
BigQuery 管理の Iceberg テーブルを BigLake Metastore Iceberg REST カタログと連携して Spark ジョブからデータを参照してみた。
こんにちは、みかみです。
好きな DWH は BigQuery です。
本記事は、クラスメソッド Google Cloud Advent Calendar 2025 の 7 日目のエントリです。
Google Cloud 好きなクラスメソッド社員が紡ぐ今年のクラスメソッド Google Cloud Advent Calendar 2025、最終日の25日までお楽しみいただけたら幸いです!
はじめに
BigQuery の Iceberg テーブルは BigLake メタストアで管理されますが、大きく分けて2種類の Iceberg カタログがあります。
Iceberg REST カタログと BigQuery 用のカスタム Iceberg カタログです。
Iceberg REST カタログは Spark などのオープンソースエンジンからデータを追加・更新できる、オープンカタログの Iceberg テーブルをサポートしています。
BigQuery からも、Iceberg テーブルの Parquet データを外部テーブルとして参照することができます。
また、BigQuery 用のカスタム Iceberg カタログは、BigQuery からデータを追加・更新できる Iceberg カタログです。
CREATE TABLE 文で BigQuery Connection と GCS バケットパスを指定することにより、BigQuery で Iceberg テーブルを簡単に作成することができます。
しかし、そのままでは Spark などのオープンソースエンジンからは参照できません。
そこで・・・
やりたいこと
- BigQuery で作成した Iceberg テーブルの最新データを、BogLake Metastore Iceberg REST カタログで参照できることを確認したい
本ブログでは上記を検証していますが、実は以下を確認したいと思ってました。
1. BigQuery で作成した Iceberg テーブルに、BigQuery、Snowflake 双方から データ参照・追加・更新できるか確認したい。
これは断念しました。
BigQuery 管理の Iceberg テーブルを BigLake Metastore Iceberg REST カタログに連携しても、Spark ジョブからデータの書き込みができないことを確認したためです。
2. BigQuery で作成した Iceberg テーブルの最新データを、Snowflake Iceberg テーブルからテーブル定義(メタデータ指定)更新なしで参照したい
BigQuery 管理の Iceberg テーブルデータを Snowflake から参照できることは検証済みですが、Snowflake の Iceberg テーブル作成時に GCS 上のメタデータフィルパスを指定する必要があるため、最新データを参照するには Snowflake 側で Iceberg テーブルを作成し直す必要があります。
Snowflake は Apache Iceberg REST catalogs をサポートしているため、BigQuery 用のカスタム Iceberg カタログと BigLake Metastore Iceberg REST カタログの連携ができれば、Snowflake の Iceberg テーブル定義を更新することなく Snowflake から BigQuery Iceberg テーブルの最新データの参照が可能な認識です。
ですが、今回 Snowflake カタログ統合のエラーが解決できず、Snowflake 連携の検証までには至りませんでした。。
追って検証したいと思います!
3. BigQuery で作成した Iceberg テーブルの最新データを、BogLake Metastore Iceberg REST カタログで参照できることを確認したい
まずは基本から。
ということで、本ブログではこちらの検証結果をご紹介しています。
前提
Google Cloud SDK(gcloud コマンド)の実行環境は準備済みであるものとします。 本エントリでは、Cloud Shell を使用しました。
また、BigQuery や BigLake など各サービス操作に必要な API の有効化と権限は付与済みです。
なお、文中、プロジェクトIDなど一部の文字は伏字に変更しています。
BigQuery 管理の Iceberg テーブルを作成
GCSバケット、BigLake Metastore カタログ、BigQuery Connection を作成
作成するリソースの名称などをあらかじめ環境変数に設定しておきます。
export PROJECT_ID="[PROJECT_ID]"
export REGION="asia-northeast1"
export BUCKET_NAME="mikami-biglake-iceberg"
export CATALOG_NAME="mikami-biglake-iceberg"
export CONNECTION_ID="mikami-iceberg-connection"
以下のコマンドで、GCSバケットを作成しました。
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
続いて BigLake Metastore カタログを作成します。
gcloud alpha biglake iceberg catalogs create $CATALOG_NAME \
--project=$PROJECT_ID \
--catalog-type=gcs-bucket
さらに、BigQuery Connection を作成します。
bq mk --connection \
--location=$REGION \
--project_id=$PROJECT_ID \
--connection_type=CLOUD_RESOURCE \
$CONNECTION_ID
Connection の サービスアカウントを取得して、先ほど作成した GCS バケットの管理者権限と BigLake 管理者ロールを付与しておきます。
$ export CONNECTION_SA=$(bq show --connection --format=json --location=$REGION $CONNECTION_ID \
| python3 -c "import sys, json; print(json.load(sys.stdin)['cloudResource']['serviceAccountId'])")
echo "Connection SA: $CONNECTION_SA"
Connection SA: bqcx-[PROJECT_NUMBER]-xa8a@gcp-sa-bigquery-condel.iam.gserviceaccount.com
gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectAdmin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/biglake.admin" \
--condition=None
BigQuery 管理の Iceberg テーブルを作成
以下のコマンドで create_bq_managed.py スクリプトを作成しました。
BigQuery のデータセットとテーブルを作成して、テーブルにデータを INSERT した後、メタデータを GCS にエクスポートします。
cat > create_bq_managed.py << 'EOF'
from google.cloud import bigquery
import os
project_id = "[PROJECT_ID]"
region = "asia-northeast1"
connection_id = "mikami-iceberg-connection"
bucket_name = "mikami-biglake-iceberg"
dataset_name = "biglake_iceberg"
table_name = "mst_user"
client = bigquery.Client(project=project_id, location=region)
# 1. データセット作成
dataset_id = f"{project_id}.{dataset_name}"
dataset = bigquery.Dataset(dataset_id)
dataset.location = region
client.create_dataset(dataset, exists_ok=True)
print(f"Dataset ensured: {dataset_id}")
# 2. テーブル作成
table_ref = f"{project_id}.{dataset_name}.{table_name}"
connection_ref = f"{region}.{connection_id}"
storage_uri = f"gs://{bucket_name}/warehouse/{dataset_name}/{table_name}"
print(f"Creating Managed Table: {table_ref}")
print(f"Storage URI: {storage_uri}")
sql = f"""
CREATE TABLE IF NOT EXISTS `{table_ref}` (
id INT64,
name STRING,
created_at TIMESTAMP
)
WITH CONNECTION `{connection_ref}`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = '{storage_uri}'
)
"""
client.query(sql).result()
# 3. データ投入
print("Inserting data...")
insert_sql = f"INSERT INTO `{table_ref}` VALUES (1, 'Alice_BQ', CURRENT_TIMESTAMP())"
client.query(insert_sql).result()
# 4. メタデータのエクスポート
print("Exporting table metadata...")
export_sql = f"EXPORT TABLE METADATA FROM `{table_ref}`"
client.query(export_sql).result()
print("✅ Table created, data inserted, and metadata exported.")
EOF
作成したスクリプトを実行します。
$ python3 create_bq_managed.py
Creating Managed Table: [PROJECT_ID].biglake_iceberg.mst_user
Storage URI: gs://mikami-biglake-iceberg/warehouse/biglake_iceberg/mst_user
Inserting data...
Exporting table metadata...
✅ Table created, data inserted, and metadata exported.
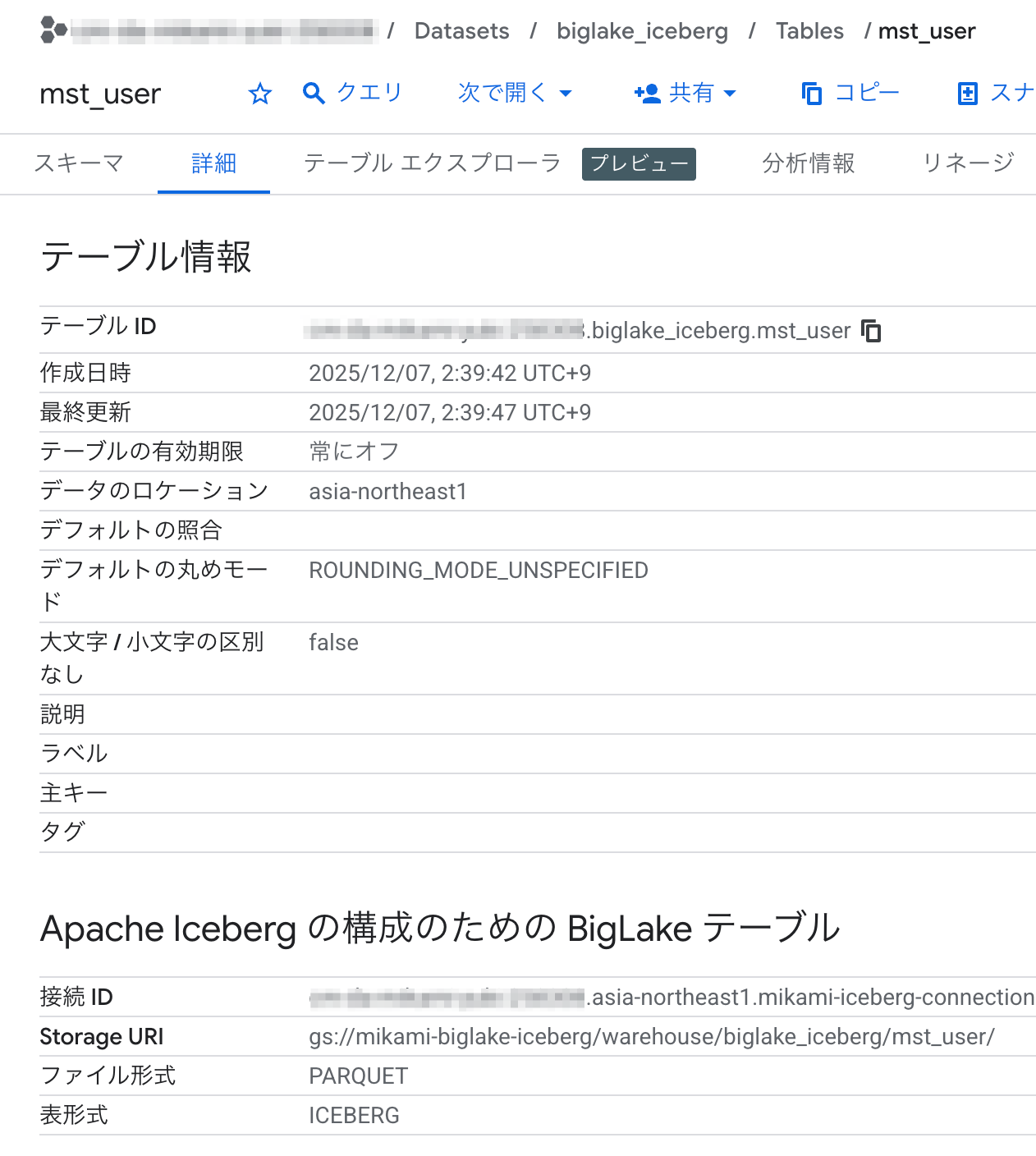
管理画面からも、テーブルが作成されてデータが入っていることが角煮できました。
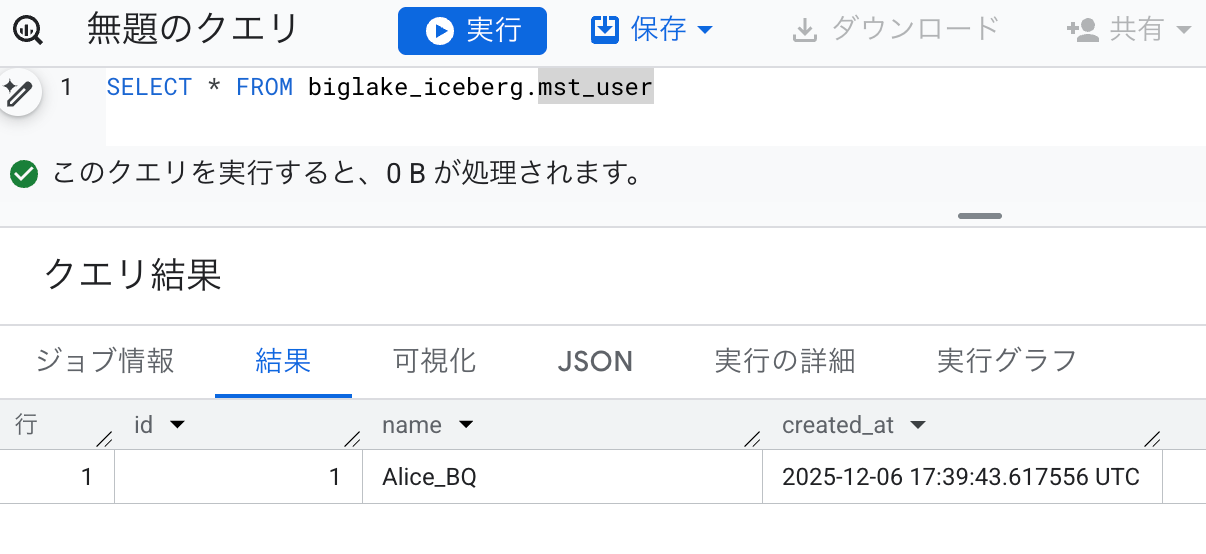
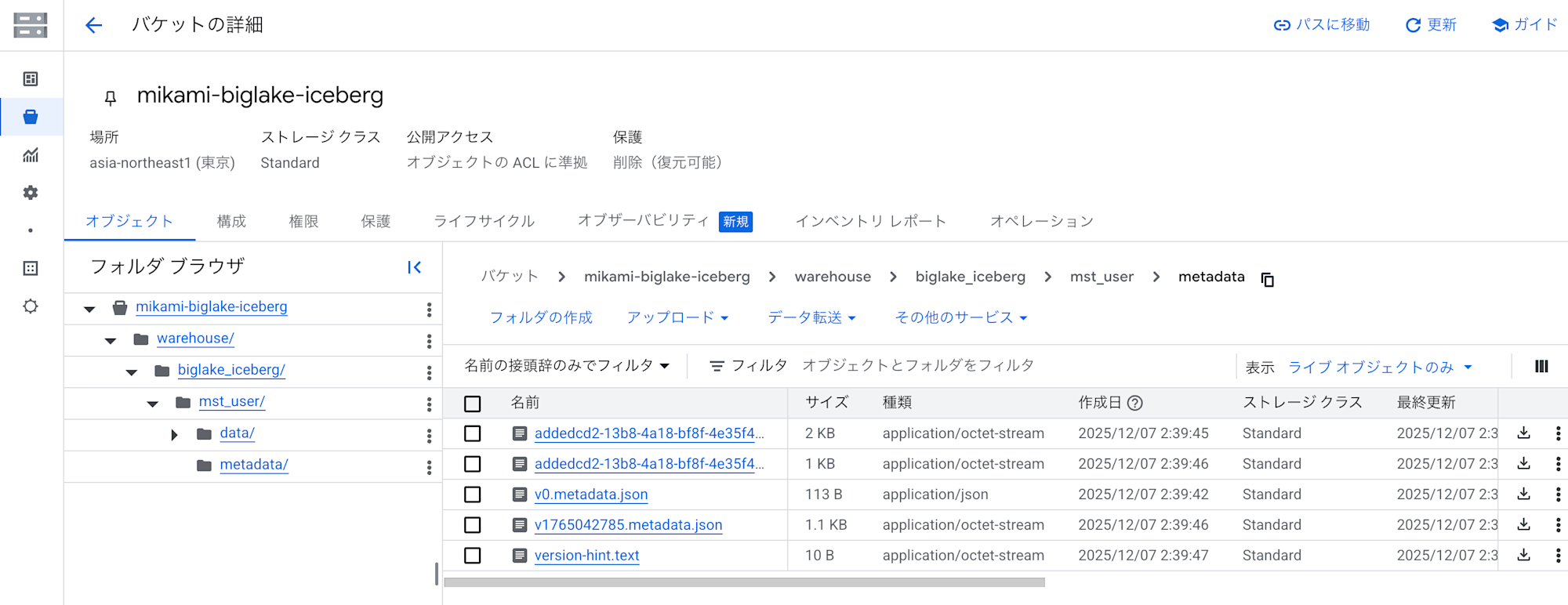
実データ(Parquet ファイル)とメタデータが指定した GCS バケットに出力されていることも確認できました。
Spark ジョブでカタログフェデレーションを実施
まず、Spark ジョブ実行用のサービスアカウントを作成します。
export SPARK_SA_NAME="spark-runner-sa"
export PROJECT_ID="[PROJECT_ID]"
gcloud iam service-accounts create $SPARK_SA_NAME --display-name="Spark Job Runner SA"
export SPARK_SA_EMAIL="$SPARK_SA_NAME@$PROJECT_ID.iam.gserviceaccount.com"
続いて以下のコマンドで、必要な権限を付与します。
gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \
--member="serviceAccount:$SPARK_SA_EMAIL" \
--role="roles/storage.objectAdmin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SPARK_SA_EMAIL" \
--role="roles/biglake.admin" \
--condition=None
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SPARK_SA_EMAIL" \
--role="roles/dataproc.worker" \
--condition=None
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SPARK_SA_EMAIL" \
--role="roles/bigquery.admin" \
--condition=None
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SPARK_SA_EMAIL" \
--role="roles/serviceusage.serviceUsageConsumer" \
--condition=None
ジョブで実行するスクリプト(blms_catalog_federation.py)を作成します。
cat > blms_catalog_federation.py << 'EOF'
from pyspark.sql import SparkSession
import google.auth
from google.auth.transport.requests import Request
# --- 設定 ---
project_id = "[PROJECT_ID]"
region = "asia-northeast1"
dataset_name = "biglake_iceberg"
table_name = "mst_user"
spark_catalog_name = "biglake"
bucket_name = "mikami-biglake-iceberg"
# --- 認証 ---
def get_auth_token():
scopes = ["https://www.googleapis.com/auth/cloud-platform"]
credentials, _ = google.auth.default(scopes=scopes)
credentials.refresh(Request())
return credentials.token
token = get_auth_token()
# --- URI設定 ---
catalog_uri = "https://biglake.googleapis.com/iceberg/v1/restcatalog"
warehouse_uri = f"bq://projects/{project_id}"
# --- Spark Session ---
spark = (SparkSession.builder
.appName("BigLake Final Job Fixed")
.config(f"spark.sql.catalog.{spark_catalog_name}", "org.apache.iceberg.spark.SparkCatalog")
.config(f"spark.sql.catalog.{spark_catalog_name}.type", "rest")
.config(f"spark.sql.catalog.{spark_catalog_name}.uri", catalog_uri)
.config(f"spark.sql.catalog.{spark_catalog_name}.warehouse", warehouse_uri)
.config(f"spark.sql.catalog.{spark_catalog_name}.header.Authorization", f"Bearer {token}")
.config(f"spark.sql.catalog.{spark_catalog_name}.header.X-Goog-User-Project", project_id)
.config(f"spark.sql.catalog.{spark_catalog_name}.io-impl", "org.apache.iceberg.hadoop.HadoopFileIO")
.config("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
.config("spark.hadoop.fs.AbstractFileSystem.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS")
.config("spark.hadoop.google.cloud.auth.service.account.enable", "true")
.config(f"spark.sql.catalog.{spark_catalog_name}.gcp_location", region)
.getOrCreate()
)
# --- 1. Namespace 設定 ---
namespace_location = f"gs://{bucket_name}/warehouse/{dataset_name}"
print(f"\n=== 1. Ensuring Namespace Location: {namespace_location} ===")
try:
spark.sql(f"""
CREATE NAMESPACE IF NOT EXISTS {spark_catalog_name}.{dataset_name}
LOCATION '{namespace_location}'
WITH DBPROPERTIES ('gcp-region' = '{region}')
""")
print("✅ CREATE NAMESPACE executed.")
except Exception as e:
print("❌ CREATE NAMESPACE Failed")
print(e)
# --- 2. USE & List ---
print(f"\n=== 2. Switching Namespace & Listing ===")
try:
# USE コマンド
spark.sql(f"USE {spark_catalog_name}.{dataset_name}")
print("✅ USE executed.")
print("\n--- Namespaces ---")
spark.sql(f"SHOW NAMESPACES IN {spark_catalog_name}").show(truncate=False)
print("\n--- Tables (in current namespace) ---")
spark.sql("SHOW TABLES").show(truncate=False)
except Exception as e:
print("❌ USE/LIST Failed")
print(e)
# --- 3. Reading Data ---
print(f"\n=== 3. Reading Table ({table_name}) ===")
try:
spark.sql(f"SELECT * FROM {table_name}").show()
print("✅ SELECT Success")
except Exception as e:
print("❌ SELECT Failed")
if hasattr(e, 'java_exception'):
print("!!! JAVA STACK TRACE !!!")
print(e.java_exception.toString())
# --- 4. Inserting Data (Write Test) ---
print(f"\n=== 4. Inserting Data (Write Test) ===")
try:
# 書き込みテスト
spark.sql(f"INSERT INTO {table_name} VALUES (888, 'Spark Insert via HadoopIO', current_timestamp())")
print("✅ INSERT Success")
print("--- Result after Insert ---")
spark.sql(f"SELECT * FROM {table_name} WHERE id = 888").show()
except Exception as e:
print("❌ INSERT Failed")
# BigQuery Managed Tableへの書き込みは制限される場合がありますが、エラー内容を確認します
print(e)
EOF
.config(f"spark.sql.catalog.{spark_catalog_name}.warehouse", warehouse_uri)
の warehouse_uri に bq://projects/PROJECT_ID/ を指定し、
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME LOCATION 'gs://BUCKET_NAME/NAMESPACE_NAME' WITH DBPROPERTIES ('gcp-region' = 'LOCATION');")
spark.sql("USE NAMESPACE_NAME;")
で BigQuery 用のカスタム Iceberg カタログとのフェデレーションを実施します。
カタログ連携後に BigQuery から書き込んだデータが参照できることを併せて確認します。
また念のため、Spark ジョブからのデータ書き込みはできないことも確認しておきます。
実行時に指定する spark.jars.packages を環境変数に設定して、
export ICEBERG_PKGS="org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1,org.apache.iceberg:iceberg-gcp:1.6.1"
Dataproc Serverless ジョブで実行します。
$ gcloud dataproc batches submit pyspark blms_catalog_federation.py \
--project=$PROJECT_ID \
--region=$REGION \
--batch="blms-catalog-federation-$(date +%s)" \
--service-account=$SPARK_SA_EMAIL \
--version=2.2 \
--properties="^#^spark.jars.packages=$ICEBERG_PKGS" \
--deps-bucket="gs://$BUCKET_NAME"
Batch [blms-catalog-federation-1765043777] submitted.
(省略)
=== 1. Ensuring Namespace Location: gs://mikami-biglake-iceberg/warehouse/biglake_iceberg ===
25/12/06 17:58:41 INFO CatalogUtil: Loading custom FileIO implementation: org.apache.iceberg.hadoop.HadoopFileIO
✅ CREATE NAMESPACE executed.
=== 2. Switching Namespace & Listing ===
✅ USE executed.
--- Namespaces ---
+--------------------------+
|namespace |
+--------------------------+
(省略)
|biglake_iceberg |
(省略)
+--------------------------+
only showing top 20 rows
--- Tables (in current namespace) ---
+---------------+---------+-----------+
|namespace |tableName|isTemporary|
+---------------+---------+-----------+
|biglake_iceberg|mst_user |false |
(省略)
+---------------+---------+-----------+
=== 3. Reading Table (mst_user) ===
(省略)
25/12/06 17:58:48 INFO SparkPartitioningAwareScan: Reporting UnknownPartitioning with 1 partition(s) for table biglake.biglake_iceberg.mst_user
+---+--------+--------------------+
| id| name| created_at|
+---+--------+--------------------+
| 1|Alice_BQ|2025-12-06 17:39:...|
+---+--------+--------------------+
✅ SELECT Success
=== 4. Inserting Data (Write Test) ===
(省略)
❌ INSERT Failed
An error occurred while calling o110.sql.
(省略)
Spark ジョブから BigQuery 管理の Iceberg テーブルデータが参照でき、INSERT はできないことが確認できました。
データを追加して Spark ジョブから参照できるか確認
BigQuery からデータ追加
SQL で BigQuery の Iceberg テーブルにデータを追加して、Spark ジョブから更新データが参照できるか確認してみます。
以下のコマンドで、データを追加しました。
export PROJECT_ID="[PROJECT_ID]"
export DATASET_NAME="biglake_iceberg"
export TABLE_NAME="mst_user"
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_NAME}.${TABLE_NAME}\` VALUES (2, 'Bob_BQ', CURRENT_TIMESTAMP())"
ちゃんと追加できたか確認してみます。
$ bq query --use_legacy_sql=false \
"SELECT * FROM \`${PROJECT_ID}.${DATASET_NAME}.${TABLE_NAME}\` ORDER BY id"
+----+----------+---------------------+
| id | name | created_at |
+----+----------+---------------------+
| 1 | Alice_BQ | 2025-12-06 17:39:43 |
| 2 | Bob_BQ | 2025-12-06 18:35:22 |
+----+----------+---------------------+
id = 2 のデータが追加されたことが確認できました。
Spark ジョブからデータを参照
以下の check_update.py スクリプトを作成し、Spark ジョブで実行します。
cat > check_update.py << 'EOF'
from pyspark.sql import SparkSession
import google.auth
from google.auth.transport.requests import Request
# --- 設定 ---
project_id = "[PROJECT_ID]"
region = "asia-northeast1"
dataset_name = "biglake_iceberg"
table_name = "mst_user"
spark_catalog_name = "biglake"
# --- 認証 ---
def get_auth_token():
scopes = ["https://www.googleapis.com/auth/cloud-platform"]
credentials, _ = google.auth.default(scopes=scopes)
credentials.refresh(Request())
return credentials.token
token = get_auth_token()
# --- URI設定 ---
catalog_uri = "https://biglake.googleapis.com/iceberg/v1/restcatalog"
warehouse_uri = f"bq://projects/{project_id}"
# --- Spark Session ---
spark = (SparkSession.builder
.appName("BigLake Check Update")
.config(f"spark.sql.catalog.{spark_catalog_name}", "org.apache.iceberg.spark.SparkCatalog")
.config(f"spark.sql.catalog.{spark_catalog_name}.type", "rest")
.config(f"spark.sql.catalog.{spark_catalog_name}.uri", catalog_uri)
.config(f"spark.sql.catalog.{spark_catalog_name}.warehouse", warehouse_uri)
.config(f"spark.sql.catalog.{spark_catalog_name}.header.Authorization", f"Bearer {token}")
.config(f"spark.sql.catalog.{spark_catalog_name}.header.X-Goog-User-Project", project_id)
.config(f"spark.sql.catalog.{spark_catalog_name}.io-impl", "org.apache.iceberg.hadoop.HadoopFileIO")
.config("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
.config("spark.hadoop.fs.AbstractFileSystem.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS")
.config("spark.hadoop.google.cloud.auth.service.account.enable", "true")
.config(f"spark.sql.catalog.{spark_catalog_name}.gcp_location", region)
.getOrCreate()
)
spark.sparkContext.setLogLevel("WARN")
target_table = f"{spark_catalog_name}.{dataset_name}.{table_name}"
print(f"\n=== Reading Table: {target_table} ===")
try:
spark.sql(f"REFRESH TABLE {target_table}")
spark.sql(f"SELECT * FROM {target_table} ORDER BY id").show(truncate=False)
print("✅ SELECT Success")
except Exception as e:
print("❌ SELECT Failed")
print(e)
EOF
実行します。
$ gcloud dataproc batches submit pyspark check_update.py \
--project=$PROJECT_ID \
--region=$REGION \
--batch="check-no-export-$(date +%s)" \
--service-account=$SPARK_SA_EMAIL \
--version=2.2 \
--properties="^#^spark.jars.packages=$ICEBERG_PKGS" \
--deps-bucket="gs://$BUCKET_NAME"
Batch [check-no-export-1765046218] submitted.
(省略)
=== Reading Table: biglake.biglake_iceberg.mst_user ===
(省略)
+---+--------+--------------------------+
|id |name |created_at |
+---+--------+--------------------------+
|1 |Alice_BQ|2025-12-06 17:39:43.617556|
+---+--------+--------------------------+
✅ SELECT Success
Batch [check-no-export-1765046218] finished.
(省略)
初めに INSERT した id = 1 のデータは参照できますが、追加した id = 2 のデータが確認できません。
メタデータを更新
BigQuery で EXPORT TABLE METADATA を実行して、メタデータを更新します。
bq query --use_legacy_sql=false \
"EXPORT TABLE METADATA FROM \`${PROJECT_ID}.${DATASET_NAME}.${TABLE_NAME}\`"
再度 Spark ジョブからデータを参照
Spark ジョブを再度実行して、追加したデータが参照できるようになったか確認します。
$ gcloud dataproc batches submit pyspark check_update.py \
--project=$PROJECT_ID \
--region=$REGION \
--batch="check-with-export-$(date +%s)" \
--service-account=$SPARK_SA_EMAIL \
--version=2.2 \
--properties="^#^spark.jars.packages=$ICEBERG_PKGS" \
--deps-bucket="gs://$BUCKET_NAME"
Batch [check-with-export-1765046510] submitted.
(省略)
=== Reading Table: biglake.biglake_iceberg.mst_user ===
(省略)
+---+--------+--------------------------+
|id |name |created_at |
+---+--------+--------------------------+
|1 |Alice_BQ|2025-12-06 17:39:43.617556|
|2 |Bob_BQ |2025-12-06 18:35:22.489289|
+---+--------+--------------------------+
✅ SELECT Success
Batch [check-with-export-1765046510] finished.
(省略)
無事、追加した id = 2のデータも参照できるようになりました。
つまづいたところ
1. BigLake Metastore カタログ作成
はじめ、任意のカタログ名を指定していたので、エラーが発生しました。。
$ gcloud alpha biglake iceberg catalogs create sample_catalog \
--project=$PROJECT_ID \
--catalog-type=gcs-bucket
Created catalog [projects/[PROJECT_ID]/catalogs/sample_catalog].
ERROR: (gcloud.alpha.biglake.iceberg.catalogs.create) PERMISSION_DENIED: RPC error. This command is authenticated as [ユーザーアカウント] which is the active account specified by the [core/account] property
※エラーメッセージ内ユーザーアカウント名は伏せ字に変更しています。
カタログ名は GCS バケット名と一致している必要があるようです。
カタログ作成時に GCS バケット名を指定していないので、カタログ名と一致するバケットをカタログバケットとみなす仕様のようです。
権限エラーのようなエラーメッセージだったので、「何か組織レベルの権限が必要?」と少し悩みました。
2. Iceberg REST カタログフェデレーション
BigQuery 管理の Iceberg テーブルを作成し、そのまま Spark ジョブで参照しようとしたところ、NAMESPACE(BigQueryのデータセット)は認識するものの、テーブルが認識されませんでした。。
NAMESPACE だけではなくテーブルも Iceberg REST カタログに明示的に連携する必要があるのか?など、しばらく試行錯誤してました。
BigQuery で Iceberg テーブルを作成・データ追加した後には、EXPORT TABLE METADATA でメタデータをエクスポートする必要がありました。
まとめ(所感)
BigQuery 管理の Iceberg テーブルを、Iceberg REST カタログから参照できることが確認できました。
Iceberg テーブルというと、マルチクラウド・マルチプラットフォームで利用できる便利なテーブル、という印象ですが、カタログ差異でデータが参照できなかったり、参照はできるもののメタデータファイルを更新しないと最新データが反映されなかったり、なかなか一筋縄ではいかないのが現状です。
また、Apache Iceberg と Delta Lake のように、同じオープンテーブルフォーマットであっても、仕様やアーキテクチャが異なるフォーマットも存在します。
これらの互換性向上や規格統一により、もっと簡単にマルチクラウド・マルチプラットフォーム連携が実現できるようになる未来を期待しています!
参考
- Introduction to BigLake metastore | BigLake ドキュメント
- Use the BigLake metastore Iceberg REST catalog | BigLake ドキュメント
- gcloud alpha biglake iceberg | Google Cloud SDK リファレンス
- BigLake API | BigQuery API リファレンス
- Iceberg REST カタログが BigLake Metastore で GA サポート開始、オープンデータの相互運用性を実現 | Google Cloud ブログ
- Apache Iceberg 用の BigQuery テーブルを操作してみる #cm_google_cloud_adcal_2024 | DevelopersIO
- BigQuery tables for Apache Icebergで定義されたテーブルをSnowflakeのIceberg Tableとしてクエリできるようにしてみた | DevelopersIO
- Google CloudのIceberg「BigLake tables for Apache Iceberg in BigQuery」を試しつつ気になるトピックを調べてみた | DevelopersIO
- Configure a catalog integration for Apache Iceberg™ REST catalogs | Snowflake ドキュメント
- Getting Started with Snowflake and BigQuery via Iceberg | Snowflake 開発者ガイド










