From Demo to Deployment: 4 ความท้าทายที่ต้องพิชิตในการทำ AI Agent ระดับองค์กร
เริ่มต้นด้วยตัวเลขที่น่าตกใจ
จากผลสำรวจของ S&P พบว่า กว่า 16% ของโปรเจกต์ AI ไม่สามารถไปถึงฝั่งได้ ถูกยกเลิกกลางทาง ทั้งที่ Demo ผ่านฉลุย แต่พอจะนำขึ้น Production จริงกลับสะดุดทุกขั้นตอน
คำถามสำคัญจึงเกิดขึ้นว่า ทำไมถึงเป็นแบบนี้?
ก่อนจะสร้าง ต้องถามตัวเองก่อนว่า "Build หรือ Buy?"
ในหลายกรณี เราอาจไม่จำเป็นต้องสร้างเอง เช่น
- Amazon Q สำหรับงาน Workplace Automation ประจำวัน
- Amazon Connect สำหรับงาน Customer Service และ Business Process
- Amazon CodeWhisperer สำหรับงาน Software Development
แต่หากองค์กรมีความต้องการเฉพาะทาง มี Logic ซับซ้อน หรือต้องการควบคุม Compliance อย่างเต็มที่ นั่นคือสัญญาณว่าควร สร้างเอง
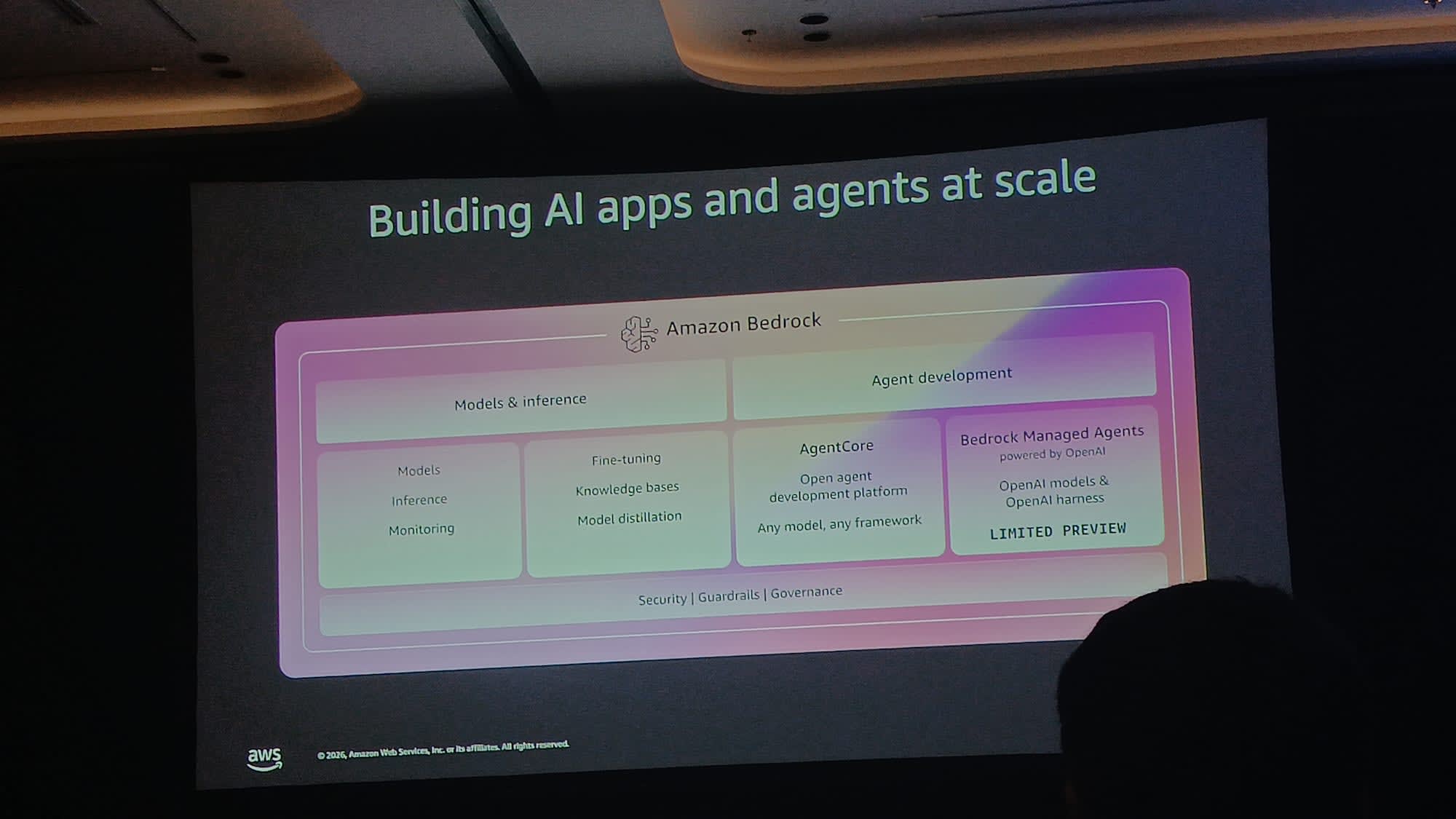

4 ความท้าทายหลักในการพา AI Agent ขึ้น Production
1. Operations: ระบบรองรับการ Scale ได้ไหม?
การ Scale ไม่ได้หมายถึงแค่รองรับผู้ใช้มากขึ้นเท่านั้น แต่ยังครอบคลุม
- Cost Control — ถ้าไม่ควบคุมค่าใช้จ่าย บิลเดือนถัดไปอาจพุ่งเป็นหมื่นบาทโดยไม่รู้ตัว
- Observability — ต้องรู้ว่า AI กำลังทำอะไรอยู่ มีปัญหาตรงไหน
- Governance — ถ้าองค์กรมี Agent หลายร้อยตัว จะควบคุมยังไง?
เครื่องมือที่ช่วยได้:
- Amazon CloudWatch — มอนิเตอร์ Latency, Token Usage, Dashboard ภาพรวม
- Amazon Bedrock Agent Observability — เหมือนมี X-ray ดูว่า Agent คิดอะไรอยู่ ตัดสินใจยังไง ทำไมถึงตอบแบบนั้น
สำหรับการควบคุมต้นทุน แนะนำให้เลือก Inference Profile ให้เหมาะกับงาน เช่น
- Priority → งาน Customer Facing ที่ต้องการความเร็วสูง
- Standard → งาน Back Office ทั่วไป
- Flex → งาน Report หรือ Batch ที่รอได้
2. Data: ข้อมูลดีแค่ไหน คือคำตอบดีแค่นั้น
เวลา AI ตอบผิด หลายคนโทษโมเดลเป็นอันดับแรก แต่ความจริงคือ ปัญหาส่วนใหญ่อยู่ที่ข้อมูล
AI Agent ต้องการข้อมูล 3 ประเภท
- Organizational Knowledge — ความรู้ขององค์กร
- Business Context — บริบทของธุรกิจ
- User Context — ผู้ใช้เป็นใคร ต้องการอะไร
ปัญหาคือข้อมูลในองค์กรมักกระจัดกระจาย ไม่รู้ว่าอยู่ที่ไหน
วิธีแก้:
- ให้ความสำคัญกับ Metadata เพราะทำให้ AI ตอบได้ตรงจุดกว่า เช่น รู้ว่าลูกค้าที่ถามเป็นลูกค้ารายใหญ่ที่สุดขององค์กร
- ทำ RAG ให้มีคุณภาพ ทั้ง Chunking, Embedding, Ranking และการอัพเดทข้อมูลสม่ำเสมอ
- จัดการ Memory ให้ดี เพื่อให้ Agent จำผู้ใช้ข้ามเซสชันได้ โดยใช้ Amazon Bedrock Agent Memory
3. Trust & Security: ปลอดภัยพอที่จะไว้ใจได้หรือยัง?
เมื่อมีผู้ใช้หลักพันคนใช้ Agent ตัวเดียวกัน คำถามคือ ทำอย่างไรให้แต่ละคนเห็นเฉพาะข้อมูลของตัวเอง?
หากระบบไม่สามารถป้องกันได้ ความเชื่อมั่นในการใช้งาน AI จะหมดทันที
สิ่งที่ต้องมี:
- Identity — ยืนยันตัวตนก่อนเสมอ ผูกกับระบบ Identity เดิมขององค์กร
- Policy — กำหนดขอบเขตให้ชัดว่าใครใช้อะไรได้ ผ่าน Amazon Bedrock Agent Policy ด้วยฟอร์แมต Cedar
- Session Isolation — แต่ละ Session ถูกแยกออกจากกันด้วย Micro VM อิสระ ใช้งานเสร็จถูก Terminate อัตโนมัติ
- Audit Trail — ทุก Action ต้องตรวจสอบย้อนหลังได้

4. Reliability: วันนี้ดี พรุ่งนี้ต้องดีเหมือนกัน
AI มีธรรมชาติที่ไม่แน่นอน ถามคำถามเดิม 5 ครั้ง อาจได้คำตอบที่แตกต่างกัน ซึ่งเป็นปัญหาใหญ่เมื่อ Scale ถึงระดับหมื่นเซสชัน
แนวทางจัดการ:
- หากมี Logic ที่ชัดเจนอยู่แล้ว เช่น สูตรคำนวณหรือ Business Rule → ให้ Code รันแทน อย่าให้ AI คิดเอง
- ลด Loop ที่ไม่จำเป็น เช่น แทนที่จะให้ AI ไปดึงวันที่ ก็ส่งวันที่ปัจจุบันไปให้เลย ประหยัดเวลาและต้นทุน
การประเมิน (Evaluation) ต้องทำตั้งแต่วันแรก ไม่ใช่วันที่จะ Deploy:
- Programmatic Evaluation — วัดผลเป็นตัวเลข
- LLM-as-a-Judge — ให้ AI มาให้คะแนน AI อีกที ประหยัดเวลากว่าคนมาก
- Human Review — ใช้คนในส่วนที่ต้องใช้วิจารณญาณจริงๆ
สำคัญมาก: ต้องดึงทีม Business เข้ามาตั้งแต่ต้น เพราะเขาคือคนที่รู้ดีที่สุดว่าคำตอบไหนถูก คำตอบไหนผิด
สรุป: เส้นทางสู่ Production AI ที่ยั่งยืน
| ความท้าทาย | สิ่งที่ต้องทำ |
|---|---|
| Operations | ใส่ Observability ตั้งแต่ Day Zero |
| Data | ให้ความสำคัญกับ Data Quality และ Memory |
| Trust | Security ไม่ใช่ Optional มันคือพื้นฐาน |
| Reliability | Evaluate ก่อน Deploy และทำต่อเนื่อง |

คำแนะนำสุดท้าย: เริ่มจากเล็กก่อนเสมอ ทดสอบกับ 1 Model, 1 Use Case แล้วค่อยขยายเป็น 10 แล้วจึง Scale ต่อ วิธีนี้จะช่วยให้คุณผ่านทุกความท้าทายได้อย่างมั่นคง