
製造業の異常検知を体系的に学ぶ「まるごと学べる異常検知の実践知」
「異常検知…全製造業の夢なのでは…」
製造業におけるAI活用の最も有名なユースケースは「外観検査」と「異常検知」だと思っているのですが、その異常検知について、理論面含めて真正面から解説してくれる本がこの「まるごと学べる異常検知の実践知」。
実践と名がついているだけあり、詳細な理論だけではなく、製造業の現場における活用やユースケースまで丁寧に触れられている全431ページの力作です。
定価3600円なので若干値が張りますが、この情報量はオライリーだと余裕で5000円は超えてくるぐらいのボリュームだと思います。異常検知を実装する人もサービス導入する人にもどちらにも非常にオススメな書籍なので、このブログでは書評という形で内容を紹介させていただきます。
この本を手に取ったきっかけ
現在自分は主に製造業の顧客向けにAWSを中心としたクラウドを活用したデータ分析・可視化や、AI活用のソリューションを提供しています。製造業のデータ活用という文脈で必ず出てくるのが「異常検知」。
自分はAIや機械学習を専門としているエンジニアではありませんが、広く製造業で必要とされる異常検知をもっと深堀って体系立てて学習したかったので、この本を手に取りました。
(参考)自分のAI関連知識
自分はAWSのAI関連認定試験の以下は取得済みです。AWS認定試験は、AWSサービス依存の知識が多いため、そのまんまAI関連知識を自分が広く取得しているわけではありませんが、Machine Learning - Specialtyはこの中でも比較的AWS依存しないAI関連知識が学べた記憶があります。
- AWS Certified AI Practitioner
- AWS Certified Machine Learning Engineer - Associate
- AWS Certified Machine Learning - Specialty
非常に親切に解説されている書籍ではありますが、最低限の機械学習知識(教師あり学習と教師なし学習の違い等)は、おさえておいたほうが理解はしやすいです。
書籍情報「まるごと学べる異常検知の実践知」

異常検知は製造業における不良品検出や故障の予兆検知、セキュリティ分野での不正アクセス検知、医療における病変検出など、実社会の幅広い場面で不可欠な技術です。本書は、その理論と実装をバランスよく解説した実用的な入門書です。
「異常データが少ない」「データの分布にモデルがうまく当てはまらない」といった実務で頻発する課題を出発点に、教師あり学習、教師なし学習、統計モデリングを用いた異常検知手法を広く紹介し、その使い分け方法を体系的に整理します。
基礎理論の平易な説明と、Pythonやオープンソースライブラリによる実用的なコード実装を通じて、実際のシステム設計や運用に直結する知識を提供します。異常検知の基礎と応用を一冊で身につけたい方に最適な手引きです。
書籍の書影をみると製造業に特化した本かと思っていたのですが、異常検知は製造業でのみ必要なユースケースではなく広く産業界で活用されてきたことがわかります。その異常検知を理論的なところから実践まで含めて詳細に解説しているのがこの本。
目次(上記公式ページより、章レベルのみ抜粋)
1章 異常検知の概要と使いどころ
2章 データの概要把握と可視化
3章 教師あり学習を用いた手法
4章 教師なし学習を用いた手法1 ―1変数データ
5章 教師なし学習を用いた手法2 ―計数データ
6章 教師なし学習を用いた手法3 ―多変数データ
7章 統計モデリングを用いた手法―入出力があるデータ
8章 ベイズ統計モデリングを用いた手法―入出力があるデータ
9章 前処理と性能評価
以下、章の流れに沿って紹介していきます。
1章 異常検知の概要と使いどころ
いきなり最重要の章。基本的にはここをしっかり読むことで異常検知の基本的なユースケースや活用方法、それに関連する技術や手法などが全て把握できます。2章以降は、1章で説明があった全体像の各部分の解説になっているので、なにはなくともここに目を通すことは必須。
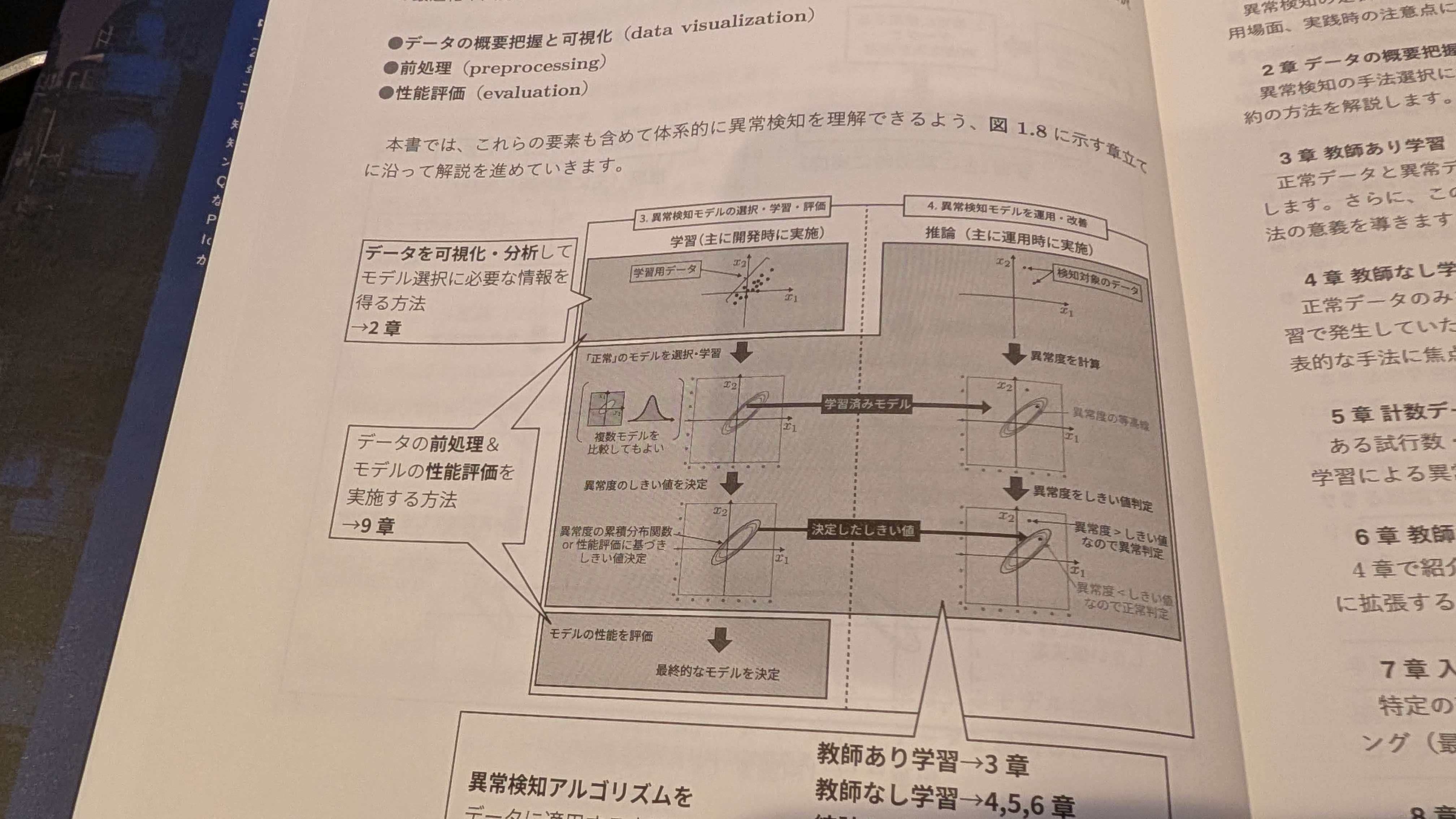
1章だけでもこれだけの見出し構成となっています。この本がどれぐらい深堀りして異常検知を扱っているのか、この見出しを見るだけでも理解できるかと思います。
1章 異常検知の概要と使いどころ
1.1 異常検知とは何か
1.1.1 「異常」を「検知」するとは
1.1.2 本書のねらい
1.1.3 異常検知の主要な活用分野
1.1.4 異常検知活用のケーススタディ
1.2 異常検知における課題と解決策
1.2.1 ドメイン知識に基づく異常検知
1.2.2 現実の異常検知は課題だらけ?
1.2.3 異常検知の課題をクリアする方法
1.2.4 本書における異常検知の定義
1.3 異常検知の実施フロー
1.3.1 異常検知のステップ分け
1.3.2 異常検知を実システムに組み込むフロー
1.3.3 学習と推論
1.4 本書の構成
1.4.1 各章の概要
1.4.2 本書で紹介する手法一覧
1.4.3 本書で紹介する異常検知アルゴリズムの概要
1.5 データとモデルの基礎知識
1.5.1 異常検知で用いるデータの構造
1.5.2 教師あり学習、教師なし学習、統計モデリングの違い
1.5.3 変数の種類の定義
1.6 各手法の使い分け
1.6.1 評価指標の選択
1.6.2 異常検知アルゴリズムの選択
1.6.3 しきい値の決定
1.6.4 前処理手法・変数の選択
1.7 実システムで陥りやすい落とし穴
1.7.1 正常データと比べて異常データが極端に少ない
1.7.2 異常データを意図して取得できない
1.7.3 誤報が頻発する
1.7.4 率データにおける分母が小さいデータの誤報の増加
1.7.5 変数が多すぎる
1.7.6 外れ値の影響で学習が破綻
1.7.7 正常範囲が他の変数に応じて変化する
1.7.8 正常範囲が時間とともに変化する
1.7.9 複雑なデータの構造のためモデルを作成できない
1.7.10 学習・テストデータの不適切な分割による過学習の見逃し
1.7.11 時間経過にともなう性能劣化―モデルドリフト
1.7.12 倫理的な問題を含んだモデル
1.8 Pythonの環境構築
1.8.1 想定する開発・実行環境
1.8.2 Pythonの特徴
1.8.3 Visual Studio Code
1.8.4 PythonのOSSライブラリとライセンス
1.8.5 本書におけるコーディングのルール
実際に異常検知に取り組もうとしたときに非常によくある落とし穴「異常データが極端に少ない!」については、代表的な落とし穴として1.7節に12個のアンチパターンとして詳細に記載されています。

「誤報の頻発」「時間経過と共にモデルの性能が低下する」など異常検知の現場でめっちゃあるあると思われるアンチパターンが網羅されていて、対処法が具体的に本書の各章への誘導含めて記載があるので、非常に活用しやすいです。
本自体が理論的なインデックスになっているだけでなく、こういう現場頻発のアンチパターンからの実践的な解説になっているのが素晴らしい。
充実のPythonをベースとしたGitHubリポジトリ
実際に試すためのPythonを利用したGitHubリポジトリも公開されています。ここの充実度もすごい。
READMEをざっと眺めてもらえると、本書中で紹介されていたソースコードの一覧や解説には含まれない付録、異常検知アルゴリズムを選択するためのチートシートなど、書籍を補完する内容も含まれています。
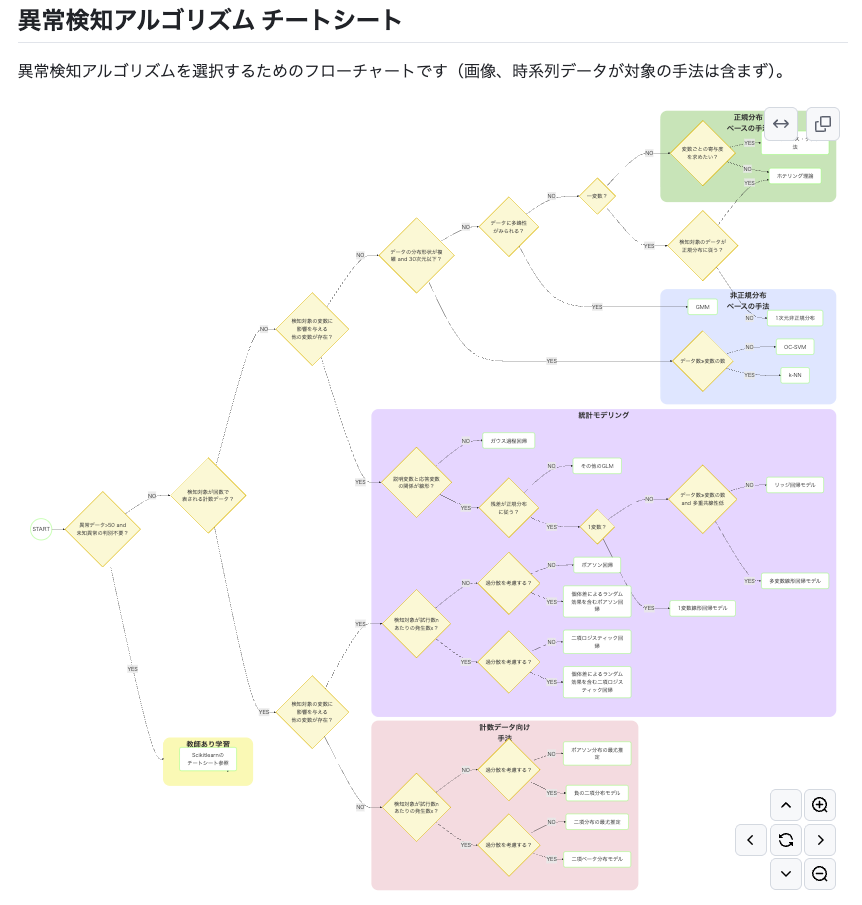
チートシートのブラッシュアップなども検討されているということなので、実際に使ってみて意見がある人は、是非Issue起票してみてください。
Visual Studio Code内でJupyter Notebook形式で開くことができるので助かります。
2章 データの概要把握と可視化
実際に異常検知をPython実装で進めていくための基本的な所作が解説されている章。データをどうやって保存するか?集めたデータをどうやって可視化するか?の部分が丁寧に解説されています。
実際問題、このあたりは現場の環境依存の部分(現場でどの技術を使っているか、可視化のためのライブラリは既に存在するか)が大きいとは思うのですが、そのあたりは個別に実装するとして、本書ではPythonのライブラリを中心としたそのあたりのデータの取扱と可視化の方法が紹介されています。
そもそも、Pythonを中心としたこのあたりのライブラリの使用感がない人(自分です)には非常に有用な章です。実際に手を動かしながら、サンプルデータを作成しつつこのあたり馴染んでいくための手順が丁寧に記載されています。
3章 教師あり学習を用いた手法
製造業のユースケースにおいては、異常データを十分に取得できることがマレなため、正常データと異常データの両方が十分に必要となる教師あり学習が利用されることは多くありません。
というわけで、ここは一旦教師あり学習の代表的な方法を振返りつつ、「3.5 教師あり学習による異常検知の問題点」では課題点が説明されています。ここを読んでおくと、後半の教師なし学習が活きる意味がわかるので、導入としてもこの章は一度読んでおくことをオススメします。
4〜6章 教師なし学習を用いた手法1〜3
教師なし学習の手法について、以下3つのデータについてそれぞれの異常検知手法が解説されています。
- 変数データ
- 計数データ
- 多変数データ
正直、このあたりから、ついていくのに気合がいるようになってきますw一つ一つの解説は非常に簡明かつ親切なので、丁寧に読み解いていけばそれぞれの手法の内容を理解することができると思いますが、ざっと流し読みで習得できるレベルではなくなってきます。

このあたりどのように本書に向き合うかは人それぞれですが、自分のように 「理論は完全に理解できなくても、異常検知がどのような数学的な理論の上に成り立っているのかの概要を把握することで、異常検知そのものの難しさと適用範囲を把握する」 ことを目的とするのであれば、教師なし学習のデータの違いによる手法の違いを把握しておくことは、重要だと思います。
本書は、理論的な解説も十分に深いのですが、それら理論が実際の製造業の異常検知のユースケースにてらして書かれていることが多いので、実務と理論の紐づけがしやすいのも大きな特徴の一つかと思います。
7章 統計モデリングを用いた手法―入出力があるデータ
教師あり学習の発展的手法の解説です。この本全てにわたって非常にありがたのが、冒頭にこのような手法が解決する現実世界の課題がわかりやすく例示されている点。
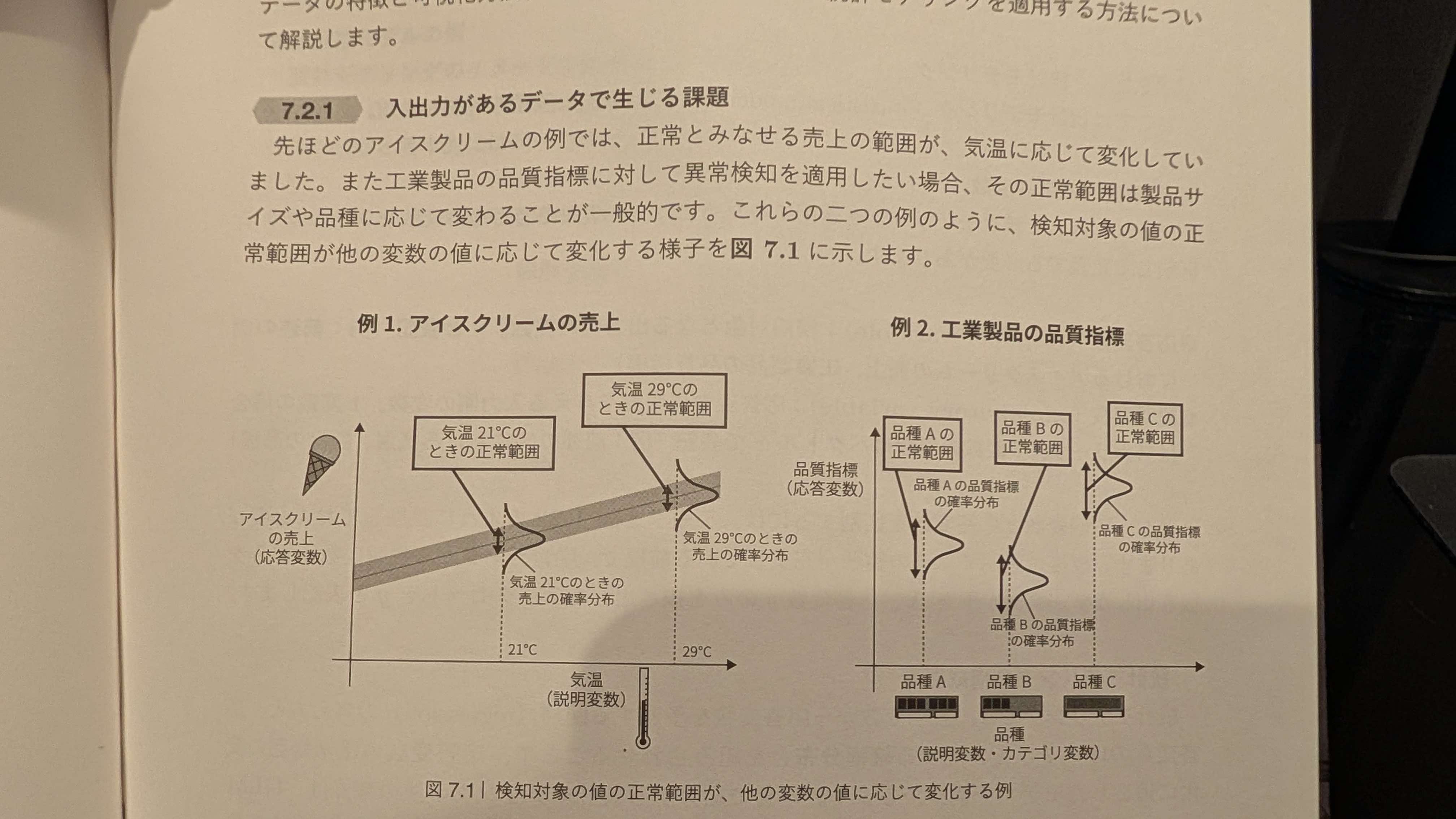
こういう内容があると、統計モデリングがこれまでの手法と何が違っていて、何が優れているのかを直感的に把握できます。だからこそ、この後の理論の説明内容が頭に入ってきやすくなります。
まとめ「理論を知ることで、世にある異常検知ソリューションへの理解が確実に深まる」
はっきり言って、この本は全く初心者向けの本ではありません。
もう少し正確に言うと異常検知ソリューションを実装する人向けの本であり、既にある異常検知ソリューションを使う人向けではないです。サービスを利用するだけであれば、この本に記載されている内容を全て把握しておく必要はないでしょう。
じゃぁ普通のユーザーならこの本が全く不要なのかというと、そう言い切れるものでも無いと思います。
例えば、2025年7月28日、AWS IoT SiteWiseにおいて以下のリリースがありました。
このリリース出た時、正直自分は「多変量異常検出ってなんじゃらほい」って思ってました。なんですが、改めて異常検知の理論が記された本書を開いて「6章 教師なし学習を用いた手法3 ―多変数データ」を読んでみることで、その機能自体がどのような異常検知を実現するのかを、理論レベルで知ることができました。
そうすると、AWSのユーザーガイドNative anomaly detectionを見ても、設定値の意味やできることできないことの境目やユースケースが、より深く知ることができます。
製造業の現場における機器は、その業種業態によって本当に千差万別です。ほぼ全ての現場で機器の保全は業務上必須と言えますが、異常検知のやり方はその目的や取れているデータ、どこまでの精度を求めるかによっても全然違うと思います。
ラインの特性上「壊れてからサービスマン呼んで直すのが、一番コスパが良い」という現場もありますし、設備によっては、単純な一つのデータを閾値決めてアラート出すだけで十分な場合もあるかもしれません。
それら含めた、異常検知というシンプルな言葉の中にある様々なユースケースと理論を紐づけて考えるきっかけをもらった本でした。
世の中にはそれこそかなりの数の異常検知サービスがあります。サービス導入側としてはそれら異常検知サービスを比較する時に、単に表面上の機能を比較するだけではなく、この本に記載された理論と照らし合わせて、どのあたりが得意不得意なのかを見極めることで、より自社の設備にあったサービスを選定することができるんじゃないでしょうか。
誰にでもオススメできるイージーな本ではないですが、記載内容が非常に丁寧で無駄が削ぎ落とされているので、業務との紐づけもしやすいので存外読み進めやすいかと思います。
サンプルのソースコードが提供されているGitHubリポジトリも非常に丁寧に作られていて、実装される方にも有用なので是非こちらもみてもらえればと思います。
それでは今日はこのへんで。濱田孝治(ハマコー)でした。










