
BigQuery テーブル作成イベントで、description の日本語をカラム名にしたビューをバッチ処理で作成してみた。
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、みかみです。
好きな童謡はやぎさんゆうびんです。
自分で食べちゃったのに「しーかたがないので」お手紙書いちゃう行動力!エンドレスなほのぼの感がなんとも。
やりたいこと
- BigQuery データを利用する時に、日本語名でアクセスしたい
- BigQuery テーブルカラム名は日本語にしたくない
- BigQuery にテーブルが作成されたら、description の日本語をカラム名にしたビューを自動で作成したい
データ利用者からすると、データ参照では日本語の項目の方が使いやすいケースも多いのではないかと思います。
BigQuery では日本語カラム名でテーブルやビューを作成できます。
とはいえ、カラム名が日本語の場合、SQLのカラム名をバッククォートでくくる必要があったり、バッチ処理および運用保守で扱うには少し手間がかかります。
バッチ処理で description に日本語を持つテーブルを作成した後に、description をカラム名としたビューを作成したら良いのでは?
とはいえ、毎回手動でビューを作成するのは手間がかかって大変です。
では、テーブル作成イベントをトリガにバッチ処理でビュー作成できたら便利では?
本ブログでは、Dataform から BigQuery テーブルを作成するケースを想定しています。
図にするとこんな感じ。
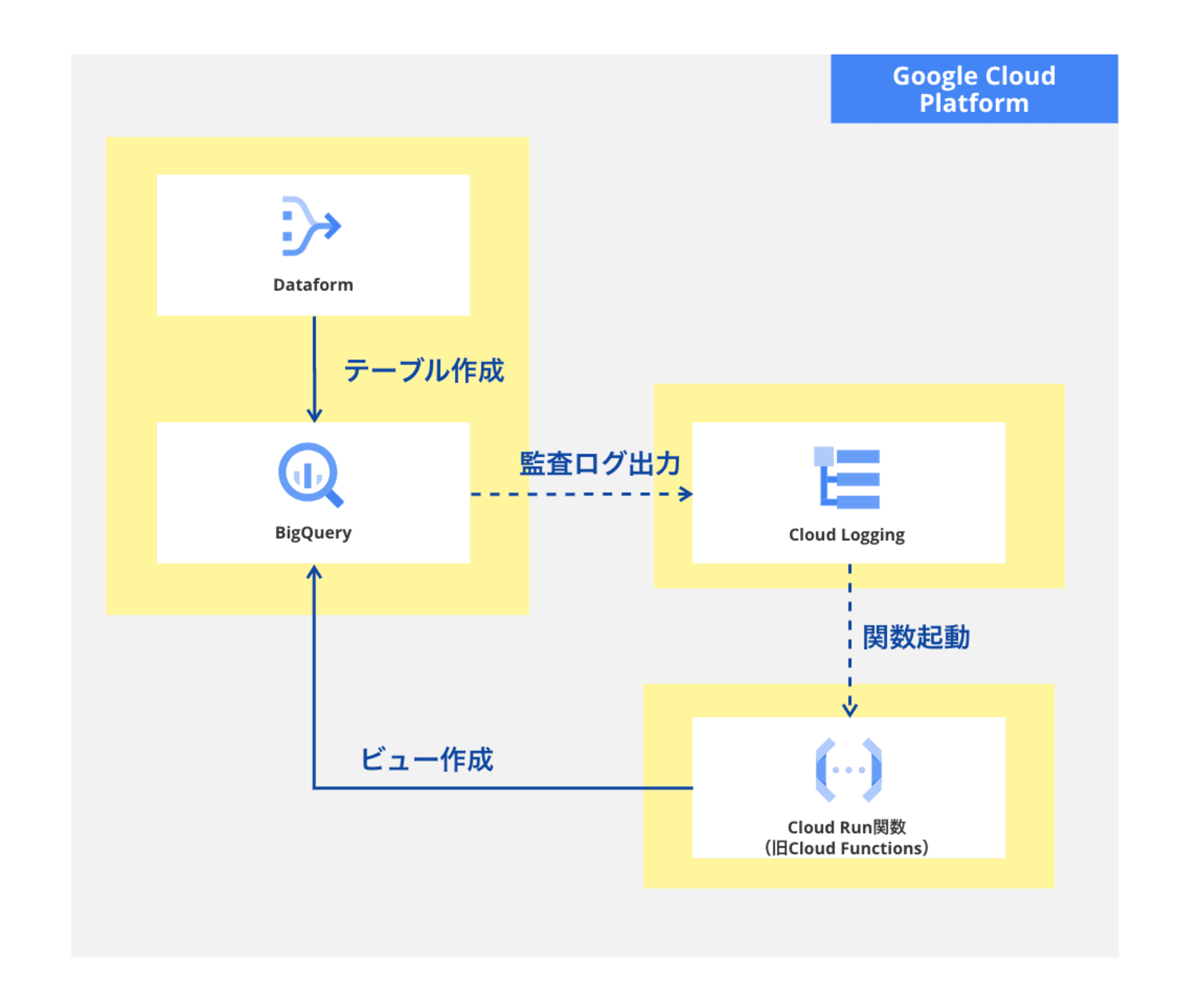
なお、カラム名の日本語サポートは、2024/09/20現在まだプレビューの機能なので、ご利用の際にはご留意ください。
前提
Google Cloud SDK(gcloud コマンド)の実行環境は準備済みであるものとします。 本エントリでは、Cloud Shell を使用しました。
また、BigQuery や Dataform など各サービス操作に必要な API の有効化と必要な権限は付与済みです。
Cloud Run Functions 実行用のサービスアカウントは前回作成したものを流用するので、サービスアカウント作成手順は省略します。
※本ブログ処理内容では roles/dataplex.admin は不要です。
なお、文中、プロジェクトIDなど一部の文字は伏字に変更しています。
Dataform 実装
以下の Dataform コードを実装済みです。
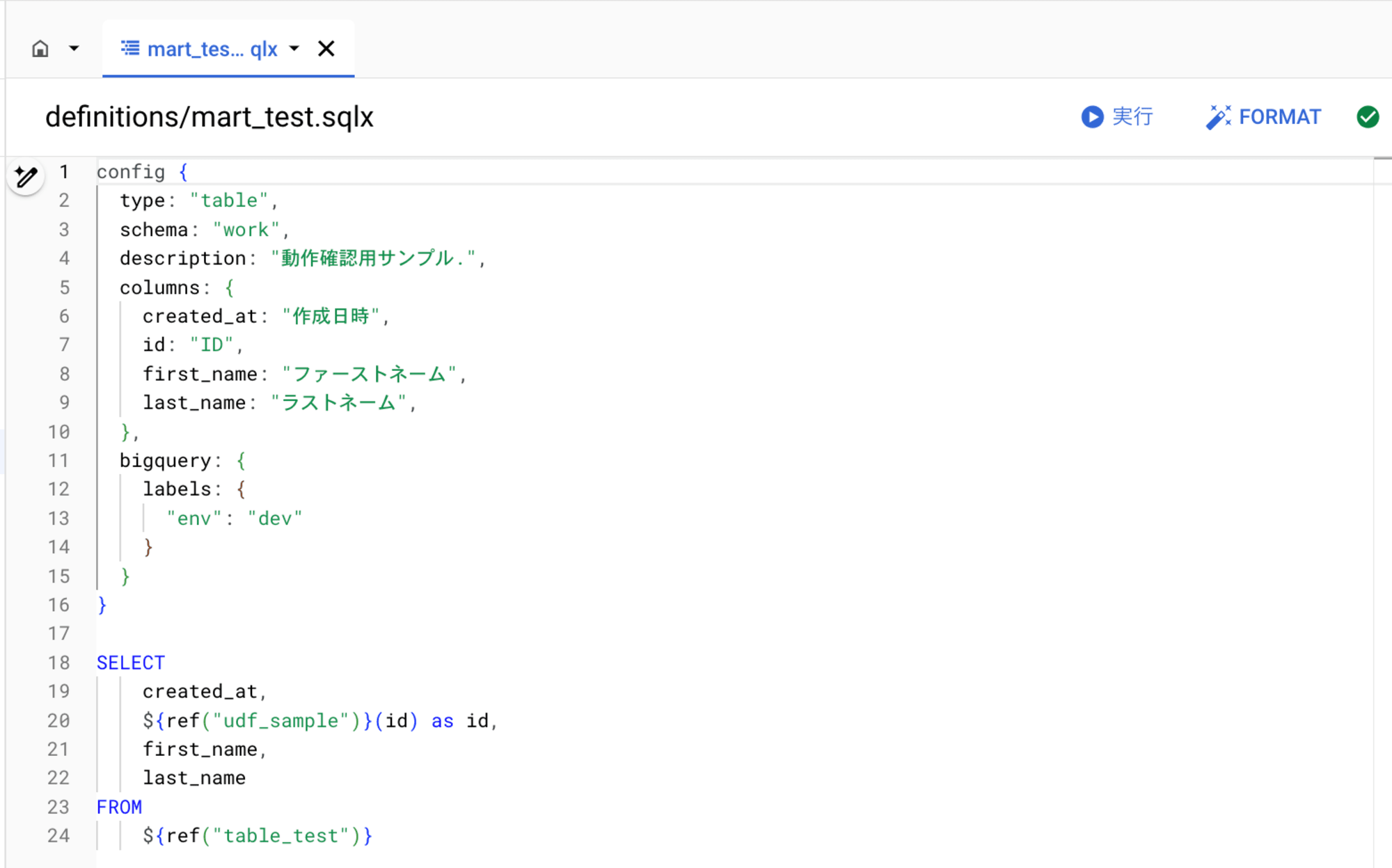
work.table_test を参照して、日本語 description 付きの work.mart_test を作成します。
Cloud Run 関数をデプロイ
Python コードを準備
以下のPythonコードを、main.py というファイル名で保存しました。
from google.cloud import bigquery
import functions_framework
import os
import time
# INFORMATION_SCHEMAからカラムとdescriptionを取得するためのテンプレート
query_template = """
SELECT
c.column_name,
c.data_type,
c.is_nullable,
cf.description,
c.ordinal_position,
cf.field_path
FROM
`{project_id}.{dataset_id}.INFORMATION_SCHEMA.COLUMNS` AS c
LEFT JOIN
`{project_id}.{dataset_id}.INFORMATION_SCHEMA.COLUMN_FIELD_PATHS` AS cf
ON
c.table_catalog = cf.table_catalog
AND c.table_schema = cf.table_schema
AND c.table_name = cf.table_name
AND c.column_name = cf.column_name
WHERE
c.table_name = '{table_id}'
ORDER BY
c.ordinal_position
"""
# ビューのSQLを作成するためのテンプレート
view_sql_template = """
CREATE OR REPLACE VIEW `{project_id}.{dataset_id}.{view_id}` AS
SELECT
{columns_sql}
FROM
`{project_id}.{dataset_id}.{table_id}`
"""
def create_view(project_id, dataset_id, table_id):
client = bigquery.Client()
# カラム情報取得SQL作成
query = query_template.format(project_id=project_id, dataset_id=dataset_id, table_id=table_id)
# クエリを実行
query_job = client.query(query)
results = query_job.result()
# カラム名とdescriptionを取得
columns = []
has_nested_structure = False
missing_description = False
for row in results:
column_name = row['column_name']
data_type = row['data_type']
description = row['description']
# ネスト構造を持つデータ型がある場合は終了
if 'STRUCT' in data_type or 'RECORD' in data_type or 'ARRAY' in data_type or 'JSON' in data_type:
has_nested_structure = True
break
# descriptionがないカラムがある場合は終了
if not description:
missing_description = True
break
columns.append(f"`{column_name}` AS `{description}`")
# ネスト構造がある場合やdescriptionがないカラムがある場合は終了
if has_nested_structure:
print("[functions]The table contains nested structures. View creation aborted.")
return
elif missing_description:
print("[functions]One or more columns are missing descriptions. View creation aborted.")
return
else:
# CREATE VIEW SQL作成
view_id = f"v_{table_id}"
columns_sql = ",\n ".join(columns)
view_sql = view_sql_template.format(project_id=project_id, dataset_id=dataset_id, table_id=table_id, view_id=view_id, columns_sql=columns_sql)
# ビューを作成
client.query(view_sql).result()
print(f"[functions]View `{view_id}` created successfully.")
return
@functions_framework.cloud_event
def main(cloudevent):
print(f"Event type: {cloudevent['type']}")
if 'subject' in cloudevent:
print(f"Subject: {cloudevent['subject']}")
# 環境変数チェック
PROJECT_ID = os.getenv('PROJECT_ID')
SA_DATAFORM = os.getenv('SA_DATAFORM')
if not PROJECT_ID or not SA_DATAFORM:
raise Exception('Invalid env val.')
# イベントデータチェック
payload = cloudevent.data.get("protoPayload")
if not payload:
return
principalEmail = payload.get('authenticationInfo', {}).get('principalEmail', None)
if principalEmail != SA_DATAFORM:
# Dataformからのクエリじゃない場合は処理せず終了
return
jobChange = payload.get('metadata', {}).get('jobChange', None)
if not jobChange:
return
statementType = jobChange.get('job', {}).get('jobConfig', {}).get('queryConfig', {}).get('statementType', None)
if statementType != 'CREATE_TABLE_AS_SELECT':
return
statementType = jobChange.get('job', {}).get('jobConfig', {}).get('queryConfig', {}).get('statementType', None)
destinationTable = jobChange.get('job', {}).get('jobConfig', {}).get('queryConfig', {}).get('destinationTable', None)
dst_dataset = destinationTable.split('/')[3]
dst_table = destinationTable.split('/')[5]
print(f"[functions] dst_dataset: {dst_dataset} / dst_table: {dst_table}")
# TODO: すぐに実行するとdescription情報が取れないことがあったので、10秒待機
time.sleep(10)
create_view(PROJECT_ID, dst_dataset, dst_table)
処理実行に必要な情報を環境変数から取得し、トリガイベントの監査ログ内容をチェックします。
テーブル作成イベントだった場合は、INFORMATION_SCHEMA からテーブルカラムと description 情報を取得し、ビュー作成クエリを実行します。
RECORD や JSON 型など、ネスト構造のデータ型をテーブルには対応していません(ビュー作成せず終了します)。
また、description がないカラムがあった場合も、ビュー作成はせず終了します。
また、以下を requirements.txt というファイル名で保存しました。
functions-framework==3.*
google-cloud-bigquery>=3.25.0
デプロイ
先ほどのファイルを保存したのと同じディレクトリで、以下のコマンドを実行して Cloud Run Functions をデプロイしました。
gcloud functions deploy create_view \
--gen2 \
--region asia-northeast1 \
--runtime python312 \
--entry-point=main \
--trigger-event-filters="type=google.cloud.audit.log.v1.written" \
--trigger-event-filters="serviceName=bigquery.googleapis.com" \
--trigger-event-filters="methodName=google.cloud.bigquery.v2.JobService.InsertJob" \
--trigger-location=asia-northeast1 \
--service-account=sa-functions@[PROJECT_ID].iam.gserviceaccount.com \
--trigger-service-account=sa-functions@[PROJECT_ID].iam.gserviceaccount.com \
--set-env-vars PROJECT_ID=[PROJECT_ID],SA_DATAFORM=service-[PROJECT_NO]@gcp-sa-dataform.iam.gserviceaccount.com
実行
Dataform を実行して、テーブル作成後にビューが作成されるか確認します。
Dataform 実行後、Cloud Run Functions のログを確認してみると

ビューが作成できたようです。
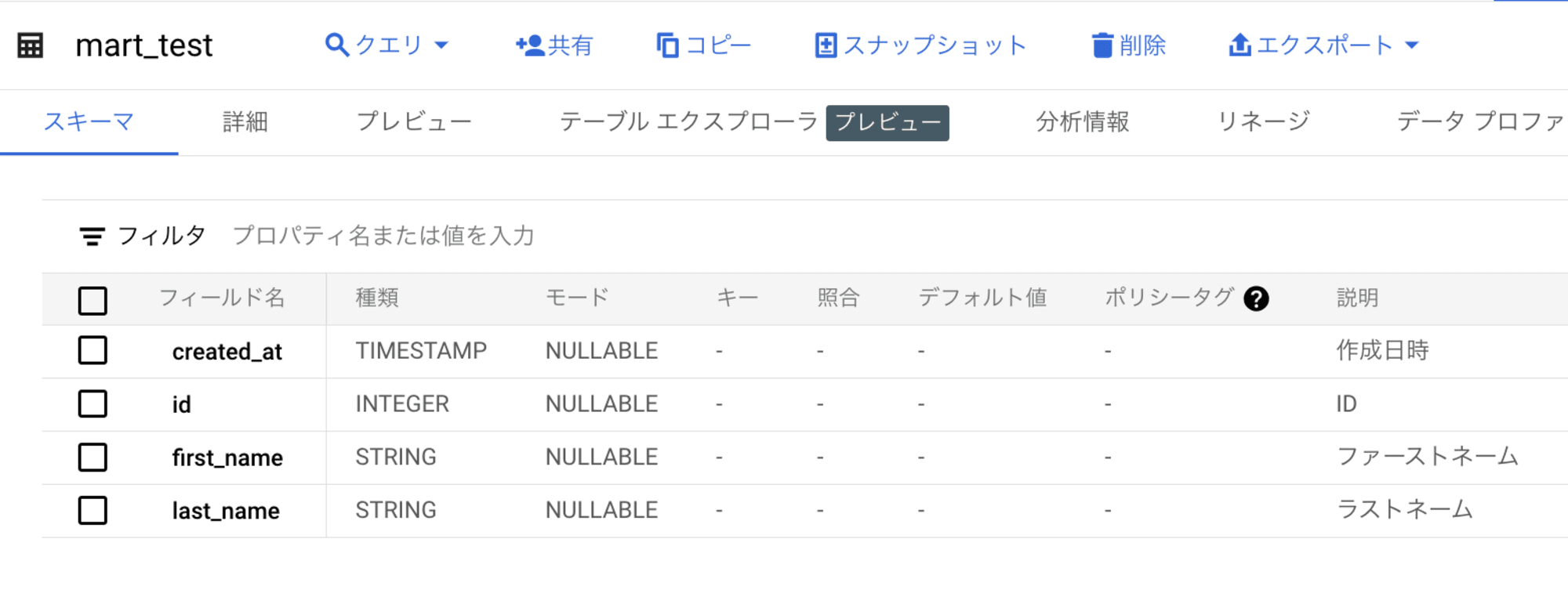
BigQuery コンソールからも確認してみます。
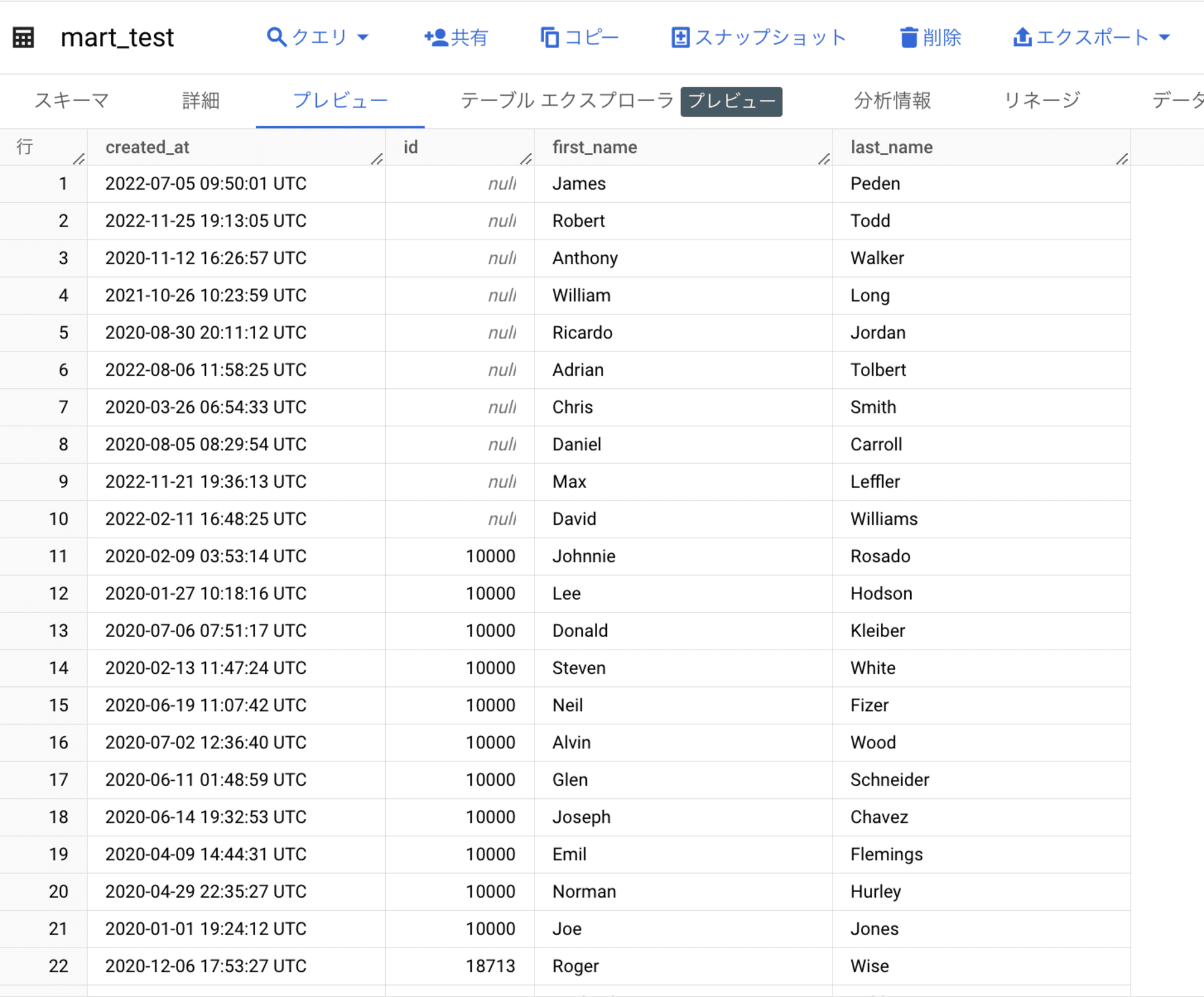
以下、Dataform から作成した、mart_test テーブルのスキーマと格納データです。
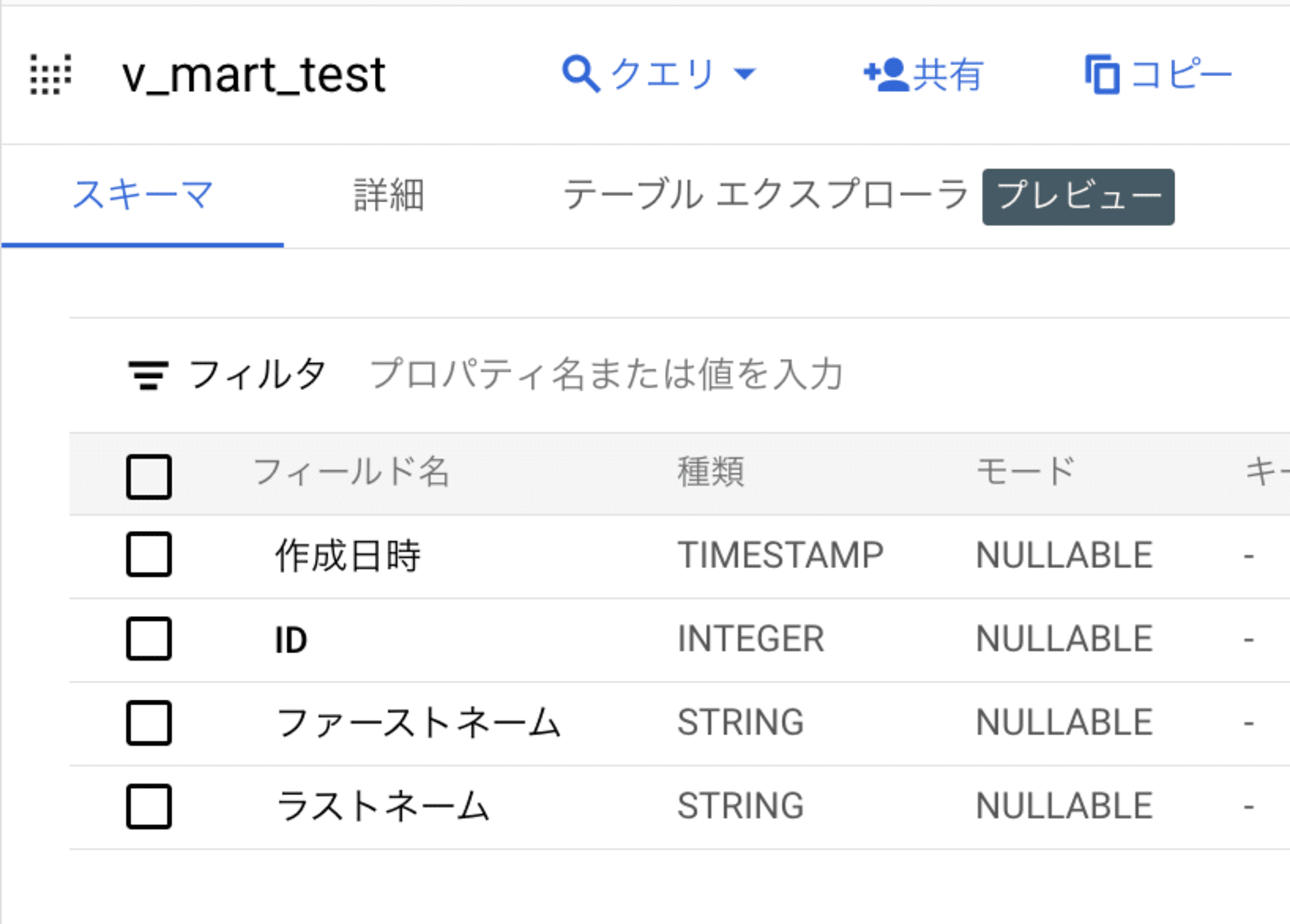
Cloud Run Functions から作成されたビューも確認してみます。
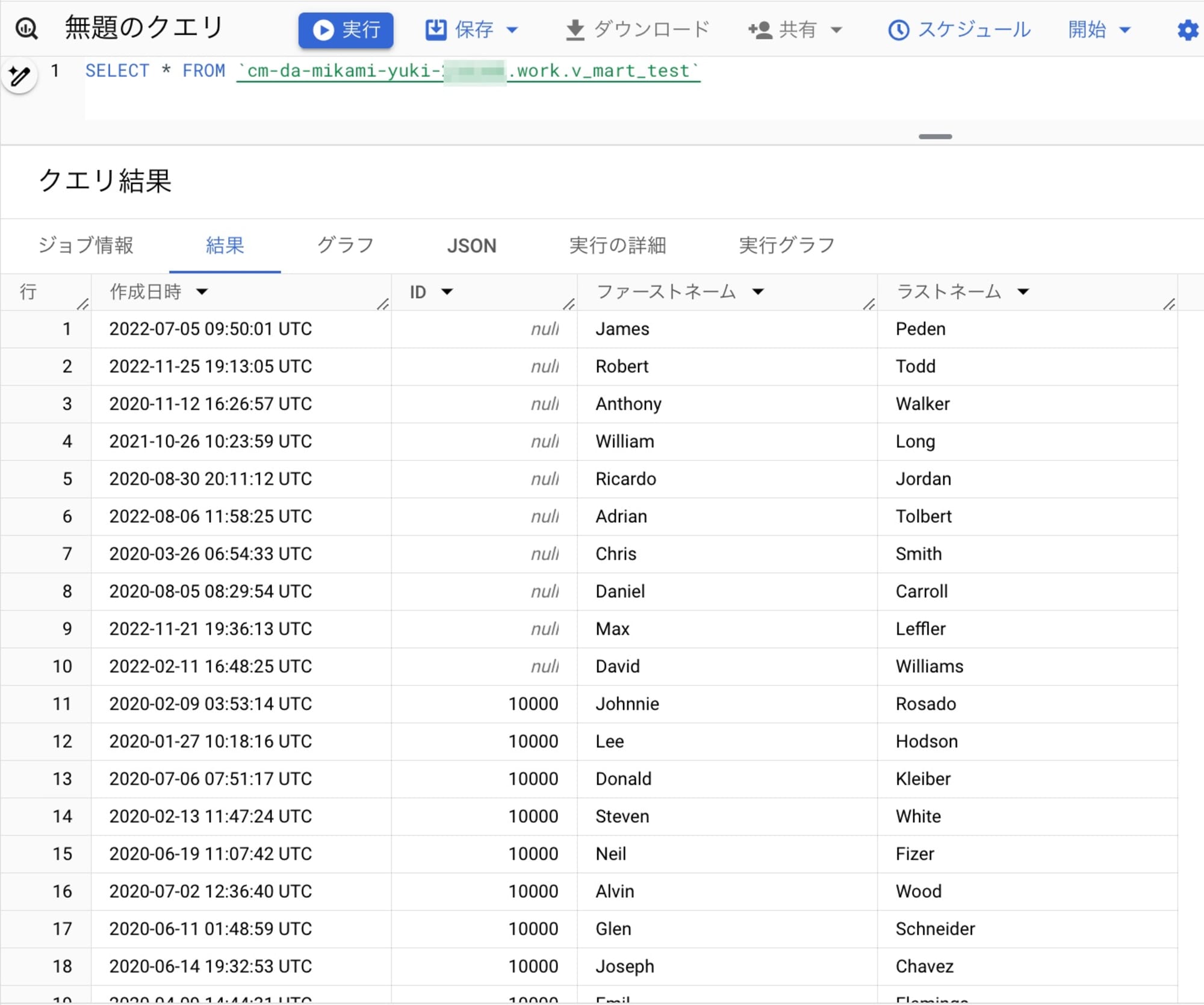
想定通り、テーブルデータを日本語カラムのビューから参照することができました。
まとめ(所感)
前回に引き続き、Dataform からのテーブル作成(再作成)ケースを想定していますが、Functions コードの Dataform サービスアカウントチェック部分を変更すれば、SQL 実行元にかかわらず Functions を起動することができます。
また、前回&今回はテーブル作成(再作成)イベントをトリガに処理実行していますが、こちらも、Functions コードのイベントチェック部分を変更すれば、データ INSERT や UPDATE イベントなどをトリガに任意の処理を実行することが可能です。
BigQuery の更新イベントをトリガに、Cloud Run Functions を簡単に実行することができます。
Cloud Run Functions で他のサービスと連携するコードを実装すれば、データの自動処理やリアルタイム分析など、さまざまな処理が可能になります。
必要に応じて、ぜひご活用ください。









