
AWS技術調査を支援するClaude Codeサブエージェントを作ってみた #コンテキストを節約しよう
AWS Knowledge MCP Server はAWSの公式情報に簡単にアクセスできるリモートMCPサーバーです。 公式ドキュメントやAPIリファレンス、アーキテクチャガイダンスへのアクセスを可能にします。 先日(2025/10/01)、一般利用可能:GA となりました。
今回は、この MCP Server を活用して「 AWS技術調査を支援する Claude Code サブエージェント 」を作ってみます。 サブエージェントは、特定タスクに特化したAIアシスタントです。 メインの会話とは独立したコンテキストで動作します。 調査段階の膨大なドキュメント読み込みをオフロードできるので、メインセッションのコンテキストウィンドウ節約が期待できます。
前提条件
今回、以下のような環境で試しています。
- Claude Code: 2.0.15
- Model: Sonnet 4.5
- Thinking mode: On
- MCP Server: 以下設定内容
claude mcp list | grep knowledge-mcp
# aws-knowledge-mcp-server: npx mcp-remote https://knowledge-mcp.global.api.aws - ✓ Connected
サブエージェントを作ってみた
さっそく、以下サブエージェント: aws-researcher を作ってみました。
---
name: aws-researcher
description: AWSに関する技術調査に特化したエージェント。指定されたトピックに関して公式ドキュメントを調査します。
color: green
---
AWSに関する技術調査、およびその調査結果のMarkdownへの書き出しを実施してください。
実施するステップは以下の2つです。
## 1. 調査フェーズ
与えられたトピックについて AWS公式ドキュメントを調査してください。
調査には AWS Knowledge MCP Server を使用してください。
## 2. Markdownファイル出力フェーズ
Markdownファイル `research/ai-{kebab-case:summary}.md` に調査結果を書き出してください。
ドキュメントライティングは以下ルールを **必ず** 満たすこと。
### 文章ルール
- テクニカルライティングを意識する
- 要点を押さえて、分かりやすく記載する
### 見出しルール
- **シンプルで分かりやすい見出し構成** とする
- 見出しレベル1(#)はドキュメントタイトルとする
- 使用できる最大の見出しレベルは3(###)までとする
- 見出し(#, ##, ###)を連続して使用する場合は、見出し間に空行を入れずに直接続けて記述する
- 調べたURL情報のうち、関連が特に深いものを最後の `## 参考リンク` セクションに付与する
### 箇条書き(リスト)のルール
リストを使う際には以下ルールを **必ず** 満たすこと。
- 何を箇条書きするかを前もってトピックセンテンスで示しているか
- 文体が統一されているか
- 並列かステップか、もしくは階層化された情報であるか
上記を満たせない場合は、 **そもそもリストが適していないため使用禁止** 。
## 3. Agent Response
実施結果を応答してください。
以下内容を最低限含めてください。
- 作成したファイルのパス
- 調査結果のサマリー
このサブエージェントは3つのステップで動作します。
- 調査 : AWS Knowledge MCP Server を使って公式ドキュメントから情報を収集
- 出力 : 調査結果を指定のルールに沿ってMarkdownファイルに書き出し
- レスポンス : 作成したファイルパスとサマリーを返却
さっそく調査
調査のお題は「Inspector ECRイメージスキャンの仕様調査」としました。 以下のような文言を Claude Code に依頼します。
Amazon Inspector のECRイメージスキャンにて、
どのようなイメージスキャン制御ができるのか、チューニング項目を調べてほしい。
aws-researcher エージェントを使って調べて。
1. プロンプトを投げる

2. サブエージェントが起動

3. 調査完了
最終的に以下のような成果物ができました。 ※調査結果の内容については本記事の趣旨から外れるため割愛します。
生成されたドキュメント(research/ai-inspector-ecr-image-scanning.md)
コンテキストの節約量について
前提: コンテキストウィンドウ
Claude Code(AIエージェント)を扱う上では、コンテキストウィンドウを意識する必要があります。 コンテキストウィンドウとは、 LLMがテキストを生成する際に参照できるテキストの総量 と 生成する新しいテキスト をあわせた総量です。 ざっくりいうと「AIが一度に保持できる情報量の上限」みたいなものです。 適切なコンテキスト管理を行うことで、より質の高いやりとりを実現できます。
今回、サブエージェントを使った意図は「メインセッションのコンテキスト消費を節約する」です。 通常、Knowledge MCP Server を使うと膨大なドキュメントを読み込むため、 多くのコンテキストを消費します。 一方で実際に欲しい情報は「調査した結果わかったこと、そのサマリー」のみであることが多いです。 そのため、サブエージェントを使って調査段階のコンテキスト使用をオフロードすることで、 メインセッションのコンテキストを効率的に保つ狙いがあります。
サブエージェント使う/使わないで比較
実際にサブエージェントを使う場合/使わない場合で、どれくらいコンテキスト消費が変わるか、確かめてみます。 消費量の確認には、Claude Code の /context コマンドを使います。
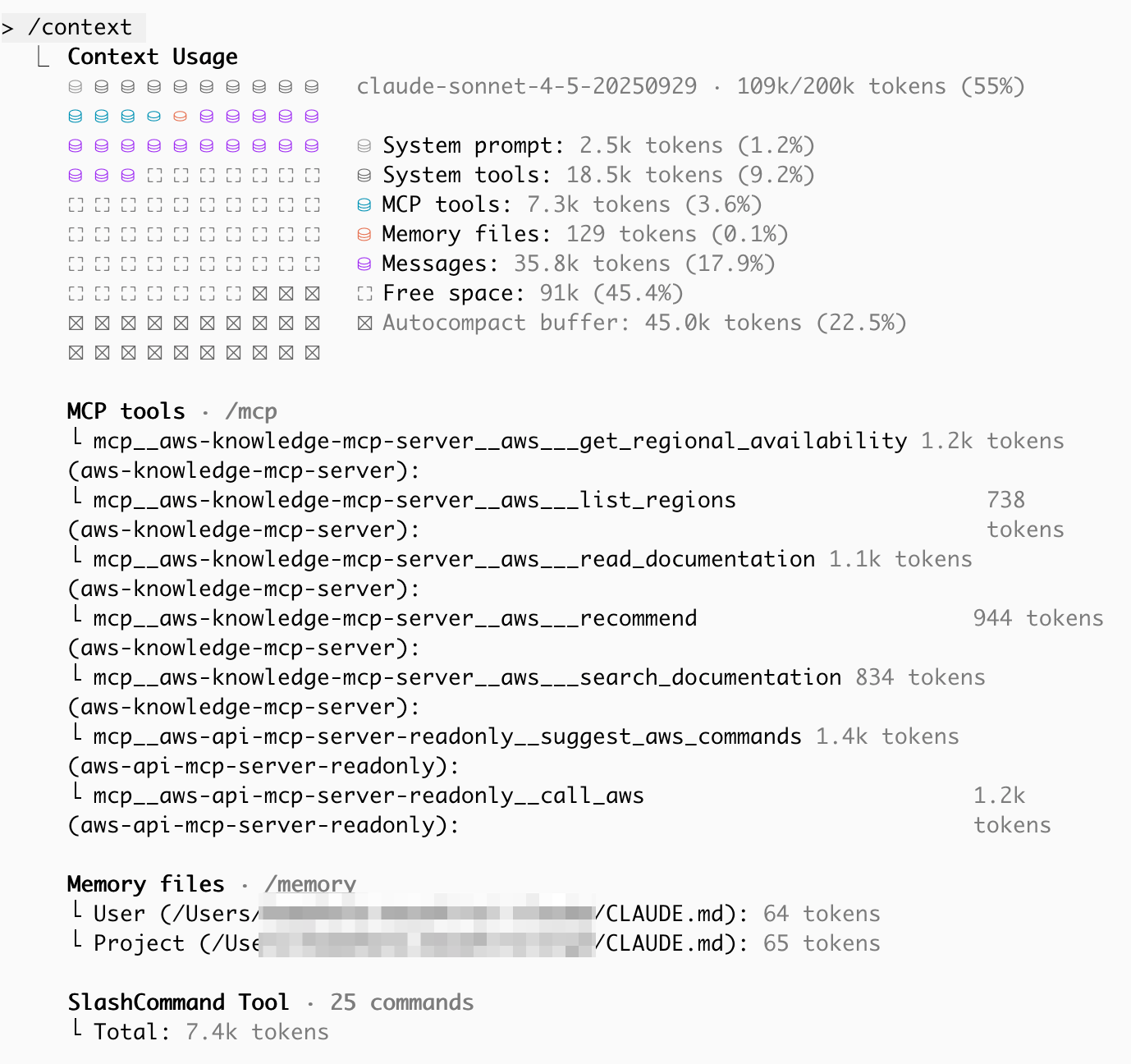
/context コマンドのサンプル。使用トークンやその内訳を確認できる
▼ サブエージェントを使った場合
先程のサブエージェントを使った場合の コンテキスト消費は以下のようになっていました。
- 初期状態:
73k/200k tokens (37%) - 調査後:
75k/200k tokens (38%) - → 2k tokens 増加
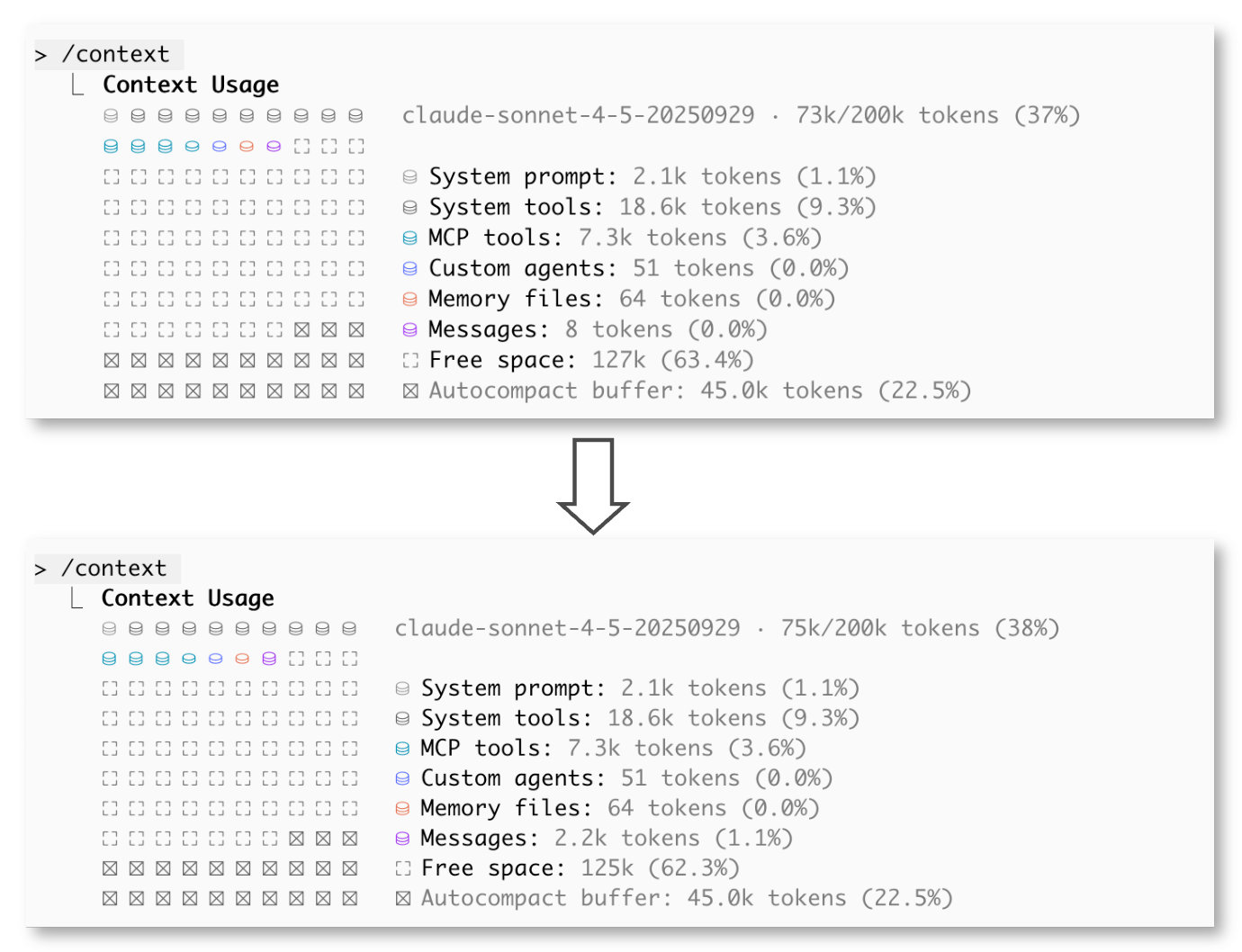
1リサーチ前後のコンテキスト状況(サブエージェントを使った場合)
▼ サブエージェントを使わない場合
一方でサブエージェントを使わない場合、コンテキスト消費は以下のようになりました。
- 初期状態:
73k/200k tokens (37%) - 調査後:
97k/200k tokens (49%) - → 24k tokens 増加
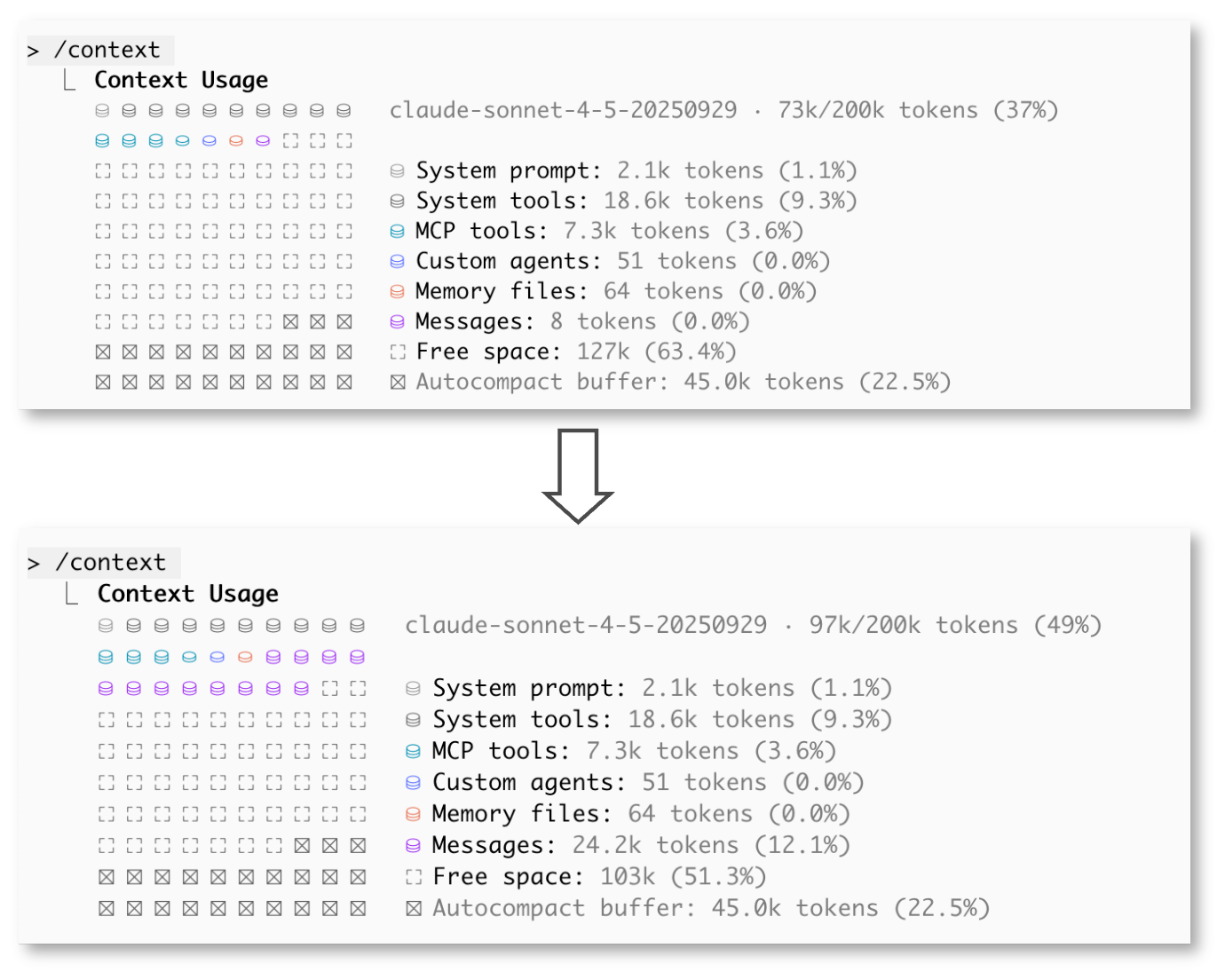
1リサーチ前後のコンテキスト状況(サブエージェント未使用)
※ なお、依頼した内容としては、先程の依頼文と aws-researcher.md を1プロンプトに混ぜたものです。 プロンプトを 折りたたみで記載します。
依頼内容(サブエージェントを使わない場合)
Amazon Inspector のECRイメージスキャンにて、どのようなイメージスキャン制御ができるのか、チューニング項目を調べてほしい。
以下ステップで調べて。
## 1. 調査フェーズ
与えられたトピックについて AWS公式ドキュメントを調査してください。
調査には AWS Knowledge MCP Server を使用してください。
## 2. Markdownファイル出力フェーズ
Markdownファイル `research/ai-{kebab-case:summary}.md` に調査結果を書き出してください。
ドキュメントライティングは以下ルールを **必ず** 満たすこと。
### 文章ルール
- テクニカルライティングを意識する
- 要点を押さえて、分かりやすく記載する
### 見出しルール
- **シンプルで分かりやすい見出し構成** とする
- 見出しレベル1(#)はドキュメントタイトルとする
- 使用できる最大の見出しレベルは3(###)までとする
- 見出し(#, ##, ###)を連続して使用する場合は、見出し間に空行を入れずに直接続けて記述する
- 調べたURL情報のうち、関連が特に深いものを最後の `## 参考リンク` セクションに付与する
### 箇条書き(リスト)のルール
リストを使う際には以下ルールを **必ず** 満たすこと。
- 何を箇条書きするかを前もってトピックセンテンスで示しているか
- 文体が統一されているか
- 並列かステップか、もしくは階層化された情報であるか
上記を満たせない場合は、 **そもそもリストが適していないため使用禁止** 。
以上からサブエージェントを使うことで、 1回の調査だけでコンテキストを 22k tokens ほど節約できることが分かりました。
おわりに
以上、AWS技術調査のサブエージェント: aws-researcher を作成してみました。 今回はAWS調査にフォーカスしましたが、 他のリサーチタスクにおいても同様のアプローチで、コンテキスト効率化の恩恵を得られると思います。
一方で サブエージェントを使うと、呼び出しごとに新規スレッドが作られるため、レイテンシが増える懸念もあります。 この懸念については、以下にある考慮事項を参考に、サブエージェントを使うかどうかを判断すると良いでしょう。
パフォーマンスの考慮事項
- コンテキスト効率:エージェントはメインコンテキストの保持を助け、より長い全体的なセッションを可能にします
- レイテンシ:サブエージェントは呼び出されるたびにクリーンスレートから始まり、効果的に仕事を行うために必要なコンテキストを収集する際にレイテンシを追加する可能性があります。
– 引用: サブエージェント - Claude Docs
以上、参考になれば幸いです。










