
BedrockのナレッジベースをRedshift Serverlessに接続して自然言語でクエリしてみた
Amazon BedrockのナレッジベースをRedshift Serverlessに接続することで、 Redshift Serverlessに格納されている情報に対して自然言語でクエリができるようになります。
この設定を試す機会があったので、一通りのやり方をまとめておこうと思います。 先に書いておくと、案内がわかりやすいのでほとんど順を追っていくだけでできた感じです!
やってみる
Bedrockのページからスタートします。 デフォルト設定から変更するべき点だけ画像内に注釈しています。
ナレッジベース→作成→「構造化データストアを含むナレッジベース」
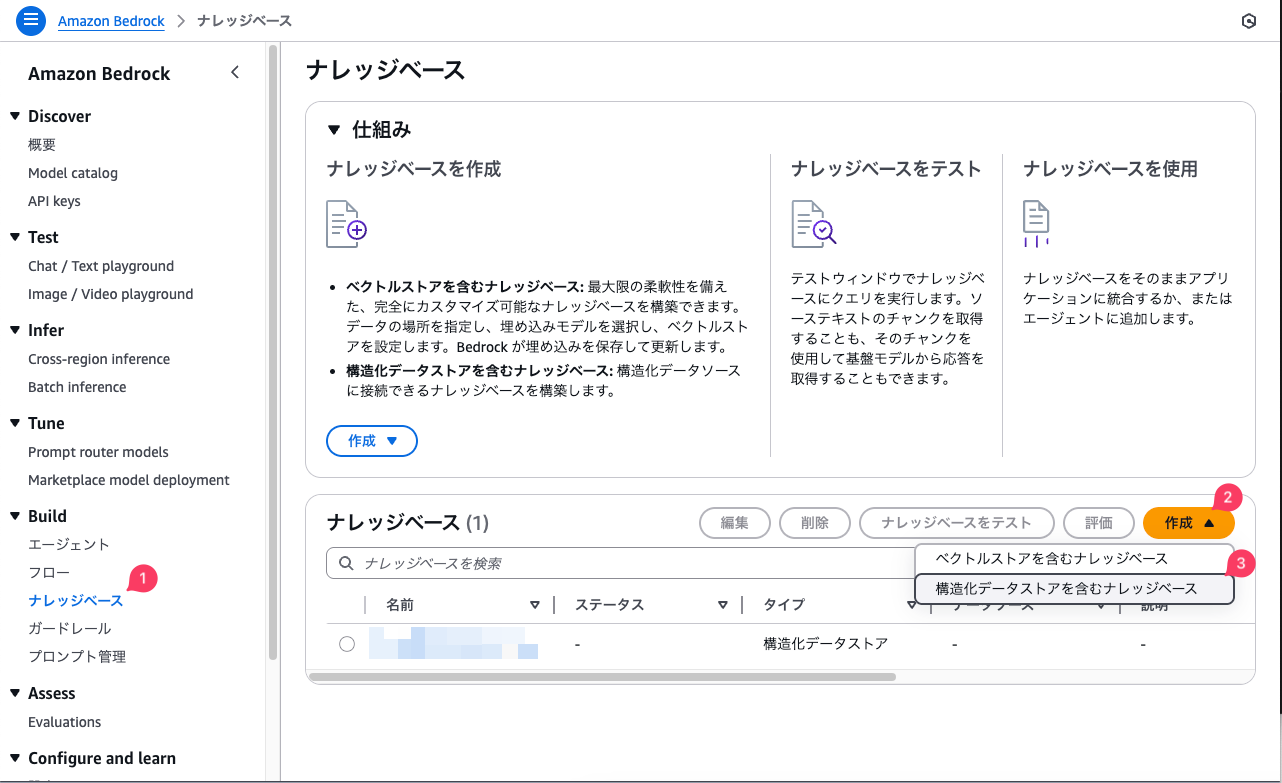
IAMロールは新規作成するので「サービスロール名」を入力します。
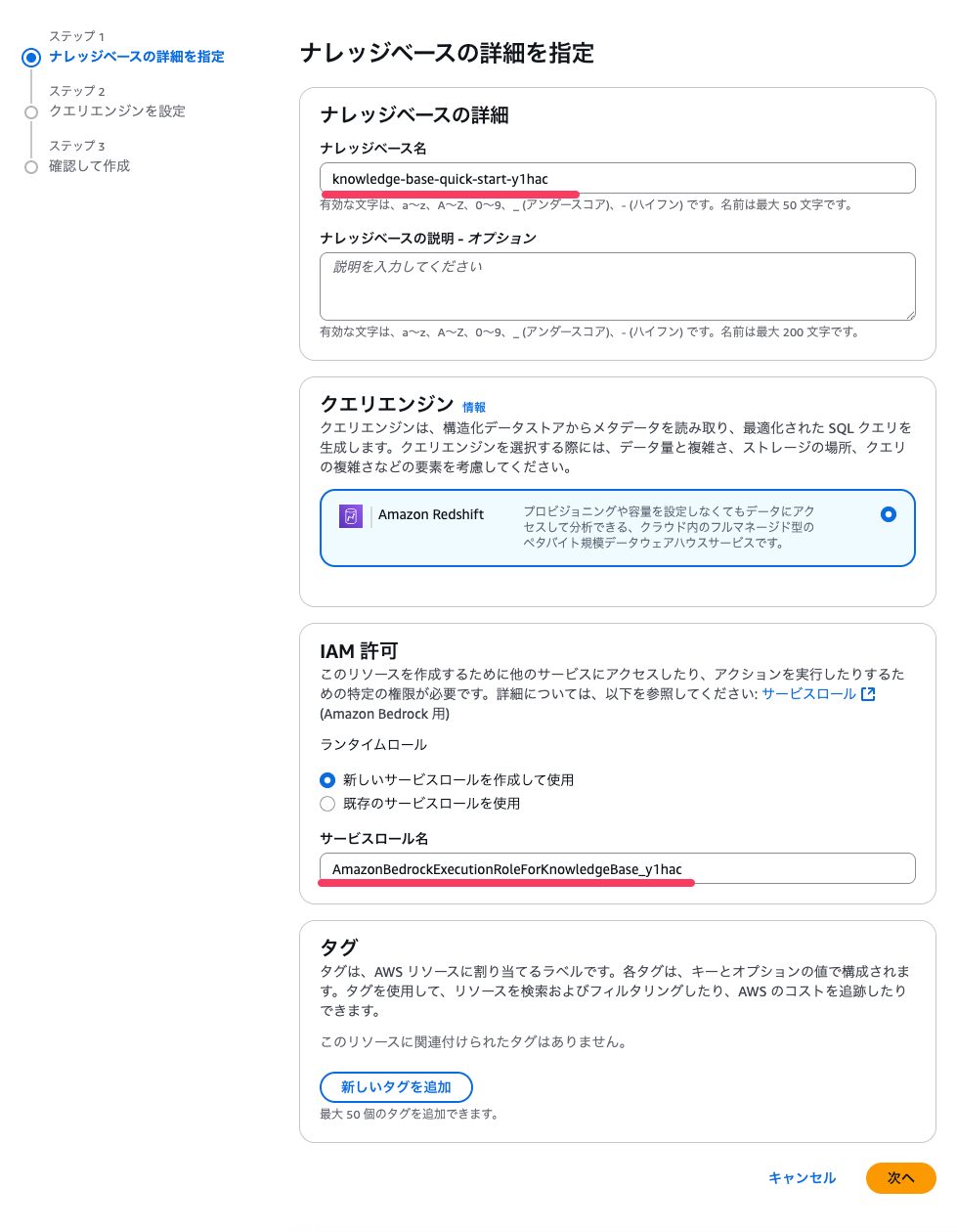
接続先のRedshift Serverless情報を入力します。 今回はBedrockのIAMロールとして接続する形で試すので 「認証」は「IAMロール」のままとします。
下部の「クエリ設定」の部分では、 特定のテーブルやカラムに説明文を加えたりできるようです。 また「キュレートクエリ」には 「こんな質問をされたらこんなSQLを生成してね」という感じで 質問とSQLの対応例を渡すことができるようです。 これを利用することで、ある典型的な言い回しを設定できたりするのだと思います(未検証)。
これらはオプションですので、何も記述せず次に進みます。
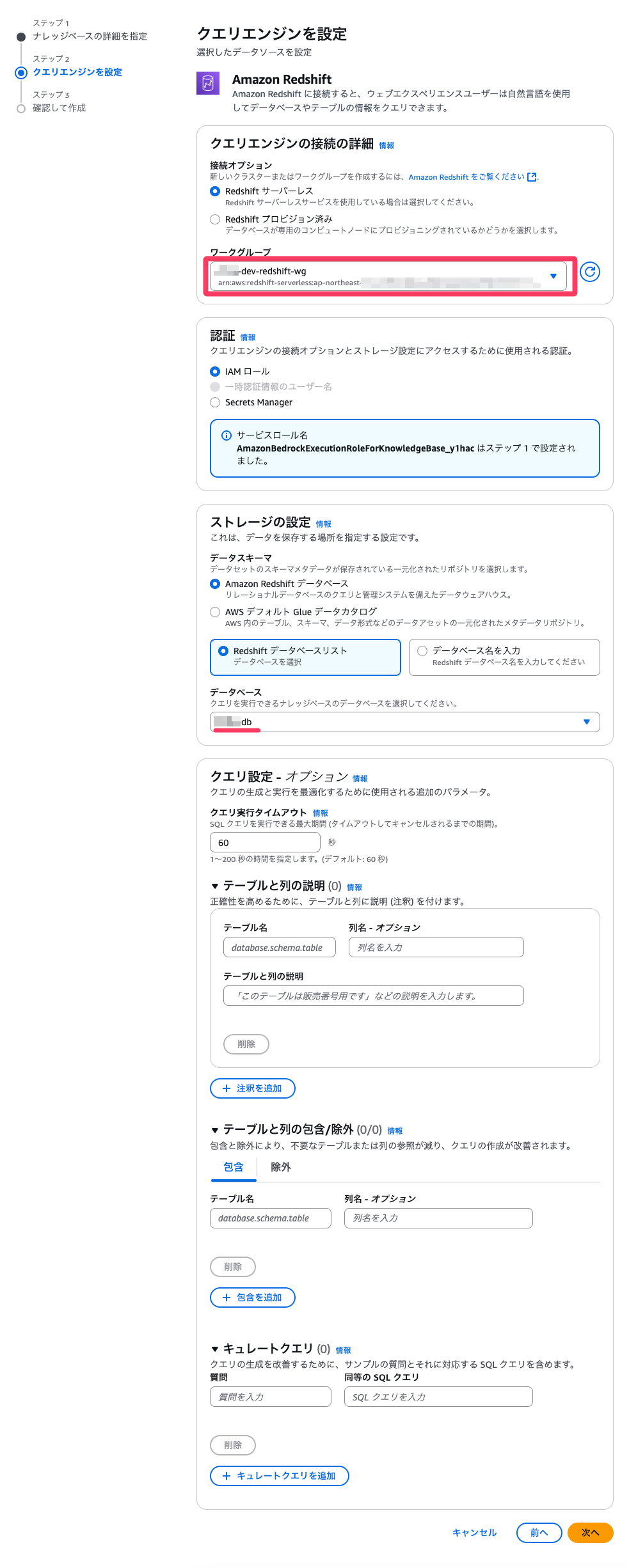
設定は以上なので、内容を確認してナレッジベースを作成します。
ナレッジベースが設定できました。
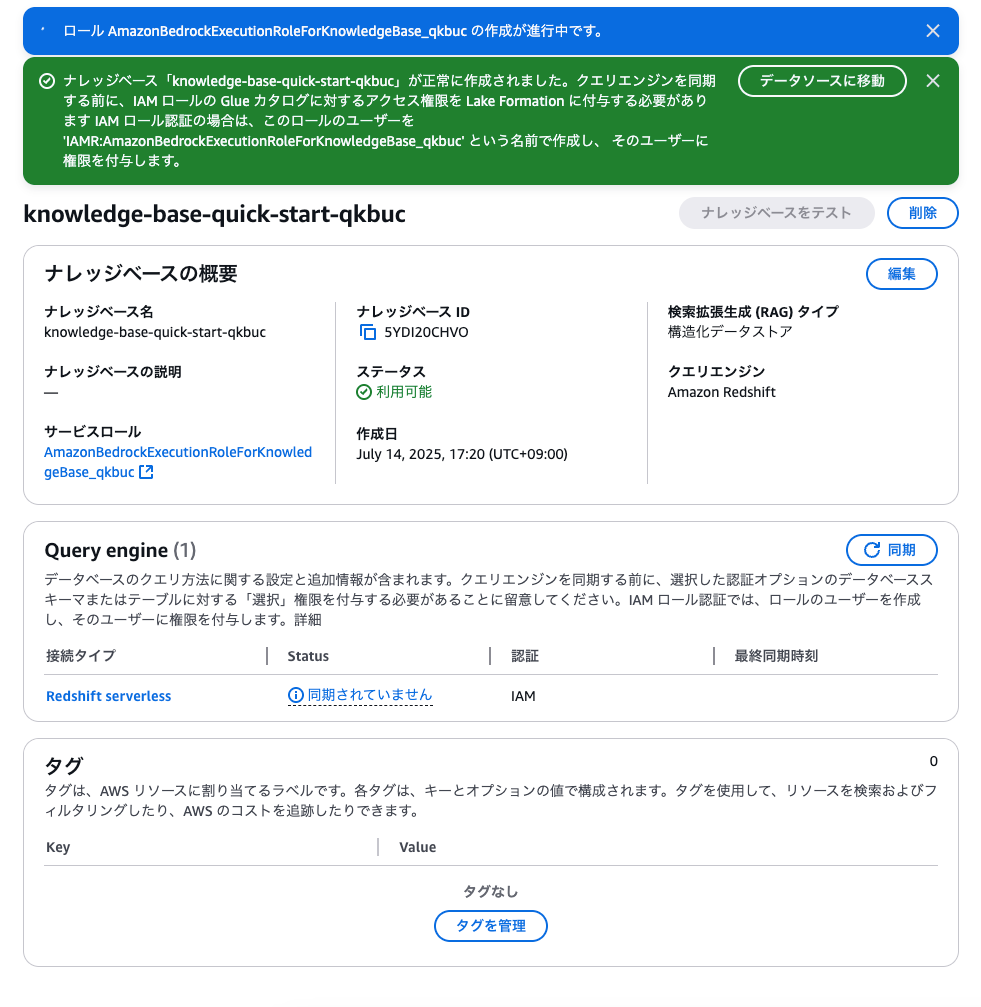
早速「ナレッジベースをテスト」したいのですが、まだ押せません。 > このナレッジベースをテストするには、1 つ以上のデータソースを同期する必要があります。
と表示されていますので同期をしてみたいと思いますが、 失敗してしまいます。

データソースの同期に失敗しました - 'knowledge-base-quick-start-46m3l-data-source' Errors: Ingestion failed. Either the database is empty, or the user does not have permission to read table data. Ensure the user has read permissions on the respective resource. Please see: https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-prereq-structured.html#knowledge-base-prereq-structured-service-role
と出ました。
これはどういうことかというと、 Redshift ServerlessにIAMロールから接続しようとしているものの、 実際にそのIAMロールではどのテーブルへもアクセスができないという状況のようです。 先ほどのナレッジベース作成で作成されたIAMロールはどこにもアクセスできないということですね。
実際に確認していきます。 このユーザです。
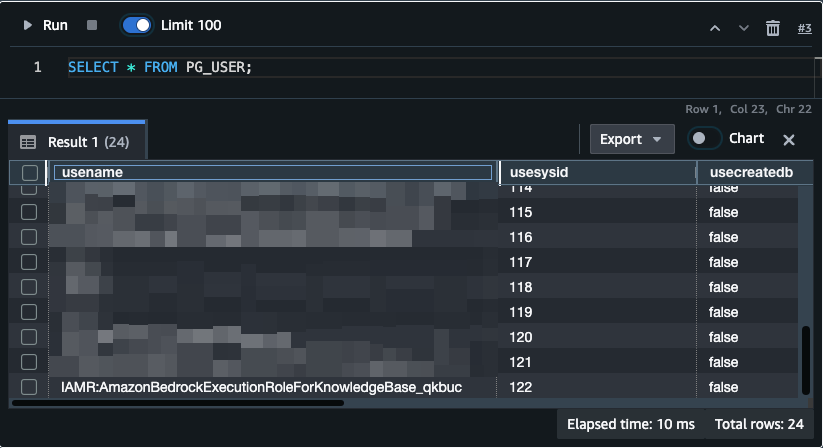
このユーザがどこにアクセスできるかを調べてみると、
WITH privilege_table AS (
SELECT
table_schema
, table_name
, HAS_TABLE_PRIVILEGE(usename, table_schema || '.' || table_name, 'select') AS select
, HAS_TABLE_PRIVILEGE(usename, table_schema || '.' || table_name, 'insert') AS insert
, HAS_TABLE_PRIVILEGE(usename, table_schema || '.' || table_name, 'update') AS update
, HAS_TABLE_PRIVILEGE(usename, table_schema || '.' || table_name, 'delete') AS delete
, HAS_TABLE_PRIVILEGE(usename, table_schema || '.' || table_name, 'drop') AS drop
, HAS_TABLE_PRIVILEGE(usename, table_schema || '.' || table_name, 'references') AS references
, HAS_TABLE_PRIVILEGE(usename, table_schema || '.' || table_name, 'alter') AS alter
, HAS_TABLE_PRIVILEGE(usename, table_schema || '.' || table_name, 'truncate') AS truncate
FROM
(
SELECT * from svv_tables
WHERE table_schema = 'public'
) as tables,
(
SELECT * FROM PG_USER
WHERE usename = 'IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_qkbuc'
) AS users
)
select * from privilege_table;
主要なテーブル(ここではサンプルですが)へのselect権限がfalseになっています。
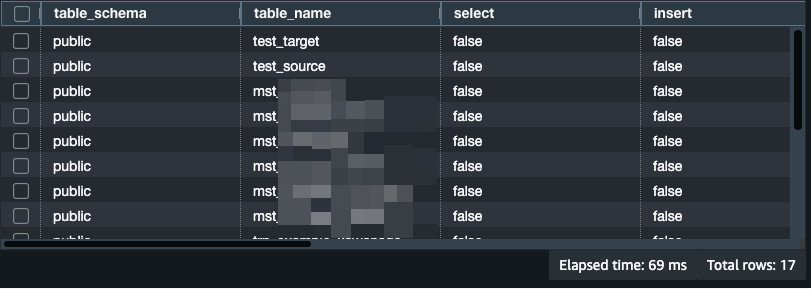
これらのテーブルへのアクセス権限を設定してみます。
publicスキーマと、その中の全てのテーブルへのアクセスを許可します。
GRANT USAGE ON SCHEMA public TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_qkbuc";
GRANT SELECT ON ALL TABLES IN SCHEMA public TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_qkbuc";
もう一度同じクエリで確認し、権限がついたことが確認できます。
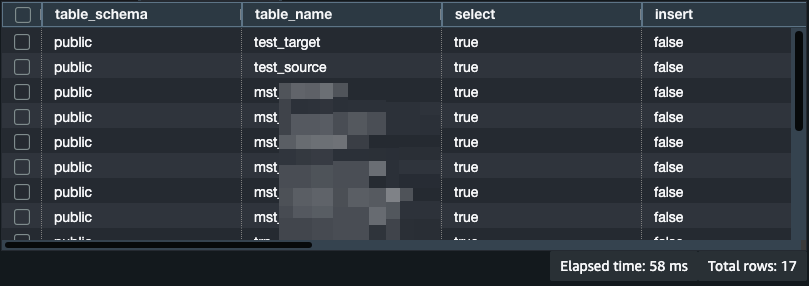
この状態でナレッジベースの画面に戻り「同期」を試すと、成功しました!

クエリを試してみる
クエリ実行を試してみます。
「ナレッジベースをテスト」をクリックすると、 どのような形での返答を受け取るかの選択肢が出てきます。
- 取得のみ: データソース
- 自然言語から生成されたSQLクエリを実行して得られるテーブルデータを受け取る
- 取得と応答生成: データソースとモデル
- 自然言語から生成されたSQLクエリの結果を元に、それを説明する自然言語で応答を受け取る
- SQL クエリの生成
- 自然言語から生成されるSQLクエリを受け取る
表示される順番がなんか変な気がしますが、
- SQLクエリを作って
- それを実行した結果を受けて
- その内容を説明する自然言語を作る
という順番で処理がされていることがわかります。 まずhデフォルトで選ばれている「取得と応答生成」で進めていきます。
適当なモデルを選択して、
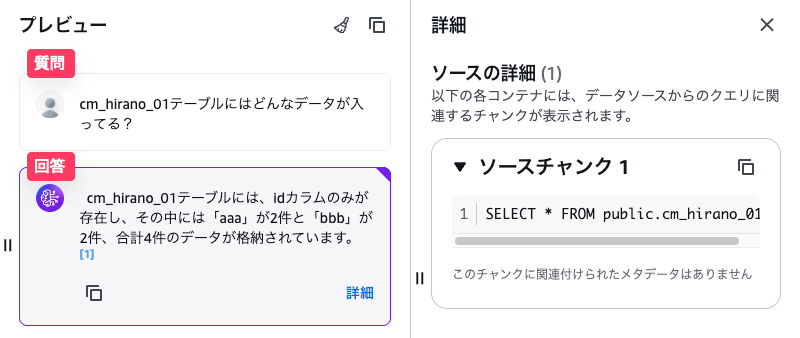
自然言語で問い合わせをすると結果が返ってきました!
「詳細」をクリックすると、投げられたクエリも見られます。
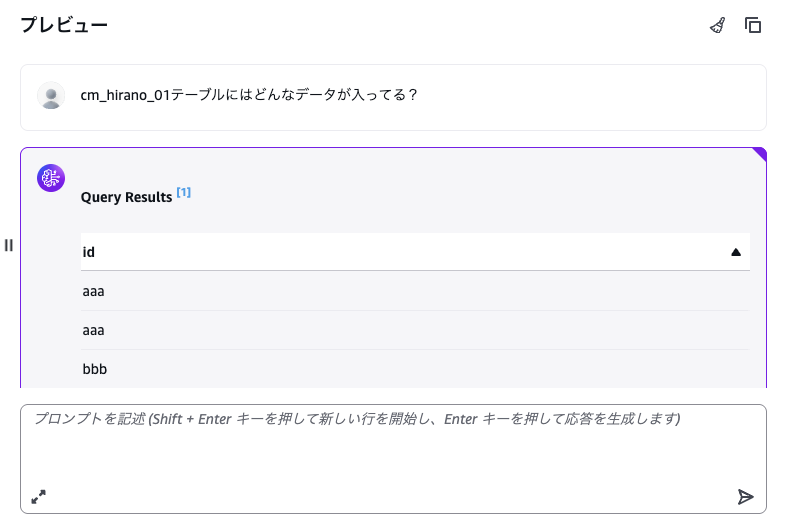
他の受け取り形式も試してみます。 「取得のみ」とすると、クエリの結果だけが表示されます。
「SQLクエリの生成」はクエリのみです。
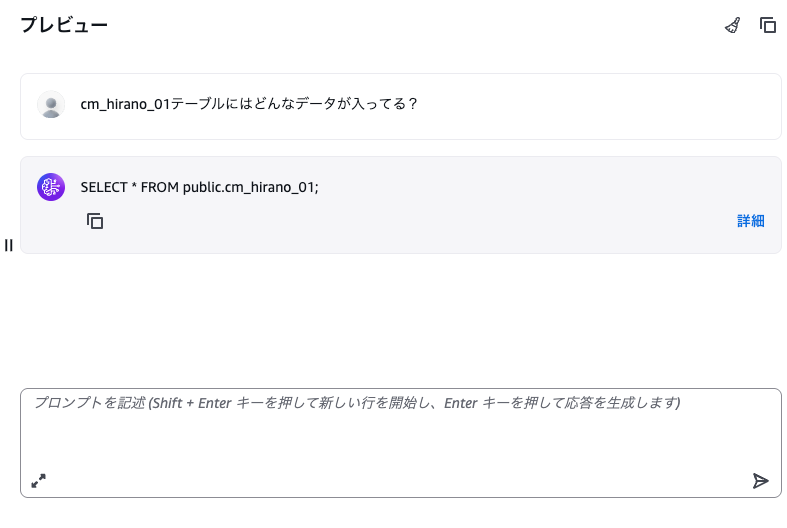
あまりにもつまらないサンプルテーブルですいません...!
まとめ
BedrockのナレッジベースでRedshift Serverlessに接続ができました。 案内も親切ですし、基本的に書かれている通りにやるだけだと思いますが、 新規IAMロールで接続する場合は、 そのユーザがスキーマ・テーブルにアクセスできるような権限設定が必要となります。 この設定についてはDB内部で設定する必要があるので少し迷うポイントかもしれません。
これでRedshift Serverlessに蓄積されたデータに対して自然言語での問い合わせが可能になりますね!
以上誰かの参考になれば幸いです。










