
Bedrock EvaluationsでKnowledge Bases RAGの検索精度を定量評価する - LLM as a Judgeな評価駆動開発
RAG(Retrieval Augmented Generation)システムを導入する際に、重要でありながら難しいのが検索精度の評価です。
最近のRAGシステムは最初から「それっぽく」動作しますが、本番導入のための品質保証や継続的な利用改善のためには、「それっぽく」ではなく、定量的な評価・改善が求められます。
これらの課題を解決するのがAmazon Bedrock Evaluationsです。
Amazon Bedrock Evaluationsは、LLMモデルとRAGに対して、AWSコンソールからGUIで誰でも簡単に評価を実行できます。
本記事では、Bedrock EvaluationsをBedrock Knowledge Basesに適用し、RAGの検索精度をLLMを使って(LLM as a judge)定量的に評価する方法を解説します。
開発サイクルにうまく取り込むことで、テスト駆動開発(TDD)ならぬ 評価駆動開発(Evaluation-Driven Development;EDD) が可能になります。
- 評価駆動開発(Eval-driven development):LLMアプリケーション開発における課題とアプローチ - LayerX エンジニアブログ
- Eval-driven development: Build better AI faster - Vercel
- How to evaluate an LLM system | Thoughtworks
Amazon Bedrock Evaluationsとは
Amazon Bedrock Evaluationsは、生成AIモデルやRAGシステムの性能を評価するためのマネージドサービスです。
評価方法は対象システムによって分かれています。
| 評価対象 | 自動評価 | 人力評価 |
|---|---|---|
| 生成AIモデル | O | O |
| RAG | O | - |
自動評価(Automatic)はLLMが評価する、一般に「LLM as a Judge」と呼ばれる手法が採用されています。
RAGシステムを対象とする場合、以下の2アプローチがあります。
| アプローチ | RAGシステム | 検索の実行 | 評価 |
|---|---|---|---|
| Bedrock Knowledge Base | Bedrock Knowledge Bases | Bedrock Evaluations | Bedrock Evaluations |
| Bring Your Own Inference (BYOI) | 任意 | ユーザー | Bedrock Evaluations |
さらに、検索フェーズだけの評価も検索から生成までのエンドツーエンドな評価も可能です。
本記事では、Bedrock Knowledge Baseのアプローチを対象に解説します。
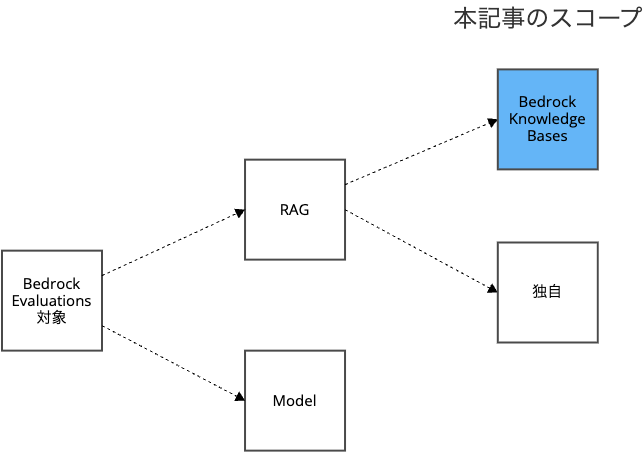
この場合、下図のような処理フローとなります。
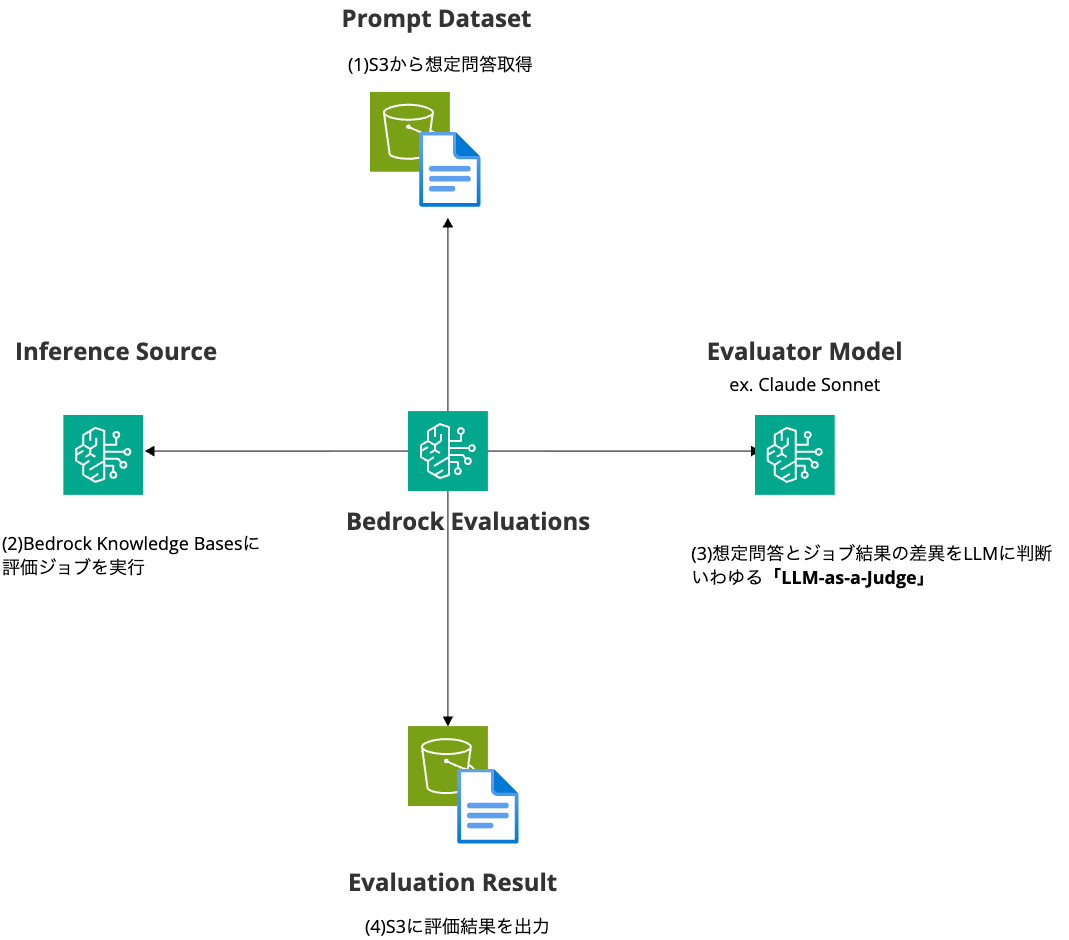
RAG評価の流れ
Bedrock EvaluationsでRAGの検索精度の評価を行う場合、以下の流れで行います。
- RAG システムの構築
- プロンプトデータセット(想定問答)の用意
- 評価ジョブの実行
- 評価ジョブレポートの確認
オプション設定がたくさんあるため、最もベーシックと思われる使い方を前提に説明します。
準備編
1. RAG システムの構築
Bedrock Knowledge Bases でRAGを構築してください。
Knowledge Basesのインターフェースがある限り、データベースはOpenSearchでもPostgreSQLでもS3 Vectorsでも構いません。
構築手順は割愛します。
2. 評価用S3バケットの構築
評価用データセットや評価結果の管理のためにS3バケットを作成しましょう。
このS3バケットにBedrock Evaluationsが読み書きできるように、CORS設定します。
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"PUT",
"POST",
"DELETE"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": [
"Access-Control-Allow-Origin"
]
}
]
3. 想定問答の用意
想定問答(評価用データセットやプロンプトデータセットなどとも呼びます)はJSONL形式で作成し、1000行(1000レコード)まで登録できます。
RAGのBedrock Evaluationsによる検索精度の評価は
- 検索
- 検索と生成
の2パターンが可能です。
データ形式は同じで、必須の質問(prompt)とオプションの想定する回答(いわゆる「ground truth」。referenceResponses)から構成されます。オプションの referenceResponses は特別な理由がない限り、用意しましょう。
1行完結のJSONLを見やすさのために複数行に展開したのが以下です。
{
"conversationTurns": [
{
"prompt": {
"content": [
{
"text": "Amazon S3 とは?"
}
]
},
"referenceResponses": [
{
"content": [
{
"text": "Amazon S3 は、任意の量のデータの保存と取得をどこからでも行えるように設計されたオブジェクトストレージです。"
}
]
}
]
}
]
}
4. プロンプトデータセットをS3に登録
作成したプロンプトデータセットを評価用S3バケットにアップロードして下さい。
評価ジョブの実行
AWSコンソールメニュー
AWSコンソールから Amazon Bedrock > Evaluations から「RAG」タブをたどり、「Create」ボタンから評価ジョブを作成します
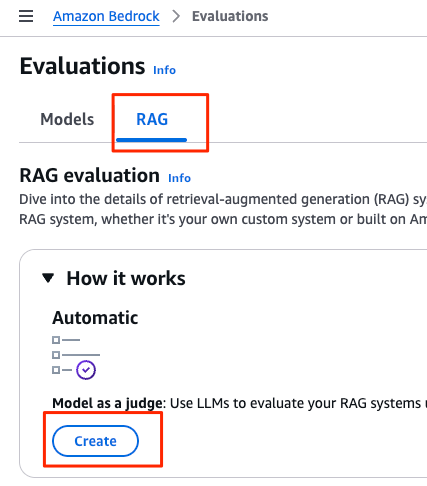
Evaluationsのデフォルトは「Models」なことに注意しましょう。
Evaluation detailsでLLM-as-a-judgeのモデルを選択
「Evaluation details」エリアでは、LLM-as-a-judgeの評価モデルを指定します。
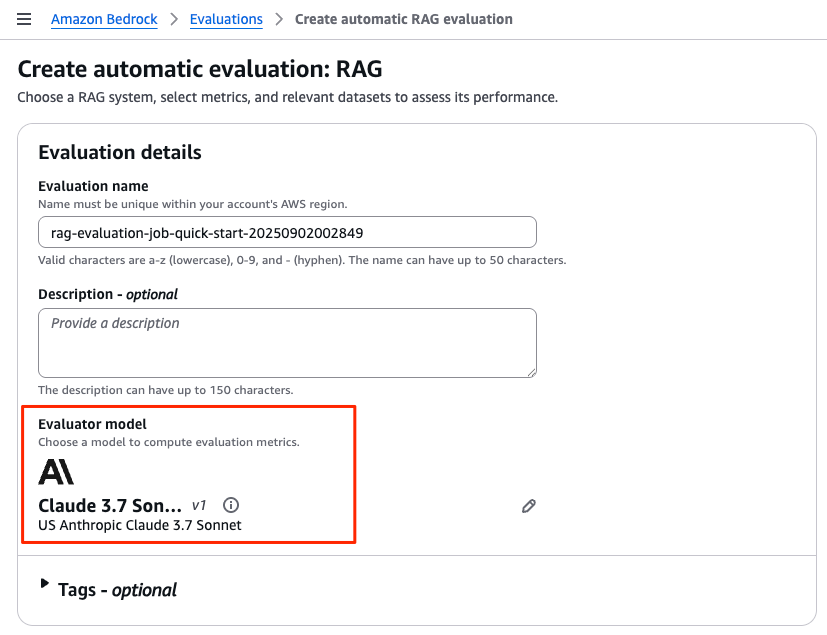
「Evaluator model」 からお好みのモデルを指定してください。
RAGシステムの指定
「Inference source」エリアでは、評価対象のRAGシステムを指定します。
Amazon Bedrock Knowledge Base とシームレスに評価する場合、 「Bedrock Knowledge Base」 をチェックし、 「Choose a Knowledge Base」 のプルダウンから対象のリソースを指定してください。
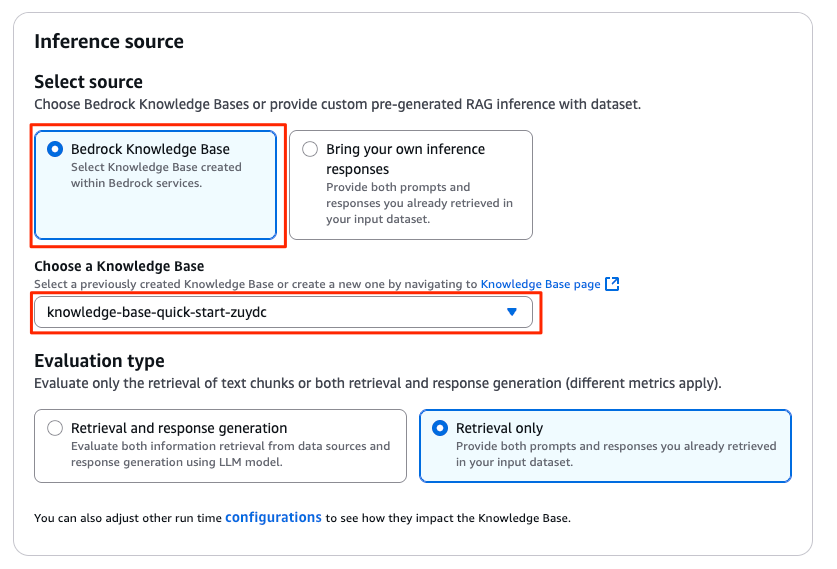
「Brin your own ineference responses」から任意のRAGシステムを評価することも可能です。
評価対象が検索だけなのか生成も含めるのか指定
「Evaluation type」 では、以下のどちらかを選択します。
- 検索のみ:Retrieval only
- 検索と生成:Retrieval and response generation
重要なのは 「configurations」リンク から詳細設定を行うことです。
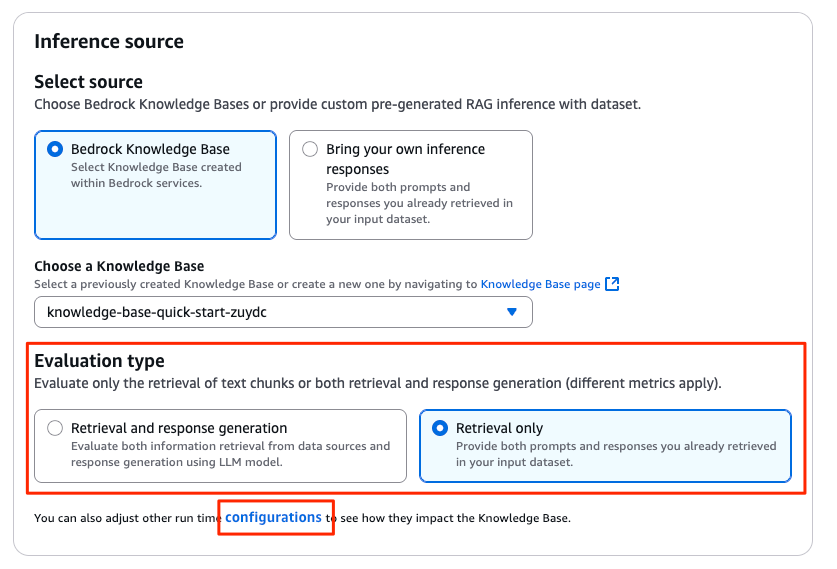
「Retrieval only」を選択した場合
- 検索方式(ベクトル検索、全文検索、その両方のハイブリッド検索)
- 取得するチャンク数
といった検索条件はこの 「configurations」クリック時のポップアップ画面から指定します。

同様に、「Retrieval and response generation」を選択した場合、まず生成に使うモデルを「Response generator model」で指定します。
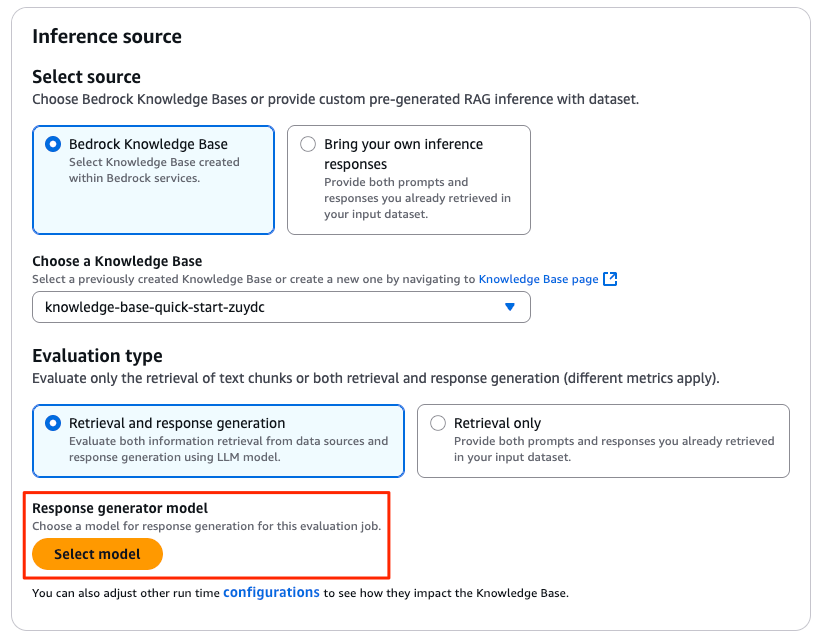
次に、以下のような設定を「configurations」リンクから行います。
- ベクトル検索、全文検索のような検索方法
- 生成時の推論パラメーター
- システムプロンプト
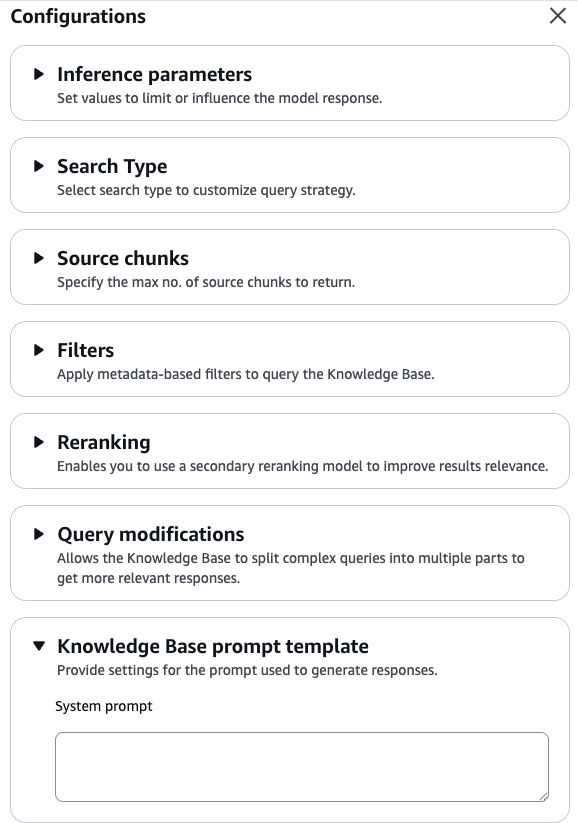
要は、アプリケーションがKnowledge Basesを呼び出すときのパラメーターを指定すればよいわけです。
検索と生成の場合、
- 評価用 のモデル(Evaluator Model)
- 回答生成用 のモデル(Response Generator Model)
という全く異なる2種類のモデルを指定することに注意しましょう。
評価メトリクス(検索)
評価メトリクスは評価タイプ(検索のみ、または、生成も含む)で異なり、有効にするメトリクスを自由に選択できます。
検索向けメトリクス はわずか2つであり、両方とも有効にしましょう。
Context relevance は検索された文書のうち、質問に関連するものの割合(Precision)のことです。
Context Coverage は正解(ground truth)に含まれる情報のうち、検索でカバーできた割合(Recall)のことです。
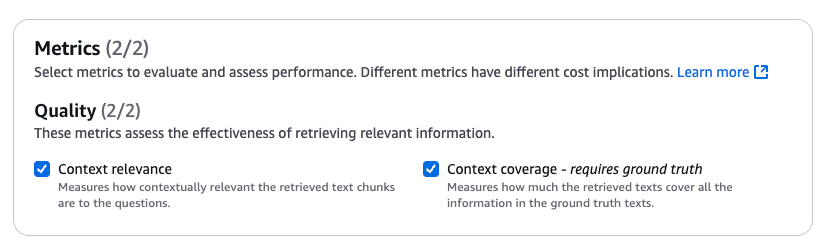
PrecisionとRecallはトレードオフの関係にあります。
詳細は、次のリンクから学びましょう。
評価メトリクス(検索・生成)
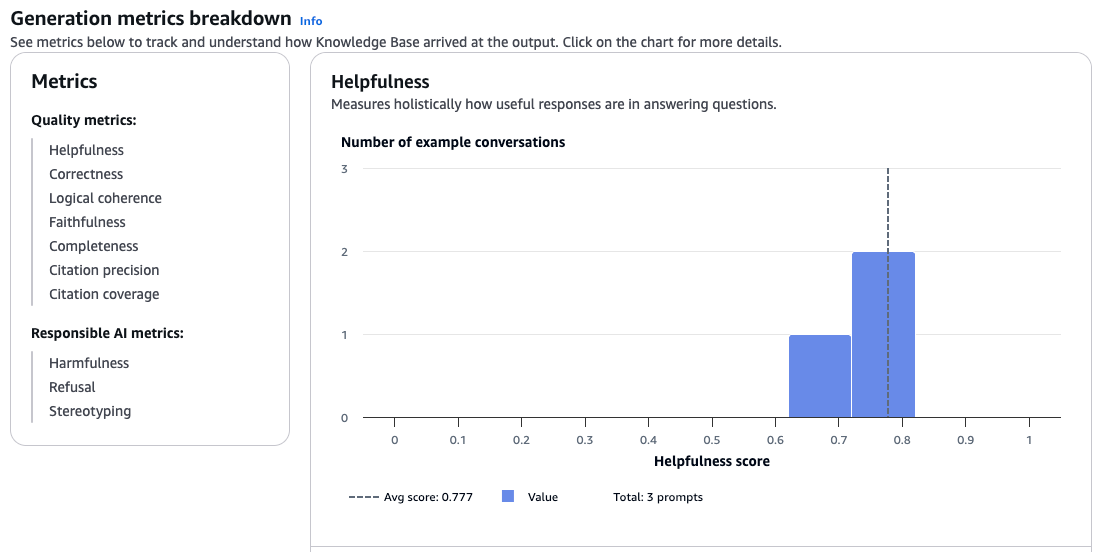
検索・生成向けメトリクス は合計10個あり、デフォルトでは「Helpfulness」と「Harmfullness」がチェックされています。
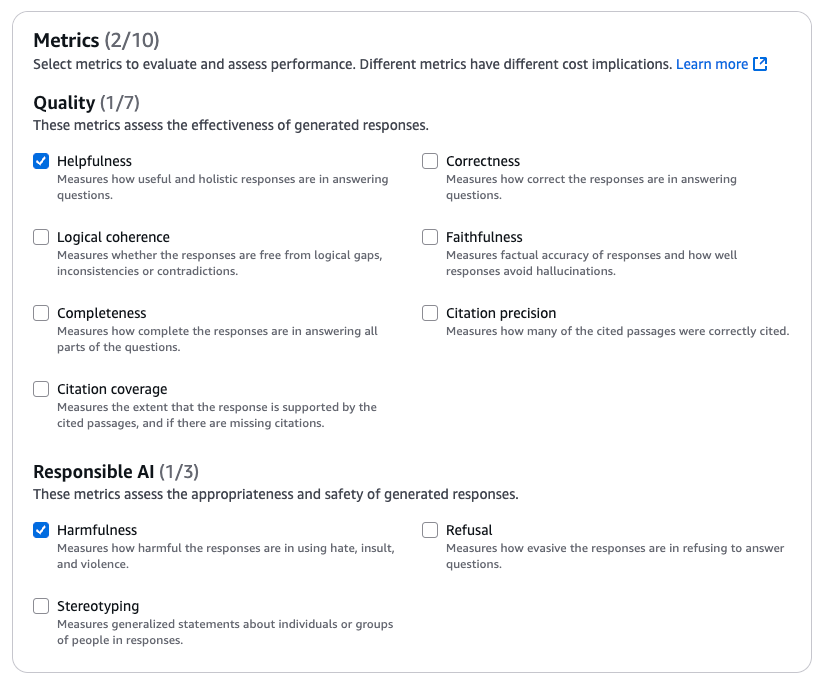
検索の質に関する主要メトリクスとして以下があります
- Helpfulness (有用性): 回答が役立つか
- Correctness (正確性): 生成された回答が正確か
- Completeness (完全性): 回答が質問に対して完全に答えているか
責任あるAIに関する主要メトリクスとして以下があります
- Harmfulness (有害性): 有害な内容が含まれていないか
- Faithfulness (忠実性): ハルシネーションがないか
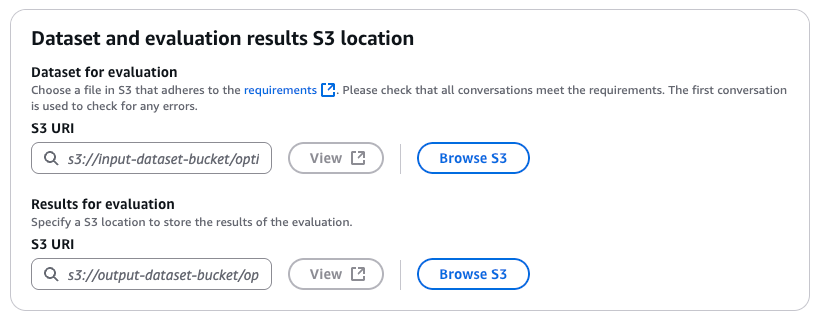
データセットと評価レポートの指定
「Dataset and evaluation results S3 location」セクションから以下を指定します。
- 評価用データセット(プロンプトデータセット)(Dataset for evaluation)
- 評価結果(Results for evaluation)
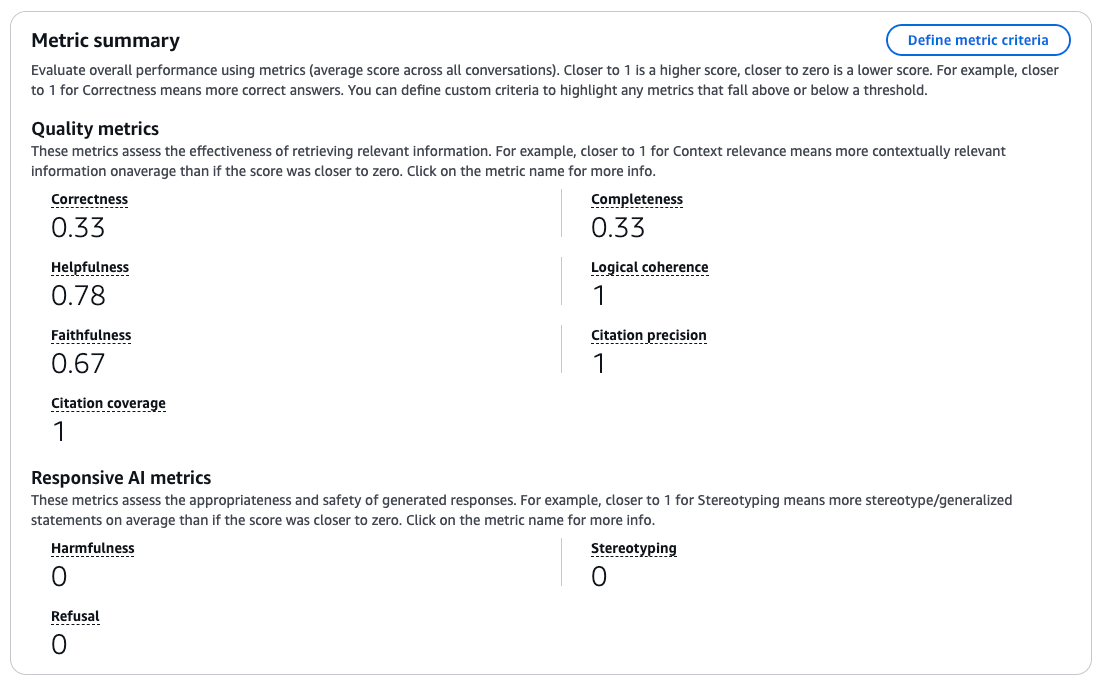
評価ジョブレポートの確認
評価ジョブは非同期に実行され、完了すると、レポートを確認できます。
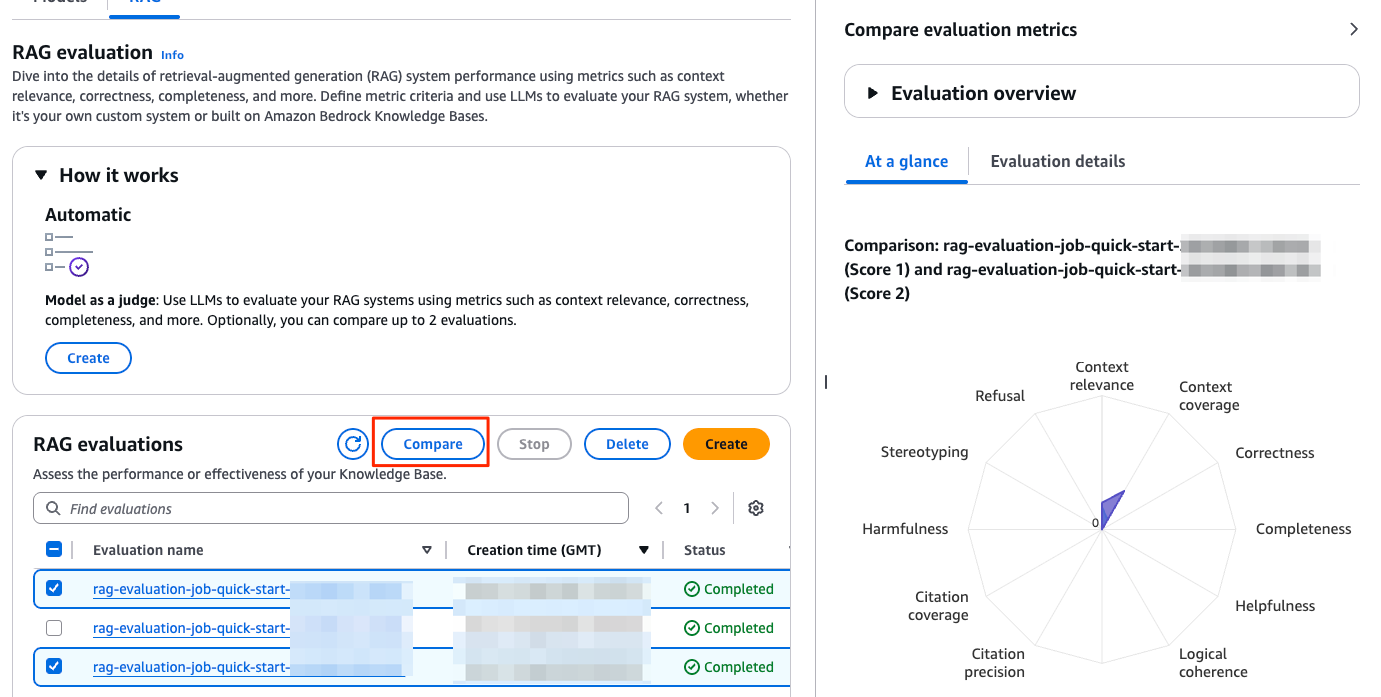
また、ジョブ間の差異を確認することもできます。
評価駆動開発な検索精度の改善
評価ジョブを1回だけ走らせるのはもったいないです。
AWSがコンソールから簡単に検索精度を評価する仕組みを提供してくれているのですから、繰り返し実行し、検索精度を改善しましょう。
Bedrock Evaluationsを利用した改善ステップをいくつか紹介します。
1. Retrieve Only から Retrieve and Generate へのステップ
RAG は名前の通り、検索のあとで生成をおこないます。
関連性の低い文書を検索していては、期待するような生成結果は得られません。
手間を省くために、最初からエンドツーエンドに「Retrieve and Generate」の評価も可能ですが、検索精度の改善サイクルをまわせるのなら、検索のみ(Retrieve Only)から始めるのをおすすめします。
2. プロンプトデータセットの継続的な拡充
評価フェーズの初期から十分なプロンプトデータセット(想定問答)を用意するのは難しいです。
網羅性やうまくいないケースやエッジケースなど、少しずつ充実させましょう。
3. 評価ジョブ間の比較分析
Bedrock Evaluationsは評価ジョブ間での比較をボタン一つで行えます。
一貫した手法・メトリクスで評価することで、イテレーションの差分を評価しましょう。
開発サイクルにうまく取り込むことで、テスト駆動開発(TDD)ならぬ評価駆動開発(Evaluation-Driven Development;EDD)が可能になります。
料金体系
LLM-as-a-judgeとして評価にBedrock Evaluationsを利用した場合、評価モデルの使用料が従量課金で発生します。
メトリクスの使用料は発生しません。
詳細な料金情報はAWS Bedrock Pricingを参照してください。
プロンプトデータセットでreferenceResponsesが必須でない理由
検索のみの評価には以下の2つのメトリクスがあります。
Context relevance は検索された文書のうち、質問に関連するものの割合(Precision)のことです。
Context Coverage は正解(ground truth)に含まれる情報のうち、検索でカバーできた割合(Recall)のことです。
なぜContext RelevanceはreferenceResponsesなしで評価できるのか?
このうち、 Context Relevance(Precision) メトリクスの評価では、プロンプトデータセットにreferenceResponses (ground truth)は必須ではありません。
これは、LLMが質問と検索結果の関連性を判断できるためです。
例えば「Amazon S3とは?」という質問に対して「S3はオブジェクトストレージサービスです」というチャンクが返ってきた場合、LLMはこの2つが関連している(relevant)と判断できます。これが LLM-as-a-Judge です。
Context CoverageにはreferenceResponsesが必要
一方、 Context Coverage(Recall) の評価にはreferenceResponsesが必須です。なぜなら、「正解に含まれる情報をどれだけカバーできたか」を測定するには、比較対象となる正解(ground truth)が必要だからです。
例えば、ground truthが「オブジェクトストレージ、スケーラブル、耐久性99.999999999%」という3つの要素を含む場合、検索結果がそのうち何割をカバーしているかを判定するには、この正解データが不可欠です。
referenceResponsesに依存する有用なメトリクスはContext Coverage以外にも多数あるため、特別な理由がない限り用意することをおすすめします。
まとめ
本記事では、Amazon Bedrock EvaluationsをBedrock Knowledge Basesに適用し、RAGシステムの検索精度を定量的に評価する方法を解説しました。
評価を1回だけ行うのではなく、以下のようなアプローチで継続的・段階的に評価するのがおすすめです
- 段階的評価: Retrieve Only → Retrieve and Generateの順で、検索精度を確立してから生成品質を改善
- データセットの拡充: 少数の初期データから多様なケース、エッジケースへと段階的に拡充
- 継続的比較分析: 評価ジョブ間の比較により、各施策の効果を定量的に把握
LLMアプリケーションの評価は専門性と時間を要する作業ですが、Amazon Bedrock Evaluationsにより、AWSコンソールから誰でも簡単にはじめられるようになりました。
導入の敷居が低く、利用費もこなれているため、プロジェクトの初期からAmazon Bedrock Evaluationsを開発サイクルに組み込むことで、継続的な評価駆動開発(Evaluation-Driven Development;EDD)を実践しましょう。
参考
- Evaluate Foundation Models - Amazon Bedrock Evaluations - AWS
- Evaluate the performance of Amazon Bedrock resources - Amazon Bedrock
- AWS re:Invent 2024 - Streamline RAG and model evaluation with Amazon Bedrock (AIM359) - YouTube
- AI evaluations on Amazon Bedrock | AWS Show and Tell - Generative AI | S1 E16 - YouTube







