
CloudWatch ログ統合管理機能のデータソースとして CloudWatch カスタムログ を取り込んで、grok パーサーを適用したりファセットを利用した分析を行ってみた #AWSreInvent
re:Invent 2025 で CloudWatch のログ管理機能全般にアップデートが入り、CloudWatch でログ基盤を作りやすくなりました。
特に下記ログは CloudWatch ログに出力しただけで自動識別されてインデックスが作成され、ファセットを利用した分析もできるようになります。
- VPC フローログ
- Route53 クエリログ
- WAF アクセスログ
- CloudTrail ログ
その他にも API Gateway のアクセスログや EKS Audit ログなど多数のログが自動識別の対象になり、インデックスポリシーを作成すれば同等の分析が可能です。
また、任意の CloudWatch ログをカスタムログとしてデータソース化することも可能です。
今回は CloudWatch カスタムログとして Nginx のアクセスログをデータソース化した後、パイプライン機能でパースして、インデックスポリシー作成と分析まで行ってみます。
CloudWatch ログをデータソース化する方法について
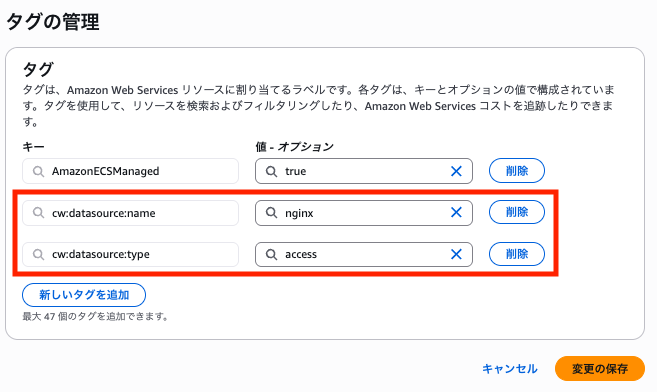
特殊なタグである cw:datasource:name と cw:datasource:type を付与することで対象のロググループを CloudWatch に認識させることができます。
Add tags to your log groups using the keys cw:datasource:name and cw:datasource:type to specify the data source name and type respectively for all logs ingested in the log group
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/data-source-discovery-management.html
cw:datasource:name がログ出力元の名前、cw:datasource:type がログ種別になります。
一つのデータソース名の中に複数のログ種別が存在することは許容されており、例えば EKS ログの場合は下記のように検出されます。
| Data Source Name | Data Source Type | 備考 |
|---|---|---|
| amazon_eks | api_server | API サーバーログ |
| amazon_eks | audit | 監査ログ |
| amazon_eks | authenticator | Authenticator ログ |
| amazon_eks | controller_manager | コントローラーマネージャーログ |
| amazon_eks | scheduler | スケジューラログ |
カスタムログの場合は任意の名前、タイプを指定可能です。
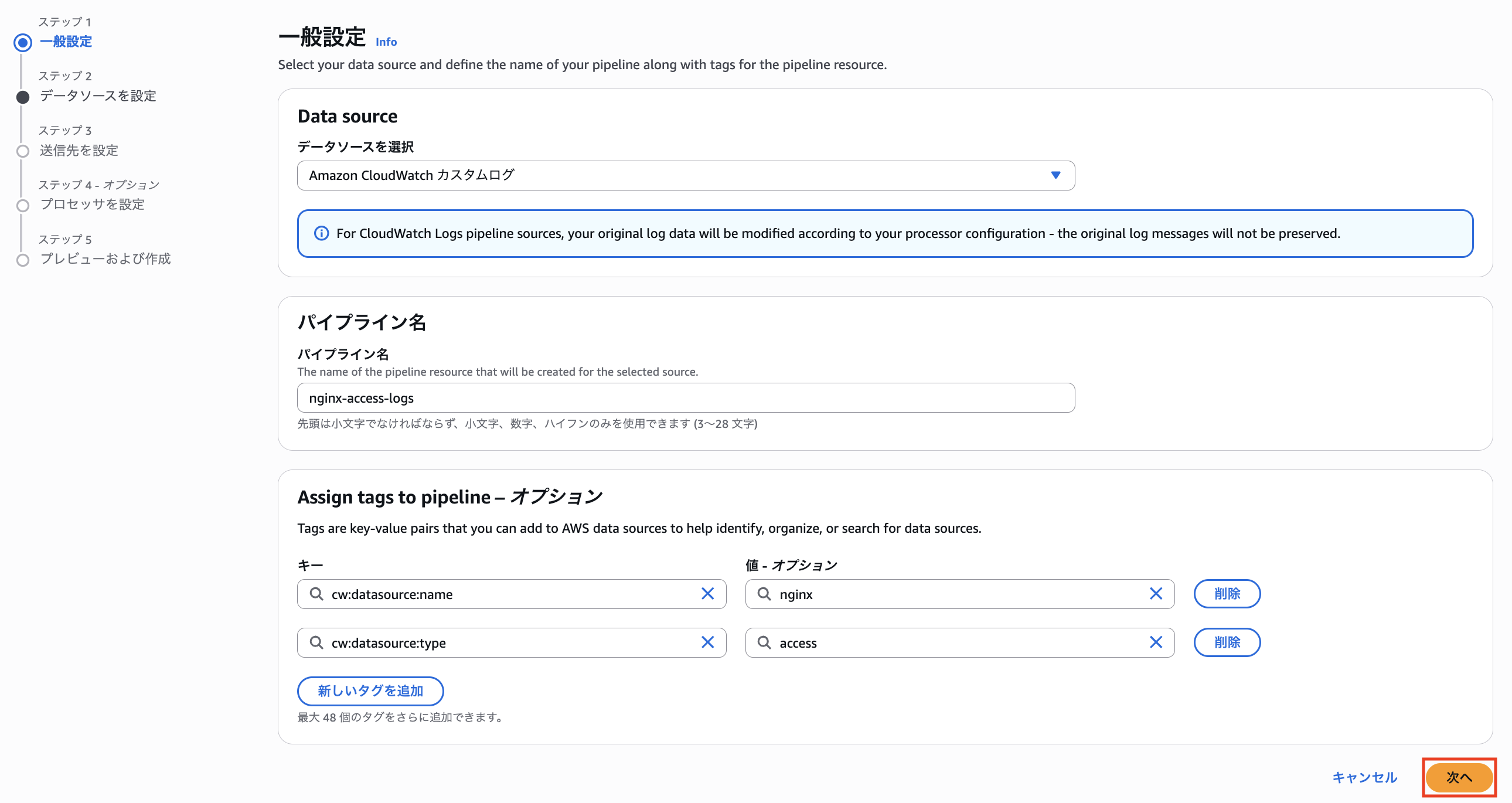
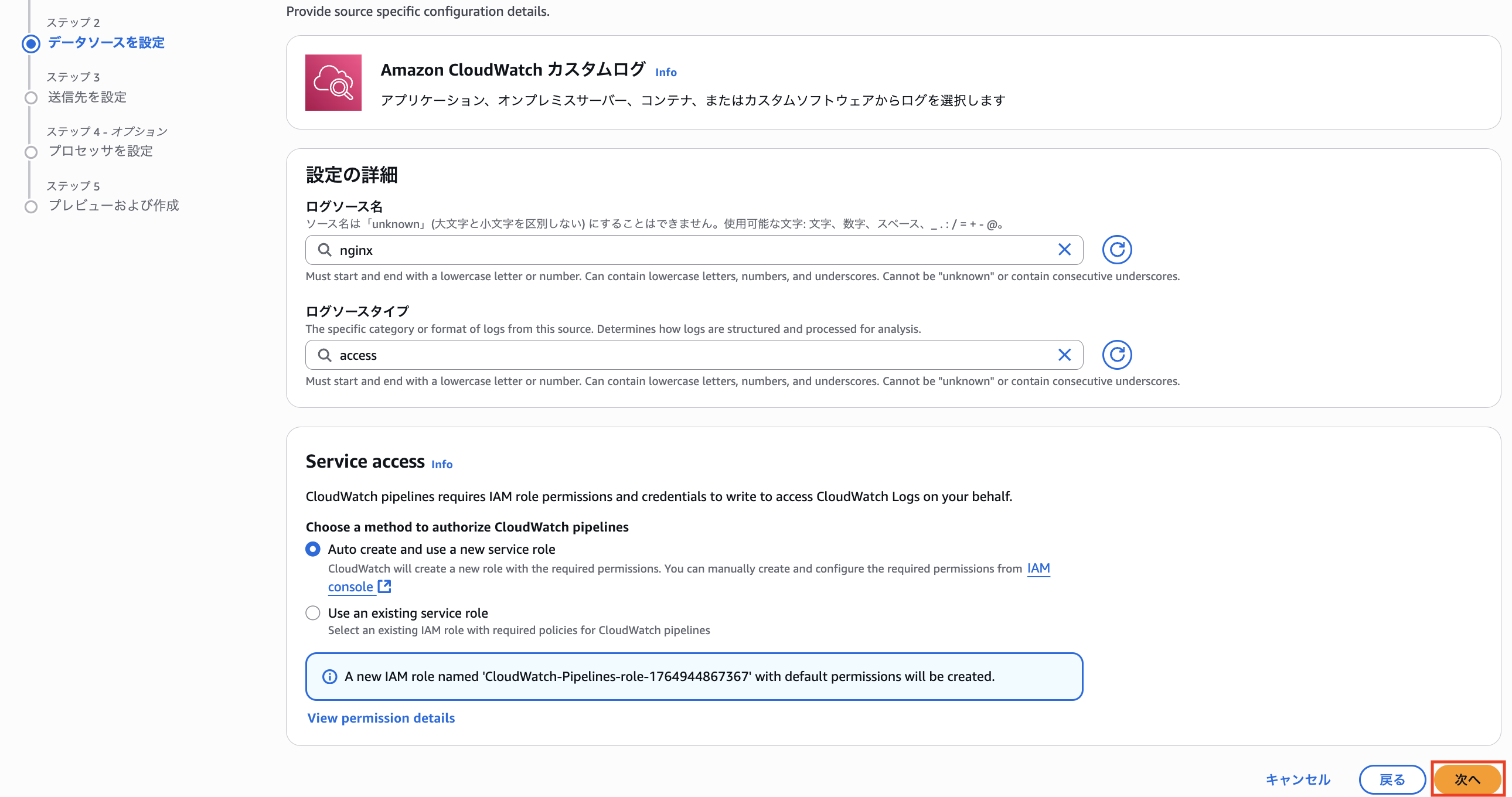
今回は Nginx のアクセスログを扱うので、Data Source Name を nginx、Data Source Type を access とします。
やってみる
まず、ロググループにタグを付与します。
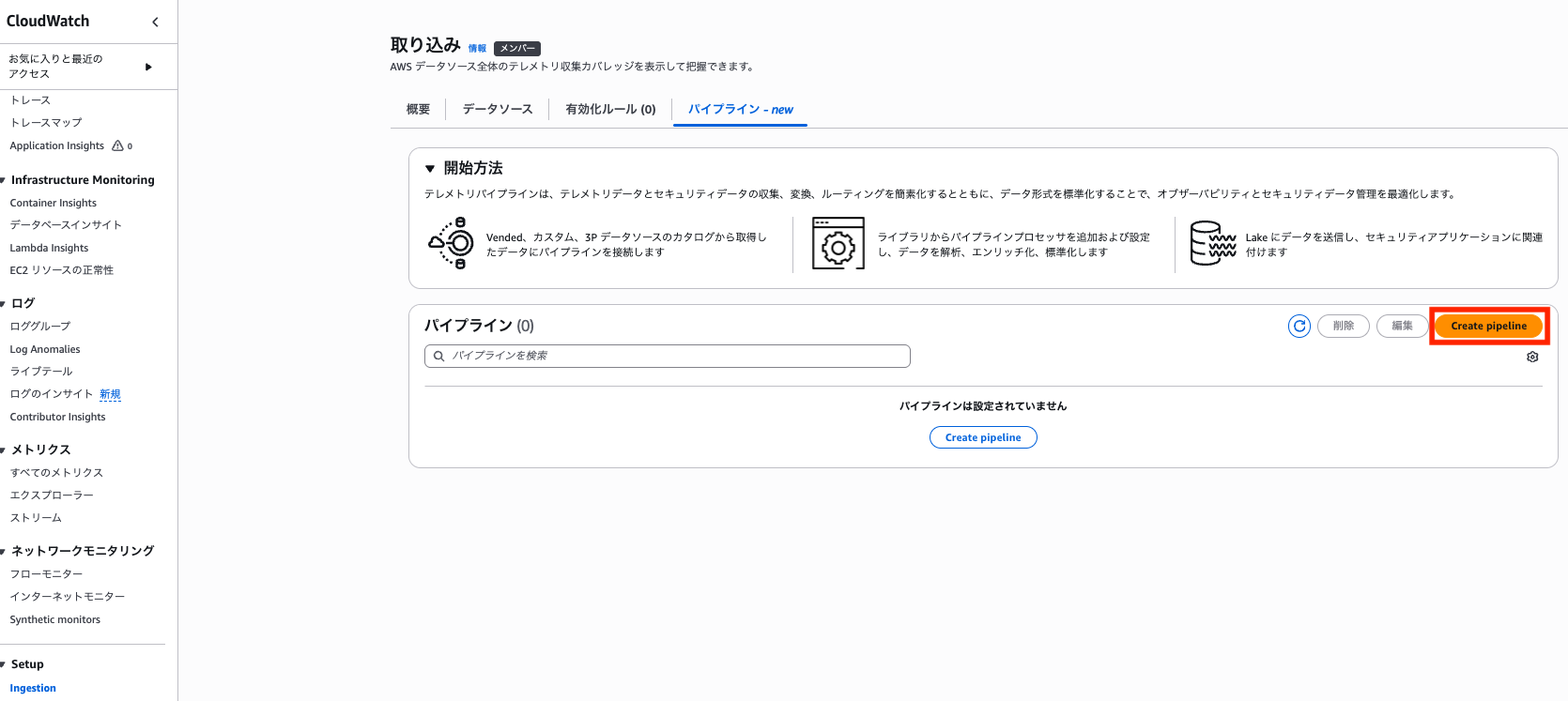
続いて、「Setup > Ingestion > パイプライン」から「Create Pipeline」をクリックします。
CloudWatch ロググループに付与したものと同じタグを指定します。
ログソース名とログソースタイプも同じものを指定します。
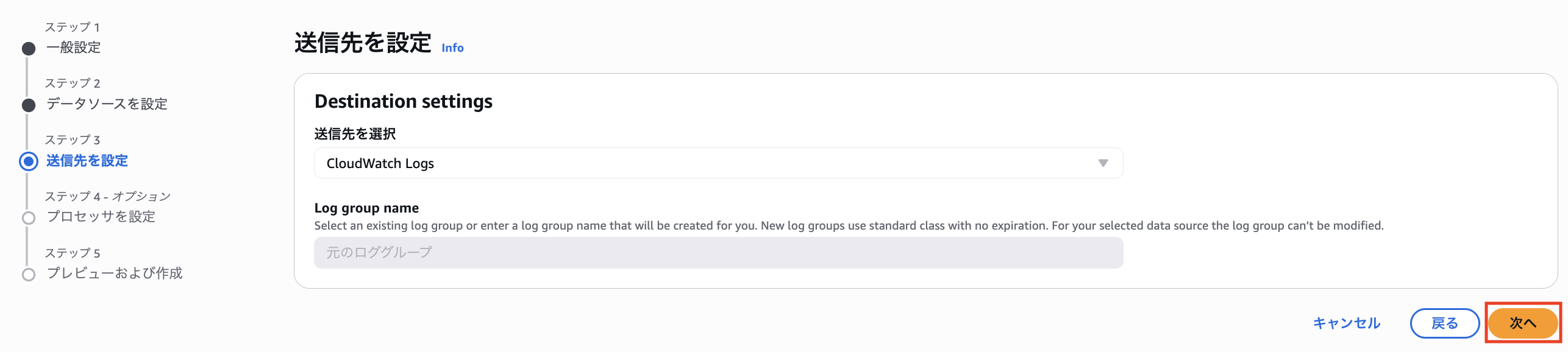
出力先は「元のロググループ」しか選べません。
パイプライン機能で変換されたログが元ロググループに直接出力されます。
今回は grok パーサーを利用して、パースを行ってみます。
NGINX、Apache、Syslog Protocol(RFC 5424) については、定義済みのカスタム grok パターンが用意されているので利用してみようと思います。
Amazon ECR Public Gallery の public.ecr.aws/nginx/nginx:1.29 を特に設定を変えず利用したのですが、普通にマッチさせるとエラーになりました。
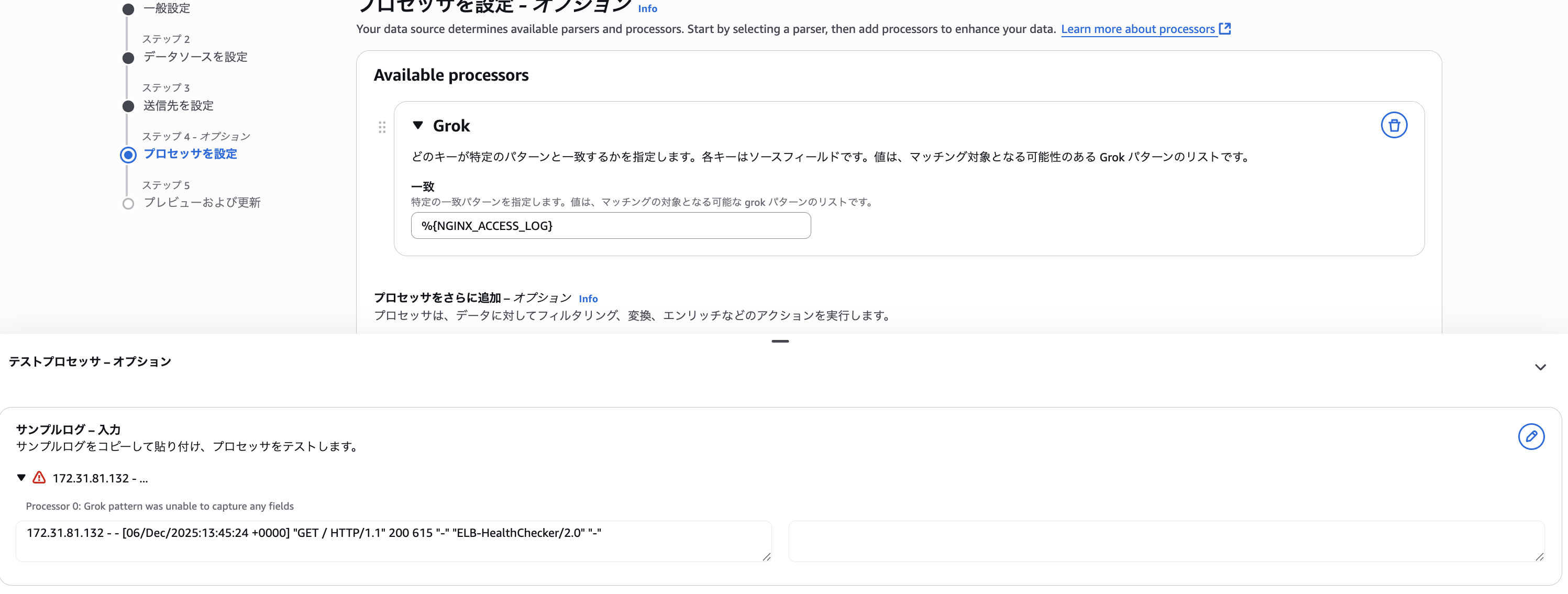
ログ形式は下記のようになり、定義されているパターンに対して、最後の X-Forward-For 分が多いようです。
172.31.81.132 - - [06/Dec/2025:13:45:24 +0000] "GET / HTTP/1.1" 200 615 "-" "ELB-HealthChecker/2.0" "-"
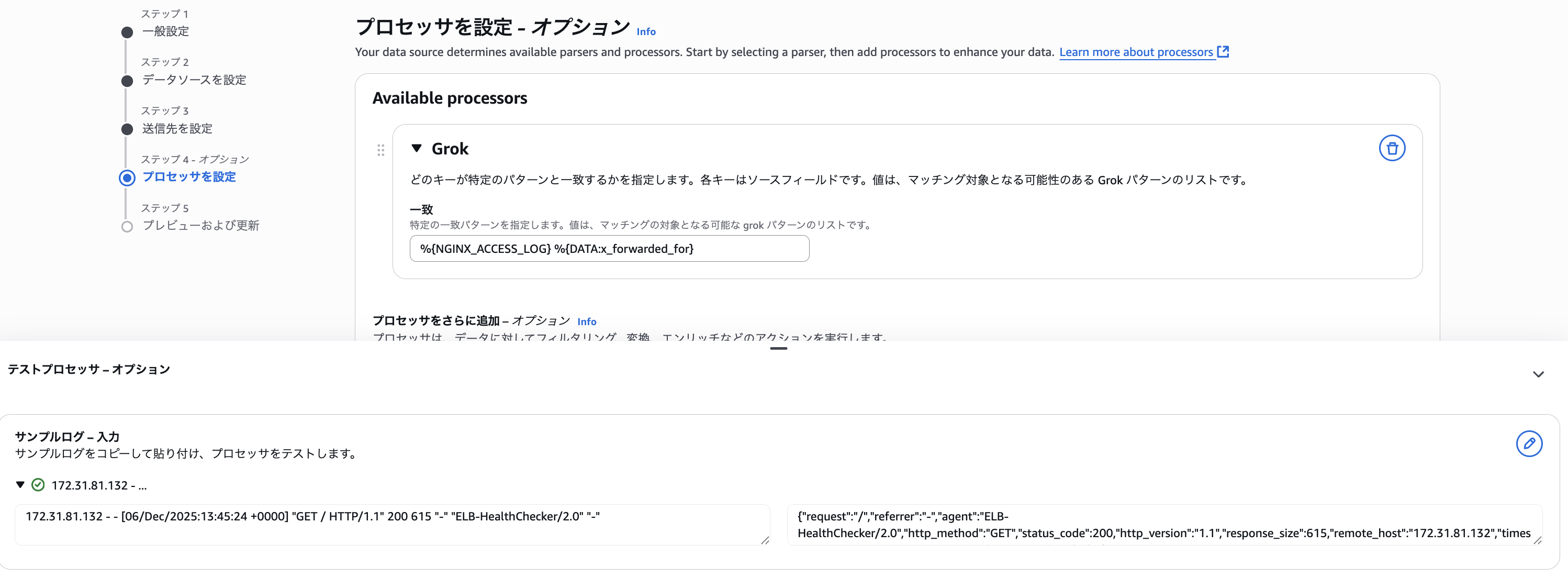
1 属性だけですし、最後に DATA パターンを追加して (%{NGINX_ACCESS_LOG} %{DATA}) 上手くパースできました。
You can use pre-defined custom grok patterns to match Apache, NGINX and Syslog Protocol (RFC 5424) log formats. When you use these specific patterns, they must be the first patterns in your matching configuration, and no other patterns can precede them. Also, you can follow them only with exactly one DATA. GREEDYDATA or GREEDYDATA_MULTILINE pattern.
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/CloudWatch-Logs-Transformation-Configurable.html#CloudWatch-Logs-Transformation-Grok
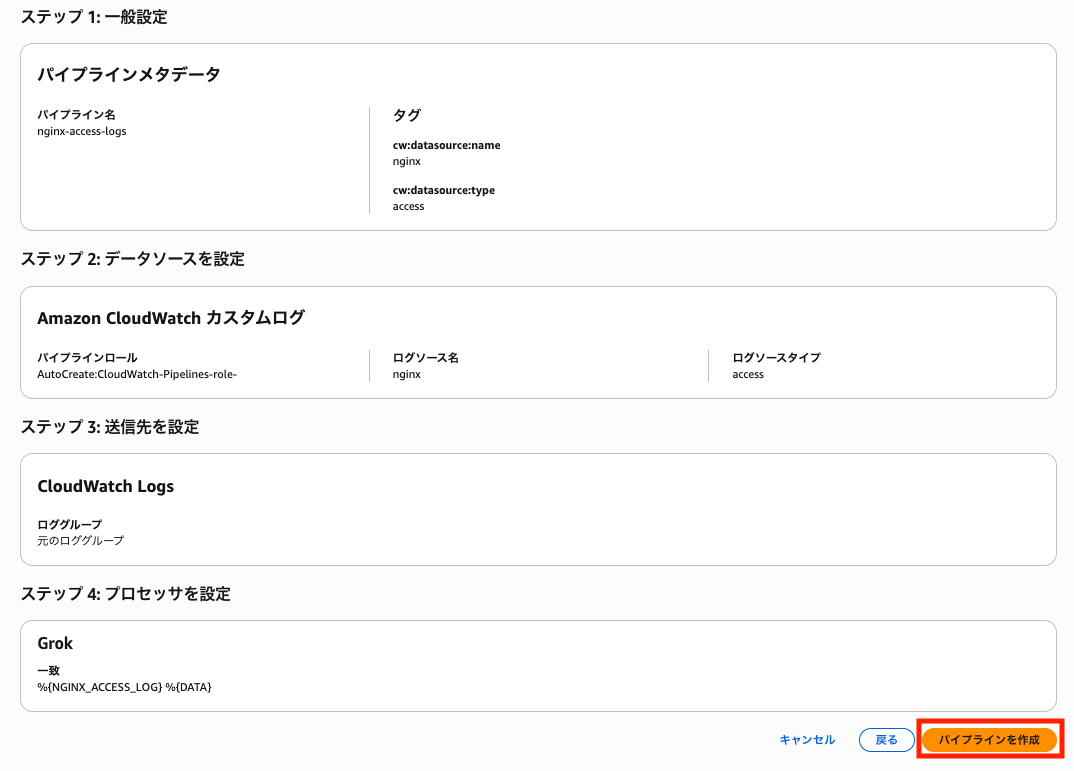
内容を確認して「パイプラインを作成」をクリックします。
続いて、インデックスポリシーを作成します。
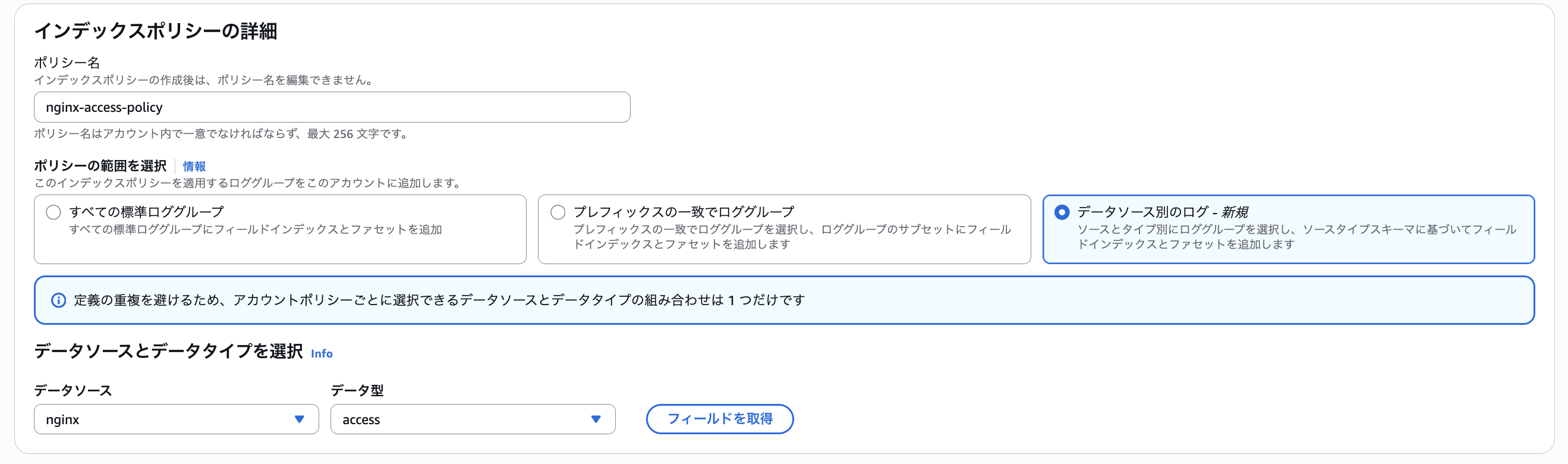
「フィールドを取得」をクリックすると、パースした後の属性一覧を取得できます。
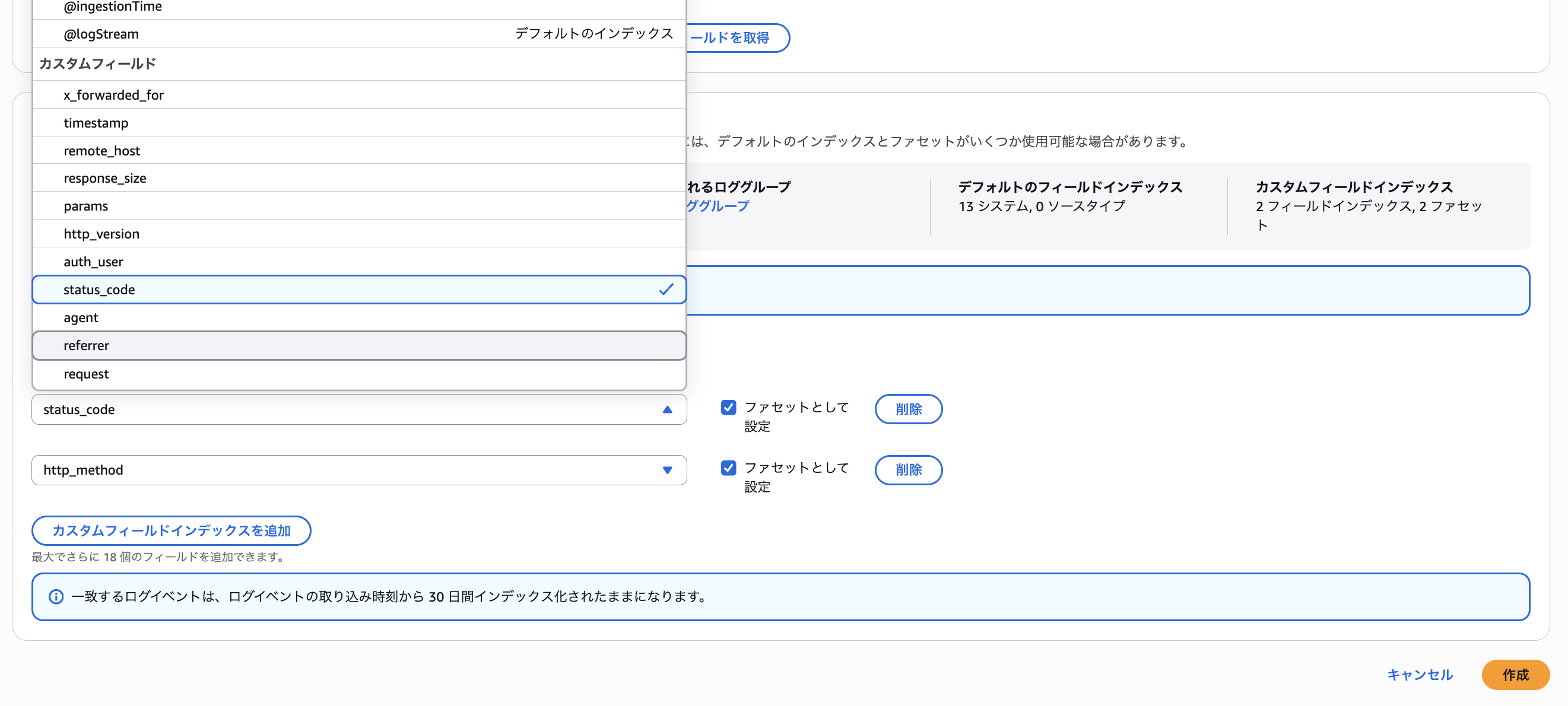
今回は、status_code、http_method、agent を指定してみました。
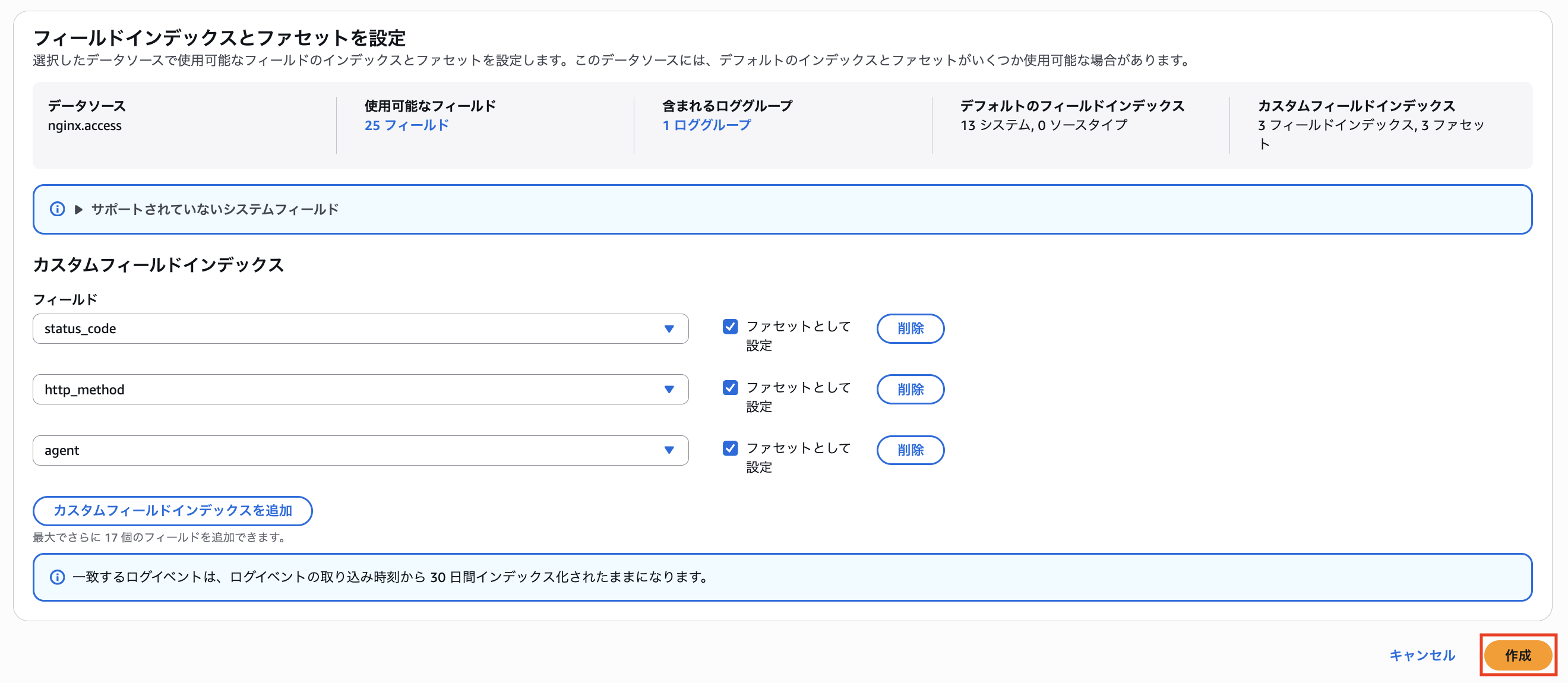
この状態で、Log insights を利用してみます。
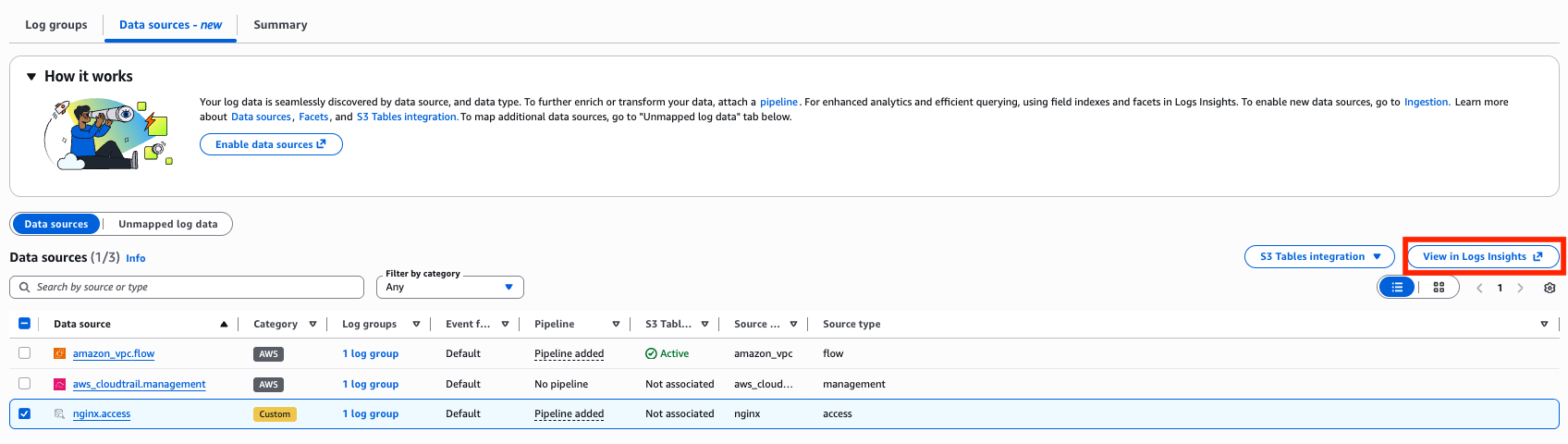
agent、http_method、status_code をファセットとして利用できるようになりました。
チェックボックスを付け替えて「クエリの実行」を行うこと簡単にログの絞り込みが可能です。
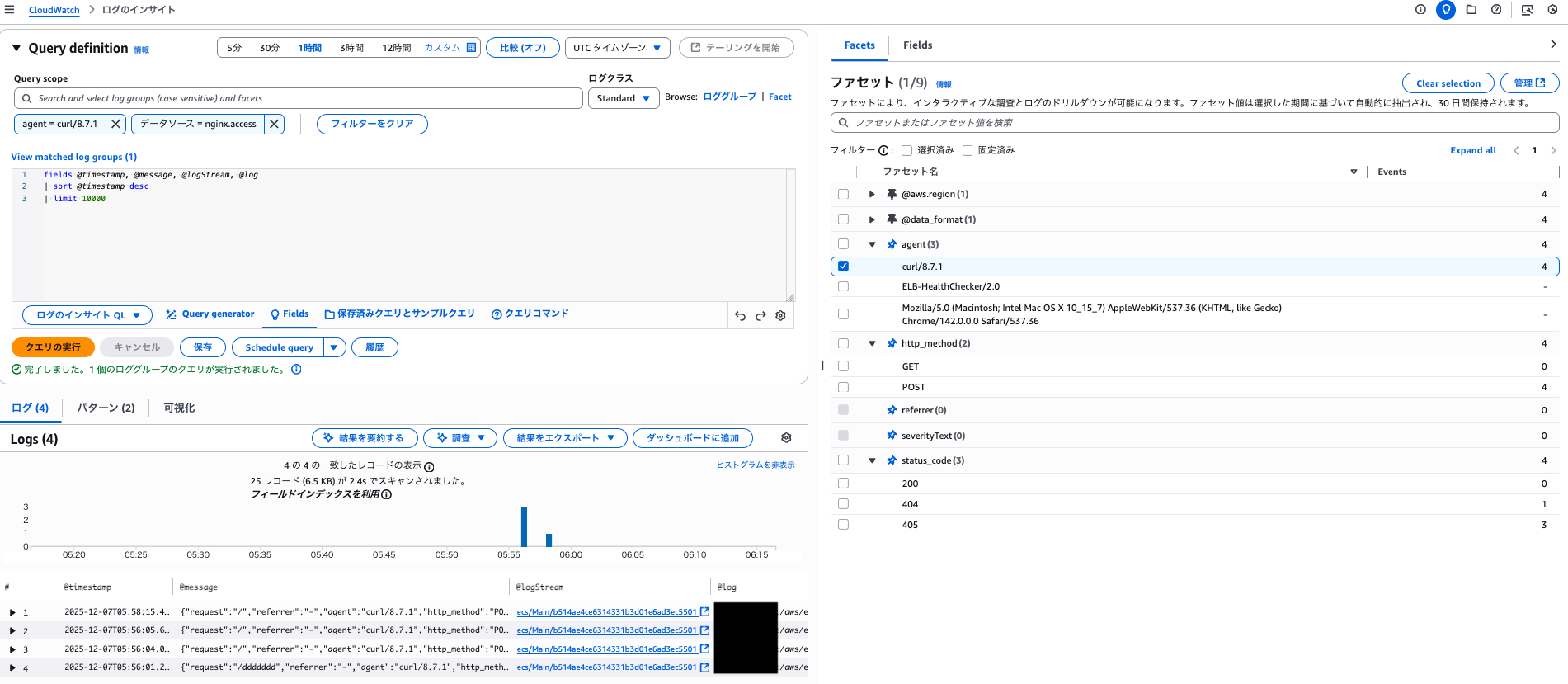
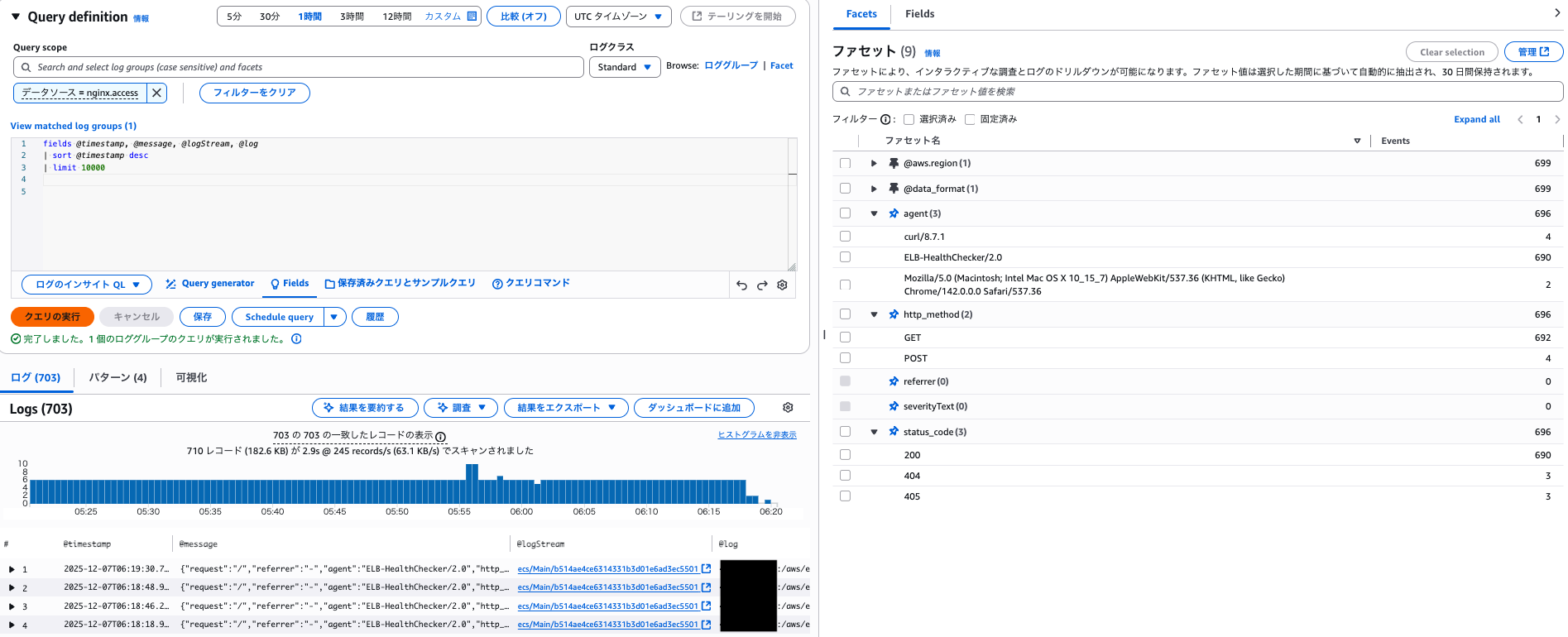
また、同じ時間枠でファセットを指定せずにクエリを行うと 710 レコードがスキャンされるのに対して、ファセットを指定した際は 25 レコードのスキャンで済んでいます。
ファセットを利用した際は自動で同等のインデックスを指定したスキャン相当になるようです。
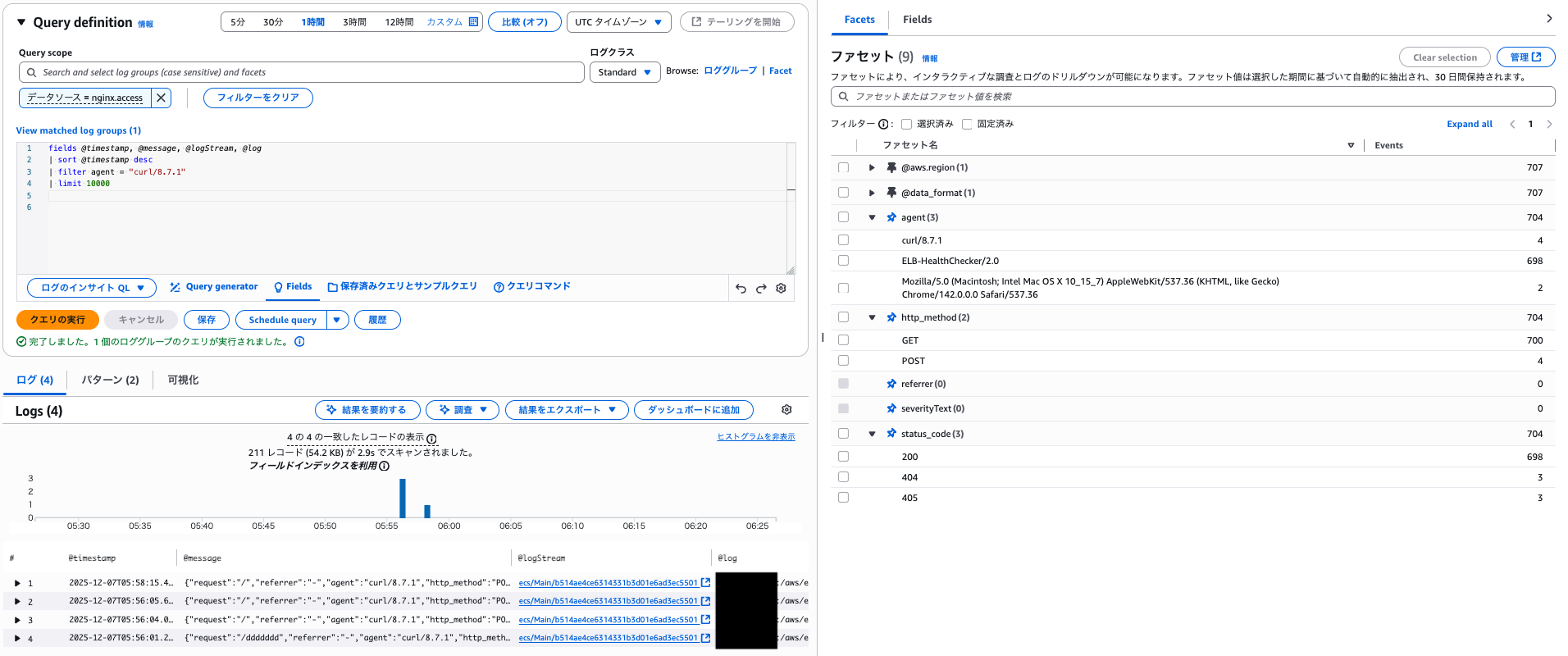
ファセットを利用せずに単に filter で絞った時も多少インデックスが効いてそうですが、211 レコードと大分スキャン量が多くなりました。
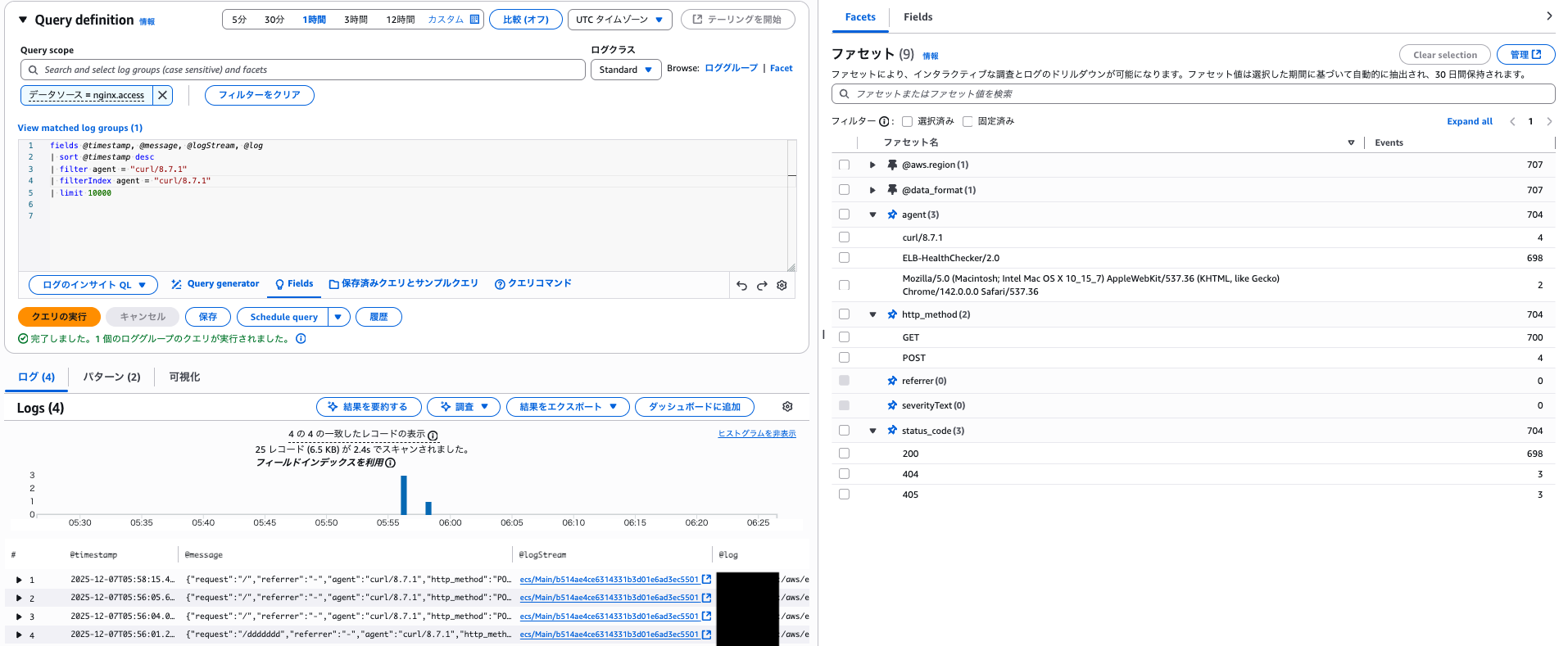
filterIndex で明示的に指定した場合もスキャンされたレコード数は変わらなかったので、ファセットを利用した場合は filterIndex を指定しなくても良さそうでした。
パース失敗時の挙動について
パイプラインのメトリクスからパースに失敗したレコード数を確認可能です。
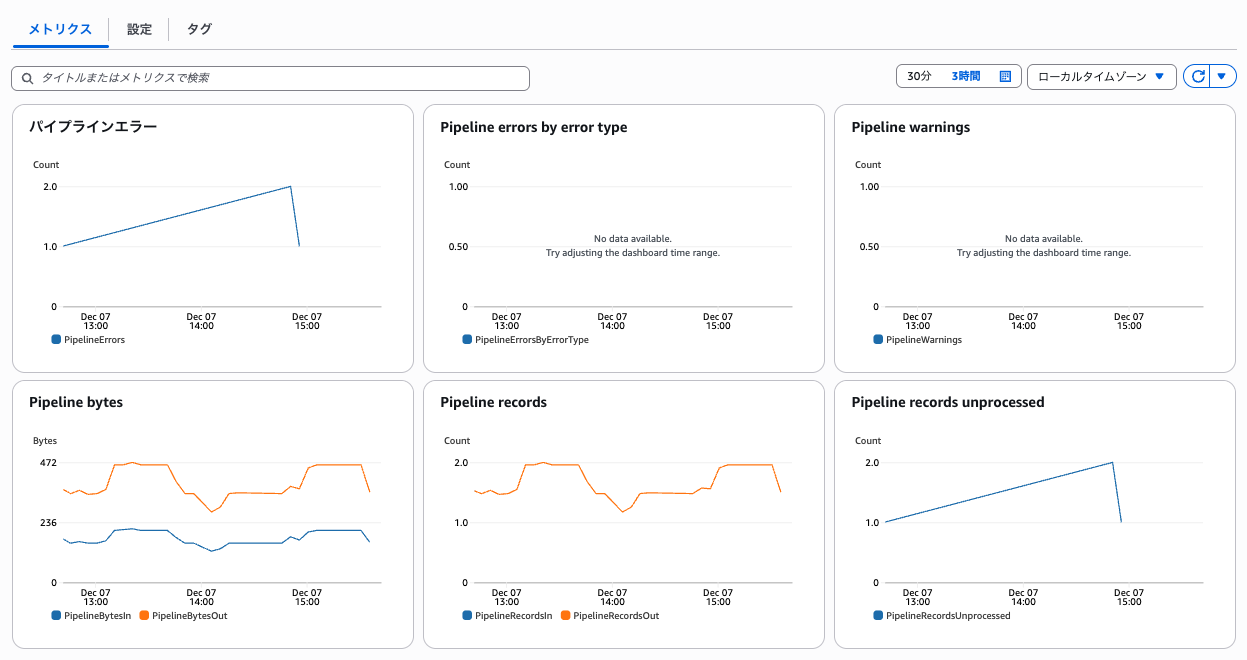
今回はエラーログなども含めて出力したロググループを指定しているので大分失敗していますね...
とはいえ、パースに失敗しても元のログがそのまま出力されるだけのようです。

最後に
今回は CloudWatch の新しいログ管理機能でカスタムログを扱ってみました。
AWS サービスログやカスタムログの他にも 3rd パーティーアプリケーションログを取り込むことが可能なので、そちらも試してみようと思います。










