
【Databricks】Iceberg REST catalogを利用してPyIcebergでアクセスしてみた
データ事業本部のueharaです。
今回は、DatabricksのIceberg REST catalogを利用してPyIcebergでテーブルにアクセスしてみたいと思います。
テーブル作成
DatabricksはDelta Lakeに保存されたテーブルのIcebergの読み取りをサポートしています。
テーブルに対してこの機能を有効化すると、Deltaテーブルにデータを書き込むために使用されるコンピューティング上でIcebergのメタデータの生成が非同期的に実行されます。
この機能を利用すれば、SnowflakeやPyIcebergからIcebergテーブルとして参照できます。
統合については以下のページをご確認下さい。
早速、以下のようにAmazon S3上に外部テーブルとしてDeltaテーブルを新規作成し、Iceberg読み取りを有効化してみます。
CREATE TABLE sample_table (
id STRING,
name STRING,
score INT
)
USING DELTA
LOCATION 's3://uehara-databricks-test/sample-table/'
TBLPROPERTIES(
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
);
テーブルの作成ができたら、適当にデータを挿入してみます。
INSERT INTO sample_table VALUES
('1', 'Alice', 100),
('2', 'Bob', 90),
('3', 'Charlie', 80),
('4', 'Dave', 70),
('5', 'Eve', 60);
データの挿入ができたら、一旦テーブルを確認してみます。
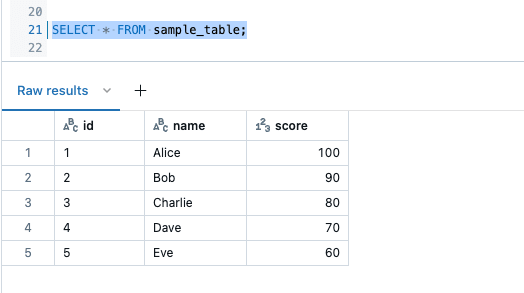
これで準備ができました。
S3やメタデータ生成ステータスの確認
ロケーションとして設定したS3のパスを確認すると _delta_log の他 metadata が作成されていることが分かります。
sample-table/
├── Kp/
│ └── part-00000-0486d4c1-8268-4858-a0b6-1055f519891f.c000.zstd.parquet
├── _delta_log/
│ ├── 00000000000000000000.crc
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.crc
│ ├── 00000000000000000001.json
│ └── _commits/
└── metadata/
├── 00000-e8a79cd8-9210-43c0-973b-90599285b946.metadata.json
├── 00001-e51afb2a-2b10-4a14-825f-280a487e2b65.metadata.json
├── 00002-c579d903-de56-4ba7-80c7-cb8e82e87e53.metadata.json
├── cb315dc5-b3c0-4656-aa2a-f13d579e0c81-m0.avro
└── snap-4128383503645490189-1-cb315dc5-b3c0-4656-aa2a-f13d579e0c81.avro
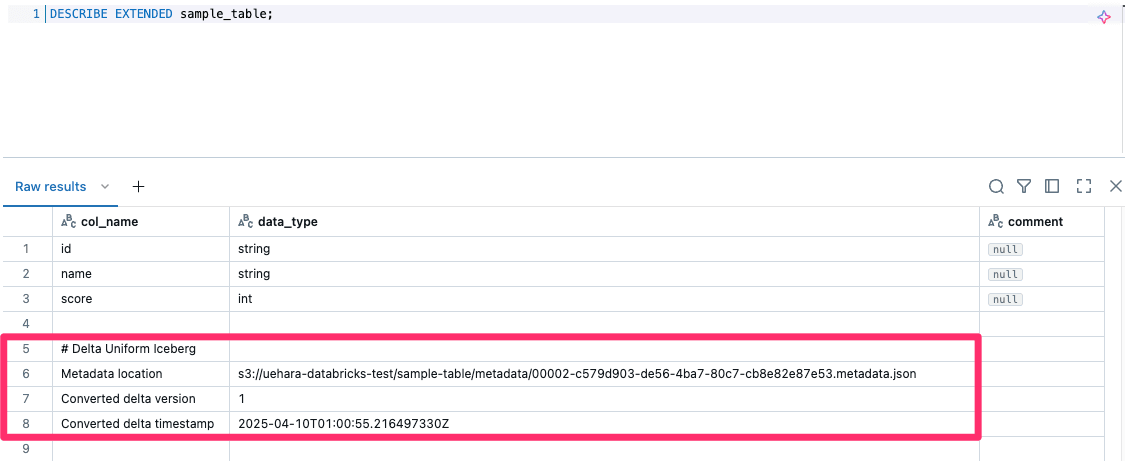
冒頭でIcebergのメタデータは非同期で生成されると記載しましたが、メタデータの生成ステータスを追跡するために以下のメタデータフィールドを確認することができます。(参考)
DESCRIBE EXTENDED <table_name>; でこれらメタデータフィールドの情報を確認することができるので、実際に確認したところ以下のようになっていました。
PyIcebergでアクセス
PyIceberg は pip を利用して以下でインストールできます。
$ pip install pyiceberg
また、接続のためのURIとTokenを環境変数に設定しておきます。
$ export UC_ICEBERG_REST_URI=<workspace-url>/api/2.1/unity-catalog/iceberg
$ export DATABRICKS_TOKEN=<your-token>
<workspace-url> には、ご自身のDatabricks workspaceのurlを、 <token> にはアクセスのためのトークンを指定してください。
上記を踏まえた上で、以下のPythonプログラムを作成します。
import os
from pyiceberg.catalog import load_catalog
# エンドポイントのURI
UC_ICEBERG_REST_URI = os.environ.get("UC_ICEBERG_REST_URI")
# Databricksパーソナルアクセストークン
DATABRICKS_TOKEN = os.environ.get("DATABRICKS_TOKEN")
# Unity Catalogのカタログ名
UC_CATALOG_NAME = "workspace"
# Unity CatalogのRESTカタログプロパティ
properties = {
"type": "rest",
"uri": UC_ICEBERG_REST_URI,
"token": DATABRICKS_TOKEN,
"warehouse": UC_CATALOG_NAME,
}
try:
catalog = load_catalog(UC_CATALOG_NAME, **properties)
# テーブルのロード
table_name = "default.sample_table"
print(f"Loading Iceberg table: {table_name}")
table = catalog.load_table(table_name)
print("Table loaded successfully.")
# データのスキャンとPandas DataFrameへのロード
print("Data loaded into Pandas DataFrame:")
df = table.scan().to_pandas()
print(df.to_string(index=False))
except Exception as e:
print(f"An error occurred: {e}")
UC_CATALOG_NAME に設定しているカタログ名はご自身の環境に合わせて下さい。
なお、外部テーブル(クラウドのオブジェクトストレージ内にデータを保存)において、外部システムからデータファイルにアクセスする場合、Unity Catalog権限は適用されません。
つまり、S3へのデータアクセス自体については別途アクセスキー等の設定が必要になります。
今回はAWS STSを利用し一時認証情報を取得して環境変数に設定し、作成したPythonスクリプトを実行するBashスクリプトを用意しました。(IAMロールには自己信頼ポリシーを追加しておく必要があります)
#!/usr/bin/env bash
set -euo pipefail
PROFILE=$1
unset AWS_PROFILE
export AWS_SDK_LOAD_CONFIG=true
ROLE_ARN=$(aws --profile ${PROFILE} configure get role_arn)
STS_RESULT=$(aws --profile ${PROFILE} sts assume-role --role-arn ${ROLE_ARN} --role-session-name sls-deploy-session --duration-seconds 3600)
export AWS_ACCESS_KEY_ID=$(echo ${STS_RESULT} | jq -r '.Credentials.AccessKeyId')
export AWS_SECRET_ACCESS_KEY=$(echo ${STS_RESULT} | jq -r '.Credentials.SecretAccessKey')
export AWS_SESSION_TOKEN=$(echo ${STS_RESULT} | jq -r '.Credentials.SessionToken')
export AWS_REGION='ap-northeast-1'
python access_with_iceberg.py
実行コマンドは次のようになります。
$ bash get_secret_and_execute_py.sh <YOUR-AWS-PROFILE>
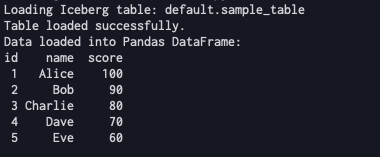
実行の結果、以下の通りテーブルデータが取得できたことを確認しました。
最後に
今回は、DatabricksのIceberg REST catalogを利用してPyIcebergでテーブルにアクセスしてみました。
参考になりましたら幸いです。








