"(?<clientip>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| parse @message /\"x-edge-response-result-type\":\"(?<edge_response_result_type>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by clientip,useragent
| sort request_count desc
| limit 10000
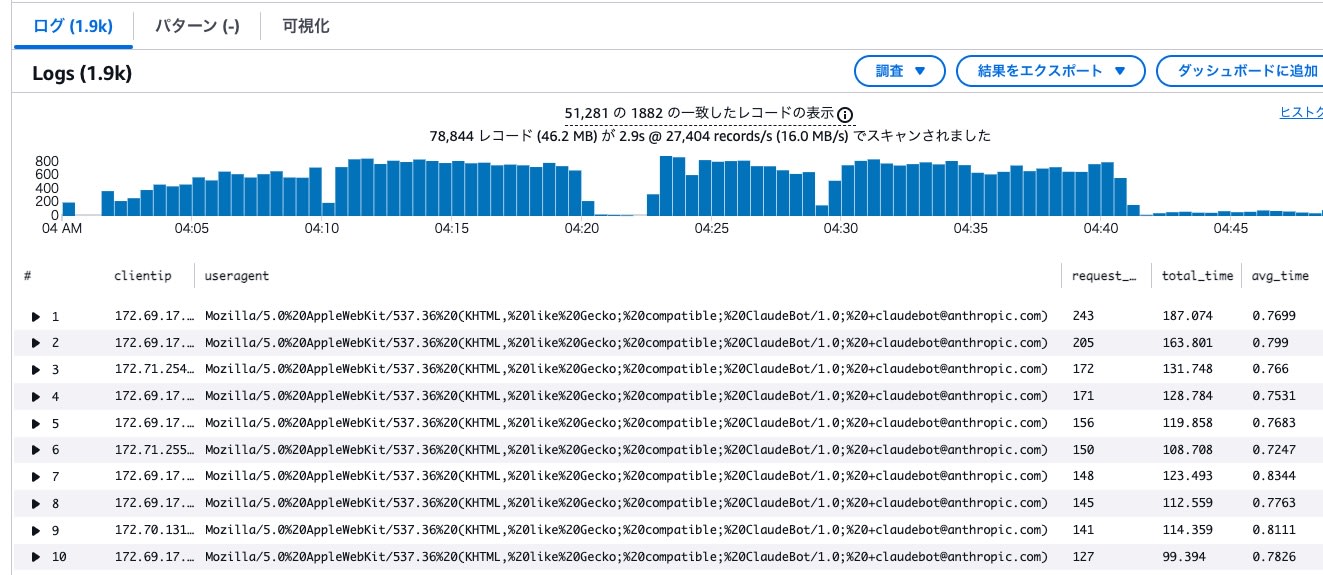
- 記録されたIP数は1888
- 1つのIPアドレスから100〜200リクエスト程度発生していました。
同時アクセスIP数
ClaudeBotのログを対象に、1 秒間当たりのユニークな IP アドレス数を確認しました。
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"c-ip\":\"(?<clientip>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| stats count(*) as total_requests,
count_distinct(clientip) as unique_ips
by bin(1s)
| sort by unique_ips desc
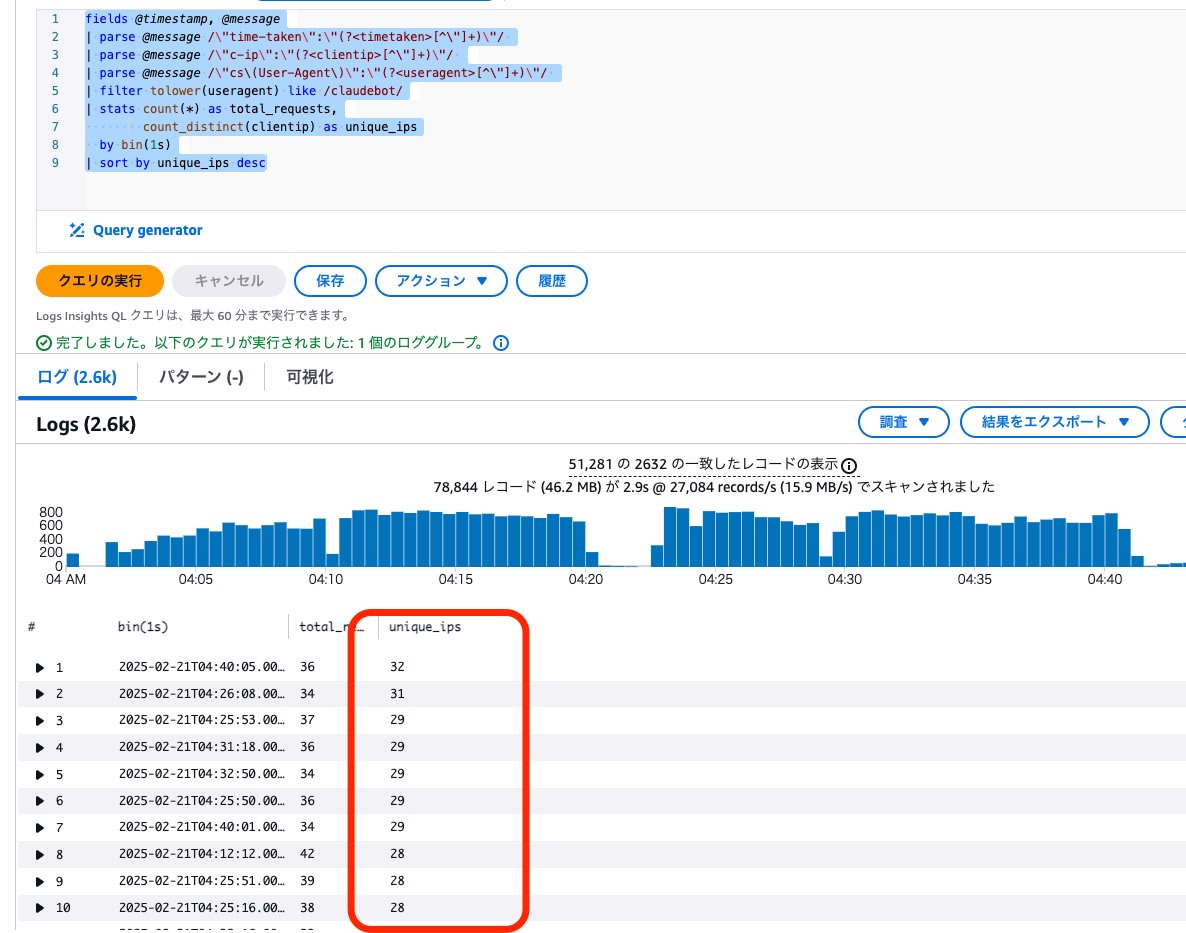
- 最大で32個のユニークなIPアドレスが同時にアクセスしており、並列数30前後でリクエストが行われていた可能性が示唆されました。
URL別集計
リクエストされたURI別の確認を試みました。
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| parse @message /\"cs-uri-stem\":\"(?<uri>[^\"]+)\"/
| parse @message /\"sc-status\":\"(?<status>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by uri,useragent, status
| sort total_time desc
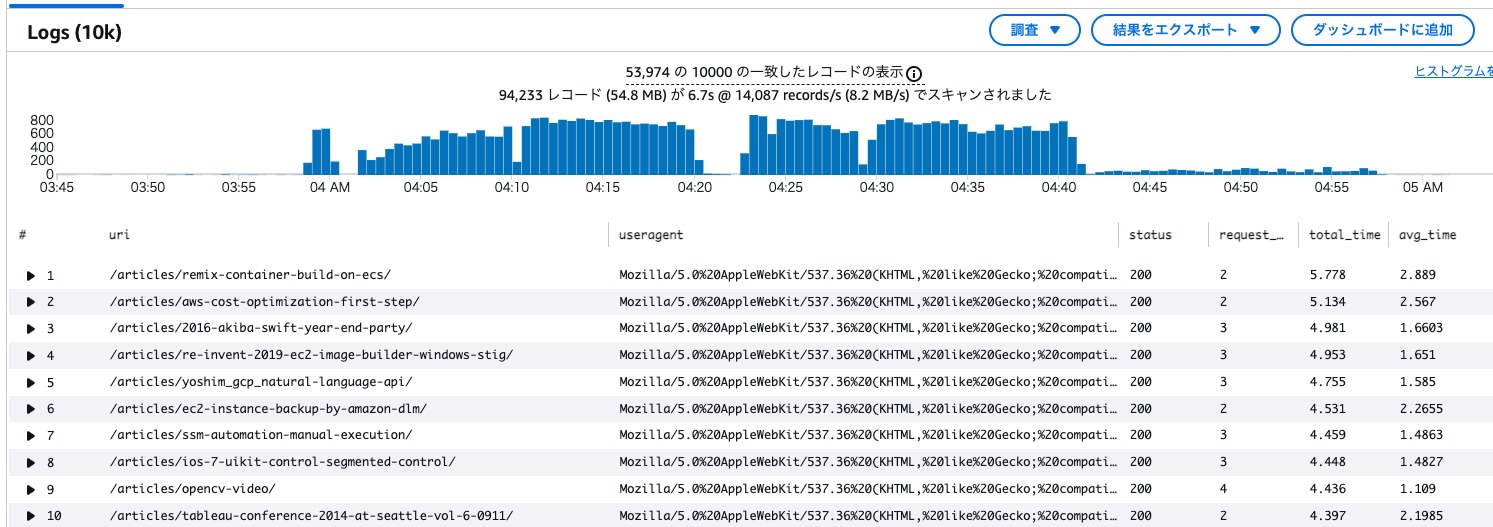
- 正規記事ページのリクエストが 2.5 万件確認されました。
x_host_header別集計
同一記事へのアクセスが複数回確認されたため、リクエスト先ホスト(ホストヘッダ)別の集計を試みました。
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| parse @message /\"x-host-header\":\"(?<x_host_header>[^\"]+)\"/
| parse @message /\"sc-status\":\"(?<status>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| stats count() as request_count,
sum(timetaken) as total_time,
avg(timetaken) as avg_time
by x_host_header,useragent, status
| sort total_time desc
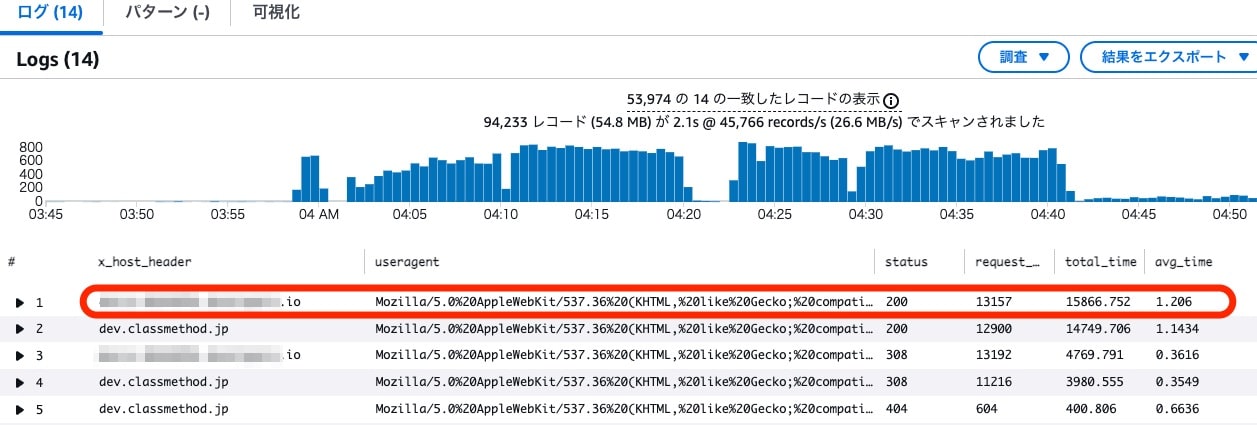
公開 URL のホスト名とは異なるホスト名でのリクエストが確認できました。
個別リクエスト
UserAgentに 「claudebot」を含むIPアドレスを求め、そのリクエスト内容を確認しました。
fields @timestamp, @message
| parse @message /\"time-taken\":\"(?<timetaken>[^\"]+)\"/
| parse @message /\"c-ip\":\"(?<clientip>[^\"]+)\"/
| parse @message /\"cs\(User-Agent\)\":\"(?<useragent>[^\"]+)\"/
| filter tolower(useragent) like /claudebot/
| filter clientip like /172.71.##.##/
| limit 100
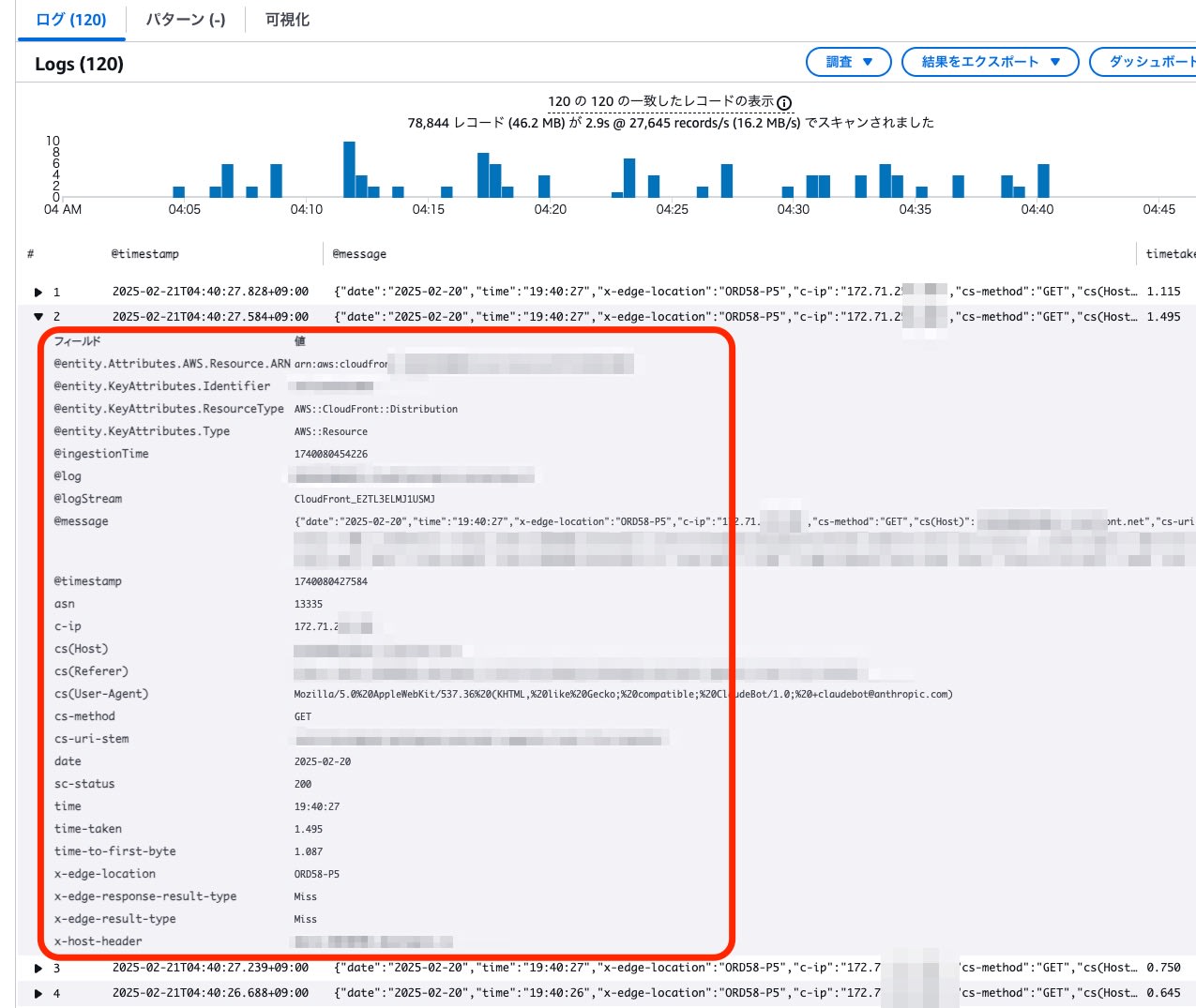
- 1つのIPアドレスから1分間のリクエスト数は10件程度
対策
robots.txt
anthropic社のガイドに倣い、robots.txtに、1秒のクロール遅延(Crawl-delay)を要求する設定を追加。
過剰なクロールの抑制する記述を試みました。
$ curl -s https://dev.classmethod.jp/robots.txt | grep 'Crawl-delay:'
Crawl-delay: 1
クローリング活動を制限するために、robots.txtの非標準のCrawl-delay拡張をサポートしています。例えば以下のようになります:
User-agent: ClaudeBot
Crawl-delay: 1Anthropicはウェブからデータをクロールしているのか、そしてサイト所有者はどのようにクローラーをブロックできるのか?
代替ドメイン
今回のスパイクアクセスの約半数は、正規公開FQDNではない代替URLに対するものでした。この代替URLは、サービス開始前は関係者向けの動作確認用、サービス開始後は性能監視のための外形監視に利用していたものでした。
従来は「x-robots-tag: noindex」を設定していました。
< HTTP/2 200
< date: Fri, 21 Feb 2025 **:**:** GMT
< content-type: text/plain
(...)
< x-robots-tag: noindex
AIクローラーには効果がなかったため、Cloudflareルールを調整し、正規サイトへ301リダイレクトする設定に変更しました。
< HTTP/2 301
< date: Fri, 21 Feb 2025 **:**:** GMT
< content-type: text/html
(...)
< location: https://dev.classmethod.jp/
リダイレクト数が収束した後、当該FQDNは廃止予定です。
Block
AWS WAFのレートルールとカスタムキーを利用して、指定期間内に一定以上のリクエストが発生した場合に遮断を実現することが可能です。
現状では遮断を極力避ける方針ですが、robots.txtなどの効果がなくスパイクアクセスが継続する場合に備え、以下のルールをAWS WAFのALCsに追加できるよう準備しました。
- bot-control 判定ラベルを利用したレート制限 (1分間に100以上でBlock発動)
{
"Name": "rate-limit-claudebot",
"Priority": 250,
"Statement": {
"AndStatement": {
"Statements": [
{
"LabelMatchStatement": {
"Scope": "LABEL",
"Key": "awswaf:managed:aws:bot-control:bot:name:claudebot"
}
},
{
"RateBasedStatement": {
"Limit": 100,
"AggregateKeyType": "CUSTOM_KEYS",
"CustomKeys": [
{
"Type": "LABEL_NAMESPACE",
"Key": "awswaf:managed:aws:bot-control:bot:name"
}
],
"TimeWindow": 60
}
}
]
}
},
"Action": {
"Block": {}
},
"VisibilityConfig": {
"SampledRequestsEnabled": true,
"CloudWatchMetricsEnabled": true,
"MetricName": "RateLimitClaudeBotRule"
}
}
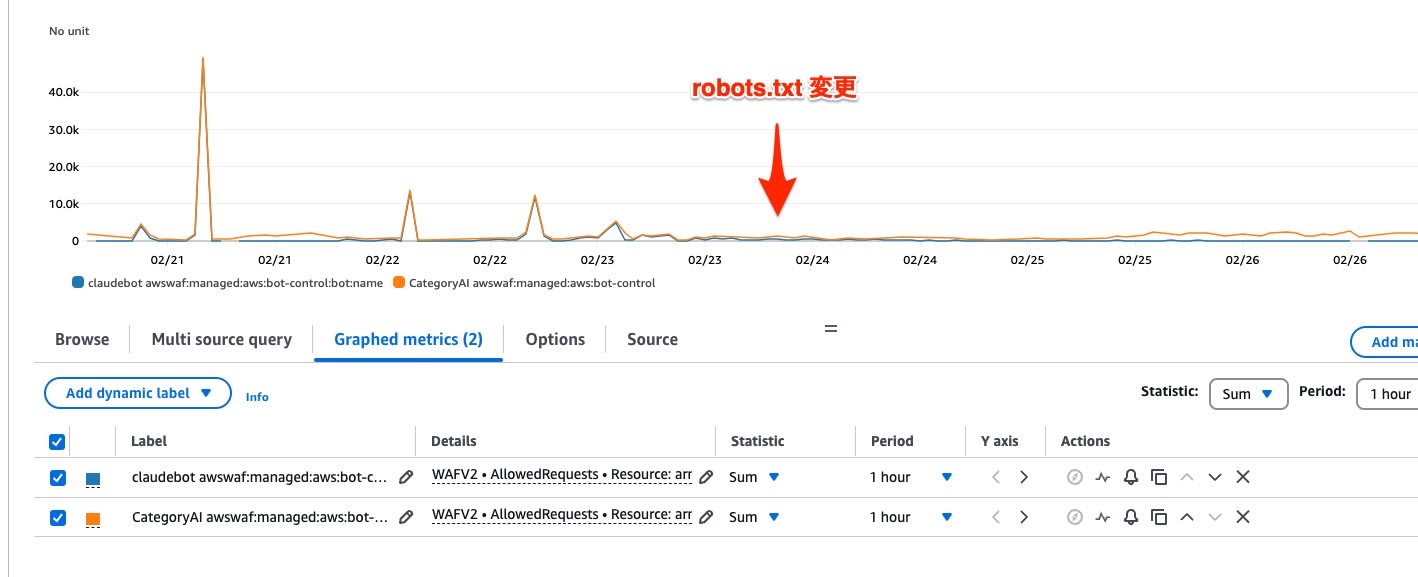
効果 (2/27追記)
robots.txt の更新後、ClaudeBot からのリクエスト数は1時間あたり20〜50回程度に減少しました。
SNS上で、iFixit社のサイトがClaudeBotから100万件規模のリクエストを受け、robots.txtで対処した事例が紹介されていました。
適切な robots.txt の設定は、ClaudeBot のクロール制御に有効であると考えられます。
まとめ
AIエージェントを排除するAWS WAF設定は容易ですが、当サイトの記事コンテンツがAIを活用した検索対象から外れたり、最新の更新情報が反映されなくなるなど、読者・執筆者双方に不利益をもたらす可能性があるため、当サイトでは遮断措置は極力避ける方針です。
今回、robots.txt によるクロール頻度の制御を試みましたが、「llms.txt」についても整備を行い、LLM(大規模言語モデル)向けの指示を明記し、AIのクローラーを誘導する施策を開始しました。
また、今回のスパイクアクセスを通じて、インフラ側の改善すべき点も明らかになりました。今後の対策として、バックエンドシステムの最適化や、オリジンの直接アクセスを防ぐためのCloudFrontのVPCサポート活用、AWS WAFの高度な設定など、複合的なアプローチでシステム全体の堅牢性を高めていく予定です。










