Azure Data FactoryでBlob Storage内のCSVをSnowflakeにデータをロードしてみた
かわばたです。
Azure Data Factory(ADF)のCopy Activityを用いて、Azure Blob Storage内のCSVファイルをSnowflakeにロードするパイプラインのセットアップ手順をまとめました。
ADFのSnowflakeコネクタ(V2)は、内部的にSnowflakeのCOPY INTO <table>コマンドを利用してデータをロードします。本記事では、Blob Storageをステージングストレージとして使用し、CSVファイルをSnowflakeテーブルにロードする構成を構築します。
全体構成
本記事で構築する構成は以下の通りです。
Azure Blob Storage (CSV)
↓ ソース
Azure Data Factory (Copy Activity)
↓ ステージング (Blob Storage経由)
Snowflake (テーブル)
ADFのCopy Activityでは、Blob Storage内のCSVファイルをソースとし、Snowflakeテーブルをシンク(宛先)とします。Copy ActivityのSettingsでステージングを有効化し、中間ステージングとしてBlob Storageを使用します。これにより、ADFがCSVデータをステージング用Blob Storageに配置した後、SnowflakeのCOPY INTO <table>コマンドでテーブルにロードする流れとなります。
Azure Blob Storage上のCSVは条件を満たせばステージングなしのDirect copyも利用できますが、本記事ではステージングを明示的に有効化する構成で検証します。
検証環境
以下の検証環境で実施します。
- Snowflake: Microsoft Azure Japan Eastリージョン、Business Criticalエディション
- 必要なSnowflakeロール: SYSADMINロール(データベース・テーブル作成)。ADF実行ユーザーには、データベースへの
USAGE、スキーマおよびテーブルへの読み書き権限、スキーマ上のCREATE STAGE権限が必要です - Azure Data Factory: Managed Virtual Networkが有効化された状態で作成済み
- Azure Blob Storage: ストレージアカウントが作成済み。IAMでロールを付与できる権限が必要です
- Azure権限: ADFでLinked Serviceを作成できる権限、Blob Storageへのアクセス権限
- CSVデータ: dbt-labsのjaffle-shopプロジェクトの
raw_customers.csvを使用
Snowflakeにロード先テーブルを作成
まず、Snowflake側にCSVデータのロード先となるデータベース・スキーマ・テーブルを作成します。
今回使用するraw_customers.csvは以下のカラム構成です。
| カラム名 | データ型 | 説明 |
|---|---|---|
| id | VARCHAR | 顧客ID(UUID形式) |
| name | VARCHAR | 顧客名 |
以下のSQLでデータベース・スキーマ・テーブル・ウェアハウスを作成します。
USE ROLE SYSADMIN;
-- データベースの作成
CREATE DATABASE IF NOT EXISTS ADF_DEMO_DB;
-- スキーマの作成
CREATE SCHEMA IF NOT EXISTS ADF_DEMO_DB.RAW;
-- テーブルの作成
CREATE TABLE IF NOT EXISTS ADF_DEMO_DB.RAW.RAW_CUSTOMERS (
ID VARCHAR,
NAME VARCHAR
);
-- ウェアハウスの作成
CREATE WAREHOUSE IF NOT EXISTS ADF_DEMO_WH
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;
テーブルが作成されたことを確認します。
DESCRIBE TABLE ADF_DEMO_DB.RAW.RAW_CUSTOMERS;
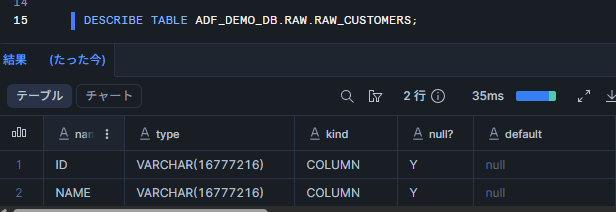
テーブルの定義が表示されればOKです。
ADF実行ユーザーの権限設定
ADFのLinked Serviceで使用するSnowflakeユーザーには、Copy Activity実行時に以下の権限が必要です。ADF専用のロールを作成して付与することを推奨します。
-- ADF実行用ロールの作成と権限付与
USE ROLE SECURITYADMIN;
CREATE ROLE IF NOT EXISTS ADF_ROLE;
GRANT ROLE ADF_ROLE TO USER <ADF用ユーザー名>;
USE ROLE SYSADMIN;
-- ウェアハウスの利用権限
GRANT USAGE ON WAREHOUSE ADF_DEMO_WH TO ROLE ADF_ROLE;
-- データベース・スキーマへのアクセス権限
GRANT USAGE ON DATABASE ADF_DEMO_DB TO ROLE ADF_ROLE;
GRANT USAGE ON SCHEMA ADF_DEMO_DB.RAW TO ROLE ADF_ROLE;
-- テーブルへの読み書き権限
GRANT SELECT, INSERT ON TABLE ADF_DEMO_DB.RAW.RAW_CUSTOMERS TO ROLE ADF_ROLE;
-- ステージの作成・削除権限(Copy Activityが内部的に使用)
GRANT CREATE STAGE ON SCHEMA ADF_DEMO_DB.RAW TO ROLE ADF_ROLE;
Snowflake Storage Integrationを作成
SnowflakeがAzure Blob Storageにアクセスするために、SnowflakeのStorage Integration(以下、Storage Integration)を作成します。Storage Integrationを使用することで、SASトークンを管理する必要がなくなり、ADFのBlob Storage Linked ServiceでもAccount keyなど任意の認証方式を利用できます。
Storage Integrationの作成
SnowflakeでACCOUNTADMINロールを使用し、Storage Integrationを作成します。
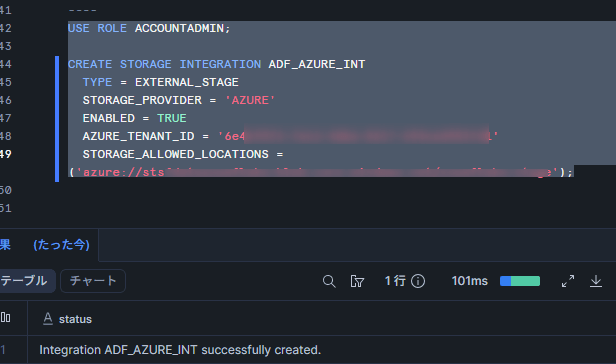
USE ROLE ACCOUNTADMIN;
CREATE STORAGE INTEGRATION ADF_AZURE_INT
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'AZURE'
ENABLED = TRUE
AZURE_TENANT_ID = '<Azure ADのテナントID>'
STORAGE_ALLOWED_LOCATIONS = ('azure://<ストレージアカウント名>.blob.core.windows.net/<コンテナー名>/');
Snowflakeサービスプリンシパルの確認
作成したStorage Integrationの情報を取得します。
DESC STORAGE INTEGRATION ADF_AZURE_INT;
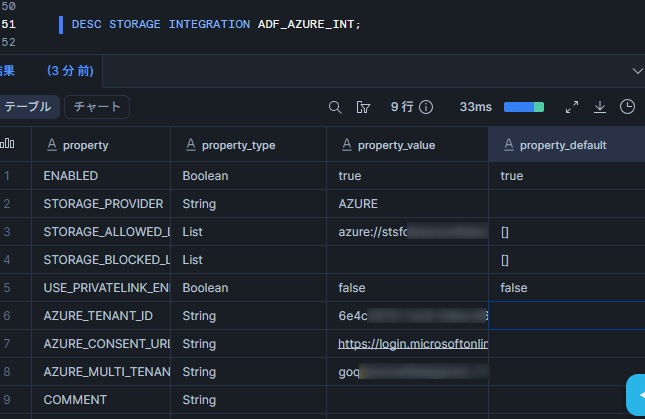
以下の値を控えておきます。
- AZURE_CONSENT_URL: Microsoft権限要求ページへのURL
- AZURE_MULTI_TENANT_APP_NAME: Snowflakeクライアントアプリケーション名
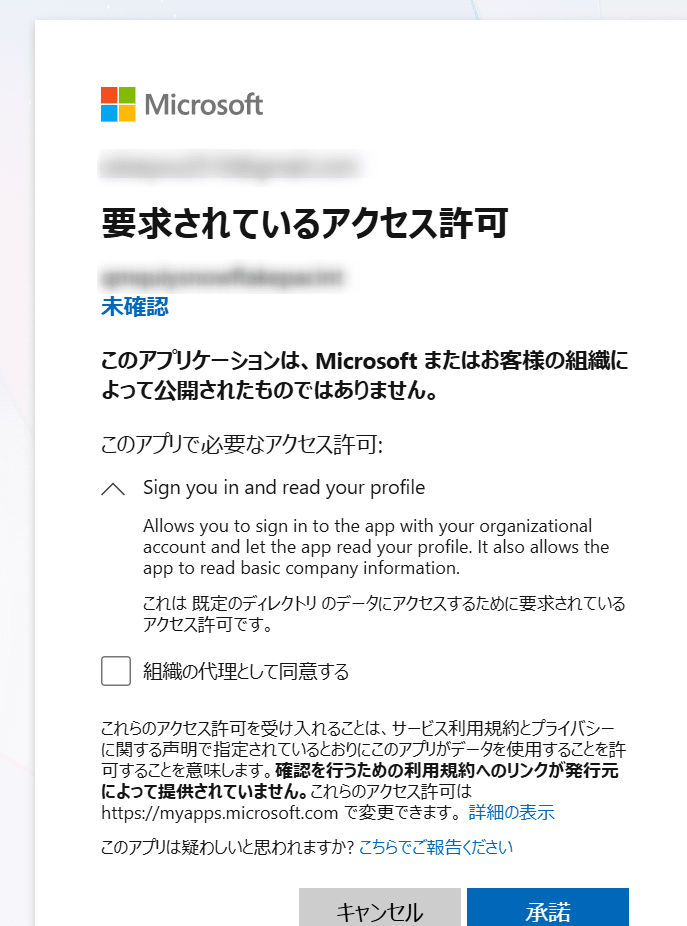
AZURE_CONSENT_URLにブラウザでアクセスし、AcceptをクリックしてSnowflakeサービスプリンシパルを承認します。
Azure Blob StorageのIAMロール付与
Azure Portalで対象のストレージアカウントを開き、アクセス制御 (IAM)→ロールの割り当ての追加を選択します。
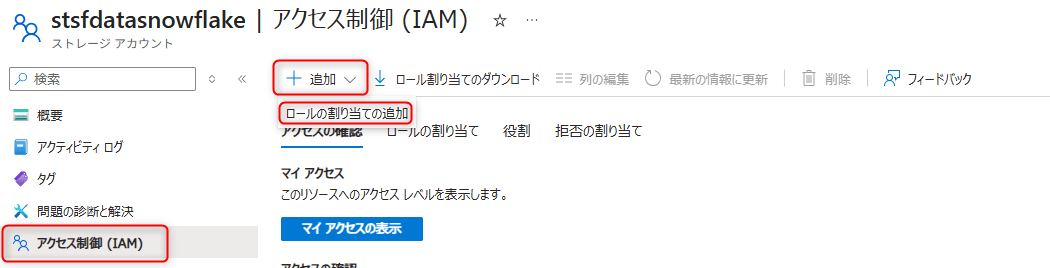
- ロールとして
Storage Blob Data Readerを選択 - メンバーの選択で、
AZURE_MULTI_TENANT_APP_NAMEのアンダースコア(_)より前の部分を検索し、Snowflakeサービスプリンシパルを選択 レビューと割り当てをクリック
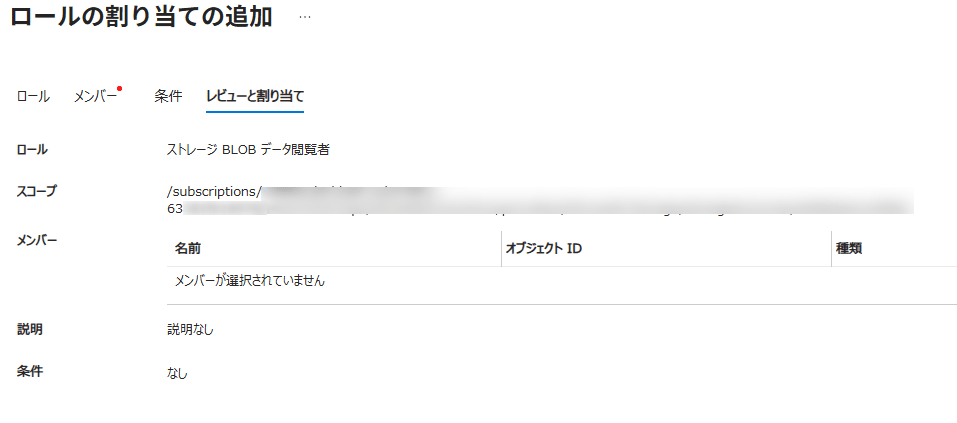
ADF実行ユーザーへのStorage Integration利用権限の付与
ADF実行用ロールにStorage IntegrationのUSAGE権限を付与します。
USE ROLE ACCOUNTADMIN;
GRANT USAGE ON INTEGRATION ADF_AZURE_INT TO ROLE ADF_ROLE;
Azure Blob StorageのLinked Serviceを作成
ADF Studioで、Blob Storageへの接続用Linked Serviceを作成します。
ADF Studioの左メニューからManage→Linked services→Newを選択します。
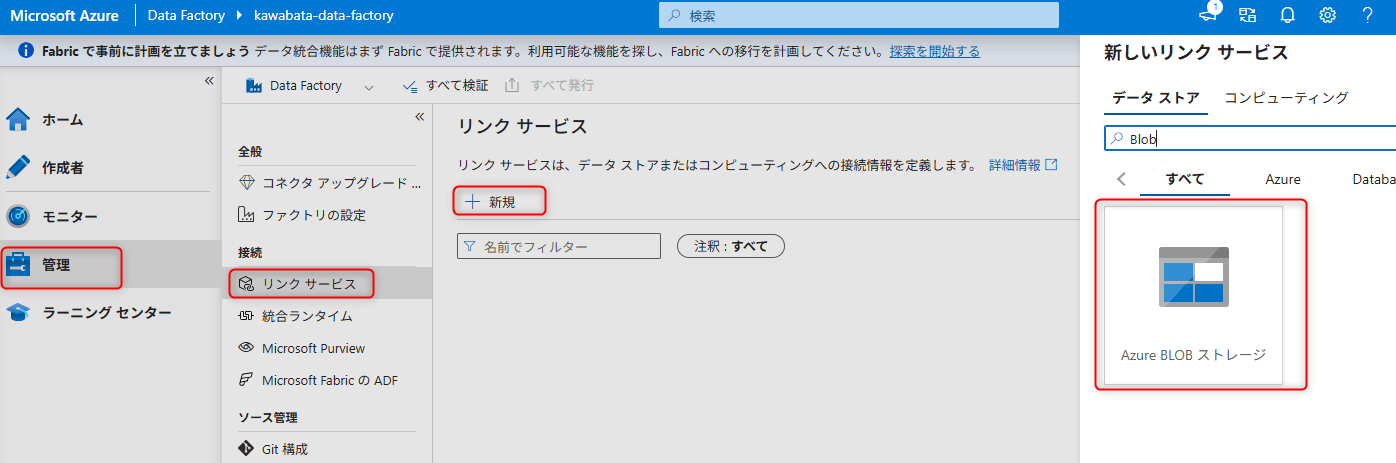
検索バーで「Blob」を検索し、Azure Blob Storageを選択してContinueをクリックします。
以下の情報を入力します。
- Name: 任意の名前
- Connect via integration runtime:
AutoResolveIntegrationRuntimeを選択 - Authentication method:
Account keyを選択 - Account selection method:
From Azure subscriptionを選択し、対象のサブスクリプションとストレージアカウントを選択
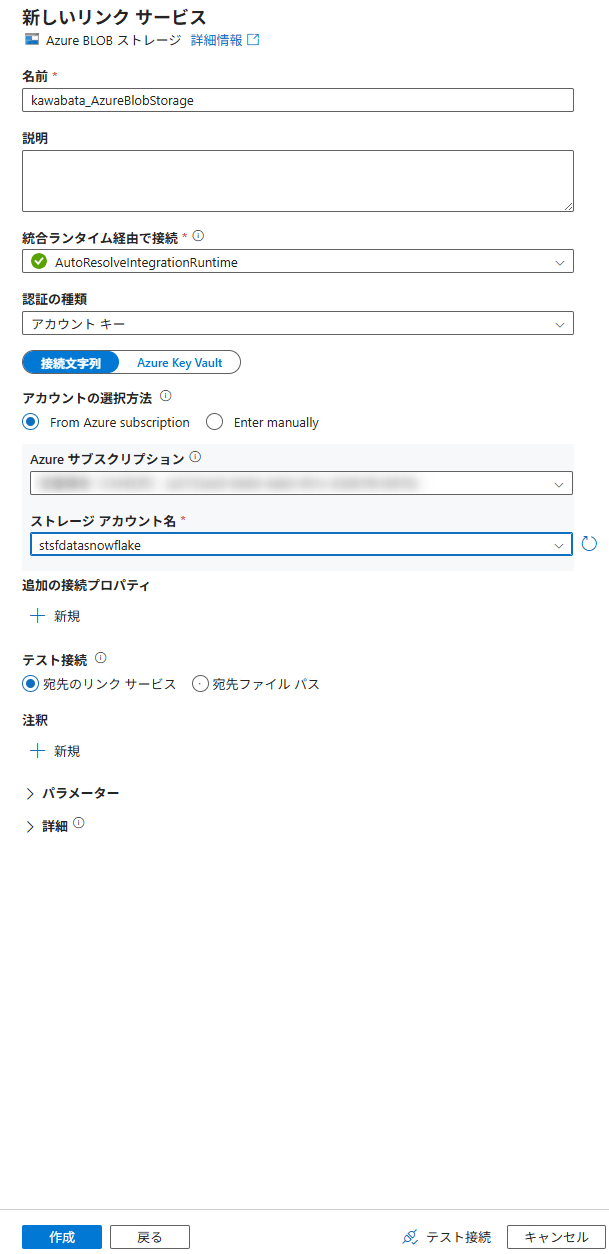
Test connectionをクリックし、「Connection successful」と表示されればOKです。
CreateをクリックしてLinked Serviceを作成します。

SnowflakeのLinked Serviceを作成
続いて、Snowflakeへの接続用Linked Serviceを作成します。
ADF Studioの左メニューからManage→Linked services→Newを選択します。
検索バーで「Snowflake」を検索し、Snowflakeコネクタを選択してContinueをクリックします。
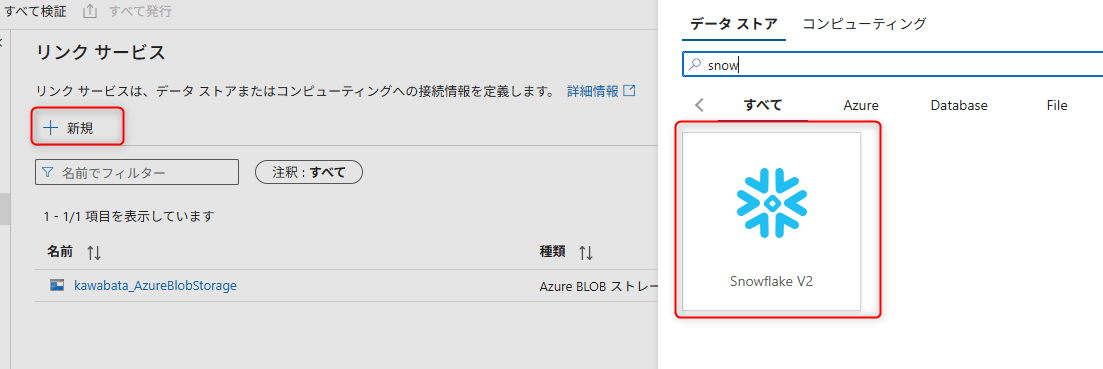
以下の情報を入力します。
- Name: 任意の名前
- Connect via integration runtime:
AutoResolveIntegrationRuntimeを選択 - Account identifier: Snowflakeのアカウント識別子
- Database:
ADF_DEMO_DB - Warehouse:
ADF_DEMO_WH(または既存のウェアハウス名) - Role:
ADF_ROLE - Authentication type:
Key Pair - User: Snowflakeのユーザー名
- Private key: Snowflakeユーザーに対応する秘密鍵
- Private key passphrase: 秘密鍵にパスフレーズを設定している場合のみ指定
Test connectionをクリックし、「Connection successful」と表示されればOKです。
CreateをクリックしてLinked Serviceを作成します。
ソースデータセット(CSV)の作成
Blob Storage上のCSVファイルを参照するデータセットを作成します。
ADF Studioの左メニューからAuthor→Datasetsの...メニュー→New datasetを選択します。
検索バーで「Blob」を検索し、Azure Blob Storageを選択してContinueをクリックします。
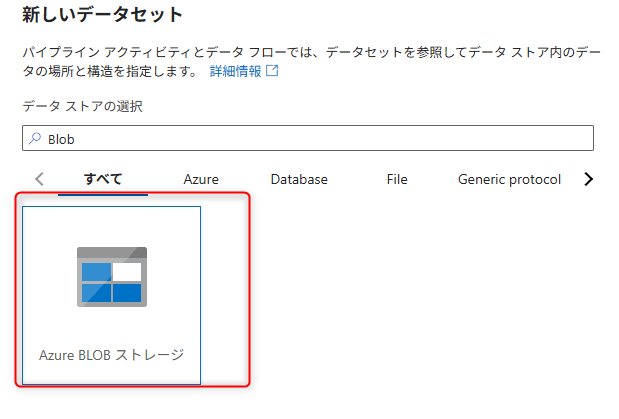
フォーマットの選択画面でDelimitedTextを選択してContinueをクリックします。

以下の情報を入力します。
- Name: 任意の名前
- Linked service: 先ほど作成したBlob StorageのLinked Service
- File path: コンテナー名(例:
adf-source)とファイル名(raw_customers.csv)を指定 - First row as header: チェックを入れる
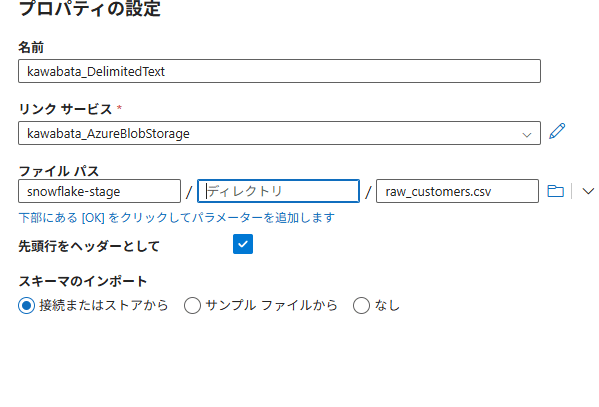
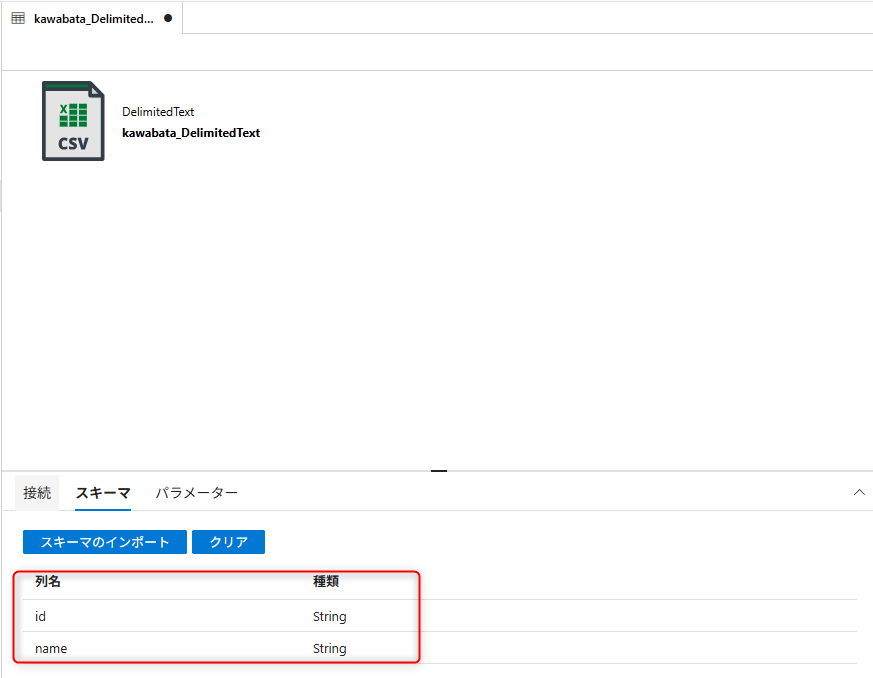
OKをクリックしてデータセットを作成します。
idとnameのカラムでデータが表示されていればOKです。
シンクデータセット(Snowflake)の作成
Snowflakeのテーブルを参照するデータセットを作成します。
ADF Studioの左メニューからAuthor→Datasetsの...メニュー→New datasetを選択します。
検索バーで「Snowflake」を検索し、Snowflakeを選択してContinueをクリックします。
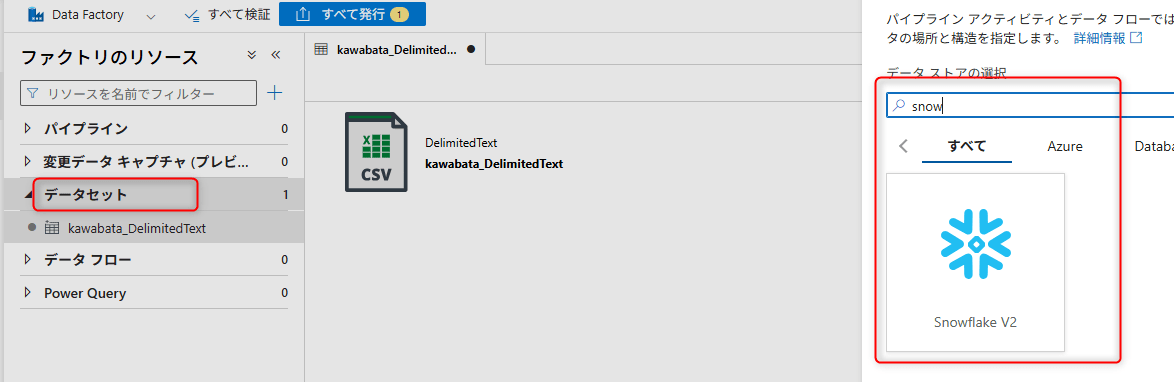
以下の情報を入力します。
- Name: 任意の名前
- Linked service: 先ほど作成したSnowflakeのLinked Service
- Schema:
RAW(ドロップダウンから選択) - Table name:
RAW_CUSTOMERS(ドロップダウンから選択)
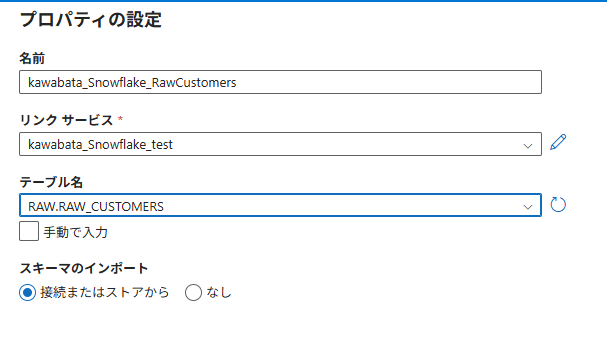
OKをクリックしてデータセットを作成します。
パイプラインとCopy Activityの作成
パイプラインを作成し、Copy Activityを構成します。
ADF Studioの左メニューからAuthor→Pipelinesの...メニュー→New pipelineを選択します。
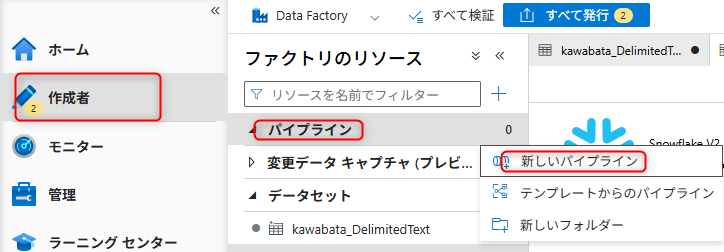
パイプラインに任意の名前を設定します。
Copy Activityの追加
アクティビティ一覧からMove & transform→Copy dataをパイプラインのキャンバスにドラッグ&ドロップします。
Copy Activityに任意の名前を設定します。
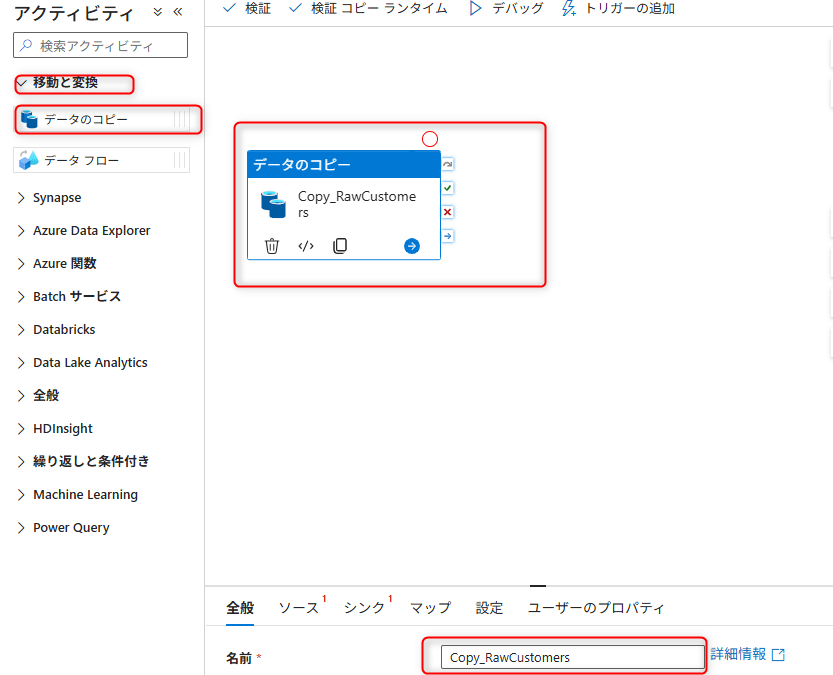
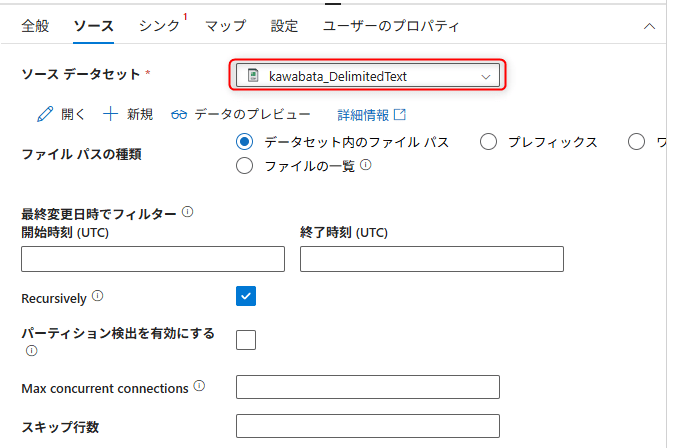
Sourceタブの設定
Sourceタブを選択し、以下を設定します。
- Source dataset: 先ほど作成したCSVデータセット
Sinkタブの設定
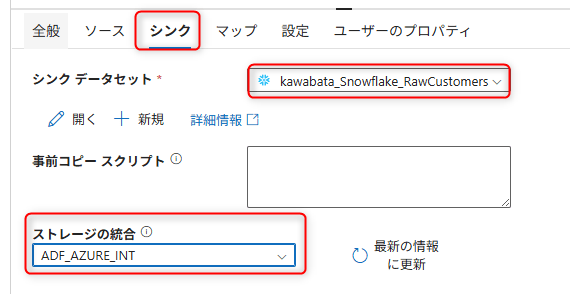
Sinkタブを選択し、以下を設定します。
- Sink dataset: 先ほど作成したSnowflakeデータセット
Import settingsのtypeは自動的にSnowflakeImportCopyCommandが設定されます。Storage integrationに、先ほど作成したStorage Integration名(ADF_AZURE_INT)を入力します。
Mappingタブの設定
Mappingタブを選択し、Import schemasをクリックします。
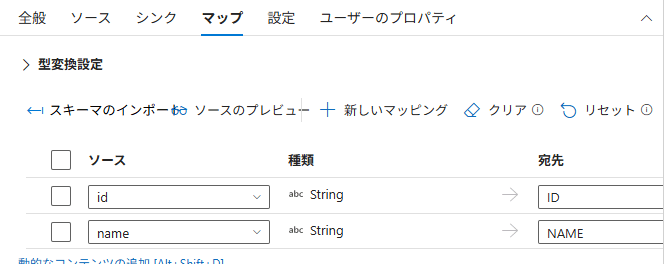
ソース(CSV)とシンク(Snowflake)のカラムマッピングが自動で設定されます。マッピングが正しいことを確認します。
id→IDname→NAME
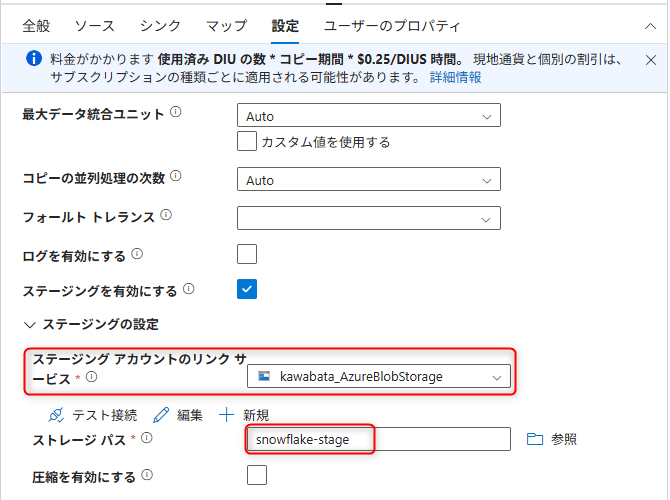
Settingsタブの設定(ステージングの有効化)
Settingsタブを選択し、ステージングを有効化します。
- Enable staging: チェックを入れる
- Staging account linked service: 先ほど作成したBlob StorageのLinked Service
- Storage Path: ステージング用のパスを指定
すべての設定が完了したら、パイプラインを保存します。
パイプラインの実行と確認
デバッグ実行
パイプラインのキャンバス上部のDebugをクリックして、パイプラインをデバッグ実行します。
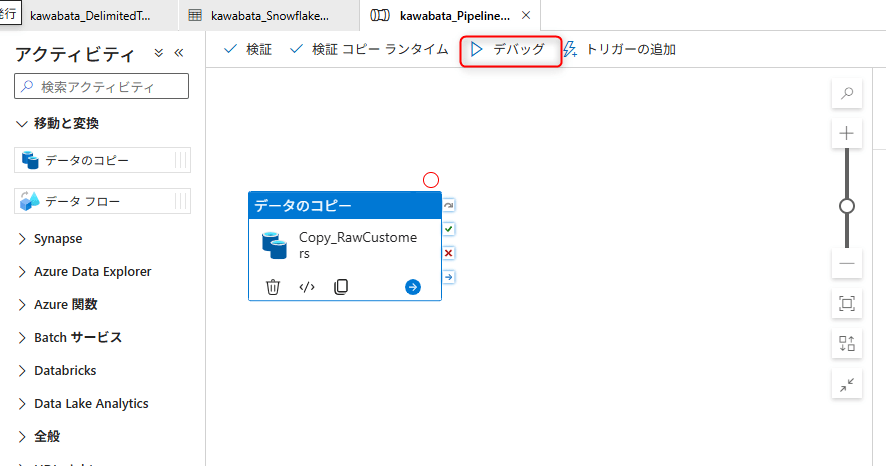
下部のOutputタブで実行状況を確認します。ステータスがSucceededと表示されればOKです。
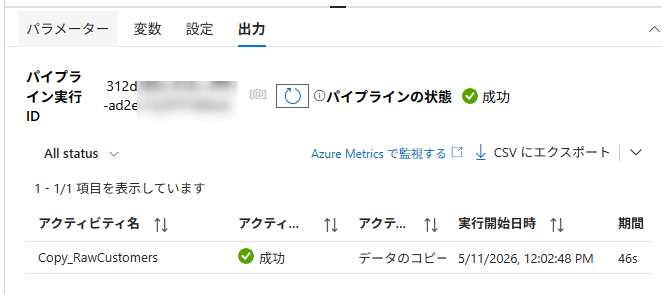
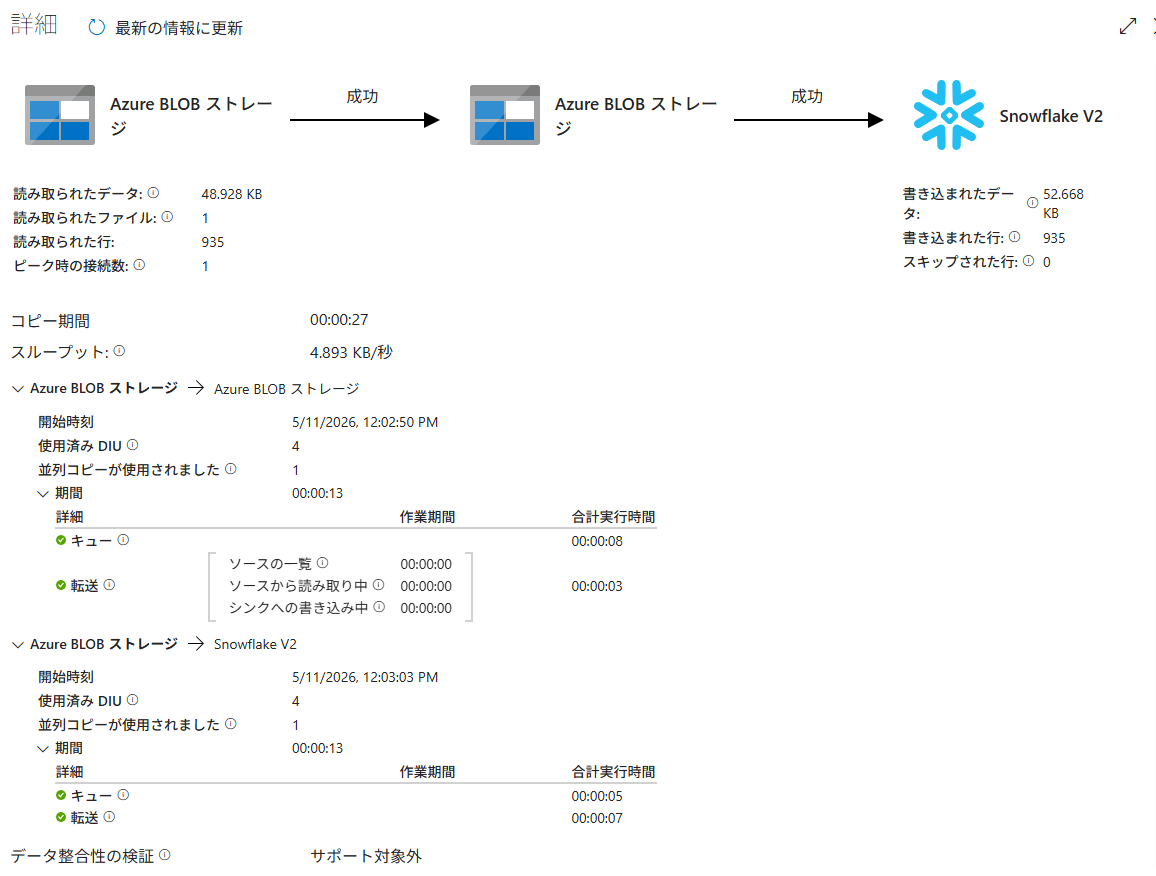
Copy Activityの実行結果をクリックすると、コピーされた行数やデータ転送量などの詳細を確認できます。
Snowflakeでデータを確認
Snowflake側でデータが正しくロードされたかを確認します。
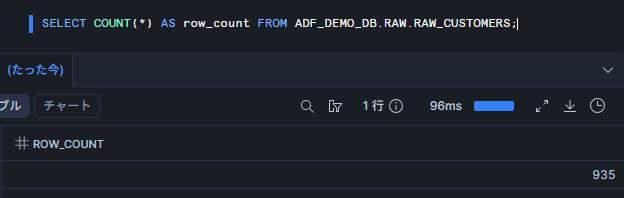
SELECT COUNT(*) AS row_count FROM ADF_DEMO_DB.RAW.RAW_CUSTOMERS;
raw_customers.csvは935件のデータ(ヘッダー行を除く)を含むため、row_countが935と表示されればOKです。
データの中身も確認してみます。
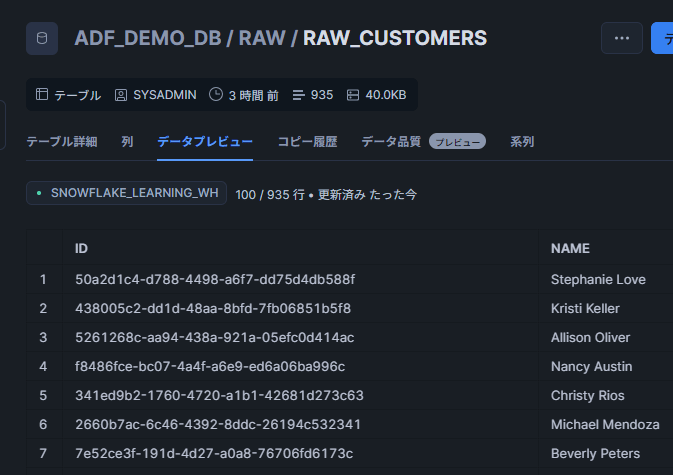
UUID形式のIDとNAMEカラムのデータが表示されていればOKです。
最後に
Azure Data FactoryのCopy Activityを使用して、Blob Storage内のCSVファイルをSnowflakeにロードするパイプラインのセットアップ手順をまとめました。
ポイントをまとめると以下の通りです。
- ADFのSnowflakeコネクタはV2(SnowflakeV2)を使用します(V1はRemoved)
- Snowflake Storage Integrationを作成し、Copy Activityの
Sink→Import settingsのstorageIntegrationに指定します - Copy Activityの
Settingsでステージングを有効化し、Storage Integrationで参照したBlob Storageをステージング先として指定します - Azure Integration RuntimeでStorage Integrationを使用する場合、Blob Storage Linked Serviceは
Account keyを含む任意の認証方式を利用できます - ADF実行ユーザーには
CREATE STAGE権限やStorage IntegrationのUSAGE権限が必要です - 本番環境ではKey Pair認証やAzure Key Vaultを活用したシークレット管理を検討してください
今回はManaged Virtual Networkが有効なADFを使用しており、Managed Private Endpoint / Azure Private Linkを使用する場合もCopy Activityの基本的な設定手順は同様です。ただし、Private Link固有の設定(Snowflake側のPrivate Link有効化、Private Endpointの承認、DNS設定等)は別途構成が必要です。
この記事が何かの参考になれば幸いです!








