![[コスト大事] Amazon Athena で S3 の大量オブジェクトをクエリする場合はスキャン量だけでなくリクエスト量も意識しよう](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-764c44f07bcd41184fe62a432ae120ab/512a4cdcd05a0ed3ddea950fdf619fa0/amazon-athena?w=3840&fm=webp)
[コスト大事] Amazon Athena で S3 の大量オブジェクトをクエリする場合はスキャン量だけでなくリクエスト量も意識しよう
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コンバンハ、千葉(幸)です。
みなさん、Amazon Athena(以降 Athena) 、使ってますか?
Athena を利用すれば Amazon S3(以降 S3) 上のデータに対してクエリを実行できます。S3 バケット上に出力された各種ログに対して Athena でクエリをかけて必要な情報を取得する、というのはよくある使い方です。
最近 S3 バケット上の AWS CloudTrail(以降 CloudTrail)ログを Atena でクエリしたい機会がありました。
「Athena ってデータをスキャンした量に応じて課金されるよな。1 TB スキャンして 5 USD くらいの料金だったよな。」という理解でいたので、1 USD もかからないくらいの料金でおさまるだろうと踏んでいました。
結果、15回強のクエリを行って約 20 USD のコストが発生しました。
スキャン量だけを気にするのではいけないんだな〜というのを学んだので、このブログで残しておきます。
先にまとめ
- Athena のクエリに伴い S3 オブジェクトへの Get リクエストが発生する
- Athena のクエリ実行に付随して発生する S3 へのアクセスは S3 の標準料金で課金される(ストレージ、リクエスト、データ転送)
- 大量の S3 オブジェクトをクエリする場合は S3 データイベントに関連する機能の有効化状況を意識しよう
- そもそもクエリ対象をなるべく絞ろう
Athena 実行時にはスキャン量だけでなくリクエスト量も意識
今回想定よりコストが膨らんだ要因は S3 へのリクエストが大量に発生したこと(その仕様を意識できていなかったこと)です。
具体的なコストの内訳としては S3 のリクエスト料金と Amazon GuardDuty(以降 GuardDuty)による S3 データイベント分析料金が一定量かかりました。
Athena のクエリに伴う料金発生の全体像は以下です。
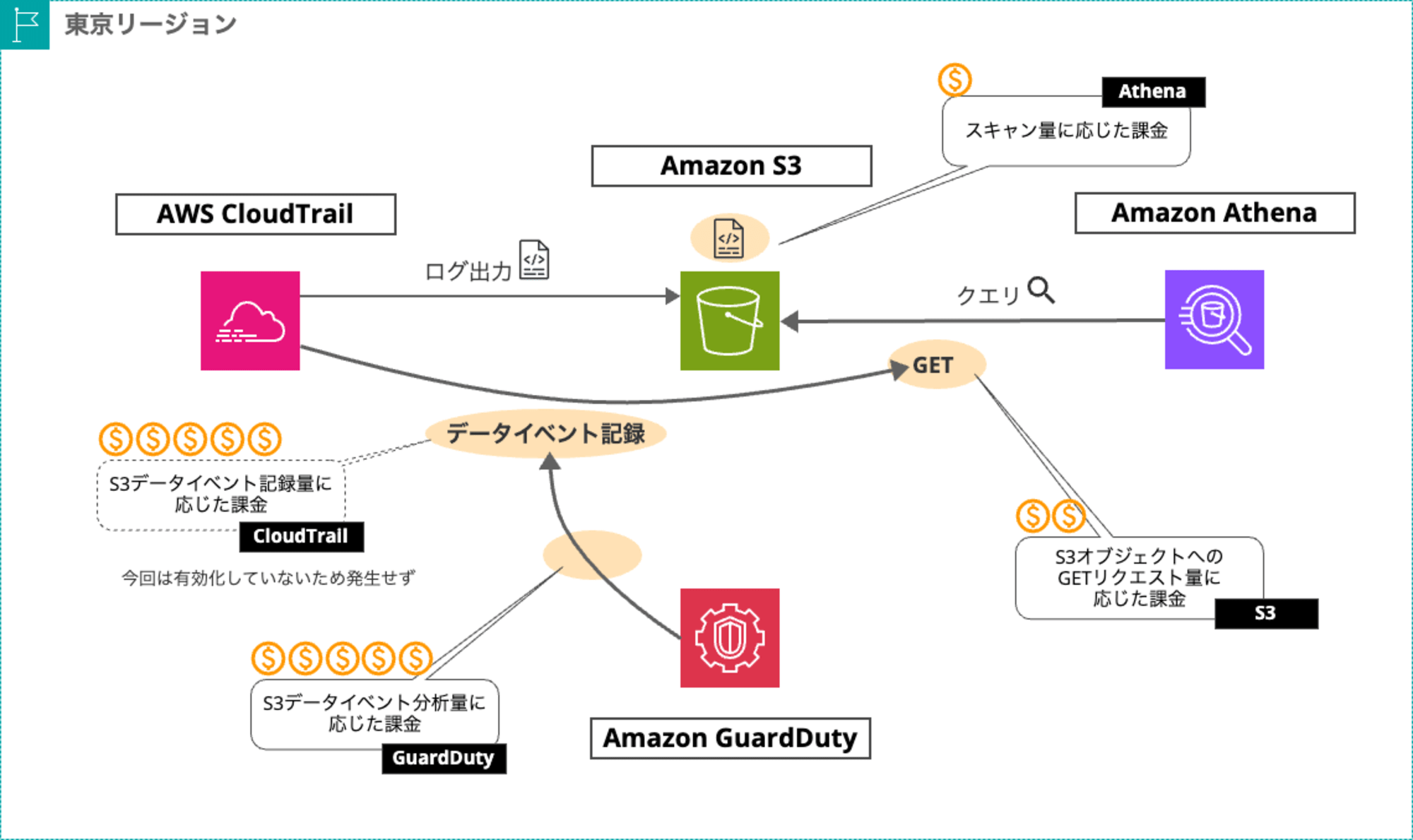
オレンジで表している部分がコスト発生箇所です
今回の料金内訳は以下の通りです。[1]
| # | サービス | タイプ | 説明 | 数量 | コスト(USD) |
|---|---|---|---|---|---|
| 1 | Athena | APN1-DataScannedInTB | 5.00 USD per Terabytes for DataScannedInTB in Asia Pacific (Tokyo) | 0.05 | 0.25 |
| 2 | S3 | APN1-Requests-Tier2 | $0.0037 per 10,000 GET and all other requests | 13,925,064 | 5.15 |
| 3 | GuardDuty | APN1-PaidS3DataEventsAnalyzed | $0.00000104 per S3 Data Event for the first 500000000 events / month analyzed in Asia Pacific (Tokyo) region | 13,923,408 | 14.48 |
意識していた Athena のスキャン量に応じた料金(#1)は想定通り 1 USD 以下に収まっていますが、それ以外の観点(#2,#3)でコストが嵩んでいます。
なお、#3は わたしの環境で GuardDuty S3 Protection 機能を明示的に有効化していたために発生した料金です。
発生しなかったけど発生する可能性があった料金
CloudTrail 証跡でデータイベントの記録を有効化していた場合、「配信されたデータイベント 100,000 あたり 0.10 USD」の料金がかかります。今回で言えば、Athena のクエリ対象である「CloudTrail ログが格納された S3 バケット」への S3 データイベントの記録を有効化していたらさらに料金がかかっていたということです。
#2,#3 と同等の約 1390万件の S3 オブジェクトの Get が記録された場合、13.9 USD が発生していたことになります。
今回実行した Athena によるクエリの背景/補足
CloudTrail ログが格納された S3 バケット
今回は以下の前提で S3 バケットへのログ出力がなされていました。
- 東京リージョンの CloudTrail 証跡からマルチリージョン証跡として S3 バケットへログ出力
- S3 バケットではライフサイクルルールが設定されており、400日を超過したログは削除される
- (S3 オブジェクトはすべて標準ストレージクラス)
つまり、過去 400 日間のすべての(有効な)リージョンの CloudTrail ログが S3 バケット上に格納されていた状態です。
S3 バケット上のデータを簡便に「メトリクス」から確認すると、約 100万のオブジェクトがあり、合計約 3.7 GB のサイズとなっていました。
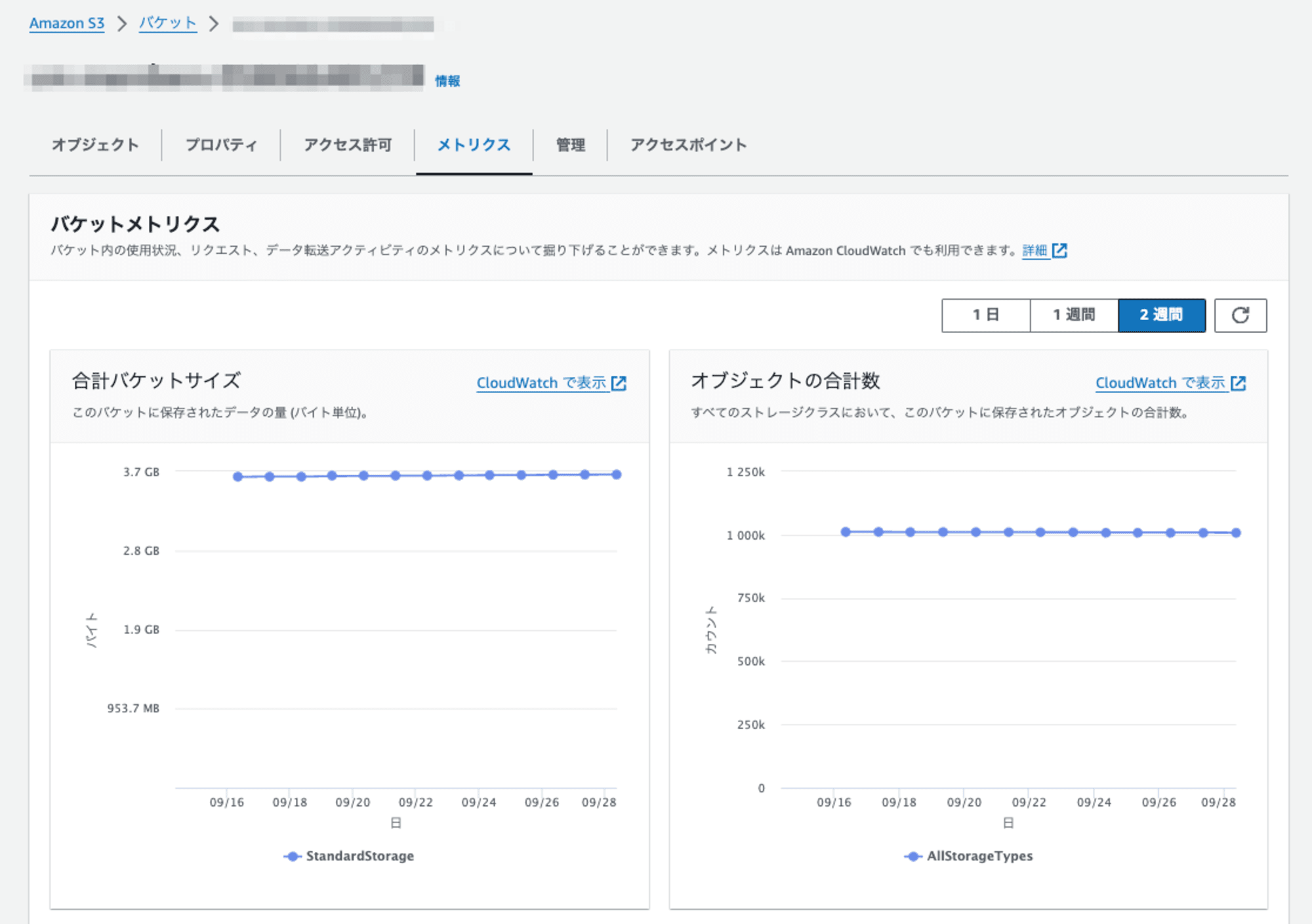
このバケットには CloudTrail ログ以外のデータも含まれているので、Athena のスキャン対象に絞って確認すると、以下の通り(オブジェクト数 約 83.7万、サイズ 3.3 GiB)となりました。[2]
aws s3 ls S3バケット名/AWSLogs/000000000000/CloudTrail/ \
--recursive --summarize --human-readable\
> /tmp/hoge.txt && tail -n 2 /tmp/hoge.txt
Total Objects: 837137
Total Size: 3.3 GiB
Athena テーブルの作成
今回の試行にあわせて新たに Athena テーブルの作成を行いました。
CloudTrail のコンソールより「Athena テーブルを作成」を選択し、CloudTrail ログが保管された S3 バケットを選択すると自動的にテーブル作成用のクエリが生成されます。
生成されたクエリの内容は以下で、今回はそのまま実行しました。
CREATE EXTERNAL TABLE cloudtrail_logs_バケット名 (
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
username: STRING>,
ec2RoleDelivery: STRING,
webIdFederationData: MAP<STRING,STRING>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
readOnly STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING,
tlsDetails STRUCT<
tlsVersion: STRING,
cipherSuite: STRING,
clientProvidedHostHeader: STRING>
)
COMMENT 'CloudTrail table for バケット bucket'
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://バケット名/AWSLogs/000000000000/CloudTrail/'
TBLPROPERTIES ('classification'='cloudtrail')
下から2行目のLOCATIONでプレフィックスを具体的に指定すればスキャン対象を限定できます。
Athena によるクエリの実行履歴
今回の一連の試行において実行したクエリの内訳は以下のとおりです。(テーブルを作る/作り直すという本筋に関係ない情報が含まれていたり、SQL の書き方の不備で何度も FAILED になっているのはご愛嬌です。)
| # | クエリ種別 | ステータス | 実行時間 | スキャンしたデータ |
|---|---|---|---|---|
| 1 | CREATE EXTERNAL TABLE | FAILED | 1.932 sec | 0 MB |
| 2 | SELECT | FAILED | 364 ms | 0 MB |
| 3 | SELECT | FAILED | 186 ms | 0 MB |
| 4 | SELECT | FAILED | 160 ms | 0 MB |
| 5 | DROP TABLE | SUCCEEDED | 552 ms | 0 MB |
| 6 | DROP TABLE | SUCCEEDED | 576 ms | 0 MB |
| 7 | CREATE EXTERNAL TABLE | SUCCEEDED | 408 ms | 0 MB |
| 8 | SELECT | SUCCEEDED | 6 sec | 48.02 KB |
| 9 | SELECT | FAILED | 188 ms | 0 MB |
| 10 | SELECT | SUCCEEDED | 1 min 47.289 sec | 3.31 GB |
| 11 | SELECT | SUCCEEDED | 1 min 48.573 sec | 3.31 GB |
| 12 | SELECT | SUCCEEDED | 1 min 50.459 sec | 3.31 GB |
| 13 | SELECT | SUCCEEDED | 1 min 50.906 sec | 3.31 GB |
| 14 | SELECT | FAILED | 181 ms | 0 MB |
| 15 | SELECT | FAILED | 178 ms | 0 MB |
| 16 | SELECT | FAILED | 176 ms | 0 MB |
| 17 | SELECT | FAILED | 189 ms | 0 MB |
| 18 | SELECT | SUCCEEDED | 1 min 48.229 sec | 3.31 GB |
| 19 | SELECT | SUCCEEDED | 1 min 44.209 sec | 3.31 GB |
| 20 | SELECT | FAILED | 339 ms | 0 MB |
| 21 | SELECT | CANCELLED | 5.183 sec | 0 MB |
| 22 | SELECT | SUCCEEDED | 1 min 59.338 sec | 3.31 GB |
| 23 | SELECT | FAILED | 179 ms | 0 MB |
| 24 | SELECT | CANCELLED | 5.511 sec | 0 MB |
| 25 | SELECT | CANCELLED | 48.695 sec | 1.59 GB |
| 26 | SELECT | FAILED | 160 ms | 0 MB |
| 27 | SELECT | CANCELLED | 1.178 sec | 0 MB |
| 28 | SELECT | FAILED | 251 ms | 0 MB |
| 29 | SELECT | FAILED | 169 ms | 0 MB |
| 30 | SELECT | SUCCEEDED | 1 min 41.431 sec | 3.31 GB |
| 31 | SELECT | SUCCEEDED | 1 min 44.662 sec | 3.31 GB |
| 32 | SELECT | SUCCEEDED | 1 min 40.542 sec | 3.31 GB |
| 33 | SELECT | SUCCEEDED | 1 min 51.53 sec | 3.31 GB |
| 34 | SELECT | SUCCEEDED | 1 min 44.747 sec | 3.31 GB |
| 35 | SELECT | SUCCEEDED | 1 min 46.178 sec | 3.31 GB |
| 36 | SELECT | SUCCEEDED | 1 min 38.994 sec | 3.31 GB |
| 37 | SELECT | SUCCEEDED | 1 min 45.633 sec | 3.31 GB |
| 38 | SELECT | SUCCEEDED | 1 min 47.959 sec | 3.31 GB |
基本的に SELECT では S3 バケット上の CloudTrail ログをすべて対象にスキャンしました。(なるべく対象を絞るべきではあるのですが、スキャン量しか意識していなかったので、クエリの内容を細かく考えるよりは全体指定でやっちゃおうという精神でした。)
全量をスキャンした場合は以下の結果になります。
- スキャンしたデータサイズ 3.31 GB
- 所要時間 1分40秒程度(長いなと思いながら律儀に待ちました)
途中でキャンセルしたものを0.5回とカウントすると、全量スキャンを行ったのは16.5回です。今回の一連の Athena クエリの試行の中で以下が行われました。
- 約 54.6 GB のスキャン(3.31 GB * 16.5)
- 約 1,380万回の GET リクエスト(約 83,700オブジェクト * 16.5)
Athena のクエリによって発生した料金の確認
Athena によるクエリを実行した数日後、AWS 管理コンソールの請求画面や CUR(AWS Cost and Usage Reports)をベースにした情報から料金を確認しました。
冒頭の再掲となりますが、以下の内訳となっていました。
| サービス | タイプ | 説明 | 数量 | コスト(USD) |
|---|---|---|---|---|
| Athena | APN1-DataScannedInTB | 5.00 USD per Terabytes for DataScannedInTB in Asia Pacific (Tokyo) | 0.05 | 0.25 |
| S3 | APN1-Requests-Tier2 | $0.0037 per 10,000 GET and all other requests | 13,925,064 | 5.15 |
| GuardDuty | APN1-PaidS3DataEventsAnalyzed | $0.00000104 per S3 Data Event for the first 500000000 events / month analyzed in Asia Pacific (Tokyo) region | 13,923,408 | 14.48 |
- Athena:50GB
- S3:約1,390万回
- GuardDuty:約1,390万回
……と、細部の数字のずれはありますが、ここまで試算した内容と一致しています。
Athena のスキャン量だけを意識していたわたしとしてはここでギョッとしました。
Athena のクエリにおける S3 リクエストの料金
Athena の料金ページには以下記述があります。
追加料金
Athena は、Amazon S3 から直接データをクエリ処理します。Athena によるデータのクエリ処理に対する追加のストレージ料金は発生しません。ストレージ、リクエスト、データ転送に対して S3 の標準料金が発生します。デフォルトでは、クエリ結果は選択した S3 バケットに保存され、S3 の標準料金が課金されます。
Athena のクエリ処理によって発生したストレージ、リクエスト、データ転送は S3 の標準料金で課金されます。
今回はストレージ、データ転送は無視できる程度の課金でしたが、対象オブジェクトが多かったためにリクエスト料金が嵩みました。
GuardDuty による S3 データイベント分析
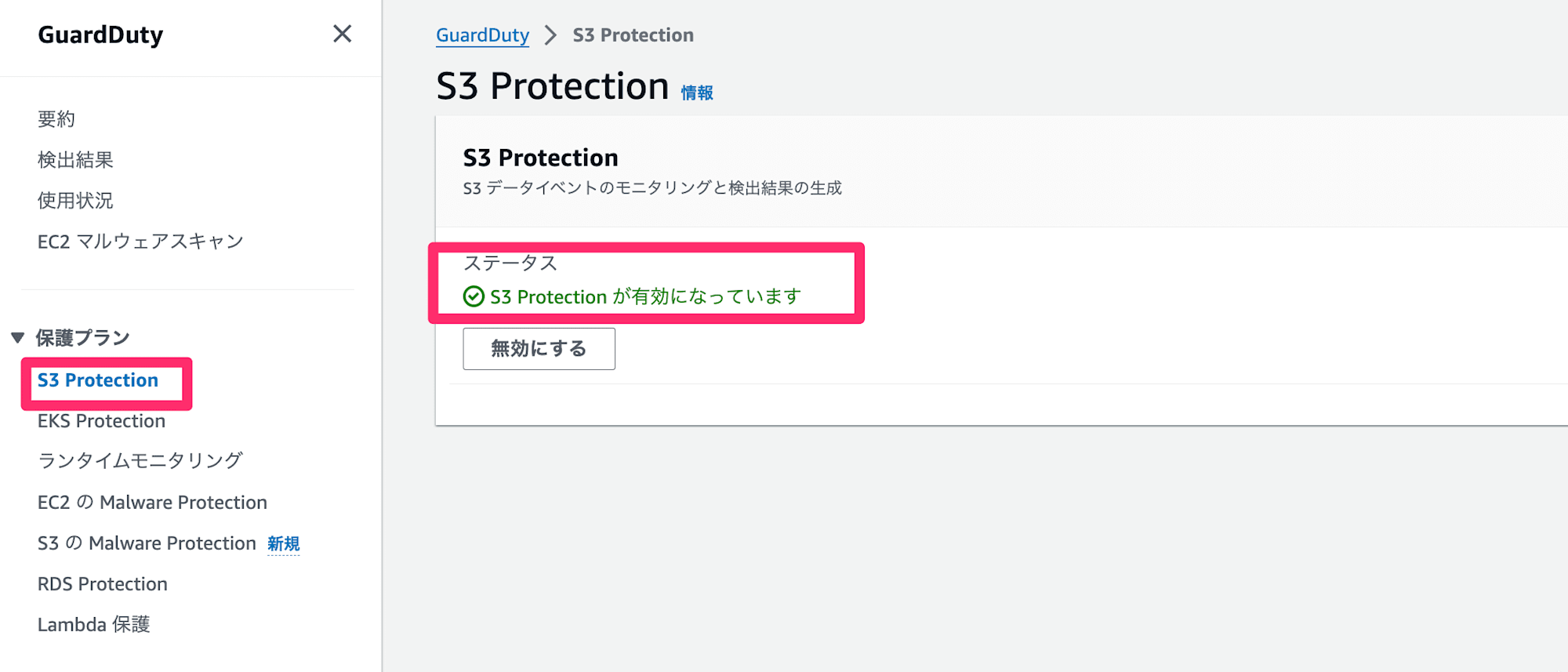
GuardDuty S3 Protection 機能を有効化すると、GuardDuty による S3 のデータイベント分析が行われます。(利用者側で CloudTrail 証跡のデータイベント記録を有効化する必要はありません。)
S3 Protection が有効になっているかは GuardDuty コンソールの以下画面から確認できます。
また、「使用状況」より GuardDuty コストの発生内訳が確認できます。
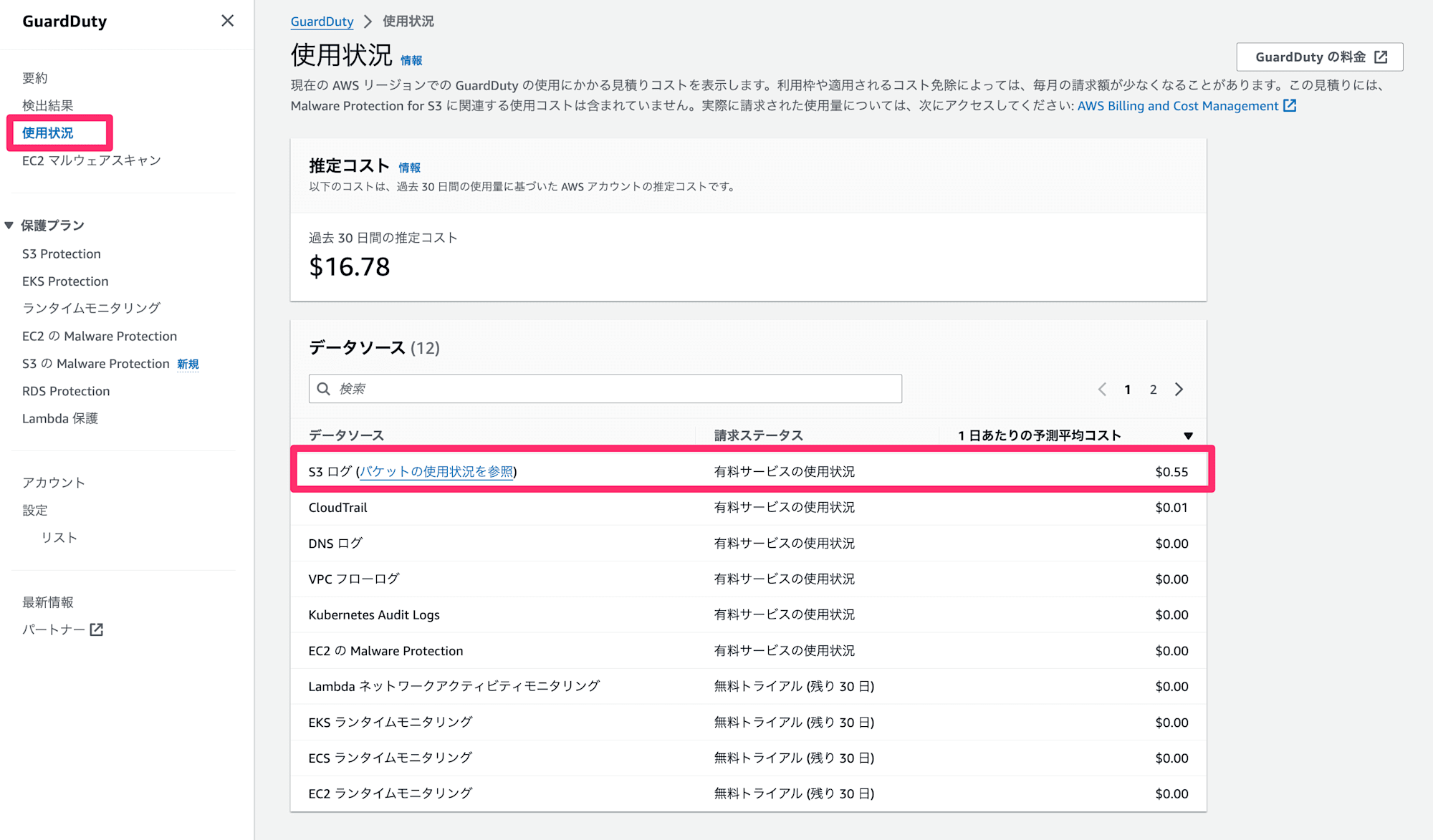
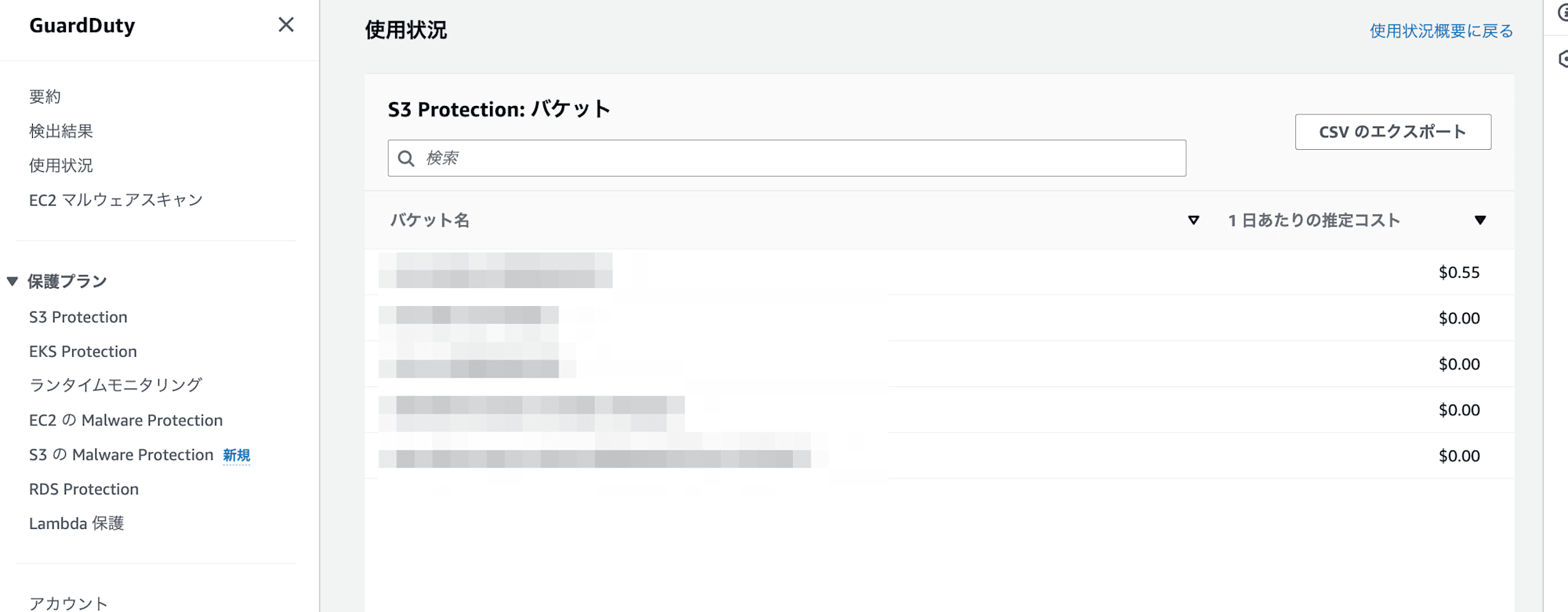
S3 バケットごとの内訳も確認できます。今回は Athena のクエリ実行対象の S3 バケットで料金が嵩んでいることが確認できました。
Athena による料金の発生を抑えるには?
今回のコスト発生の大きな要因は以下のとおりです。
- スキャン対象にした S3 オブジェクトが大量である
- スキャン対象が広い
- 何度も試行している
- S3 データイベント量に応じた課金が発生する機能を有効化していた
もし GuardDuty S3 Protection を有効化しておらず、かつ全量スキャンの試行を 5回程度に抑えていれば発生コストは2ドル程度でした。特に気に掛けるようなボリュームではありません。
とは言え、スキャン対象を適切な範囲にする、というのは常日頃から意識しておきべきです。以下のような取り組みで必要最小限の範囲へのクエリを行うようにしましょう。
- テーブル作成時にプレフィックスを限定する
- データのパーティション化 を行う
また、S3 データイベントに関連した機能の有効化状況も押さえておきましょう。Athena クエリ実行のために機能のオン/オフをする必要はないでしょうが、「意図せずまとまった課金発生」は避けたいところです。
- CloudTrail 証跡でのデータイベント記録
- GuardDuty による S3 データイベント分析
まとめ(再掲)
- Athena のクエリに伴い S3 オブジェクトへの Get リクエストが発生する
- Athena のクエリ実行に付随して発生する S3 へのアクセスは S3 の標準料金で課金される(ストレージ、リクエスト、データ転送)
- 大量の S3 オブジェクトをクエリする場合は S3 データイベントに関連する機能の有効化状況を意識しよう
- そもそもクエリ対象をなるべく絞ろう
Athena 実行時の料金に注意
Amazon Athena によるクエリで想定外に料金がかかった、という話でした。
突き詰めて考えると、以下の部分をきちんと押さえられていなかったな、という点に尽きます。
Athena は、Amazon S3 から直接データをクエリ処理します。Athena によるデータのクエリ処理に対する追加のストレージ料金は発生しません。ストレージ、リクエスト、データ転送に対して S3 の標準料金が発生します。 デフォルトでは、クエリ結果は選択した S3 バケットに保存され、S3 の標準料金が課金されます。
「Athena 実行時にはスキャン量だけじゃなくてリクエスト量も意識しておかないとコストが膨らむことがある」という点だけ伝わっていれば幸いです。
以上、チバユキ (@batchicchi)がお送りしました。
参考
- 料金 - Amazon Athena | AWS
- 料金 - Amazon GuardDuty | AWS
- 料金 - Amazon S3 |AWS
- 料金 - AWS CloudTrail | AWS
- Athena のパフォーマンスを最適化する - Amazon Athena










