
BigQuery tables for Apache Icebergで定義されたテーブルをSnowflakeのIceberg Tableとしてクエリできるようにしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
さがらです。
先日、海外のMediumで下記の記事が投稿されていました。端的に述べると「BigQueryでのみエクスポート可能なFirebaseなどのデータをSnowflakeにもロードしたい時、Icebergを介すことでパイプラインを効率化」という内容の記事です。(画像はリンク先より引用)
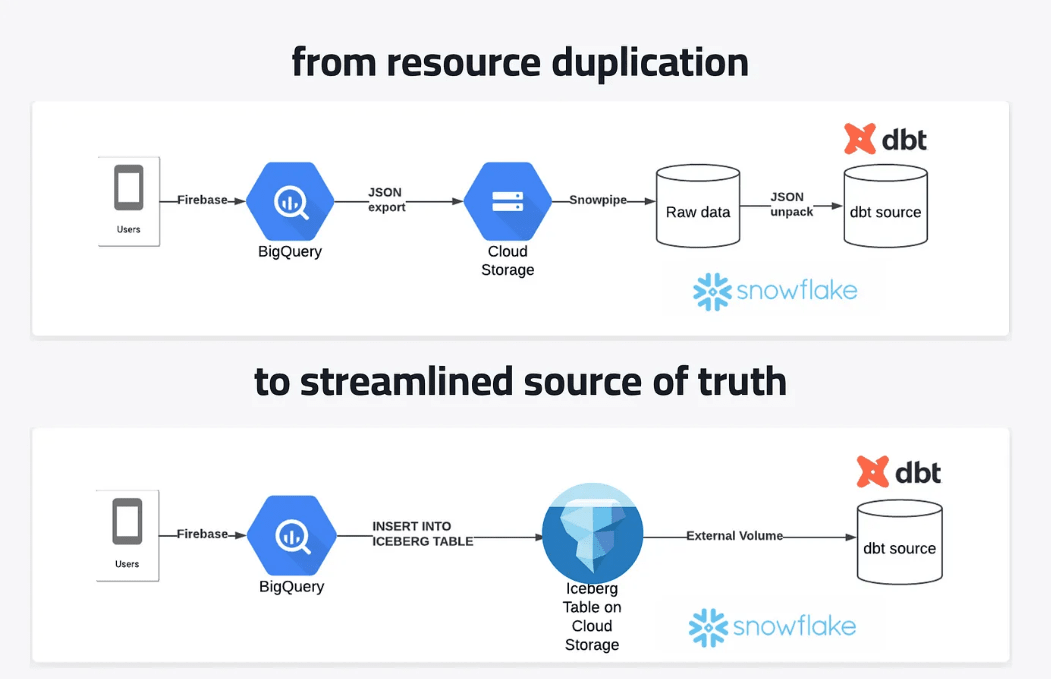
この記事の内容を参考に、自分も実際にやってみたので、その内容をまとめてみます。
BigQuery tables for Apache Icebergでテーブル定義
まず、BigQuery tables for Apache Icebergでテーブル定義を作成する必要があります。
今回は下記の記事を参考に、下図のようなテーブルを定義しておきました。
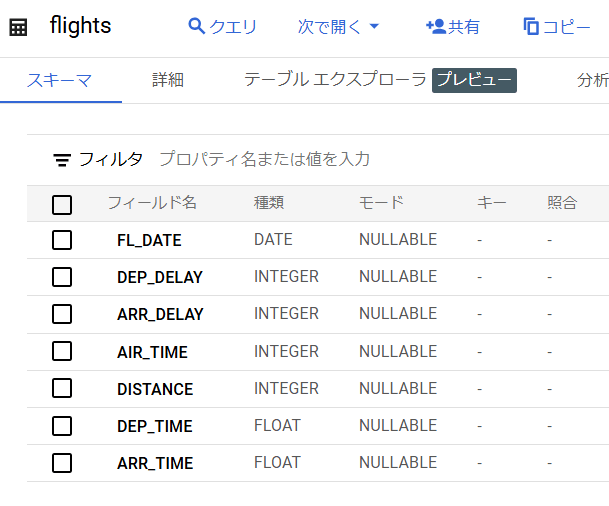
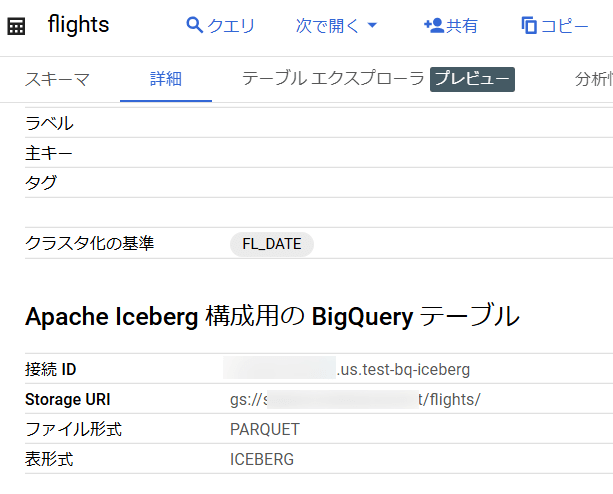
GCSのバケットの内容は下図のようになっています。
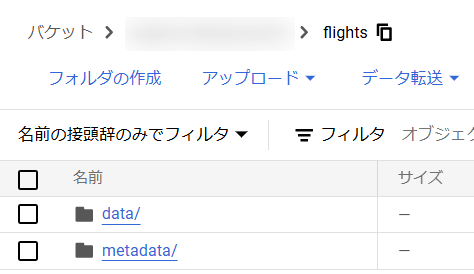
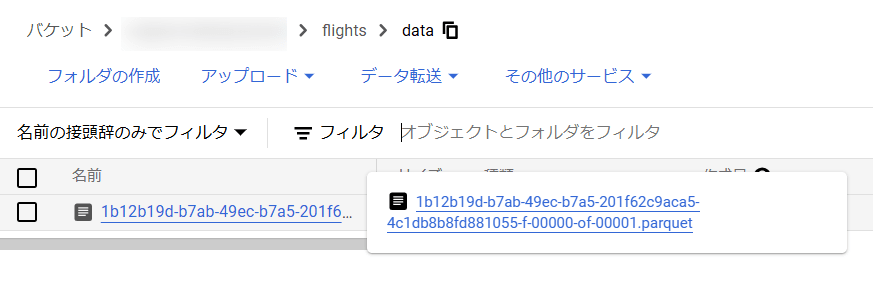
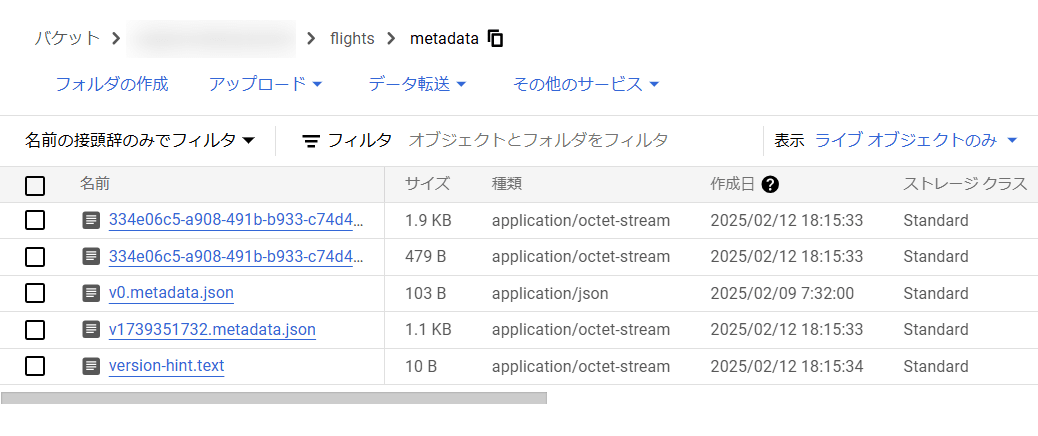
この状態で、以下のEXPORT TABLE METADATAコマンドを実行します。これにより、metadataフォルダが更新され最新の状態が反映されます。(このEXPORT TABLE METADATAコマンドに関する公式Docs)
EXPORT TABLE METADATA FROM <作成したテーブル名>;
SnowflakeからGCSに対するExternal Volumeの定義
次に、先ほどBigQueryで作成したIcebergテーブルに対してアクセスできるように、SnowflakeからGCSに対するExternal Volumeを定義していきます。
まず、以下のクエリを実行してGCSへのExternal Volumeを定義します。
CREATE EXTERNAL VOLUME <任意のExternal Volume名>
STORAGE_LOCATIONS =
(
(
NAME = '<Snowflakeアカウント内で一意となる任意の識別子>'
STORAGE_PROVIDER = 'GCS'
STORAGE_BASE_URL = 'gcs://<バケット名>/<フォルダ>'
)
);
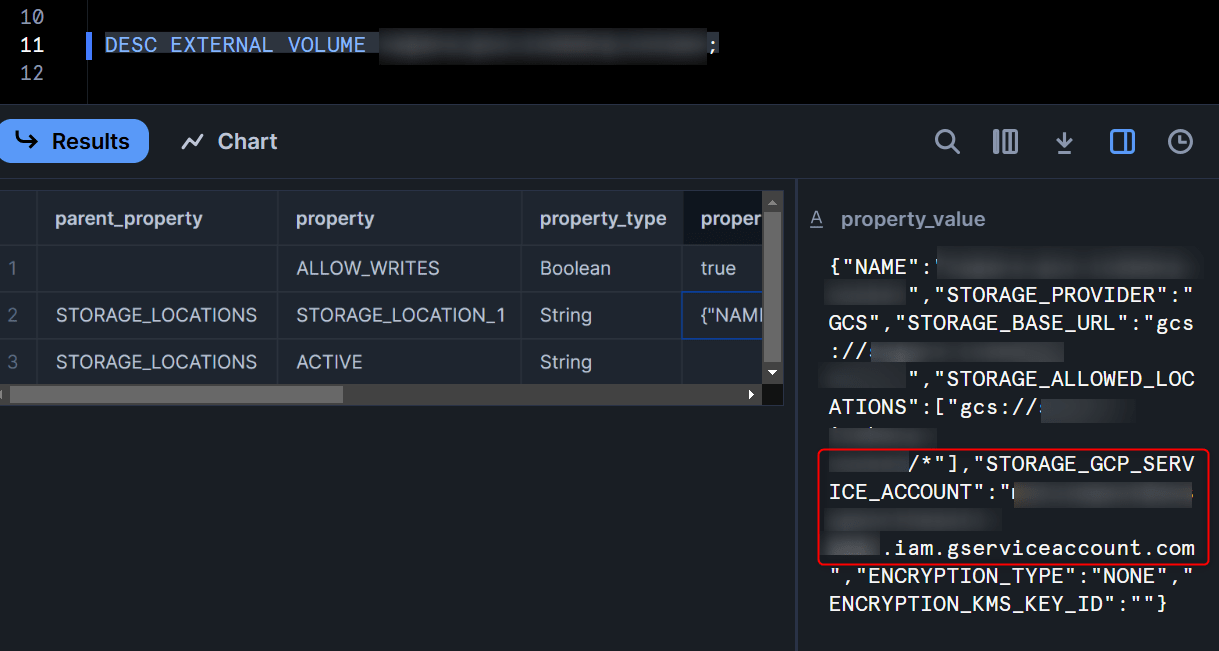
次に、作成したExternal Volumeに対して以下のクエリを実行し、サービスアカウントの値を取得します。
DESC EXTERNAL VOLUME <作成したExternal Volume名>;
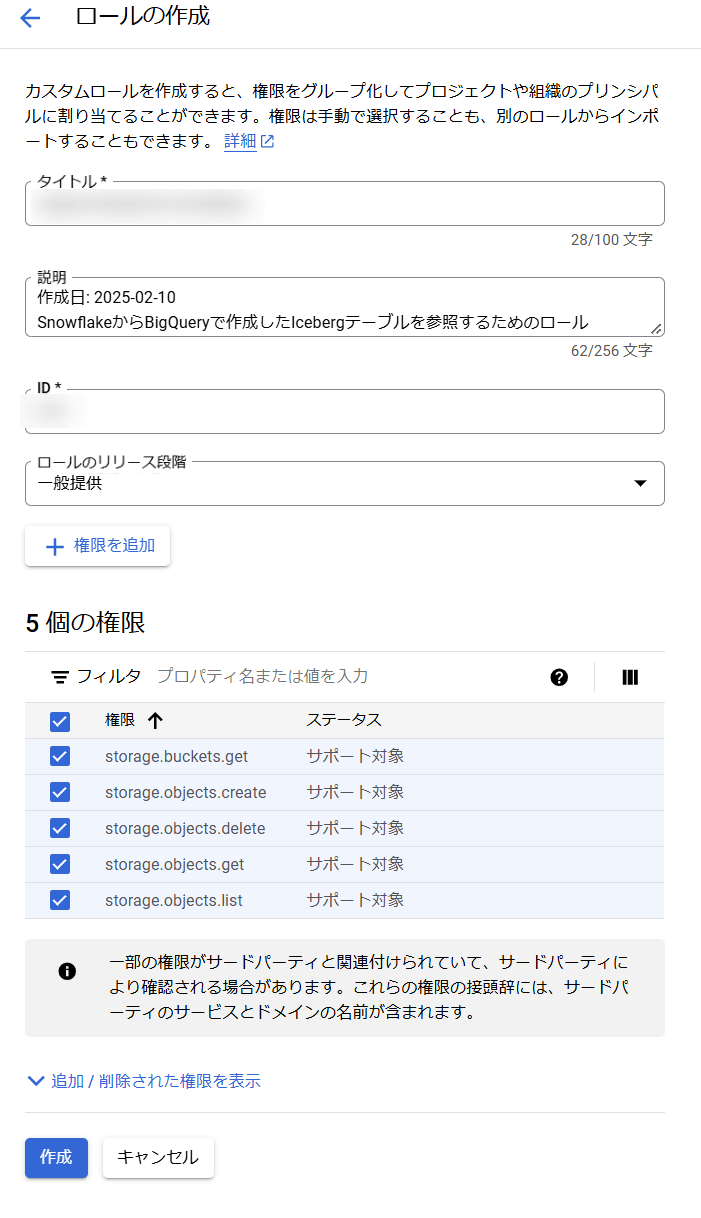
次に、Google Cloud上で下記の権限を持つカスタムIAMロールを作成します。
storage.buckets.getstorage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
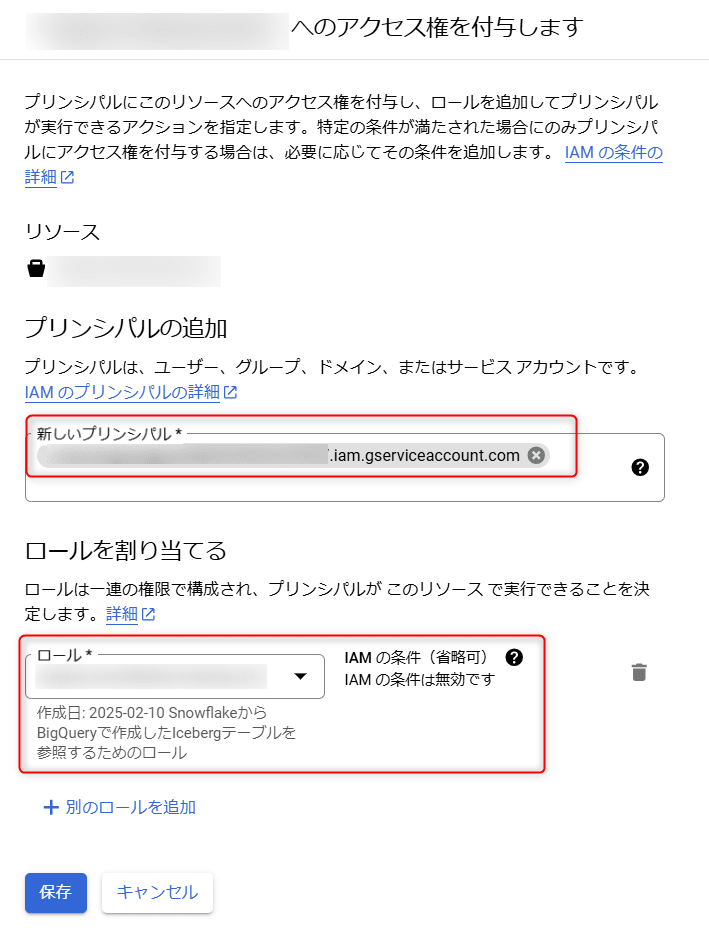
先ほどIcebergテーブルを作成したバケットに対して、作成したカスタムIAMロールをSnowflakeで確認したサービスアカウントに対して付与します。
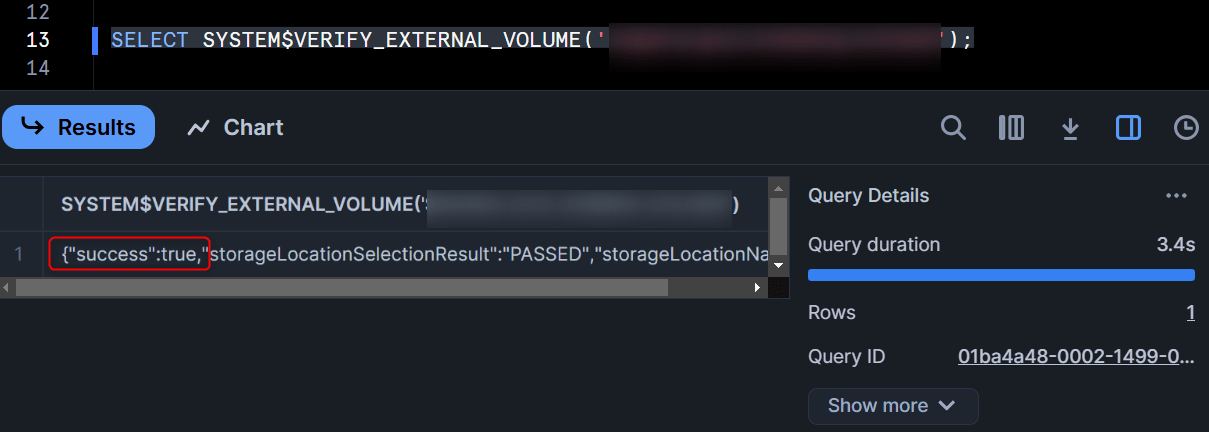
最後に、下記のクエリを実行して"success":trueの結果が返ってくれば、External Volumeの定義は完了です!
SELECT SYSTEM$VERIFY_EXTERNAL_VOLUME('<作成したExternal Volume名>');
Catalog Integrationの定義
次に、GCS上のIcebergのメタデータファイルを参照させるためのCatalog Integrationを定義します。
CREATE OR REPLACE CATALOG INTEGRATION <任意のCatalog Integration名>
CATALOG_SOURCE = OBJECT_STORE
TABLE_FORMAT = ICEBERG
ENABLED = TRUE;
Iceberg Tableの定義
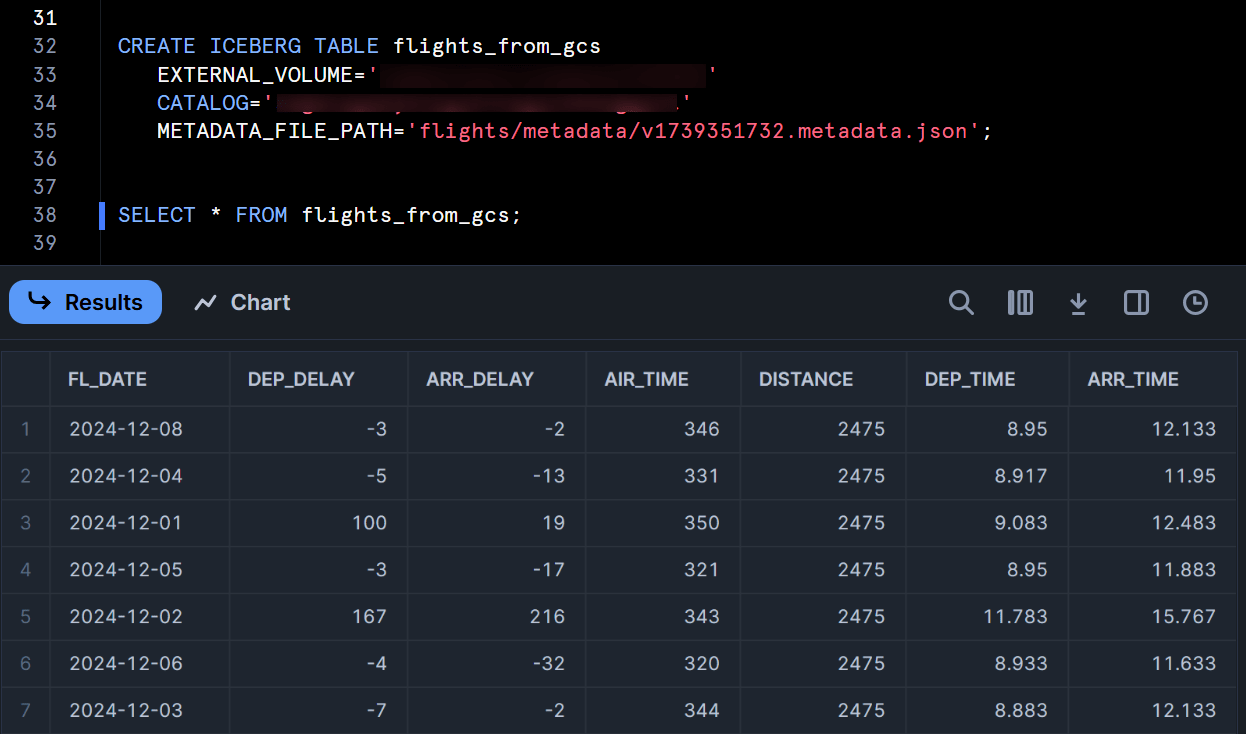
続いて、これまで定義した各オブジェクトを用いて、BigQuery tables for Apache Icebergで定義されたテーブルを、SnowflakeのIceberg Tableとしてクエリできるように定義します。
CREATE ICEBERG TABLE <任意のテーブル名>
EXTERNAL_VOLUME='<作成したExternal Volume名>'
CATALOG='<作成したCatalog Integration名>'
METADATA_FILE_PATH='flights/metadata/v1739351732.metadata.json'; -- GCS上の最新の〇〇metadata.jsonを指定
この上で、このテーブルに対してSELECT文を実行してみると、無事にクエリが出来ました!
最新のメタデータファイルを参照するためのストアドプロシージャの定義
これまでの手順でBigQueryで定義したIcebergテーブルをSnowflakeでクエリすることができました。
しかし、このままだとテーブル作成時にメタデータファイルを指定しているため、BigQuery側でデータを更新してもすぐに反映させることが出来ません。
そのため、今回は参考にしているブログに書いてあったストアドプロシージャを用いて、Snowflakeで定義したIcebergテーブルが最新のメタデータファイルを参照するようにしてみます。
事前準備:対象のGCSに対する外部ステージを作成
このストアドプロシージャでは外部ステージに対してファイル名や更新日などを取得するクエリを実行しているため、事前に対象のGCSに対する外部ステージを作成しておく必要があります。
こちらの外部ステージの作成については、下記の記事が参考になると思います。
ストアドプロシージャの定義
次に、最新のメタデータファイルを参照できるようにするためのストアドプロシージャを定義します。
下記は、実際に私がテーブル名とステージ名を書き換えて作成したものとなります。
CREATE OR REPLACE PROCEDURE REFRESH_ICEBERG_METADATA()
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
AS
$$
// Step 1: Get current metadata location
var sql_get_metadata = "SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('SAGARA_RAWDATA_DB.ICEBERG_SCHEMA.FLIGHTS_FROM_GCS') AS METADATA_INFO";
var stmt_metadata = snowflake.createStatement({sqlText: sql_get_metadata});
var result_metadata = stmt_metadata.execute();
var current_metadata = '';
if (result_metadata.next()) {
var metadata_info = result_metadata.getColumnValue(1);
current_metadata = JSON.parse(metadata_info).metadataLocation;
}
// Step 2: Identify latest metadata file on stage
var sql_new_file = `
SELECT METADATA$FILENAME AS FILE_PATH
FROM @sagara_gcs_stage (PATTERN => 'flights/metadata/.*metadata.json')
ORDER BY METADATA$FILE_LAST_MODIFIED DESC
LIMIT 1
`;
var stmt_new_file = snowflake.createStatement({sqlText: sql_new_file});
var rs_new_file = stmt_new_file.execute();
var new_metadata_file_path = rs_new_file.next() ? rs_new_file.getColumnValue("FILE_PATH") : '';
// Step 3: Refresh if changed
if (new_metadata_file_path && !current_metadata.includes(new_metadata_file_path)) {
var alter_cmd = "ALTER ICEBERG TABLE SAGARA_RAWDATA_DB.ICEBERG_SCHEMA.FLIGHTS_FROM_GCS REFRESH '" + new_metadata_file_path + "'";
var stmt_alter = snowflake.createStatement({sqlText: alter_cmd});
stmt_alter.execute();
return 'Metadata updated with latest file: ' + new_metadata_file_path;
} else {
return 'No metadata refresh needed.';
}
$$;
ストアドプロシージャの動作確認
まず、BigQuery上で以下のクエリを実行し、新しいデータをINSERTして、EXPORT TABLE METADATAコマンドでGCS上のメタデータもアップデートします。
INSERT INTO `data_set_iceberg.flights` (FL_DATE,DEP_DELAY,ARR_DELAY,AIR_TIME,DISTANCE,DEP_TIME,ARR_TIME)
VALUES
('2024-07-01',25,35,150,800,22.167,0.667),
('2024-07-02',30,45,155,800,23.083,1.667),
('2024-07-03',20,30,152,800,21.917,0.417),
('2024-07-04',15,25,148,800,22.500,0.917),
('2024-07-05',40,55,153,800,23.333,1.917);
EXPORT TABLE METADATA FROM `data_set_iceberg.flights`;
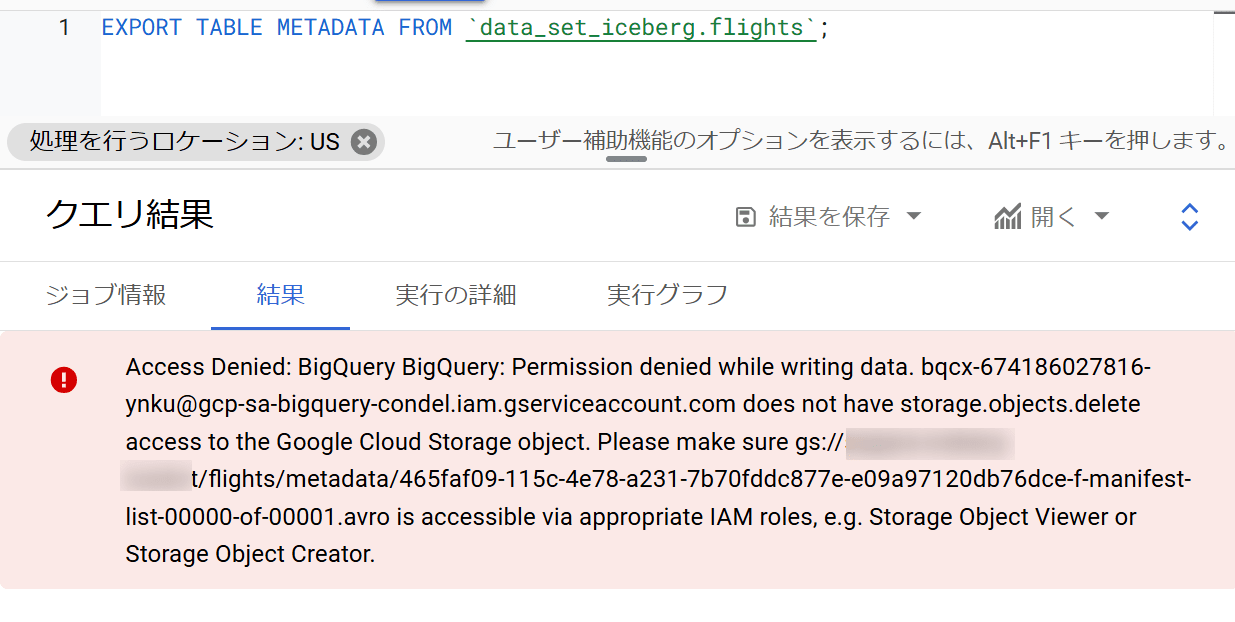
※余談:上述のEXPORT TABLE METADATAのクエリを実行したときに下図のエラーが出たのですが、GCSを見るとメタデータファイルは更新されていたのでよくわからずです…BigQuery for Apache Icebergがプレビュー機能なこともあり動作が不安定なところがあるかもしれません。
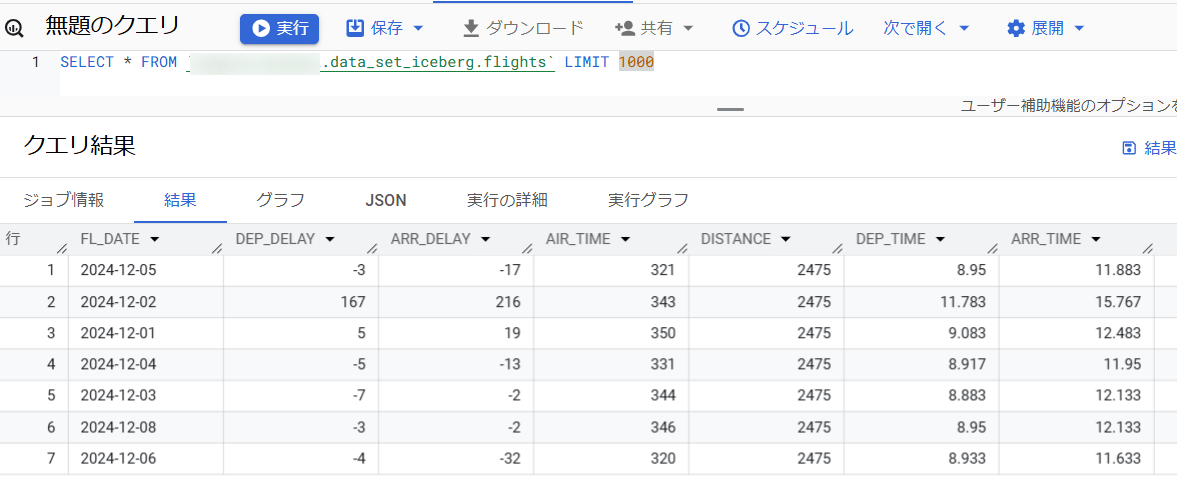
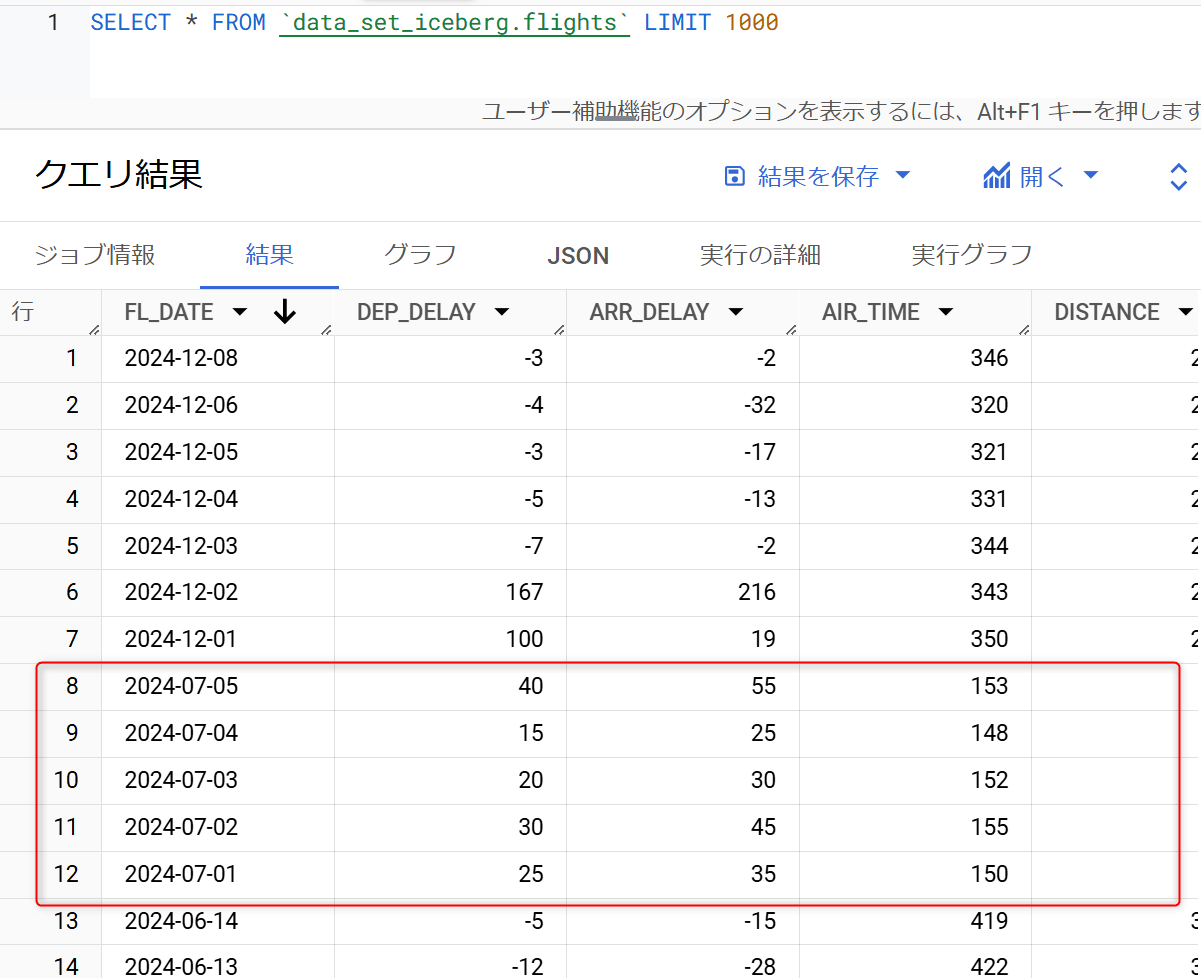
この上で、BigQueryとSnowflakeそれぞれから対象のIcebergテーブルを確認すると、BigQueryの方のみ最新のデータとなっています。これはSnowflakeのIcebergテーブルは古いメタデータファイルを参照しているためです。
- BigQueryからの実行結果
- Snowflakeからの実行結果
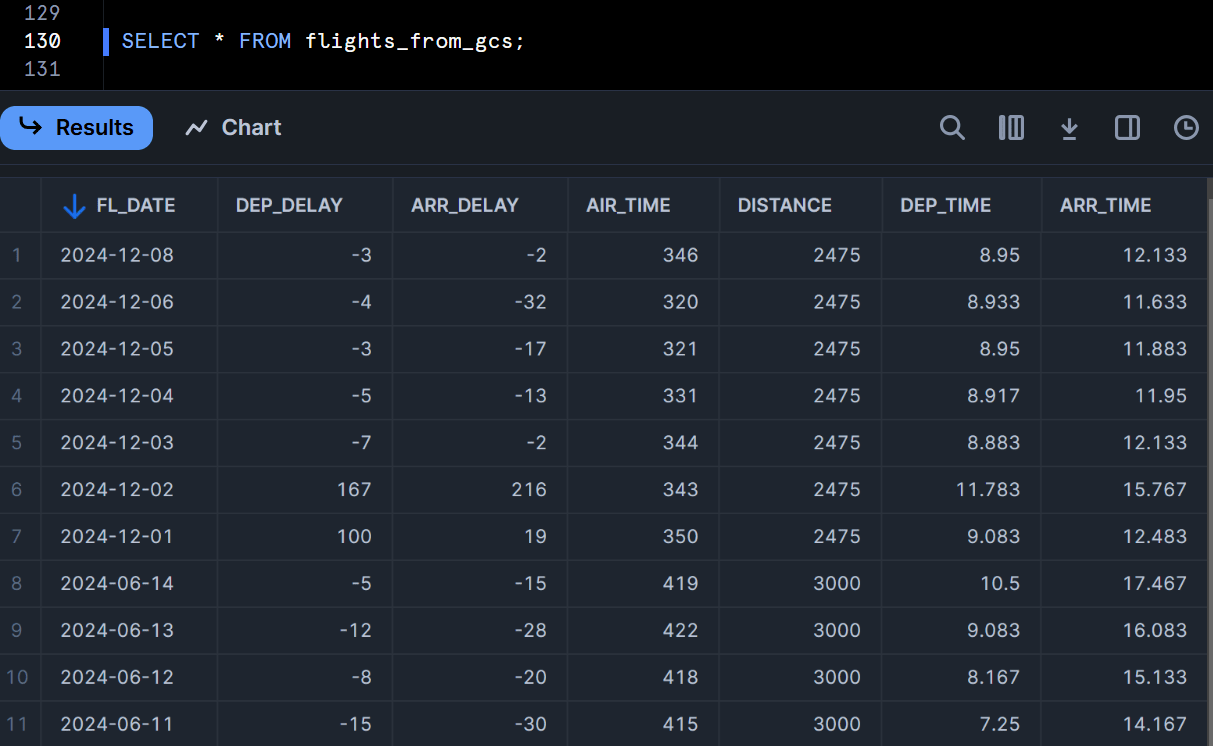
この上で、先程定義したストアドプロシージャを実行して、その上でもう一度SnowflakeからIcebergテーブルの内容を確認してみます。
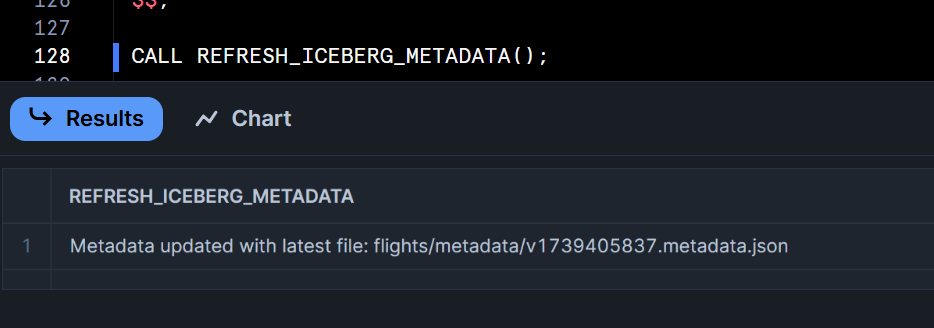
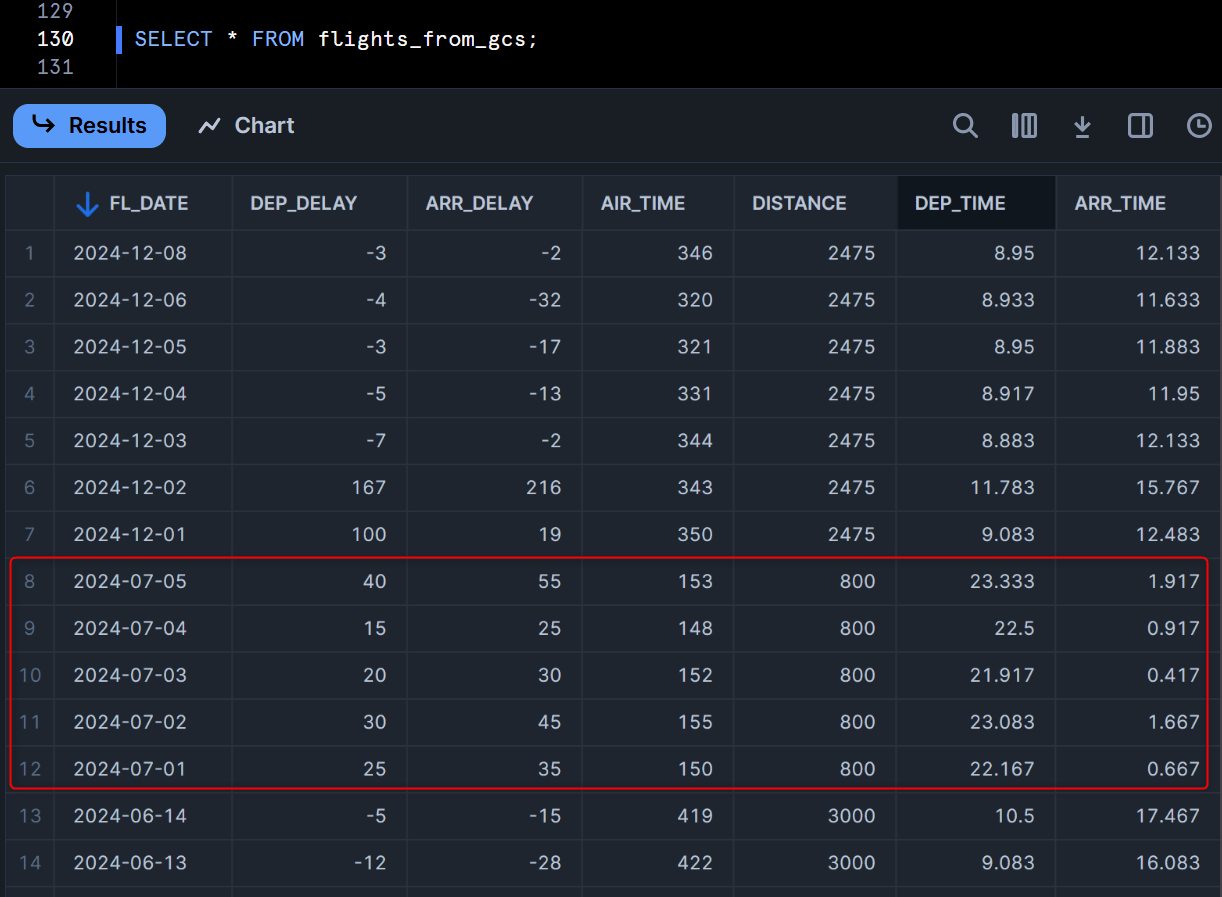
すると、下図のようにBigQueryで新しくINSERTしたデータがSnowflake上でも確認できるようになりました!Snowflakeから定期的にこのストアドプロシージャを実行すれば、BigQueryで更新された内容を元に、Snowflakeでも最新のデータに対してクエリすることができますね。
最後に
Mediumの記事を参考に、BigQuery tables for Apache Icebergで定義されたテーブルをSnowflakeのIceberg Tableとしてクエリできるようにしてみました。
メタデータファイルの更新が少し手間ではあるのですが、これまでのBigQuery⇛Snowflakeのデータパイプラインの構築方法が抜本的に変わるアイデアだと思います!!(Mediumの記事の執筆者の方に感謝ですね!)
先日Google CloudはBigQuery metastoreも発表しています。BigQuery metastoreをカタログとして、BigQueryからSQLでIcebergテーブルの作成・更新ができるようになると、BigQuery metastoreを介して最新のメタデータを参照できるようになると思うので、今後のアップデートに期待しています!(現状はBigQuery metastoreでのテーブルの作成・更新がSparkなどの外部エンジンからのAPI経由でしか出来ない認識です。)









