
【BigQuery】S3 Tables→BigQueryのデータ転送にJWTを使ってセキュアに実装したい
はじめに
データ事業本部の川中子(かわなご)です。
AWSのGlueカタログで管理しているテーブルのデータをBigQueryに連携したかったのですが、
現状では様々な条件により実現が困難だったため、代替案を記事にしてみました。
S3で管理されているデータであれば、BigQuery Omniを使うことで直接BigQueryから
クエリが実行可能となりますが、こちらは現在東京リージョンでは一般提供されていません。
今回は、GoogleサービスアカウントのJWTトークンを使ってAWS IAMロールをAssumeRoleし、
AWSのGlueカタログからGoogle CloudのBigQueryへのデータ連携を実装してみました。
なお認証の方法については以下の記事を参考にさせていただきました。
全体の構成について
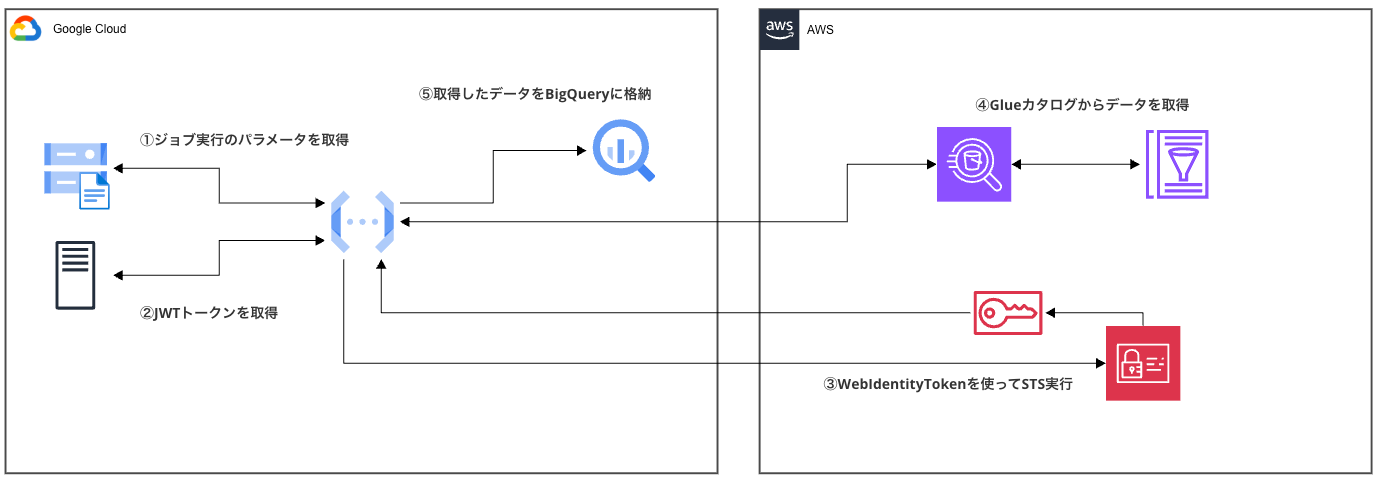
今回実装した構成の大まかな流れは以下のようになります。
- 設定読み込み: GCSバケットから設定ファイル(config.yaml)を取得
- JWT取得: GoogleメタデータサーバーからサービスアカウントのIdentity Tokenを取得
- AWS認証: JWTトークンを使ってAWS IAMロールをAssumeRole
- Athenaクエリ実行: 取得した認証情報でAthenaクエリを実行
- データ取得: Athenaからクエリ結果を取得
- BigQuery挿入: 取得したデータをBigQueryテーブルに挿入
今回実装する認証方式は、GoogleサービスアカウントのIdentity Tokenを使って
AWS側のIAMロールをAssumeRoleする仕組みです。
具体的には、Cloud Functions実行時にGoogleのメタデータサーバーから取得したJWTトークンを
AWS STSの AssumeRoleWithWebIdentity APIに渡すことで、一時的なAWS認証情報を取得します。
この方式であれば、AWSのアクセスキーなどをGoogle Cloud側で保管する必要がなく、
1時間という期限付きのトークンでセキュリティリスクも軽減できる点がメリットになります。
検証準備
今回の検証で作成するアセットは以下のとおりです。
この中でGlue関連の資材のみ、既存のアセットを使用しています。
- AWS側
- IAMロール:Cloud Functionsが引き受ける用のロール
- Glue データベース/テーブル:ソースデータになるテーブル(今回はVIEWを使用)
- Google Cloud側
- サービスアカウント:Cloud Functionsに使用するサービスアカウント
- BigQuery データセット/テーブル:ターゲットになるテーブル
- GCSバケット:ジョブの設定ファイルを保管するためのバケット
- Cloud Functions:処理の主体となるジョブ
データソースの確認
まず、ソースとなるAthenaのVIEWの状態を確認しておきます。
SELECT * FROM active_records_view
+---------+---------------+-----------+-------------+
| int_col | string_col | float_col | boolean_col |
+---------+---------------+-----------+-------------+
| 1001 | sample_data_1 | 3.14159 | true |
| 1003 | test_string_3 | 1.41421 | true |
| 1005 | demo_value_5 | 2.23607 | true |
+---------+---------------+-----------+-------------+
ビューには3行のテストデータが含まれています。
今回の検証では、このデータがBigQueryに正しく転送されるかを検証していきます。
ステップ1:GCPサービスアカウントとリソース作成
まず、GCP側のリソースを作成していきます。
■サービスアカウントの作成
gcloud iam service-accounts create cm-kawanago-sa \
--display-name="Kawanago Test Service Account" \
--description="Service account for Athena to BigQuery data transfer"
作成したサービスアカウントの一意IDを確認しておきます。
この一意IDはAWSのIAMロールの信頼関係ポリシー(oaudと sub条件)で使用します。
gcloud iam service-accounts describe [SERVICE_ACCOUNT_EMAIL] \
--format="value(uniqueId)"
# 出力例
[SERVICE_ACCOUNT_UNIQUE_ID:123456789012345678901]
■BigQueryデータセットとテーブルの作成
データ転送先のBigQueryテーブルも作成しておきます。
# データセット作成
bq mk --dataset [GCP_PROJECT_ID]:cm_kawanago
# テーブル作成
bq mk --table [GCP_PROJECT_ID]:cm_kawanago.tbl_from_aws_view \
int_col:INTEGER,string_col:STRING,float_col:FLOAT,boolean_col:BOOLEAN
■GCSバケットと設定ファイルの準備
設定ファイルを格納するGCSバケットを作成します。
gsutil mb -p [GCP_PROJECT_ID] -c STANDARD \
-l asia-northeast1 gs://cm-kawanago-athena-bigquery-config
作成したバケットに設定ファイル config.yamlをアップロードしておきます。
gsutil cp config.yaml gs://cm-kawanago-athena-bigquery-config/
設定ファイルの内容は以下のようになります。
# AWS設定
aws:
account_id: "[AWS_ACCOUNT_ID]"
region: "us-east-1"
iam_role_name: "cm-kawanago-google-jwt-role"
# Athena設定
athena:
workgroup: "primary"
catalog: "AwsDataCatalog" # defaultカタログ
# GCP設定
gcp:
project_id: "[GCP_PROJECT_ID]"
# BigQuery設定
bigquery:
dataset_id: "cm_kawanago"
table_id: "tbl_from_aws_view"
ステップ2:IAMロール設定
次に、GoogleサービスアカウントからのJWT認証を受け入れるAWS側の設定を行います。
■IAMロールの作成
aws iam create-role \
--role-name cm-kawanago-google-jwt-role \
--assume-role-policy-document file://aws-iam-trust-policy.json
信頼関係ポリシーでは、先ほど確認したサービスアカウントIDをConditionに設定し、
Principalには"Federated": "accounts.google.com" を指定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "accounts.google.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"accounts.google.com:oaud": "sts.amazonaws.com",
"accounts.google.com:sub": "[SERVICE_ACCOUNT_UNIQUE_ID]"
}
}
}
]
}
■IAMロールへの権限付与
今回はあくまでも一時的な検証として、管理者権限を付与しておきます。
aws iam attach-role-policy \
--role-name cm-kawanago-google-jwt-role \
--policy-arn arn:aws:iam::aws:policy/AdministratorAccess
ステップ3:Cloud Functionsの実装
本体となるPythonアプリケーションを実装していきます。
■依存関係の設定
まず、必要なライブラリをrequirements.txtに定義します。
functions-framework==3.5.0
boto3==1.34.69
google-cloud-bigquery==3.17.2
google-cloud-storage==2.14.0
pyyaml==6.0.1
■メイン関数の実装
メインとなる関数を以下のように作成しました。
import json
import time
import yaml
import urllib.request
import urllib.parse
from datetime import datetime
import functions_framework
import boto3
from google.cloud import bigquery
from google.cloud import storage
@functions_framework.http
def athena_to_bigquery(request):
"""
Athenaからデータを取得してBigQueryに挿入する
"""
try:
# 設定ファイル読み込み
config = load_config()
# AWS認証
credentials = assume_aws_role(config)
# Athenaクエリ実行
headers, data = execute_athena_query(credentials, config)
# BigQueryへ挿入
row_count = insert_to_bigquery(headers, data, config)
return json.dumps({
'success': True,
'message': f'Successfully transferred {row_count} rows from Athena to BigQuery',
'timestamp': datetime.utcnow().isoformat()
}), 200, {'Content-Type': 'application/json'}
except Exception as e:
return json.dumps({
'success': False,
'error': str(e),
'timestamp': datetime.utcnow().isoformat()
}), 500, {'Content-Type': 'application/json'}
■JWT取得機能の実装
JWTトークン取得の機能は以下のようになっています。
def get_google_identity_token():
"""Google Identity Token取得"""
try:
metadata_server = 'http://metadata.google.internal/computeMetadata/v1/'
token_request_url = metadata_server + 'instance/service-accounts/default/identity'
token_request_headers = {'Metadata-Flavor': 'Google'}
audience = 'sts.amazonaws.com'
params = {'audience': audience, 'format': 'full', 'include_email': 'true'}
url = f"{token_request_url}?{urllib.parse.urlencode(params)}"
req = urllib.request.Request(url, headers=token_request_headers)
with urllib.request.urlopen(req) as response:
identity_token = response.read().decode('utf-8')
return identity_token
except Exception as e:
raise Exception(f"JWT取得エラー: {e}")
この実装では、GoogleメタデータサーバーからJWTを取得しています。
メタデータサーバーは、Google Cloud上で動作するサービスが、
自身に紐付けられたサービスアカウントの情報を取得するための内部エンドポイントです。
audienceにsts.amazonaws.comを指定することで、
AWS側の信頼関係ポリシーのoaud条件と合致させ、よりセキュアな認証を行っています。
■AWS認証機能の実装
取得したJWTトークンを使ってAWS IAMロールをAssumeRoleします。
def assume_aws_role(config):
"""AWS IAMロールを引き受ける"""
jwt_token = get_google_identity_token()
sts_client = boto3.client('sts', region_name=config['aws']['region'])
role_arn = f"arn:aws:iam::{config['aws']['account_id']}:role/{config['aws']['iam_role_name']}"
response = sts_client.assume_role_with_web_identity(
RoleArn=role_arn,
RoleSessionName='athena-bigquery-transfer',
WebIdentityToken=jwt_token
)
return response['Credentials']
ステップ4:Cloud Functionsのデプロイ
実装が完了したら、Cloud Functionsにデプロイします。
gcloud functions deploy athena-to-bigquery \
--gen2 \
--runtime=python311 \
--region=asia-northeast1 \
--source=athena-to-bigquery-function \
--entry-point=athena_to_bigquery \
--trigger-http \
--service-account=[SERVICE_ACCOUNT_EMAIL] \
--allow-unauthenticated
結果
動作確認
デプロイしたCloud Functionsを実行してみます。
curl -X POST https://[CLOUD_FUNCTIONS_ENDPOINT]
成功すると以下のようなレスポンスが返ってきます。
{
"success": true,
"message": "Successfully transferred 3 rows from Athena to BigQuery",
"timestamp": "2025-07-24T00:48:26.385817"
}
BigQueryでの確認
BigQueryのテーブルを確認すると、VIEWで確認した3行分のレコードが格納されています。
これでAthenaのVIEWから、BigQueryテーブルにデータを転送できることが確認できました。
SELECT * FROM `[GCP_PROJECT_ID].cm_kawanago.tbl_from_aws_view`
実行結果:
+---------+---------------+-----------+-------------+
| int_col | string_col | float_col | boolean_col |
+---------+---------------+-----------+-------------+
| 1001 | sample_data_1 | 3.14159 | true |
| 1003 | test_string_3 | 1.41421 | true |
| 1005 | demo_value_5 | 2.23607 | true |
+---------+---------------+-----------+-------------+
まとめ
今回は、GoogleサービスアカウントのJWTトークンを使用して、
AWSのGlueカタログからGoogle CloudのBigQueryへのデータ転送を実装しました。
この構成ではAWSとGoogle Cloudの両方でコストが発生するため注意が必要です。
Google Cloudのリソースで完結したい場合には、BigQuery OmniのGAを待つ必要がありますね。
なお今回データを参照したAWSのVIEWは、S3 Tablesのテーブルを参照しているため、
LakeFormationで正しく権限を設定すれば、S3 Tables上のデータを直接連携することも可能です。
最後まで記事をお読みいただきありがとうございました。
少しでも参考になれば幸いです。










