
Claude CodeとTerraformでCloudWatchの導入を省力化しよう
こんにちは!
クラウド事業本部 運用イノベーション部の大野です。
業務上、AWS環境にCloudWatchの監視(Alarm やカスタムダッシュボード)を構築する機会が度々あります。
対象が増えるほど、似たようなリソースを環境ごとに少しずつパラメータを変えながら大量に作ることになり、なかなかに工数のかかる作業です。
今回は、この構築作業を Terraform と Claude Code の併用 で省力化する方法をご紹介します。
初めに結論だけお伝えすると、.tf 側で「型」だけ先に決めておき、実際の値である terraform.tfvars の作成をClaude Codeにお任せする、という内容になります。
そもそもの前提として「なぜTerraformを使うのか」「Claude Codeの挙動をどう制御して安全に使うのか」については、別の方の記事で大変わかりやすく解説されていますので、ぜひご一読ください!
本記事ではその前提には深入りせず、.tfvars の生成と流用に絞ってご紹介いたします。
またサンプルも用意しましたので、お時間あれば実際に手元でお試しください。
(フィードバックもお待ちしております!)
.tfで「型」、tfvarsで「値」を分担する
本題に入ります。
AIとTerraformの併用の要点としては、AIに触らせる範囲を限定することです。
.tf(リソース定義・変数定義):最初に用意し、以降は基本的に変更しないterraform.tfvars(値):AI(本記事ではClaude)が生成する
リソースの構造や検証ルールは .tf に固定されているため、Claude Codeが触るのは「どの環境に・どの閾値で・どのリソースを監視するか」という値だけになります。
生成対象が値に限定されるので出力のブレが小さく、一定の冪等性を担保しながら作業を省力化できます。
.tf側:型とバリデーションを先に固める
まず variables.tf で、監視対象ごとの「型」を定義しておきます。
ここでは例としてEC2インスタンスの標準メトリクス監視設定を挙げます。
アラート重要度として「Warning / Critical」の2種を設定し、それぞれに評価回数や比較演算子、閾値を持たせる構造です。
variable "ec2_instances" {
description = "EC2インスタンスの監視設定リスト"
type = list(object({
resource_name = string
instance_id = string
cpu_utilization = optional(object({
warning = optional(object({ evaluation_periods = number, comparison = string, threshold = number, datapoints_to_alarm = number }))
critical = optional(object({ evaluation_periods = number, comparison = string, threshold = number, datapoints_to_alarm = number }))
}))
network_in = optional(object({
warning = optional(object({ evaluation_periods = number, comparison = string, threshold = number, datapoints_to_alarm = number }))
critical = optional(object({ evaluation_periods = number, comparison = string, threshold = number, datapoints_to_alarm = number }))
}))
network_out = optional(object({
warning = optional(object({ evaluation_periods = number, comparison = string, threshold = number, datapoints_to_alarm = number }))
critical = optional(object({ evaluation_periods = number, comparison = string, threshold = number, datapoints_to_alarm = number }))
}))
}))
default = []
validation {
condition = length(var.ec2_instances) == length(distinct([for i in var.ec2_instances : i.resource_name]))
error_message = "resource_name はリスト内で一意である必要があります。"
}
validation {
condition = alltrue([
for i in var.ec2_instances : can(regex("^i-[0-9a-f]{8,17}$", i.instance_id))
])
error_message = "instance_id は 'i-' で始まる有効な EC2 インスタンス ID である必要があります。"
}
validation {
condition = alltrue(flatten([
for i in var.ec2_instances : [
for m in ["cpu_utilization", "network_in", "network_out"] : [
for sev in ["warning", "critical"] :
try(i[m][sev].comparison, null) == null ||
contains([">", ">=", "<", "<="], i[m][sev].comparison)
]
]
]))
error_message = "comparison は '>', '>=', '<', '<=' のいずれかである必要があります。"
}
}
validation ブロックを置いておくことで、resource_name の重複や comparison の表記ゆれといった、生成AIがやりがちなミスを terraform plan の前に弾いてくれます。
型とバリデーションを先に固めておくことで、AIの出力に対するガードレールとして機能してくれます。
tfvars側:Claude Codeが値だけを生成する
.tf で型が決まっていれば、Claude Codeに生成させる範囲は変数に入れ込む値だけで済みます。
生成される terraform.tfvars はこのようなイメージになります。
aws_account_id = "123456789012"
region = "ap-northeast-1"
sns_topic_arn = "" # 空なら通知アクションなしでアラームだけ作成
ec2_instances = [
{
resource_name = "web-server"
instance_id = "i-0123456789abcdef0"
cpu_utilization = {
warning = { evaluation_periods = 3, comparison = ">", threshold = 70, datapoints_to_alarm = 3 }
critical = { evaluation_periods = 3, comparison = ">", threshold = 90, datapoints_to_alarm = 3 }
}
network_in = {
warning = { evaluation_periods = 3, comparison = ">", threshold = 100000000, datapoints_to_alarm = 3 }
critical = { evaluation_periods = 3, comparison = ">", threshold = 200000000, datapoints_to_alarm = 3 }
}
network_out = {
warning = { evaluation_periods = 3, comparison = ">", threshold = 100000000, datapoints_to_alarm = 3 }
critical = { evaluation_periods = 3, comparison = ">", threshold = 200000000, datapoints_to_alarm = 3 }
}
},
]
以下は冒頭に添付した検証用のリポジトリの内容です。
ディレクトリ構成は、cloudwatch-alarm-setup/ と cloudwatch-dashboard-setup/ をそれぞれ _template/ 配下にまとめた最小構成にしています。
今回の例ではEC2の標準メトリクス(CPU・NetworkIn・NetworkOut)だけをAlarm作成の対象にしています。
terraform-monitoring-setup/
├── example-customer.md # 入力(監視ヒアリングシート)
├── .claude/skills/generate-tfvars/ # md → tfvars 生成スキル(/generate-tfvars)
│ └── SKILL.md
├── cloudwatch-alarm-setup/
│ └── _template/
│ ├── terraform.tf # required_version
│ ├── providers.tf # provider 設定
│ ├── variables.tf # 型(スキーマ)+ validation ← 人間が用意
│ ├── main.tf # EC2 アラームの生成ロジック
│ ├── outputs.tf
│ ├── terraform.tfvars.example # 生成結果の例
│ └── terraform.tfvars # 値 ← Claude Code が生成
└── cloudwatch-dashboard-setup/ # (ダッシュボードは後述)
└── _template/
main.tf が var.ec2_instances を読み、(インスタンス × メトリクス × Warning/Critical)の組み合わせを aws_cloudwatch_metric_alarm に展開します。
Alarm構築の流れ
実際の流れはシンプルです。
監視要件をまとめた入力を渡し、tfvars 生成用に用意したカスタムスキルを実行します。
スキル化しておくと、フィールドの対応づけや命名規則を毎回プロンプトで指示せずに済み、担当者ごとの入力ブレも防げます。
# 監視要件(example-customer.md)から tfvars を生成するカスタムスキル
/generate-tfvars example-customer.md
生成後は terraform plan で中身を確認しておきましょう。
cd cloudwatch-alarm-setup/_template
terraform init
terraform plan -out=tfplan
planの内容に問題がなければapplyします。
作業内容に責任を持つという意味合いを込めて、AIを通さない方法でのplan結果の確認(確認用スクリプト+目視)を実施していますが、想定外のリソースが作成されてしまった...などの事象は今のところ発生していません。
terraform apply tfplan
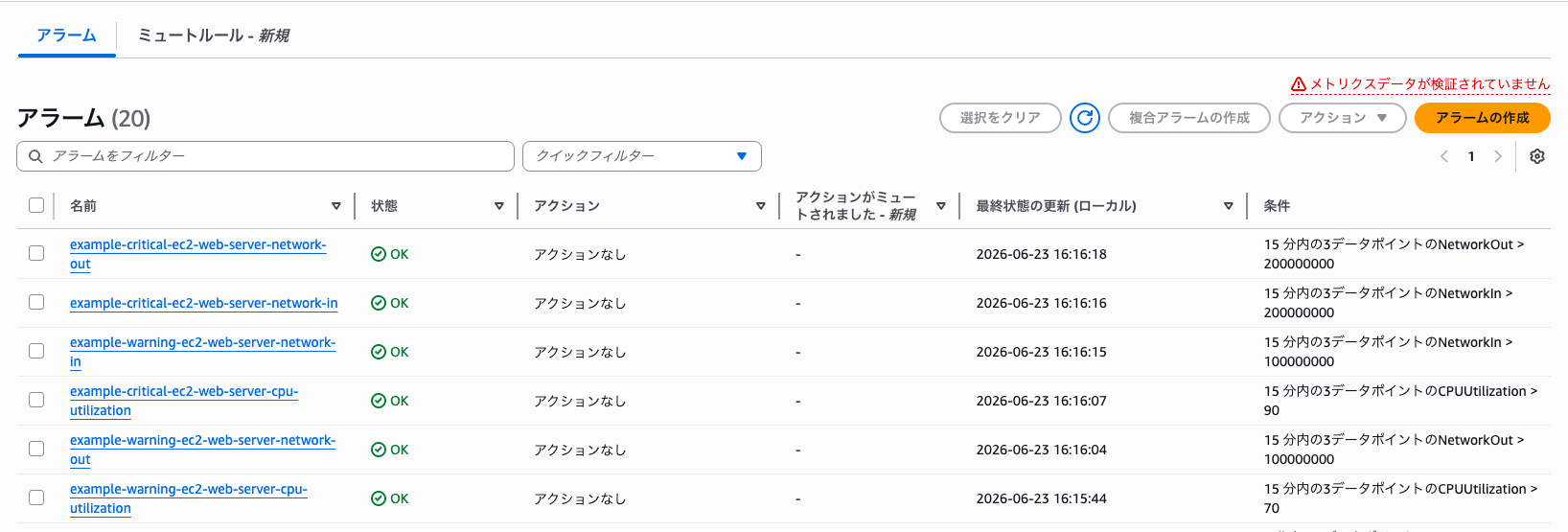
作成されるAlarm例 ↓
カスタムダッシュボードをTerraformで実装する
ここからがTerraformの恩恵を感じられる部分ですね。
Alarm用に作った tfvars は、カスタムダッシュボード側でもそのまま流用できます。
ダッシュボード側の構成もAlarm側とほぼ同じで、main.tf がダッシュボード本体、locals.tf が tfvars からウィジェット(グラフ)を組み立てる役割です。
cloudwatch-dashboard-setup/
└── _template/
├── terraform.tf # required_version
├── providers.tf # provider 設定
├── variables.tf # Alarm と同じスキーマ + dashboard_config
├── main.tf # aws_cloudwatch_dashboard(本体JSON)
├── locals.tf # tfvars → ウィジェットJSON の組み立て
└── outputs.tf
Alarmのtfvarsをそのまま使える理由はシンプルで、Alarm用とダッシュボード用の2つのルートモジュールが、まったく同じ変数スキーマを宣言している からです。
tfvars に書いてあるのは「どの環境の・どのリソースを監視したいか」という監視の意図そのものです。
この同じ意図を、
- Alarm側のモジュールは
aws_cloudwatch_metric_alarm(アラーム)として解釈する - ダッシュボード側のモジュールは
aws_cloudwatch_dashboardのウィジェット(グラフ)として解釈する
という違いがあるだけで、入力となる変数(ec2_instances など)の名前と型は両者で共通です。
なお、ダッシュボード側の変数定義は、型チェックをAlarm側で済ませているぶん、type = any で受けるだけのシンプルな形にしています。
# dashboard 側: Alarm と同名・同型の変数を受け取るだけ
variable "ec2_instances" {
description = "EC2インスタンスの監視設定リスト(Alarm の tfvars を流用)"
type = any
default = []
}
ダッシュボード本体:tfvarsからウィジェットを組み立てる
ダッシュボードの main.tf では、tfvars から組み立てたウィジェット配列(local.all_widgets)を aws_cloudwatch_dashboard の本体JSONに流し込むだけです。
# main.tf
resource "aws_cloudwatch_dashboard" "this" {
# 監視対象が1つも無ければダッシュボード自体を作らない
count = length(local.all_widgets) > 0 ? 1 : 0
dashboard_name = "example-${var.aws_account_id}-${var.region}"
dashboard_body = jsonencode({
start = "-PT6H"
periodOverride = "inherit"
widgets = local.all_widgets
})
}
ウィジェット定義:変数をループしてJSONを生成
肝心のウィジェットは、locals.tf で var.ec2_instances をループして組み立てます。
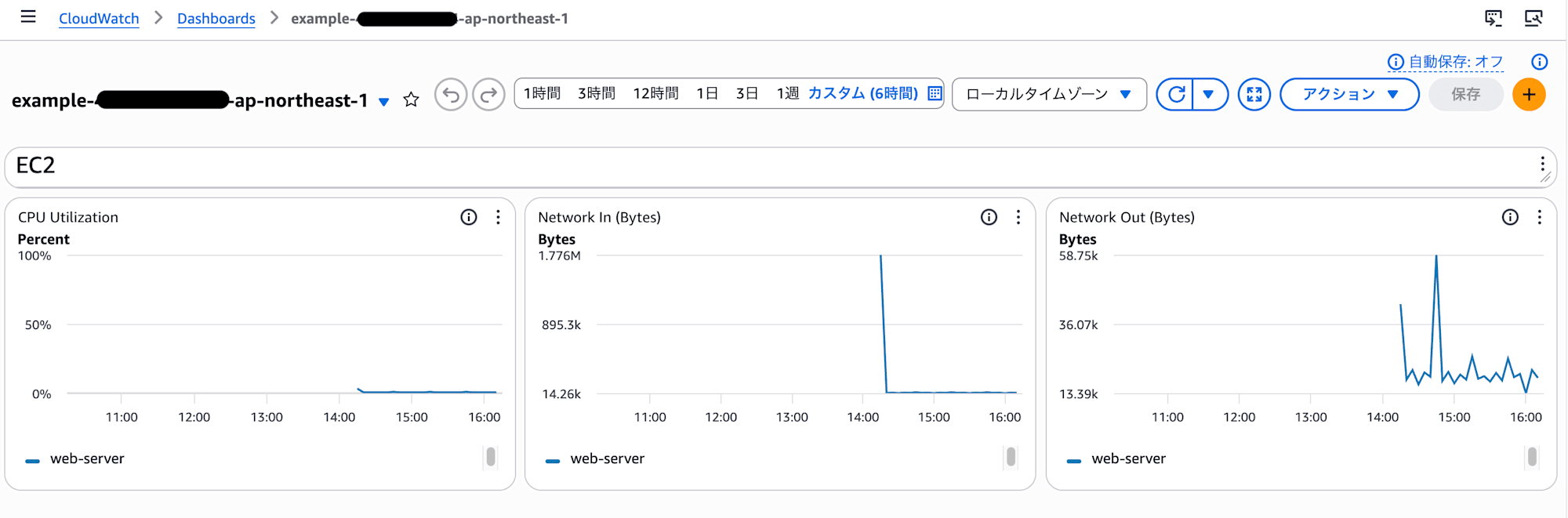
たとえばCPU使用率グラフは、CPU監視が設定されているインスタンスだけをグラフ上に並べて表示する、という作りです。
# locals.tf
locals {
ec2_widgets = concat(
# セクション見出し(監視対象がある時だけ表示)
length(var.ec2_instances) > 0 ? [{
type = "text", width = 24, height = 1,
properties = { markdown = "## EC2" }
}] : [],
# CPU使用率グラフ: cpu_utilization が設定されたインスタンスだけを並べる
length([for i in var.ec2_instances : i if try(i.cpu_utilization, null) != null]) > 0 ? [{
type = "metric", width = 8, height = 6,
properties = {
title = "CPU Utilization"
view = "timeSeries"
region = var.region
period = 300
stat = "Average"
yAxis = { left = { min = 0, max = 100 } }
metrics = [
for i in var.ec2_instances :
["AWS/EC2", "CPUUtilization", "InstanceId", i.instance_id, { label = i.resource_name }]
if try(i.cpu_utilization, null) != null
]
}
}] : []
# NetworkIn / NetworkOut も同じ要領で並べる
)
}
ダッシュボードには「ウィジェットの一覧」を1本の配列で渡す必要があるため、サービスごとに作ったウィジェットを最後に flattenで1つの配列(all_widgets)にまとめます。
さらに dashboard_config を使うと、「EC2のグラフだけ表示する」のように、表示するセクションを選ぶこともできます(指定しなければ全部表示)。
# locals.tf(続き)
locals {
enabled = try(var.dashboard_config.enabled_sections, null)
# enabled_sections 未指定なら全表示、指定があれば該当セクションのみ
all_widgets = flatten([
[for w in local.ec2_widgets : w if local.enabled == null || contains(local.enabled, "ec2")],
])
}
tfvars に書いた監視対象が、そのままグラフの並びになる構造です。
流用の手順
Alarm作成時に生成されたtfvarsをコピーするだけです。
# alarm-setup の tfvars をそのままダッシュボード側へコピー
cp cloudwatch-alarm-setup/_template/terraform.tfvars \
cloudwatch-dashboard-setup/_template/terraform.tfvars
cd cloudwatch-dashboard-setup/_template
terraform init
terraform plan -out=tfplan
terraform apply tfplan
表示するセクションを絞りたい場合は、dashboard_config で指定できます(指定しなければ全サービスを表示します)。
# terraform.tfvars に追記、または dashboard.auto.tfvars(任意)
dashboard_config = {
enabled_sections = ["ec2"]
}
作成されるカスタムダッシュボード例 ↓
やってみて感じたメリット
これまでの繰り返しにもなりますが、実際に使用して効果を感じているのは次の点です。
- 省力化
- ヒアリング事項を読み取って
tfvarsに転記していく作業をAIにお任せできるので、大幅な工数削減につながりました。 - おそらく処理速度とコストだけで考えれば専用のスクリプトを開発した方が良いのでしょうが、記入時の表記揺れがあった場合でも処理が止まることなく設定値を入れ込んだ上でこちらに報告してくれるなど、単純なスクリプトだけでは実現できない温かみがあります。(挙動はモデルに依存します)
- またスクリプトの場合は仕様変更やランタイム更新に伴う影響が発生しますが、AIの場合はその辺りを考慮する必要がないのもメリットですね。
- ヒアリング事項を読み取って
- 冪等性・再現性
- リソースの構造は
.tfに固定されているので、tfvarsの値が同じなら同じ結果になります。 tfvarsの作成もskillで依頼すれば、実行者によらず再現性を確保できます。
- リソースの構造は
- レビューのしやすさ
- 差分が
tfvarsとterraform planに閉じるため、何が変わるのかを追いやすいです。 - plan実行時に
terraform plan -out=tfplan && terraform show -json tfplan > tfplan.jsonなどで結果をファイルに出力しておくとより利便性と透明性が上がります。
- 差分が
0から100まで「AIに丸投げ」ではなく、型の作成と検証を人間が担当し、値の作成だけをAIに任せるという分担にしたことで、省力化と安心感の確保を両立できたと感じています。
今後はtfvars作成時のコスト削減と高速化を目標として改良を進めていきます。
まとめ
CloudWatchの監視構築を、.tf で「型」を固定し tfvars の作成をClaude Codeに任せる形にすることで、冪等性を保ちながら省力化できた!という内容でした。
tfvarsの流用は当初から想定していたわけではなく棚ぼた的なメリットだったのですが、ありがたく活用させてもらっております。
私自身、Terraformを使い始めてまだ半年程度の初学者ではありますが、この記事がどなたかのお役に立てれば幸いです。
「なぜTerraformなのか」「Claude Codeの挙動をどう制御するのか」が気になられた方は、ぜひ冒頭でご紹介した記事もあわせてご覧ください。
以上、大野でした!











