![[レポート]AWSのデータ取り込み戦略 - Solving different data ingestion use cases with AWS (ANT330) #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]AWSのデータ取り込み戦略 - Solving different data ingestion use cases with AWS (ANT330) #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のsutoです。
本記事は「AWS re:Invent 2024 - Solving different data ingestion use cases with AWS (ANT330)」のセッションレポートです。
セッションの動画は以下で公開されています。
概要
Ingesting data is typically the first step in building your data pipelines. The growing landscape of data types like unstructured data, incremental data, and open table formats such as Apache Iceberg makes it all the more critical to build durable data pipelines, land the data immediately, apply the desired schema structure, and provide quality outputs for different types of use cases. Join this session to explore specific solutions that can help solve for different data ingestion challenges. Learn about the robust architectures and key strategies for efficiently ingesting and processing data with services like AWS Glue, Amazon Kinesis, Amazon Redshift, and Amazon OpenSearch Service.
通常、データの取り込みは、データ パイプラインを構築する最初のステップです。非構造化データ、増分データ、Apache Iceberg などのオープン テーブル形式などのデータ タイプの増加により、耐久性のあるデータ パイプラインを構築し、データを即座に取得し、必要なスキーマ構造を適用し、さまざまなデータに高品質の出力を提供することがますます重要になっています。ユースケースの種類。このセッションに参加して、さまざまなデータ取り込みの課題の解決に役立つ具体的なソリューションを検討してください。 AWS Glue、Amazon Kinesis、Amazon Redshift、Amazon OpenSearch Service などのサービスを使用してデータを効率的に取り込み、処理するための堅牢なアーキテクチャと主要な戦略について学びます。
スピーカー
- Rahul Sonawane (Principal Solutions Architect, Amazon Web Services)
- Chinmayi Narasimhadevara(Senior Solutions Architect, Amazon Web Services)
アジェンダ

セッション内容
様々な場所にデータを持っているにもかかわらず、明確なIngestion(データの取り込み)戦略がないとその後のデータ分析~ビジネスインテリジェンスを得ることはできません。
データソース(RDB、ファイル、SaaS製品、IoT など)からデータ取込頻度(バッチ/ストリーミング)やデータ構造(構造化/半構造化/非構造化)と多岐にわたります。
本セッションでは、時代とともに変化してきたデータIngestionの状況について、特にモダンなData Architecture戦略に焦点を当てて解説しています。

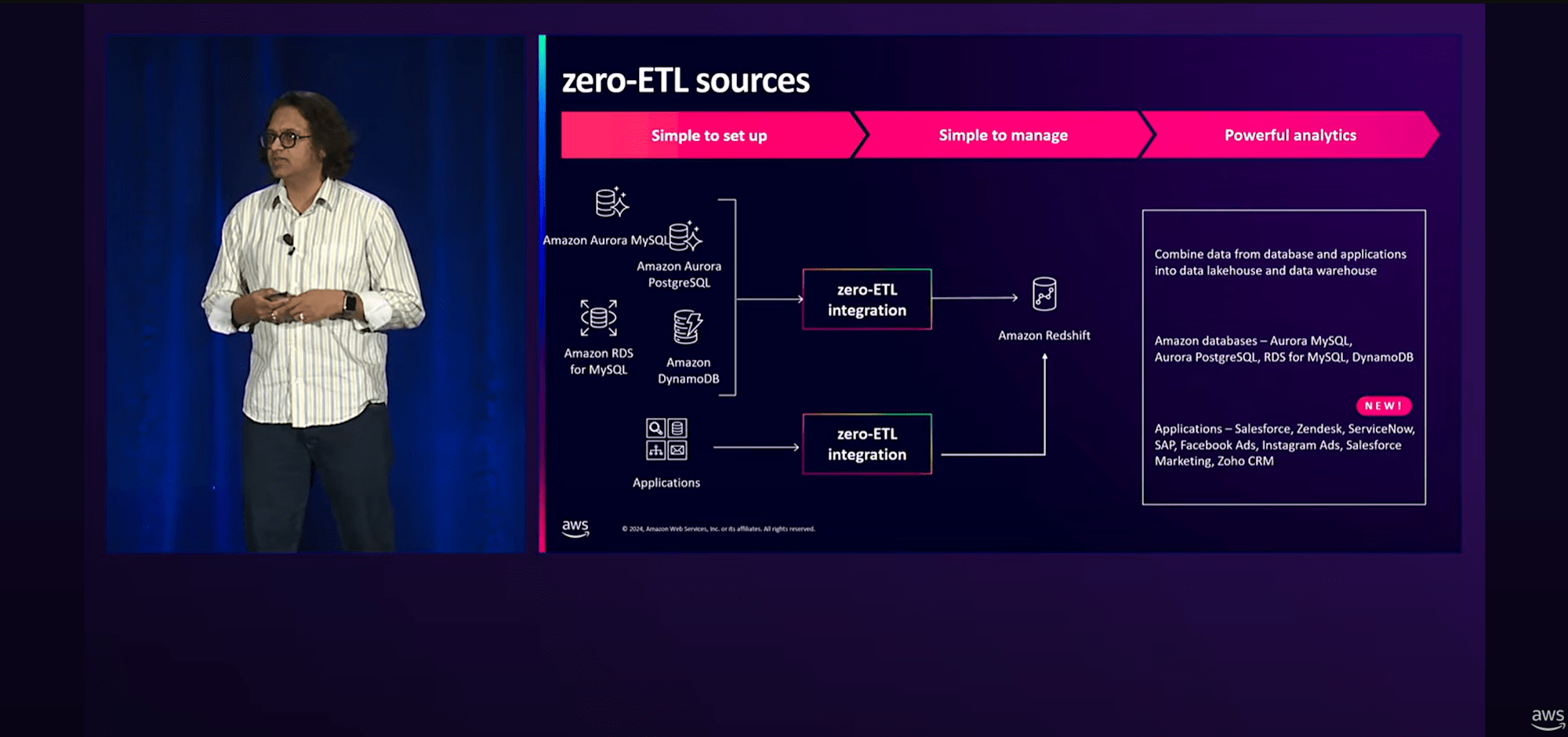
Amazon Redshiftを活用したデータウェアハウスへのIngestion戦略については、近年「Zero-ETL」という概念を持つ機能が発表されています。
Zero-ETLとは、
- ポイントツーポイントのデータ移動のために設計しており、ユーザーがETLパイプラインを作成する必要がない
- バッチやトリガーに基づいて全体のジョブをオーケストレーションする必要がないので、コスト効率がよい
- 必要に応じて自動的にスケールアップ・ダウンするため、データは素早くターゲットシステムで利用可能
- ユーザーが複数のシステムにまたがる分析を行い、インサイトを得られるようサポート
RedshiftへのZero-ETLによるIngestion機能は、私が現地参加したre:Invent 2022のキーノートで発表されたのを覚えていますが、現在の機能を以下に整理します。
- Amazon Aurora MySQLのZero-ETL(2023年11月 GA)
- Amazon RDS for MySQLのZero-ETL(2024年9月 GA)
- Amazon Aurora PostgreSQLのZero-ETL(2024年10月 GA)
- Amazon DynamoDBのZero-ETL(2024年10月 GA)
- 【NEW】SaaSアプリケーションのZero-ETL(2024年12月)
- 参考記事:https://dev.classmethod.jp/articles/amazon-sagemaker-lakehouse-redshift-zeroetl-8apps/
- ※Salesforce,ServiceNow,Zendeskなど広く使われているSaaS製品のデータ取込プロセスが大きく簡素化できそうです
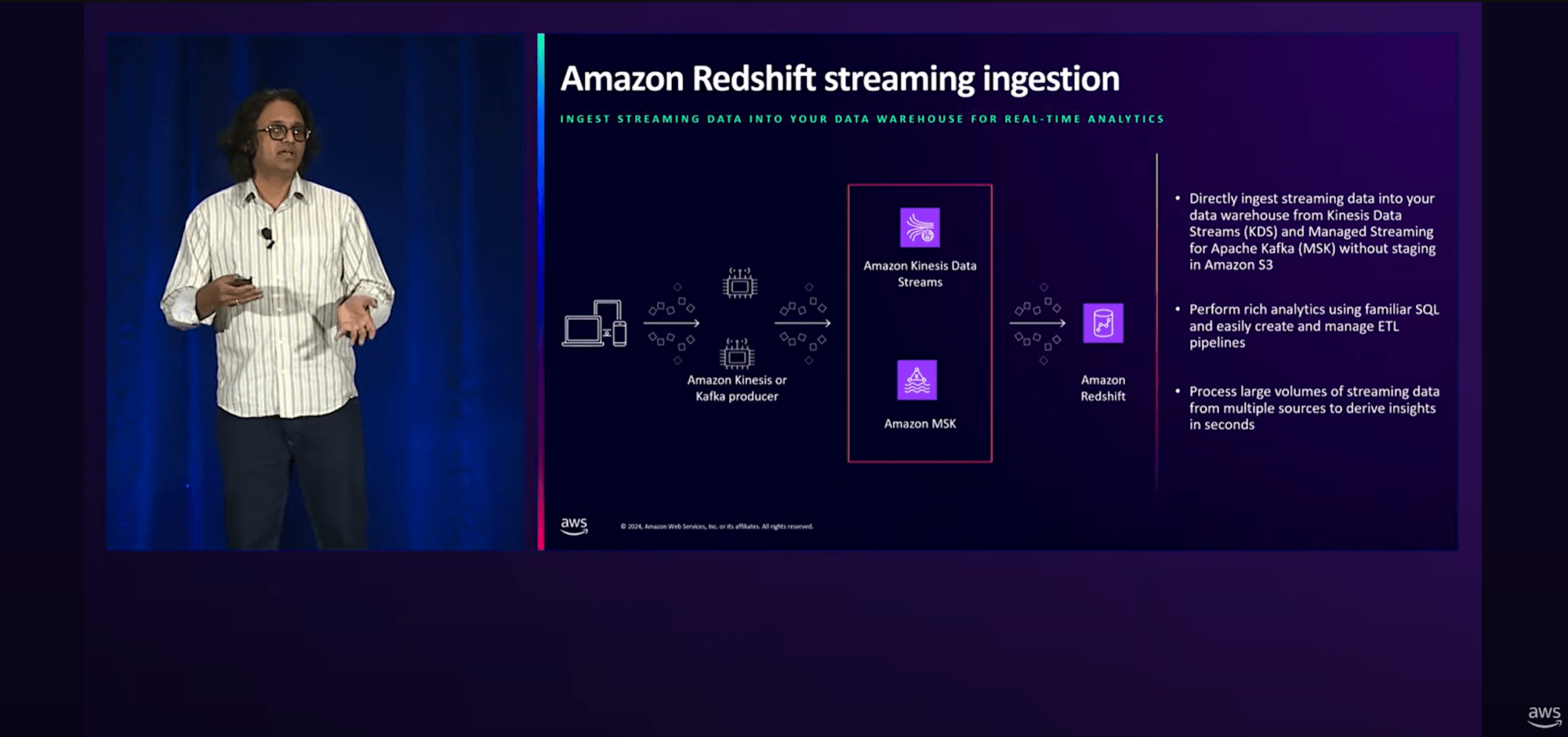
RedshiftへのストリーミングIngectionについては、これまでにKinesis Data StreamやMSKとの連携があります。
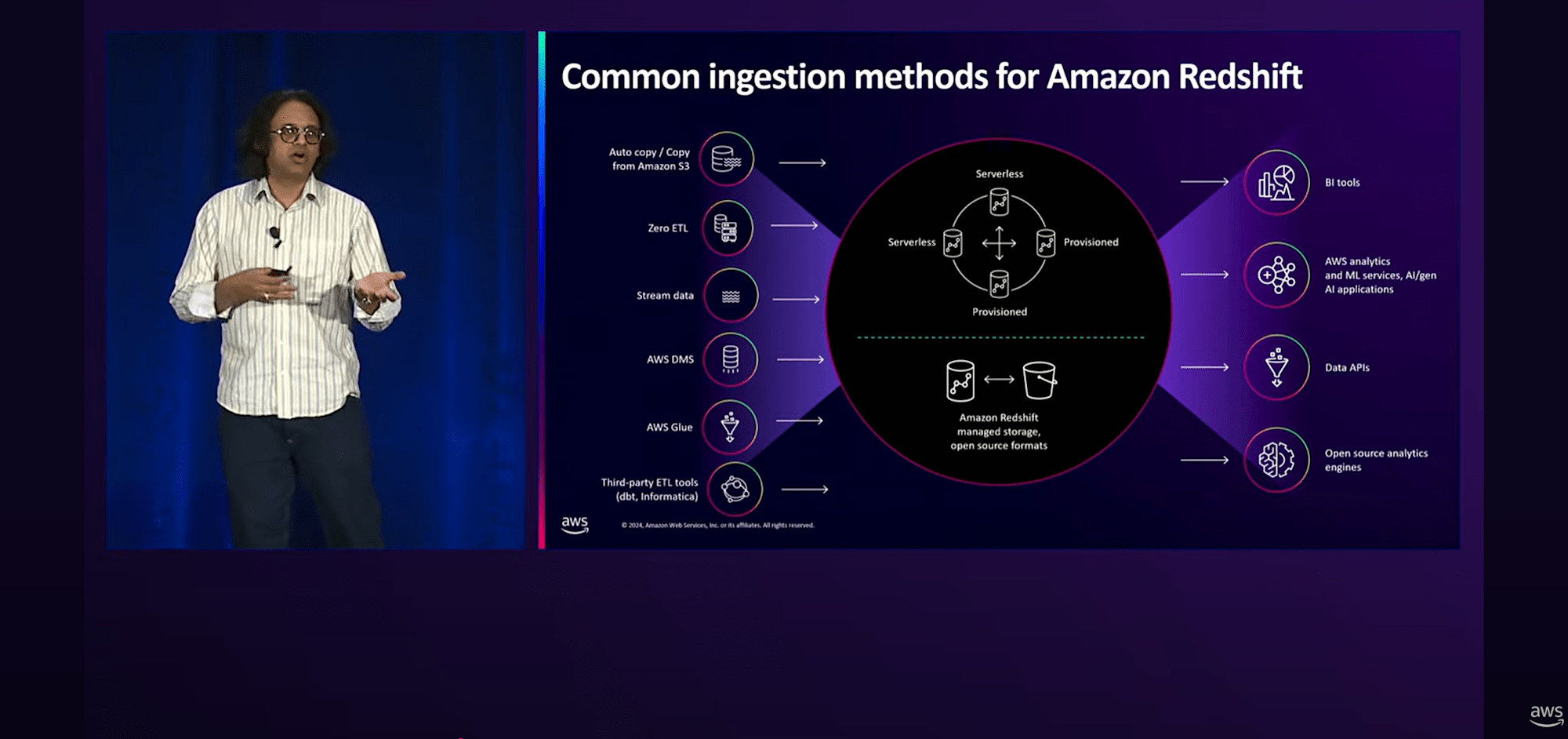
S3からRedshiftへのAuto-copyを使えば、copyコマンド実行のためのオーケストレーションを構築する手間を省けます。(もちろんS3に配置するデータの中身自体がRedshiftに問題なく取り込める状態になっている前提ですが)
- S3イベント統合によるRedshiftへのAuto-copy(2024年 10月 GA)

以上紹介したパターンの他に、従来からある「AWS DMSによるオンプレミスのデータベースからRedshiftへの取込」、「データをAWS GlueやInformatica、DBTなどのサードパーティサービスを駆使してETL後にRedshiftへ出力」などの方法もあります。
まとめると以下のような図になります。
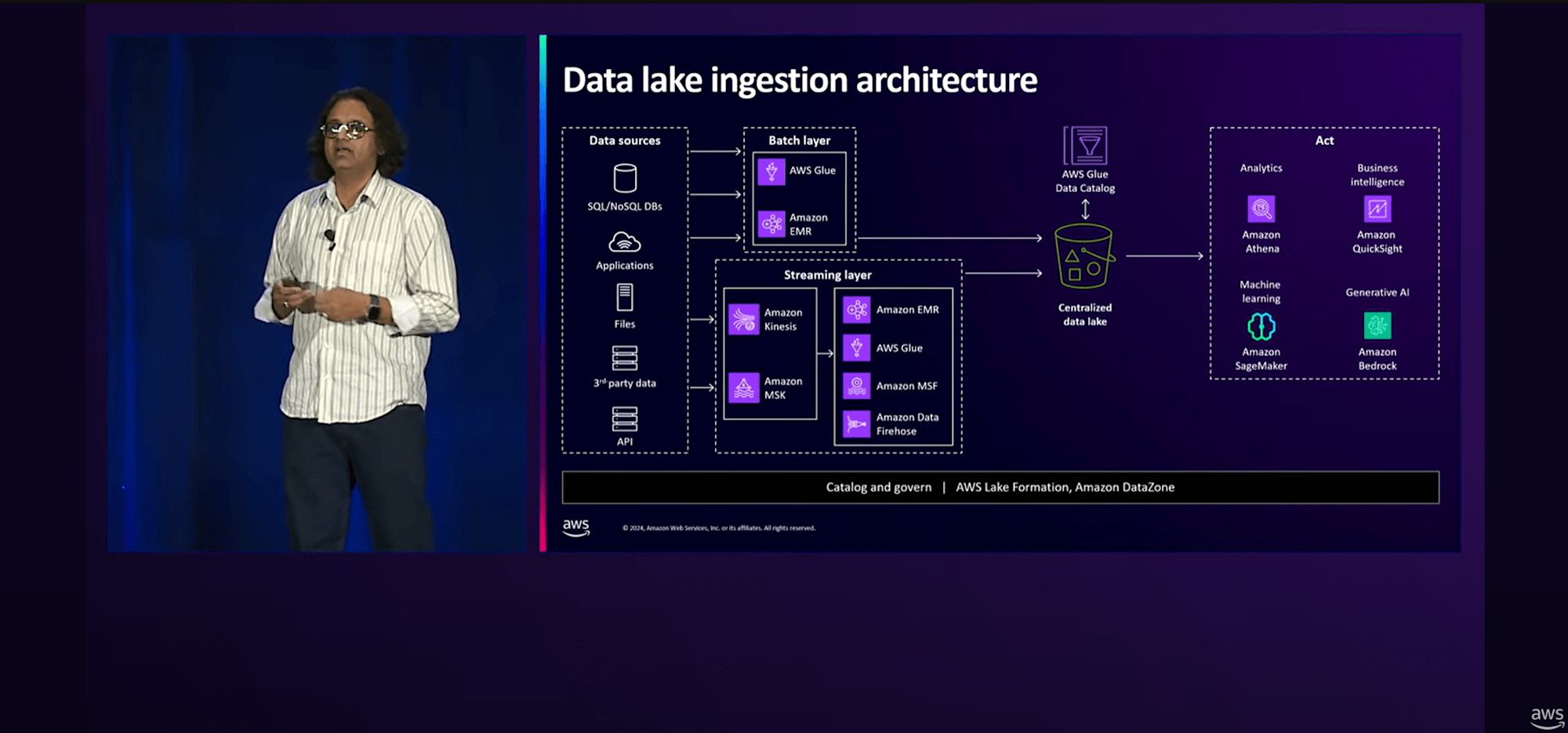
次にLake Houseデータの取り込みについて
様々なデータソースを分析サービス(Athena、QuickSight、Sagemaker、Bedrock)で扱えるようにするにはデータを処理するサービスが必要になります。
本セッションでは以下のサービスの機能についていくつか紹介されていました。
- AWS Glue
- Amazon Kinesis Data Streams
- Amazon MSK
- Amazon Data Firefose
一方で、ビジネスサイドの方々は、これらの技術的な区別をそれほど気にしていません。
どちらかというと、「データに対してクエリを実行できる一元化された場所を持つこと」の方に関心があります。
そこで私たちは、Data WarehouseとData Lakeの間のギャップを埋めるLake Houseアプローチを導入を始めました。( Amazon SageMaker Lake House の導入)
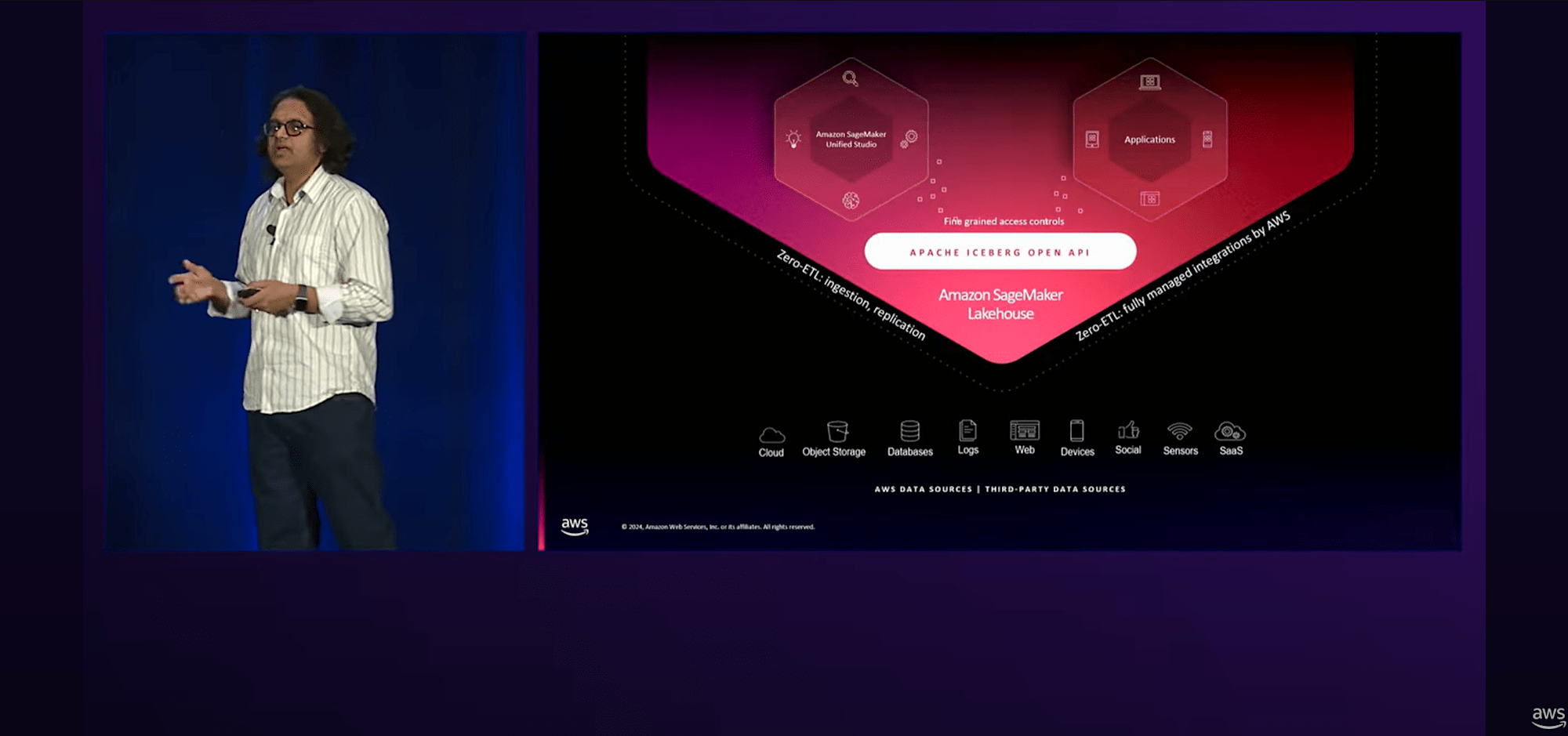
Amazon SageMaker Lake Houseは、
- 前半で解説したZero-ETL統合の機能でSageMaker Lakehouseへデータ取込ができる
- Zero-ETLを利用しない/できない場合でも、「Apache Iceberg 互換 API」を通じてデータにアクセスできる
- Amazon SageMaker Unified Studioを使用してSageMaker Lake Houseと連携
- 最近発表されたGlue 5.0と、SageMaker Lake Houseとの直接統合が可能
つまり、Amazon SageMaker Unified Studioの画面1つでデータソースの取込からデータの分析、変換、AI 活用をシームレスに実施できることを目指しているようですね。
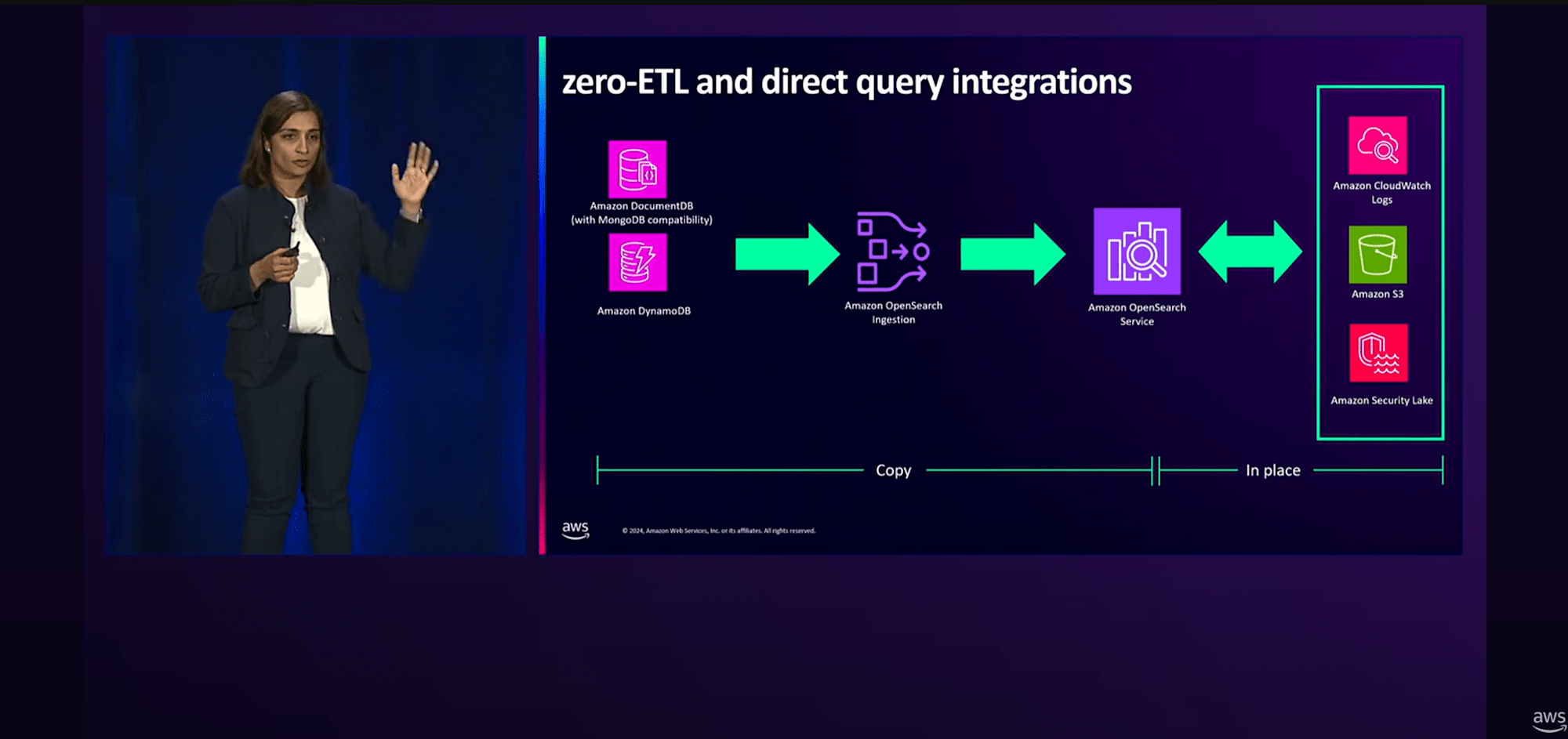
Amazon OpenSearch Serviceを用いたログと分析データの取り込みについて、こちらにも多数のZero-ETL機能があります。
- Amazon DynamoDBからOpenSearch ServiceへのZero-ETL(2023年11月 GA)
- Amazon DocumentDBからOpenSearch ServiceへのZero-ETL(2024年5月 GA)
- OpenSearch ServiceからS3へのZero-ETL(2024年5月 GA)
- 【NEW】OpenSearch ServiceからS3へのZero-ETL(2024年12月)
- 【NEW】OpenSearch ServiceからAmazon Security LakeへのZero-ETL(2024年12月)
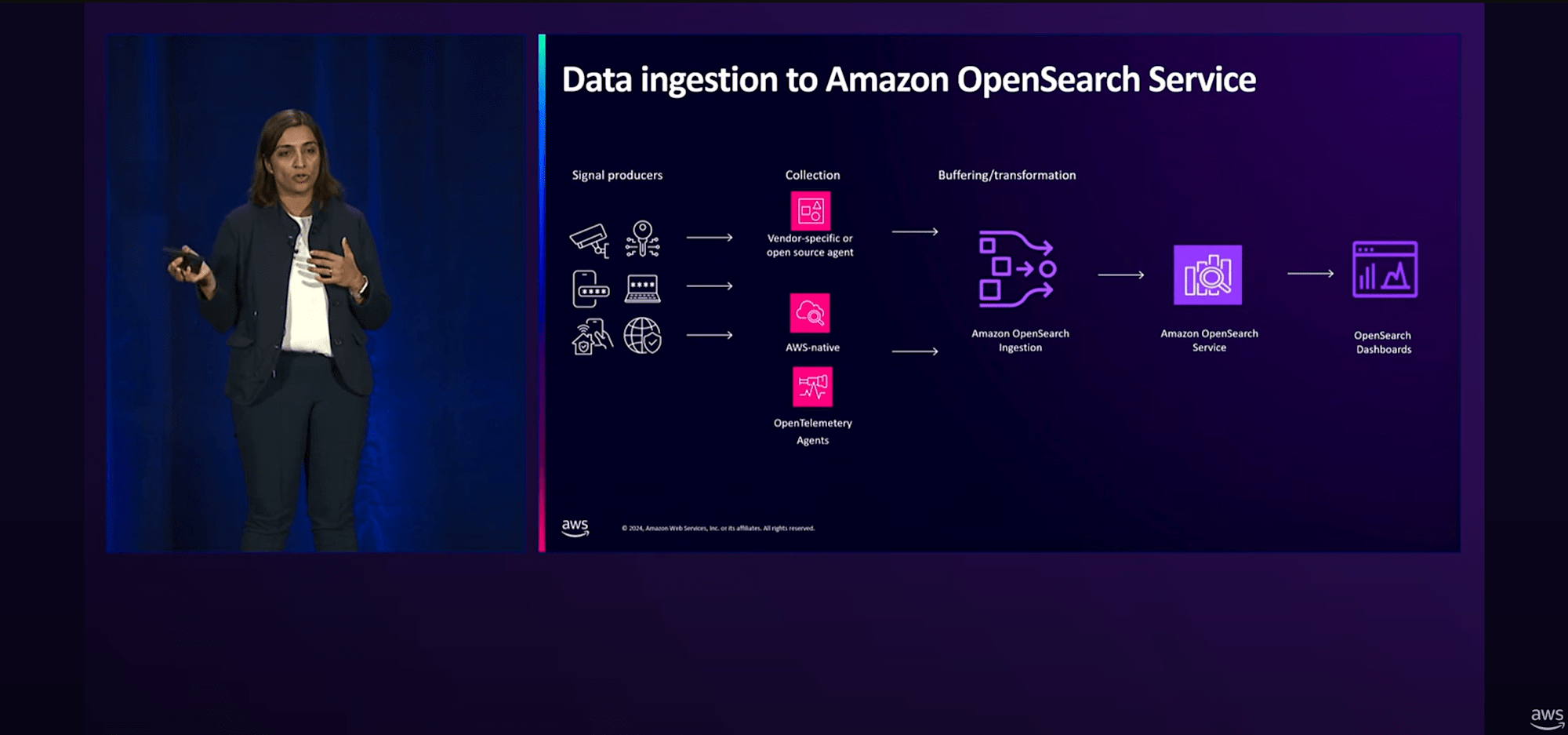
OpenSearchはZero-ETL 連携だけでなく、他の多くのソースもサポートしています。Amazon S3、HTTP、そしてOpenTelemetryのソースに対応しており、MSKやKinesis Data Streamsなどのストリーミングサービスからもデータを取り込むことができます。
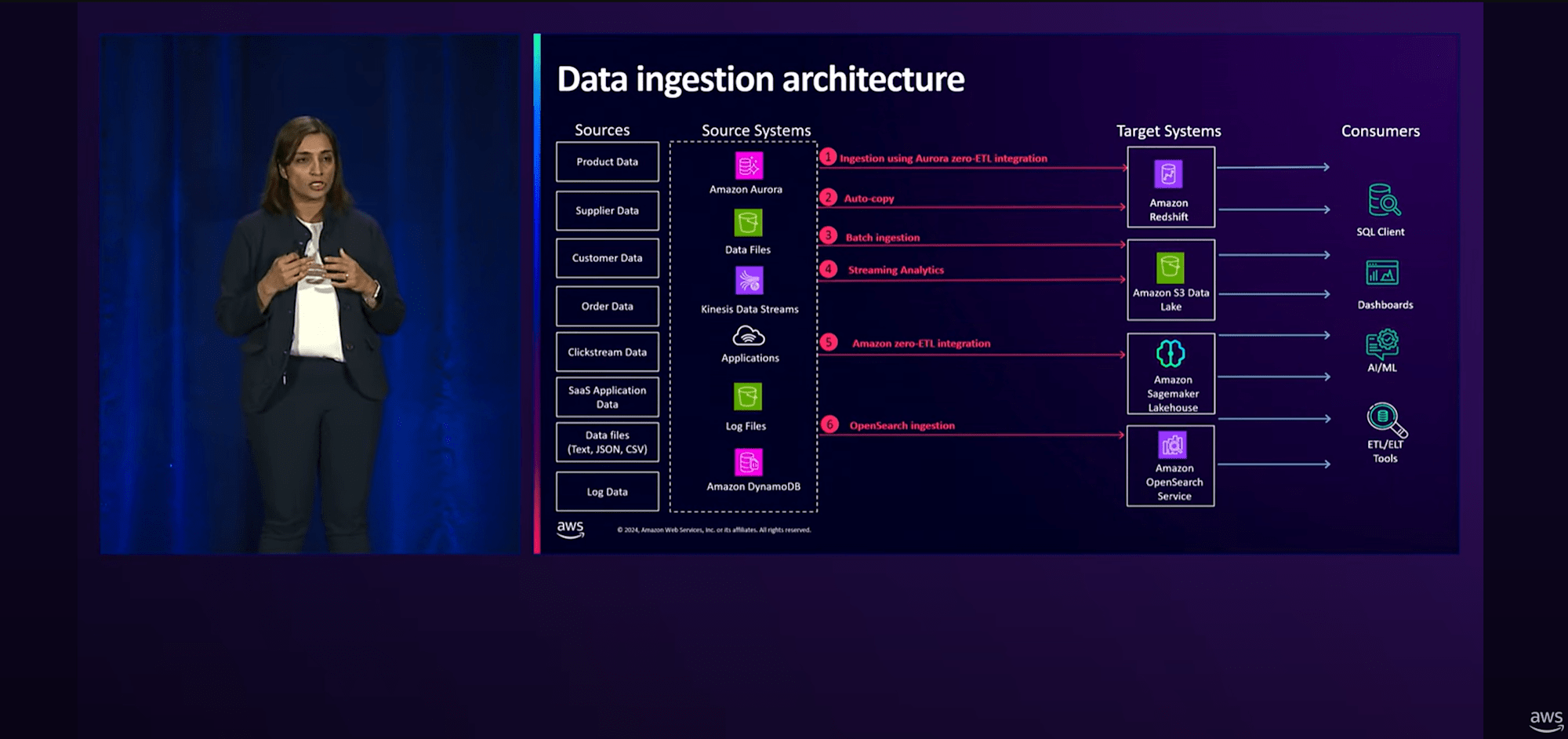
以上、紹介したデータIngectionから取込先として"Redshift"、"S3"、"Sagemaker"、"OpenSearch"に出力、コンシューマはそれらをデータソースとして"クエリ実行"、"ダッシュボード作成"、"AI/MLの活用"、"ETL/ELTツールへの利用"をすることになります。
要点をまとめた図が以下のキャプチャとなります。
最後に
現時点における、シンプルかつ簡単なデータ取込方法を知るために有効なセッションでした。
データアナリティクス系、AI系のサービスは、アップデートとともに多岐にわたるサービスやオプション機能が存在し、どんな機能がありどこまで使えるのかを把握するのが大変です。とりわけSageMaker系のサービスは弊社の内部でも「サービス名が多すぎ!」との声が出ています。
将来的に、
- 統合開発環境 (IDE):Amazon SageMaker Unified Studio
- データストア:Amazon SageMaker Lakehouse
- データのガバナンス、カタログ:SageMaker Data & AI Governance
に統合していきたいという構想なのかもしれません。
いずれにせよ、扱いやすいサービスになってくれると助かりますので、今後の動向に注目したいところです。










