
Claudeのコンテキスト節約のために実装だけローカルLLMにオフロードしてみた
こんにちは、せーのです。
Claude や Codex でコードを書いていると、ログや差分、試行錯誤のメモが会話に積み上がるほど、残りコンテキストが気になります。そんなとき、実装の細部まで同じ会話に載せ続けるのがいつまでも最適か、と疑いたくなります。
そこで今回は、Claude Code を司令塔に据えたまま、実装寄りのタスクだけをローカル LLM(Ollama 上の Qwen3 / Gemma4)に渡したら、所要時間・品質・メモリはどう振れるかを、同じ 5 タスクでベンチマークしてみました。
先に結論
今回の検証で、実運用で使いやすい方針は次のようになりました。
- 設計・判断・CLI 系は Claude Code に寄せる
- 速度優先のオフロードは
qwen3-coder:latest(30B 相当) - 品質優先のオフロードは
gemma4:31b-it-q4_K_M - ただしローカル LLM はどれも 人手レビュー前提(特に CLI と jq/JMESPath 境界)
つまり「ローカルで Claude を置き換える」ではなく、Claude のコンテキストを守る別働隊としてローカルを使うのが、今回の落としどころでした。
この検証でやったこと
次の 4 条件で、**同一の handoff(実装依頼メモ)**に基づく 5 タスクを処理しました。
- Claude Code(Opus 4.7)がそのまま生成(API 経由・ベースライン)
- **Ollama の
qwen3:14b(汎用)**にqwen-run.sh経由でオフロード - **Ollama の
qwen3-coder:latest(30B 相当)**に同様にオフロード - **Ollama の
gemma4:31b-it-q4_K_M(31B 相当)**に同様にオフロード
計測したのは、合計所要時間、著者主観の品質スコア(5 段階平均)、ローカル実行時の Ollama メモリ、人手修正が要りそうかです。品質は「Claude 直生成の出来」を基準にした相対評価で、厳密な自動採点ではありません(同じ観点で揃えて比較)。
違いを整理すると、ベースラインは「全部 Claude の会話に載せて短時間で終わらせる」、オフロード側は「handoff とラッパーだけで回して会話ログを増やさない」、という構図です。
今回のストーリー
※数値は単一マシンでの PoCです。モデルバージョンや量子化、電源設定、同時実行の有無で変動します。
環境
環境は次のとおりです(機種は一般名で表記)。
| 項目 | 値 |
|---|---|
| マシン | MacBook Pro(Apple M4 Max) |
| メモリ | 36GB ユニファイドメモリ |
| macOS | 26.4.1 |
| シェル | zsh |
| ランタイム | Homebrew 経由でインストールした Ollama |
5タスクの中身
次の5本を、それぞれの条件で順に処理しました(A は AWS CLI と JMESPath / jq が絡む系で、ここが一番「CLI 知識」が問われます)。
| ID | 概要 |
|---|---|
| A | S3 の全バケット名を取得し、各バケットのオブジェクト合計サイズを表示する AWS CLI ワンライナー(JMESPath / jq) |
| B | JSON を CSV に変換するコード |
| C | Markdown の表を整形する編集 |
| D | shellcheck の指摘に沿ったシェルスクリプト修正 |
| E | フィボナッチ関数とユニットテストの実装 |
最初の仮説
今回の検証を始めた時点の仮説は次の3つでした。
- パラメータが大きいモデルほど、少なくともコーディングは有利ではないか
- 速度は落ちても、コンテキスト節約の価値が勝つ場面があるのではないか
- CLI とテキスト整形では、得意不得意が分かれるのではないか
途中で llama3.3:70b も試そうとしましたが、36GB メモリ環境ではダウンロード・実行コストが重く、今回は Gemma4 検証を優先しました。
Ollama のモデル選びでハマった点(先に共有)
当初は「コーディング用の 14B」を探したのですが、qwen3-coder:14b というタグは Ollama 上に存在しませんでした。Hub を見ると qwen3-coder は latest(本実験では約 18GB、30B 相当)が中心で、14B を使うなら qwen3:14b(汎用) が現実的、という整理になります。30B 側は qwen3-coder:latest を取得して計測しています。
ワークフロー(ローカル側)
ローカル実行は、handoff を読み込んで Ollama の HTTP API に投げ、結果を outputs/ 配下に保存する qwen-run.sh ラッパー(ローカルに置いた AI ワークフロー用スクリプト)で統一しました。再現イメージとしては、次のような形です(qwen-run.sh の実パスと、handoff / 出力ディレクトリは読み替えてください)。
# 14B の例(task-id / handoff / 出力ディレクトリ)
bash /path/to/qwen-run.sh \
"<task-id>" \
experiment-project/handoff/qwen-task-003-a.md \
experiment-project/outputs \
--model 14b --mode notes
# 30B(qwen3-coder:latest)の例
bash /path/to/qwen-run.sh \
"<task-id>" \
experiment-project/handoff/qwen-task-003-a.md \
experiment-project/outputs \
--model 30b --mode notes
Task 002: Claude Code が直接処理したベースライン
Claude Code(Opus 4.7)に、そのまま 5 タスクを処理してもらい、所要時間と品質、およびコンテキスト消費の概算をメモしました。
| タスク | 所要時間 | 品質(5 段階) | Claude コンテキスト消費(概算) |
|---|---|---|---|
| A: S3 ワンライナー | 1 秒 | 4 | 約 250 トークン |
| B: JSON→CSV | 1 秒 | 5 | 約 200 トークン |
| C: MD 表整形 | 0 秒 | 5 | 約 350 トークン |
| D: shellcheck 修正 | 0 秒 | 4 | 約 300 トークン |
| E: フィボナッチ+テスト | 1 秒 | 5 | 約 200 トークン |
| 合計 | 3 秒 | 平均 4.6 | 約 1,300 トークン |
正直、速さと安定感はこちらが別格でした。ここが今回の基準点です。
一方で、長いセッションでは会話履歴全体がコンテキスト消費の主因になりやすい。これが、あえてローカルに振る理由です。
Task 003: qwen3:14b でオフロード(まずは軽量側)
同一 handoff を qwen-run.sh で順に実行した結果です。
| タスク | 所要時間 | 品質 | Ollama メモリ | 修正要否 |
|---|---|---|---|---|
| A | 119 秒 | 2 | 11.3GB | 要修正(jq クエリ誤り) |
| B | 285 秒 | 5 | 11.3GB | 不要 |
| C | 201 秒 | 5 | 11.3GB | 不要 |
| D | 199 秒 | 3 | 11.3GB | 要修正(不完全) |
| E | 209 秒 | 5 | 11.3GB | 不要 |
| 合計 | 1,013 秒(約 17 分) | 平均 4.0 | 常時 11.3GB | 2 / 5 |
動作確認(ダミー handoff での単発計測・Task A 相当)
ラッパー導入直後に、Task A に近い内容で一度だけ切り分け計測をしています。
| メトリクス | 値 |
|---|---|
| 生成のみ | 78 秒 |
curl 込みの往復全体 |
113 秒 |
| Ollama メモリ | 約 11,289MB(約 11GB) |
| 品質(主観) | 3 / 5 |
このとき JMESPath 側で Buckets[?] のような誤ったクエリが出ており、正しくは Buckets[] のような形になる、というタイプのミスでした(CLI と JSON クエリの境目でよくあるやつ、という感じです)。
Task 005: qwen3-coder:latest(30B 相当)で同じ 5 タスク(速度狙い)
30B モデルの取得は約 18GB で、回線次第ですがかなり時間がかかる部類でした(ログ上は途中 stall もあり、kill して再開したら残りから再開できる、という運用メモが残っています)。
| タスク | 所要時間 | 品質 | Ollama メモリ | 修正要否 |
|---|---|---|---|---|
| A | 47 秒 | 1 | 19.3GB | 要修正(jq 内で aws CLI を呼ぶ無効な案) |
| B | 38 秒 | 4 | 19.3GB | 不要 |
| C | 38 秒 | 5 | 19.3GB | 不要 |
| D | 37 秒 | 3 | 19.3GB | 要修正(for 文のクォート漏れ) |
| E | 38 秒 | 5 | 19.3GB | 不要 |
| 合計 | 198 秒(約 3.3 分) | 平均 3.6 | 常時 19.3GB | 2 / 5 |
やはり 30B 側は 14B より約 5 倍速い 結果でした。一方で品質平均は 3.6 で、14B の 4.0 を下回ります。
特に Task A は 1 / 5 で、「コーダー特化」でも CLI と jq の境界は別問題になりやすい、という当たりを取りにいけた実験でした。
Task 006: gemma4:31b-it-q4_K_M(31B 相当)で同じ 5 タスク(品質狙い)
Gemma4 の 31B(Q4)も同じ handoff で実行しました。llama3.3:70b 系は 36GB メモリ環境でダウンロード・実行時間が長く、今回は実験対象から外しています。
| タスク | 所要時間 | 品質 | Ollama メモリ | 修正要否 |
|---|---|---|---|---|
| A | 386 秒 | 3 | 22.3GB | 要修正(GB表示不足・精度確認が必要) |
| B | 199 秒 | 4 | 22.3GB | 不要 |
| C | 201 秒 | 5 | 22.3GB | 不要 |
| D | 762 秒 | 4 | 22.2GB | 要修正(引数分割の実装方針確認) |
| E | 169 秒 | 5 | 22.2GB | 不要 |
| 合計 | 1,717 秒(約 28.6 分) | 平均 4.2 | 常時 22.2〜22.3GB | 2 / 5 |
品質平均は今回のローカル勢で最も高かった一方、速度は最遅でした。
つまり Gemma4 は「速さ」ではなく「品質寄り」を取りに行く選択肢、という位置づけです。
4 条件の並べ(最終サマリー)
| Claude Code | qwen3:14b |
qwen3-coder:latest(30B) |
gemma4:31b-it-q4_K_M |
|
|---|---|---|---|---|
| 速度(5 タスク合計) | 3 秒 | 1,013 秒(約 17 分) | 198 秒(約 3.3 分) | 1,717 秒(約 28.6 分) |
| 対 Claude 比 | 基準 | 約 338 倍遅い | 約 66 倍遅い | 約 572 倍遅い |
| 品質平均(主観) | 4.6 | 4.0 | 3.6 | 4.2 |
| メモリ(ローカル) | 0GB(API) | 11.3GB | 19.3GB | 22.3GB |
| CLI / コマンド系 | 強い | やや弱い | かなり弱い(今回の A) | やや弱い(A は 3/5) |
| 整形・定型コード系 | 強い | 強い | 強い(C は満点) | 強い(C は満点) |
| 修正が要ったタスク数 | 0 / 5 | 2 / 5 | 2 / 5 | 2 / 5 |
ここまでを一文でまとめると、**「速さは qwen3-coder、品質は Gemma4、難所は Claude」**でした。
背景(なぜローカルに振るのか)
Claude のようなクラウドモデルは、公称どおり非常に長いコンテキストを扱えます。一方で、長い履歴のなかで重要情報が埋もれることや、入力トークン量に比例してコストとレイテンシが増えることは、運用では意識した方がよい部類の話です。長文における注意点として知られているのが、たとえば次のような資料です。
- Lost in the Middle: How Language Models Use Long Contexts(長いコンテキストのどこを見やすいか、という研究)
- Anthropic — Prompting long contexts(長文プロンプトの扱い方の公式ガイド)
なので今回のスタンスは、「ローカル LLM が Claude を置き換える」ではなく、コンテキストというリソースを、設計・判断・難所の実装に寄せるために、定型寄りの生成を別プロセスに逃がす、という割り切りです。
役割分担のイメージ
| 役割 | 担当 | コンテキストへの載せ方 |
|---|---|---|
| タスク分解・handoff 作成・統合レビュー | Claude Code(司令塔) | 会話に載る |
| handoff に書かれた範囲の実装・下書き | ローカル LLM(Ollama) | 原則として handoff 本文+短いプロンプト程度 |
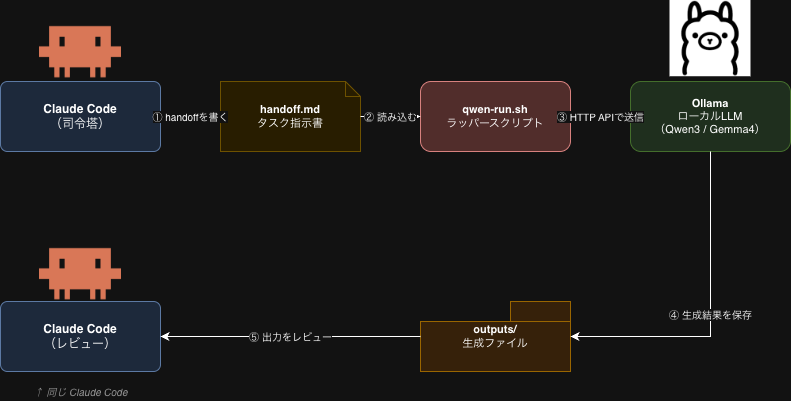
考察(数字の背後で言えること)
「パラメータ数が大きい = 速い / 高品質」ではない、というのが率直な感想です。今回の環境(M4 Max)では、qwen3-coder:30b が圧倒的に速かった一方で CLI 系の正しさは弱く、Gemma4 は品質が高めでも速度は大きく落ちました。Apple Silicon の Neural Engine まわりとの相性などは、**断定は避けて「そういう要因もあり得る」**くらいに留めておきます(要確認: 同条件を別マシンで再測したい)。
Task A で起きたこと(補足)
14B は JMESPath の書き方が一部誤る(Buckets[?] のような形)タイプのミスでしたが、アプローチ自体は「CLI で一覧 → jq で集計」という筋は通っていました。一方 30B は、jq のフィルタ式のなかで aws s3api ... を再度呼び出すような、シェルとして実行不能な案を出してしまい、品質スコアは 1 / 5まで落ちました。つまり「コーダー特化」でも、シェルと JSON クエリと AWS CLI の境界は別スキルになりやすい、という見立てです。
実際の出力を並べると、違いがはっきりします。
Claude(4/5)
aws s3api list-buckets --query 'Buckets[].Name' --output text \
| tr '\t' '\n' \
| while read bucket; do
size=$(aws s3api list-objects-v2 --bucket "$bucket" --query 'sum(Contents[].Size)' --output text 2>/dev/null || echo 0)
echo "${size:-0} $bucket"
done \
| sort -rn \
| awk '{printf "%.2f GB\t%s\n", $1/1073741824, $2}'
JMESPath は正しく Buckets[].Name と書けており、変数クォートも適切。ただし「1行ワンライナー」ではなく複数行になった点と、バケットごとに API を叩く N+1 問題があるため 4/5。
qwen3:14b(2/5)
aws s3api list-buckets --region ap-northeast-1 | jq -r '.Buckets[] | .Name' \
| xargs -I {} sh -c 'aws s3api list-objects --bucket {} --region ap-northeast-1 --max-items 1000 \
| jq -r "sum(.Contents[].Size) / 1024 / 1024 / 1024" \
| jq -r ". + \" \" + {}" | sort -k1 -nr
jq -r ". + \" \" + {}" の {} は xargs で展開されず jq がオブジェクトコンストラクタと解釈するため構文エラーになります。アプローチ(list-buckets → xargs → jq で集計)という流れ自体は正しいものの、jq クエリの細部でミス。
qwen3-coder:latest(30B相当)(1/5)
aws s3api list-buckets --query 'Buckets[].Name' --output json \
| jq -r '.[] | {bucket: ., size: (aws s3api list-objects-v2 --bucket . --output json --query "sum(Contents[].Size) // 0")}' \
| jq -r '.bucket + " " + (.size / 1024 / 1024 / 1024 | floor | tostring) + "GB"' \
| sort -k2 -nr
jq のフィルタ式の中で aws s3api list-objects-v2 ... を呼び出そうとしています。jq はシェルコマンドを実行できないため、これは構文エラーにすらならず動作しません。「コーダー特化」でも、CLI とデータ変換ツールの責務境界は別の話でした。
Task D で起きたこと(補足)
shellcheck 系は、14B は 「直したつもりだが不完全」、30B は for まわりのクォート漏れのように、別の穴を開けるパターンでした。どちらも最終的には人手レビュー前提になりやすく、「ローカルが一発で緑」を期待しないほうが安全です。
元のスクリプト(shellcheck 指摘あり)は次のようなものを想定しています。
#!/usr/bin/env bash
FILES=$1
for f in $FILES
do
if [ -f $f ]; then
cat $f >> /tmp/output.txt
echo "processed $f"
fi
done
echo "Done. $FILES files processed."
各モデルの修正結果を並べます。
Claude(4/5)
#!/usr/bin/env bash
FILES="$1" # fixed: SC2086 - quote to prevent word splitting
for f in $FILES # fixed: SC2086 - iterate over quoted arg
do
if [ -f "$f" ]; then # fixed: SC2086 - quote variable
cat "$f" >> /tmp/output.txt # fixed: SC2086
echo "processed $f" # fixed: SC2086
fi
done
echo "Done. $FILES files processed." # fixed: SC2086
FILES="$1" のクォートと "$f" のクォートは修正済み。for f in $FILES の $FILES が未クォートのまま残っている点で 4/5。
qwen3:14b(3/5)
#!/usr/bin/env bash
FILES=$1
for f in $FILES
do
if [ -f "$f" ]; then
cat "$f" >> /tmp/output.txt
echo "processed $f"
fi
done
echo "Done. "$FILES" files processed."
# fixed: SC2086 SC2148
$f のクォートは直っていますが、FILES=$1 のクォートが未修正のまま。さらに echo "Done. "$FILES" files processed." という文字列結合も不自然で、shellcheck の指摘番号コメントを付けるだけで実質的な修正が不完全でした。
qwen3-coder:latest(30B相当)(3/5)
#!/usr/bin/env bash
FILES="$1" # fixed: SC2086
for f in $FILES # fixed: SC2086
do
if [ -f "$f" ]; then # fixed: SC2086
cat "$f" >> /tmp/output.txt
echo "processed $f"
fi
done
echo "Done. $FILES files processed."
FILES="$1" は正しく修正。しかし for f in $FILES の $FILES がクォートされていない(for f in "$FILES" が正解)。コメントで「fixed: SC2086」と書きながら、肝心の for 行のクォートが漏れているパターン。14B と同じ 3/5 でも、ミスの性質が異なります。
また、Markdown 表整形(Task C)は 4 条件すべて 5 / 5でした。つまり「ローカルに振る価値」は、速さだけでなく、司令塔のコンテキストを汚さない作業として切り出せるかどうか、という見立てのほうが現実的です。逆に AWS CLI と JMESPath / jq が絡む系は、少なくとも今回のモデル構成では Claude 優先が安全でした。
フォールバック設計(ローカル失敗時にだけクラウドへ)をスクリプト化しておく、というのは、research 側でも触れていた実用的な落とし所だと思います。今回は PoC なので最小構成(shell + handoff)に寄せていますが、CrewAI や LangGraph を立てずに回せたのは小さな収穫でした。
まとめ
今回の実測だけを抜き出すと、次の整理になります。
- 速度: Claude が突出。ローカルでは qwen3-coder:30b が最速(3.3分)、Gemma4 は最遅(28.6分)。
- 品質(主観): 平均では Claude > Gemma4 > 14B > 30B。ただしタスク依存が大きい(C は全員満点、A は差が出やすい)。
- メモリ: 14B で約 11GB、30B で約 19GB、Gemma4 で約 22GB。ノート PC では体感差が大きい。
- 実運用の指針: 置き換えではなく分担。設計/CLI は Claude、速度系の定型タスクは qwen3-coder、品質寄りの下書きは Gemma4。
そして今回いちばんの学びは、モデル選びより先に「何を司令塔側に残すか」を決めることでした。
ローカル LLM を使う価値は、生成そのものより、司令塔のコンテキストを守る設計にあります。
もっとスマートな役割分担や、別モデル(別量子化)での再測定ノウハウを御存知の方がいれば、ぜひ DevelopersIO のコメントや X などで教えてください。











