
Anthropicが提示するマルチエージェント設計パターン5選 〜ローカル完結からAWS実装イメージまで〜
はじめに
前回、Claude Codeのマルチエージェントを使ってChrome拡張機能を作りました。マネージャー・フロントエンド・バックエンド・QAの4人体制です。
Claude Codeのエージェントチーム機能そのものの使い方については、優秀な同期の片桐が詳しく書いてくれています。環境構築からセットアップまで丁寧に解説されているので、まずはそちらをどうぞ。
今回は「どう使うか」ではなく、「どう設計するか」の話です。前回の4人体制を組む前に、Anthropicが公開しているマルチエージェントの設計指針を読みました。
Multi-agent coordination patterns: Five approaches and when to use themという記事で、複数エージェントの構成を5つのパターンに整理した内容です。
この記事を読んで、Chrome拡張開発には Orchestrator-subagent が合うと判断して設計しました。今回はその判断の根拠を共有しながら、5つのパターン全体を整理します。ローカルで完結するパターンはClaude Codeでの構成を、ローカルでの実装が難しい3パターンは例としてAWSアーキテクチャ図つきで解説します。
パターン早見表
Anthropicは「まず Orchestrator-subagent から始め、困った課題が出たら別のパターンへ進む」という考え方を推奨しています。Chrome拡張開発でOrchestrator-subagentを選んだ理由は後述します。
| # | パターン | 強み(向いているタスク) | 弱み | 推奨環境 |
|---|---|---|---|---|
| 1 | Generator-Verifier | 品質が重要で、検証基準を明示できる | 基準が曖昧だとVerifierが機能しない | Local |
| 2 | Orchestrator-subagent | 短く明確なサブタスクに分解できる ★推奨スタート | 親がボトルネックになりやすい | Local |
| 3 | Agent Teams | 長く・並列に・独立して走れる仕事がある | Worker間の衝突・完了検知が難しい | Cloud |
| 4 | Message Bus | イベント駆動で処理が分岐し、エージェントが増える | デバッグとイベント追跡が難しい | Cloud |
| 5 | Shared State | 互いの発見を参照しながら探索を深める共同調査 | 終了条件がないと無限ループになる | Cloud |
Agent TeamsはWorkerのクラッシュ耐性、Shared Stateは並列書き込みの競合管理、Message Busは非同期イベントルーティングの観点で、ローカルのファイルシステムでは運用上の限界が出やすくなります。
5つのパターンを読んでみる
1. Generator-Verifier ― 生成と検証を役割分担し、差し戻しループで品質を上げる
一方が案を出し(Generator)、もう一方がそれを審査する(Verifier)。NGなら差し戻して修正、OKなら次へ進むというループ構成です。
強み: コード生成とテスト、コンプライアンス確認、ファクトチェックのように、「良いか悪いか」を明確な基準で判定できるタスクで品質を担保できます。単一エージェントでは見逃しやすいミスをVerifierが捕捉するため、出力の信頼性が上がります。
弱み: Verifierの検証基準が曖昧だと機能しません。「良いコードかどうか確認して」では「なんとなく良さそうです」と通してしまう可能性が高いです。「テストが全件通るか」「SQLインジェクションのリスクがないか」のような、判定できる基準の明文化が前提となります。また差し戻しが繰り返されても決着がつかないケースがあるため、差し戻し上限とフォールバックを最初から設計しておく必要があります。
ローカルでの構成:
Claude Codeのエージェントチームで「Generator担当」と「Verifier担当」の2役を立てます。それぞれの役割と検証基準をCLAUDE.mdかプロンプト内に明記しておくと良いでしょう。
roles:
generator:
役割: 要件に従ってコードを生成し output/draft.md に書き出す
verifier:
役割: output/draft.md を読み、以下の基準で評価して output/feedback.md に書き出す
検証基準:
- テストが全件通るか
- 型エラーがないか
- セキュリティ上の問題がないか
差し戻し上限: 3回。超えた場合は output/fallback.md に理由を記載して終了
ファイルを受け渡しの媒体にすることで、Claude Code上でループを実現できます。GeneratorとVerifierが同じディレクトリを共有し、draft.md → feedback.md → draft.md(修正版) という流れで回します。
2. Orchestrator-subagent ― タスクを分解して並列処理する、Anthropic推奨の標準構成
親エージェント(Orchestrator)がタスク全体を分解してサブエージェント(Subagent)に振り、最後に結果を統合する構成です。Anthropicが「まずここから始めるべき」と明示しているパターンで、Claude Code自体もこの構成の例として挙げられています。
強み: タスクを明確に分解でき、サブタスク同士の依存が少ない場合に適しています。コードレビューの並列実行や、複数ページのドキュメント一括生成など。Orchestratorが全体を把握しているため、進捗や品質の管理がしやすく、最初に試すパターンとして扱いやすいです。
弱み: 情報がOrchestratorに集まるためボトルネックになりやすいです。あるサブエージェントの発見を別のサブエージェントに伝える際にOrchestratorを経由する必要があり、要約されすぎたり伝達が遅れたりします。並列化を明示しないとマルチエージェントのコストだけかかって速度の恩恵が出ないケースもあります。
ローカルでの構成:
Claude Codeがこのパターンをネイティブに実装しています。メインセッションに「このタスクを分割してサブエージェントに並列で実行させて」と指示するだけで動きます。
実際の流れはシンプルです。
1. メインセッション(Orchestrator)がタスクを分解
例:「docs/以下の3ファイルをそれぞれ要約してoutput/以下に書き出して」
2. Claude Codeが各ファイルへのサブエージェントを並列起動
└ subagent-a: docs/api.md → output/api-summary.md
└ subagent-b: docs/setup.md → output/setup-summary.md
└ subagent-c: docs/usage.md → output/usage-summary.md
3. 全サブエージェント完了後、メインセッションが output/ を回収して統合
サブタスクの結果をファイルに書き出させ、Orchestratorが最後に読み取る設計にすると、Claude Codeの標準的なファイル操作の範囲内で完結します。
3. Agent Teams ― 担当領域の文脈を長期保持しながら並列で走るWorker型
複数のWorkerエージェントがタスクキューから仕事を取り、長期間にわたって担当領域の文脈を保持しながら走るパターンです。Orchestrator-subagentとの最大の違いはWorkerが生き続けること。Orchestrator-subagentがタスクごとにサブエージェントを起動して終了させるのに対し、Agent TeamsのWorkerは担当領域の文脈を蓄積しながら複数タスクを処理し続けます。
強み: Workerが担当領域の文脈を長期保持するため、大規模なコードベースのフレームワーク移行のように、深い理解が必要な長期並列タスクに有効です。担当を固定することで、同じ領域への繰り返しの理解コストを減らせるようになります。
弱み: Worker同士が衝突しやすく、共有ファイルやDBを操作すると競合が起きやすいです。途中の気づきをWorker間で自然に共有する仕組みがないため、情報の分断が起きることがあり、全Workerの完了検知もOrchestrator-subagentより複雑になりやすいです。
4. Message Bus ― イベントの発行・購読でエージェントを疎結合に繋ぐ
各エージェントがイベントをpublish/subscribeしながら連携するイベント駆動型の構成です。あるエージェントの処理結果がイベントとして発行され、それを受け取った別のエージェントが起動するという連鎖で処理が進みます。
強み: エージェントを疎結合に保てるため、新しいエージェントを追加するときに既存の配線を変えなくて済みます。セキュリティ運用の自動化(異常検知→調査→対処)のように、外部イベントを起点に処理が複雑に分岐するパイプラインや、将来的にエージェントの種類が増えていく構成に向いています。
弱み: どのイベントがどこへ飛び、どのエージェントが反応したかを追いにくくデバッグが難しいです。ルーティングの設定ミスにより裏で失敗するリスクがあるため、全イベントをログに残す設計を最初から入れることが実質必須になります。
5. Shared State ― 共有ストレージを介して互いの発見を活かす共同調査型
中央の司令塔なしに、全エージェントが共通のストレージを読み書きして協調するパターンです。論文・市場・特許などを別々のエージェントが調べ、互いの発見を参照しながら次に何を調べるかを変えていく共同調査が典型例です。
強み: 中央の司令塔がないため単一障害点がなく、エージェント同士がリアルタイムで互いの発見を参照しながら探索の方向を変えられます。あるエージェントの気づきが別のエージェントの調査を自然に深めていき、有機的な協調が生まれやすいです。
弱み: 終了条件を最初から設計しないと、互いの更新に反応してまた書き込み、それにまた反応して…というループでトークンを消費し続ける事があります。重複作業も起きやすいので、「最後の更新から30分経過したら終了」「調査エントリ数が100件を超えたら終了」のような明示的な収束条件が必須です。
なぜChrome拡張開発でOrchestrator-subagentを選んだか
前回のChrome拡張開発で使ったのはOrchestrator-subagentに当たります。マネージャーがフロントエンド・バックエンド・QAにタスクを振り、結果を統合するという役割分担がそのまま Orchestrator-subagent の構成です。
前回のタスクは「同じサイトのタブを自動でグループ化し、アルファベット・50音順で整列させる」という機能の開発です。実装領域を分解すると以下のようになりました。
- フロントエンド:ポップアップUI・スタイル・ユーザー操作の処理
- バックエンド:タブグループ化ロジック・eTLD+1判定・デバウンス処理(300ms)
- QA:動作確認・エッジケース検証・レビュー
担当領域が明確に独立しており、サブタスクへの分解とその統合が自然に設計できる構造でした。フロントエンド・バックエンド・QAそれぞれに明確なアウトプット(UIの実装、ロジックの実装、検証レポート)があり、Orchestratorであるマネージャーが最終的に統合する役割を担いました。
マネージャーを置いたのは、タスク分配・進捗管理・成果物統合を担当させるためです。結果としてMV3対応・デバウンス処理・整合性チェックの要件を満たす実装が完成しました。
クラウド推奨パターンの実装イメージ
Agent Teams・Message Bus・Shared State の3パターンは、ローカルのファイルシステムでは耐障害性・競合管理・イベントルーティングの面で限界が出るため、クラウド上で実装することをおススメします。今回は実際にAWS上で構成するなら、といった形で整理していきます。
Agent Teams on AWS ― ECS Fargateで文脈を保持したWorkerを長期稼働させる
Workerが長期間動き続ける構成なので、LambdaよりECS Fargate(コンテナ)が向いています。コンテナはSQS FIFOからジョブを取り続け、担当領域の文脈をコンテナメモリに保持します。全Workerの完了はDynamoDB Streams + Lambdaで検知します。
アーキテクチャ図:
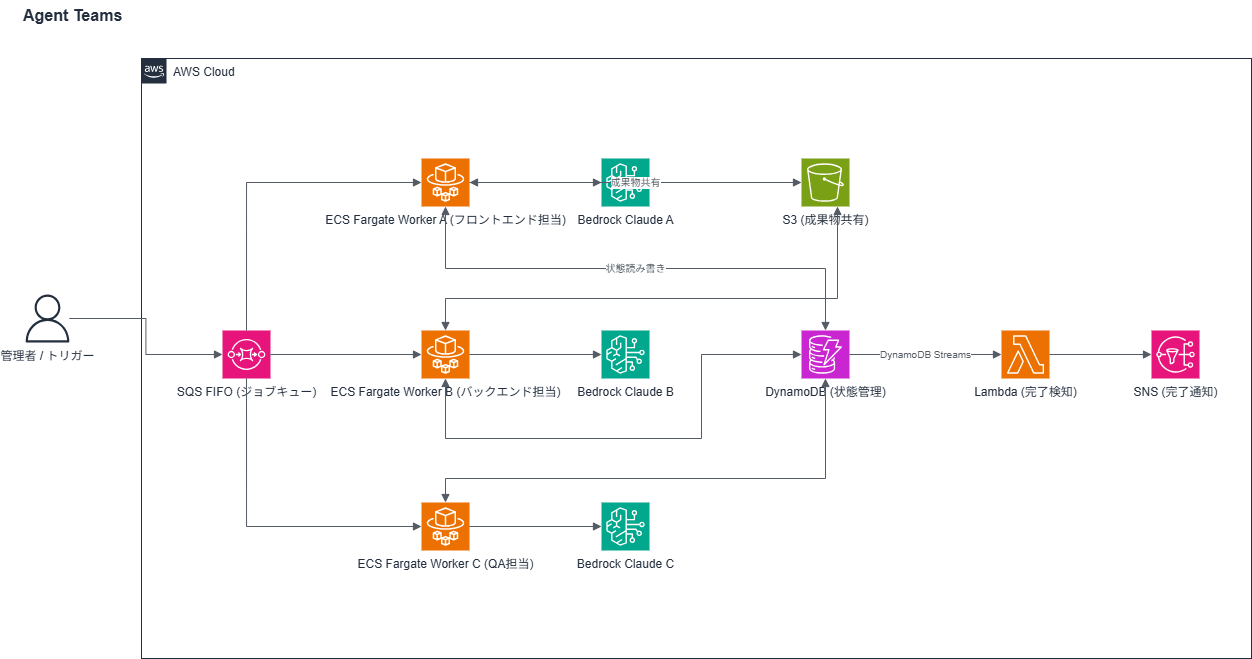
| 設計ポイント | 理由 |
|---|---|
| SQS FIFOのメッセージグループIDでタスクを分ける | Worker間の二重取得を防ぐ |
| DynamoDB Streamsで全Worker完了を検知 | 完了検知が難しいため専用の仕組みが必要 |
| S3バージョニングを有効化 | Worker間の成果物共有で古いファイルを参照するリスクを減らす |
Message Bus on AWS ― EventBridgeをハブに各エージェントをイベントで疎結合に繋ぐ
EventBridgeをバスとして使い、各エージェントLambdaがpublisher兼subscriberとして動きます。EventBridgeのルール設定でどのエージェントがどのイベントを受け取るかを管理します。
アーキテクチャ図:
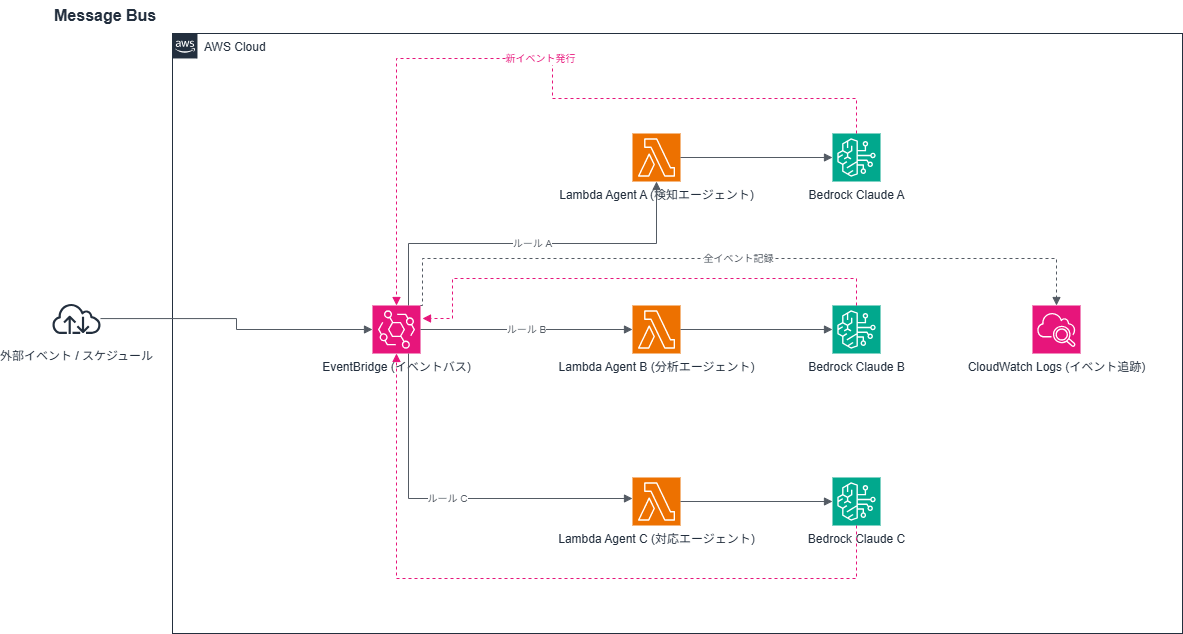
| 設計ポイント | 理由 |
|---|---|
| 全イベントをCloudWatch Logsに記録するルールを必ず追加 | デバッグ用 |
| EventBridge Schema Registryでイベントschemaを管理 | ルーティングミスを早期に検出できる |
Shared State on AWS ― ElastiCacheとDynamoDBで共有ステートを高速かつ永続化する
頻繁な読み書きが必要なのでElastiCache(Redis)を共有ステートとして使い、永続化はDynamoDBで分担します。終了条件のチェックはStep Functionsで管理するとタイムアウト・再試行の制御がしやすいです。
アーキテクチャ図:
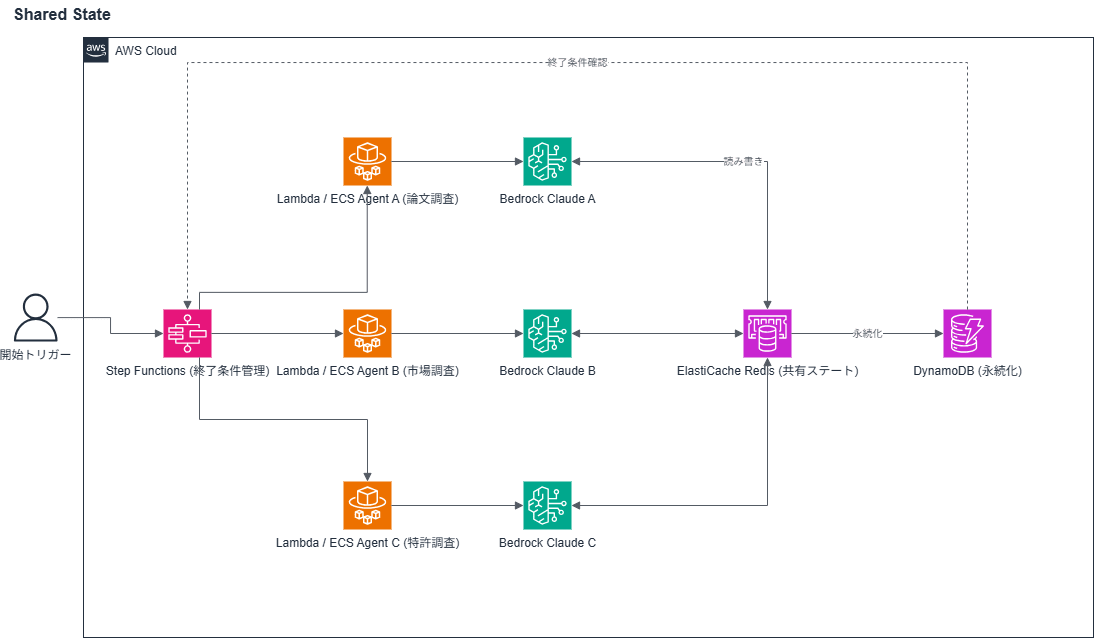
| 設計ポイント | 理由 |
|---|---|
| Redisキーに最終更新タイムスタンプを持たせる | 古い情報への過剰反応ループを防ぐ |
| Step Functionsで終了条件を管理 | タイムアウト・収束条件の制御がしやすい |
クラウド推奨パターンのAWSサービス対応まとめ
| パターン | 実行基盤 | 状態管理 | 調整レイヤー | 向いているコスト特性 |
|---|---|---|---|---|
| Agent Teams | ECS Fargate | DynamoDB + S3 | SQS FIFO | 長時間稼働 |
| Message Bus | Lambda | CloudWatch Logs | EventBridge | 都度起動・短命 |
| Shared State | Lambda / ECS | ElastiCache + DynamoDB | Step Functions | 読み書き頻度次第 |
まとめ
Anthropicの5つのパターンを知っていると、マルチエージェントの設計が「人数をどうするか」という問いではなく、「このタスクはどの構成か」という問いから始まるようになります。
前回のChrome拡張開発はOrchestrator-subagentでした。担当領域が明確に独立していてサブタスクへの分解が自然にできる構造だったので、Anthropicの推奨パターンがそのまま合っていた形です。同じ「マルチエージェントで開発する」でも、タスクの性質によって合う構成は変わります。
おわり!











