
Vertex AI経由でのClaude Code利用の監査ログ周りについて調査する
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
エンタープライズ環境でAIコーディングアシスタントを導入する際、「誰がいつどのモデルを使ったか」「どのようなプロンプトが送られたか」を記録・追跡できることはコンプライアンス上の重要な要件かと思います。Claude CodeをVertex AI経由で利用している場合、Google Cloudが提供する2種類のログ機能を組み合わせることで、Claude Codeの使用状況を多層的に記録することができます。
今回は、Vertex AIのログ機能(Cloud Audit LogsとRequest-Response Logging)の違いを整理した上で、それぞれの有効化手順とCloud Logging・BigQueryを使った確認方法を紹介します。
Cloud Audit LogsとRequest-Response Loggingの違い
Vertex AI経由でClaude Codeを使用する際、ログには2種類があります。まず両者の違いを整理します。
| 項目 | Cloud Audit Logs | Request-Response Logging |
|---|---|---|
| 記録内容 | 誰がいつどのAPIを呼び出したか | プロンプトとレスポンスの全文 |
| 保存先 | Cloud Logging(_Defaultバケット) | BigQueryテーブル |
| デフォルト | Admin Activityのみ有効 | 無効(明示的に有効化が必要) |
| 主な用途 | コンプライアンス・セキュリティ監査 | 不正利用検知・コスト・トークン使用量分析 |
| プロンプト内容 | 含まない | 含む |
本記事では、両方のログを設定するハンズオンも実施します。
Vertex AIのCloud Audit Logsとは
Cloud Audit LogsはGoogle Cloudが提供する監査ログ機能で、「誰が・何を・いつ・どこで」行ったかを記録します。Vertex AIでは以下の2種類の監査ログが利用できます。
Admin Activity監査ログ(常時有効)
リソースの作成・削除・変更などの管理操作を記録します。無効化できず、追加費用なしで常時有効です。
代表的な記録対象操作の例は以下の通りです。
| 操作 | 説明 |
|---|---|
endpoints.create |
エンドポイントの作成 |
endpoints.deployModel |
モデルのデプロイ |
Claude CodeをVertex AI経由で使う場合、これらの管理操作は自動的に記録されます。
Data Access監査ログ(明示的な有効化が必要)
デフォルトでは無効になっており、明示的に有効化しないと記録されません。3種類のサブタイプがあります。
| タイプ | 説明 | Claude Code利用時の該当操作 |
|---|---|---|
| ADMIN_READ | メタデータ・設定情報の読み取り | endpoints.get、models.list など |
| DATA_READ | ユーザーデータの読み取り | endpoints.rawPredict(←Claude Code呼び出し) |
| DATA_WRITE | ユーザーデータの書き込み | 該当なし(Claudeのみ使用の場合) |
重要なのはDATA_READです。Claude CodeはVertex AI上のClaudeモデルに対してrawPredict/streamRawPredictメソッドで推論リクエストを送りますが、これがendpoints.rawPredict操作としてDATA_READログに記録されます。つまり、DATA_READを有効化しないとClaude Codeの呼び出し自体は監査ログに残りません。
Data Access監査ログが記録する情報
Data Access監査ログには以下の情報が含まれます(プロンプト内容は含まれません)。
| フィールド | 内容 |
|---|---|
timestamp |
APIが呼び出された時刻 |
protoPayload.authenticationInfo.principalEmail |
呼び出したユーザー/サービスアカウントのメールアドレス |
protoPayload.requestMetadata.callerIp |
呼び出し元のIPアドレス |
protoPayload.methodName |
操作名(例: google.cloud.aiplatform.v1.PredictionService.StreamRawPredict) |
protoPayload.resourceName |
呼び出したモデルのリソース名 |
protoPayload.serviceName |
aiplatform.googleapis.com |
これにより「誰が(principalEmail)・どのモデルを(resourceName)・いつ(timestamp)・どこから(callerIp)使ったか」を追跡することができます。
Data Access監査ログを有効化してみる
ここからは実際にData Access監査ログを有効化し、Claude Codeの呼び出しがログに記録されることを確認する手順を紹介します。
前提条件
- Google CloudプロジェクトにVertex AI APIが有効化されていること
- Claude CodeがVertex AIを使用するよう設定済みであること(
CLAUDE_CODE_USE_VERTEXとCLOUD_ML_REGIONとANTHROPIC_VERTEX_PROJECT_IDの環境変数が設定済み) gcloudCLIがインストール・認証済みであること- プロジェクトのIAMポリシー設定権限(
resourcemanager.projects.setIamPolicy)を持っていること
Vertex AI経由でClaude Codeを利用するための、初期セットアップに関しては以下のブログを参照してください。
Data Access監査ログを設定する
Data Access監査ログをコンソール上から設定していきます。
[IAMと管理] -> [監査ログ]をクリックします。
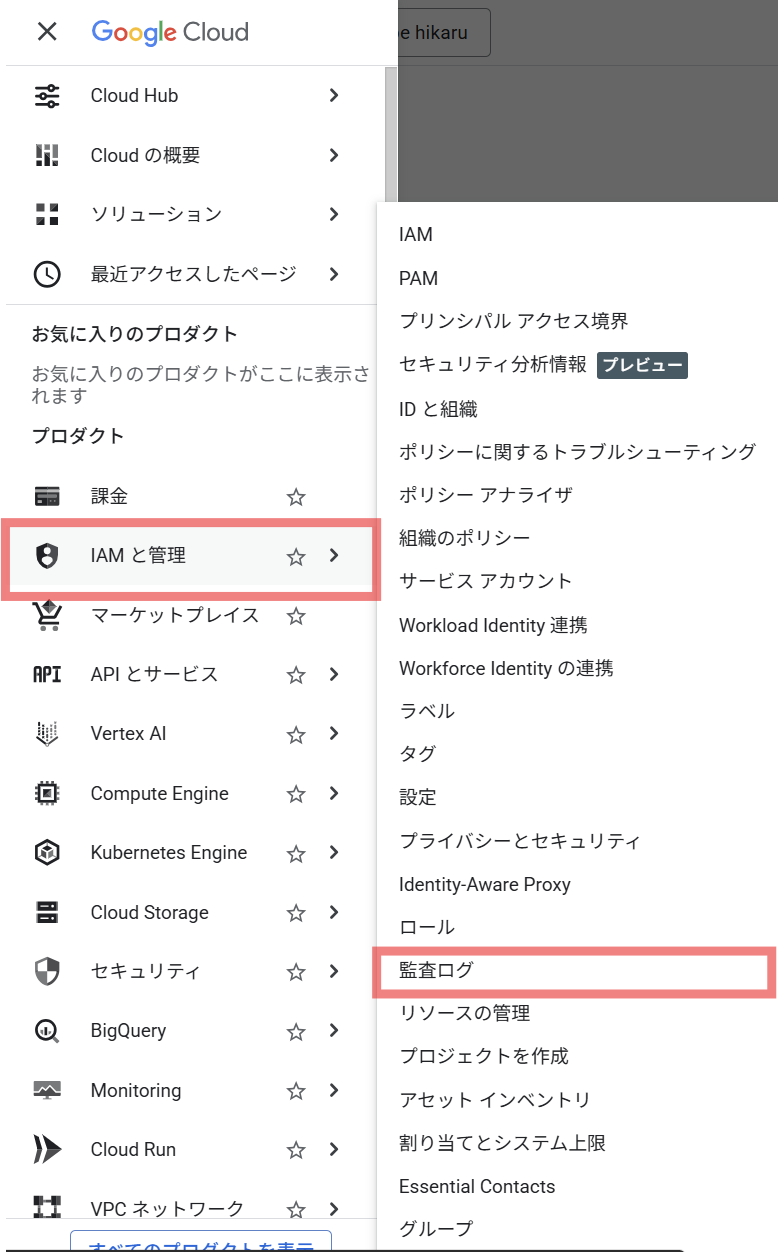
フィルタにVertex AI APIを入力し、監査ログの設定を行いたいサービスをフィルタリングします。
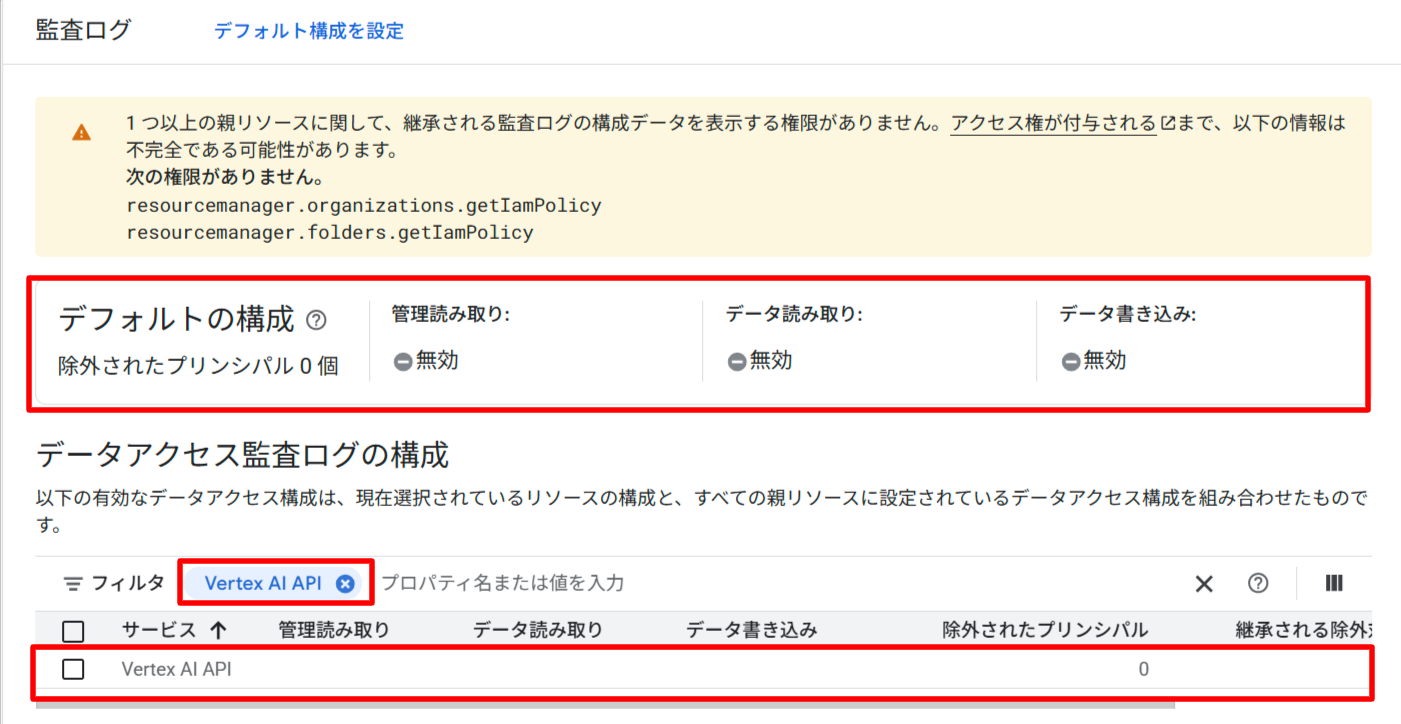
Vertex AI APIをクリックすると、右側に以下の監査ログの種類が表示されるので、データ読み取り:DATA_READのみを選択し、保存をクリックします。
- 管理読み取り:ADMIN_READ
- データ読み取り:DATA_READ
- データ書き込み:DATA_WRITE
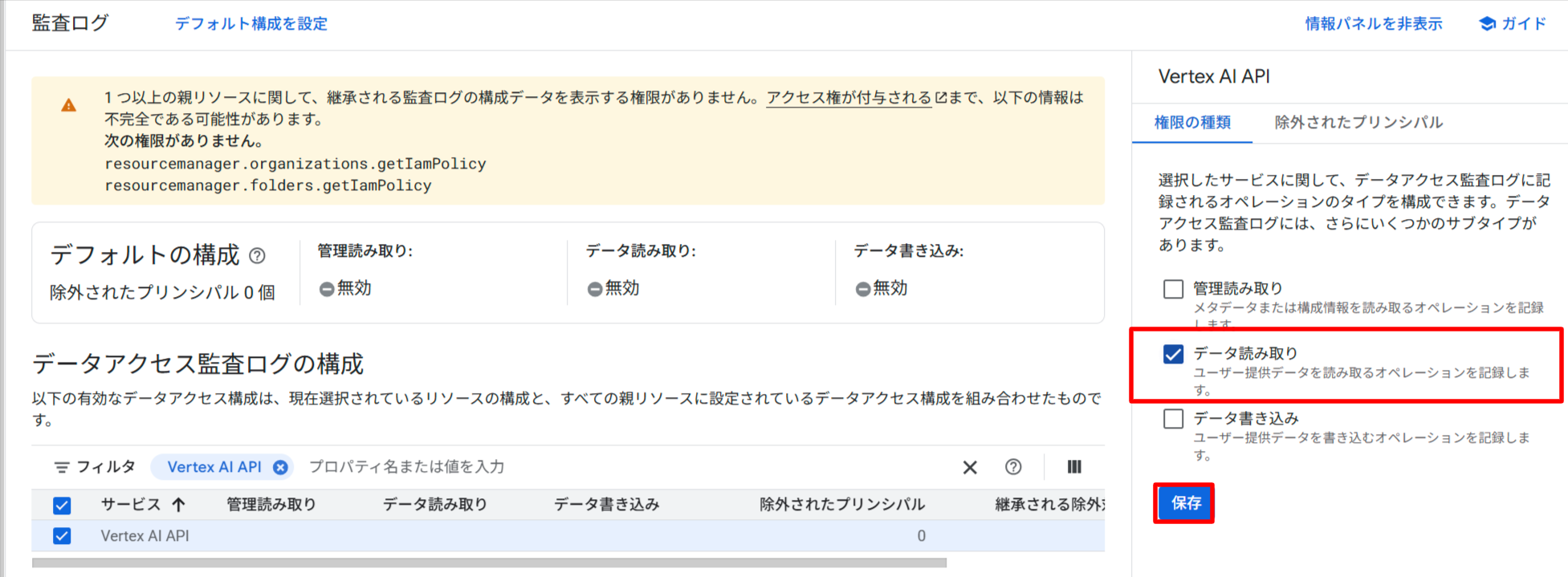
保存が完了すると、データ読み取り:DATA_READのみにチェックがつきます。
これでData Access監査ログの設定は完了です。
Data Access監査ログを閲覧するロールを付与する
Data Access監査ログはPrivate Logs Viewerロール(roles/logging.privateLogViewer)がないと閲覧できません。通常のroles/logging.viewerでは閲覧不可です。
# 監査ログ閲覧者にPrivate Logs Viewerロールを付与
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:LOG_VIEWER_EMAIL" \
--role="roles/logging.privateLogViewer"
Claude Codeで推論を実行してログを生成する
Claude CodeをVertex AI経由で動かし、監査ログのエントリを生成します。
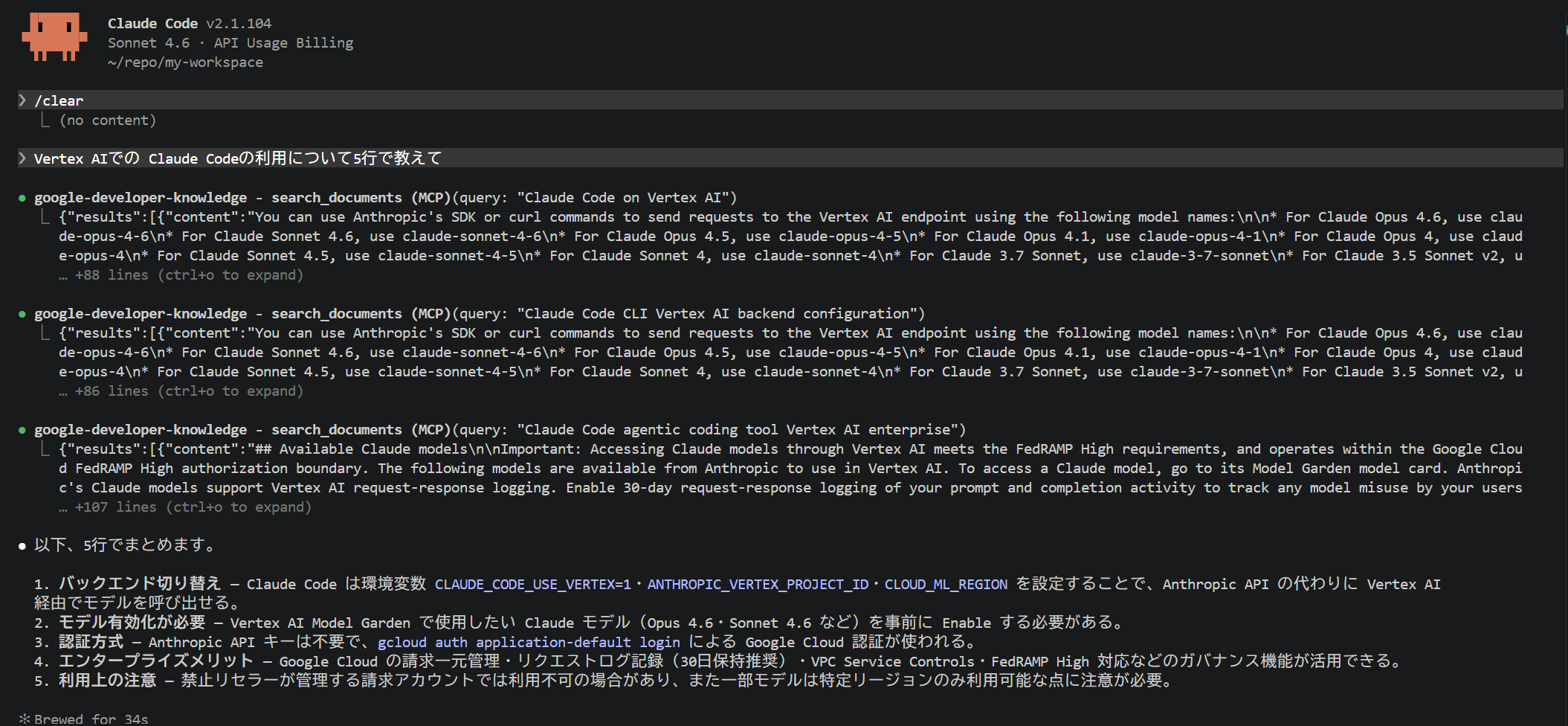
この状態でClaude Codeを起動すると、Vertex AIへのAPIリクエストが自動的に発生します。
監査ログを確認する
設定反映後にClaude Codeを使用すると、Data Access監査ログが記録されます。Cloud Loggingのコンソール画面からVertex AIのData Accessログを絞り込んで確認します。
resource.type="audited_resource"
protoPayload.serviceName="aiplatform.googleapis.com"
protoPayload.authorizationInfo.permissionType="DATA_READ"
{
insertId: "****"
logName: "projects/****/logs/cloudaudit.googleapis.com%2Fdata_access"
operation: {
first: true
id: "****"
producer: "aiplatform.googleapis.com"
}
protoPayload: {
@type: "type.googleapis.com/google.cloud.audit.AuditLog"
authenticationInfo: {
oauthInfo: {
oauthClientId: "****.apps.googleusercontent.com" (Google Auth Library)
}
principalEmail: "****@****.jp"
principalSubject: "user:****@****.jp"
}
authorizationInfo: [
0: {
granted: true
permission: "aiplatform.endpoints.predict"
permissionType: "DATA_READ"
resource: "projects/****/locations/global/publishers/anthropic/models/claude-sonnet-4-6"
resourceAttributes: {
}
}
]
methodName: "google.cloud.aiplatform.v1.PredictionService.StreamRawPredict"
request: {
@type: "type.googleapis.com/google.cloud.aiplatform.v1.StreamRawPredictRequest"
endpoint: "projects/****/locations/global/publishers/anthropic/models/claude-sonnet-4-6"
}
requestMetadata: {
callerIp: "***.***.***.***"
callerSuppliedUserAgent: "claude-cli/2.1.104 (external, cli),gzip(gfe)"
destinationAttributes: {
}
requestAttributes: {
auth: {
}
time: "2026-04-12T22:56:15.751663977Z"
}
}
resourceName: "projects/****/locations/global/publishers/anthropic/models/claude-sonnet-4-6"
response: {
@type: "type.googleapis.com/google.api.HttpBody"
}
serviceName: "aiplatform.googleapis.com"
status: {
}
}
receiveTimestamp: "2026-04-12T22:56:18.792616870Z"
resource: {
labels: {
method: "google.cloud.aiplatform.v1.PredictionService.StreamRawPredict"
project_id: "****"
service: "aiplatform.googleapis.com"
}
type: "audited_resource"
}
severity: "INFO"
timestamp: "2026-04-12T22:56:15.741821158Z"
}
protoPayload.authenticationInfo.principalEmailフィールドで誰"****@****.jp"がClaude Codeを使用したかを確認できます。protoPayload.methodNameフィールドで利用されたAPIgoogle.cloud.aiplatform.v1.PredictionService.StreamRawPredictを確認することができます。
これでClaude Code利用者の誰が利用しているかの監査ログについて取得することができました。
Request-Response Loggingを設定してみる
Request-Response Loggingは、Claude Codeが送ったプロンプトとモデルのレスポンスの全文をBigQueryに記録する機能です。Cloud Audit Logsでは「誰が呼んだか」しか分かりませんが、Request-Response Loggingと組み合わせることで「何を送って何が返ってきたか」まで把握できます。
前提条件
- Vertex AI API(
aiplatform.googleapis.com)と BigQuery API(bigquery.googleapis.com)が有効化されていること - BigQueryデータセットへの書き込み権限(
roles/bigquery.dataEditor)を持っていること
BigQueryデータセットを作成する
ログの保存先となるBigQueryデータセットを作成します。
bq mk \
--location=US \
--dataset \
"${GOOGLE_CLOUD_PROJECT}:vertex_ai_logs"
ロギングを有効化する
ClaudeモデルのRequest-Response LoggingはREST APIで設定します。AnthropicモデルはPython SDK(google-cloud-aiplatform)による設定には対応していないため、setPublisherModelConfig APIを直接呼び出す必要があります。
samplingRateは0.0〜1.0の範囲で指定します。1.0ですべてのリクエストをログに記録します。
setPublisherModelConfig APIを呼び出してロギングを有効化します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-d '{
"publisherModelConfig": {
"loggingConfig": {
"enabled": true,
"samplingRate": 1.0,
"bigqueryDestination": {
"outputUri": "bq://${GOOGLE_CLOUD_PROJECT}.vertex_ai_logs"
},
"enableOtelLogging": true
}
}
}' \
"https://us-east5-aiplatform.googleapis.com/v1beta1/projects/${GOOGLE_CLOUD_PROJECT}/locations/us-east5/publishers/anthropic/models/claude-sonnet-4-6:setPublisherModelConfig"
複数モデルを使用している場合は、モデルごとにコマンドを実行します(例: claude-haiku-4-5)。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-d '{
"publisherModelConfig": {
"loggingConfig": {
"enabled": true,
"samplingRate": 1.0,
"bigqueryDestination": {
"outputUri": "bq://${GOOGLE_CLOUD_PROJECT}.vertex_ai_logs"
},
"enableOtelLogging": true
}
}
}' \
"https://us-east5-aiplatform.googleapis.com/v1beta1/projects/${GOOGLE_CLOUD_PROJECT}/locations/us-east5/publishers/anthropic/models/claude-haiku-4-5:setPublisherModelConfig"
設定を確認する
fetchPublisherModelConfig APIで設定が反映されたことを確認します。
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://us-east5-aiplatform.googleapis.com/v1beta1/projects/${GOOGLE_CLOUD_PROJECT}/locations/us-east5/publishers/anthropic/models/claude-sonnet-4-6:fetchPublisherModelConfig"
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://us-east5-aiplatform.googleapis.com/v1beta1/projects/${GOOGLE_CLOUD_PROJECT}/locations/us-east5/publishers/anthropic/models/claude-haiku-4-5:fetchPublisherModelConfig"
sonnet-4.6とhaiku-4.5ともに以下のようなレスポンスが返ってくれば設定完了です。
{
"loggingConfig": {
"enabled": true,
"samplingRate": 1,
"bigqueryDestination": {
"outputUri": "bq://${GOOGLE_CLOUD_PROJECT}.vertex_ai_logs.request_response_logging"
},
"enableOtelLogging": true
}
}
BigQueryでプロンプト・レスポンスを確認する
Claude Codeを使用すると、BigQueryのrequest_response_loggingテーブルにログが蓄積されます。テーブルのスキーマには以下のフィールドが含まれます。
| フィールド | 型 | 内容 |
|---|---|---|
logging_time |
TIMESTAMP | レスポンス返却時刻 |
request_id |
NUMERIC | リクエストID |
model |
STRING | モデルのリソース名 |
api_method |
STRING | RawPredict / StreamRawPredict |
request_payload |
REPEATED STRING | Claudeへのプロンプト(全文) |
response_payload |
REPEATED STRING | Claudeのレスポンス(全文) |
request_payloadとresponse_payloadはREPEATED STRING(配列型)のため、クエリではARRAY_TO_STRING()関数で結合して扱います。
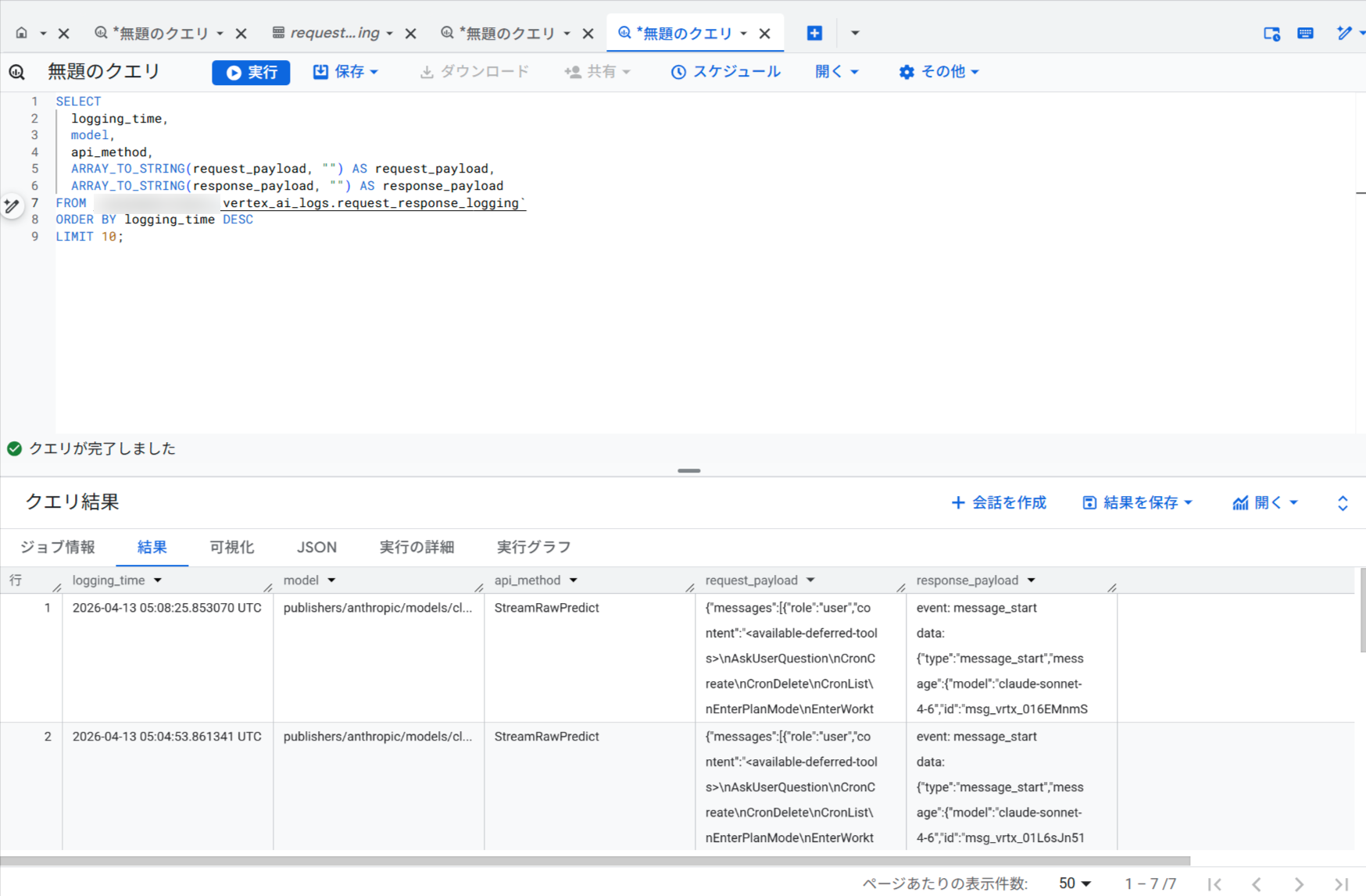
以下のクエリで直近のリクエストとレスポンスを確認できます。
SELECT
logging_time,
model,
api_method,
ARRAY_TO_STRING(request_payload, "") AS request_payload,
ARRAY_TO_STRING(response_payload, "") AS response_payload
FROM `your-project-id.vertex_ai_logs.request_response_logging`
ORDER BY logging_time DESC
LIMIT 10;
直近のリクエストとレスポンスを確認することができました。
リクエストとレスポンスの内容についてはもう少し解析しがいがありそうです。
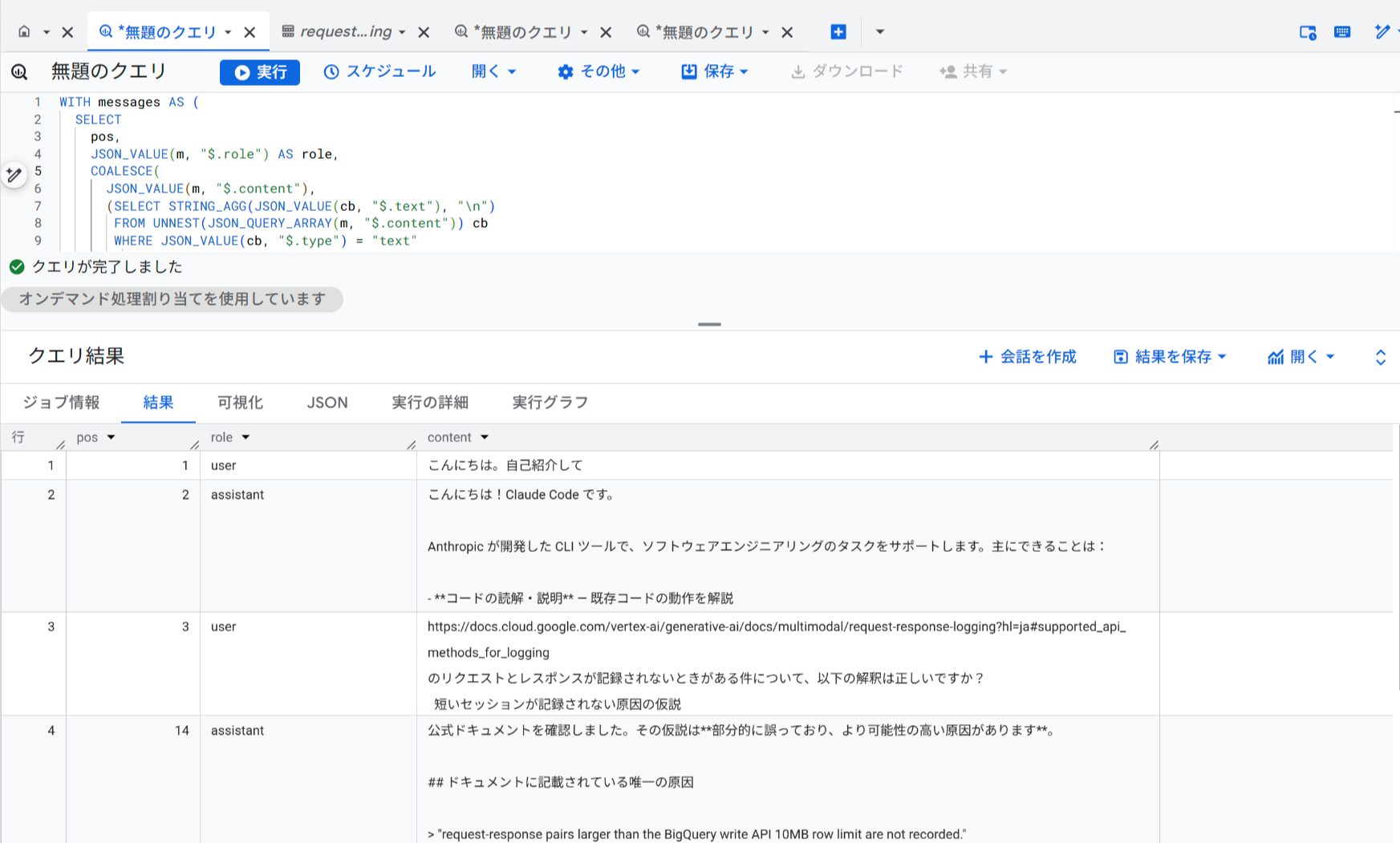
プロンプトとレスポンスのテキストを抽出する
request_payloadにはClaude APIのリクエストJSONが格納されており、messages配列の中にユーザーの入力テキストとアシスタントの応答テキストが含まれています。以下のクエリで会話の内容をテキストとして抽出できます。
WITH messages AS (
SELECT
pos,
JSON_VALUE(m, "$.role") AS role,
COALESCE(
JSON_VALUE(m, "$.content"),
(SELECT STRING_AGG(JSON_VALUE(cb, "$.text"), "\n")
FROM UNNEST(JSON_QUERY_ARRAY(m, "$.content")) cb
WHERE JSON_VALUE(cb, "$.type") = "text"
AND JSON_VALUE(cb, "$.text") NOT LIKE "<%")
) AS content
FROM UNNEST(
JSON_QUERY_ARRAY(
SAFE.PARSE_JSON(
ARRAY_TO_STRING(
(SELECT request_payload
FROM `your-project-id.vertex_ai_logs.request_response_logging`
ORDER BY logging_time DESC LIMIT 1),
""
)
),
"$.messages"
)
) AS m WITH OFFSET pos
)
SELECT pos, role, LEFT(content, 300) AS content
FROM messages
WHERE content IS NOT NULL AND content != ""
AND content NOT LIKE "<%"
AND content NOT LIKE "Tool loaded%"
AND content NOT LIKE "Base directory for this skill:%"
ORDER BY pos;
先ほどのクエリよりかはより具体的な会話の内容が抽出することができました。
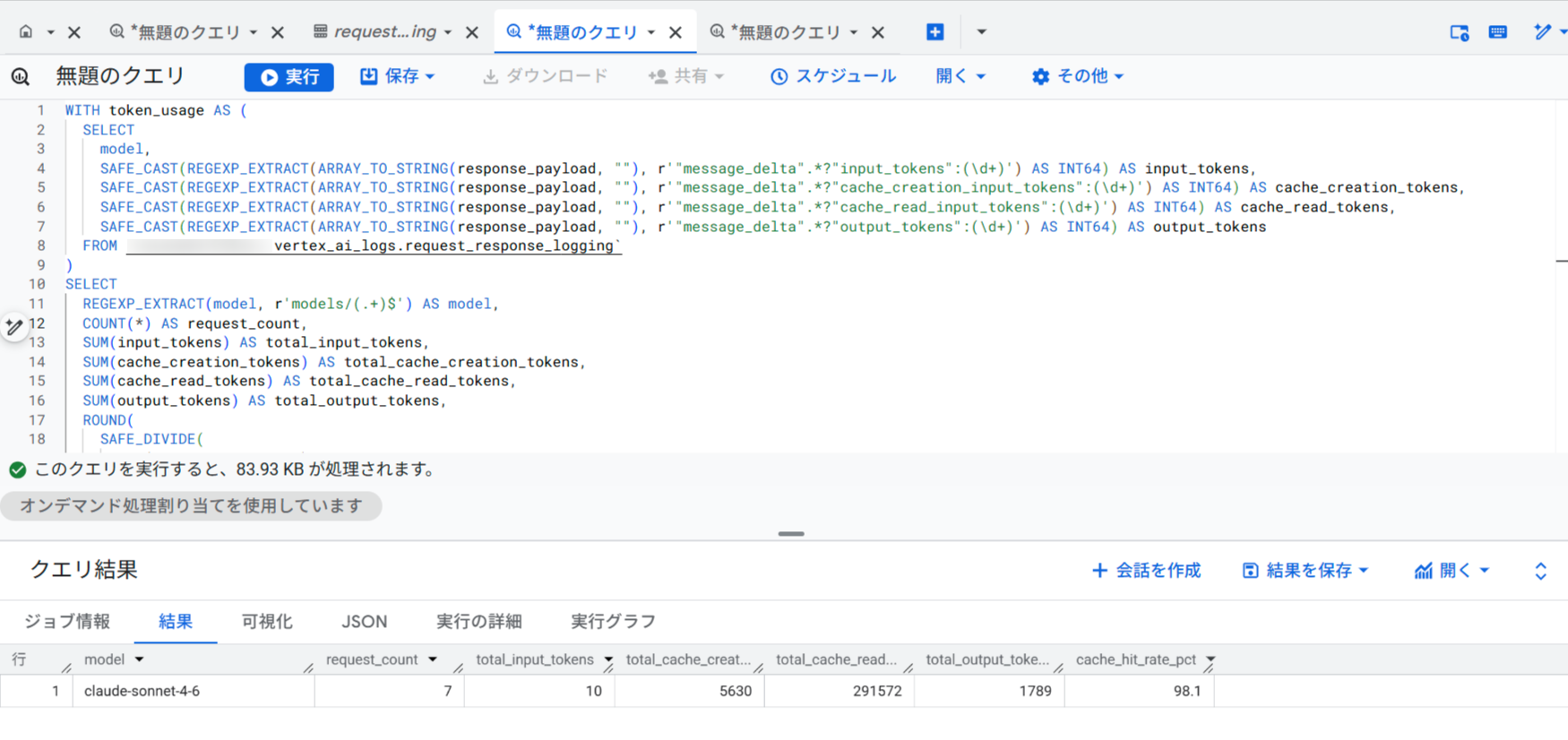
トークン使用量を分析する
レスポンスのSSEストリーム内に含まれるmessage_deltaイベントからトークン使用量を抽出できます。モデルごとのリクエスト数、入出力トークン数、プロンプトキャッシュのヒット率を集計するクエリは以下の通りです。
WITH token_usage AS (
SELECT
model,
SAFE_CAST(REGEXP_EXTRACT(ARRAY_TO_STRING(response_payload, ""), r'"message_delta".*?"input_tokens":(\d+)') AS INT64) AS input_tokens,
SAFE_CAST(REGEXP_EXTRACT(ARRAY_TO_STRING(response_payload, ""), r'"message_delta".*?"cache_creation_input_tokens":(\d+)') AS INT64) AS cache_creation_tokens,
SAFE_CAST(REGEXP_EXTRACT(ARRAY_TO_STRING(response_payload, ""), r'"message_delta".*?"cache_read_input_tokens":(\d+)') AS INT64) AS cache_read_tokens,
SAFE_CAST(REGEXP_EXTRACT(ARRAY_TO_STRING(response_payload, ""), r'"message_delta".*?"output_tokens":(\d+)') AS INT64) AS output_tokens
FROM `your-project-id.vertex_ai_logs.request_response_logging`
)
SELECT
REGEXP_EXTRACT(model, r'models/(.+)$') AS model,
COUNT(*) AS request_count,
SUM(input_tokens) AS total_input_tokens,
SUM(cache_creation_tokens) AS total_cache_creation_tokens,
SUM(cache_read_tokens) AS total_cache_read_tokens,
SUM(output_tokens) AS total_output_tokens,
ROUND(
SAFE_DIVIDE(
SUM(cache_read_tokens),
SUM(cache_read_tokens) + SUM(cache_creation_tokens)
) * 100, 1
) AS cache_hit_rate_pct
FROM token_usage
GROUP BY model;
実行結果の例は以下の通りです。
この結果から、Claude Codeのプロンプトキャッシュが98.1%のヒット率で効率的に機能していることが分かります。cache_read_tokensが大半を占めているため、キャッシュにより入力トークンのコストが大幅に削減されています。
会話の深さを分析する
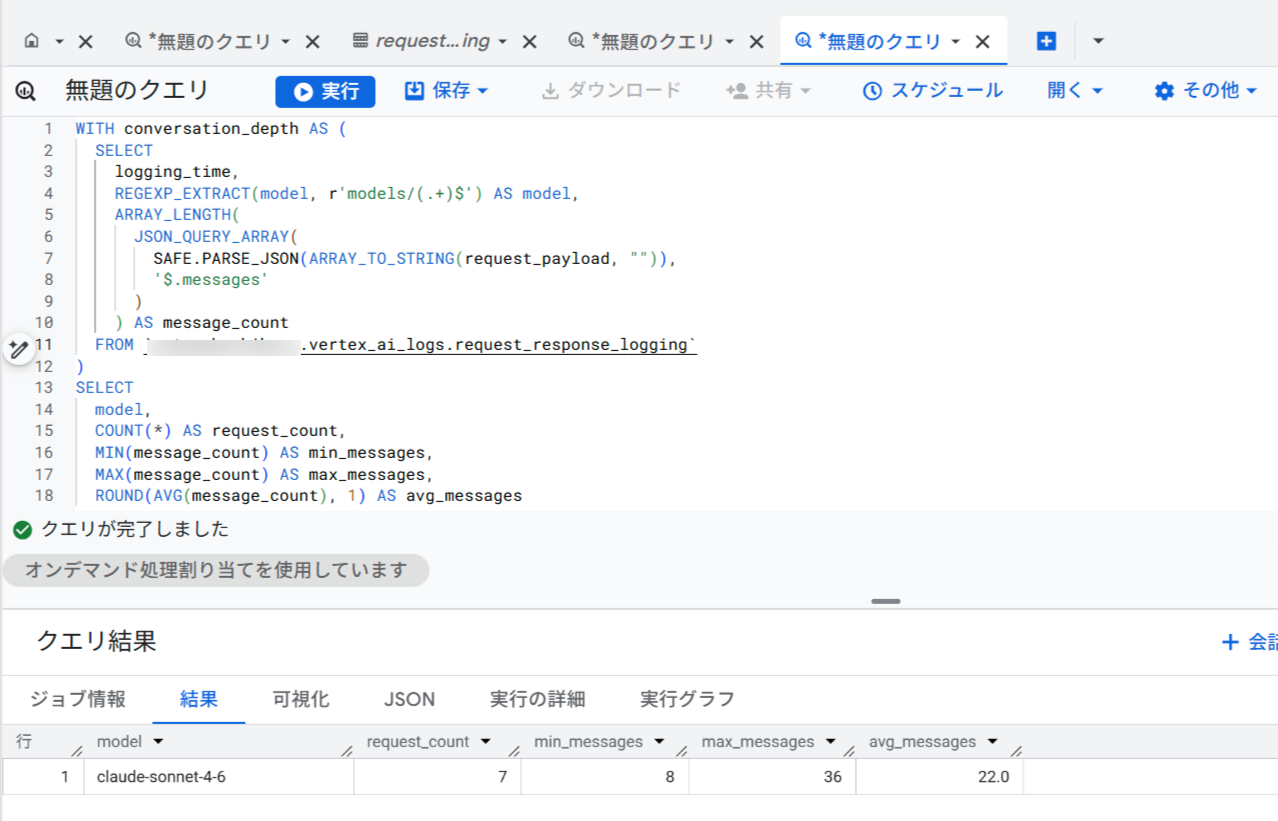
Claude Codeは1回のユーザー指示に対して、ツール呼び出しを繰り返しながら複数回のAPIリクエストを送信します。request_payload内のmessages配列の長さを見ることで、各APIリクエスト時点での会話のターン数を確認できます。
WITH conversation_depth AS (
SELECT
logging_time,
REGEXP_EXTRACT(model, r'models/(.+)$') AS model,
ARRAY_LENGTH(
JSON_QUERY_ARRAY(
SAFE.PARSE_JSON(ARRAY_TO_STRING(request_payload, "")),
'$.messages'
)
) AS message_count
FROM `your-project-id.vertex_ai_logs.request_response_logging`
)
SELECT
model,
COUNT(*) AS request_count,
MIN(message_count) AS min_messages,
MAX(message_count) AS max_messages,
ROUND(AVG(message_count), 1) AS avg_messages
FROM conversation_depth
GROUP BY model;
実行結果の例は以下の通りです。
会話が深くなるほど1リクエストあたりの入力トークン数が増加するため、コスト管理の観点から会話の深さを監視することが有効です。
Request-Response Logging単体ではユーザーを特定できない
Request-Response Loggingのrequest_payload内にはmetadata.user_idフィールドが含まれますが、格納されているのはハッシュ化されたdevice_idとsession_idのみで、メールアドレスなどのユーザーを直接特定できる情報は含まれていません。
{
"device_id": "****...(SHA-256ハッシュ)",
"account_uuid": "",
"session_id": "4341ec45-b341-4848-ace7-9e5911fc7ace"
}
ユーザーを特定するには、本記事の前半で紹介したCloud Audit LogsのprincipalEmailフィールドとタイムスタンプで突合する必要があります。つまり、Cloud Audit LogsとRequest-Response Loggingの両方を有効化することで、初めて「誰が(Cloud Audit Logs)何を送って何が返ってきたか(Request-Response Logging)」を一気通貫で追跡できるようになります。
注意点や制限事項について
Cloud Audit Logsに関する注意点
- Data Access監査ログの追加コスト: Data Accessログは量が多くなりやすく、Cloud Loggingの無料枠(1プロジェクトあたり月50GiB)を超えると課金が発生します。
aiplatform.googleapis.comに絞った設定(allServicesを避ける)でログ量を抑えることを推奨します - プロンプト内容は記録されない: Cloud Audit Logsには「誰が呼んだか」は記録されますが、プロンプトやレスポンスの内容は含まれません
- ログの遅延: Data Access監査ログはリアルタイムではなく、数分程度の遅延が生じる場合があります
- Private Logs Viewerロールが必要: Data Accessログの閲覧には
roles/logging.viewerでは不十分で、roles/logging.privateLogViewerが必要です。roles/editorでは閲覧不可です - 組織レベルの設定が優先: 組織やフォルダレベルで監査ログを有効化している場合、プロジェクトレベルで無効化することはできません
Request-Response Loggingに関する注意点
- Preview機能: ClaudeモデルへのRequest-Response Loggingは現時点でPreview機能です。本番環境での利用は最新の公式ドキュメントを確認してください
- Python SDKによる設定は非対応: AnthropicモデルのRequest-Response Logging設定は、
google-cloud-aiplatformPython SDKでは対応しておらず、REST APIで行う必要があります - 10MBを超えるリクエスト・レスポンスは記録されない: BigQuery Write APIの10MB行制限を超えるリクエスト・レスポンスのペアはBigQueryに記録されません
- BigQueryへの反映に遅延がある: リクエスト後すぐにBigQueryに反映されるわけではなく、数分程度かかる場合があります
- 機密情報の取り扱い: プロンプト内容がBigQueryに平文で保存されるため、アクセス制御(列レベルセキュリティ等)の設計を事前に検討することを推奨します
まとめ
Vertex AI経由でClaude Codeを利用する際に設定すべき2種類のログ機能 Cloud Audit Logs と Request-Response Logging の概要と設定手順を紹介しました。
Cloud Audit LogsとRequest-Response Loggingを組み合わせることで、Vertex AI経由でClaude Codeを利用する際にガバナンスを多層的に実現することができます。
Cloud Audit LogsのData Access(DATA_READ)監査ログを明示的に有効化することで、Claude Codeが使用するrawPredict/streamRawPredictAPIの呼び出しが記録され、「誰がいつどのモデルを使ったか」をIAMレベルで追跡することができます。
また、Request-Response LoggingのsetPublisherModelConfig APIでBigQueryへのログ記録を有効化すると、プロンプトとレスポンスの全文が保存され、トークン使用量の分析などに活用できます。
コンプライアンス要件のある環境でClaude Codeを展開する際は、両方のログを有効化することを検討してみてはいかがでしょうか。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!









