
Real-Time Data Operations Platform: ฐานข้อมูลอัจฉริยะสำหรับยุค Real-Time AI
เมื่อข้อมูลต้องวิ่งเร็วเท่าความต้องการของธุรกิจ
ในยุคที่ทุกอย่างต้องเกิดขึ้น "ทันที" การประมวลผลข้อมูลแบบ Real-Time ไม่ใช่แค่ตัวเลือกอีกต่อไป แต่กลายเป็นหัวใจสำคัญของธุรกิจยุคใหม่ ลองจินตนาการดูว่าถ้าระบบแนะนำสินค้าของเราสามารถเรียนรู้พฤติกรรมลูกค้าและอัปเดตผลลัพธ์ได้แบบทันทีทันใด นั่นคือพลังของการผสานระหว่าง Real-Time Streaming กับฐานข้อมูลประสิทธิภาพสูง
ทำไมฐานข้อมูลถึงสำคัญมากสำหรับ AI?
เมื่อพูดถึง AI โดยเฉพาะ Agentic AI (AI ที่ทำงานได้อย่างอัตโนมัติ) ฐานข้อมูลที่ดีต้องมีคุณสมบัติสำคัญ 4 ประการ ดังนี้
1. ความเร็ว (Low Latency)
ยิ่ง Latency ต่ำเท่าไหร่ ประสิทธิภาพของแอปพลิเคชัน AI ก็ยิ่งดีขึ้นเท่านั้น เพราะทุกมิลลิวินาทีมีความหมาย
2. ความพร้อมใช้งานสูง (High Availability)
ฐานข้อมูลต้องพร้อมใช้งานถึง 99.99% ลองคิดดูว่าถ้าระบบตรวจจับธุรกรรมผิดปกติ (Fraud Detection) หยุดทำงานแม้แค่นาทีเดียว ความเสียหายที่เกิดขึ้นกับลูกค้าอาจมหาศาลเพียงใด
3. รองรับการขยายตัว (Scalability)
เมื่อผู้ใช้งานเพิ่มขึ้น ฐานข้อมูลต้องขยายตัวตามได้อย่างราบรื่น โดยไม่กระทบต่อประสิทธิภาพโดยรวม
4. ฟีเจอร์รองรับ AI โดยตรง (AI-Native Features)
ต้องรองรับ Vector Database, MCP (Model Context Protocol) และการจัดเก็บข้อมูลแบบที่ทำให้ AI Agent ทำงานร่วมกับฐานข้อมูลได้อย่างสะดวกและสมบูรณ์
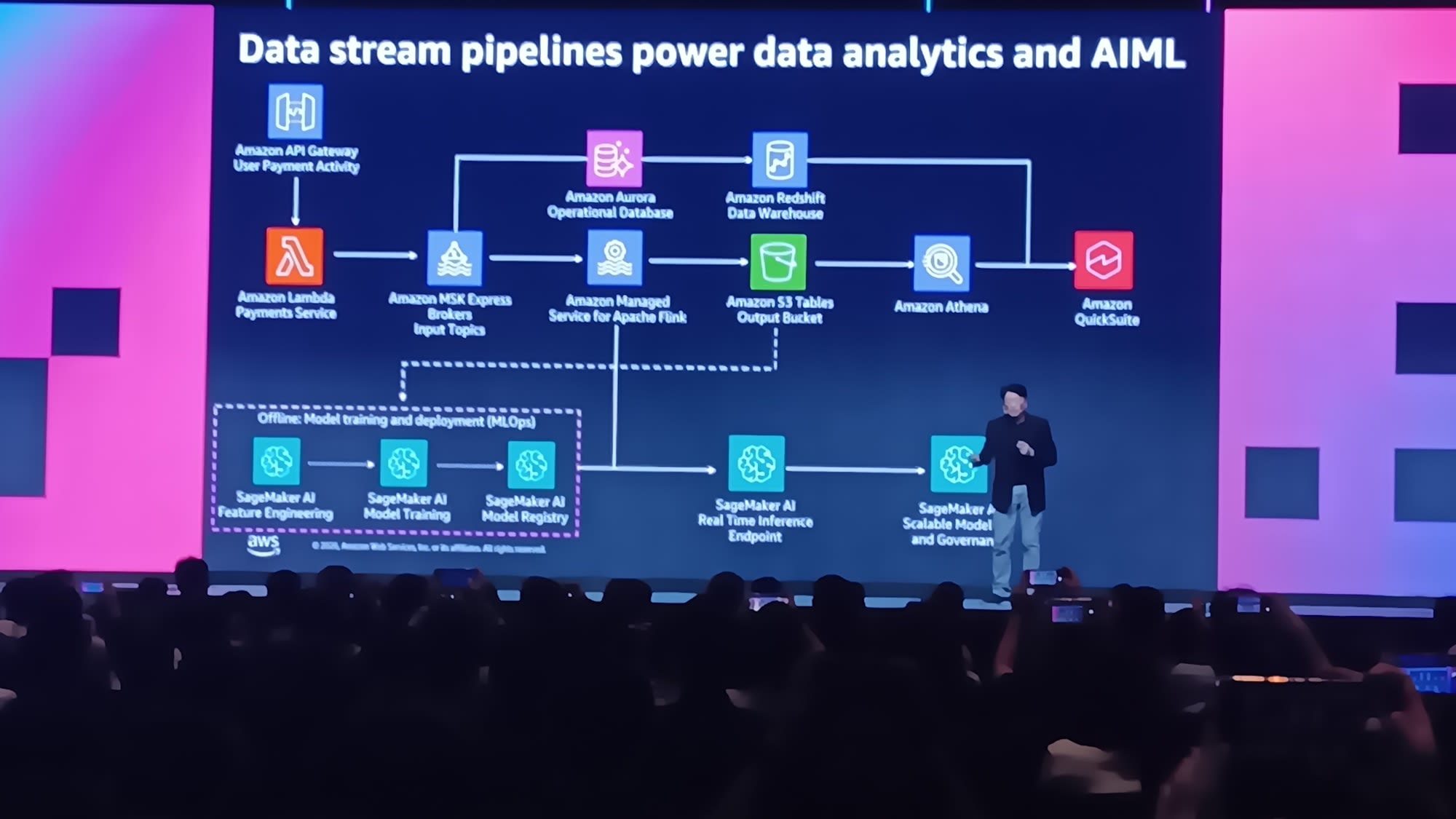
Amazon Aurora คืออะไร?
Amazon Aurora คือบริการฐานข้อมูลของ AWS ที่ให้บริการมานานกว่า 10 ปี โดยนำจุดเด่นของโลก Open Source อย่าง MySQL และ PostgreSQL มาผสมผสานกับความสามารถระดับ Enterprise ทำให้ได้ฐานข้อมูลที่ทั้งทรงพลังและใช้งานง่าย
Aurora มีความโดดเด่นในหลายด้าน ได้แก่
- รองรับ Multi-AZ และ Multi-Region เพื่อความทนทานสูงสุด
- เป็น Fully Managed ช่วยลดภาระงานด้าน Operation เช่น การสำรองข้อมูล การทำ Patching และการจัดการ Failover โดยอัตโนมัติ
- รองรับการขยายตัวได้ถึง 1 Writer และ 15 Read Replicas พร้อมระบบ Shared Storage ที่กระจายข้อมูล 6 สำเนาใน 3 Availability Zone

Aurora กับ Agentic AI: บทบาทที่มากกว่าแค่การเก็บข้อมูล
ในโลกของ Agentic AI ฐานข้อมูลได้กลายเป็น "โครงสร้างพื้นฐานอัจฉริยะ" ที่ AI ต้องพึ่งพาใน 3 มิติหลัก
มิติที่ 1: การพัฒนา AI Agent
Aurora รองรับ MCP (Model Context Protocol) ซึ่งเปรียบเสมือน "สะพานเชื่อม" ระหว่าง AI กับฐานข้อมูล ทำให้ AI สามารถแปลงคำถามภาษาธรรมชาติ ไม่ว่าจะเป็นภาษาไทยหรืออังกฤษ ให้กลายเป็น SQL Query ได้โดยอัตโนมัติ ลด Learning Curve และเพิ่มความสะดวกในการทำงานอย่างมาก
มิติที่ 2: RAG (Retrieval-Augmented Generation)
เพื่อให้ AI ตอบคำถามได้แม่นยำและลด Hallucination Aurora รองรับ pgvector ซึ่งเป็น Vector Database ที่ช่วยให้ AI ดึงข้อมูลที่เกี่ยวข้องมาประกอบการตอบได้อย่างถูกต้องและตรงบริบทมากขึ้น
มิติที่ 3: หน่วยความจำของ AI (Agent Memory)
Aurora ทำหน้าที่เป็นทั้ง Short-term Memory, Long-term Memory และ Episodic Memory ของ AI Agent ทำให้ AI "จำ" ได้ว่าผู้ใช้ชอบอะไร เคยซื้อสินค้าอะไร และมีพฤติกรรมแบบไหน เพื่อมอบประสบการณ์แบบ Personalization ที่แท้จริง

เทคนิคเพิ่มประสิทธิภาพ RAG ด้วย Aurora
สำหรับทีมที่ต้องการดึงประสิทธิภาพสูงสุดจากการทำ RAG มีเทคนิคที่น่าสนใจดังนี้
- ใช้ HNSW Algorithm ร่วมกับ Re-ranker เพื่อคัดกรองเวกเตอร์ที่ไม่เกี่ยวข้องออก และสมดุลระหว่างความแม่นยำกับความเร็ว
- การกรองข้อมูลล่วงหน้า (Metadata Filtering) สามารถลดข้อมูลที่ไม่เกี่ยวข้องออกได้ถึง 40-60% และเพิ่มประสิทธิภาพ AI Agent ได้ 2-3 เท่า
- การใช้ MCP บน Aurora ช่วยให้ AI สามารถวิเคราะห์โครงสร้างฐานข้อมูลและสร้าง Query ได้เองโดยอัตโนมัติ เช่น ค้นหาสินค้า Top 10 ที่ขายดีที่สุดในไทยช่วง Harr Season
Amazon Aurora Limitless: เมื่อต้องการสเกลแบบไม่มีขีดจำกัด
สำหรับงานที่ต้องการ Throughput สูงมาก Aurora Limitless คือคำตอบ ด้วยจุดเด่นคือ
- รองรับ Multi-Region Active-Active Architecture
- Downtime เพียงแค่ไม่กี่วินาทีต่อปี
- ข้อมูลกระจายไปยัง Shards โดยอัตโนมัติ รองรับ Workload ขนาดใหญ่ได้อย่างราบรื่น
ฟีเจอร์เด่นอื่นๆ ที่น่าสนใจ
- Dynamic Data Masking: ซ่อนข้อมูลสำคัญบางคอลัมน์โดยไม่แก้ไขข้อมูลต้นทาง เหมาะสำหรับการควบคุมสิทธิ์การเข้าถึงข้อมูล
- Aurora Serverless: ฐานข้อมูลที่ขยายและลดขนาดได้อัตโนมัติตาม Workload จริง ประหยัดต้นทุนในช่วงที่การใช้งานไม่แน่นอน
- รองรับ PostgreSQL 17 และ Instance รุ่นใหม่ที่รองรับ Storage ได้สูงถึง 250TB
สรุป: ทำไมต้อง Aurora สำหรับยุค Real-Time AI
ในยุคที่ AI ต้องทำงานแบบ Real-Time และตอบสนองต่อทุกการกระทำของผู้ใช้ได้ทันที Aurora ไม่ได้เป็นแค่ฐานข้อมูล แต่คือโครงสร้างพื้นฐานอัจฉริยะที่รองรับทั้ง Fraud Detection, Hyper-Personalization และ Streaming Services ไปพร้อมกัน ช่วยให้ทีมพัฒนาโฟกัสกับการออกแบบ Schema และ Query Optimization เพื่อตอบโจทย์ธุรกิจได้เต็มที่ โดยไม่ต้องกังวลเรื่องการจัดการโครงสร้างพื้นฐานอีกต่อไป











