
Azure AI Search のシノニムマップをPythonで作成してみた
はじめに
こんにちは、コンサルティング部の神野です。
皆さんはAzure AI Searchのシノニム検索機能を使っていますか?私も最近、ドキュメント検索システムの改善でこの機能が必要になったのですが、Azure ポータルからはシノニムマップを作成できないということを知り、REST APIでの登録が必要でした。
もちろんREST APIでも登録可能ですが、今回はシノニムの定義を更新する必要があり、デプロイパイプラインに組み込みたくPythonスクリプトで自動化してみました!
今回はその実装方法と、実際に動かしてみた結果を共有したいと思います。
シノニム検索について
Azure AI Searchのシノニム機能は、事前に登録した類義語を使って検索の幅を広げる機能です。
例えば
- 「顧客」と検索したら「お客様」「クライアント」「カスタマー」も検索
- 「データベース」と検索したら「DB」「database」「データストア」も検索
と類義語でも検索が可能になります。
環境情報
今回使用した環境は以下の通りです。
- Python 3.11.5
- Azure AI Search (S1 Standard)
Azure AI Search の作成
まずは Azure AI Search を作成していきましょう!
1. Azureポータルでの作成
-
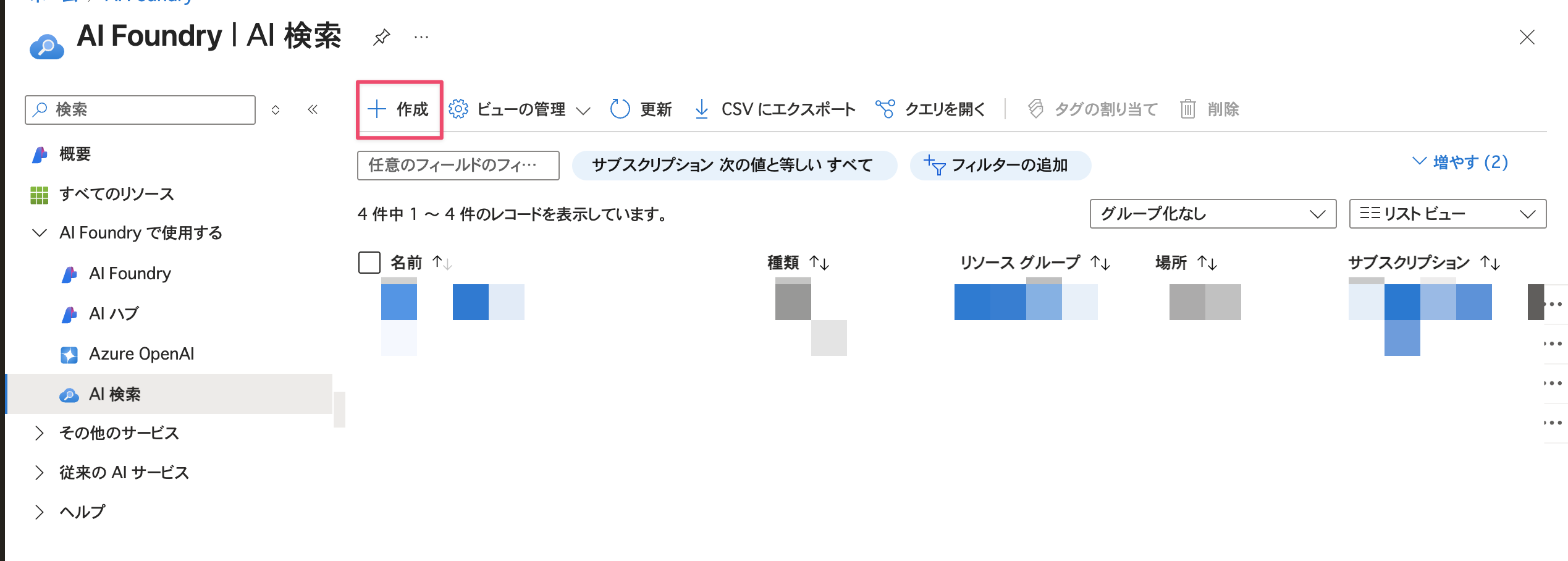
Azure ポータルにログインして、「AI Foundry」を表示して
作成ボタンを選択
-
以下の設定で作成
サービス名: search-synonym-demo 場所: Japan East 価格レベル: 基本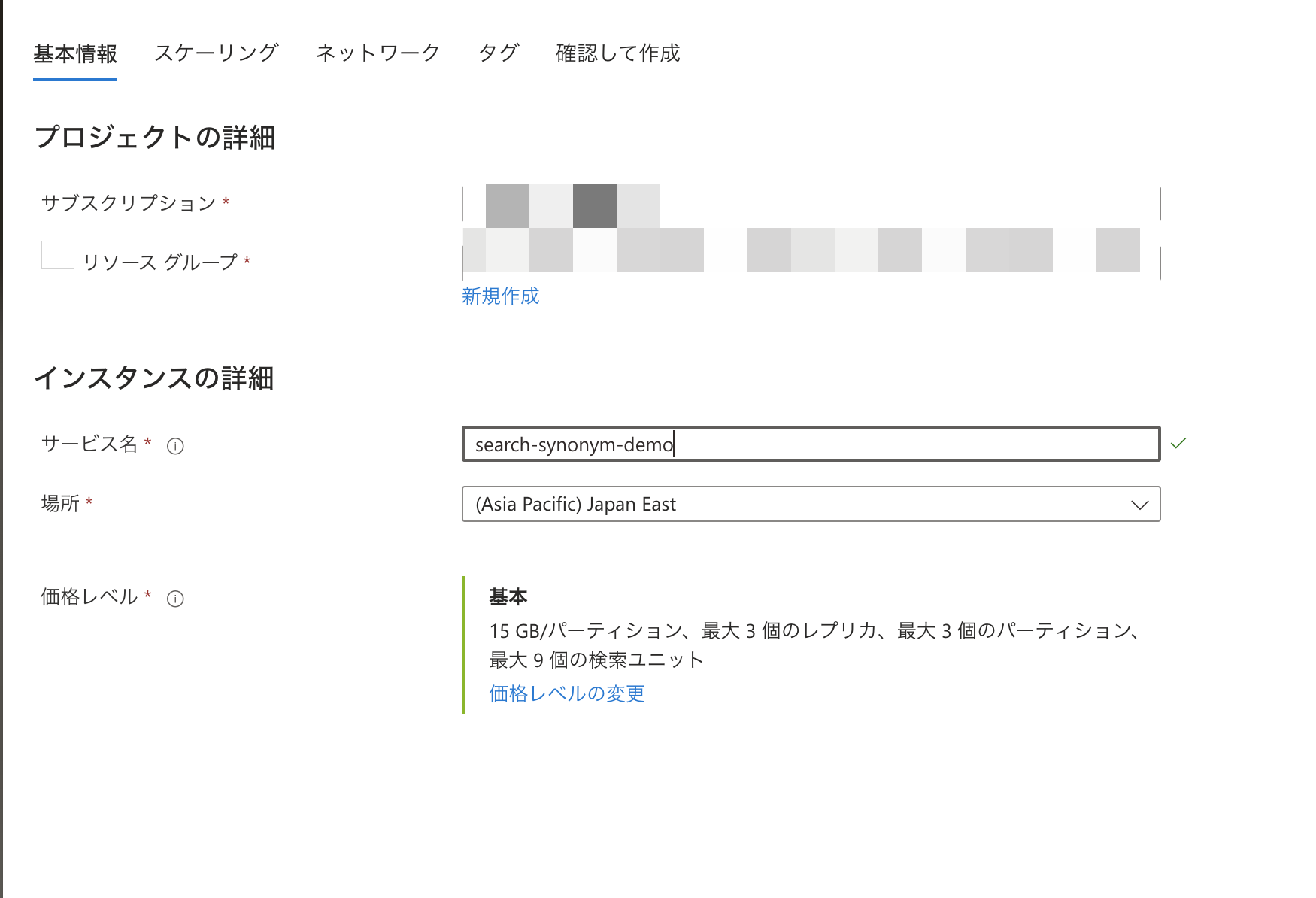
2. インデックスの作成
次に、検索対象となるインデックスを作成します。今回はシンプルに以下のようなスキーマにしました。
- title:タイトル(ex.月次売上レポートの作成方法)
- chunk:説明(ex.売上高の集計方法について説明します。各部門の売上を集計し、前月比や前年同期比を算出します。収益分析には専用のツールを使用してください)
{
"name": "documents-index",
"fields": [
{
"name": "id",
"type": "Edm.String",
"key": true,
"searchable": false
},
{
"name": "title",
"type": "Edm.String",
"searchable": true,
"filterable": true
},
{
"name": "chunk",
"type": "Edm.String",
"searchable": true
}
]
}
インデックスの追加(JSON)から投入します。
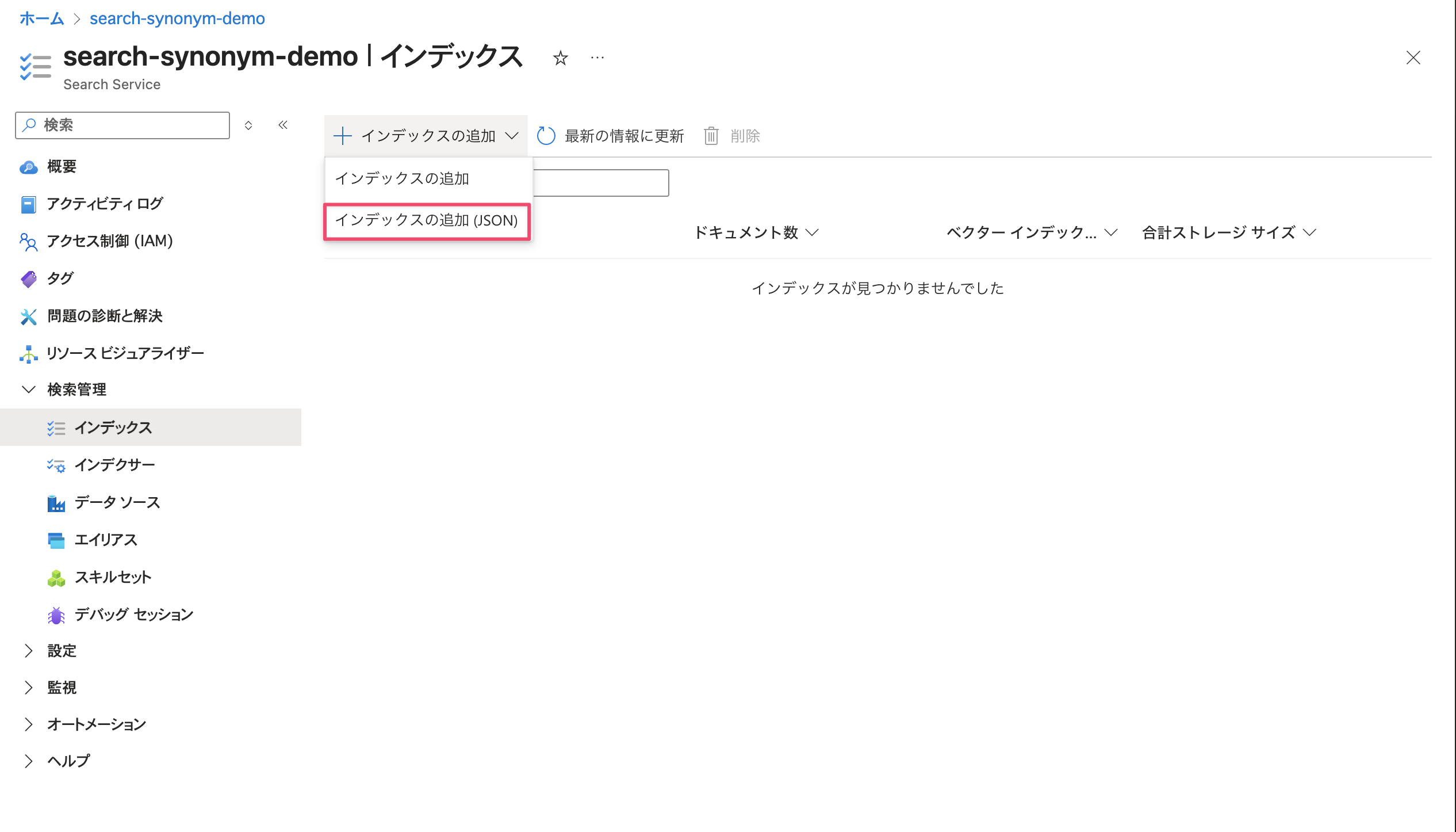
定義をコピペして保存ボタンを選択します。

3. サンプルデータの投入
インデックスにテストデータを投入します。以下のようなPythonスクリプトで投入できます。
import os
from dotenv import load_dotenv
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
# 環境変数の読み込み
load_dotenv()
# 環境変数から接続設定を取得
endpoint = os.getenv("AZURE_SEARCH_ENDPOINT")
index_name = os.getenv("AZURE_SEARCH_INDEX_NAME")
key = os.getenv("AZURE_SEARCH_ADMIN_KEY")
# 環境変数の検証
if not all([endpoint, index_name, key]):
raise ValueError(
"必要な環境変数が設定されていません。"
"AZURE_SEARCH_ENDPOINT, AZURE_SEARCH_INDEX_NAME, AZURE_SEARCH_ADMIN_KEY を設定してください。"
)
# クライアントの作成
search_client = SearchClient(
endpoint=endpoint,
index_name=index_name,
credential=AzureKeyCredential(key)
)
# サンプルドキュメント
documents = [
{
"id": "1",
"title": "月次売上レポートの作成方法",
"chunk": "売上高の集計方法について説明します。各部門の売上を集計し、前月比や前年同期比を算出します。収益分析には専用のツールを使用してください。"
},
{
"id": "2",
"title": "新規顧客獲得戦略について",
"chunk": "お客様のニーズを的確に把握することが重要です。クライアントとの信頼関係を構築し、長期的なパートナーシップを目指します。カスタマーサポートの充実も欠かせません。"
},
{
"id": "3",
"title": "データベース設計のベストプラクティス",
"chunk": "DBの設計では正規化が重要です。データストアの選択も慎重に行う必要があります。databaseのパフォーマンスチューニングについても解説します。"
},
{
"id": "4",
"title": "会議効率化のための10のヒント",
"chunk": "ミーティングの時間を短縮する方法を紹介します。meetingの前には必ずアジェンダを準備し、打ち合わせの目的を明確にしましょう。"
},
{
"id": "5",
"title": "セキュリティポリシーの策定",
"chunk": "企業のsecurityを守るためには、包括的なセキュアな環境構築が必要です。データ保護の観点から、アクセス制御も重要な要素となります。"
},
{
"id": "6",
"title": "クラウド移行プロジェクトの進め方",
"chunk": "オンプレミスからcloudへの移行には計画的な準備が必要です。クラウドサービスの選定から、移行後の運用まで、段階的に進めていきます。"
}
]
# ドキュメントのアップロード
try:
result = search_client.upload_documents(documents=documents)
print(f"正常にアップロードされました: {len(result)} 件のドキュメント")
# 結果の詳細を表示
for item in result:
print(f" - ID: {item.key}, ステータス: {item.succeeded}")
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
スクリプトは環境変数から情報を読み取るので、.envに下記値を設定しておきます。
AZURE_SEARCH_ENDPOINT=https://search-synonym-demo.search.windows.net
AZURE_SEARCH_INDEX_NAME=documents-index
AZURE_SEARCH_ADMIN_KEY=xxx
エンドポイントは概要ページからコピーできます。
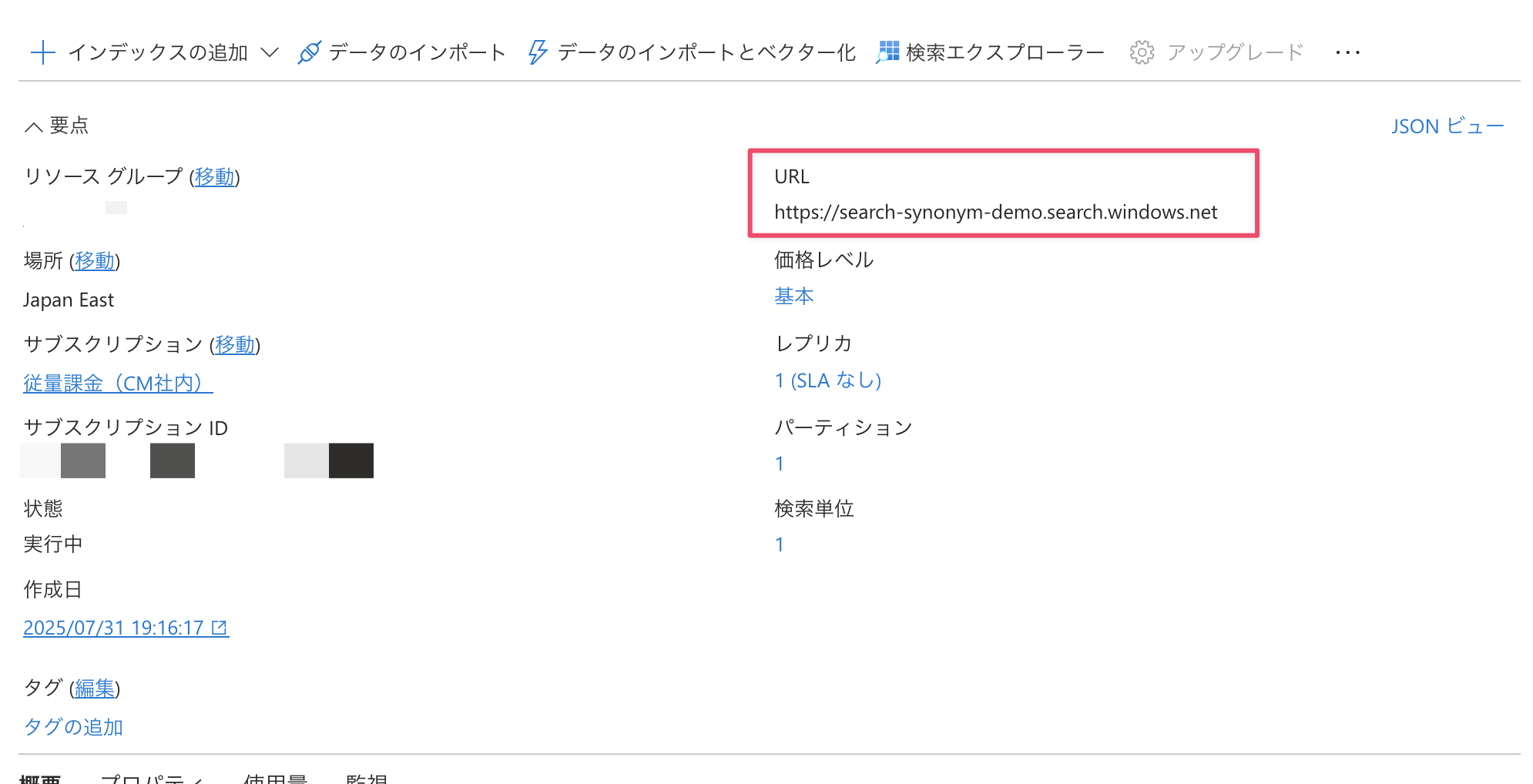
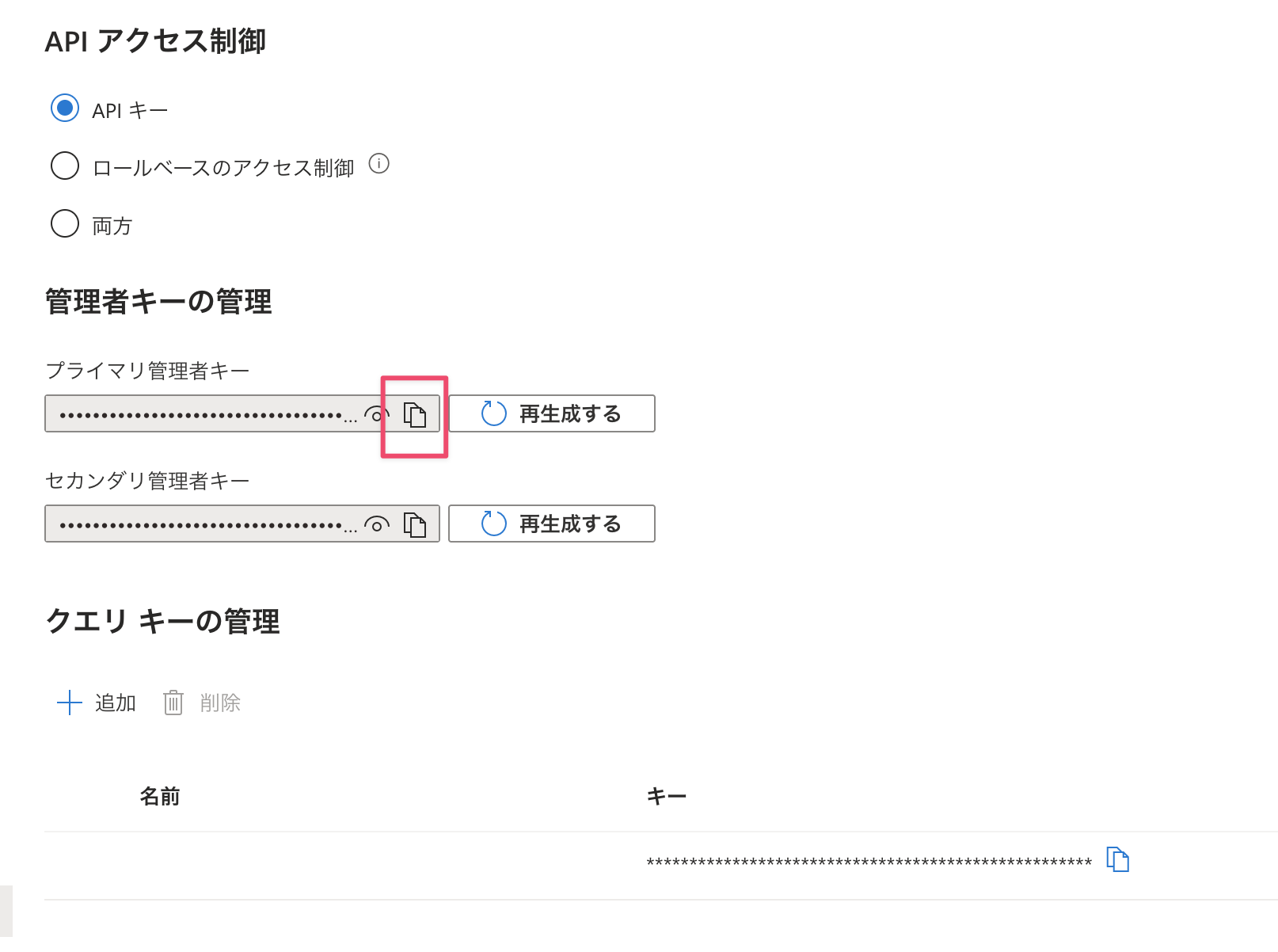
管理キーは設定>キーからプライマリー管理者キーをコピーします。
この状態で、ライブラリを入れてテストデータを実行します。
requirements.txtには下記ライブラリを記載します。
azure-search-documents
azure-core
python-dotenv
pydantic
pip installを実行します。
pip install -r requirements.txt
インストールが完了したら、スクリプトを実行します。
python upload_documents.py
正常にアップロードされました: 6 件のドキュメント
- ID: 1, ステータス: True
- ID: 2, ステータス: True
- ID: 3, ステータス: True
- ID: 4, ステータス: True
- ID: 5, ステータス: True
- ID: 6, ステータス: True
上記のように出力されていればOKです!
念の為、AI Searchでクエリを実行して検索結果が表示されるか確認してみます。
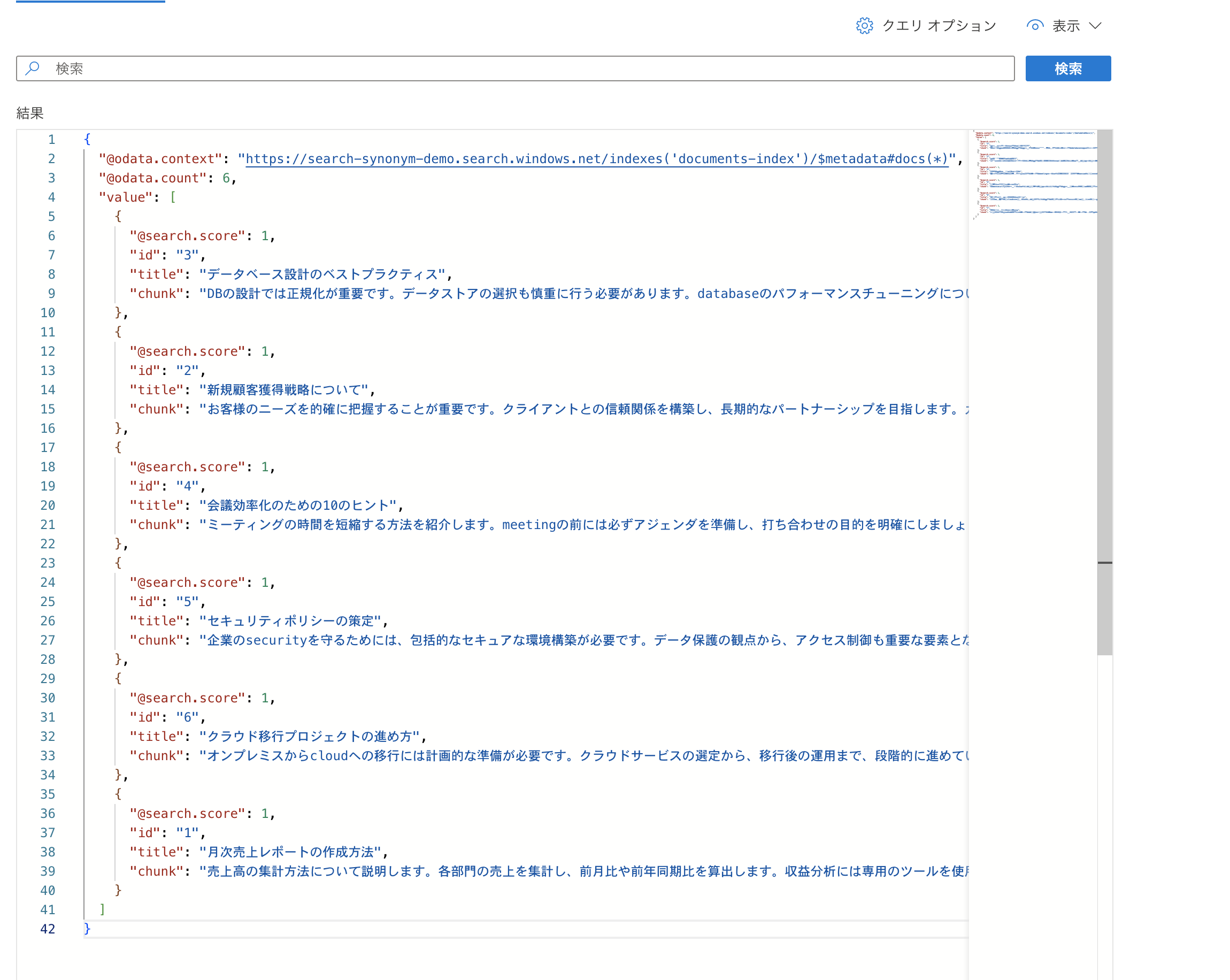
しっかりと6件表示されていました!登録完了していますね!
シノニムマップの定義
ここからが本題です!シノニムマップは以下のようなJSON形式で定義します。synonyms.jsonとしておきます。
{
"name": "business-terms",
"synonyms": "売上, 売上高, revenue, セールス\n顧客, お客様, クライアント, カスタマー, customer, client\nデータベース, DB, database, データストア\n会議, ミーティング, meeting, 打ち合わせ, 会合\nセキュリティ, security, セキュア, 保護\nクラウド, cloud, クラウドサービス\n企業, 会社, 法人, コーポレーション, company"
}
Pythonスクリプトによる自動化
Azure ポータルではシノニムマップを作成できないため、Pythonスクリプトで自動化しました。
コード全文(長いので省略しています)
"""
Azure AI Searchのシノニムマップを作成・更新するスクリプト
"""
import json
import logging
import os
import sys
from datetime import datetime
from typing import Dict, List, Optional
from azure.core.credentials import AzureKeyCredential
from azure.core.exceptions import AzureError, ResourceNotFoundError
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import SearchField, SearchIndex, SynonymMap
from pydantic import BaseModel, Field
# ログ設定
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler("synonym_update.log"),
logging.StreamHandler(sys.stdout),
],
)
logger = logging.getLogger(__name__)
class SynonymConfig(BaseModel):
"""Azure AI Searchシノニム設定"""
# Azure AI Search接続設定
service_endpoint: str = Field(..., description="AI Search service endpoint")
admin_key: str = Field(..., description="AI Search admin key for write operations")
index_name: str = Field(..., description="AI Search index name")
# シノニム設定
synonym_file_path: str = Field(..., description="シノニム定義JSONファイルのパス")
synonym_map_name: str = Field(
default="business-terms", description="シノニムマップ名(JSONファイル内のnameフィールドを優先)"
)
# 実行設定
dry_run: bool = Field(default=False, description="実際には更新せずにログ出力のみ")
overwrite_existing: bool = Field(
default=True, description="既存のシノニムマップを上書きするか"
)
class SynonymUpdater:
"""Azure AI Searchのシノニムマップを更新するクラス"""
def __init__(self, config: SynonymConfig):
self.config = config
self.index_client = SearchIndexClient(
endpoint=config.service_endpoint,
credential=AzureKeyCredential(config.admin_key),
)
def _load_synonym_definition(self) -> Dict:
"""シノニム定義JSONファイルを読み込む"""
try:
with open(self.config.synonym_file_path, "r", encoding="utf-8") as f:
data = json.load(f)
logger.info(f"Loaded synonym definition from: {self.config.synonym_file_path}")
logger.debug(f"Synonym data: {data}")
# 必須フィールドの確認
if "synonyms" not in data:
raise ValueError("Missing 'synonyms' field in JSON file")
# nameフィールドがあれば使用、なければconfigのデフォルトを使用
if "name" in data:
self.config.synonym_map_name = data["name"]
logger.info(f"Using synonym map name from JSON: {self.config.synonym_map_name}")
return data
except FileNotFoundError:
logger.error(f"Synonym file not found: {self.config.synonym_file_path}")
raise
except json.JSONDecodeError as e:
logger.error(f"Invalid JSON in synonym file: {e}")
raise
except Exception as e:
logger.error(f"Error loading synonym definition: {e}")
raise
def _create_synonym_map(self, synonym_data: Dict) -> SynonymMap:
"""シノニムマップオブジェクトを作成"""
try:
# シノニムデータを適切な形式に変換
synonyms_raw = synonym_data["synonyms"]
if isinstance(synonyms_raw, str):
# 文字列の場合は改行で分割してリストに変換
synonyms_list = [line.strip() for line in synonyms_raw.split('\n') if line.strip()]
logger.info(f"Converted synonym string to list: {len(synonyms_list)} rules")
logger.debug(f"Synonym rules: {synonyms_list}")
elif isinstance(synonyms_raw, list):
# すでにリストの場合はそのまま使用
synonyms_list = synonyms_raw
logger.info(f"Using synonym list as-is: {len(synonyms_list)} rules")
else:
raise ValueError(f"Invalid synonym format: {type(synonyms_raw)}")
# SynonymMapオブジェクトを作成
synonym_map = SynonymMap(
name=self.config.synonym_map_name,
synonyms=synonyms_list,
encryption_key=synonym_data.get("encryptionKey"), # オプション
)
logger.info(f"Created synonym map object: {synonym_map.name}")
return synonym_map
except Exception as e:
logger.error(f"Error creating synonym map object: {e}")
raise
def _check_existing_synonym_map(self) -> Optional[SynonymMap]:
"""既存のシノニムマップを確認"""
try:
existing_map = self.index_client.get_synonym_map(self.config.synonym_map_name)
logger.info(f"Found existing synonym map: {existing_map.name}")
return existing_map
except ResourceNotFoundError:
logger.info(f"No existing synonym map found: {self.config.synonym_map_name}")
return None
except Exception as e:
logger.error(f"Error checking existing synonym map: {e}")
raise
def _update_index_fields(self) -> None:
"""インデックスのフィールドにシノニムマップを適用"""
try:
# 現在のインデックス定義を取得
index = self.index_client.get_index(self.config.index_name)
logger.info(f"Retrieved index: {index.name}")
# インデックス内の全フィールドをデバッグ出力
logger.info("Available fields in index:")
for field in index.fields:
field_type = field.type.name if hasattr(field.type, 'name') else str(field.type)
logger.info(f" Field: {field.name}, Type: {field_type}, Searchable: {field.searchable}")
# シノニムマップを適用するフィールドを特定
# chunk と title フィールドのみに適用
updated_fields = []
fields_to_update = []
for field in index.fields:
field_type = field.type.name if hasattr(field.type, 'name') else str(field.type)
if (
field.searchable
and field_type == "Edm.String"
and field.name in ["chunk", "title"] # 対象フィールドを限定
):
# synonym_map_namesプロパティを確認(Azure AI Searchの実際のプロパティ名)
field_dict = field.as_dict()
current_maps = field_dict.get("synonym_map_names", []) or []
logger.info(f"Field '{field.name}' current synonym maps: {current_maps}")
if self.config.synonym_map_name not in current_maps:
# フィールドのコピーを作成して更新
field_dict["synonym_map_names"] = [self.config.synonym_map_name]
updated_field = SearchField.from_dict(field_dict)
updated_fields.append(updated_field)
fields_to_update.append(field.name)
logger.info(f"Will update field '{field.name}' with synonym map '{self.config.synonym_map_name}'")
else:
updated_fields.append(field)
logger.info(f"Field '{field.name}' already has synonym map '{self.config.synonym_map_name}'")
else:
updated_fields.append(field)
field_type = field.type.name if hasattr(field.type, 'name') else str(field.type)
if field.searchable and field_type == "Edm.String":
logger.info(f"Skipping field '{field.name}' (not in target list)")
logger.info(f"Found {len(fields_to_update)} fields to update: {fields_to_update}")
if not fields_to_update:
logger.info("No fields need synonym map update")
return
if self.config.dry_run:
logger.info(f"DRY RUN: Would update fields: {fields_to_update}")
return
# インデックスを更新
logger.info("Updating index with synonym maps...")
index.fields = updated_fields
result = self.index_client.create_or_update_index(index)
logger.info(f"Successfully updated index with synonym map on fields: {fields_to_update}")
logger.info(f"Index update result: ETag={getattr(result, 'e_tag', 'N/A')}")
except Exception as e:
logger.error(f"Error updating index fields: {e}")
logger.error(f"Error type: {type(e).__name__}")
import traceback
logger.error(f"Traceback: {traceback.format_exc()}")
raise
def run(self) -> None:
"""シノニムマップ更新処理を実行"""
logger.info("Starting synonym map update process")
logger.info(f"Service endpoint: {self.config.service_endpoint}")
logger.info(f"Index name: {self.config.index_name}")
logger.info(f"Synonym file: {self.config.synonym_file_path}")
logger.info(f"Dry run: {self.config.dry_run}")
try:
# シノニム定義を読み込む
synonym_data = self._load_synonym_definition()
# シノニムマップオブジェクトを作成
synonym_map = self._create_synonym_map(synonym_data)
# 既存のシノニムマップを確認
existing_map = self._check_existing_synonym_map()
# シノニムマップを作成または更新
if existing_map:
if not self.config.overwrite_existing:
logger.warning(
f"Synonym map '{self.config.synonym_map_name}' already exists and overwrite_existing=False"
)
return
if self.config.dry_run:
logger.info(
f"DRY RUN: Would update existing synonym map '{self.config.synonym_map_name}'"
)
else:
self.index_client.create_or_update_synonym_map(synonym_map)
logger.info(f"Updated synonym map: {self.config.synonym_map_name}")
else:
if self.config.dry_run:
logger.info(f"DRY RUN: Would create new synonym map '{self.config.synonym_map_name}'")
else:
self.index_client.create_synonym_map(synonym_map)
logger.info(f"Created new synonym map: {self.config.synonym_map_name}")
# インデックスのフィールドにシノニムマップを適用
logger.info("Applying synonym map to index fields...")
self._update_index_fields()
logger.info("Synonym map update process completed successfully")
except Exception as e:
logger.error(f"Synonym map update failed: {e}")
raise
def main():
"""メイン実行関数"""
# 環境変数から設定を読み込み
service_endpoint = os.getenv("AZURE_SEARCH_SERVICE_ENDPOINT")
admin_key = os.getenv("AZURE_SEARCH_ADMIN_KEY")
index_name = os.getenv("AZURE_SEARCH_INDEX_NAME")
synonym_file_path = os.getenv("SYNONYM_FILE_PATH", "synonyms.json")
if not all([service_endpoint, admin_key, index_name]):
logger.error("Required environment variables are missing:")
logger.error(" AZURE_SEARCH_SERVICE_ENDPOINT")
logger.error(" AZURE_SEARCH_ADMIN_KEY")
logger.error(" AZURE_SEARCH_INDEX_NAME")
sys.exit(1)
# 設定を作成
config = SynonymConfig(
service_endpoint=service_endpoint, # type: ignore
admin_key=admin_key, # type: ignore
index_name=index_name, # type: ignore
synonym_file_path=synonym_file_path,
dry_run=os.getenv("DRY_RUN", "false").lower() == "true",
overwrite_existing=os.getenv("OVERWRITE_EXISTING", "true").lower() == "true",
)
# シノニムマップ更新実行
updater = SynonymUpdater(config)
updater.run()
if __name__ == "__main__":
main()
以下の点を実装しています。
- 既存のシノニムマップの確認
- 存在する場合は更新、存在しない場合は新規作成
- インデックスフィールドへの適用
- 対象フィールド(chunk, title)のみに適用
- 他のフィールドには影響を与えない
- ドライラン機能
- 実際の更新前に動作確認が可能
実行時のログ出力
実行すると以下のようなログが出力されます。
2025-01-01 10:00:00 - INFO - Starting synonym map update process
2025-01-01 10:00:00 - INFO - Service endpoint: https://search-synonym-demo.search.windows.net
2025-01-01 10:00:00 - INFO - Index name: documents-index
2025-01-01 10:00:01 - INFO - Created synonym map object: business-terms
2025-01-01 10:00:02 - INFO - Updated synonym map: business-terms
2025-01-01 10:00:03 - INFO - Available fields in index:
2025-01-01 10:00:03 - INFO - Field: id, Type: Edm.String, Searchable: False
2025-01-01 10:00:03 - INFO - Field: title, Type: Edm.String, Searchable: True
2025-01-01 10:00:03 - INFO - Field: chunk, Type: Edm.String, Searchable: True
2025-01-01 10:00:04 - INFO - Successfully updated index with synonym map on fields: ['chunk', 'title']
2025-01-01 10:00:04 - INFO - Synonym map update process completed successfully
使い方
このスクリプトを使うには、以下の環境変数を設定すれば実行可能です。
export AZURE_SEARCH_SERVICE_ENDPOINT="https://your-search.search.windows.net"
export AZURE_SEARCH_ADMIN_KEY="your-admin-key"
export AZURE_SEARCH_INDEX_NAME="documents-index"
export SYNONYM_FILE_PATH="synonyms.json"
# ドライランで確認
export DRY_RUN=true
python update_synonym.py
# 実際に更新
export DRY_RUN=false
python update_synonym.py
フィールドの選択的な更新
全フィールドにシノニムマップを適用するのではなく、必要なフィールドのみに適用するようにしました。
if (
field.searchable
and field_type == "Edm.String"
and field.name in ["chunk", "title"] # 対象フィールドを限定
):
これによりIDフィールドなど、シノニム検索が不要なフィールドには影響を与えません。
動作確認
実際にシノニム検索が動作するか確認してみました!
下記コマンドを実行します。
python update_synonym.py
コマンドを実行した結果、下記のように成功ログが出ていればOKです!
2025-07-31 20:02:09,874 - INFO - Synonym map update process completed successfully
シノニム適用前の検索結果
まず、シノニムマップを適用する前に「customer」で検索してみました。
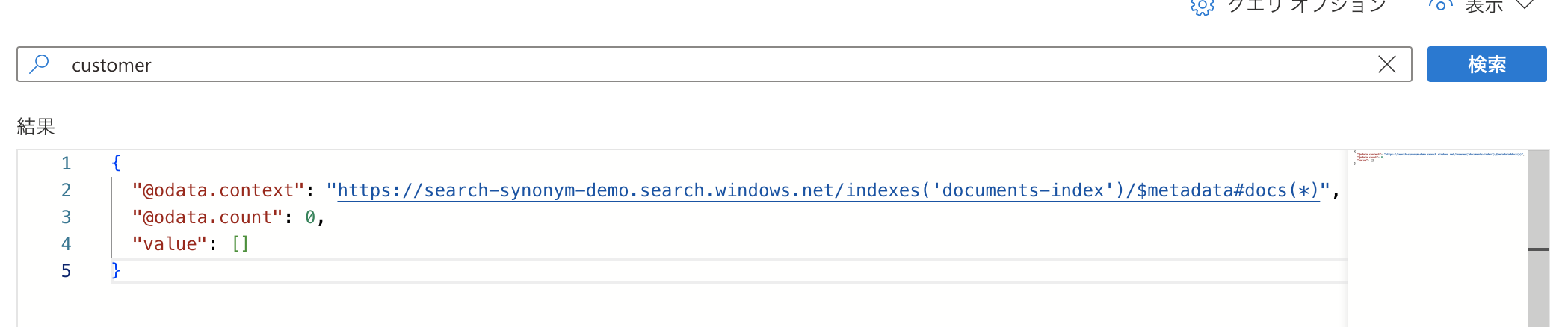
1件もヒットしていませんね。
シノニム適用後の検索結果
シノニムマップを適用した後、同じく「customer」で検索してみました。
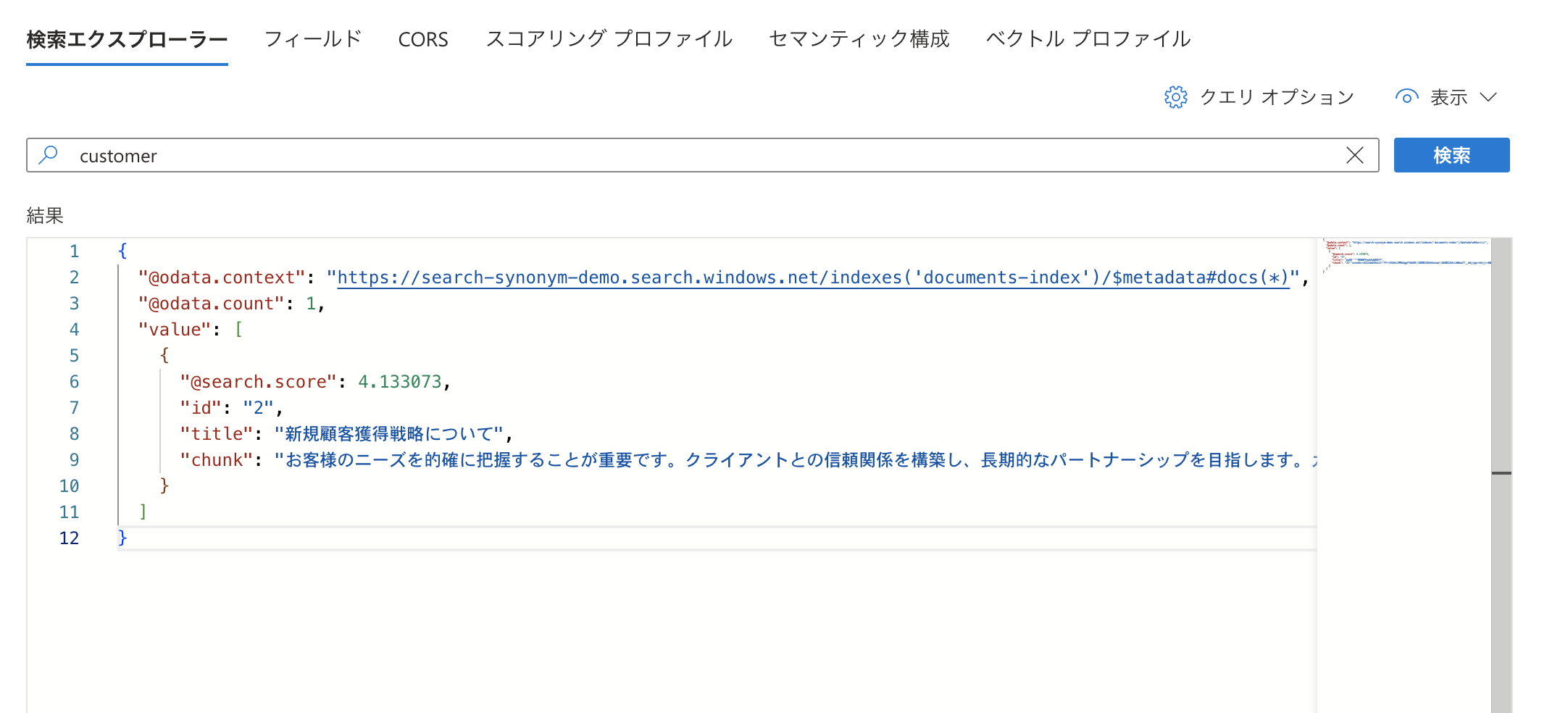
シノニムが登録されているので検索結果が返却されましたね!
他の検索パターンも
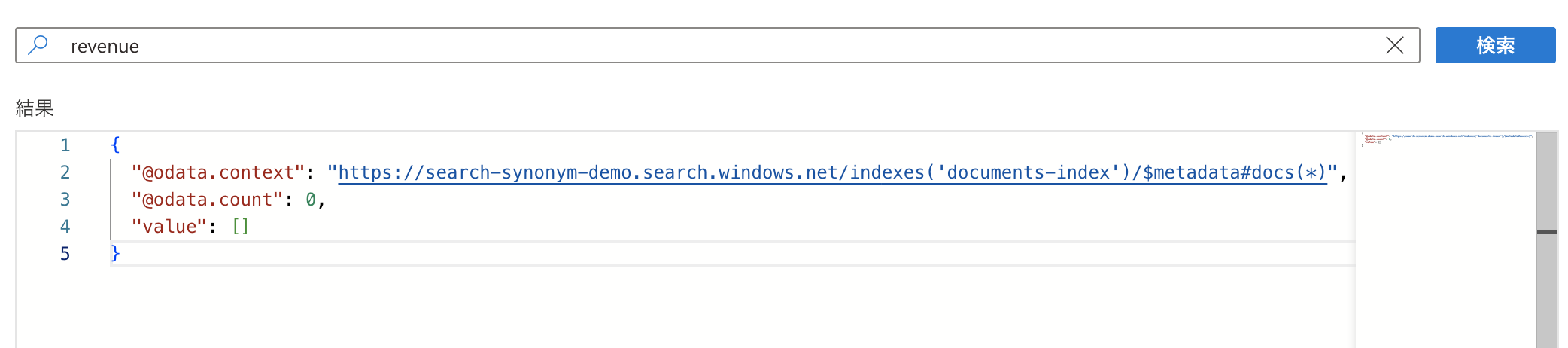
シノニム適用前で「revenue」で検索
シノニム適用後
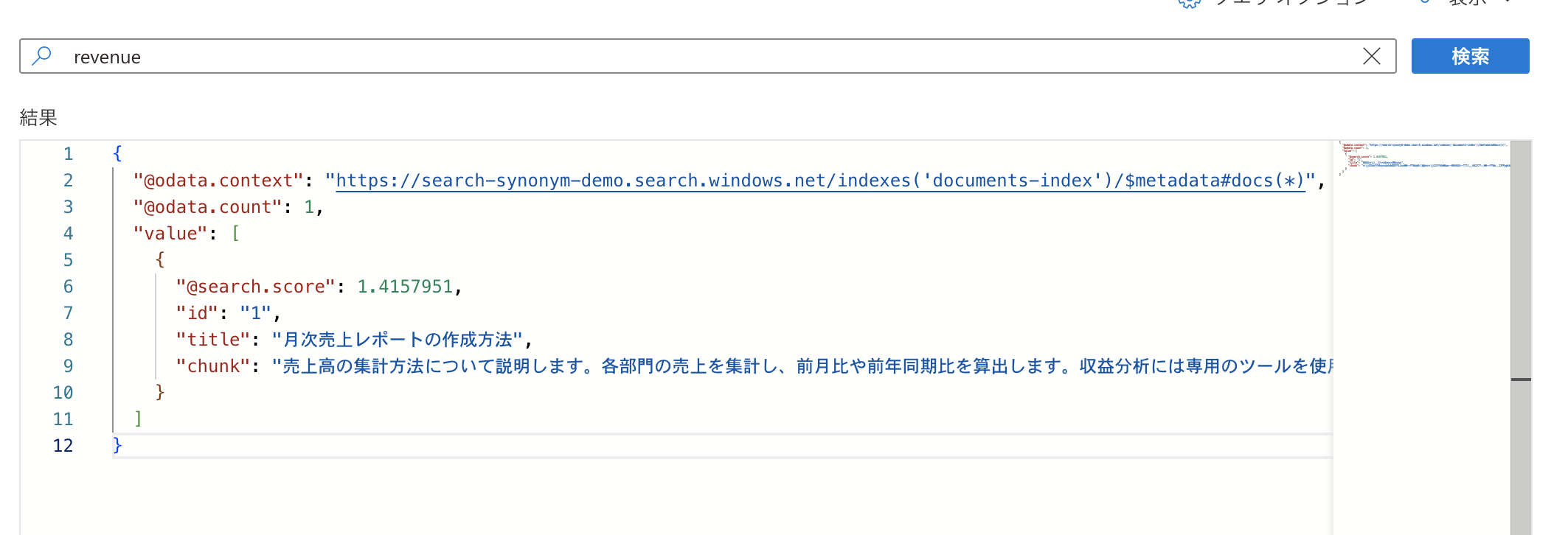
こちらも期待通り検索結果として返却されるようになりましたね!
おわりに
今回はPythonスクリプト上からシノニムマップを作成してみました!
ポータル上から登録されないのは若干不便ですが、そこまで難しくなく対応できたのでよかったです!
本記事が少しでも役に立ちましたら幸いです!
最後までご覧いただきありがとうございました!









