
【Databricks】Auto LoaderとDLTを利用してS3に連携されるファイルで増分更新・洗い替えをしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のueharaです。
今回は、DatabricksでAuto LoaderとDLTを利用してS3に連携されるファイルでテーブルの増分更新・洗い替えをしてみたいと思います。
はじめに
Databricksを利用してて、S3に連携されるファイルでテーブルの増分更新や洗い替えをしたいケースってありますよね。
今回はAuto LoaderとDLTを利用しテーブル更新試してみたいと思います。
Auto Loaderについて
Auto Loaderは一言でいうとクラウドストレージに新しいデータファイルが連携されるケースにおいて、それらデータを段階的かつ効率的に処理するための仕組みです。
クラウドストレージはAmazon S3やGoogle Cloud Storage, Azure Blob Storageなどに対応しています。
Auto Loaderには以下の2つのモードがあります。
- ディレクトリ一覧表示モード(デフォルト)
- ファイル通知モード
デフォルトのファイル一覧表示モードでは、シンプルに入力ディレクトリの一覧を持っておき("チェックポイント"を管理)、更新時にその差分で新規ファイルを識別します。
ファイル通知モードはAWSだとSNSやSQSといったサービスと連携し、S3へのファイルPutイベントを検知して処理をするモードとなります。
前者はストレージへのアクセス権限さえ持っていれば実現可能ですが、後者については別途利用するクラウドサービスへのアクセス権限が必要となります。
今回の検証ではDatabricksのコンピュートとしてDatabricks ClusterではなくSQL Warehouse (Serverless SQL Warehouse)を使うため、ファイル一覧表示モードで対応します。(※検証日時点でServerless SQL Warehouseがファイル通知モードに対応していないため)
DLTについて
DLTは一言でいうとデータ処理パイプラインを構築するためのフレームワークです。
例えば、以下のようなことが実行できます。
- ソースからのデータ取り込み
- データの段階的変換
- チェンジデータキャプチャ (CDC)の実行
DLTパイプラインの中でAuto Loaderを利用することもできるので、今回の検証ではDLTを使います。
※DLTパイプラインのすべてのテーブル、データ、チェックポイント、およびメタデータはDLTによってフルマネージドされます。
事前準備
今回はS3へのデータアクセスのため、既にStorage Credentialの設定や外部ロケーションの作成が完了していることを想定しています。
したがって、取り込むRawデータ用のファイルの準備から始めます。
今回はRawデータとして、簡単ですが以下の2つのcsvファイルを利用したいと思います。
id,name,price
1,aaa,100
2,bbb,200
id,name,price
3,ccc,300
4,ddd,400
取り急ぎ、Rawデータ用のバケットに book_1.csv だけ配置しておきます。
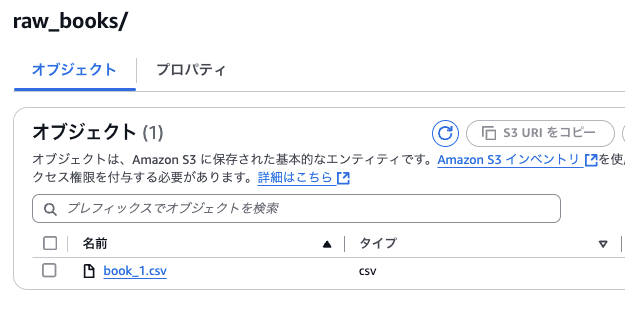
増分更新をしてみた
そもそもDLTの主要な技術的メリットは簡単に増分アップデートを実現できる点になります。(ストリーミングテーブルと言います)
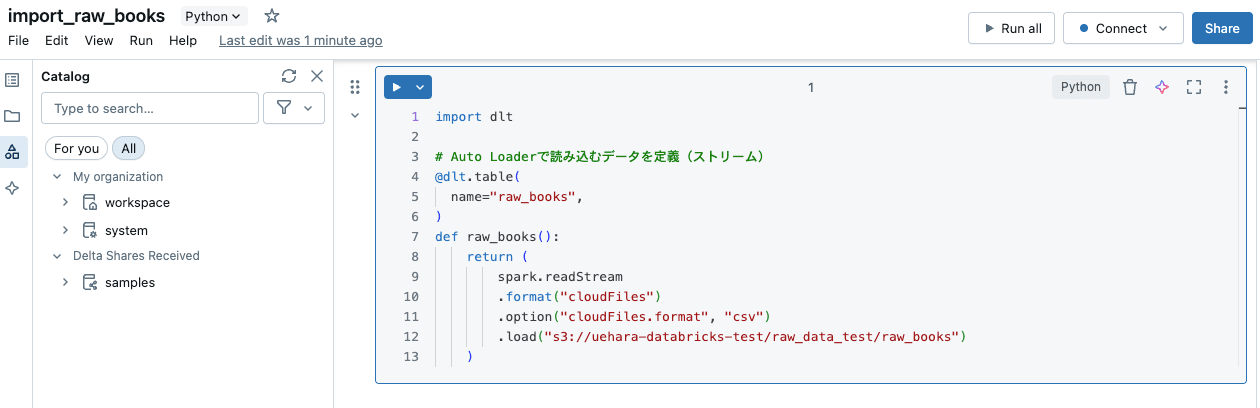
まず、Databricksトップ画面の左側のタブから『Workspace』に遷移し、新しくNotebookを作成します。
import_raw_books 等適当な名前をつけ、以下スクリプトを記載します。(S3バケットのパスはご自身の環境に合わせて下さい)
import dlt
# Auto Loaderで読み込むデータを定義(ストリーム)
@dlt.table(
name="raw_books",
)
def raw_books():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv")
.load("s3://uehara-databricks-test/raw_data_test/raw_books")
)
この時点で以下のようになっているかと思います。
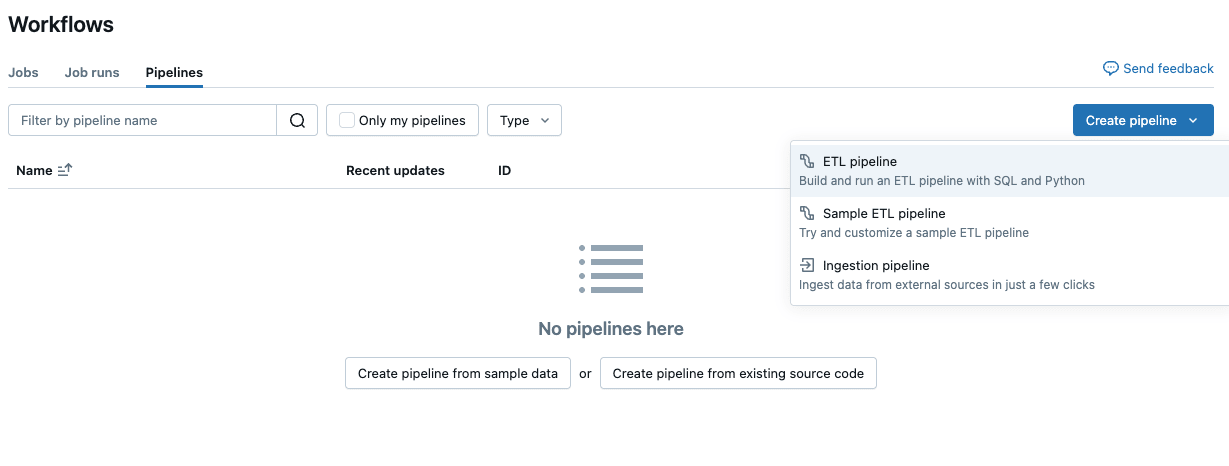
次にパイプラインを構築します。
Databricksトップ画面の左側のタブから『Pipelines』を選択します。
開いた画面から『ETL pipeline』を選択します。
import_raw_books_pipeline など適当な名前をつけ、『Source code』では先程作成したNotebookを選択します。
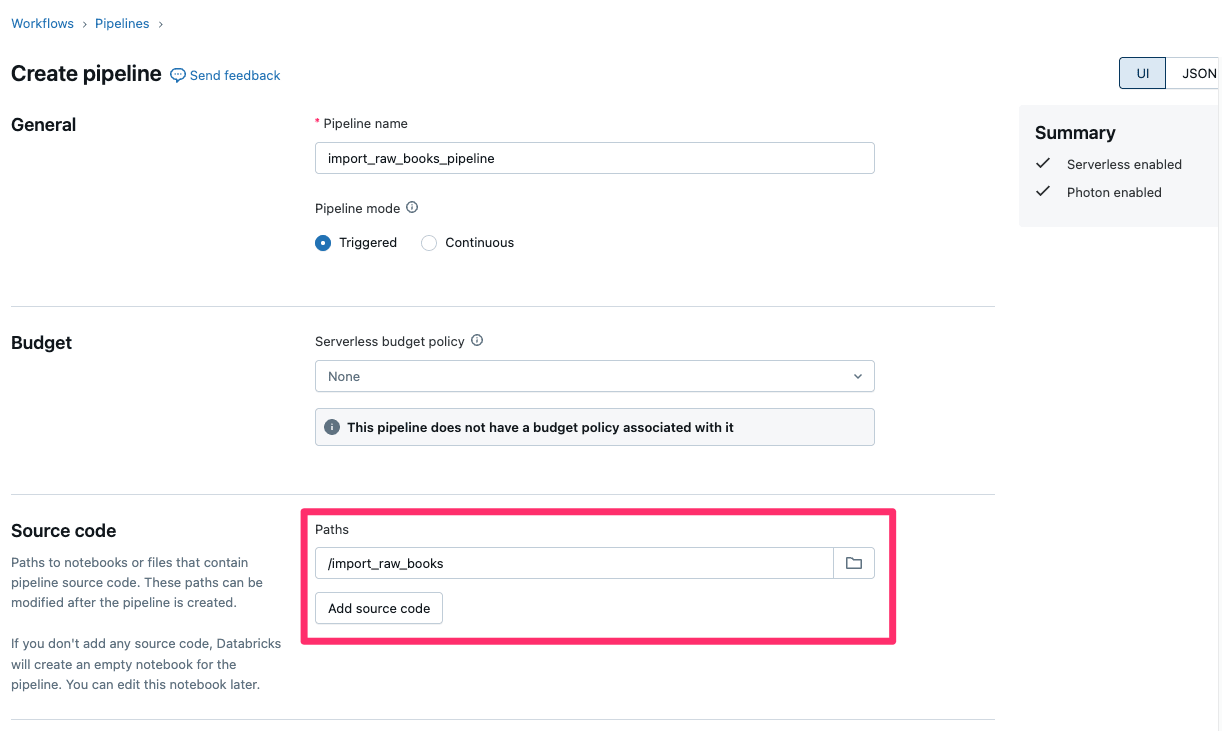
『Destination』には、今回作成するテーブルのカタログとスキーマを定義します。
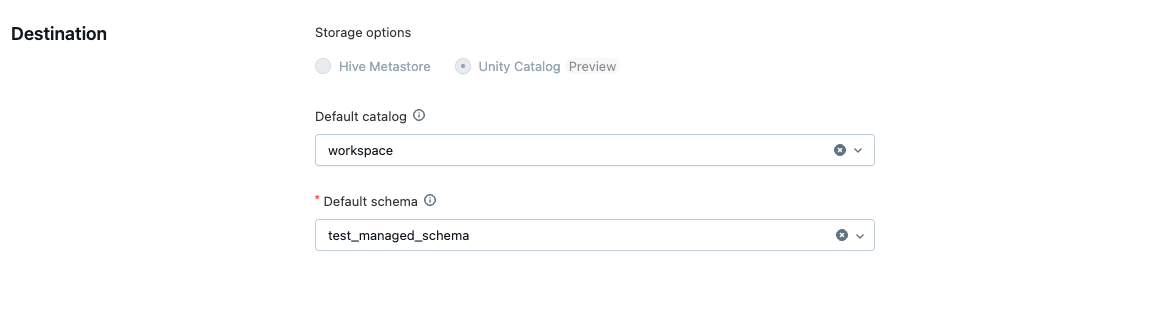
あとは『Create』ボタンを押せばパイプラインの作成は完了です。
パイプラインの作成が完了したので、実行してみます。
実行が成功すると、以下のようにストリーミングテーブルが作成されたことが分かります。
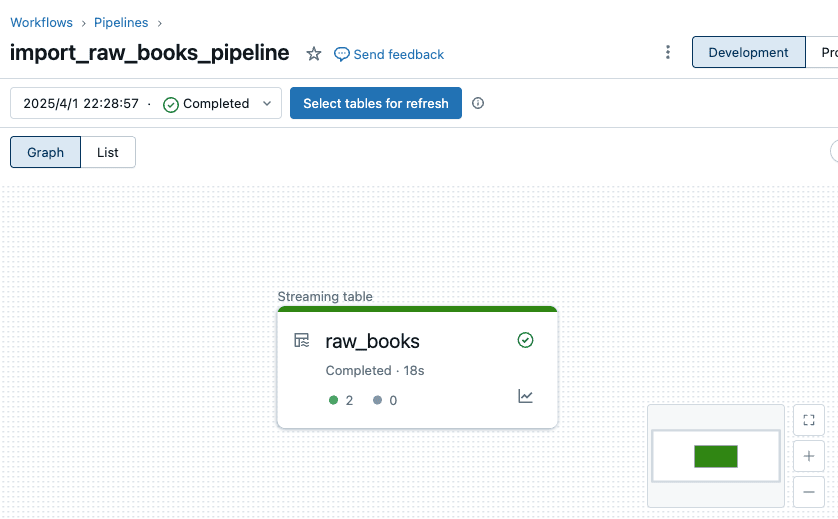
テーブルに対しクエリを実行すると、無事データが確認できました。
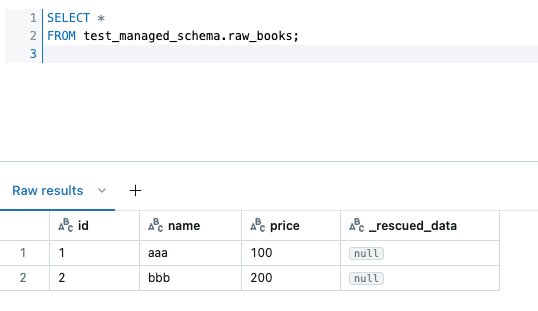
次に、先程のS3のパスに book_2.csv をアップロードします。
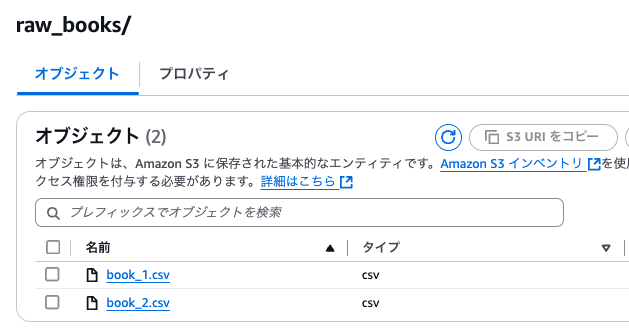
アップロードが完了したので、再度パイプラインを実行してみます。
先ほどと同じようにストリーミングテーブルが正常に更新できたことを確認して、テーブルの中身を確認します。

無事、更新分のデータが反映されていました。
洗い替えをしてみた
先にお話した通り、Auto Loader + DLTは基本的に増分更新となります。
したがって、洗い替えを行いたい場合には削除処理を挟む必要があり、ちょっと工夫が入ります。
まず、検証のため増分更新で作成したテーブルを一旦DROPします。
DROP TABLE raw_books;
S3のファイルも再度 book_1.csv のみにしておきます。
準備ができたら再度Notebookを開いて、増分更新の時に作成したスクリプトを以下の通り変更します。(S3バケットのパスはご自身の環境に合わせて下さい)
import dlt
# Auto Loaderで読み込むデータを定義(ストリーム)
@dlt.table(
name="raw_books",
table_properties={
"pipelines.reset.allowed": "false"
}
)
def raw_books():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv")
.load("s3://uehara-databricks-test/raw_data_test/raw_books")
)
フルリフレッシュが実施されてしまうとチェックポイントがクリアされてしまうため(すなわち、フルリフレッシュでパイプラインが更新されてしまうとS3に存在するファイルが全て読み込まれてしまう)、テーブルのプロパティで pipelines.reset.allowed を false にしています。
ここで一旦先ほど作成したパイプラインを実行してテーブルを作成してみます。
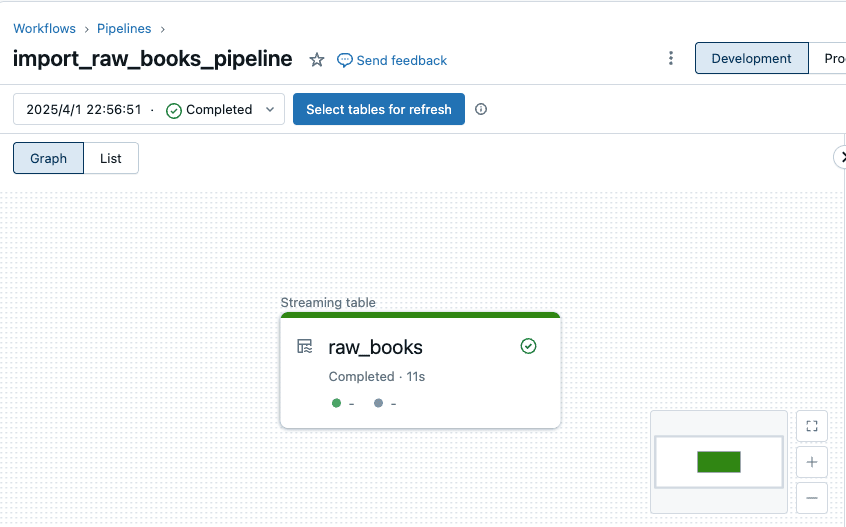
増分更新の時と同様、 book_1.csv のデータが確認できました。
次にNotebookを1つ追加します。
delete_raw_books 等適当な名前をつけ、以下SQLを記載します。(※Notebookの言語設定はSQLにして下さい)
DELETE FROM workspace.test_managed_schema.raw_books_stream;
設定が完了すると、以下のようになっているかと思います。

Notebooksが作成できたら、『Workflows』からJobを作成します。
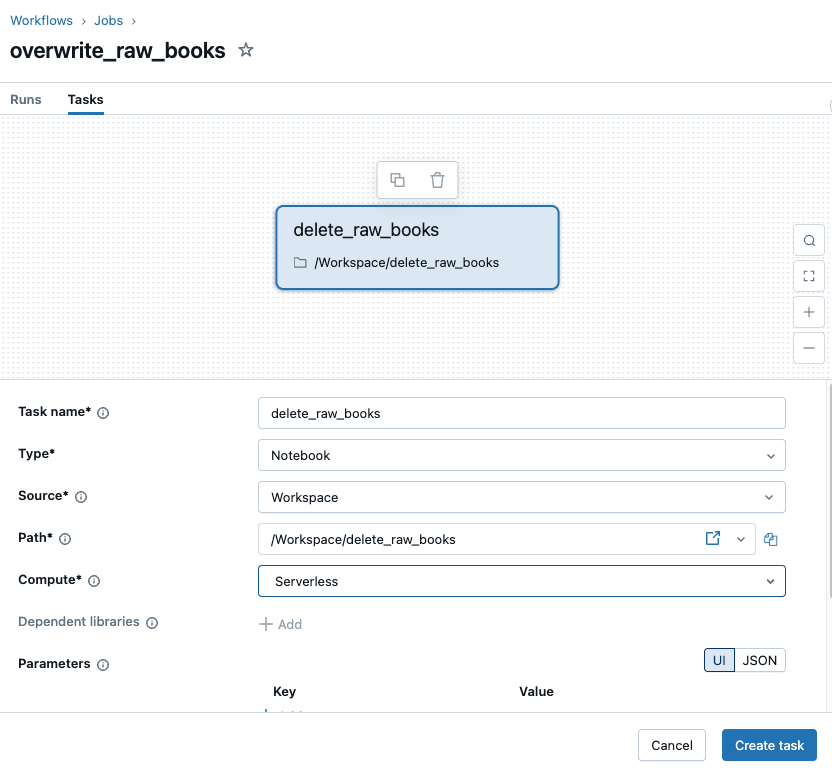
まず、1つ目のタスクをTypeはNotebookとして、delete処理を記載したNotebookを指定して『Create task』ボタンを押します。
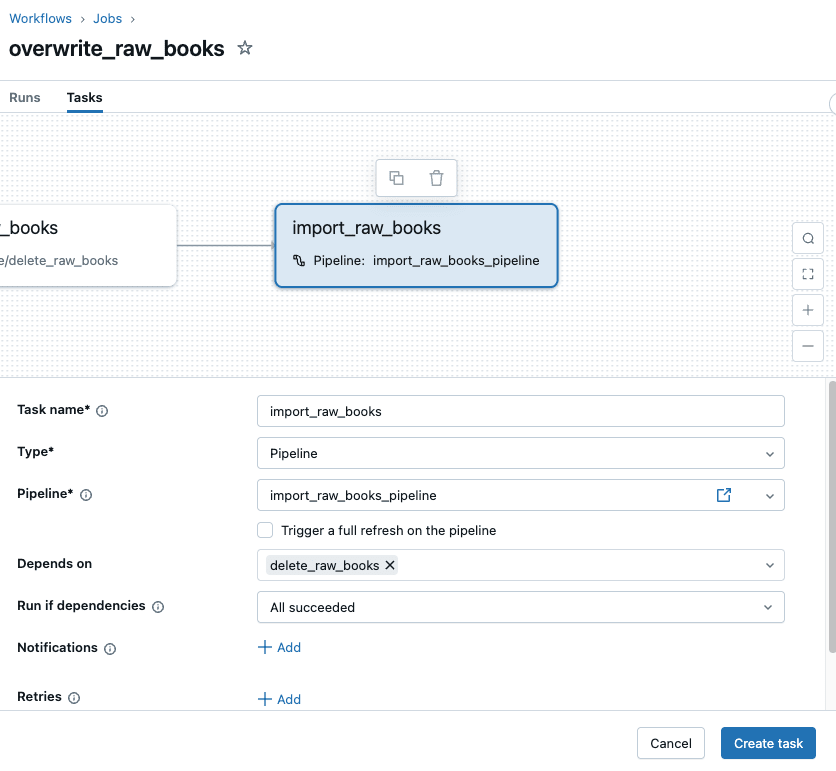
次に『Add Task』を押してTypeはPipelineとし、先に作成したパイプラインを指定して『Create task』ボタンを押します。
これで削除→更新を行う準備ができたので、再度S3に book_2.csv をアップロードします。
アップロードが完了したら、作成したJobを実行します。
成功するとJob実行画面は以下のようになります。

テーブルのデータを確認すると、2つ目に連携したファイルで洗い替えがされていることを確認できます。
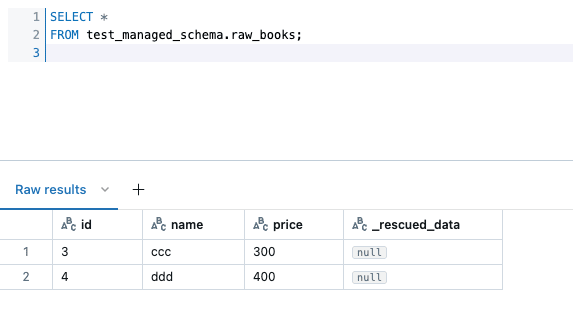
※ただし、これはあくまで「前回確認時点(チェックポイント)からの更新分のデータで洗い替え」となっていることにご注意下さい。
洗い替えに代えマテビューで対応
洗い替えをするのではなく、ストリーミングテーブルにはデータを全て保持しておき、後続のマテビューで最新断面のみ抽出するということもDLTで実現できます。
例えばNotebookを更新し、以下のようにします。
import dlt
from pyspark.sql.window import Window
from pyspark.sql.functions import current_timestamp, col, lit, max as max_
# Auto Loaderで読み込むデータを定義(ストリーム)
@dlt.table(
name="raw_books_stream",
table_properties={
"pipelines.reset.allowed": "false"
}
)
def raw_books_stream():
df = (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv")
.load("s3://uehara-databricks-test/raw_data_test/raw_books")
)
ingest_time = current_timestamp()
# ストリームデータに処理時間のタイムスタンプを追加
return (
df
# タイムスタンプを追加
.withColumn("ingest_timestamp", lit(ingest_time))
)
# 上記テーブルを元に最新データのみを含むテーブルを作成
@dlt.table(
name="raw_books"
)
@dlt.expect_or_drop("valid_timestamp", "ingest_timestamp IS NOT NULL")
def raw_books():
# ストリームデータを読み込み
df = spark.read.table("raw_books_stream")
# ingest_timestampの最大値を取得
max_ts_df = df.agg(max_("ingest_timestamp").alias("max_ts"))
# 最新のtimestampを持つレコードを抽出
return (
df.join(max_ts_df, df["ingest_timestamp"] == max_ts_df["max_ts"], "inner")
.drop("max_ts")
)
このパイプラインを実行すると以下のようになります。
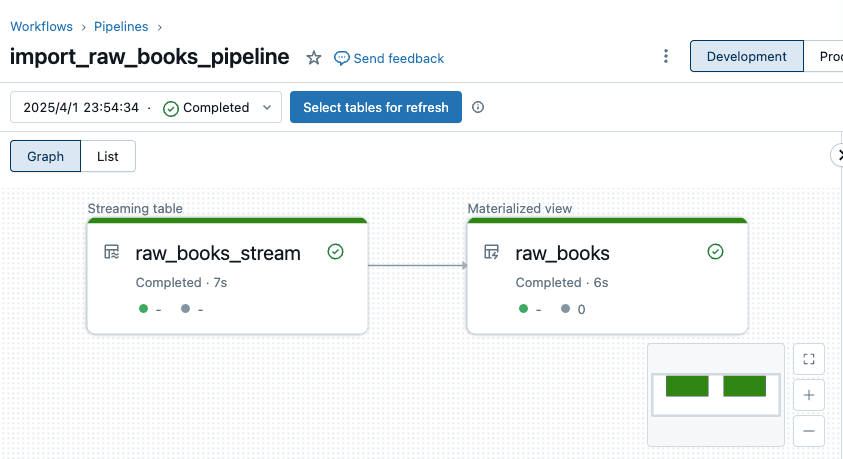
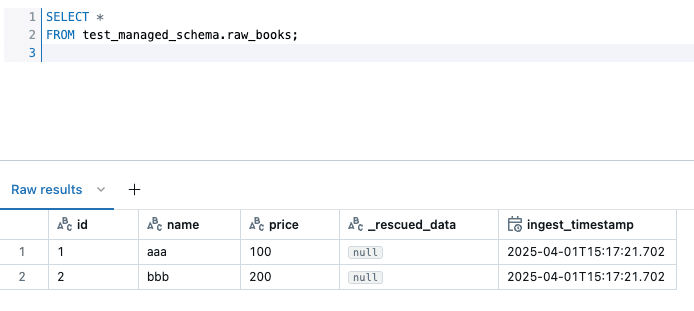
book_1.csv が連携されている状態でパイプラインを実行するとテーブルの中身は以下のようになります。
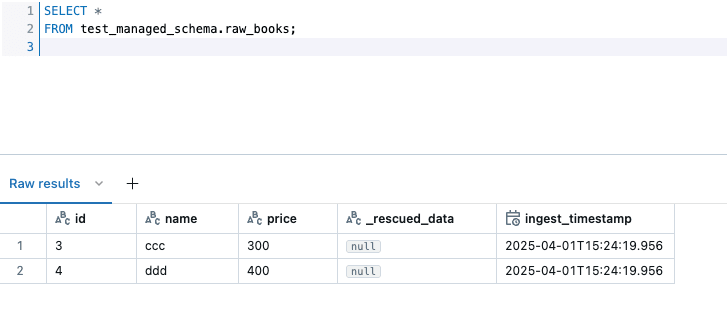
続けて、 book_2.csv を連携してパイプラインを実行するとテーブルの中身は以下のようになります。
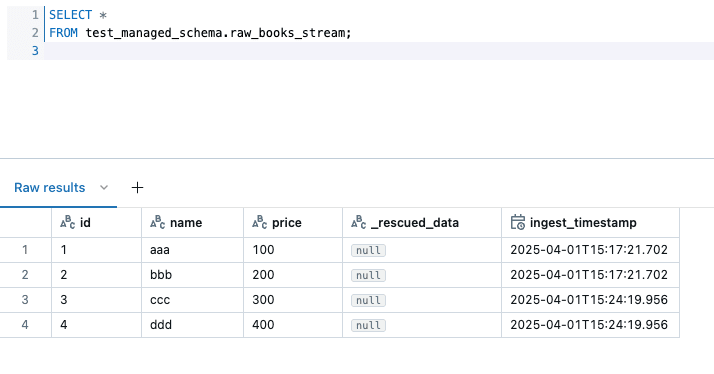
大元のストリーミングテーブルは全量を保持しています。
最後に
今回は、DatabricksでAuto LoaderとDLTを利用してS3に連携されるファイルでテーブルの増分更新・洗い替えをしてみました。
参考になりましたら幸いです。








