
Loop EngineeringをClaudeを使って実践してみた。
こんにちは、せーのです。
2026年6月、Loop Engineering という言葉が一気に広がりました。Boris Cherny 氏の "I don't prompt Claude anymore. I have loops running that prompt Claude"、Addy Osmani 氏の Loop Engineering、日本語では Zenn の設計論 など、概念と設計の整理は充実しています。
一方で、「結局 Claude でどう実装するのか」 に踏み込んだ記事はまだ少ない、と感じています。6 つのプリミティブや L1/L2/L3 の話は理解できても、コピペで動くコードや、実際に試した時のハマりどころが無いと手が止まりますよね。
私は普段、Claude Code では次のような使い方をしています。
- Skill をたくさん作り、定型処理はその中の script に外出しする
- サブエージェントや Team Agents を使い、複数の LLM に作業を割り振って実行させる
- 最初は基本的に Plan モードで、私の方から Claude とディスカッションしながら、なるべく細かい設計を作ってから実装させる
実装が終わったあとも、別のエージェントや AI に対して、ターミナルから手動で「この成果物をセキュリティ観点でレビューして」「この設計を運用観点で見て」と指示したり、指摘を踏まえて修正させたりしています。こうした手前の設計・割り振り・レビューのやり取りに、それなりの手間をかけています。
Loop Engineering が示しているのは、その手間をさらに減らす方向性だと受け取りました。どのエージェントをいくつ作るか、どうレビューして検証するかを、人間が毎回組み立てるのではなく、ループとして自律的に回す設計に移す、という話です。停止条件、STATE.md、Maker-Checker、denylist ゲートといった設計規律は、まさにそのための部品です。
今回は、その部分を実際にコードを書いて回してみる実験を行いました。
本記事では、その結果を 自律度・運用レベルの低い順に並べた 6 つの実装例としてまとめます。手元の bash ループから始め、Agent SDK の hooks、GitHub Actions 常駐まで、段ごとに「動くコード」「実際の出力」「この段の限界」を見ていきます。検証は 2026-06-13 に Claude Code 2.1.177 / claude-agent-sdk 0.2.93 で実施しました。
Loop Engineering とは(おさらい)
Loop Engineering とは、AI に毎回手でプロンプトを打つのをやめ、「エージェントにプロンプトを打つシステム」そのものを設計する方法論です。Boris Cherny 氏の "I don't prompt Claude anymore. I have loops running that prompt Claude" や、Peter Steinberger 氏の "You should be designing loops that prompt your agents" といった発言がきっかけで、2026 年 6 月に一気に話題になりました。
エンジニアのレバレッジの所在は、こう移ってきている、という整理がよく引用されます。
| 段階 | 設計対象 | 人間の関与 |
|---|---|---|
| Prompt Engineering | 個別プロンプト文 | ターンごと必須 |
| Context Engineering | モデル窓の中身 | レスポンスごと必須 |
| Loop Engineering | ループ全体の制御 | 例外・承認ゲートのみ |
ループには 6 つのプリミティブ(スケジューリング、Worktrees、Skills、MCP、Sub-agents、Memory/State)があり、段階的自律 L1/L2/L3(報告のみ → 補助修正 → 完全自律)でロールアウトする、というのが設計論の定石です。
どうですか。わかりましたか。私は完全に理解しました(嘘)。
つまりこういうことです。
まず プリミティブ というのは、ループを作るための基本部品です。例えば「いつ起動するか」を決めるのがスケジューリング、「どの作業場所で安全に動かすか」を分けるのが Worktrees、「作業手順を覚えさせる」のが Skills、「Slack や GitHub など外部ツールにつなぐ」のが MCP、「実装係とレビュー係を分ける」のが Sub-agents、「前回どこまでやったかを残す」のが Memory/State、というイメージです。
次に L1 / L2 / L3 は、自律度の段階です。
- L1: AI は調べて報告するだけ。変更は人間が判断する
- L2: AI が一部の修正まで行う。ただし危ない変更は人間が見る
- L3: 条件を満たす範囲では、AI が実行・検証・反映まで自律的に進める
そして ロールアウト というのは、いきなり L3 の完全自律にしない、ということです。まず L1 で「ちゃんと見ているか」を確認し、次に L2 で「安全な範囲だけ直させる」ようにし、最後に条件が固まったところだけ L3 にする。つまり Loop Engineering は、AI に丸投げする話ではなく、AI が回るための部品と安全装置を揃え、自律度を少しずつ上げていく話です。
詳しい概念・7 つのループパターンは Addy Osmani の Loop Engineering や Zenn: ループエンジニアリング設計の考え方、CLI ツール cobusgreyling/loop-engineering がよくまとまっています。
既存記事との射程の違い
Developers.IO ではすでに Claude Code の /loop や /goal、Desktop のスケジュール機能を比較した記事があります。
これらは個別機能の使い分けを整理した記事です。本記事は、それらを踏まえて Loop Engineering という設計の考え方を、Claude の実装手段で具体的に動かす方を扱います。
具体的には、claude -p の最小ループ、/loop、/schedule、Maker-Checker、Agent SDK hooks、GitHub Actions を、最小構成から順に動かしていきます。思想そのものの網羅的な解説はしません。概念は前述の資料に任せ、ここでは「どこに停止条件を置くのか」「実装したエージェント自身にレビューさせず、別の観点を持ったレビュアーエージェントにどう検証させるのか」「いくらくらいかかるのか」に絞ります。
読む時は、まず 実装1〜3 で「サブスク枠のまま始められる範囲」を掴み、次に 実装4〜5 で「自動修正に進む時の安全装置」を見る、という順番がおすすめです。GitHub Actions は、最後に常駐化したくなった時の選択肢として読めば十分です。
前提条件
# Claude Code(headless / /loop / /schedule 用)
npm install -g @anthropic-ai/claude-code
claude --version # 検証時: 2.1.177
# Agent SDK(実装5用)
pip install claude-agent-sdk # Python 3.10+、検証時: 0.2.93
# 認証(headless / SDK 用)
export ANTHROPIC_API_KEY="..." # 環境変数で設定
# JSON 出力のパース用
brew install jq
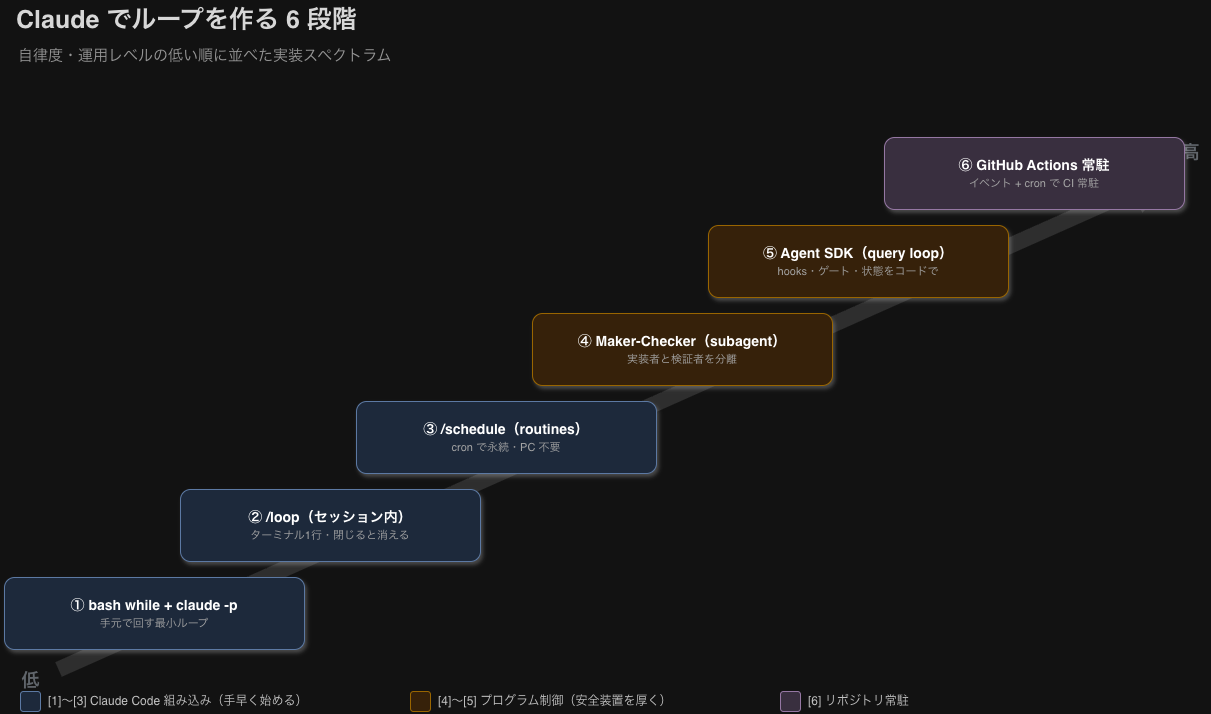
Claude でループを作る 6 段階
自律度・運用レベルが低い順に並べます。急に GitHub Actions 常駐から入ると、権限・コスト・失敗時の影響が大きくなります。なので、まずは「手元で回す」→「セッション内で回す」→「クラウドで報告だけさせる」→「検証者を分ける」→「ゲートをコードで作る」という順番で見ていきます。
どの段から始めるかは後半のまとめでも触れますが、**最初の本番ループは Daily Triage の L1(報告のみ)**が無難です。
低 ─────────────────────────────────────────────→ 高
[1] bash while + claude -p 手元で回す最小ループ
[2] /loop(セッション内) ターミナル1行、閉じると消える
[3] /schedule(routines) cron で永続、PC 不要
[4] Maker-Checker(subagent) 実装者と検証者を分離
[5] Agent SDK(query loop) hooks / ゲート / 状態をコードで作り込む
[6] GitHub Actions 常駐 イベント + cron で CI 常駐
違いを整理すると、[1]〜[3] は Claude Code 組み込み機能中心で手早く始められるもの、[4]〜[5] はプログラムから制御して安全装置を厚くするもの、[6] はリポジトリに常駐させるもの、というイメージです。
実装1: 最小ループ — claude -p を bash while で回す
Loop Engineering の最小実体は generate → test → fix → repeat です。まずは複雑な仕組みにせず、claude -p を 1 回だけ呼ぶところから始めます。
claude -p "Run the test suite and fix any failures" \
--allowedTools "Bash,Read,Edit" \
--max-turns 15
注: v2.1.177 では
--max-turnsが--helpから消えていますが、隠しフラグとして受理され、上限到達時はsubtype: "error_max_turns"/is_error: trueで終了します。ドキュメント化された--max-budget-usd <amount>(1 呼び出しのコスト上限)も併用を推奨します。
「テストが通るまで」回す自己修正ループ
次に、テストが落ちたら Claude に直させ、通るまで繰り返す形にします。素朴に書くとこうです。
#!/usr/bin/env bash
# fix-until-green.sh — テストが通るまで Claude に直させる(素朴版)
set -euo pipefail
MAX_ATTEMPTS=3
attempt=0
while ! npm test --silent; do
attempt=$((attempt + 1))
if [ "$attempt" -gt "$MAX_ATTEMPTS" ]; then
echo "❌ ${MAX_ATTEMPTS}回試しても直らない。人間にエスカレーション。"
exit 1
fi
echo "🔁 attempt ${attempt}: Claudeに修正させる"
npm test 2>&1 | claude -p \
"These tests are failing. Read the output, find the root cause, and fix the code. Do not modify the tests themselves." \
--allowedTools "Bash,Read,Edit" \
--max-turns 15 \
--bare
done
echo "✅ テストが通った(attempt=${attempt})"
--bare は hooks / MCP / CLAUDE.md の自動読込をスキップし、スクリプトや CI では毎回同じ結果に近づけます。"Do not modify the tests themselves" は Verifier Theater(テストを書き換えて「通った」ことにする)対策です。
実は静かに壊れている — pipefail の罠
実際にサンドボックスリポジトリ(add 関数が a - b になっているバグ入りコード)で回してみたところ、Claude は 1 回目で正しく直したのに、スクリプトは exit 1 で異常終了しました。
+ npm test
+ claude -p '...' --allowedTools Bash,Read,Edit --max-turns 15 --bare
All tests pass now. ...(Claudeの応答)
★ スクリプト終了コード = 1
| 確認項目 | 結果 |
|---|---|
✅ テストが通った の出力 |
出ない |
attempt 2 への到達 |
到達しない |
| スクリプト終了コード | 1(成功なのに失敗扱い) |
何が起きているか、少し分解します。
まず set -euo pipefail は、bash スクリプトを厳しめに実行するための設定です。ここで効いているのは主に -e と pipefail です。
set -e: コマンドが失敗(終了ステータスが 0 以外)したら、その時点でスクリプトを終了するpipefail:cmd1 | cmd2のようなパイプラインで、最後のコマンドだけでなく、途中のコマンドが失敗してもパイプライン全体を失敗扱いにする
次に問題の行です。
npm test 2>&1 | claude -p ...
これは、npm test の出力を Claude に渡すためのコードです。2>&1 は、標準エラーも標準出力に混ぜる指定です。つまり、テストの失敗メッセージも含めて Claude に読ませようとしています。
ここで大事なのは、テストが失敗している時の npm test は、終了ステータス 1 などの「失敗」を返すという点です。これは正常な挙動です。テストが落ちているのですから、npm test は「失敗しました」とシェルに伝えます。
通常のパイプラインでは、最後の claude -p ... が成功すれば、パイプライン全体も成功扱いになりがちです。ですが pipefail を有効にしているため、途中の npm test が失敗した時点で、このパイプライン全体も失敗扱いになります。
その結果、流れはこうなります。
while ! npm test --silent; doで、テスト失敗を検知してループに入る- Claude に失敗内容を渡すため、もう一度
npm test 2>&1 | claude -p ...を実行する npm testは当然まだ失敗中なので、終了ステータス 0 以外を返すpipefailにより、パイプライン全体も失敗扱いになるset -eにより、スクリプトがその場で終了する
つまり、Claude は修正してくれるのですが、シェル側は「パイプラインが失敗した」と判断してスクリプトを止めてしまうわけです。だから attempt 2 に進まず、最後の ✅ テストが通った にも到達しません。Loop Engineering でいちばん大事な「どう止めるか」が、意図しない場所で発火してしまっているわけですね。一見動いて見えるのが厄介です。
修正版
修正版では、npm test の出力をいったん変数にキャプチャし、テスト失敗の終了ステータスをパイプラインに持ち込まないようにします。
#!/usr/bin/env bash
set -euo pipefail
MAX_ATTEMPTS=3
attempt=0
while ! npm test --silent; do
attempt=$((attempt + 1))
if [ "$attempt" -gt "$MAX_ATTEMPTS" ]; then
echo "❌ ${MAX_ATTEMPTS}回試しても直らない。人間にエスカレーション。"
exit 1
fi
echo "🔁 attempt ${attempt}: Claudeに修正させる"
test_output="$(npm test 2>&1 || true)"
printf '%s\n' "$test_output" | claude -p \
"These tests are failing. Read the output, find the root cause, and fix the code. Do not modify the tests themselves." \
--allowedTools "Bash,Read,Edit" \
--max-turns 15 \
--bare
done
echo "✅ テストが通った(attempt=${attempt})"
ポイントはこの 2 行です。
test_output="$(npm test 2>&1 || true)"
printf '%s\n' "$test_output" | claude -p ...
npm test 2>&1 || true は、「npm test が失敗しても、この行全体としては成功扱いにする」という意味です。テストの失敗出力は test_output に残りますが、終了ステータスは true によって 0 になります。
そのあと printf で test_output の中身を Claude に渡します。この時点では、パイプラインの左側は npm test ではなく printf です。printf は普通に成功するため、pipefail が有効でも、テスト失敗の終了ステータスに引きずられてスクリプトが止まることはありません。
違いを整理すると、素朴版は **「失敗中の npm test そのものをパイプに流していた」**もの、修正版は **「失敗出力だけを取り出し、終了ステータスはループ制御から切り離して Claude に渡す」**もの、というイメージです。
修正版の実測結果です。
成功パス(attempt 1):
Claude の応答(抜粋):
**Root cause:** The `add` function in `src/math.js` was implemented with subtraction
(`return a - b`) instead of addition. ...
**Fix:** Changed the operator to `+` so `add` returns `a + b`. All 3 tests now pass,
and I left the tests unchanged.
✅ テストが通った(attempt=1)
attempt cap(直らないシナリオ):
🔁 attempt 1: Claudeに修正させる
🔁 attempt 2: Claudeに修正させる
🔁 attempt 3: Claudeに修正させる
❌ 3回試しても直らない。人間にエスカレーション。
この段の限界: 手元のターミナルでしか動きません。閉じたら終わりです。セッション内の定期実行なら実装2、永続化なら実装3へ。
コストと結果を JSON で記録する
ループの監視には --output-format json が便利です。
result=$(claude -p "Summarize today's git log" \
--output-format json --bare --allowedTools "Bash(git log *)")
echo "$result" | jq -r '.result'
echo "$result" | jq -r '.total_cost_usd'
echo "$result" | jq -r '.num_turns'
echo "$result" | jq -r '.is_error'
実出力(整形):
{
"type": "result",
"subtype": "success",
"is_error": false,
"num_turns": 1,
"result": "hi",
"total_cost_usd": 0.002532,
"session_id": "9c0e7aa9-..."
}
.total_cost_usd を積算すれば「日次上限 80% で停止」も自前で作れます(実装5でも触れます)。
ここまでで、最小の「直すまで回す」ループは作れました。ただしこれは、あくまで手元のプロセスです。次は、Claude Code の中で定期的に回す方法を見てみます。
実装2: Claude Code 組み込みの /loop(セッション内ループ)
スクリプトを書かず、ターミナルで 1 行。Claude Code 内で対話的に回します。ちょっとした監視や、作業中だけ回したい確認にはこれが一番軽いです。
/loop 5m gh pr list で未レビューのPRを確認し、新しいものがあれば要約して
/loop ← 間隔省略で self-paced(既定 10 分)
- 間隔:
30s5m2h1dなど(最小 1 分・既定 10 分・最長 3 日) - ターミナル / Claude Code を閉じると全ループがキャンセル(永続しない)
- カスタムな停止判定が要るなら
/goal(別記事参照)
なお、/loop と /goal、さらにサブエージェントを組み合わせると、もう少し凝ったループも作れます。これは少し踏み込んだ話なので、実装の一通りを見たあとに「応用」として別途まとめます。
この段の限界: PC を閉じると消えます。夜間・休日に回らない。→ 永続・PC 不要なら実装3。
実装3: スケジュール駆動 — /schedule(routines)で Daily Triage
cron で定期起動する永続ループです。ここからは、PC を閉じても動く世界に入ります。Loop Engineering の代表例「Daily Triage」を Claude で実装します。
Daily Triage とは、毎朝(あるいは数時間おきに)リポジトリの状態をひと通り見回して、対応すべきことを仕分け(triage)するループのことです。具体的には、CI が落ちていないか、新しい Issue が来ていないか、直近のコミットで気になる変更がないか、といった「定期的に誰かが見ておくべき雑務」を Claude に任せます。
ポイントは、この段ではまだ **L1(報告のみ)**にとどめることです。Claude は状態を読んで「ここが対応待ちです」と教えてくれますが、自動では直しません。読むだけなのでトークンコストも低く、暴走のリスクもほぼありません。だからこそ「最初に本番投入するループ」として向いています。自動修正は、検証を分離できる実装4以降に進んでから足していきます。
STATE.md(外部メモリ)
ループは毎回記憶を失います。状態は会話の外に置くのが鉄則です。
<!-- STATE.md — Daily Triage ループの永続メモリ -->
# Triage State
## Open(対応待ち)
- #142 CI flaky test in auth_spec — 初検出 2026-06-12, 未対応
## Watching(様子見)
- #138 dependency bump (lodash) — patch のみ、auto-merge 禁止
## Done(クローズ済み・週次で pruning)
- #130 typo in README — 2026-06-11 解決
トリアージ用 SKILL.md
.claude/skills/daily-triage/SKILL.md に手順を固定します(intent debt 解消)。
---
name: daily-triage
description: 毎朝 CI 失敗・新着 Issue・直近コミットを読み、STATE.md を更新して要対応を報告する
---
# Daily Triage 手順
1. `gh issue list --state open` と直近の CI 結果を読む
2. STATE.md の Open/Watching と照合し、新規・解決済みを差分検出
3. STATE.md を更新(Done は週次で pruning)
4. **L1 運用**: 修正は行わない。要対応サマリーを報告するだけ
ルーティンとして登録
/schedule
→ 「毎朝7時に /daily-triage を実行し、要対応があれば Slack に通知」
/schedule はクラウドの cron で起動するため PC を閉じても回ります。Daily Triage はトークンコストが低く、しかも L1(報告のみ)で価値が出ます。なので、最初の本番ループとして最適です。
実務上の注意:
- routine の最小周期は 1 時間(
/loopのセッション内最小 1 分とは別物) /scheduleは claude.ai サブスクログイン必須。シェルにANTHROPIC_API_KEYがあると CLI から/scheduleが隠れることがあります(web UI を使うか、一時的にunsetする)- Web / Desktop / CLI の 3 入口は同一クラウドアカウントに書き込みます
この段の限界: L1(報告のみ)。自動修正に進むなら、まず Maker-Checker(実装4)で検証を分離します。
実装4: Maker-Checker — 実装者と検証者を分離する
"The model that wrote the code is way too nice grading its own homework."
ここまでは「回す」ことが中心でした。ここからは、自動修正に進むための検証の設計です。
自動修正ループの安全性の中核は、実装者と検証者を分けることです。Agent SDK の agents で実装者と検証者を別エージェントに分けます。
# maker_checker.py — 実装者と検証者を分離した修正ループ
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions, AgentDefinition, ResultMessage
async def run():
async for message in query(
prompt=(
"1. Use the 'fixer' agent to fix the failing tests in this repo.\n"
"2. Then use the 'reviewer' agent to independently verify the fix by "
"running the tests and checking the diff. Report PASS only if tests actually pass."
),
options=ClaudeAgentOptions(
allowed_tools=["Read", "Edit", "Bash", "Glob", "Grep", "Agent"],
cwd="./sandbox-repo", # 対象リポジトリを明示
max_turns=40,
max_budget_usd=2.0, # 暴走・課金ガード
agents={
"fixer": AgentDefinition(
description="Implements code fixes for failing tests.",
prompt="Fix the root cause in the source. Never edit test files.",
tools=["Read", "Edit", "Bash", "Glob", "Grep"],
),
"reviewer": AgentDefinition(
description="Independently verifies a fix. Skeptical by default.",
prompt=(
"You did NOT write this code. Run the tests yourself. "
"Read the diff. If tests fail or the diff edits test files, return FAIL with reasons."
),
tools=["Read", "Bash", "Glob", "Grep"], # Edit なし=検証専任
),
},
),
):
if isinstance(message, ResultMessage):
print(message.result)
asyncio.run(run())
設計ポイント:
- reviewer に Edit を与えない → 「直しながら採点」を構造的に禁止
"You did NOT write this code"→ 確証バイアスを言語で打ち消す- さらに堅くするなら reviewer を別モデル(例: 実装 Sonnet、検証 Opus)にする
実測: PASS パス
- fixer:
return a - b→return a + b(src 1 行のみ、test 不変) - reviewer: 独立してテスト実行 + diff 確認 → PASS
- コスト: $0.71 / turns: 3
実測: Verifier Theater を FAIL で検出
src のバグは直さず、テストの期待値だけをバグ出力に合わせて改ざんした状態では、npm test は pass 3 になります。ナイーブな「テスト通った?」判定は騙されます。
reviewer の判定(抜粋):
**FAIL** — The diff edits a test file — disqualifying on its own. …
The developer changed the assertions to `add(2,3) == -1` … making the tests assert
*incorrect* arithmetic so they'd go green against the broken implementation.
| シナリオ | テスト結果 | reviewer 判定 | コスト |
|---|---|---|---|
| 正当な fix | pass 3 | PASS | $0.71 |
| Verifier Theater | pass 3 | FAIL | $0.21〜0.36 |
「テストを実際に走らせろ」「diff がテストを触ったら FAIL」をプロンプトに焼き込む設計は、テストがグリーンでも不正を構造的に検出できることを実機で確認しました。
つまり、ここでやっているのは「AI にレビューしてもらう」ではなく、レビュー専任のエージェントに編集権限を渡さず、独立した証拠で判定させることです。ここが手動レビュー指示をループ化する時の肝になります。
実装5: Agent SDK で本格ループ — hooks でゲートと監査
プログラムからループ全体を制御する段です。Maker-Checker で検証者を分けたら、次は「そもそも触ってはいけないもの」を機械的に止めます。denylist ゲート・監査ログ・状態の読み書きをコードで作り込みます。
PreToolUse hook で denylist ゲート
# guarded_loop_v2.py — permissionDecision 形式(推奨)
import asyncio
from datetime import datetime
from claude_agent_sdk import query, ClaudeAgentOptions, HookMatcher, ResultMessage
DENYLIST = (".env", "credentials", "secrets", ".aws/", "id_rsa")
async def deny_sensitive(input_data, tool_use_id, context):
path = input_data.get("tool_input", {}).get("file_path", "")
if any(bad in path for bad in DENYLIST):
return {
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny",
"permissionDecisionReason": f"denylist: {path} への変更は禁止",
}
}
return {}
async def audit(input_data, tool_use_id, context):
path = input_data.get("tool_input", {}).get("file_path", "unknown")
with open("./loop-audit.log", "a") as f:
f.write(f"{datetime.now().isoformat()} modified {path}\n")
return {}
async def run():
async for message in query(
prompt="Create .env with FOO=bar, then create notes.txt with hello.",
options=ClaudeAgentOptions(
allowed_tools=["Read", "Edit", "Write", "Bash", "Glob", "Grep"],
permission_mode="acceptEdits",
max_turns=20,
hooks={
"PreToolUse": [HookMatcher(matcher="Edit|Write", hooks=[deny_sensitive])],
"PostToolUse": [HookMatcher(matcher="Edit|Write", hooks=[audit])],
},
),
):
if isinstance(message, ResultMessage):
print("result:", message.result)
asyncio.run(run())
hook の返り値: SDK 0.2.93 では
permissionDecision: "deny"(上記)と、簡潔な{"decision": "block", "reason": "..."}の両方がブロックします。PreToolUse の許可制御は前者を正とするのが無難です。
実測:
| 対象 | 結果 |
|---|---|
.env(denylist) |
作成されず — ブロック成功 |
notes.txt(許可) |
作成成功 |
監査ログ loop-audit.log:
2026-06-13T21:09:48.976992 modified .../notes.txt
ブロックされた .env は PostToolUse が発火しないため、監査ログには成功した変更だけが残ります。
トークン予算ガード(日次 80% で停止)
# budget_guard.py — 複数回呼び出しの累計上限
import json, subprocess, sys
DAILY_LIMIT_USD = 5.00
spent = 0.0
def run_once(prompt):
out = subprocess.run(
["claude", "-p", prompt, "--output-format", "json", "--bare",
"--allowedTools", "Read,Edit,Bash", "--max-turns", "15"],
capture_output=True, text=True,
)
return json.loads(out.stdout)
for item in ["fix #142", "fix #143", "fix #144"]:
if spent >= DAILY_LIMIT_USD * 0.8:
print(f"⏸ 予算80%到達(${spent:.2f})。残りは翌日へ。")
sys.exit(0)
res = run_once(item)
spent += float(res.get("total_cost_usd", 0))
print(f"{item}: done, 累計 ${spent:.3f}")
実測(検証用に上限を $0.004 に設定):
reply with the word one: done(cost=$0.0101), 累計 $0.0101
⏸ 予算80%到達($0.0101 / 上限$0.004)。残りは翌日へ。
使い分け:
--max-budget-usd: 1 回のclaude -p呼び出し内のコスト上限budget_guard.py方式: 複数回の呼び出しを跨いだ累計上限。常駐ループでは両方併用が堅いです
実装6: GitHub Actions で CI 常駐ループ
PC を離れ、リポジトリのイベント + cronでループを回す最終段です。ここまで来ると、ローカルの便利ツールというより、リポジトリに常駐する運用部品になります。anthropics/claude-code-action@v1 を使います。
セットアップ
Claude Code 内で(リポジトリ管理者権限が必要):
/install-github-app
GitHub App 導入と ANTHROPIC_API_KEY secret 登録をガイドしてくれます。
パターンA: @claude メンションに応答
# .github/workflows/claude.yml
name: Claude Code
on:
issue_comment:
types: [created]
pull_request_review_comment:
types: [created]
jobs:
claude:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
Issue に @claude このバグを直して PR を出して とコメント → Claude が実装して PR を作成、という流れです。
パターンB: cron で Daily Triage
# .github/workflows/daily-triage.yml
name: Daily Triage
on:
schedule:
- cron: "0 22 * * *" # 毎日 07:00 JST(UTC 22:00)
jobs:
triage:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
prompt: "/daily-triage"
claude_args: "--max-turns 10 --model claude-sonnet-4-6"
コスト制御
with:
claude_args: "--max-turns 5"
timeout-minutes: 15
concurrency:
group: claude-${{ github.ref }}
cancel-in-progress: true
検証範囲の注記: 本記事執筆時点では、上記 YAML の構文検証と
@v1タグの解決、CLI フラグの受理までを確認しています。ライブ実行(cron 起動 → PR 自動作成)は未実施です。GitHub App 導入・secret 登録・Actions runner 時間は課金・権限に関わるため、各自の検証用リポジトリで/install-github-appから試してください。手動起動する場合はworkflow_dispatch:を追加すると便利です。
応用: /loop・/goal・サブエージェントを組み合わせる
ここまでの部品(/loop・/goal・サブエージェント・Agent SDK・/schedule)が揃ったので、それらを組み合わせた一歩進んだループを見ていきます。
/loop と /goal を組み合わせる
/loop は「一定間隔で同じプロンプトを投げ直す」もの、/goal は「条件が満たされるまでターンを継続する」ものです。混同しやすいので、公式ドキュメントの整理を借りると次のとおりです。
| コマンド | 次のターンが始まる条件 | 止まる条件 |
|---|---|---|
/goal |
前のターンが終わったら | 別の評価モデルが「条件達成」と判定したら |
/loop |
一定の時間間隔が経過したら | 自分で止めるか、Claude が「もう完了」と判断したら |
ここで「ループの中で goal は叩けないのか」という疑問が出ますが、結論から言うと /loop は slash command も回せます。/loop 自体が「プロンプトまたは slash command を一定間隔で実行する」スキルで、/loop 5m /foo のように slash command を指定できます。
そして /goal の条件は Markdown ファイルを指す書き方ができます。公式ドキュメントにもこういう例があります。
/goal implement the spec in docs/specs/feature.md until all acceptance criteria hold and the test suite passes
つまり「やってほしいこと」を docs/specs/feature.md のような仕様ファイルに書いておき、/goal の条件からそれを参照させる、という形です。条件は最大 4,000 文字まで書けるので、ファイルへの参照+達成条件+制約(「テストファイルは触らない」など)をまとめて書けます。
ただし注意が必要なのは、1 セッションでアクティブにできる /goal は 1 つだけで、新しい /goal を打つと前のものが置き換わる点です。なので、
/goal XXX.md
/goal YYY.md ← これだと前の XXX.md のゴールは消えて YYY.md に置き換わる
のように 複数のゴールを同時に並走させることはできません。「エージェントごとに別のゴールファイルを割り当てて並列に回す」をやりたい場合は、
- それぞれを **サブエージェント(
/agentsや Task)**に分けて担当させる .claude/loop.mdに「各ファイルを順に処理する」手順を書いて bare/loopに拾わせる- もしくは Agent SDK /
/batchでファイル単位に分解して回す
といった「外側のオーケストレーション」と組み合わせるのが現実的です。/goal 単体は「1 つの到達点に向けて粘る」ための仕組み、と捉えておくのが正確です。
ループからサブエージェントへファンアウトする
「ループで何かをチェックして、できていなかったらサブエージェントを 3 つ作り、それぞれに別の md ファイルを与えて、別々の役割で作業させる」——こんな形は作れないでしょうか。
まず結論です。
- 「ループからサブエージェントを複数起動して、それぞれに別の仕様 md を渡す」は できます。
- ただし、各サブエージェントが自分で
/goalを実行するわけではありません。/goalはセッションに対する slash command であって、サブエージェントの中で叩くものではないからです。サブエージェント側の「ゴール」は、渡す prompt(spec md)+maxTurnsなどの停止条件で表現します。
なので「goal XXX.md をサブエージェントごとに並べる」という書き方そのものは正しくありません。実際にやるなら、サブエージェントを定義して、親(ループ側)からファンアウトさせます。
まず、役割ごとのサブエージェントを .claude/agents/ に置きます(それぞれが担当する仕様 md を prompt で指す形です)。
---
name: api-worker
description: API 層の未完了タスクを spec に沿って実装する
tools: Read, Edit, Bash, Glob, Grep
maxTurns: 20
isolation: worktree
---
docs/specs/api.md を読み、そこに書かれた受け入れ条件をすべて満たすまで実装する。
テストファイルは変更しない。完了したらテスト結果を要約して報告する。
同じ要領で docs/specs/ui.md を見る ui-worker、docs/specs/docs.md を見る docs-worker を用意します(isolation: worktree で、並列に動いてもファイル衝突しないようにします)。
そのうえで、ループ側のプロンプト(.claude/loop.md でも /loop <prompt> でも可)に、「チェック → ダメなら 3 体にファンアウト」を書きます。
<!-- .claude/loop.md — チェックして、未完了なら3役を並列で走らせる -->
まず npm test を実行して状態を確認する。
すべて通っていれば「グリーン」とだけ報告して終了する。
失敗していれば、以下の 3 つのサブエージェントを並列で起動し、それぞれの担当 spec を実装させる:
- api-worker(docs/specs/api.md 担当)
- ui-worker(docs/specs/ui.md 担当)
- docs-worker(docs/specs/docs.md 担当)
3 体の報告が出そろったら、もう一度 npm test を実行して結果を要約する。
これを /loop 15m などで回せば、「15 分ごとにチェック → 落ちていたら 3 役を並列で走らせる → 再チェック」というループになります。1 回の親ターンの中で 3 体を同時に(depth 1 のファンアウトで)起動でき、各サブエージェントは自分の context window と maxTurns を持って独立に動きます。
補足: サブエージェントの入れ子は、Claude Code v2.1.172 以降では「サブエージェントがさらにサブエージェントを起動」も可能になっています(変更前は 1 段のみ)。ただし Agent SDK 側は「サブエージェントは子を持てない」と記載されており、ドキュメントとバージョンで挙動が動きやすい領域です。実機とバージョンで必ず確認してから組んでください。
もし「各ワーカーにも評価モデルによる goal ループを持たせたい」なら、サブエージェントではなく、各ワーカーを
claude -p "/goal <spec.md を参照した条件>"として 個別の headless セッションで起動する手もあります。ただしclaude -pは毎回フルのセッションを立てるためコストが乗り、6/15 以降はメーター課金対象です。
逆に「/goal の中でサブエージェントを立てる」なら
では逆向きはどうでしょう。「/goal の条件に指す md ファイルの中で、サブエージェントを 3 つ立てて、3 つの観点から解決させる」——こちらは、実はさっきのパターンより仕様に素直で、おすすめできます。
理由はこうです。/goal はセッションに 1 つ持てる完了条件で、達成するまでターンを継続します。その各ターンの中で、メインのセッションはサブエージェントを起動できます。なので「1 つのゴールを掲げ、そのゴールに向かう過程で 3 観点のサブエージェントにファンアウトする」という形は、ゴール 1 つ・サブエージェント 3 体できれいに収まります。
まず spec md に、ゴールと「3 観点でサブエージェントに解かせる」手順を書いておきます。
<!-- docs/specs/fix-flaky.md -->
# ゴール
auth まわりの flaky テストを解消し、npm test が安定して通る状態にする。
# 進め方
原因を 3 つの観点から並列に調査・修正する。次のサブエージェントを使うこと:
- race-investigator: 非同期処理・タイミング起因の競合を調べて直す
- fixture-investigator: テストデータ・モックの不備を調べて直す
- env-investigator: 環境差・グローバル状態の汚染を調べて直す
各サブエージェントの報告を統合し、最小の修正を適用する。
テストファイル自体は書き換えない。
# 完了条件
npm test を 3 回連続で実行し、すべて green であること。
そのうえで、/goal の条件からこの md を参照させます。
/goal docs/specs/fix-flaky.md の進め方に従い、3観点のサブエージェントを使って原因を解消し、完了条件(npm test が3回連続green)を満たすまで続ける
こうすると、
/goalがターンを開始し、メインがrace / fixture / envの 3 サブエージェントを並列で起動する- 3 体がそれぞれの観点で調査・修正し、要約だけをメインの会話に返す
- メインが要約を統合して修正を当て、
npm testを走らせる - ターン終了後、評価モデル(既定 Haiku)が「3 回連続 green」かどうかを会話の内容から判定する
- 未達なら理由を添えて次のターンへ、達成なら自動でゴールがクリアされる
という流れになります。ゴール(粘る軸)は 1 つ、観点の分担はサブエージェント、という役割分担です。先ほどの「ループから 3 ゴール」よりも、/goal 1 つで完結する分すっきりします。
ただし /goal の評価モデルには 1 つ注意があります。評価モデルは自分でファイルを読んだりコマンドを実行したりせず、会話に出てきた内容だけで判定します。なので完了条件は「npm test の結果が会話に出ている」など、メイン(とサブエージェントの要約)が会話に surface させたものから判定できる形で書く必要があります。サブエージェントの結果が要約としてメインに返ることが、ここで効いてきます。
さらにこれを /loop で回す
ここまでで「1 回のゴール(3 観点のサブエージェントでファンアウト)」はできました。ただし /goal は その条件を 1 回満たしたら終わりです。flaky テストのように「直してもまた再発する」種類の相手だと、1 回 green になっても、しばらくするとまた赤くなります。
そこで、この /goal ごと /loop で定期的に回します。ただし「毎回とりあえずゴールを起動する」だと無駄が多いので、外側のループにも条件(ガード)を持たせます。具体的には、ループのたびにまず状態をチェックして、「直す必要がある時だけ」内側の /goal を起動する、という形にします。
/loop のプロンプトは自然文で書けるので、こう書けます。
/loop 1h まず npm test を実行して状態を確認する。
- すべて green なら「グリーン」とだけ報告して、今回は何もしない。
- 失敗していれば、docs/specs/fix-flaky.md の進め方に従い、
/goal で3観点のサブエージェントを使って原因を解消し、
完了条件(npm test が3回連続green)を満たすまで続ける。
- まだ docs/specs/fix-flaky.md が無ければ作成し、その旨を報告して今回は終了する。
これで全体はこういう二重構造になります。
- 外側の
/loop(1 時間ごと・ガード付き): まず状態を見て、赤い時だけゴールを起動する「見張り」 - 内側の
/goal(達成まで): 起動されたら 3 観点のサブエージェントを並列起動し、green になるまで粘る
/loop 1h
└─ まず npm test で状態チェック
├─ green → 「グリーン」と報告して何もしない
├─ spec が無い → spec を作成して報告(今回は終了)
└─ red → /goal(docs/specs/fix-flaky.md)を起動
├─ race-investigator ┐
├─ fixture-investigator ├─ 並列で調査・修正 → 要約を返す
└─ env-investigator ┘
└─ メイン統合 → npm test → 評価モデルが「3回連続green」を判定
つまり、「いつ起動するか」と「そもそも起動すべきか(ガード)」は /loop、「1 回でどこまで粘るか」は /goal、「どんな観点で解くか」はサブエージェント、と役割が分かれます。最初に欲しかった「ループで回して、ダメなら複数の観点で解決させる」は、この形がいちばん素直に表現できます。
外側にガードを置くのは、コスト面でも効きます。green の時はチェックだけで終わるので、サブエージェント 3 体を毎回起動せずに済みます(サブエージェントを並列で回すとコストが一気に上がります。後述のコスト節も参照)。
なお /loop はセッション内なので、ターミナルを閉じると止まります。PC を閉じても回したいなら、この /goal 起動を /schedule(実装3)の routine に載せるか、GitHub Actions(実装6)の cron から prompt: "/goal ..." で叩く形にします。
補足:
/goalは trusted workspace(信頼ダイアログ承認済み)でのみ動き、disableAllHooksなどで hooks を止めていると使えません(評価が hooks の仕組みを使うため)。
⚠️
.claude/loop.mdの自動検出は、バージョンによっては bare/loopで拾われず、/loop follow the instructions in .claude/loop.mdのように明示指定が必要なケースが報告されています(claude-code#47883)。手元の挙動で確認してから使ってください。
安全装置 — どの段でも効かせる設計規律
ここまで 6 つの実装を見てきました。コードはそれぞれ違いますが、効かせるべき安全装置は共通しています。実装1〜6のどの段でも意識したい装置を整理します。
| 安全装置 | 具体的な実装 | 本記事の該当 |
|---|---|---|
| 停止条件を先に書く | MAX_ATTEMPTS / --max-turns / --max-budget-usd / timeout-minutes |
実装1・5・6 |
| denylist | PreToolUse hook で .env / credentials をブロック |
実装5 |
| トークン予算 | total_cost_usd 積算、80% で停止 |
実装1・5 |
| Maker-Checker | 実装者と検証者を別エージェント | 実装4 |
| Verifier Theater 対策 | 「テストを書き換えるな」「実際に走らせろ」 | 実装1・4 |
| 段階的ロールアウト | 必ず L1(報告のみ)から | 実装3 |
| 理解負債の管理 | 週次ダイジェスト / 監査ログ | 実装5 |
失敗モードの代表例:
- 同一 PR を 5 回修正し続ける → Checker を強化、リトライ上限 3 回
- CI 失敗でも承認される → テスト・lint の実出力を検証に必須化
- STATE.md が肥大化 → Done を週次 pruning
- 許可外パスを変更 → denylist を最初に設定
鉄則: ループを作るより先に、どう止めるかを決める。実装1 の pipefail バグは、その大事さを実感させてくれる例でした。
コスト実測と 2026/6/15 以降の課金
ループは便利ですが、回り続ける以上、コストの話は避けられません。特に claude -p や Agent SDK を使う場合は、対話利用とは別の扱いになるため、ここで整理しておきます。
実測コスト(2026-06-13 / Claude Code 2.1.177)
--output-format json の total_cost_usd で捕捉した値です。
| 操作 | 構成 | 実測コスト | turns |
|---|---|---|---|
| 1 ターン応答(ツール無し) | claude -p "say only the word: hi" |
$0.0025 | 1 |
| 1 ターン応答(ツール許可あり) | --allowedTools Read,Edit,Bash |
$0.0101 | 1 |
| Maker-Checker フル | Agent SDK query() |
$0.71 | 3 |
| reviewer 単体(FAIL 判定) | Agent SDK query() |
$0.21〜0.36 | 4〜5 |
- **Daily Triage(L1・読むだけ)**は 1 回 $0.01 未満で回せる見込み → 最初の本番ループに向く
- Maker-Checker は 1 サイクル $0.7 前後 → CI Sweeper を 5〜15 分周期で回すと「極高」になるのは妥当
- GitHub Actions の runner 時間も別途かかります
2026/6/15 以降: Agent SDK クレジットの線引き
2026 年 6 月 15 日から、プログラム経路は対話枠とは別の 月次 Agent SDK クレジット(API リスト価格ベース)から消費されます。公式ヘルプ より。
メーター対象(別枠クレジット):
- Agent SDK
query() claude -p(非対話 / headless)- Claude Code GitHub Actions(実装6も対象)
- Agent SDK 認証のサードパーティアプリ
クレジット額(個人プラン例): Pro $20 / Max 5x $100 / Max 20x $200(月次リセット、繰越なし)。初回はアカウント設定から**クレジットの有効化(claim)**が必要です。
メーター対象外(従来どおりサブスク枠):
| 経路 | 課金 |
|---|---|
ローカルターミナルの対話 /loop / /goal |
サブスク枠 |
claude.ai/code routine(/schedule・クラウド) |
サブスク枠(日次実行上限あり) |
| Claude Desktop / claude.ai チャット | サブスク枠 |
Claude Platform の API キー課金を使っている場合は従来どおり従量課金で、上記クレジットは対象外です。
ポイント: Loop Engineering の設計規律(停止条件・STATE.md・Maker-Checker・denylist・/goal)は Agent SDK 必須ではありません。/loop + /goal(ターミナル)と /schedule(クラウド・PC 不要)だけでサブスク枠のまま始められます。SDK / claude -p / GitHub Actions は「プログラムから細かく作り込みたい人向けの上位段」で、6/15 からメーター課金になります。常駐ループを非メーターで回すなら、GitHub Actions より /schedule ルーティンが有利です。
💡**【追記】公開前の確認**
6/15 以降のクレジット仕様・クレジット額は変更される可能性があります。公開直前に 公式ヘルプ を再確認してください。本記事執筆時点(2026-06-13)は施行前です。
まとめ
Loop Engineering を Claude で実装してみて感じたのは、概念は思想ではなく、停止条件・検証・状態管理の積み重ねだ、ということです。
自分で Plan を書き、複数の AI にレビューを依頼し、指摘を受けて直す、という今のやり方は十分に強力です。ただ、そこに「毎回、人間が設計して割り振る」という手間が残ります。Loop Engineering は、その手前の設計・割り振り・レビューの流れを、少しずつループ側に寄せていく考え方なのだと感じました。
停止条件を先に書く
MAX_ATTEMPTS や --max-budget-usd は「後から足す」ものではなく、ループの最初の行に書くものです。pipefail の罠は、見た目は動いているのに制御フローが壊れている典型例でした。
実装したエージェント自身にレビューさせない
Maker-Checker と Verifier Theater 対策は、プロンプトの気合いではなく権限分離と独立シグナルで担保します。つまり、実装したエージェント自身に「これで大丈夫?」と聞くのではなく、別の観点を持ったレビュアーエージェントを立て、テスト結果や diff などの証拠を見て判定させます。テストがグリーンでも、diff がテストを触っていれば FAIL、を実機で確認できました。
STATE は会話の外に
/schedule で Daily Triage を L1 から回すなら、STATE.md と SKILL.md をリポジトリに committed しておくのが第一歩です。
そして、、、どの段から始めるかで言えば、私は Daily Triage L1 を /schedule で登録するところから入るのが現実的だと感じました。5 行 bash は仕組みを理解するため、Maker-Checker と hooks は自動修正に進む段階で、という順番です。
ぜひ試してみてはいかがでしょうか。もっとスマートなループ設計を御存知の方がいればXなどでご連絡下さい。
参考資料
起点・設計論
Claude Code 公式
- Run Claude Code programmatically(headless /
claude -p) - Keep Claude working toward a goal(
/goal) - Run prompts on a schedule(
/loop/loop.md/ routines) - Agent SDK overview
- Claude Code GitHub Actions
- Use the Claude Agent SDK with your Claude plan(6/15 クレジット)
- anthropics/claude-code-action(GitHub)











