
Cloudflare WorkersのCron TriggersとKVでAPIレスポンスを定期キャッシュする
はじめに
皆様こんにちは、あかいけです。
最近Cloudflare Workersで個人的なサイトを作る中で、
外部APIから取得したデータをどうやってキャッシュするか悩む場面がありました。
具体的には、Qiita、Zenn、DevelopersIOなど複数の技術ブログプラットフォームから自分の記事一覧を取得して表示する機能を実装したのですが、
リクエストのたびに外部APIを叩くのはさすがに非効率ですよね。
レスポンスも遅くなりますし、APIのレート制限に引っかかるリスクもあります。
そこで今回は、Cloudflare WorkersのCron TriggersとKVを組み合わせて、
外部APIの取得結果を定期的にキャッシュする仕組みを実装してみたので、その方法をまとめます。
ざっくり概要
アーキテクチャの全体像は以下のとおりです。
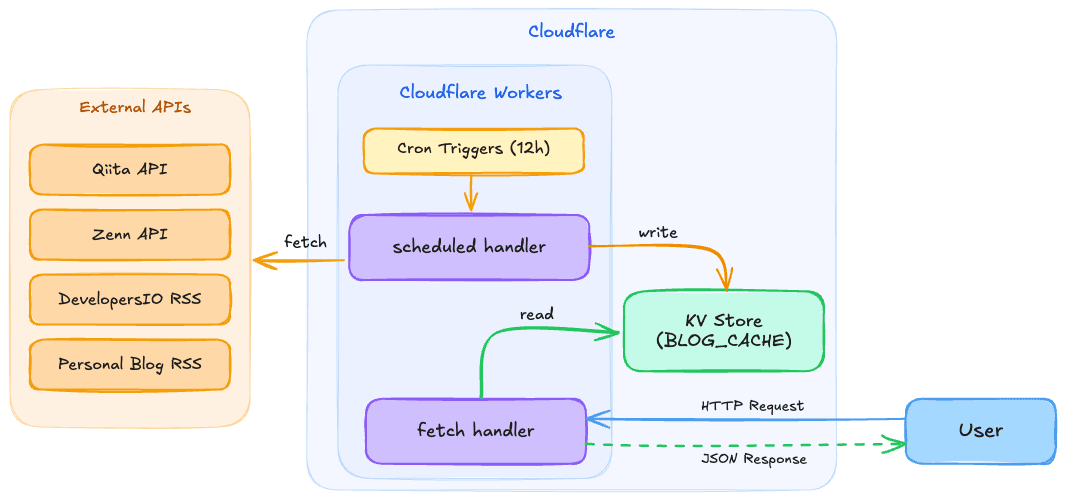
ポイントは以下の2つで、この構成にすることで、ユーザーのリクエスト時に外部APIを叩く必要がなくなり、レスポンスが高速になるとともに、外部APIのレート制限も気にしなくてよくなります。
- Cron Triggers
- 定期的(今回は12時間ごと)に外部APIからデータを取得し、KVに保存する
- KV
- 取得したデータをキャッシュとして保持し、ユーザーリクエスト時はKVから返す
実装
1. wrangler設定
まずはwrangler.jsoncでKVネームスペースとCron Triggersを設定します。
{
"name": "my-worker",
"main": "./workers/app.ts",
"kv_namespaces": [
{
"binding": "BLOG_CACHE",
"id": "your-kv-namespace-id"
}
],
"triggers": {
"crons": [
"0 */12 * * *"
]
}
}
- kv_namespaces
- KVネームスペースを任意のバインディング名(上記の場合はBLOG_CACHE)で紐づけます。
idはKVネームスペース作成時に発行されるIDです
- KVネームスペースを任意のバインディング名(上記の場合はBLOG_CACHE)で紐づけます。
- triggers.crons
- cron式で実行スケジュールを指定します。
0 */12 * * *は12時間ごとに実行する設定です
- cron式で実行スケジュールを指定します。
KVネームスペースの作成は以下のコマンドで行えます。
npx wrangler kv namespace create "BLOG_CACHE"
2. Workerのエントリーポイント
Workerのエントリーポイントでは、通常のHTTPリクエストを処理するfetchハンドラと、
定期実行されるscheduledハンドラの2つを定義します。
import { updateBlogCache } from "./blogFetcher";
export default {
// 通常のHTTPリクエストを処理
async fetch(
request: Request,
env: Env,
ctx: ExecutionContext
): Promise<Response> {
// アプリケーションのリクエストハンドラに渡す
return handleRequest(request, env, ctx);
},
// Cron Triggersによる定期実行
async scheduled(
_controller: ScheduledController,
env: Env,
ctx: ExecutionContext
): Promise<void> {
ctx.waitUntil(updateBlogCache(env.BLOG_CACHE));
},
} satisfies ExportedHandler<Env>;
scheduledハンドラがCron Triggersで呼び出されるエントリーポイントです。
ctx.waitUntil()を使うことで、レスポンスを返した後もバックグラウンドで処理を継続できます。
3. 外部APIからのデータ取得
外部APIからデータを取得する処理です。
今回はQiita API、Zenn API、DevelopersIOのRSSフィード、個人ブログのRSSフィードの4つのソースから記事を取得する例を示します。
const KV_KEY = "blog_articles";
// Cloudflare Workersのサブリクエスト上限は50回/実行
// 各ソースの取得ページ数を制限して上限を超えないようにする
const MAX_PAGES_QIITA = 5;
const MAX_PAGES_ZENN = 5;
// DevelopersIOはRSSのページネーションが効かないため1ページのみ
const MAX_PAGES_DEVIO = 1;
export interface Article {
id: number;
title: string;
date: string;
excerpt: string;
tags: string[];
url: string;
source: string;
likes_count?: number;
page_views_count?: number;
comments_count?: number;
}
各ソースからの取得処理は独立しているので、Promise.allSettled()で並列実行します。
Promise.all()ではなくPromise.allSettled()を使うのがポイントです。
一部のAPIがエラーになっても、成功したソースの結果は取得できます。
export const fetchAllArticles = async (): Promise<Article[]> => {
const results = await Promise.allSettled([
fetchQiitaArticles(),
fetchZennArticles(),
fetchDevelopersIOArticles(),
fetchTortoiseTechBlogArticles(),
]);
const articles: Article[] = [];
for (const result of results) {
if (result.status === "fulfilled") {
articles.push(...result.value);
} else {
// 失敗したソースはログに記録して続行
console.error("Failed to fetch articles:", result.reason);
}
}
// URLベースで重複を除去して日付降順でソート
const seen = new Set<string>();
const unique = articles.filter((a) => {
if (seen.has(a.url)) return false;
seen.add(a.url);
return true;
});
unique.sort(
(a, b) => new Date(b.date).getTime() - new Date(a.date).getTime()
);
// マージ・ソート後に連番IDを振る
unique.forEach((article, index) => {
article.id = index + 1;
});
return unique;
};
個々のAPI取得処理の例として、Qiita APIの取得処理を示します。
ページネーションに対応しつつ、サブリクエスト上限を意識して最大ページ数を制限しています。
const fetchQiitaArticles = async (): Promise<Article[]> => {
const allData: QiitaArticle[] = [];
let page = 1;
const perPage = 100;
while (page <= MAX_PAGES_QIITA) {
const response = await fetch(
`https://qiita.com/api/v2/users/{username}/items?page=${page}&per_page=${perPage}`
);
if (!response.ok) {
throw new Error(`Qiita API returned status: ${response.status}`);
}
const data = (await response.json()) as QiitaArticle[];
if (!data || data.length === 0) break;
allData.push(...data);
// 取得件数がper_page未満なら最後のページ
if (data.length < perPage) break;
page++;
}
return allData.map((item, index) => ({
id: index,
title: item.title,
date: item.created_at.split("T")[0],
url: item.url,
source: "Qiita",
tags: item.tags.map((tag) => tag.name),
}));
};
4. KVへのキャッシュ保存と読み出し
KVへの書き込みと読み出しの処理です。
/**
* Fetch articles and store them in KV.
*/
export const updateBlogCache = async (kv: KVNamespace): Promise<void> => {
console.log("Updating blog cache...");
const articles = await fetchAllArticles();
if (articles.length > 0) {
await kv.put(KV_KEY, JSON.stringify(articles));
console.log(`Blog cache updated: ${articles.length} articles stored`);
} else {
// 全ソースが失敗した場合は既存キャッシュを維持
console.warn("No articles fetched, skipping KV update");
}
};
/**
* Get cached articles from KV.
* Returns empty array if KV is empty.
*/
export const getCachedArticles = async (
kv: KVNamespace
): Promise<Article[]> => {
const cached = await kv.get(KV_KEY);
if (cached) {
return JSON.parse(cached) as Article[];
}
// KVが空の場合はログを出して空配列を返す
// 次回のCron Triggerで自動的にKVにデータが保存される
console.warn("KV cache is empty. Waiting for next scheduled update.");
return [];
};
getCachedArticles()では、KVが空の場合(デプロイ直後でまだCronが走っていない場合など)は空配列を返し、次回のCron Triggerでデータが保存されるのを待つ設計にしています。
ユーザーリクエスト時に外部APIを直接叩くフォールバックを入れないことで、サブリクエスト制限に引っかかるリスクやレスポンス遅延を回避できます。
5. リクエスト時のKV読み出し
ユーザーからのリクエスト時は、KVからキャッシュを読み出して返します。
以下はReact Router v7のSSR loaderでの例です。
export async function loader({ context }: Route.LoaderArgs) {
try {
const articles = await getCachedArticles(
context.cloudflare.env.BLOG_CACHE
);
return { articles, error: null };
} catch (err) {
console.error("Failed to load blog articles:", err);
return { articles: [], error: "記事の取得中にエラーが発生しました。" };
}
}
KVの読み出しは非常に高速なので、ユーザーはほぼ待ち時間なしで記事一覧を閲覧できます。
その他注意点
サブリクエスト制限
Cloudflare WorkersのFreeには1回の実行につきサブリクエスト(外部へのfetch)は50回までという制限があります。
そのため複数のAPIからページネーション付きでデータを取得する場合、この上限にすぐ到達する可能性があります。
今回のケースでは、各ソースの最大ページ数を制限することで対処しています。
// 4ソース合計で上限を超えないようにページ数を制限
const MAX_PAGES_QIITA = 5; // 最大5リクエスト
const MAX_PAGES_ZENN = 5; // 最大5リクエスト
const MAX_PAGES_DEVIO = 1; // 1リクエスト
// tortoise-tech-blog: 1リクエスト
// 合計: 最大12リクエスト(50回の上限内に収まる)
エラーハンドリング
外部APIは常に成功するとは限りません。
Promise.allSettled()を使うことで、一部のAPIが失敗しても他のソースの結果を取得できるようにしています。
また、全ソースが失敗した場合でも既存のKVキャッシュを維持する(上書きしない)ことで、
一時的なAPI障害でデータが消えてしまう事態を防いでいます。
KVの結果整合性
Cloudflare KVは**結果整合性(Eventual Consistency)**のストレージです。
書き込み後、世界中のエッジロケーションに反映されるまで最大60秒程度かかる場合があります。
今回のようにCron Triggersで12時間ごとに更新するユースケースでは、
この結果整合性は特に問題になりません。
ただし、リアルタイム性が求められるデータには向かないので注意してください。
Cron Triggersの実行タイミング
Cron Triggersの実行タイミングはUTCベースです。
本記事の0 */12 * * *の場合、UTC 0:00とUTC 12:00に実行されます(JST 9:00とJST 21:00)。
さいごに
以上、Cloudflare WorkersのCron TriggersとKVで外部APIの取得結果を定期キャッシュする方法でした。
この構成のいいところは、シンプルな仕組みで外部APIへの依存度を大幅に下げられる点です。
Cloudflare Workersはエッジで動作するため、KVからの読み出しも非常に高速ですし、
Cron Triggersで定期的にキャッシュを更新しておけば、ユーザーリクエスト時に外部APIの応答を待つ必要がありません。
今回はブログ記事の一覧取得という比較的シンプルなユースケースでしたが、外部APIのレスポンスをキャッシュしたいケースは割と多いかと思います。
同じような課題を抱えている方の参考になれば幸いです。










