![[レポート]クエリパフォーマンスチューニングの傾向と対策 #SWTTokyo25](https://images.ctfassets.net/ct0aopd36mqt/4c23cKcRWSfL7fbZjZSEYa/9a2f285542f7937bedd49a78ad421a45/eyecatch_snowflakeworldtourtokyo2025_1200x630.png?w=3840&fm=webp)
[レポート]クエリパフォーマンスチューニングの傾向と対策 #SWTTokyo25
2025.09.15
2025年9月11日~2025年9月12日に、「SNOWFLAKE WORLD TOUR 2025 - TOKYO」が開催されました。
本記事はセッション「クエリパフォーマンスチューニングの傾向と対策」のレポートブログとなります。
登壇者
- Snowflake合同会社
- Yoshi Matsuzaki 氏
パフォーマンスチューニングの基礎
- パフォーマンスチューニングは、クエリの実行時間やコストを目標値まで削減すること
- なので、目標設定が必要

- また、このプロセスは一度で終わることは少なく、段階的な改善が必要
- 基本的に1回で終わることはないため、パフォーマンスチューニング時は、繰り返し試行が必要ということを理解しておく
- 組織全体としても、チューニングにはこのプロセスが必要であることを理解していることが重要
- チューニングのサイクル
- 目標を定義
- 観測(現状把握)
- 仮説を立てる
- テストと分析
- これを繰り返す

- ボトルネック解消時の方法
- Workaround
- Permanent Solution
- 基本的には、Permanent Solution として問題の根本原因を特定し、その対処に集中する

- 比較を用いた仮説の立て方
- 例:「遅くなったクエリ」と「速かったクエリ」の比較
- 実行環境、データのボリューム、属性
- 例:移行元と移行先の比較
- 条件(CPU/メモリなど)を揃えてフェアに比較
- 例:「遅くなったクエリ」と「速かったクエリ」の比較
- 製品間での差異など、差異を完全に排除できない場合は、差異があることを認識し考慮すること




Snowflakeにおけるパフォーマンスの問題
- 前提
- 処理に時間がかかると感じても、実際は想定通りに時間がかかっている可能性もある
- 想定通りであれば、ここに固執せず次のボトルネックにアプローチする
- 日々 Snowflake のパフォーマンスも改善されている
- 以降の内容は今時点のもの
- 処理に時間がかかると感じても、実際は想定通りに時間がかかっている可能性もある

クエリコンパイルの最適化
- クエリコンパイル
- ユーザーの書いた SQL を実行可能な形に変換する処理
- クエリ実行時間に対して、コンパイル時間がかかるケースもある
- コンパイル時間の方が長いケースは珍しいことではない
- コンパイルを最適化できると得という観点で分析できるとよい
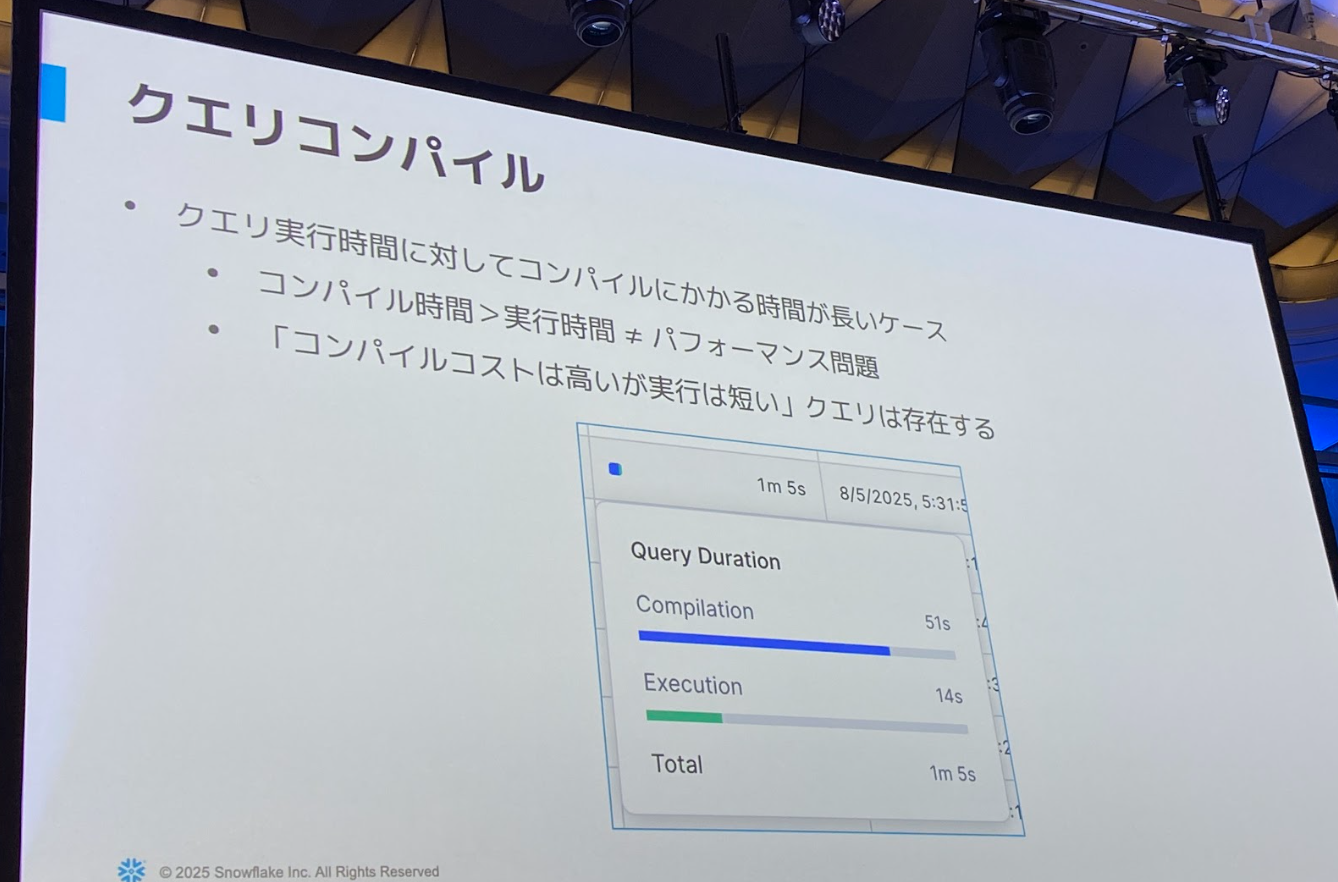
- コンパイルに時間がかかる原因
- 単純に複雑なクエリ
- メタデータの多いテーブル(カラム数の多いテーブル) など

- シンプルにすることが基本的なアプローチ
- Snowflake は結合することでパフォーマンスあげられる DWH
- 大量カラムを単一のテーブルで保持するよりは、正規化することが望ましい
- ビュー、ロールはネストのレベルを下げる
- Snowflake は結合することでパフォーマンスあげられる DWH

クエリ実行の最適化
- 典型的なテーブルスキャンに時間がかかるクエリ

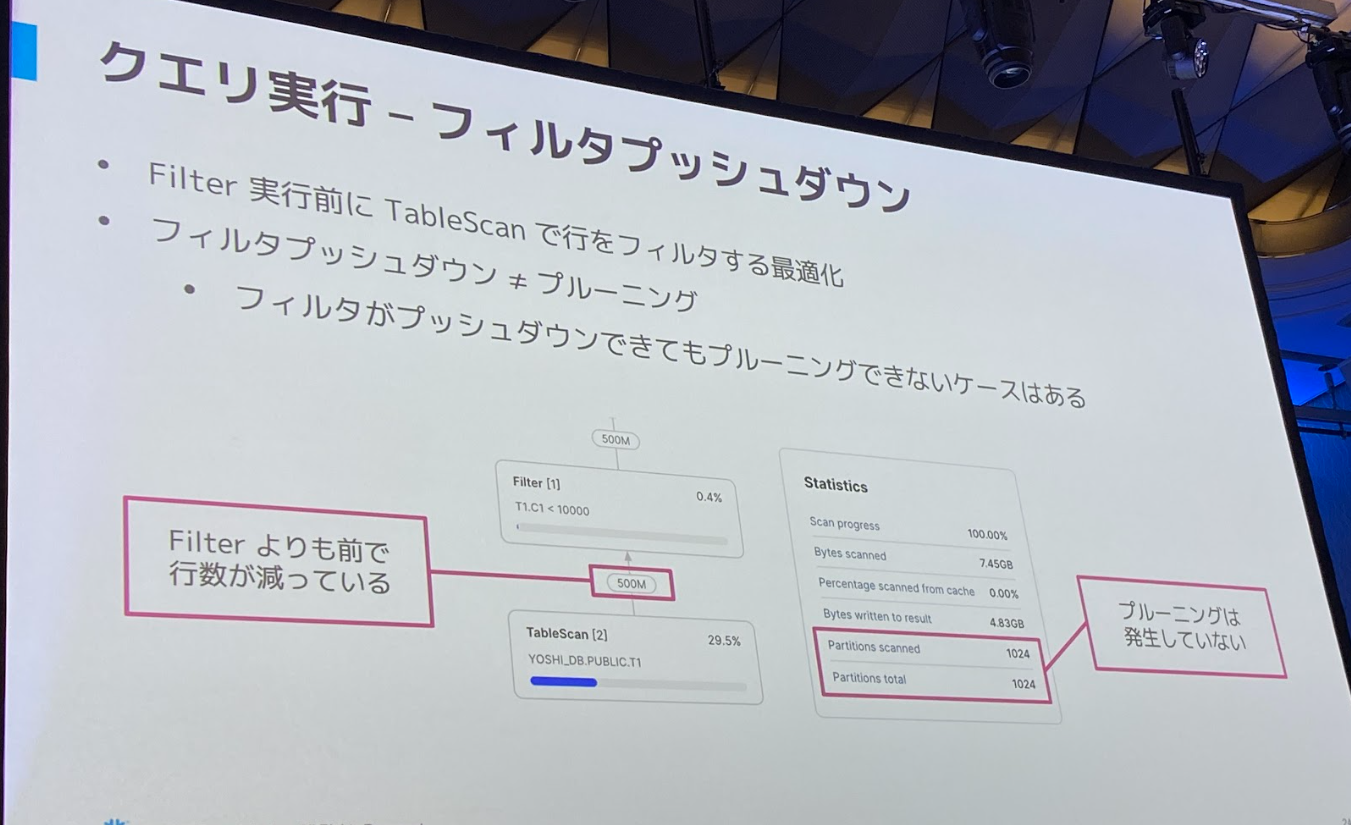
- フィルタプッシュダウン
- テーブルからデータを読み込む際に、フィルター処理を待たずに、読み込みの段階で不要な行を排除すること
- フィルタプッシュダウンはプルーニングとは異なるので、図のようにフィルタプッシュダウンできていても、プルーニングはできていないケースもある
- プルーニングできているとより速度改善が見込める
- テーブルスキャン時のベストプラクティス
- クラスタリングでプルーニングの効率を上げ、読み込み量を減らす
- フィルター
- できる限り多くの行数を絞り込むフィルターを使用
- 式の単純化
- 複雑な式がある場合、プッシュダウンを妨げるため、シンプルな式を使用する
- クエリアクセラレーションサービス
- 上記で対処できない場合に検討できる

- メモリ不足により、ローカルディスクやリモートストレージ(S3)に一時的にデータを書き出す(スピル)ことでパフォーマンスが低下する
- ただし、スピル発生は必ずしもパフォーマンスの問題ではない
- サイズの大きなデータを扱う際は、ローカルへのスピルは十分起き得る
- リモートスピルは気にすべき

- メモリ不足の原因
- 一番はクエリの並列実行

- ベストプラクティス
- 大量のメモリを消費するクエリは、他のクエリと同じクラスター上で実行しないようにする
- プルーニングなどで読み込むデータを減らす
- 単純にウェアハウスのサイズを大きくする

- 集約時のパフォーマンス
- 集約対象のデータ量が多い場合や、複雑な集約関数を使用する場合などに発生

- 集約時もクラスタリングが効く
- クラスタリングキーと検索最適化サービスの使い分けは考慮すべき点

- 結果生成に時間がかかる場合もある
- 単純にデータ量の問題や、結果が VARIANT 型の場合に、パフォーマンスペナルティがある(通常のデータ型と比較すると不利)

- 結合順序
- 結合は SQL の記載順に実行されるわけではない
- 結果は同じだが、結合順序はオプティマイザが判断

- 悪い結合順序もある
- 中間行数が多くなる、大きいテーブルが Build 側に置かれている場合
- Snowflake では Hash Join で結合が実装されており、Build 側は全行に対して Hash テーブルを作るので、小さなテーブルを Build 側に置く方がよい

- Directed join で結合順序を指定できる
- 順序の違いで10倍近くの差が出ている

- 結合順序のベストプラクティス
- プレースホルダに NULL を使うとオプティマイザが判断しやすくなる
- Directed Join でもコントロールできるが、できればオプティマイザに任せる

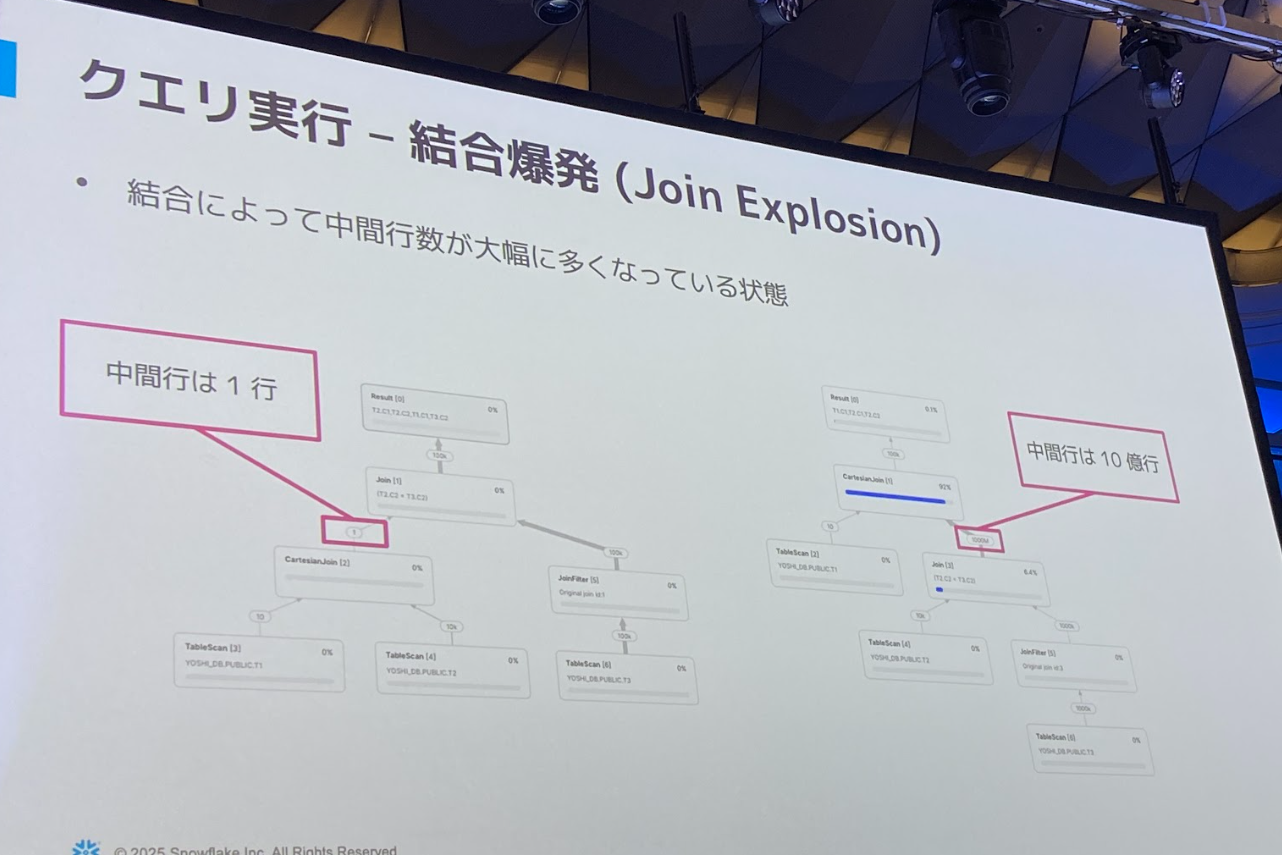
- 関連する内容として、結合爆発について
- 結合対象のデータ量、等価結合条件がない場合、重複行がある場合は、下図のようなことが起こり得る
- ベストプラクティス
- 結合合対象となるデータの量を減らす
- 結合条件を単純化する(等価結合条件を使い、複雑な条件式は避ける)

- まとめ
- パフォーマンスチューニングはイテレーション前提と理解しそのためのカルチャー、仕組みづくりが重要
- オプティマイザーの視点に立ち、何が見えているのかを想像することが良いクエリを書く上で不可欠

さいごに
Snowflake におけるパフォーマンスチューニング時の考慮事項について、その基礎から実際のクエリ実行時の各要素で問題となり得る点、そしてその際のベストプラクティスまで解説いただいたセッションでした。
明確な目標の無い「ただ速度を改善したい」という考え方では、終わりが見えなくなるので、目標設定とパフォーマンスチューニングそのものには試行が必要という点を理解しつつ、見ていく観点として、紹介いただいた各要素は今後の実務で非常に役立つと感じました。







