![[AWS Glue]クローラーとジョブを組み合わせて、パーティション分割されたデータソースをパーティション分割したデータターゲットに追加するETLフローを作ってみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/aws-glue.png)
[AWS Glue]クローラーとジョブを組み合わせて、パーティション分割されたデータソースをパーティション分割したデータターゲットに追加するETLフローを作ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
AWS Glueでは、パーティション分割を行うことによりデータの整理や効率的なクエリ実行を行うことが可能です。
今回は、クローラーとジョブを組み合わせて、パーティション分割されたデータソースをパーティション分割したデータターゲットに追加するETLフローを作ってみました。
作るもの
- データソースに追加されたデータをもとにGlueテーブルにパーティションを追加するクローラー
- パーティション分割されたデータソースをパーティション分割したデータターゲットに追加するジョブ
これらクローラーとジョブで下記のようなワークフローを作成します。まずクローラーを実行し、正常に実行が完了したらジョブが実行されるようにします。
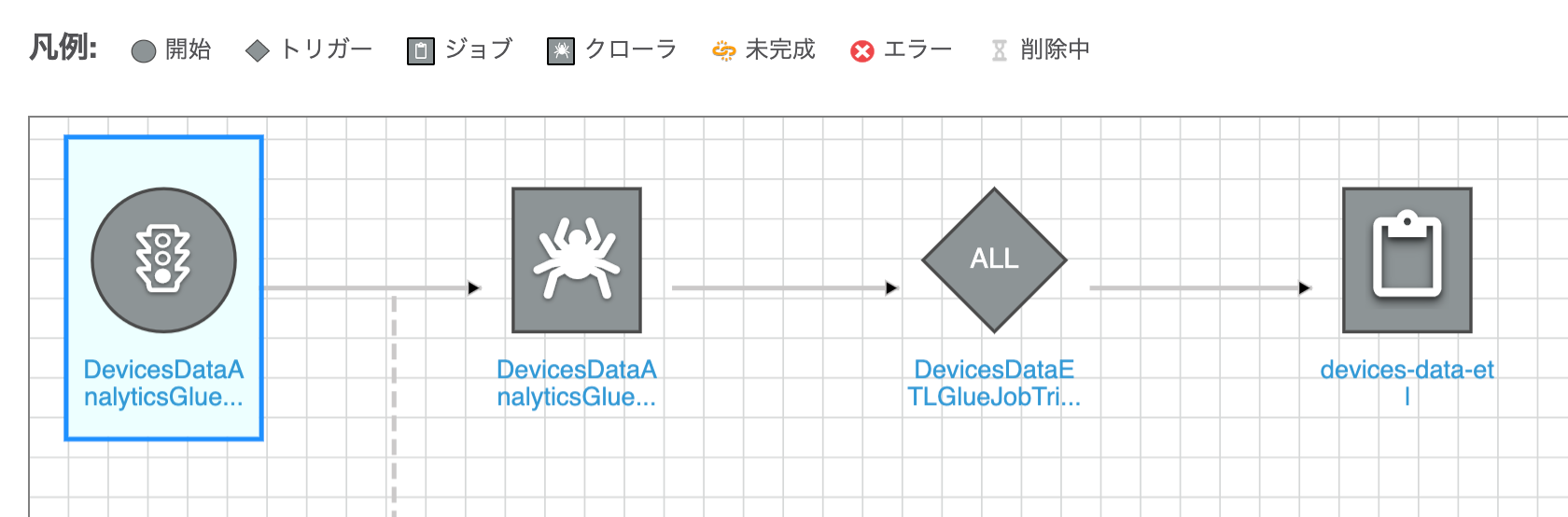
やってみた
まず最初に以降のコマンド実行で使用する変数を定義しておきます。
% AWS_REGION=ap-northeast-1
% ACCOUNT_ID=$(aws sts get-caller-identity | jq -r ".Account")
% RAW_DATA_BUCKET=s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}
% DATA_ANALYTICS_BUCKET=s3://devices-data-analytics-${ACCOUNT_ID}-${AWS_REGION}
% GLUE_DATABASE_NAME=devices_data_analystics
% RAW_DATA_GLUE_TABLE_NAME=devices_raw_data
% INTEGRATED_DATA_GLUE_TABLE_NAME=devices_integrated_data
% WORKFLOW_NAME=devices-analytics
% ATHENA_WORK_GROUP_NAME=devices-data-analytics
環境構築
動作確認環境を作成します。
CloudFormationスタック
CloudFormationスタックのテンプレートです。(長いため折りたたんでいます。)
クリックで展開
<div>
</div>
データターゲットへの書き込み時にGlueテーブルにパーティションを作成したい場合はジョブの実行ロールでglue:BatchCreatePartitionアクションを許可する必要があるため、リソース定義ExecuteDevicesDataETLGlueJobRoleで許可しています。
スタックをデプロイします。
% aws cloudformation deploy \
--template-file template.yaml \
--stack-name devices-data-analytics-stack \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset
Glueジョブスクリプト
データソースから取得したデータに対して、パーティションスキーマの値を使用したpartition_date列を追加し、データターゲットに書き込むPySparkスクリプトです。(長いため折りたたんでいます。)
クリックで展開
<div>
@
</div>
データターゲットへの書き込み時に指定のパーティションを作成する場合は、write_dynamic_frame.from_catalog()でadditional_optionsを下記のように指定します。
additionalOptions = {
"enableUpdateCatalog": True
}
additionalOptions['partitionKeys'] = [
'year', 'month', 'day'
]
glueContext.write_dynamic_frame.from_catalog(
frame = dyf,
database = args['GLUE_DATABASE_NAME'],
table_name = args['INTEGRATED_DATA_GLUE_TABLE_NAME'],
transformation_ctx = 'datasink',
additional_options=additionalOptions
)
スクリプトをS3バケットにアップロードします。
% aws s3 cp devices-data-etl.py \
${DATA_ANALYTICS_BUCKET}/glue-job-script/devices-data-etl.py
データソースへのデータ作成
データソースの場所となるS3バケットのパスにデータが記載されたパーティションパスを持つオブジェクトを作成します。
% aws s3 cp raw-data.json \
${RAW_DATA_BUCKET}/raw-data/year=2021/month=01/day=13/raw-data.json
この時点ではデータソースのGlueテーブルにパーティションは一つも作成されていません。
% aws glue get-partitions \
--database-name ${GLUE_DATABASE_NAME} \
--table-name ${RAW_DATA_GLUE_TABLE_NAME}
{
"Partitions": []
}
動作確認
Glueワークフローを実行します。
% RunId=$(
aws glue start-workflow-run --name ${WORKFLOW_NAME} \
--query RunId \
--output text
)
ワークフローの実行のStatistics.SucceededActionsが2となれば、すべてのアクションの実行が正常に完了しています。
% aws glue get-workflow-run \
--name ${WORKFLOW_NAME} \
--run-id ${RunId} \
--query Run.Statistics
{
"TotalActions": 2,
"TimeoutActions": 0,
"FailedActions": 0,
"StoppedActions": 0,
"SucceededActions": 2,
"RunningActions": 0
}
データターゲットのGlueテーブルのパーティションを取得してみると、データソースと同じパーティションが作成されています。
% aws glue get-partitions \
--database-name ${GLUE_DATABASE_NAME} \
--table-name ${INTEGRATED_DATA_GLUE_TABLE_NAME} \
--query 'Partitions[0].Values'
[
"2021",
"01",
"13"
]
データターゲットからS3オブジェクトを取得してみると、ちゃんとパーティション分割されてオブジェクトが作成されています。
% aws s3 ls ${DATA_ANALYTICS_BUCKET}/integrated-data --recursive
2021-01-14 19:55:09 90 integrated-data/year=2021/month=01/day=13/run-datasink-4-part-r-00000
AthenaでクエリSELECT * FROM ${RAW_DATA_GLUE_TABLE_NAME}を実行してデータターゲットのデータを取得してみます。
% QueryExecutionId=$( \
aws athena start-query-execution \
--query-string "SELECT * FROM ${INTEGRATED_DATA_GLUE_TABLE_NAME}" \
--work-group ${ATHENA_WORK_GROUP_NAME} \
--query-execution-context Database=${GLUE_DATABASE_NAME},Catalog=AwsDataCatalog \
--query QueryExecutionId \
--output text \
)
クエリの実行結果を取得すると、データターゲットにGlueジョブで加工されたデータが作成されていることが確認できました。
% aws athena get-query-results \
--query-execution-id $QueryExecutionId \
--query ResultSet.Rows
[
{
"Data": [
{
"VarCharValue": "device_id"
},
{
"VarCharValue": "timestamp"
},
{
"VarCharValue": "state"
},
{
"VarCharValue": "partition_date"
},
{
"VarCharValue": "year"
},
{
"VarCharValue": "month"
},
{
"VarCharValue": "day"
}
]
},
{
"Data": [
{
"VarCharValue": "3ff9c44a"
},
{
"VarCharValue": "1609348014"
},
{
"VarCharValue": "true"
},
{
"VarCharValue": "2021/01/13"
},
{
"VarCharValue": "2021"
},
{
"VarCharValue": "01"
},
{
"VarCharValue": "13"
}
]
}
]
おわりに
クローラーとジョブを組み合わせて、パーティション分割されたデータソースをパーティション分割したデータターゲットに追加するETLフローを作ってみました。
今回はETLワークフローを手動実行しましたが、cronベースのトリガーで日次バッチとして実行させることももちろん可能です。これを基本形にいろいろ応用させてみたいですね。
参考
- Glueの使い方的な⑤(パーティション分割してるcsvデータをパーティション分割したparquetに変換) - Qiita
- AWS Glueを用いてパフォーマンス向上やコスト最適化するカラム名ありパーティションのデータに変換するETLコードを作成する | Developers.IO
- AWS::Glue::Trigger - AWS CloudFormation
- get-workflow-run — AWS CLI 1.18.214 Command Reference
- ls — AWS CLI 1.18.214 Command Reference
以上









