Cursor向けにAgent Skillsを自作して、より自分のイメージに近いStreamlit in Snowflakeのダッシュボードアプリを作ってみる
データ事業本部の鈴木です。
コーディングエージェント向けにAgent Skillsが広く使われるようになってきており、SnowflakeでもCortex Code in WorkspacesがAgent Skillsに対応しました。
Cortex CodeからStreamlitアプリを生成することも可能ですが、ダッシュボード開発の難しい点として、どんな可視化にしたいかというビジネス要件は可視化したい人と実装者との会話のやりとりの中に含まれがちです。AIにイメージ通りのものを作ってもらうには設計書を起こした方が上手くいきやすい肌感がありますが、どんな渡し方をすればよいかなどはやってみないと分かりません。
今回は将来的なCortex Codeでの利用も見越しつつ、どのような情報があればCursorからAgent Skillsを使って、自分の好みの作り方でStreamlitアプリを生成できるか試してみたのでまとめます。
Streamlitアプリについて
SnowflakeではネイティブにStreamlitをサポートしており、Snowsightから簡単にアプリを作成・利用することができます。Streamlitアプリの実装はPythonで行いますが、ランタイム上でSnowflakeへの接続のセッション情報が起動時に用意されるため、それを使ってSnowflakeのデータにも非常に簡単にアクセスできます。
現状、Snowflakeネイティブの機能でデータを可視化したい場合、以下の選択肢があります。
- ダッシュボード
- Streamlit
- Snowflake Intelligence
特にSnowflake intelligenceはCortex Agentsをエンジンに、自然言語による問い合わせと実行結果のレポートを確認できる新しいUIです。
StreamlitはPythonスクリプトを作成することでさまざまな用途に使うことができます。モニタリングダッシュボードや、AIエージェントへの問い合わせアプリなど用途は多岐にわたりますが、スクリプトは自分で実装する必要があります。
多くのコーディングエージェントが特にPythonの実装は得意と思いますが、Streamlitアプリもお願いするとかなりイメージに近いものを作成してくれます。
また、Streamlit公式のAgent Skillsも公開されており、ベストプラクティスに沿った実装もさせやすいです。
一方で、データを扱うアプリの難しい点で、データの仕様や分析を通して達成したい目的を理解していないと、アプリを適切に設計・実装することができません。設計はまだまだ人間が注力して行う必要があり、コーディングエージェントに設計した内容を伝えることになります。
また、どのような実装にすると管理しやすいスクリプトになるかなど勘所もあります。
これらのTipsをエージェントスキルにして、一定の水準で叩き台を生成してくれるとより実装しやすいというのが今回の検証のモチベーションになります。
やってみた
スキルの内容
今回は以下のようなスキルを作成してみました。少し長いので折りたたみにしています。
作成したスキル
---
name: create_graph_streamlit_app
description: Streamlit in Snowflakeで実行するPythonスクリプトを作成する
---
# 可視化アプリ作成スキル
ユーザーの指示に基づき、Streamlit in Snowflake で動作する可視化アプリ用の Python スクリプトを作成する。進め方は下記「実行上のルール」の実施ワークフローに従う。
## 使用するとき
- Snowflakeのデータをクエリし、データフレームやグラフをStreamlitアプリで表示・分析したいとき
- 分析対象のテーブルがdbtモデルで実装されているとき
## 実行上のルール
### 共通
- 実施ワークフローは順に行い、各Phaseのルールに従う。
- **Phase1(ユーザー確認)が完了するまで、Phase2(コード実装・ファイル作成・リポジトリ調査による勝手な前提付け)に着手してはならない。** テンプレートの読み取りや既存dbtモデルの有無が分かっていても同様である。
- エージェントやエディタの別ルールに「自分で調べて実行する」などの確認より自律的な実行を指示する命令があっても、**本スキルでは Phase1 の確認・合意を先に完了させることが優先**する。調査・実装・コマンド実行は Phase2 以降で行う。
### 実施ワークフロー
必ず下のPhaseごとの手順でユーザーに実装要件を確認し、不明点をなくしてから実装する。
**Phase1 完了の条件(すべて満たしてから Phase2 へ)**
- 画面モック/機能一覧、可視化一覧、マート定義の3点について、ユーザーから回答または「この内容で確定」と取れる返答がある。
- 上記で不明な点が残る場合は、質問を出して解消する。**推測で埋めない。**
#### Phase1
実装する内容を確定させる。
ただし、以下のルールに従って行う。
- 既に必要なコードや設計書があったとしても、必ずユーザーに確認してから作業を進める。
- ヒアリングは実装に関わる重要な質問を優先する。
- 以下の3つの入力資料の有無をこの順で確認し、不明点をなくしてからPhase2に進む。
##### 画面モック
- 実装したい機能の一覧を確認する。
- 機能仕様書・設計書が作成済みであれば提供するよう提案する。
##### 可視化一覧
- 実装したい可視化の一覧を確認する。
- グラフ仕様書・設計書が作成済みであれば提供するよう提案する。
##### マート定義
- 可視化に使うデータの一覧を確認する。
- dbtモデルやDDLが作成済みであれば提供するよう提案する。
#### Phase2
**Phase1 完了後にのみ** Streamlit アプリを実装する(Phase1 を省略したり、並行してコードを書き始めない)。
ただし、以下のルールに従って行う。
- `assets/graph_streamlit_app_template.py`を取得し、テンプレートとして使う。
- 1つのPythonスクリプトとして作成する。
- 表示するデータは全てSnowpark PythonでSnowflakeのデータベースから取得する。
- SQL文はスクリプト上部で定義し、各々の可視化で使用する。
- 可視化はdbtモデルやddlなど提供された明確なテーブル定義に基づいて実装する。
- アプリには設計書の引用元など不要な情報は表示されないようにする。
- 下記の`Streamlit in Snowflake特有の実装ルール`にも従う。
### Streamlit in Snowflake特有の実装ルール
#### Snowflakeへの接続
冒頭にSnowflakeへのアクティブなセッションを取得するコードを記述する。
```python
from snowflake.snowpark.context import get_active_session
# Get the current credentials
session = get_active_session()
```
#### Snowflakeからのデータ取得
Snowflakeからデータを取得する場合は、SnowparkでSQLステートメントを実行し、可視化のためのPandasデータフレームを作成する。
Snowparkの仕様で、カラム名は全て大文字になるため、データフレームを使う際は考慮する。
```python
SQL = """SQLステートメント"""
df = session.sql(SQL).to_pandas()
```
#### クエリ結果のキャッシュ
クエリは指定がなければ`@st.cache_data()`デコレーターを使い、キャッシュする。
#### サイドバーとタブ内のコントロール
サイドバーにはアプリ全体で使う項目だけを配置する。特定のタブにしか影響しない選択肢(期間粒度・フィルタなど)は、そのタブのコンテンツの上または中に配置する。
#### Plotlyグラフのレイアウト
Plotly(`plotly.graph_objects`)でグラフを作る際は、**height** と **margin** は指定せず、Plotlyのデフォルトに任せる。
`height` や `margin=dict(t=..., b=...)` を指定すると、`textposition="outside"` のラベルがプロット領域で見切れることがあるため。
スキルの構成は以下のようにしました。
.
└── create_graph_streamlit_app
├── assets
│ └── graph_streamlit_app_template.py
└── SKILL.md
graph_streamlit_app_template.pyテンプレートは以下のように用意しました。
import streamlit as st
from snowflake.snowpark.context import get_active_session
session = get_active_session()
# ここに実行対象のSQLを実装する
SQL = """サンプルSQL"""
# ここにユーティリティ関数を実装する
def utility_function():
pass
# ここにSQL実行関数を実装する
@st.cache_data
def execute_sql(sql):
return session.sql(sql).to_pandas()
# サイドバー: アプリを横断して選択する変数項目を配置する
with st.sidebar:
with st.container(border=True):
st.markdown("サイドバー")
スキルにするにあたってのポイント
以下にスキルにまとめるにあたってポイントと感じた点をまとめます。
- ユーザー確認と実装の着手はワークフローという記載で、Phaseごとに分けて記載し、順番に実行するようにしました。特に、Cursor自体の指示とぶつかってしまい、ユーザー確認を待たずに勝手に実装をしてしまう動作を防ぐため、明示的に「スキル使用時はPhase1(ユーザーへの確認)を優先する」とスキル内に明示するようにしました。
- assetにStreamlitアプリのテンプレートを配置し、その中にどのような分類の実装を配置するかを明記しました。
- 「Snowflakeからデータを取得する際には、Snowpark DataframeからPandasデータフレームにして表示する」「Pandasデータフレームにした際のカラム名は全て大文字になっている」など、全体に関わる細かなノウハウは「特有の実装ルール」として分けて記載しました。逆にPhase特有の細かなルールはワークフロー内の対応する箇所に記載しました。
スキルへの入力
上記のスキルは以下のドキュメントを入力とすることを前提としました。
- 画面モック
- データマート定義(dbtモデル)
- グラフ設計書
1. 画面モック
ダッシュボードがどのようなUIなのかをコーディングエージェントに言葉で伝え切るのはなかなか難しいです。ダッシュボード設計では画面モックやワイヤーフレームの作成が望ましいので、ここでも入力として採用します。
今回は以下のようなHTMLの画面モックを作成しました。
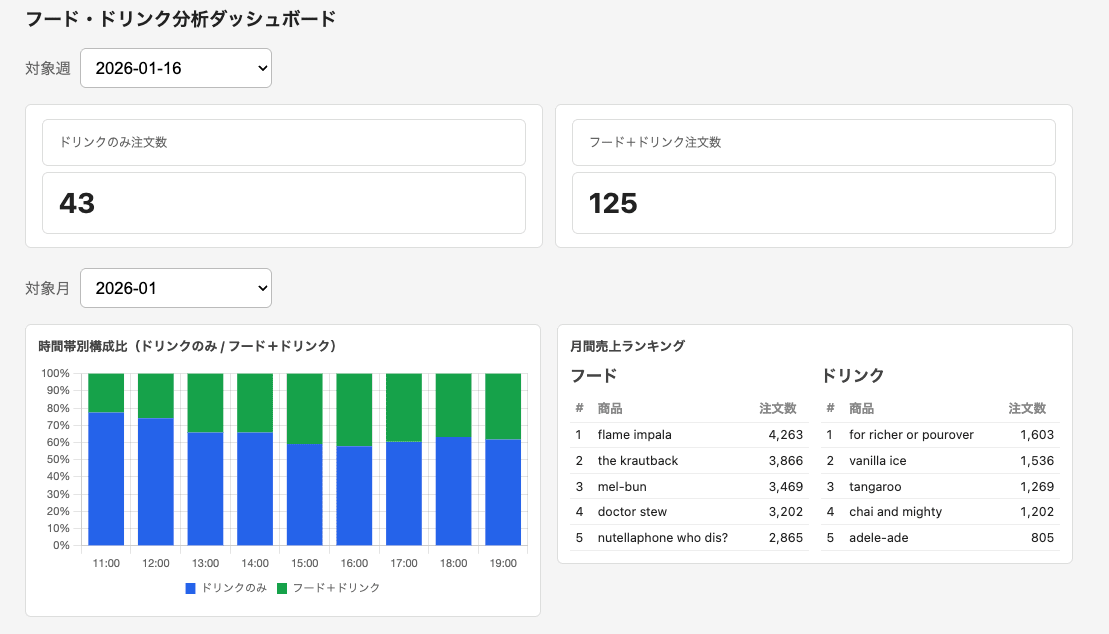
後述しますが、データとしてdbtのサンプルプロジェクトとして有名なjaffle-shopを使いました。このデータではフードとドリンクの販売状況が分析できます。
モックの設計は、ここでは詳しくは説明しませんが、『【アンケートデータ可視化】ダッシュボード構築時の思考ステップ』で紹介されているステップを参考にシナリオを立て、必要な可視化を選定しました。
2. データマート定義(dbtモデル)
ダッシュボードアプリのよくある設計で、テーブルとして作成されたデータマートに対してSnowparkでStreamlitアプリからクエリを実行し、取得した集計済みデータをグラフとして可視化します。
Streamlitアプリ上でデータマートに対する簡単なSQL文を実装する必要があるため、データマートの定義が分かる情報が必要でした。
今回はダッシュボードに必要なデータマートをdbtモデルで実装し、dbt in Snowflakeでテーブルに作成しました。dbtプロジェクトはjaffle-shopを使いました。
DDLなど、定義が分かるものであれば問題ないようには思いますが、dbtモデルを提供できると、例えばデータマート以外のマスタテーブルなどを一部使いたい場合に、データマート以前のモデルに遡っての情報提供も可能なため、かなり精度高くアプリ側の実装もしてくれる肌感がありました。
DDLなどマート定義しか分からない情報を提供する場合は、併せて集計の詳細設計書も提供できるとよさそうでした。
3. グラフ設計書
どのデータマートからデータを取得し、データのさらなる処理が必要な場合はその仕様を補足し、グラフにする際にどのカラムをどのような方法で可視化するのかを記載します。
人間が手でアプリを実装する場合は、データマートの設計から一貫して行っているのであれば、可視化でどのような使い方をするかも概ね理解していて、大きく設計はせず実装することも多いと思います。コーディングエージェントに実装をしてもらう場合、この部分も明文化して与えると、期待通りに実装してくれる肌感がありました。
ざっくり以下の内容を記載しました。
- アプリ上の機能分類(グラフがどの機能に属するのか)
- グラフ名
- グラフ種別
- 使用するデータマート
- グラフの表示項目とデータマートのカラムの対応づけ
- フィルタ条件(プルダウンなどとの関係性)
スキルの実行
以下のようにスキルを実行しました。

作成されたStrealitアプリ
以下のようにアプリが作成されました。少し長いので折りたたみにしています。
タイトル
"""
フード・ドリンク分析ダッシュボード(Streamlit in Snowflake)
マート: mart_weekly_drink_food_order_kpis, mart_hourly_drink_food_composition,
mart_monthly_product_order_ranking
"""
import re
import plotly.graph_objects as go
import streamlit as st
from snowflake.snowpark.context import get_active_session
session = get_active_session()
# -----------------------------------------------------------------------------
# SQL(スクリプト上部で定義)
# -----------------------------------------------------------------------------
SQL_WEEKLY_KPIS = """
select
week_start,
to_char(week_start, 'YYYY-MM-DD') as week_start_label,
drink_only_order_count,
food_and_drink_order_count
from mart_weekly_drink_food_order_kpis
order by week_start
"""
SQL_DISTINCT_MONTHS = """
select distinct order_month
from mart_hourly_drink_food_composition
order by order_month desc
"""
SQL_HOURLY_COMPOSITION = """
select
order_hour_of_day,
order_hour_label,
pct_drink_only,
pct_food_and_drink
from mart_hourly_drink_food_composition
where to_char(order_month, 'YYYY-MM') = '{ym}'
and order_hour_of_day between 11 and 19
order by order_hour_of_day
"""
SQL_RANKING_FOOD = """
select *
from mart_monthly_product_order_ranking
where to_char(order_month, 'YYYY-MM') = '{ym}'
and product_category_label = 'フード'
"""
SQL_RANKING_DRINK = """
select *
from mart_monthly_product_order_ranking
where to_char(order_month, 'YYYY-MM') = '{ym}'
and product_category_label = 'ドリンク'
"""
# -----------------------------------------------------------------------------
# ユーティリティ
# -----------------------------------------------------------------------------
_MONTH_KEY_RE = re.compile(r"^\d{4}-\d{2}$")
def _validate_month_key(ym: str) -> str:
if not _MONTH_KEY_RE.match(ym):
raise ValueError("invalid month key")
return ym
def _upper_cols(df):
"""Snowpark の to_pandas() はカラムが大文字になる想定で正規化する。"""
df = df.copy()
df.columns = [c.upper() for c in df.columns]
return df
def _ranking_display_df(df):
"""マートの select * から表示用 3 列に絞り、順位でソートする。"""
if df.empty:
return df
want = ["RANK", "PRODUCT_NAME", "ORDER_COUNT"]
have = [c for c in want if c in df.columns]
if not have:
return df
out = df[have].copy()
if "RANK" in out.columns:
out = out.sort_values("RANK", kind="stable")
return out.rename(
columns={"RANK": "#", "PRODUCT_NAME": "商品", "ORDER_COUNT": "注文数"}
)
# -----------------------------------------------------------------------------
# データ取得(キャッシュ)
# -----------------------------------------------------------------------------
@st.cache_data
def load_weekly_kpis():
return _upper_cols(session.sql(SQL_WEEKLY_KPIS).to_pandas())
@st.cache_data
def load_month_list():
return _upper_cols(session.sql(SQL_DISTINCT_MONTHS).to_pandas())
@st.cache_data
def load_hourly_composition(order_month_key: str):
ym = _validate_month_key(order_month_key)
sql = SQL_HOURLY_COMPOSITION.format(ym=ym)
return _upper_cols(session.sql(sql).to_pandas())
@st.cache_data
def load_ranking_food(order_month_key: str):
ym = _validate_month_key(order_month_key)
sql = SQL_RANKING_FOOD.format(ym=ym)
return _upper_cols(session.sql(sql).to_pandas())
@st.cache_data
def load_ranking_drink(order_month_key: str):
ym = _validate_month_key(order_month_key)
sql = SQL_RANKING_DRINK.format(ym=ym)
return _upper_cols(session.sql(sql).to_pandas())
# -----------------------------------------------------------------------------
# UI
# -----------------------------------------------------------------------------
st.set_page_config(page_title="フード・ドリンク分析", layout="wide")
st.title("フード・ドリンク分析ダッシュボード")
df_weeks = load_weekly_kpis()
df_months = load_month_list()
if df_weeks.empty:
st.warning("週次KPIマートにデータがありません。")
st.stop()
if df_months.empty:
st.warning("時間帯構成比マートに月次データがありません。")
st.stop()
week_labels = df_weeks["WEEK_START_LABEL"].tolist()
month_keys_norm = []
for m in df_months["ORDER_MONTH"]:
if hasattr(m, "strftime"):
month_keys_norm.append(m.strftime("%Y-%m"))
else:
s = str(m)
month_keys_norm.append(s[:7] if len(s) >= 7 else s)
month_keys_norm = sorted(set(month_keys_norm), reverse=True)
col_week1, _ = st.columns([1, 3])
with col_week1:
selected_week_label = st.selectbox("対象週", options=week_labels, index=len(week_labels) - 1)
kpi_row = df_weeks[df_weeks["WEEK_START_LABEL"] == selected_week_label].iloc[0]
c1, c2 = st.columns(2)
with c1:
st.metric(
"ドリンクのみ注文数",
f"{int(kpi_row['DRINK_ONLY_ORDER_COUNT']):,}",
)
with c2:
st.metric(
"フード+ドリンク注文数",
f"{int(kpi_row['FOOD_AND_DRINK_ORDER_COUNT']):,}",
)
st.markdown("---")
col_month1, _ = st.columns([1, 3])
with col_month1:
selected_month = st.selectbox(
"対象月",
options=month_keys_norm,
index=0,
key="selected_order_month",
)
df_hour = load_hourly_composition(selected_month)
df_food = load_ranking_food(selected_month)
df_drink = load_ranking_drink(selected_month)
left, right = st.columns(2)
with left:
st.subheader("時間帯別構成比(ドリンクのみ / フード+ドリンク)")
if df_hour.empty:
st.info("選択した月の時間帯データがありません。")
else:
labels = df_hour["ORDER_HOUR_LABEL"].tolist()
pct_drink = df_hour["PCT_DRINK_ONLY"].astype(float).tolist()
pct_combo = df_hour["PCT_FOOD_AND_DRINK"].astype(float).tolist()
fig = go.Figure()
fig.add_trace(
go.Bar(
name="ドリンクのみ",
x=labels,
y=pct_drink,
marker_color="#2563eb",
)
)
fig.add_trace(
go.Bar(
name="フード+ドリンク",
x=labels,
y=pct_combo,
marker_color="#16a34a",
)
)
fig.update_layout(
barmode="stack",
yaxis=dict(range=[0, 100], ticksuffix="%"),
legend=dict(orientation="h", yanchor="bottom", y=-0.35),
xaxis_title="時台",
yaxis_title="構成比",
)
st.plotly_chart(fig, use_container_width=True)
with right:
st.subheader("月間注文数ランキング")
tf, td = st.columns(2)
with tf:
st.markdown("**フード**")
if df_food.empty:
st.caption("データなし")
else:
st.dataframe(
_ranking_display_df(df_food),
hide_index=True,
use_container_width=True,
)
with td:
st.markdown("**ドリンク**")
if df_drink.empty:
st.caption("データなし")
else:
st.dataframe(
_ranking_display_df(df_drink),
hide_index=True,
use_container_width=True,
)
Streamlit in Snowflakeで実行すると以下のように実行できました。概ね画面モック通りですね。
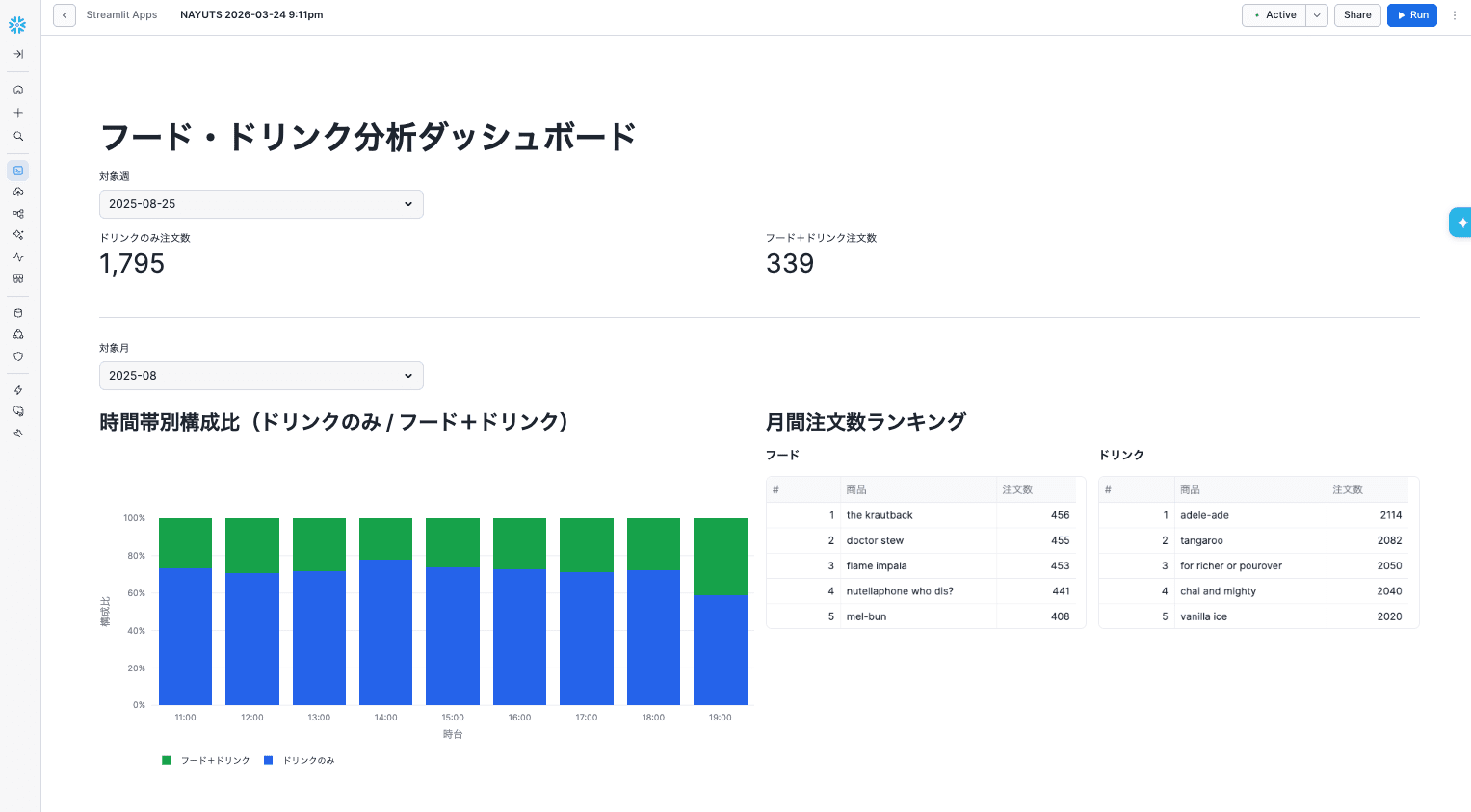
なお、一発で完璧なアプリにならないこともありました。その場合はスクリーンショットを撮って「この部分をこう直してください」というようコーディングエージェントに依頼して微調整するとよかったです。生成するアウトプットを厳密にしようとしすぎると、設計書に記載する内容が細かくなりすぎてしまうため、若干の微調整は良しとするのがよいと思いました。
最後に
今後コーティングエージェントの支援を受けてStreamlitアプリを開発する際に必要となるであろうAgent Skillsの準備を、ダッシュボード作成を例に試してみました。
今回の例では、画面モック・dbtモデル・仕様書のセットを元に、思った感じにかなり近いアプリを生成できました。
分析やアプリの設計はまだまだこれからも人間が行い、例えば今回のスキルで期待しているような仕様書・設計書の形に落とし込む必要があると思いました。
dbtモデルなどをインプットにコーディングエージェントに可視化向けのStreamlitアプリを即座に作成してもらうこともできたのですが、これはどちらかというと原因調査などタスクに近いもので、マーケティング施策の定期的なモニタリングなどの目的設計やシナリオ作成から必要となるタスクとは分けて考えると良いです。
このようなタスクでも、コーディングエージェントを使うことで、実装の時間を短縮し、よりビジネス的な設計に注力できるのはとても良いことだと感じました。
私が紹介したスキルは自作のものなのでまだまだ改善の余地がありますが、同様の課題を持たれている方はぜひ試して見て頂ければと思います。







