![[レポート] Build an AI-ready data foundation に参加してきました! #ANT304 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] Build an AI-ready data foundation に参加してきました! #ANT304 #AWSreInvent
こんにちは!
運用イノベーション部の大野です。
re:Invent 2025 の 「Build an AI-ready data foundation」に参加してきましたので、内容をご紹介いたします。

セッション概要
セッションタイトル
ANT304 | Build an AI-ready data foundation
説明
生成AIとエージェントAIへの関心が高まる中、組織はデータ戦略を見直す必要に迫られています。データパイプライン、データアーキテクチャ、データストア、データガバナンスといったデータ基盤の構成要素は進化が求められる一方で、コスト効率やデータ資産全体での効果的な連携といったビジネス要素は維持される必要があります。本セッションでは、AWS上でデータ基盤を構築することで、これら両方のニーズのバランスを取り、AI対応アプリケーションを構築するためのデータ戦略を成長させる方法について解説します。
スピーカー
- Imtiaz (Taz) Sayed - Tech Leader, AWS Analytics, Amazon
- Shikha Verma - Head of Product, AWS Analytics & Governance, AWS
セッションカテゴリなど
- Type: Breakout session
- Level: 300 – Advanced
- Topic: Analytics
- Services: Amazon OpenSearch Service, Amazon SageMaker, Amazon Q Developer
セッションサマリ
本セッションでは、AIアプリケーション構築のための「AI対応データ基盤」について、実際のデモを交えながら解説が行われました。
データ基盤の基本要素から、MCPサーバー、コンテキスト管理、ベクターストア、イベント駆動アーキテクチャ、そしてデータガバナンスまで、包括的な内容が紹介されました。
データ基盤とは何か
データ分析のためのデータ基盤
セッション冒頭では、データ基盤の定義について説明がありました。
データ基盤とは、以下の基本要素を提供するものです。

- データストア:データを格納する場所
- データ処理:データを変換・加工する機能
- データ統合:異なるソースからのデータを結合する機能
- データガバナンス:データの品質、セキュリティ、アクセス制御を管理する機能
これらは、コストパフォーマンスとスケーラビリティを備えた形で提供され、データパイプラインを構成します。
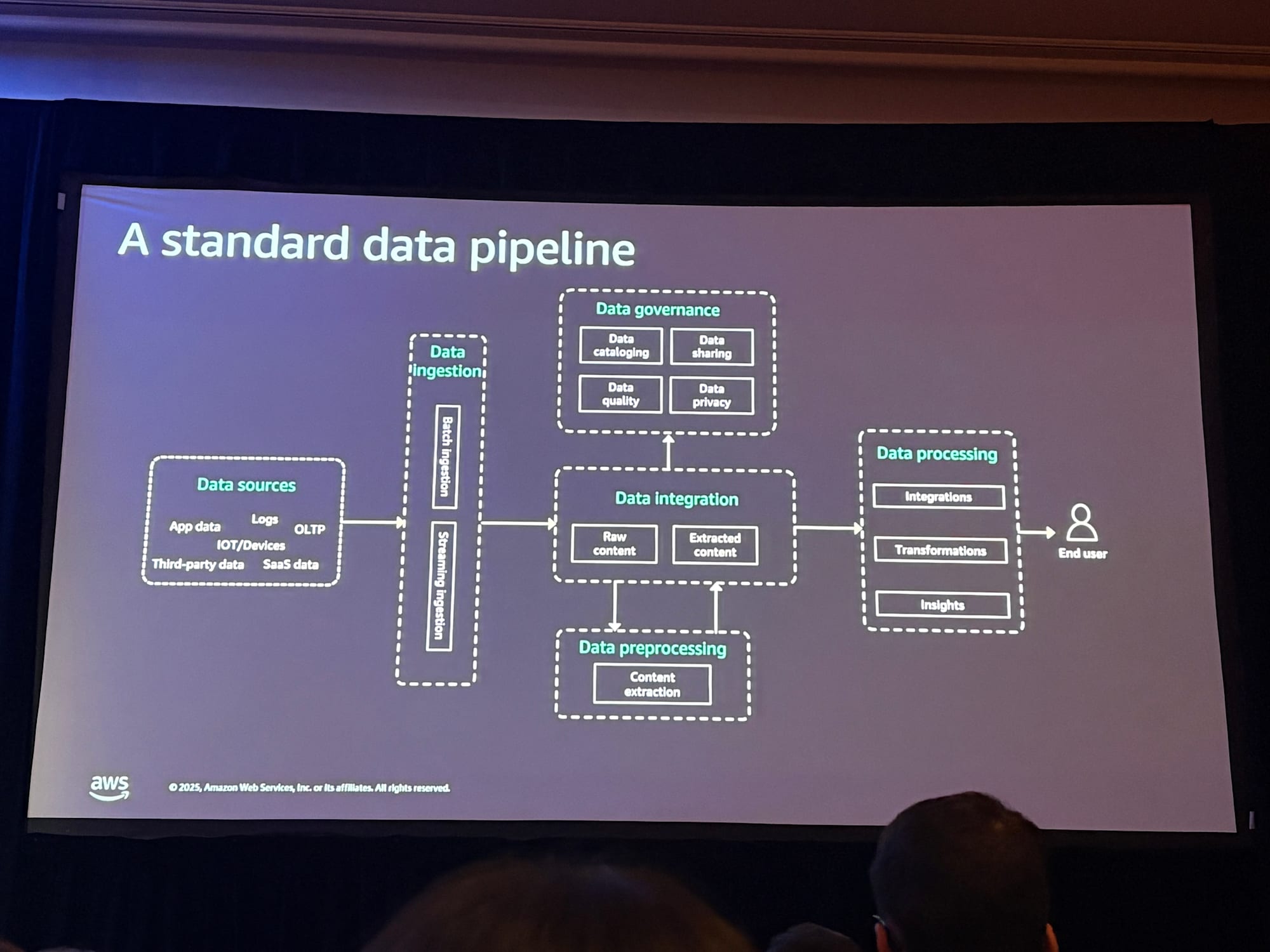
AIアプリケーションのためのデータ基盤
重要なポイントとして、AIアプリケーションを構築する際に、新しいデータ基盤を一から構築する必要はないということが強調されました。既存のデータ基盤を活用し、適応させることでAIアプリケーションを構築できます。
データとデータエンジニアリングは、AIの差別化要因となる重要な要素です。
AIアプリケーションの成功には、データ処理、データストレージ、データ統合が不可欠であり、これらはまさにデータ基盤が提供する機能です。
AIの進化とデータパイプラインへの影響
AIは急速に進化しており、それに伴いデータパイプラインも変化しています。
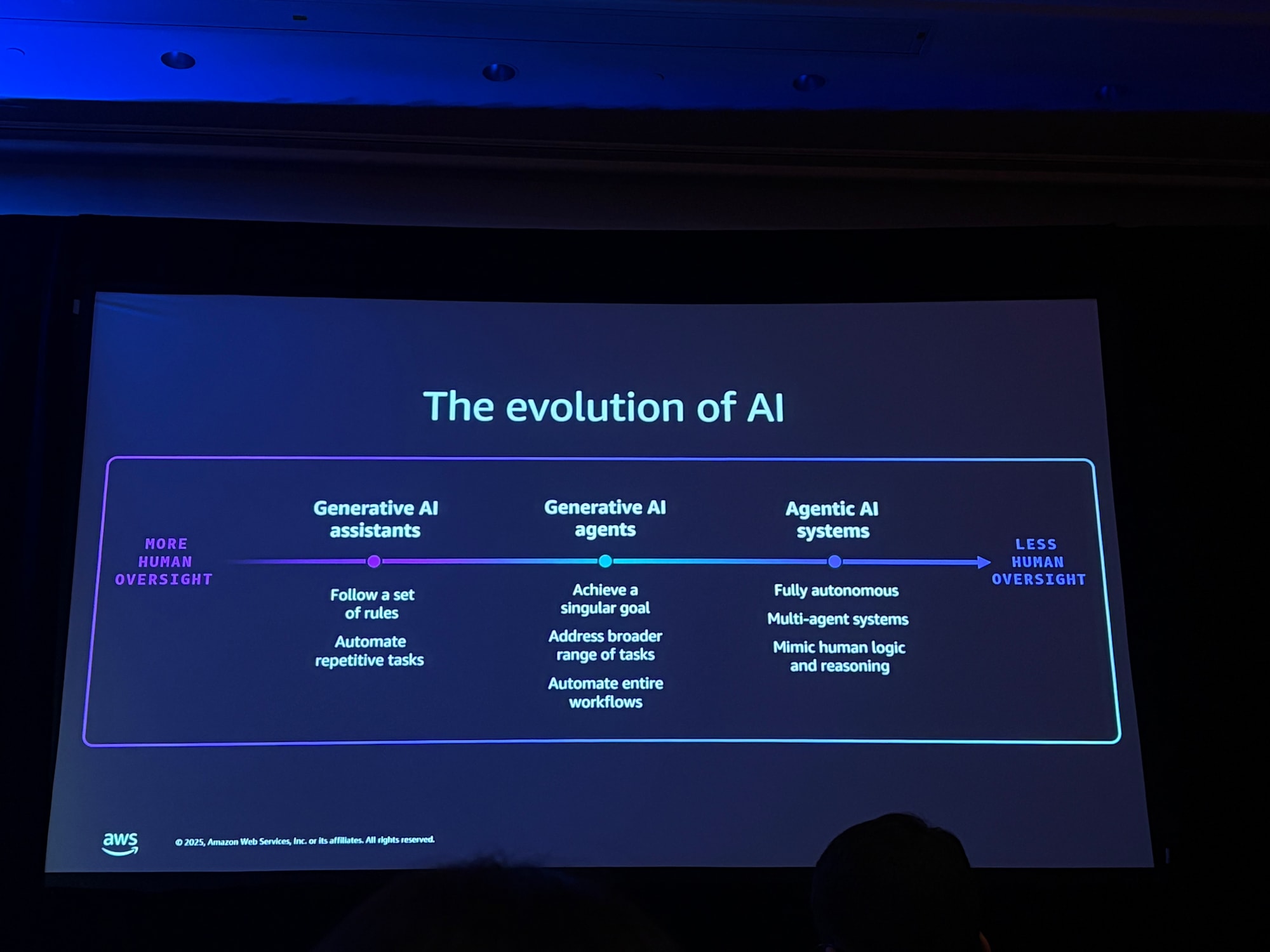
- 生成AIアシスタント:定義されたルールに従って反復的なタスクを自動化
- AIエージェント:目標指向で、より広範なタスクを処理し、環境に適応
- 自律型マルチエージェントシステム:複雑な意思決定が可能な複数エージェントの協調
この進化により、データパイプラインには以下の変化が求められます。
非構造化データの増加
AIアプリケーションでは、従来の構造化データに加えて、非構造化データ(文書、画像、音声など)の取り扱いが重要になります。
非構造化データは事前定義されたスキーマを持たないため、メタデータ管理やデータガバナンスに新たなアプローチが必要です。
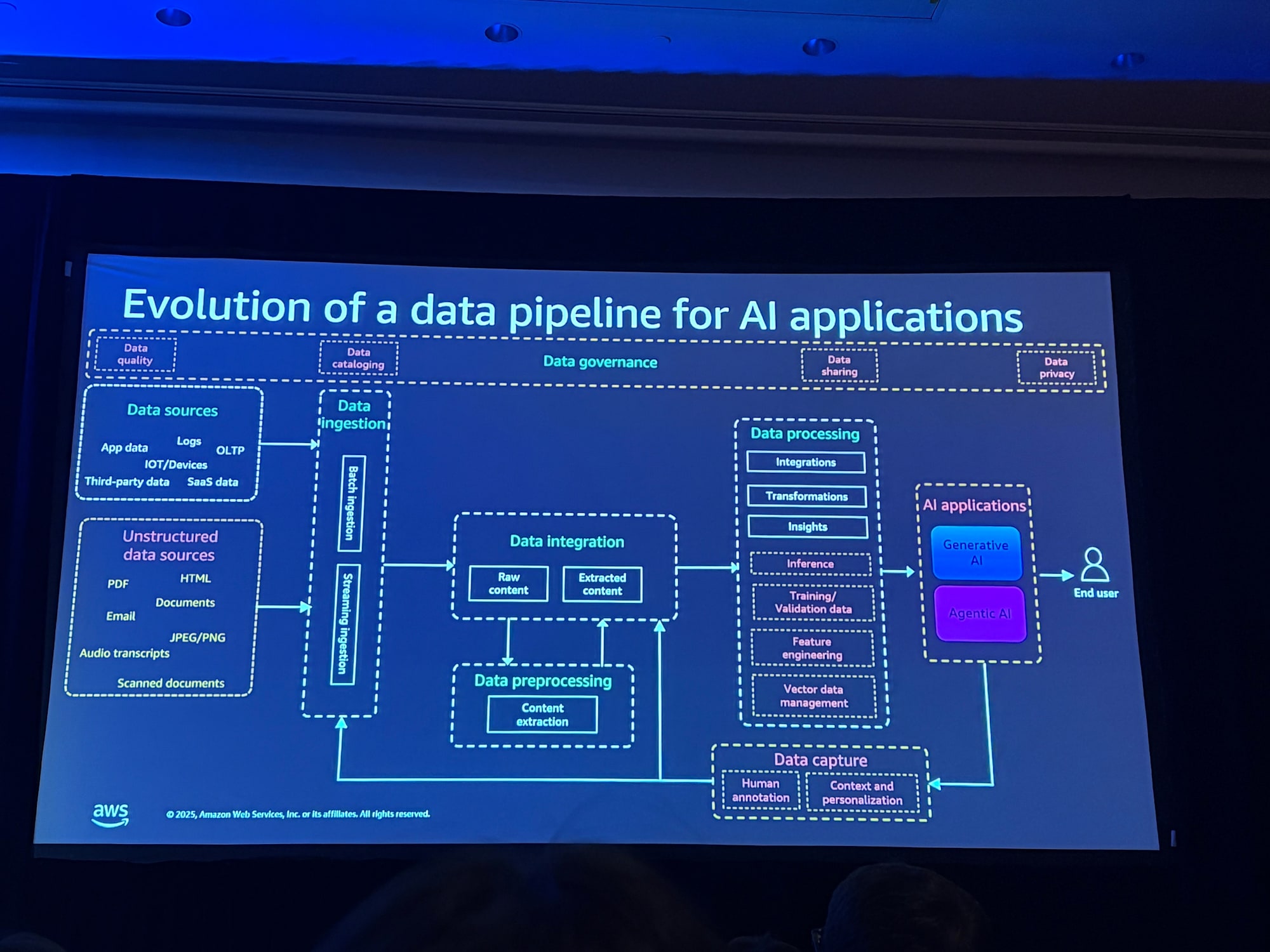
データ処理の高度化
- モデルのトレーニングや検証のためのデータ移動
- RAG(Retrieval Augmented Generation)シナリオでの継続的な事前学習
- リアルタイムコンテキスト提供のためのメモリ管理
データガバナンスの重要性
AIアプリケーションは多様なデータソースとユーザーに開かれるため、データプライバシー、データ品質、データカタログ化といったガバナンス機能がパイプライン全体で必要になります。
デモ:AI旅行予約エージェント
セッションでは、航空券予約エージェントアプリケーションのデモが実施されました。
このデモでは、Strands Agents(AWSがオープンソースで公開しているAIエージェントSDK)を使用してエージェントを構築しています。
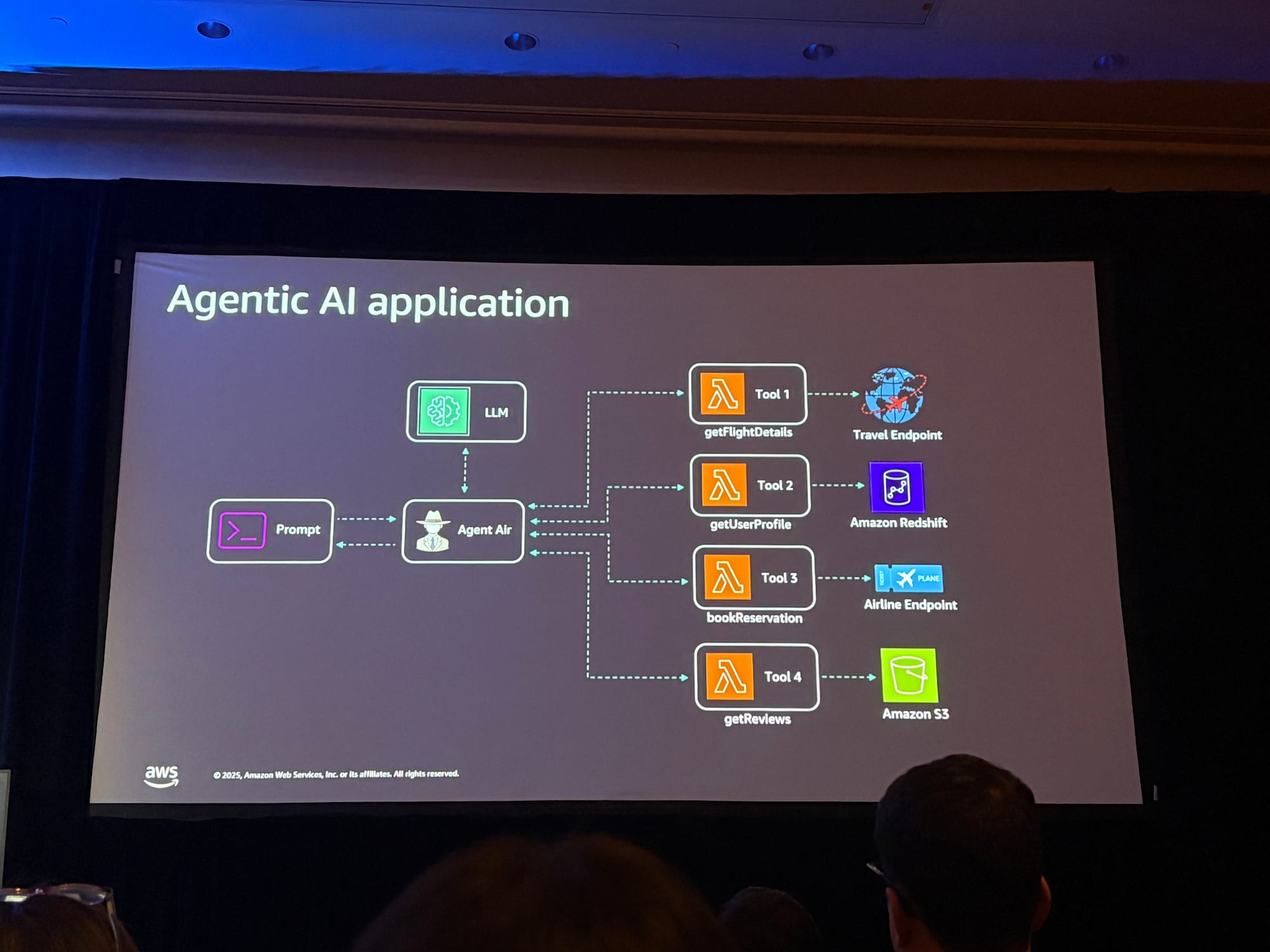
デモシナリオ1:フライト検索と予約
ユーザーがJFK(ニューヨーク)からロサンゼルスへのフライトを検索すると、エージェントは以下の情報を取得して回答します:
- フライトの空き状況と価格:サードパーティの旅行代理店APIから取得
- ユーザーレビュー:S3 Tablesに保存された社内の同僚のレビュー
- 会社の旅行ポリシー:ナレッジベースから取得した価格上限などのポリシー
- ポリシー違反の通知:選択したフライトがポリシーに違反する場合、例外申請が必要であることを通知
デモシナリオ2:ポリシー違反フライトの予約
会社のポリシーに違反するフライトを予約しようとした場合、
- エージェントがポリシー違反を検知し、マネージャーの承認が必要であることを通知
- バックエンドで承認を取得
- エージェントが承認を確認し、予約を完了
- 確認メールの送信、請求処理など、複数のバックエンドエージェントが連携して処理
MCPサーバーの活用
MCPサーバーとは

Model Context Protocol(MCP)は、Anthropic社が2024年11月に発表したオープンプロトコルで、AIアシスタントをデータシステムに接続するための標準規格です。
従来のエージェント開発では、各ツールやAPIに対してハードコードされた呼び出しを実装する必要がありましたが、これには以下の問題があります。
- エージェントの機能が設計時に固定される
- クエリが事前定義されている必要がある
- 各データソースに対するカスタム統合が必要
MCPサーバーを使用することで、エージェントは自然言語を通じてツールを自律的に呼び出し、ReActループ内で次のステップを決定できるようになります。
AWSのMCPサーバー
AWSは、AWS MCP Serversリポジトリで複数の専用MCPサーバーを公開しています。

Amazon Redshift MCPサーバー
Amazon Redshift MCPサーバーは、AIエージェントとAmazon Redshiftインフラストラクチャの間のブリッジとして機能します。
- クラスター検出:プロビジョニングされたクラスターとサーバーレスワークグループを自動検出
- メタデータ探索:自然言語でデータベース、スキーマ、テーブル、カラムを探索
- 安全なクエリ実行:読み取り専用モードでSQLクエリを実行
Amazon S3 Tables MCPサーバー
Amazon S3 Tables MCPサーバーを使用すると、自然言語でS3 Tablesと対話できます。
- テーブルバケットと名前空間の管理
- テーブルの作成、リネーム、一覧表示
- データのクエリとコミット
MCPサーバーの注意点
MCPサーバーは万能ではありません。
以下のような操作には従来のAPIコールの方が適しています。
- 大規模な構造化データ処理:複雑なデータ変換が必要な操作
- 時間的制約のある操作:予約処理など、リアルタイム性が求められる処理
これらの操作は、モデルのコンテキストウィンドウを超過し、コストとパフォーマンスに影響を与える可能性があります。
コンテキスト管理
コンテキストの重要性
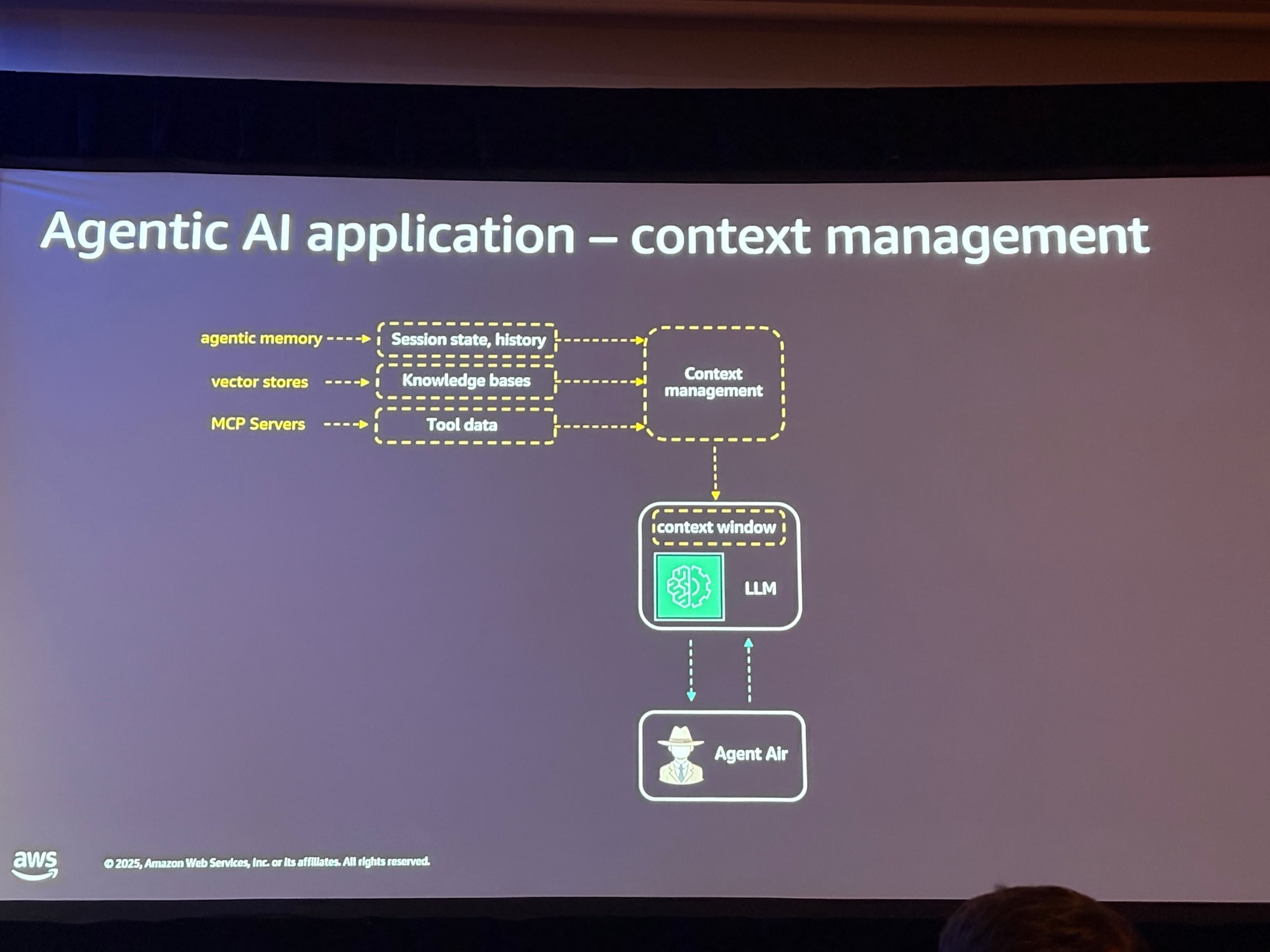
AIエージェントは高度な推論能力を持ちますが、2つの重要な制約があります。
- ステートレス性:LLMは過去のやり取りを記憶できない
- 有限なコンテキストウィンドウ:処理できるデータ量に制限がある
コンテキストウィンドウには通常、以下の3種類の情報が含まれます:
- 指示セット:ユーザープロンプト、システムプロンプト、会話履歴、ユーザープロファイル
- ナレッジベース:構造化・非構造化データの中央リポジトリ
- ツール/MCPサーバーからのデータ:外部システムから取得した情報
エージェントメモリ
エージェントメモリは、パーソナライズされた体験を提供するために不可欠です。
デモでは、Amazon Bedrock AgentCoreを使用してメモリ機能を実装しています。
Amazon Bedrock AgentCoreは、AIエージェントを大規模に安全にデプロイ・運用するための包括的なサービスセットで、re:Invent 2025で新機能が発表されました。
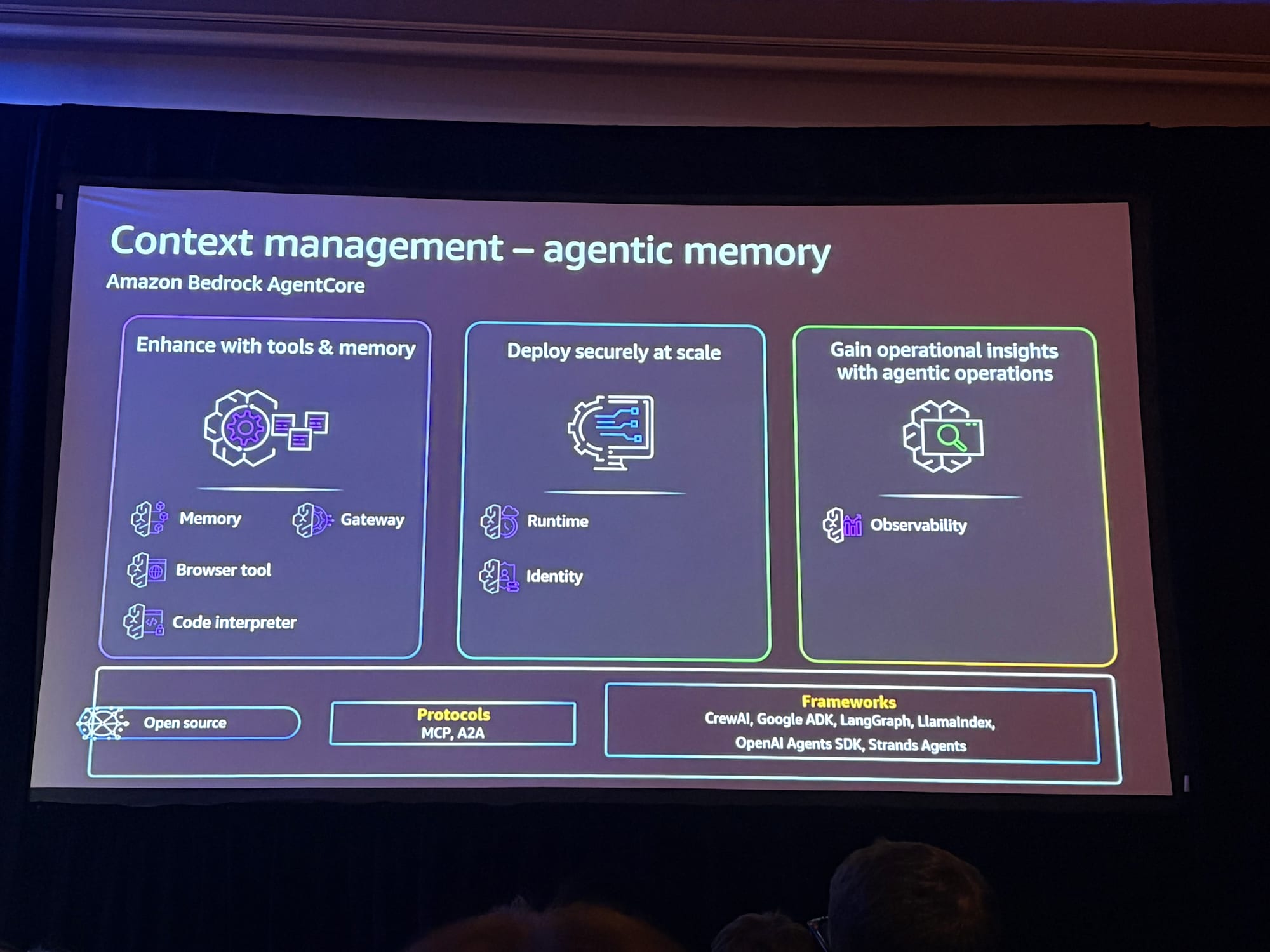
- AgentCore Runtime:低レイテンシのサーバーレス環境
- AgentCore Memory:セッションメモリと長期メモリの管理、エピソード記憶のサポート
- AgentCore Gateway:既存APIをエージェント対応ツールに変換
- AgentCore Policy(プレビュー):自然言語でポリシーを定義し、Cedar言語に自動変換
- AgentCore Evaluations(プレビュー):エージェントのパフォーマンステストと継続的モニタリング
ビジネスニーズに応じて、以下のような他のAWSサービスもメモリストアとして利用可能です。

- Amazon ElastiCache:高性能なインメモリキーバリューストア
- Amazon DynamoDB:分散型NoSQLデータベース
- Amazon Neptune Analytics:ナレッジグラフベースの動的な関係性分析
ナレッジベースとベクター(ベクトル)ストア
デモでは、会社の旅行ポリシー文書(PDF、HTMLファイルなど)をAmazon S3に保存し、Knowledge Bases for Amazon Bedrockを使用してナレッジベースを構築しています。
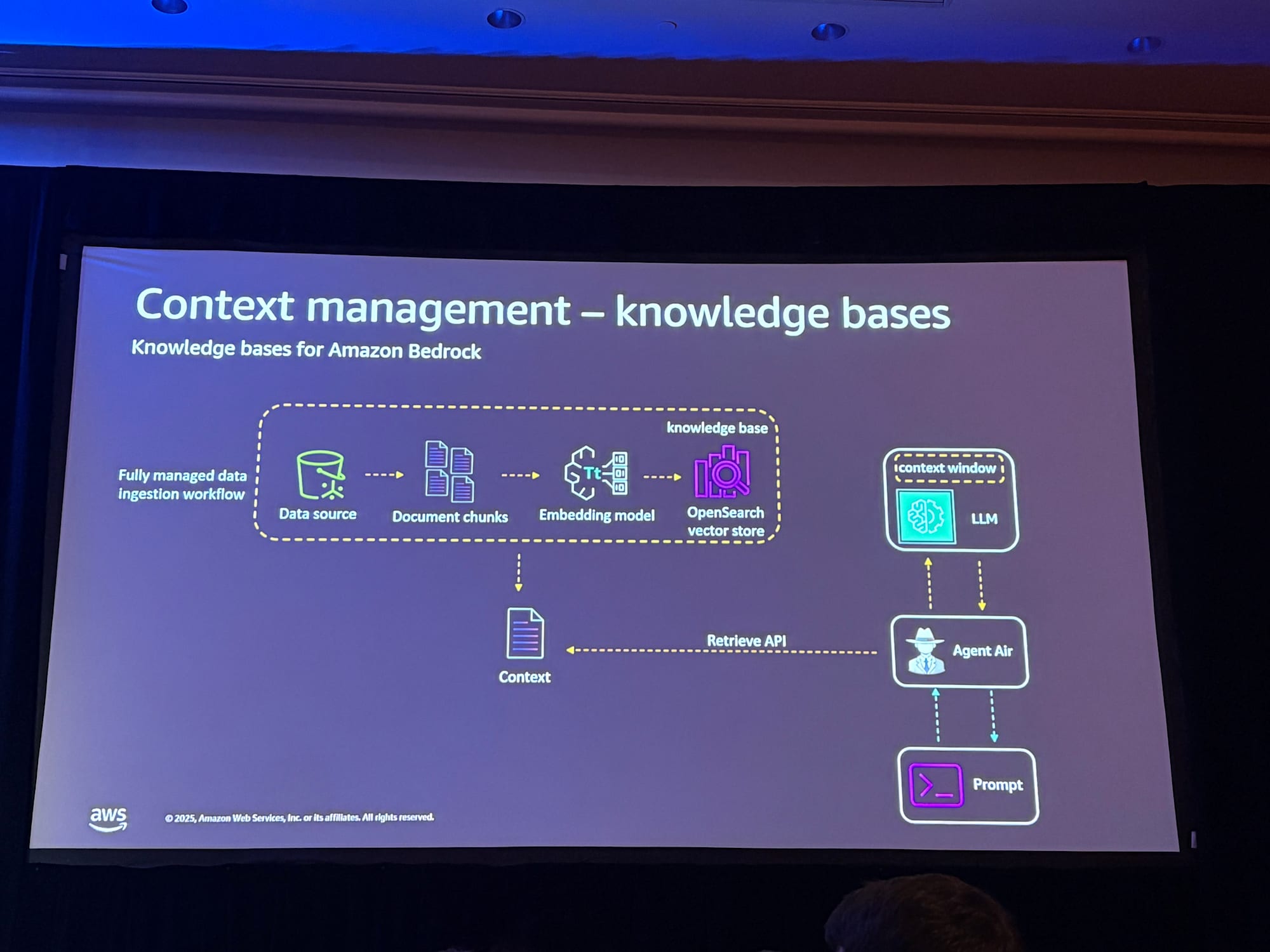
ナレッジベースは以下のように機能します。
- データの場所(S3)を指定
- 埋め込みモデルがデータをベクトル化
- ベクターストア(この例ではAmazon OpenSearch)にベクトルを保存
- エージェントがセマンティック検索を実行し、関連するポリシーをコンテキストに追加
ベクターストアの選択肢
AWSは複数のベクターストアオプションを提供しています。

Amazon OpenSearch Service(GPUアクセラレーション対応)
Amazon OpenSearch Serviceは、NVIDIA cuVSを活用したサーバーレスGPUアクセラレーションを提供しています。
- ベクターデータベースを最大10倍高速に構築
- インデックスコストを1/4に削減
- 10億規模のベクターデータベースを1時間以内に構築可能
- OpenSearch 3.1以降およびServerlessコレクションでサポート
Amazon S3 Vectors(一般提供開始)
Amazon S3 Vectorsは、re:Invent 2025で一般提供が開始された、クラウドストレージ初のネイティブベクターサポート機能です。

- 単一インデックスで最大20億ベクターを保存・検索(プレビュー時の40倍)
- ベクターバケットあたり最大20兆ベクターをサポート
- 頻繁なクエリで100ミリ秒以下のレイテンシ
- 代替ソリューションと比較して最大90%のコスト削減
- Amazon Bedrock Knowledge BasesおよびAmazon OpenSearch Serviceと統合
イベント駆動アーキテクチャとマルチエージェント
マルチエージェントの必要性
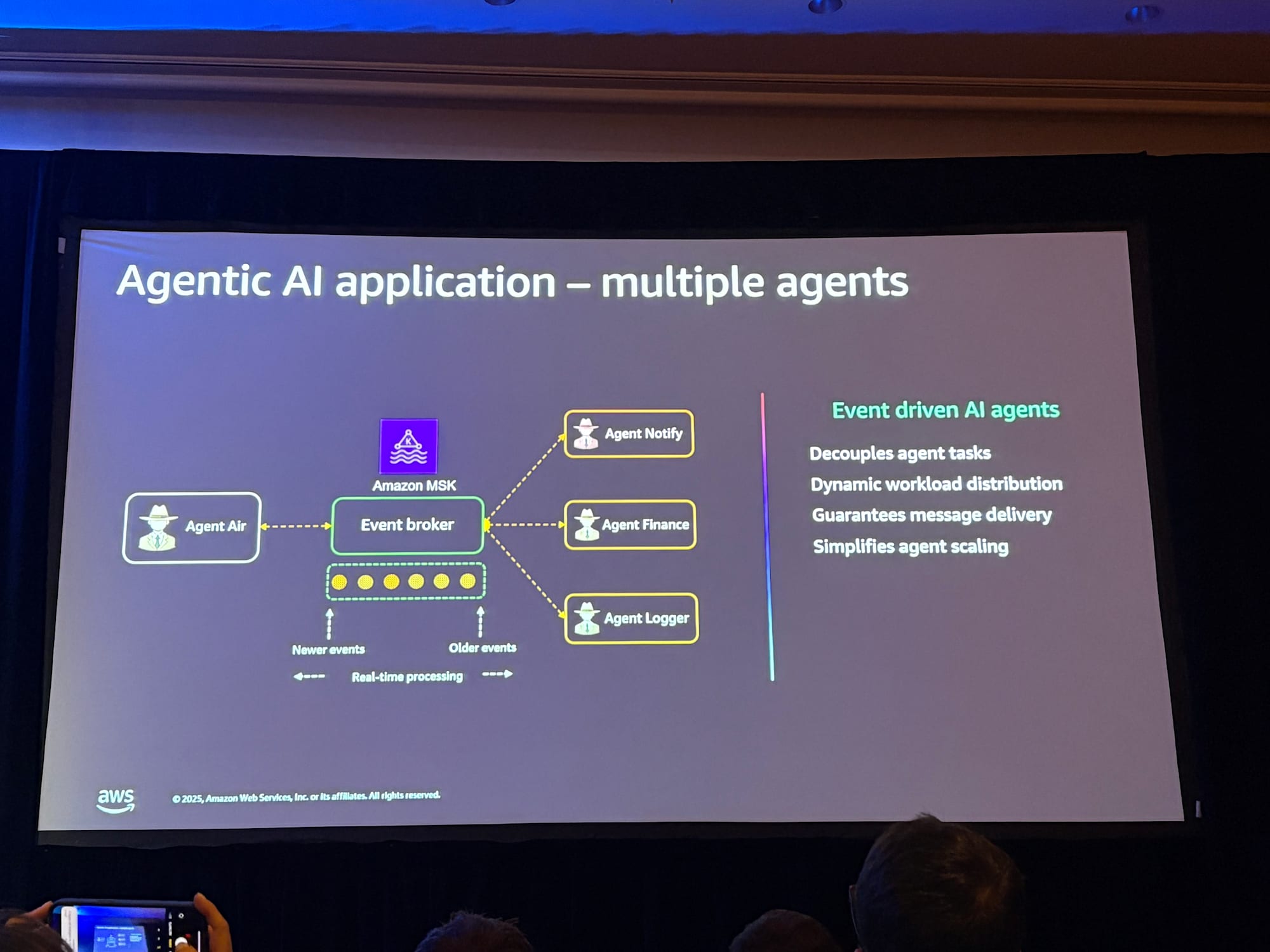
実際のAIアプリケーションでは、複数のエージェントが協調して動作することが一般的です。
デモの旅行予約アプリケーションでも、以下のような複数のエージェントが連携していました。
- メインエージェント:ユーザーとの対話、フライト検索、予約処理
- 確認メール通知エージェント:予約確認メールの送信
- ポリシーチェックエージェント:旅行ポリシー違反のチェックとルールの適用
- 請求エージェント:トランザクションの請求処理
なぜ単一のエージェントではないのか
単一のエージェントですべてを処理しようとすると、以下の問題が発生します。
- ReActループでの混乱
- 限られたコンテキストウィンドウの圧迫
- コストとパフォーマンスの悪化
イベント駆動アーキテクチャの利点
マルチエージェントシステムには、マイクロサービスベースのアプリケーションに類似した疎結合の非同期アーキテクチャが推奨されます。

Amazon MSK(Managed Streaming for Apache Kafka)を使用したイベント駆動アーキテクチャにより、
- エージェントの疎結合化:各エージェントが独立して動作
- スケーラビリティ:エージェントの追加・削除が容易
- 回復力:1つのエージェントの障害が全体に影響しない
- 永続的なイベント管理:メッセージの耐久性と配信保証
- リアルタイムなイベント交換:高スループットのイベント処理
データガバナンスとメタデータ管理
メタデータの重要性

セッションでは、メタデータが「今まさに注目を集めている」と強調されていました。
AIエージェントが自律的にデータを利用するためには、適切なメタデータが不可欠です。
従来、データ生産者とデータ消費者の間でメタデータを管理してきましたが、現在は消費者にAIエージェントも加わっています。
人間とAIの両方が同じシステムを使用できるよう、適切なメタデータとガバナンスを構築することが重要です。
Amazon SageMaker Unified Studio

次世代のAmazon SageMakerは、データ、分析、AIのための統合プラットフォームとして再構築されました。
SageMaker Unified Studio(プレビュー)
データの発見から、データ分析、データ処理、モデルトレーニング、生成AIアプリ構築まで、エンドツーエンドの開発ワークフローを単一のガバナンス環境で実行できます。
SageMaker Lakehouse
SageMaker Lakehouseは、以下を統合するオープンデータアーキテクチャを提供しています。
- Amazon S3データレイク
- Amazon Redshiftデータウェアハウス
- フェデレーテッドデータソース
Apache Iceberg互換のツールとエンジンでアクセス可能です。
SageMaker Data and AI Governance
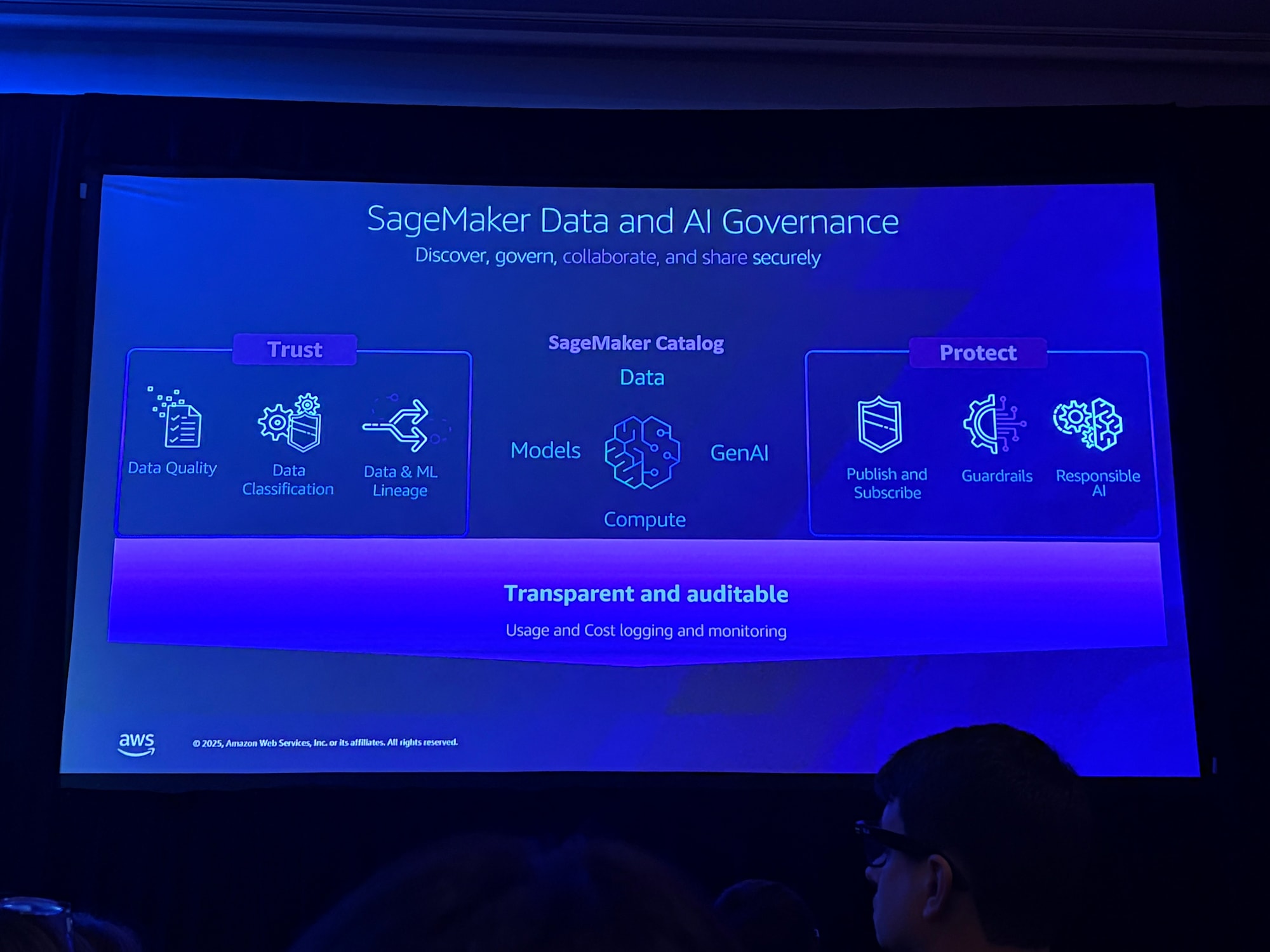
データ、モデル、エージェントを統合し、データの信頼性を構築するための中心的なプラットフォームです。
- データ品質:データの品質スコアと監視
- データリネージ:データの来歴と変換履歴の追跡
- アクセス制御:きめ細かな権限管理
- 監査証跡:すべてのアクセスと変更の記録
AIによるメタデータ自動生成
デモでは、SageMaker Catalogを使用して、AIがテーブルやカラムのビジネスコンテキストメタデータを自動生成する機能が紹介されました。
- テーブルを選択
- 「Generate」をクリック
- AIがテーブルの概要、用途、カラムの説明を自動生成
- 生成されたメタデータを確認・編集して承認
- メタデータがデータカタログにフィードバックされ、他のユーザーやエージェントが利用可能に
この機能により、従来は人手で行っていたメタデータ整備を大幅に効率化できます。
SageMaker Studioの新機能
SageMaker Notebook
新しく追加されたSageMaker Notebookでは、以下の機能がサポートされています。


- SQLセルとPythonセルを組み合わせて使用可能
- セル間でデータを相互参照可能
- 組み込みのAIエージェントがコード生成をサポート
データエージェントによるコード生成
デモでは、データエージェントを使用してセンチメント分析を実行する様子が紹介されました。
- 自然言語で「レビューのセンチメント分析を実行して」と指示
- エージェントが自動的にSQLからPythonに切り替え
- 必要なライブラリ(TextBlob、Transformers)を選択
- センチメント分析のコードを生成・実行
- エラーが発生した場合は「Fix with AI」機能で自動修正
- 結果の可視化まで自動生成
従来、このような分析には数週間かかることもありましたが、このデモでは10分以内で完了しました。
まとめ
本セッションの主要なポイントは以下の通りです:
-
新しいデータ基盤を構築する必要はない
- 既存のデータ基盤を活用し、AIアプリケーション向けに拡張する
- データとデータエンジニアリングはAIの重要な差別化要因
-
技術的なデータ機能とAI機能を活用する
- MCPサーバーでエージェントの自律性を向上
- コンテキスト管理でモデルの限界を補完
- ベクターストアでセマンティック検索を実現
- データガバナンスでAI対応のデータ品質を確保
-
段階的に始める
- すべてを一度に導入する必要はない
- ビジネスニーズに応じて必要なコンポーネントを選択する
感想
AIアプリケーション構築のためのデータ基盤について、非常に実践的な内容が紹介されたセッションでした!
日常的に業務でもプライベートでもAIを利用していますが、その背後の基盤構成についてはあまり意識できていませんでした。
最新情報のインプットと併せて基礎知識の理解に励みます...!
re:Invent2025でもAWS公式・パートナー企業の全体でAI関連のセッションが大部分を占めており、EXPOブースでもAIを取り入れたサービスの広告が多く見られました。
この業界に身を置く以上、AIアプリケーションやMl基盤の構築・運用に携わる機会は必ず訪れると思いますので、インプットは重要だと再認識できました。
以上、大野でした!
参考リンク
- Top announcements of AWS re:Invent 2025
- Introducing the next generation of Amazon SageMaker
- Amazon S3 Vectors now generally available
- Introducing Amazon Bedrock AgentCore
- Amazon OpenSearch Service GPU acceleration
- AWS MCP Servers
- Accelerating SQL analytics with Amazon Redshift MCP server
- Implementing conversational AI for S3 Tables using MCP
- Strands Agents
- Introducing Strands Agents, an Open Source AI Agents SDK
- Knowledge Bases for Amazon Bedrock
- Model Context Protocol (Anthropic)









