
SnowflakeのデータをDatabricks Lakeflow ConnectのQuery-based ingestionで取り込む手順を試してみた
かわばたです。
SnowflakeからDatabricksへデータを定期的に取り込みたいというニーズに対して、Databricks Lakeflow ConnectのQuery-based ingestionを使うことで、カスタムETLパイプラインを構築せずに差分取り込みを実現できないか試してみました。
手順と確認結果をまとめます。
背景・課題
SnowflakeにあるデータをDatabricks側に取り込み、Lakehouse上のテーブルとして利用したいケースがあります。たとえば以下のような状況です。
- SnowflakeのマスタデータをDatabricksの分析基盤に取り込みたい
- Snowflake側で更新されたデータを定期的にDatabricks側に反映したい
- できるだけカスタムETLやサードパーティツールに依存せず、Databricksの機能で完結させたい
こうしたケースでは、差分取り込み(incremental ingestion)の仕組みが必要になります。自前でETLパイプラインを構築・運用するのは開発・保守コストがかかるため、Databricksの標準機能で実現できないか検討しました。
技術的アプローチ
今回はDatabricks Lakeflow ConnectのQuery-based ingestionを使って、SnowflakeからDatabricksへの差分データ取り込みを検証します。
Query-based ingestionは、ソースデータベースに対して直接クエリを実行し、updated_atのような**cursor column(カーソル列)**を基準に前回実行時より新しい行を取り込む方式です。
今回の全体構成は以下のとおりです。
制限事項
2026年5月25日時点での制限事項です。
- Query-based ingestionはPublic Previewの機能です。GAまでに仕様が変わる可能性があります
- cursor columnは単一列のみ指定可能です。composite cursor(複数列の組み合わせ)はサポートされていません
- cursor columnの値は単調増加する必要があります。timestamp/date型、数値型、バイナリ型、文字列型に対応しています
- cursor columnがNULLの行は取り込まれません
- continuous ingestion(継続的な取り込み)には対応していません。スケジュール実行でソースをクエリする方式です。低レイテンシが必要な場合はmanaged CDC database connectorの利用を検討してください
- 以下の機能はAPI経由でのみ利用可能です(UIからは設定できません)
- 行フィルタリング
- ソフト削除トラッキング
- ハード削除トラッキング(Beta)
- APPEND_ONLYモード
- マルチ宛先カタログ・スキーマ
コスト
- Databricks側: サーバレスパイプラインのDBUが発生します。2026年5月25日時点では公式ドキュメントにQuery-based ingestion固有のコストに関する詳細な記載はありませんでした
- Snowflake側: パイプライン実行時にはSnowflake側でクエリが実行されるため、warehouseが起動または稼働し、Snowflake側のクレジットが発生します。スケジュール間隔を短くしすぎるとコストが増加する点にご注意ください
事前準備
Snowflake側のユーザー・ロール・権限の準備
まずSnowflake側で、Databricksから読み取り専用でアクセスするためのユーザーとロールを作成します。
USE ROLE ACCOUNTADMIN;
-- Databricks接続用ロールの作成
CREATE ROLE IF NOT EXISTS DATABRICKS_READ_ROLE;
-- Databricks接続用ユーザーの作成(パスワード認証の場合。検証用途)
CREATE USER IF NOT EXISTS DATABRICKS_USER
PASSWORD = '<STRONG_PASSWORD>'
DEFAULT_ROLE = DATABRICKS_READ_ROLE
DEFAULT_WAREHOUSE = <SNOWFLAKE_WAREHOUSE_NAME>
MUST_CHANGE_PASSWORD = FALSE;
GRANT ROLE DATABRICKS_READ_ROLE TO USER DATABRICKS_USER;
-- Warehouse使用権限の付与
GRANT USAGE ON WAREHOUSE <SNOWFLAKE_WAREHOUSE_NAME>
TO ROLE DATABRICKS_READ_ROLE;
-- Database / Schema / Table の読み取り権限の付与
GRANT USAGE ON DATABASE <SNOWFLAKE_DATABASE_NAME>
TO ROLE DATABRICKS_READ_ROLE;
GRANT USAGE ON SCHEMA <SNOWFLAKE_DATABASE_NAME>.<SNOWFLAKE_SCHEMA_NAME>
TO ROLE DATABRICKS_READ_ROLE;
GRANT SELECT ON ALL TABLES IN SCHEMA <SNOWFLAKE_DATABASE_NAME>.<SNOWFLAKE_SCHEMA_NAME>
TO ROLE DATABRICKS_READ_ROLE;
GRANT SELECT ON FUTURE TABLES IN SCHEMA <SNOWFLAKE_DATABASE_NAME>.<SNOWFLAKE_SCHEMA_NAME>
TO ROLE DATABRICKS_READ_ROLE;
PEM private key認証を使う場合は、PASSWORDの代わりにRSA_PUBLIC_KEYを設定します。
-- Databricks接続用ユーザーの作成(PEM private key認証、本番向け)
CREATE USER IF NOT EXISTS DATABRICKS_USER
TYPE = SERVICE
RSA_PUBLIC_KEY = '<PUBLIC_KEY_WITHOUT_HEADER_FOOTER>'
DEFAULT_ROLE = DATABRICKS_READ_ROLE
DEFAULT_WAREHOUSE = <SNOWFLAKE_WAREHOUSE_NAME>;
Databricks Secretsの準備
Snowflakeの認証情報はSQLに平文で書かず、Databricks Secretsに保存します。
Databricks Secretsの管理にはDatabricks CLI、Secrets API、SDKを利用できます。
本記事ではDatabricks CLIを使用します。
# Secret Scopeの作成
databricks secrets create-scope snowflake-prod
# ユーザー名の保存
databricks secrets put-secret snowflake-prod sf-user
先ほど作成したユーザー名を入力

# パスワードの保存
databricks secrets put-secret snowflake-prod sf-password
Secret ScopeとSecret keyが作成されていることを確認できました。

PEM private keyを使う場合は以下も保存します。
databricks secrets put-secret snowflake-prod sf-pem-private-key
Snowflake Connectionの作成
Databricks側でSnowflakeへのConnectionを作成します。
UIで作成する場合
- Databricks Workspaceを開く
- 左メニューから
Catalogを開く - 画面上部の
Addアイコンをクリック Create a connectionを選択
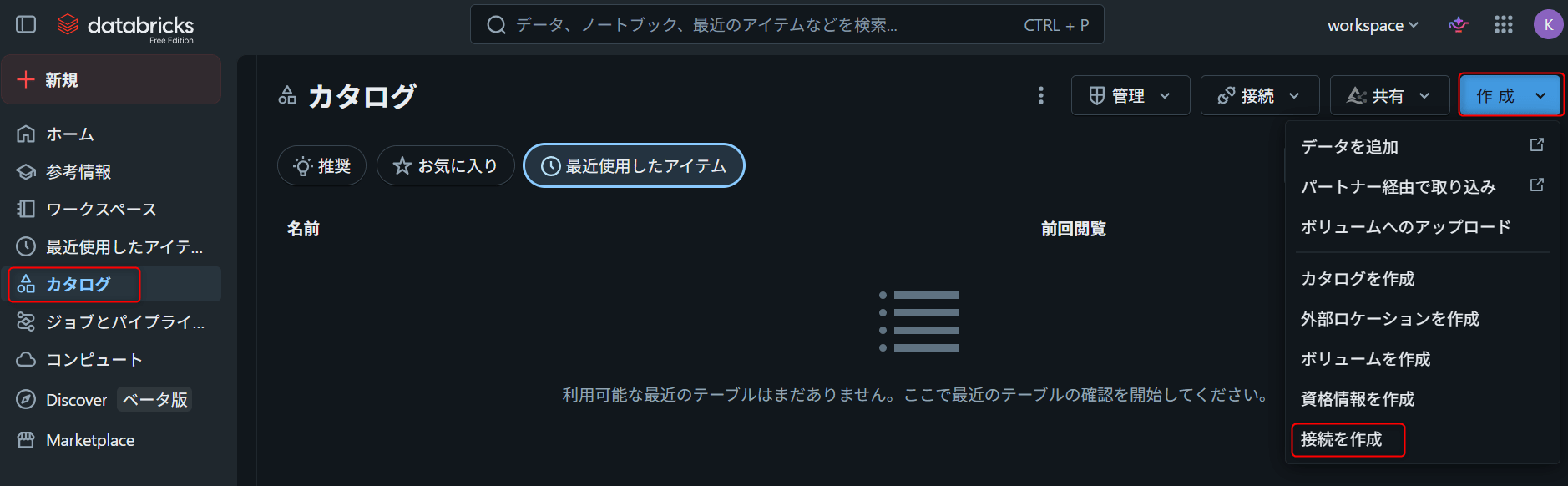
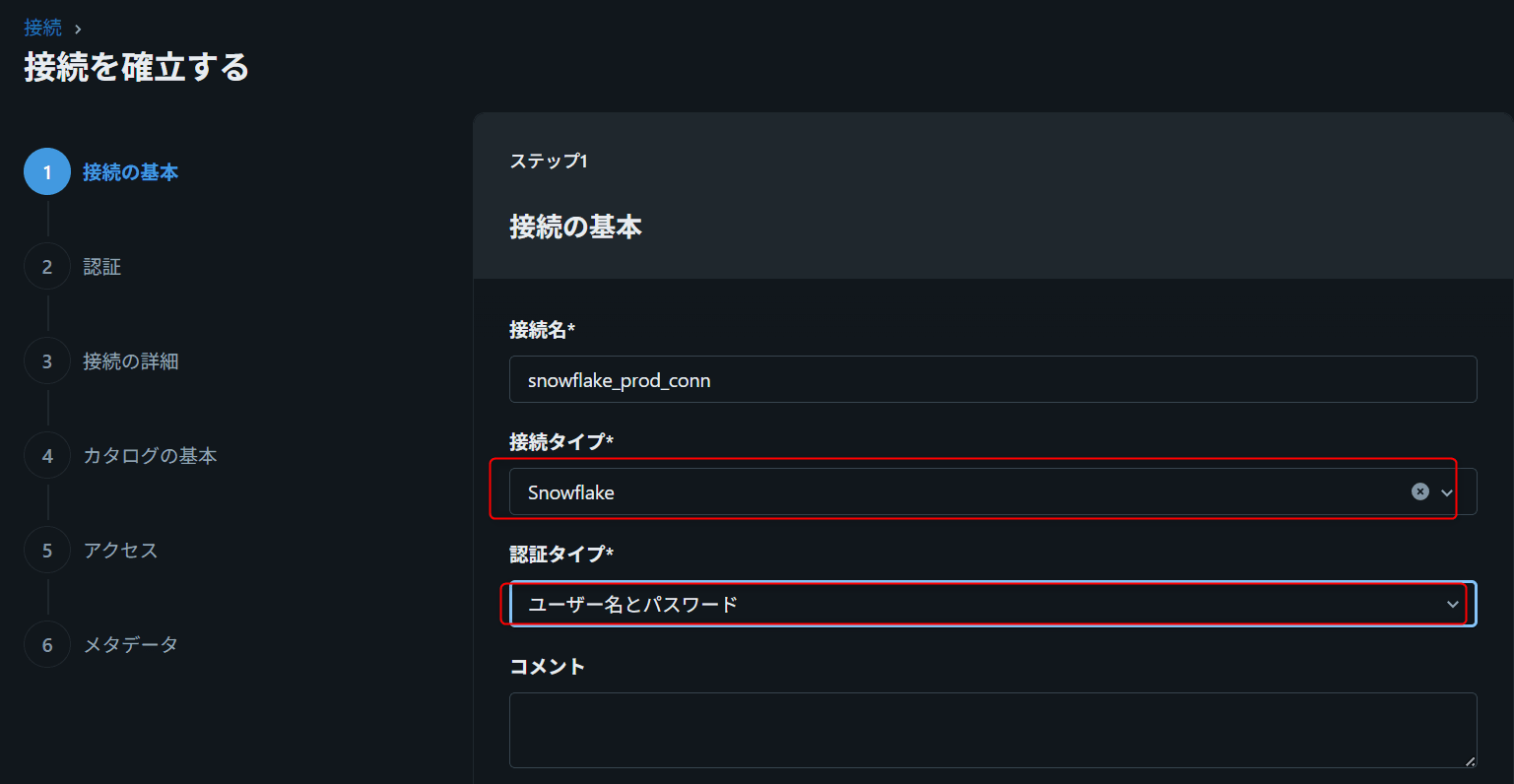
5. Connection nameを入力(例: snowflake_prod_conn)
6. Connection typeでSnowflakeを選択
7. 認証方式を選択(Username and passwordまたはPEM private key)
8. 接続情報を入力
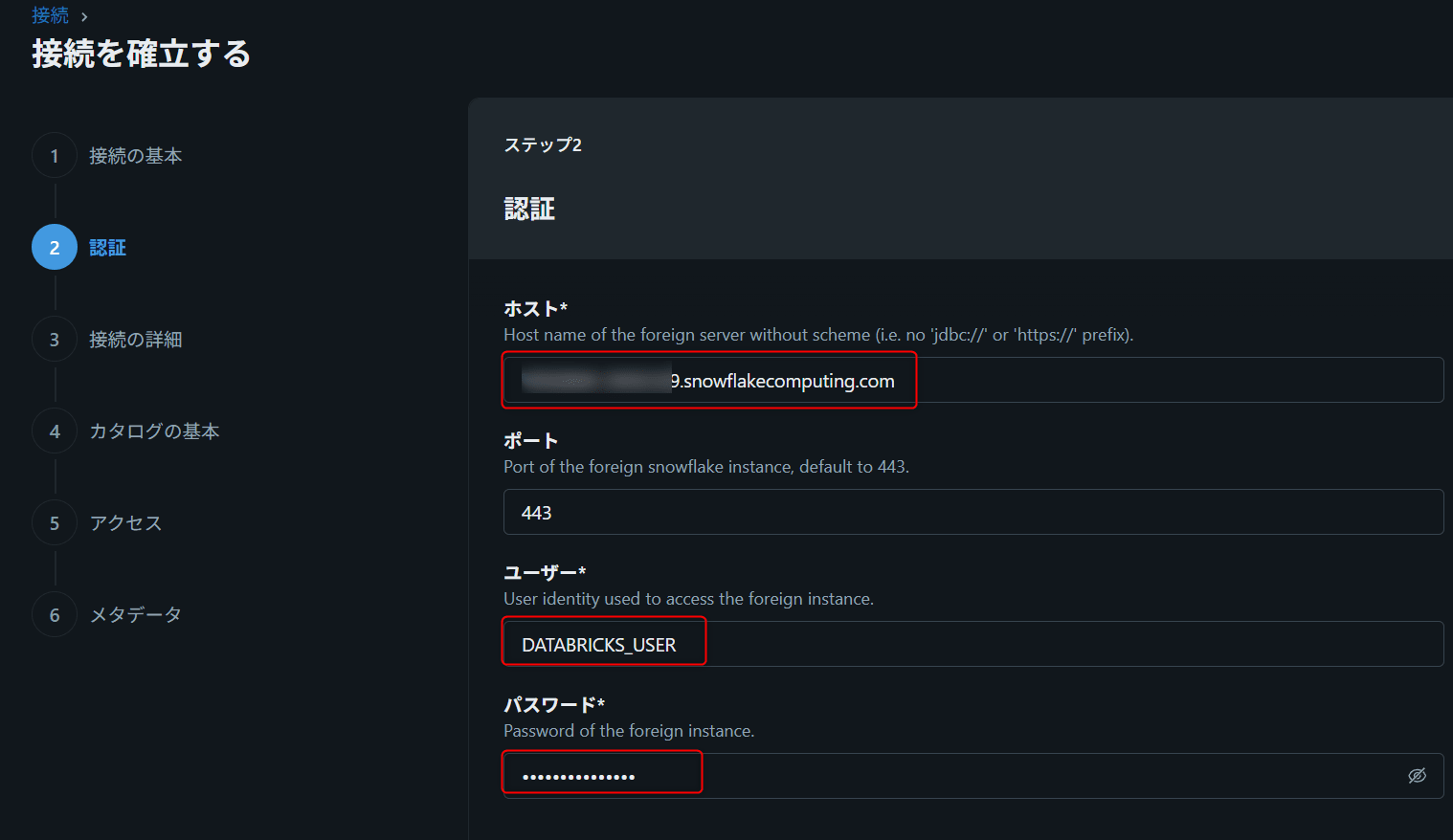
| 項目 | 入力例 |
|---|---|
| Host | <account_identifier>.snowflakecomputing.com |
| Port | 443 |
| User | DATABRICKS_USER |
| Password | Databricks Secretに保存した値 |
| Snowflake warehouse | <SNOWFLAKE_WAREHOUSE_NAME> |
| Snowflake role | DATABRICKS_READ_ROLE |
Test connectionをクリック
接続テストが成功すればOKです。
SQLで作成する場合: Username / Password(クリックで展開)
Databricks SQL EditorまたはNotebookで実行します。
CREATE CONNECTION snowflake_prod_conn TYPE snowflake
OPTIONS (
host '<account_identifier>.snowflakecomputing.com',
port '443',
sfWarehouse '<SNOWFLAKE_WAREHOUSE_NAME>',
user secret ('snowflake-prod', 'sf-user'),
password secret ('snowflake-prod', 'sf-password'),
sfRole 'DATABRICKS_READ_ROLE'
);
SQLで作成する場合: PEM private key(クリックで展開)
CREATE CONNECTION snowflake_prod_conn TYPE snowflake
OPTIONS (
host '<account_identifier>.snowflakecomputing.com',
port '443',
sfWarehouse '<SNOWFLAKE_WAREHOUSE_NAME>',
user secret ('snowflake-prod', 'sf-user'),
pem_private_key secret ('snowflake-prod', 'sf-pem-private-key'),
expires_in_secs '3600',
sfRole 'DATABRICKS_READ_ROLE'
);
PEM private keyを使う場合、Snowflake JDBCドライバーは暗号化された秘密鍵での認証に対応していないため、-nocryptオプション付きで鍵を生成する必要があります。
Foreign Catalogの作成
次に、SnowflakeのdatabaseをDatabricks Unity Catalog上のForeign Catalogとして登録します。
UIで作成する場合
Connection作成ウィザードの後続画面でForeign Catalogを作成できます。
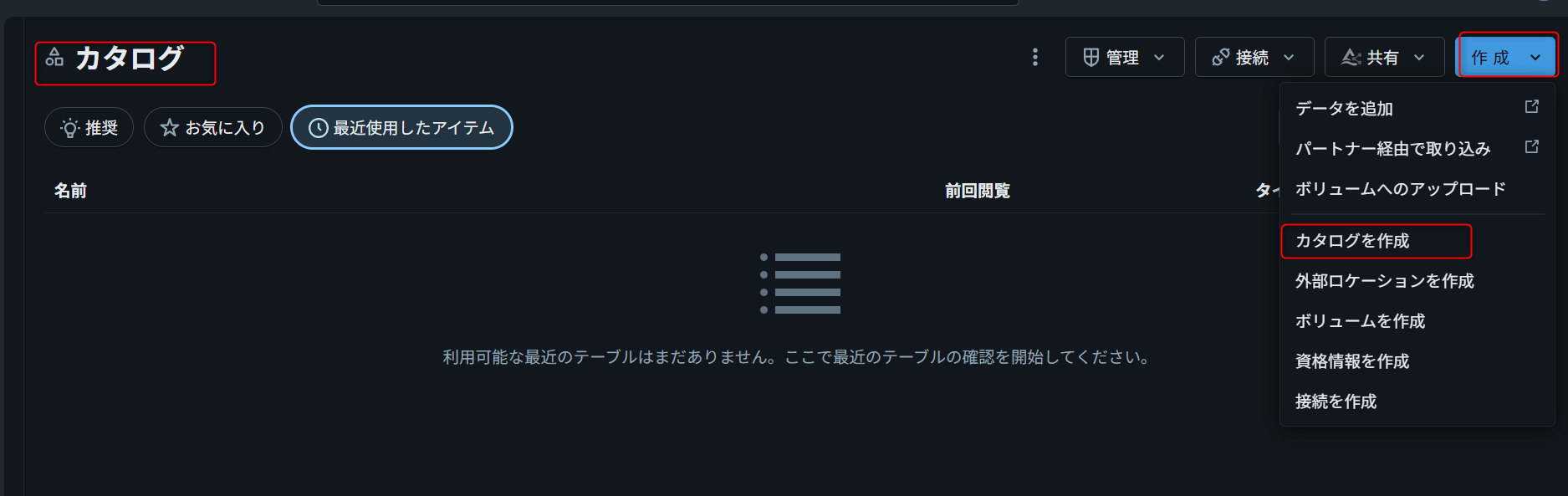
| 項目 | 入力例 |
|---|---|
| Catalog name | sf_prod |
| Connection | snowflake_prod_conn |
| Database | <SNOWFLAKE_DATABASE_NAME> |
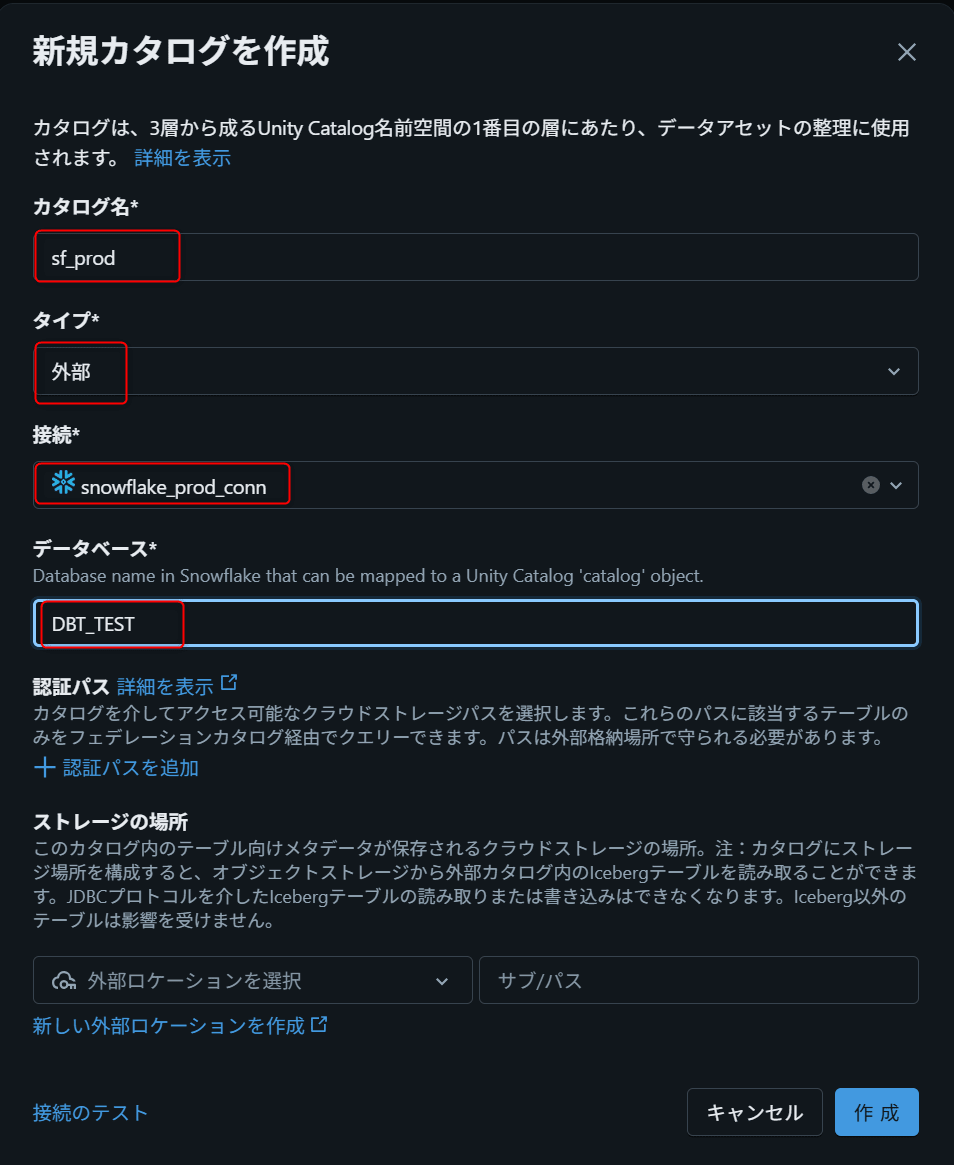
SQLで作成する場合
CREATE FOREIGN CATALOG sf_prod
USING CONNECTION snowflake_prod_conn
OPTIONS (
database = '<SNOWFLAKE_DATABASE_NAME>'
);
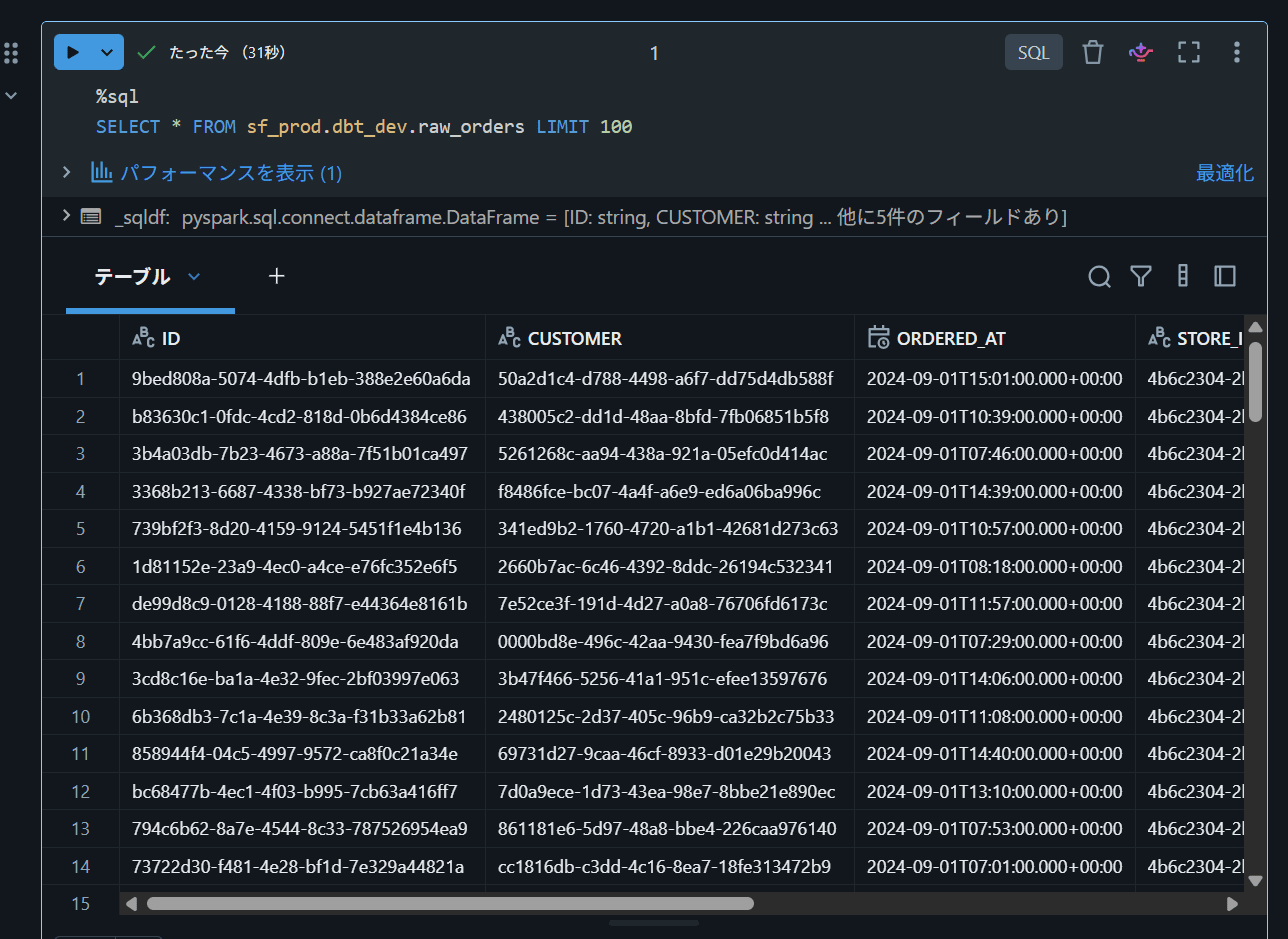
作成後、Databricks上では以下のように参照できます。
SELECT * FROM sf_prod.<snowflake_schema_name>.<snowflake_table_name>
Snowflake上のデータをDatabricksで参照することができました。
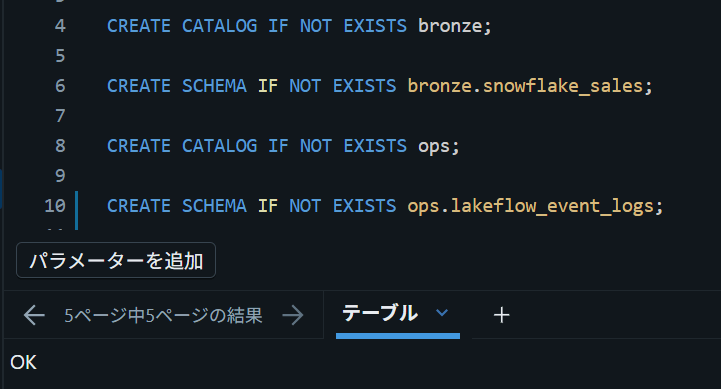
取り込み先catalog/schemaの作成
Databricks側で取り込み先を用意します。
CREATE CATALOG IF NOT EXISTS bronze;
CREATE SCHEMA IF NOT EXISTS bronze.snowflake_sales;
イベントログ用のschemaも作成しておきます。
CREATE CATALOG IF NOT EXISTS ops;
CREATE SCHEMA IF NOT EXISTS ops.lakeflow_event_logs;
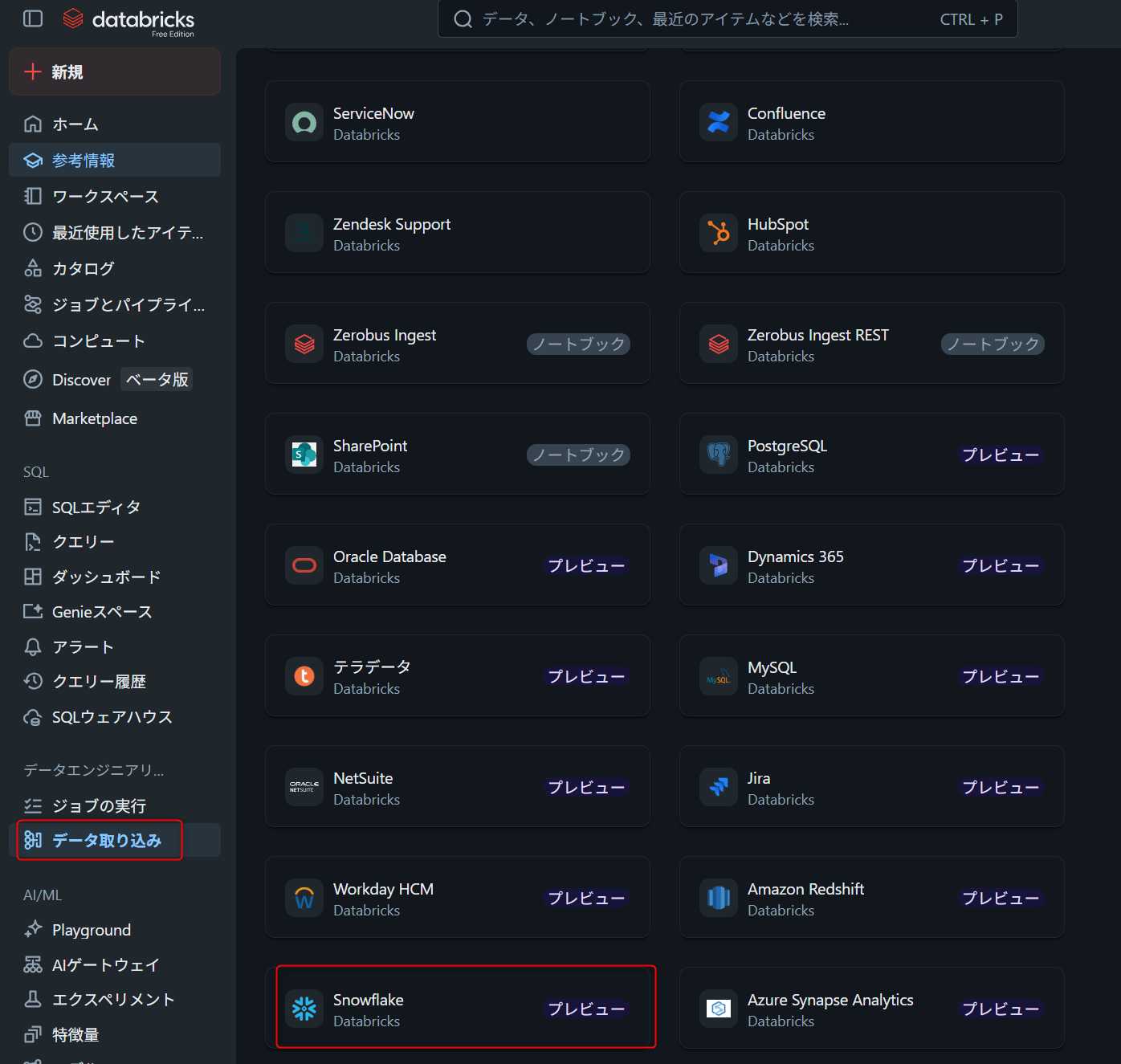
試してみた
Data Ingestionからパイプラインを作成する
Databricks Workspaceの左メニューからData Ingestionを開き、Add data画面でSnowflakeを選択します。
パイプライン名を入力します。
ingest_snowflake_sales_prod
イベントログの場所で、事前に作成したcatalog/schemaを選択します。
| 項目 | 値 |
|---|---|
| catalog | ops |
| schema | lakeflow_event_logs |
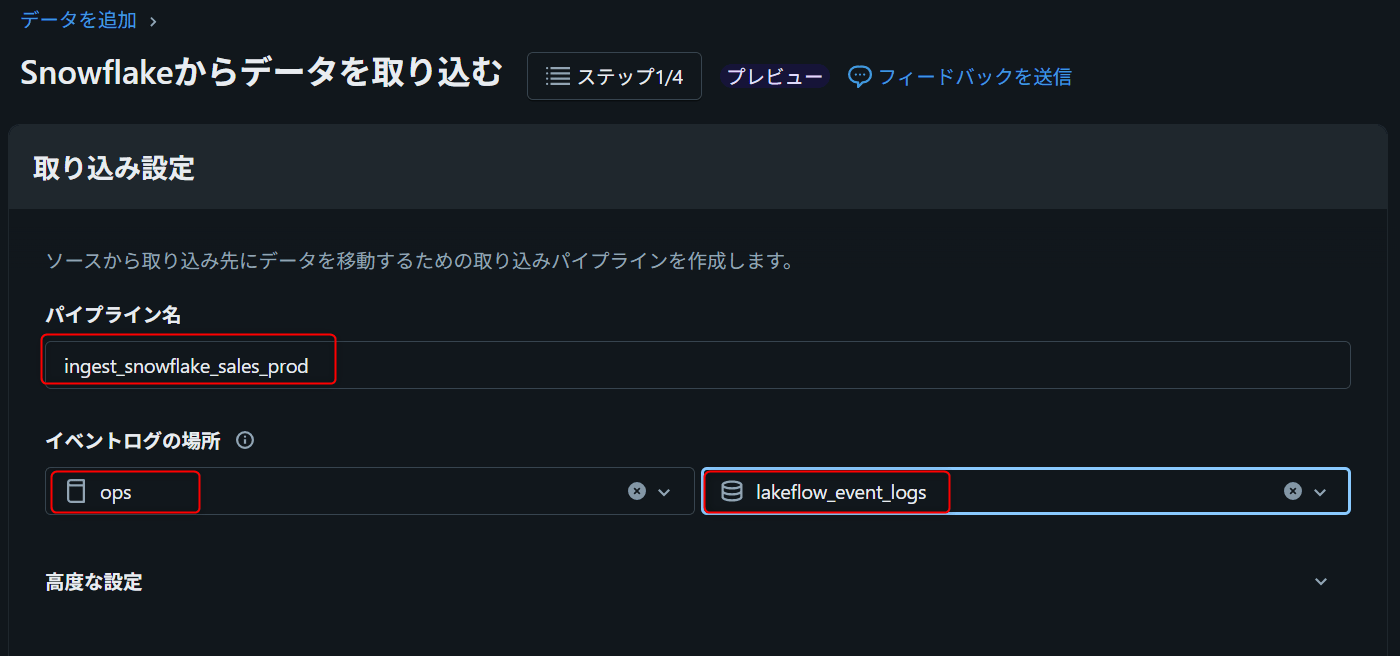
Connection typeとForeign Catalogを選択する
次の画面で以下を設定します。
| 項目 | 設定値 |
|---|---|
| Connection type | Foreign catalog |
| Foreign catalog | sf_prod |
| Destination catalog | bronze |
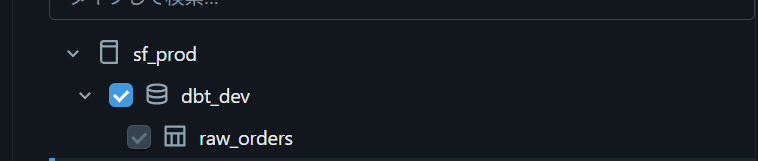
取り込み対象のschema/tableを選択する
Sourceページで、Snowflake側のschema/tableを選択します。
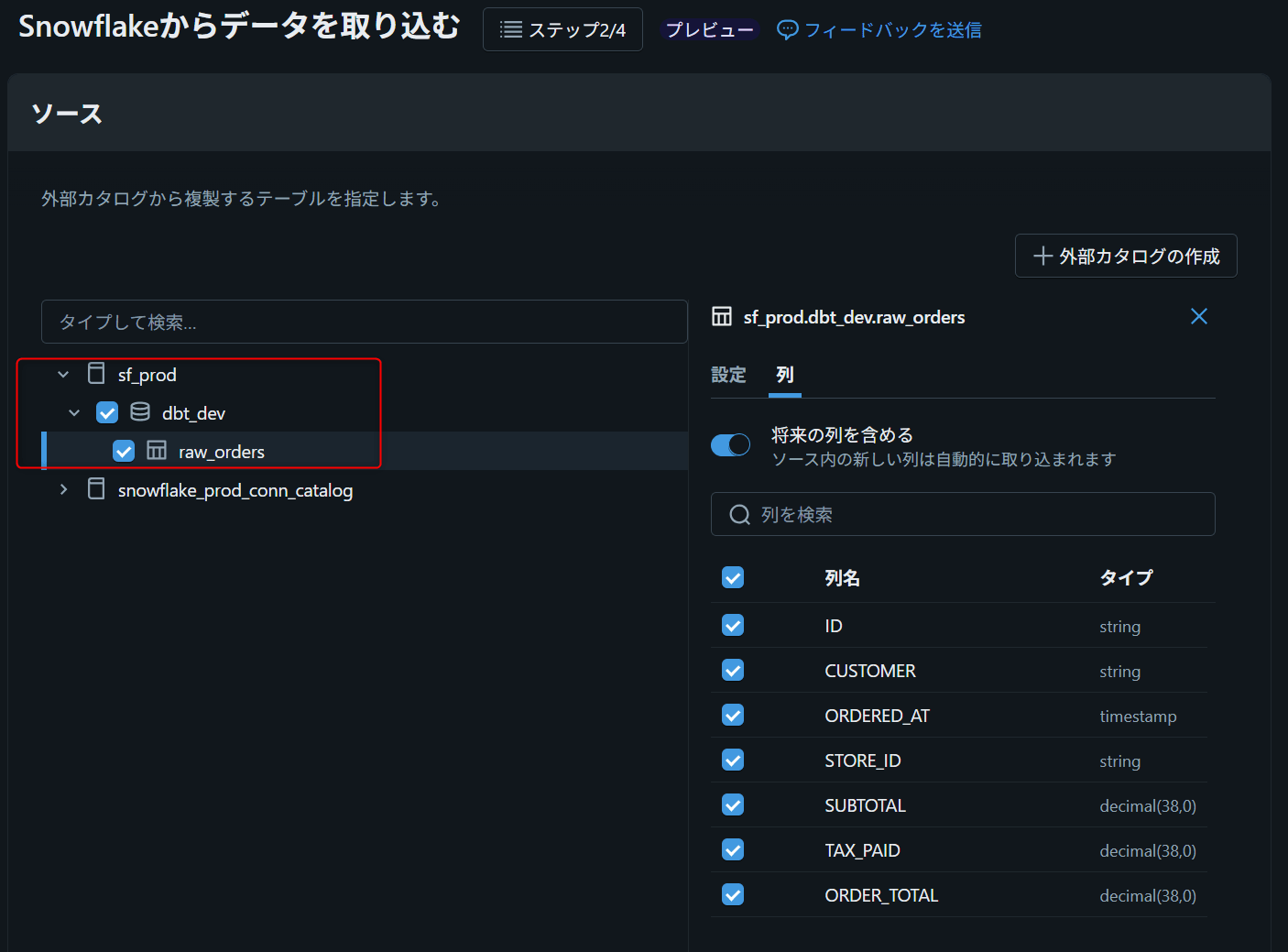
cursor columnとprimary keyを設定する
各テーブルに対してcursor columnを指定します。cursor columnは差分取り込みの基準となる列で、値が単調増加する必要があります。
| テーブル | cursor column |
|---|---|
| raw_orders | UPDATED_AT |
cursor columnの選び方
良い例:
updated_at、last_modified_at、modified_timestamp— 更新があるテーブルに最適created_at、id、row_id— append-only(追記のみ)のテーブルなら使えます
避けるべき例:
status、category、customer_id— 単調増加しない列は使えませんcreated_at— 更新があるテーブルでは使わないでください。既存レコードの更新を検知できません
履歴追跡を選択する
用途に応じて履歴追跡モードを選択します。
下記ドキュメントより、SCD_TYPE_2の履歴追跡の設定が可能です。
【SCD_TYPE_2について】
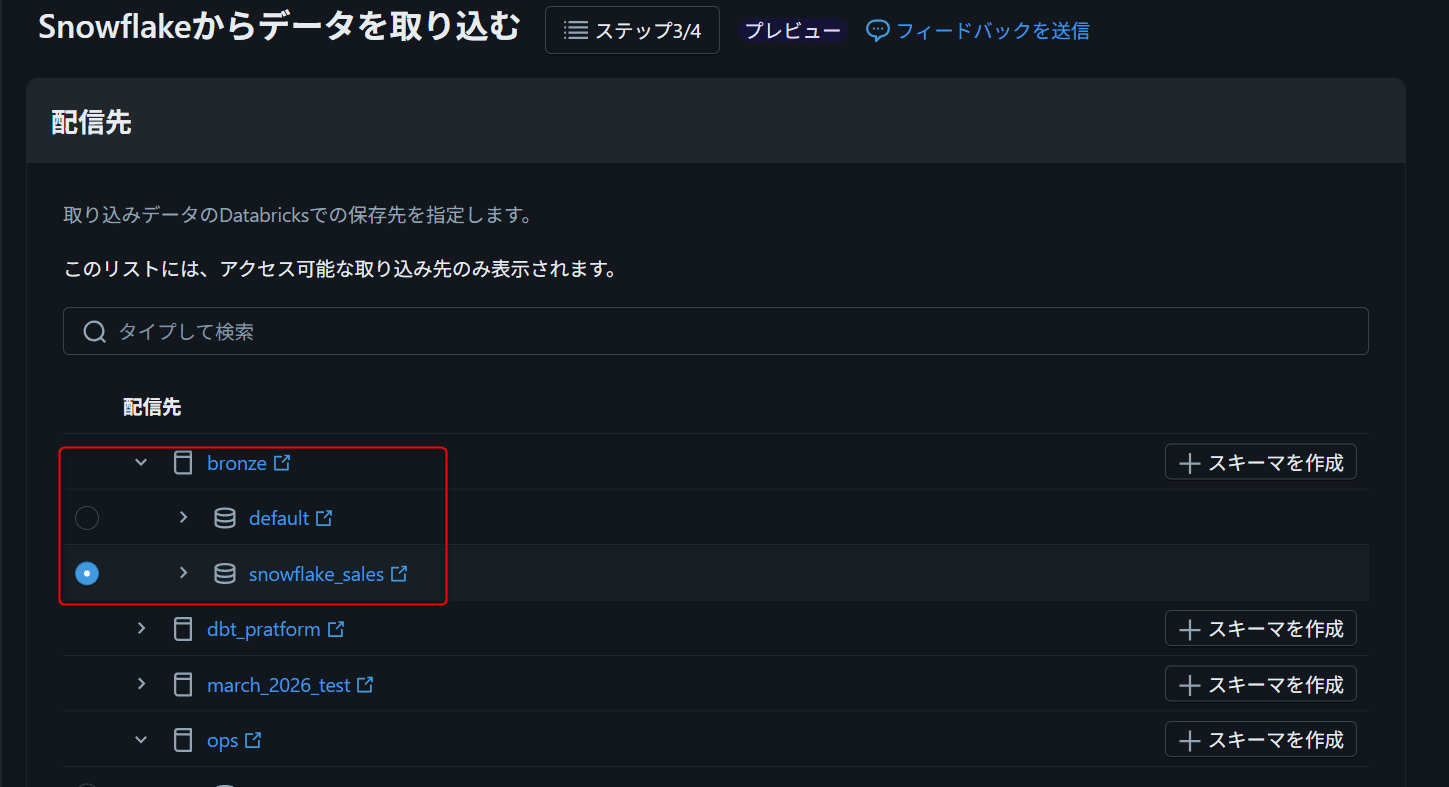
取り込み先を設定する
Destinationページで、Databricks側の取り込み先を指定します。宛先テーブル名を明示的に変更しない場合、ソーステーブル名がそのまま使われます。今回はソーステーブル名と同じraw_ordersとして作成される構成にしています。
| 項目 | 値 |
|---|---|
| Destination catalog | bronze |
| Destination schema | snowflake_sales |
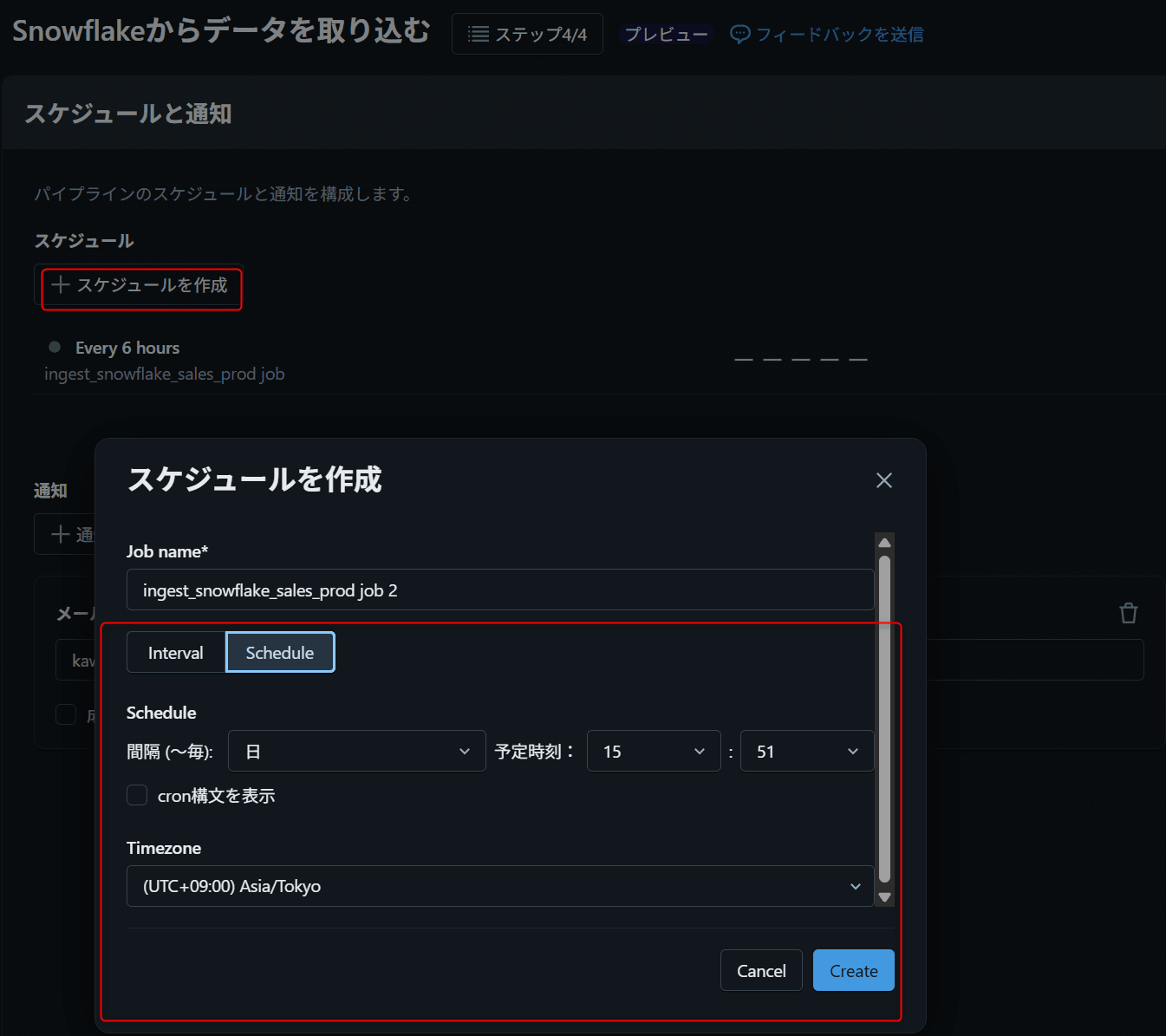
スケジュールと通知を設定する
Settingsページでスケジュールを設定します。
最初は手動実行から始め、問題なければ1時間ごとに設定するのが安全です。
通知設定では、本番運用では失敗時の通知を必ず設定することを推奨します。
パイプラインを保存・実行する
Save and run pipelineをクリックします。
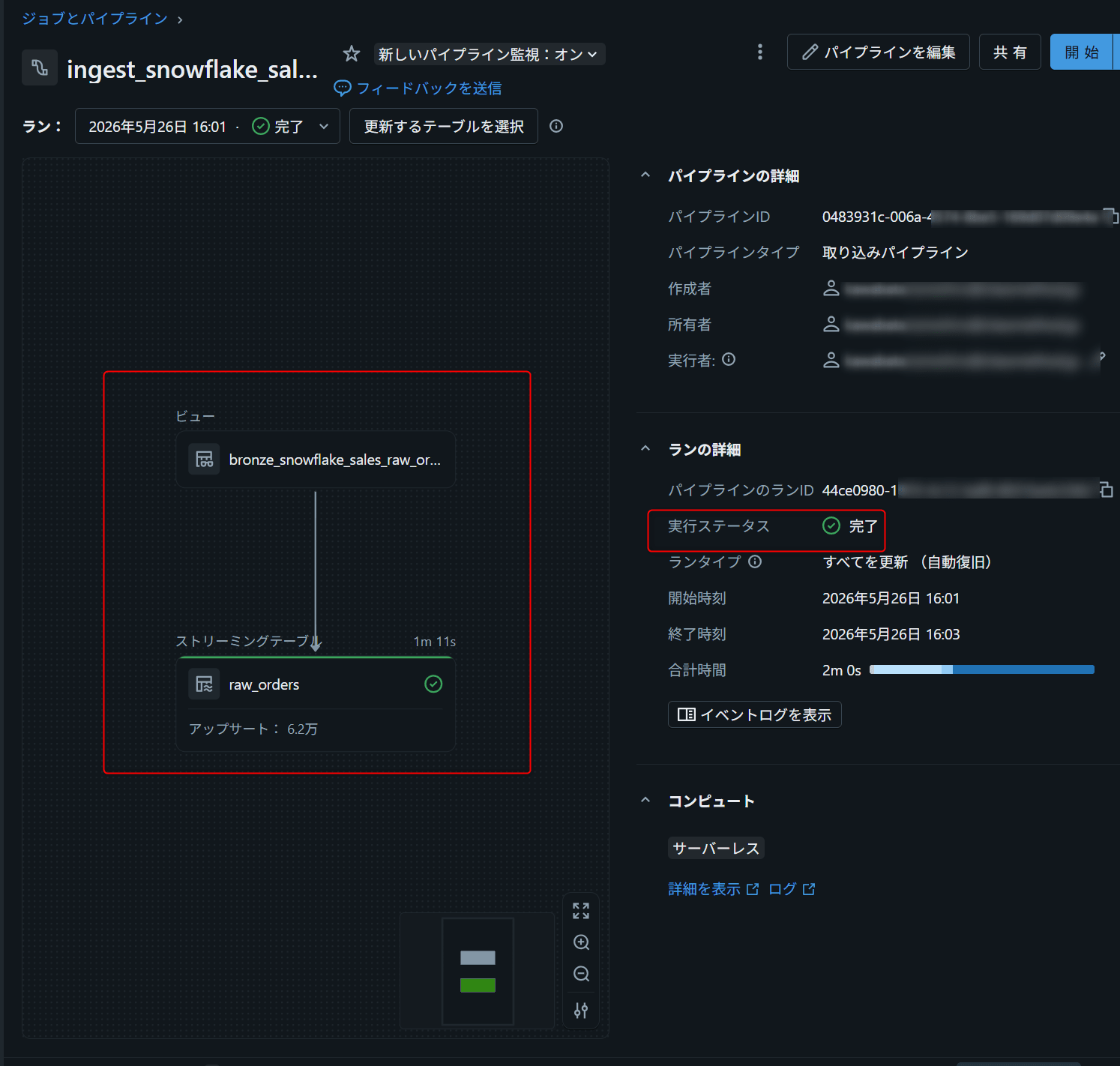
実行結果を確認する
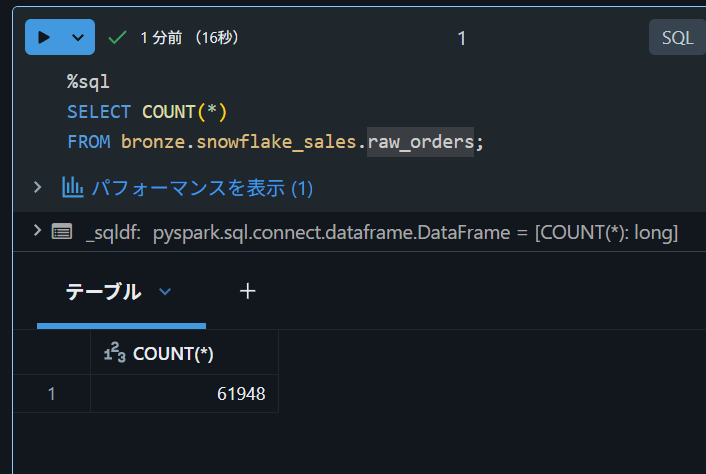
取り込みが完了したら、Databricks SQL Editorで確認します。
SHOW TABLES IN bronze.snowflake_sales;
SELECT COUNT(*)
FROM bronze.snowflake_sales.raw_orders;
Snowflake側と件数を比較します。
Snowflake側:
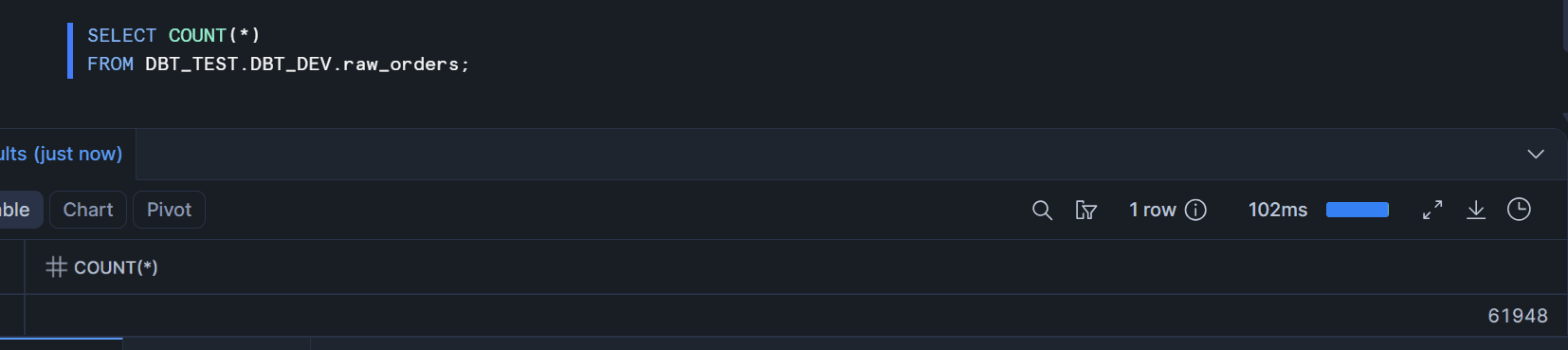
SELECT COUNT(*)
FROM <DATABASE>.<SCHEMA>.raw_orders;
初回はfull loadになるため、Snowflake側と件数が一致して確認できました。2回目以降はcursor columnに基づいて増分取り込みされます。
最後に
Lakeflow ConnectのQuery-based ingestionを使って、SnowflakeからDatabricksへの差分データ取り込みパイプラインを構築できることを確認しました。
便利だと感じた部分は、cursor columnを指定するだけで差分取り込みが実装できてパイプラインの構築が容易にできる部分が素晴らしいと思いました。
まずは小規模なテーブルで手動実行から試してみて、cursor columnやprimary keyの設計を検証してから本番導入を進めるのがおすすめです。
この記事が何かの参考になれば幸いです!









