
【Databricks】Lakeflow Connectを利用してSalesforceからデータを取り込んでみた
データ事業本部のueharaです。
今回は、DatabricksのLakeflow Connectを利用してSalesforceからデータを取り込んでみたいと思います。
Lakeflow Connectとは
Lakeflow Connectは、Databricksのマネージド機能として提供されているデータ統合のためのコネクタ機能です。
マネージドコネクタとして、SalesforceやZendesk, Google Analyticsといった様々なサービスに対してコネクタが提供されています。
やってみた
Lakeflow Connectの設定
今回は、表題の通りSalesforceで試してみたいと思います。(設定はとても簡単です!)
まず、Databricksのコンソール画面トップから『Data Ingestion』を選択し、コネクタの一覧から『Salesforce』を選択します。
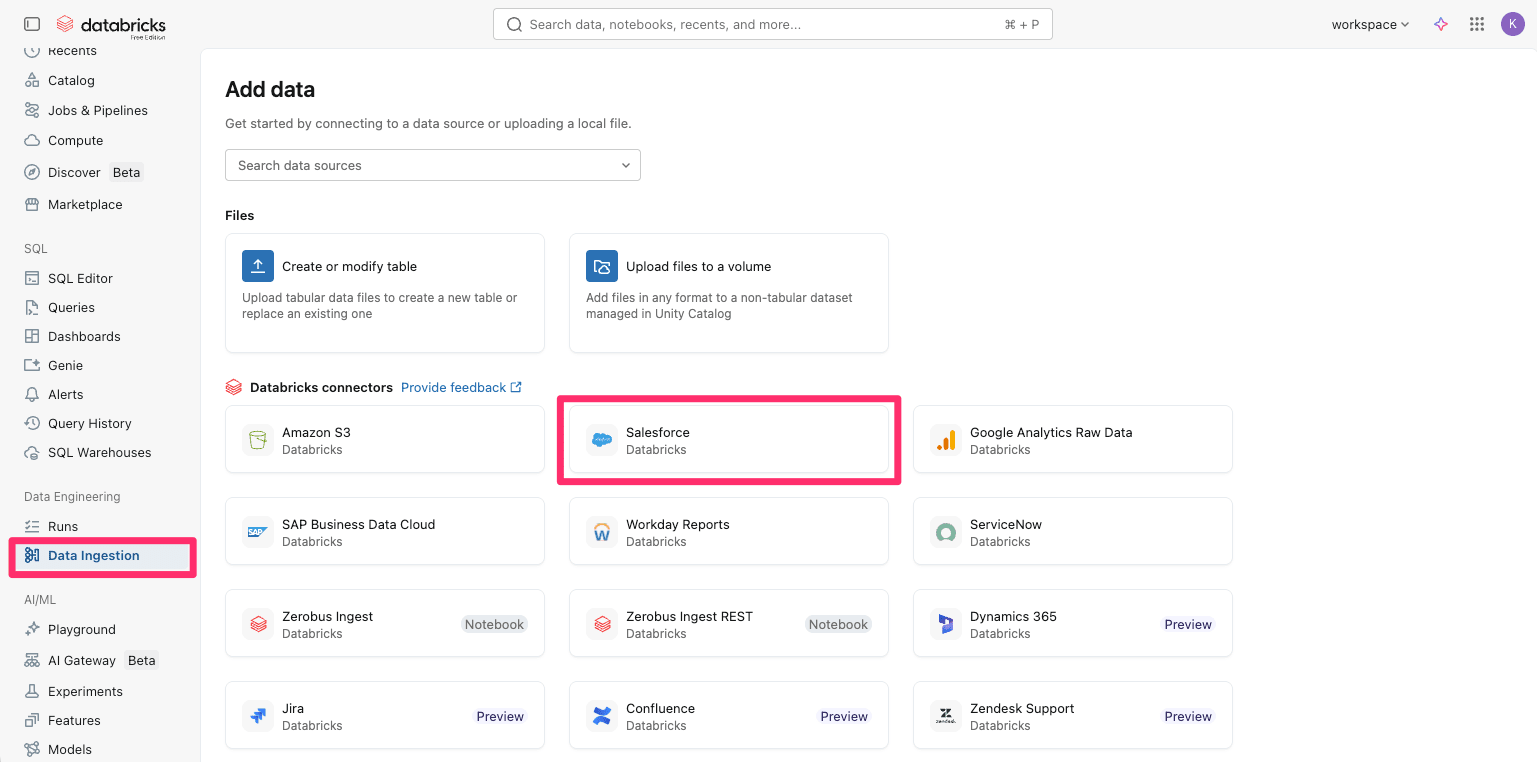
すると設定のページが開きますので、『Create connection』を選択します。
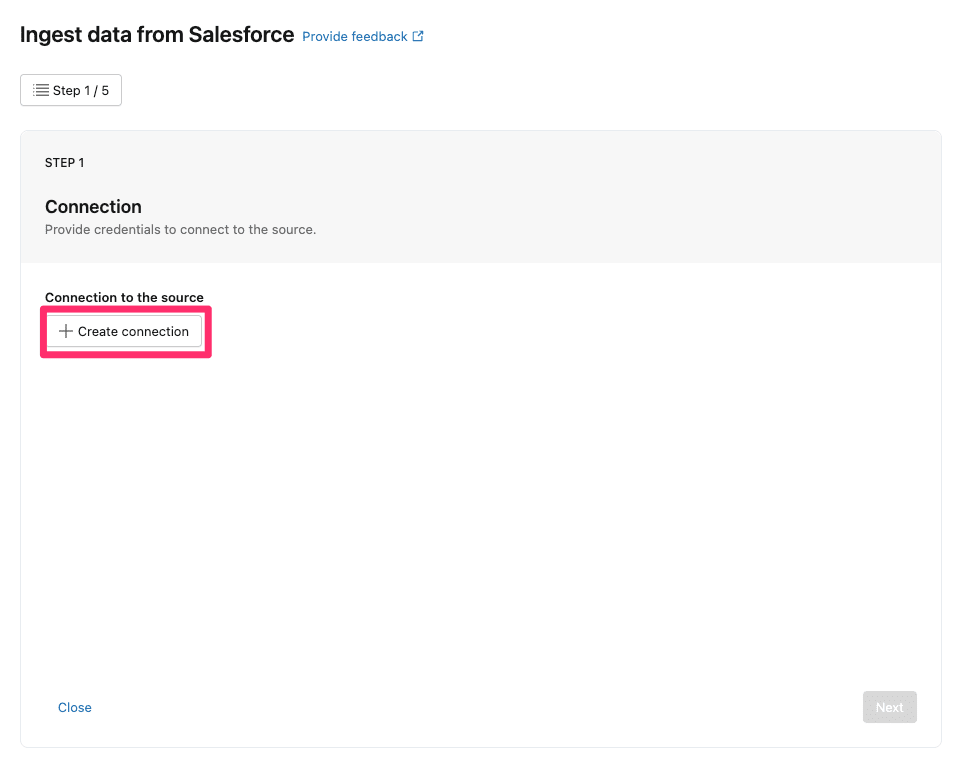
コネクションの名前は適当なものを入力します。私の手元では『salesforce_test_connection』としました。
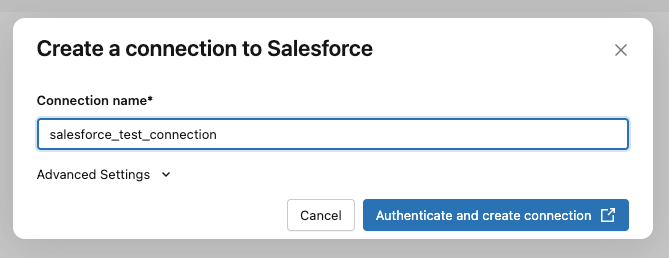
次にSalesforceのユーザー名とパスワードの入力が求められるので、入力します。
入力が完了すると、Databricks Ingestion Connectorからのアクセス許可に関する確認画面が表示されるため、承認を行います。
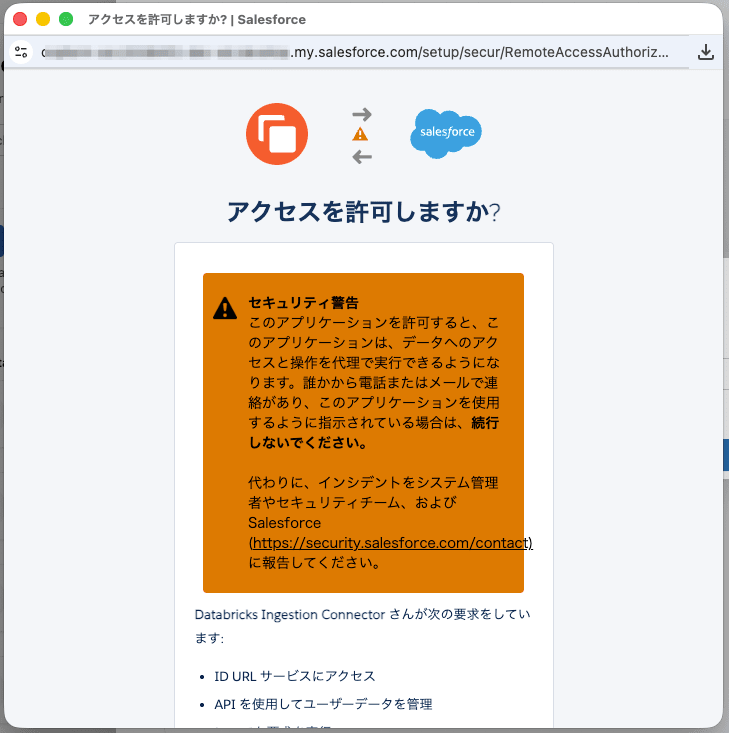
承認をするとコネクションが作成されるため、『Next』を押下します。
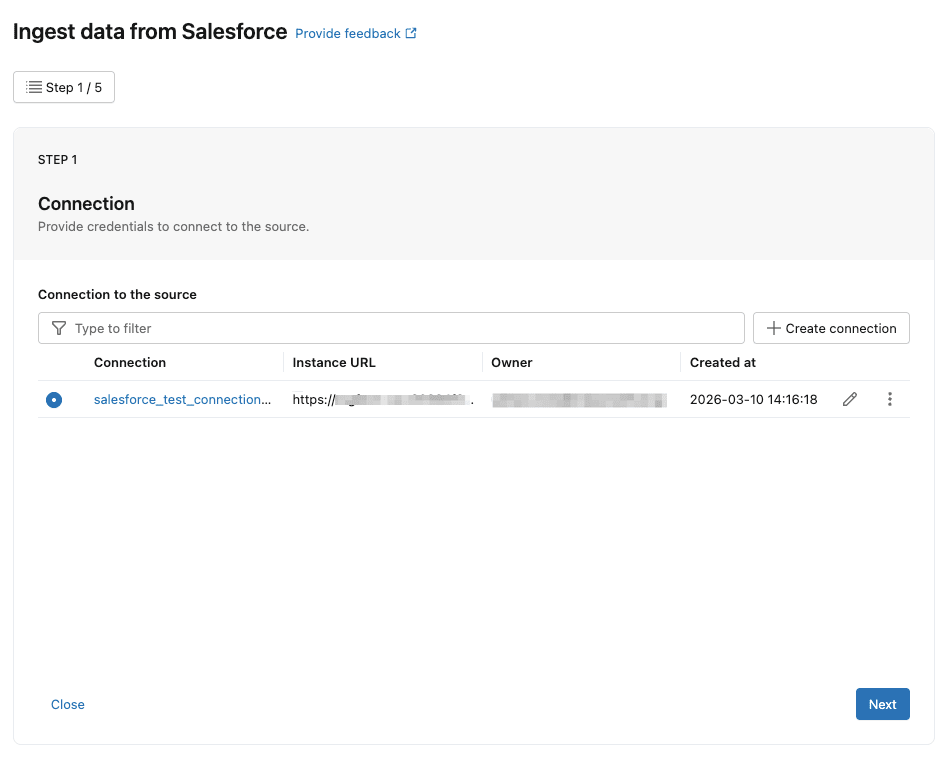
すると、データを連携するためのパイプラインの設定画面が表示されます。
こちらも適当なパイプライン名を付けます。私の手元では『salesforce_test_pipeline』としました。
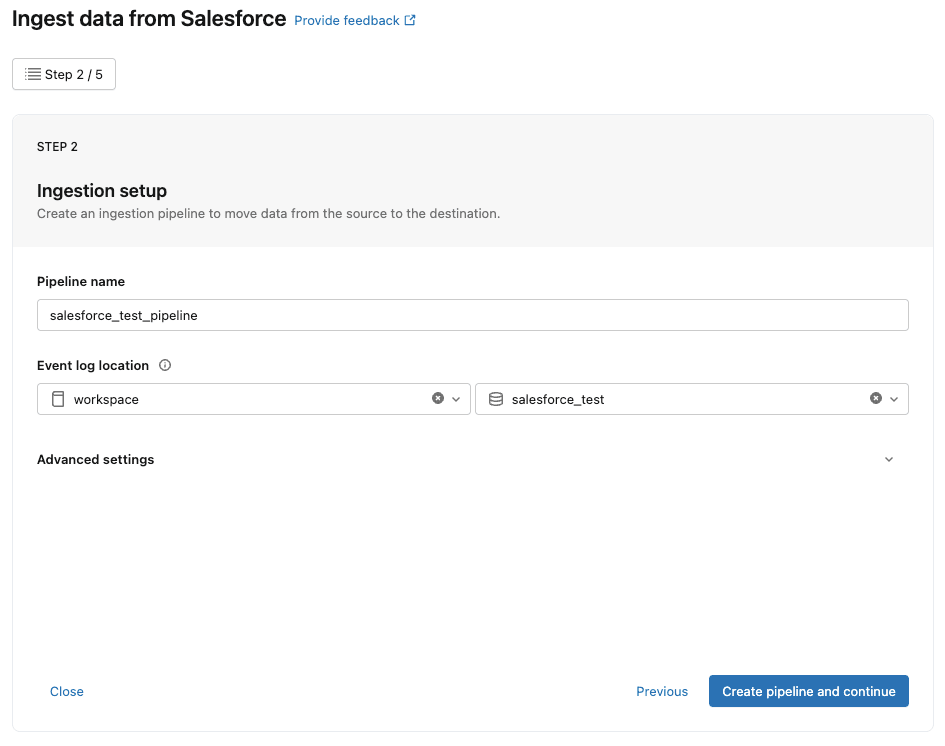
実行ログを保存するスキーマについても、任意の場所を設定ください。
次に、SalesforceからDatabricksへ連携するテーブルが一覧表示されます。
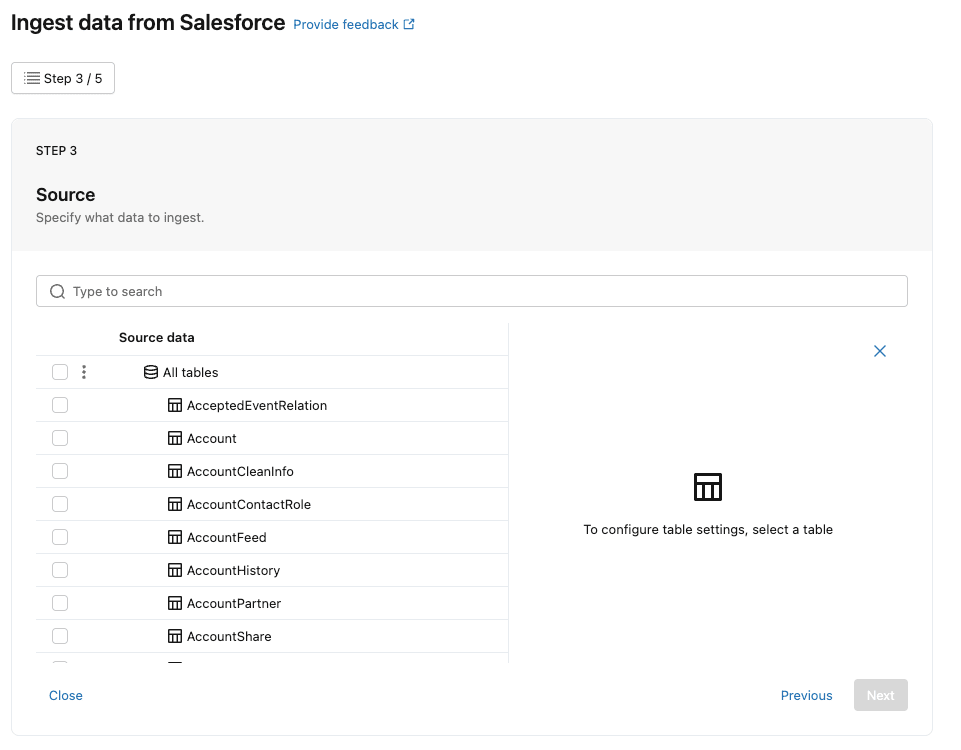
今回はテストのため、『Account』テーブルだけ選択します。
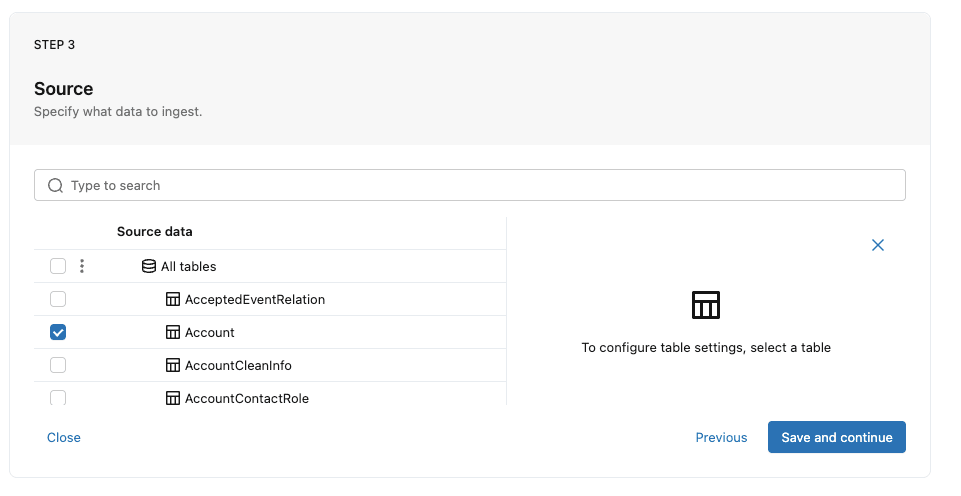
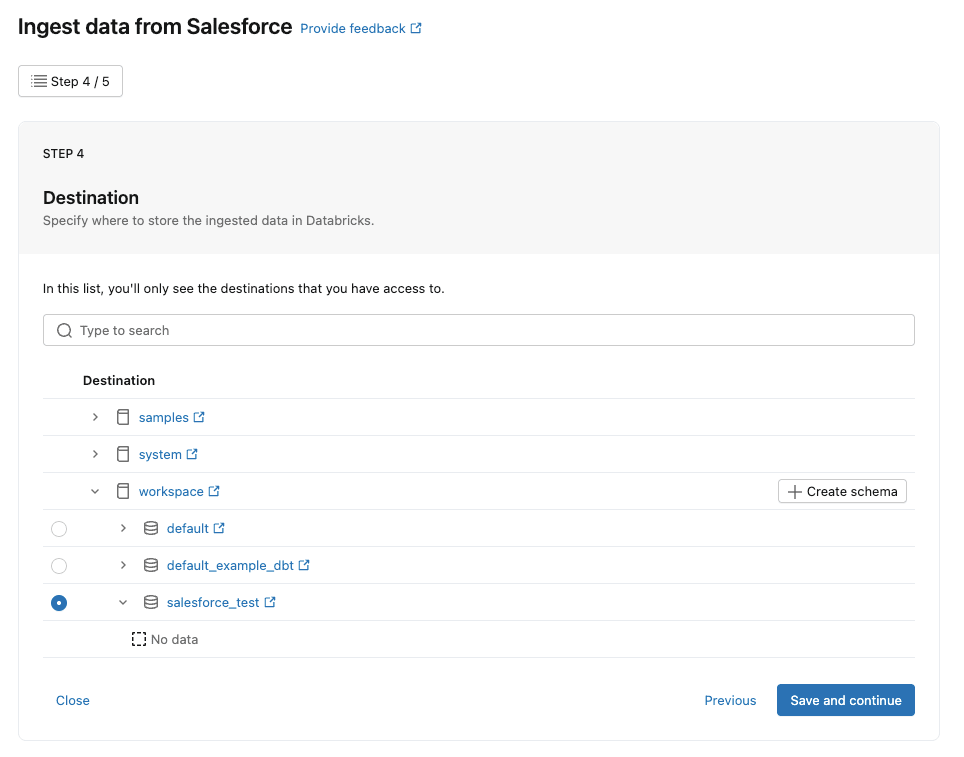
テーブルを選択するとDatabricksの宛先スキーマが選択できるので、こちらも任意の場所を設定してください。
最後に、パイプラインのスケジュール実行用ジョブの確認画面が表示されます。
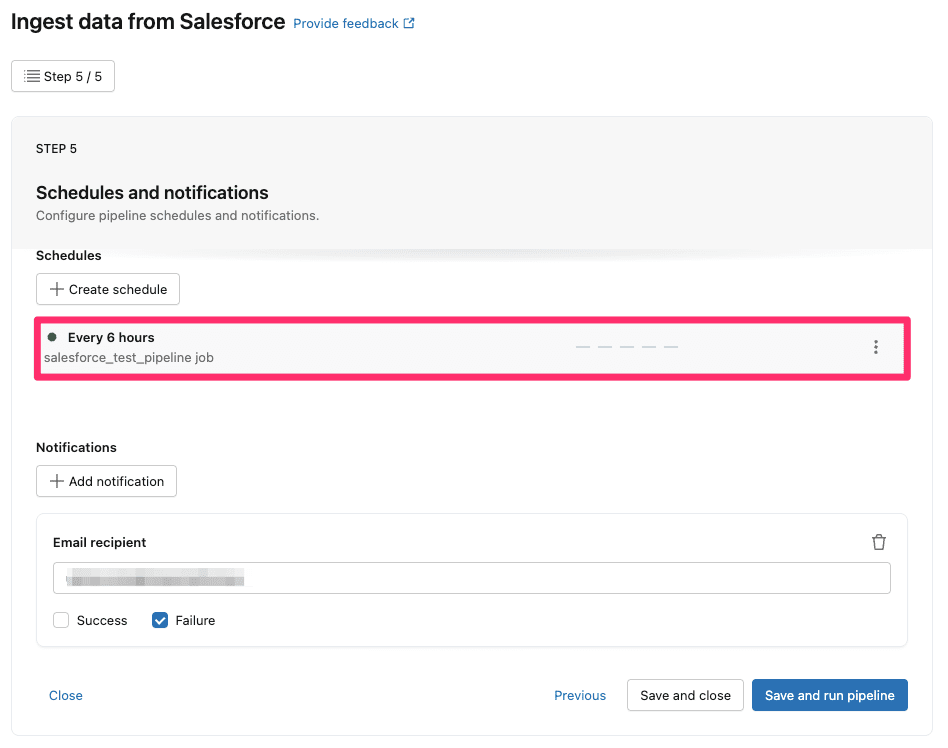
デフォルトでは6時間毎にパイプラインを実行するジョブが組まれるようです。(こちらは後でも変更可能です)
ここまで来たら『Save and run pipeline』のボタンを押下して、パイプラインを実行します。
パイプライン実行すると実行ページが表示されるため、確認してみると以下の通り先程設定した『account』テーブルが連携されていることが分かります。
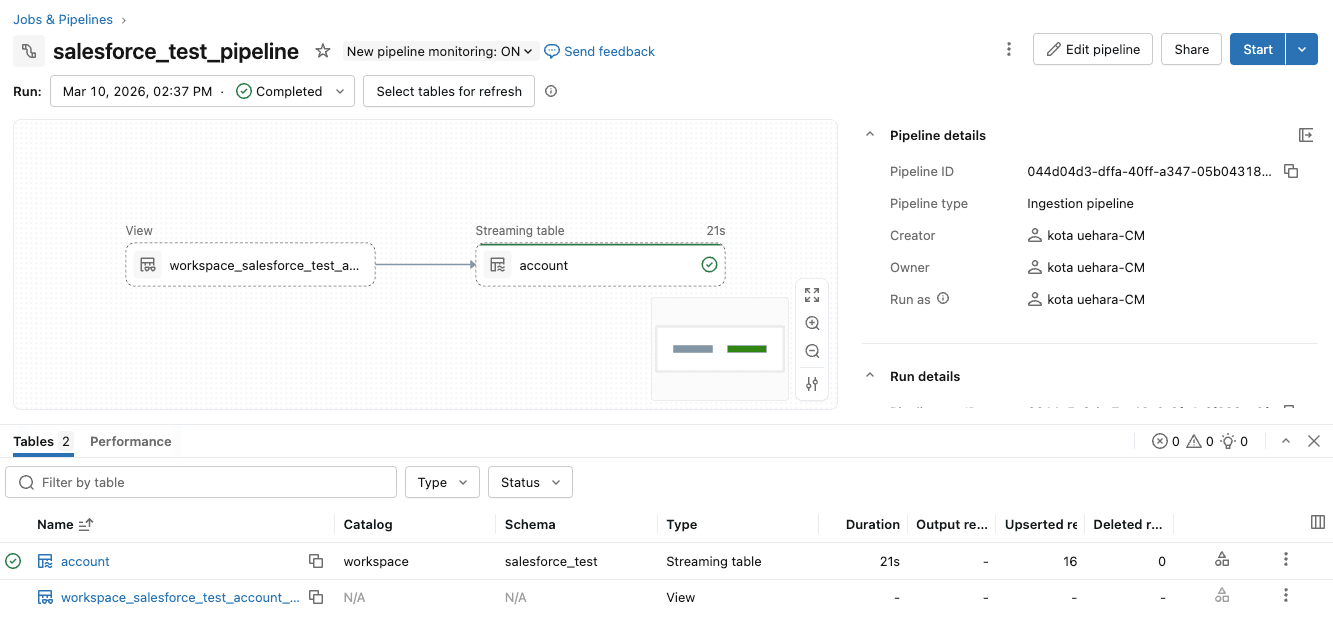
改めて『Jobs & Pipelines』を確認すると、今回作成したパイプラインとそれを6時間毎に実行するためのジョブが作成されていることが分かります。
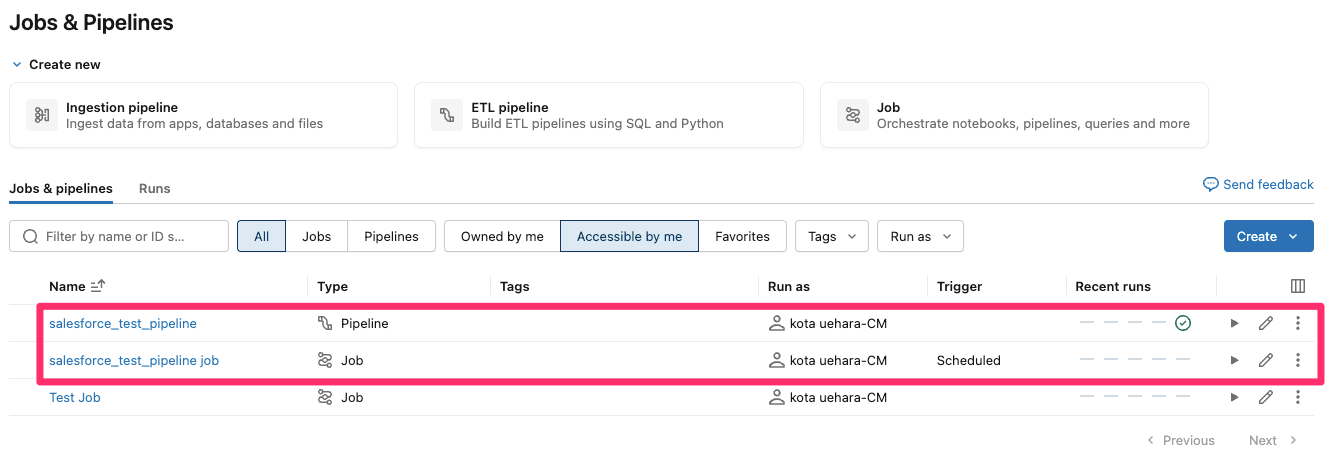
念のため、ジョブの定義はこのような形です。
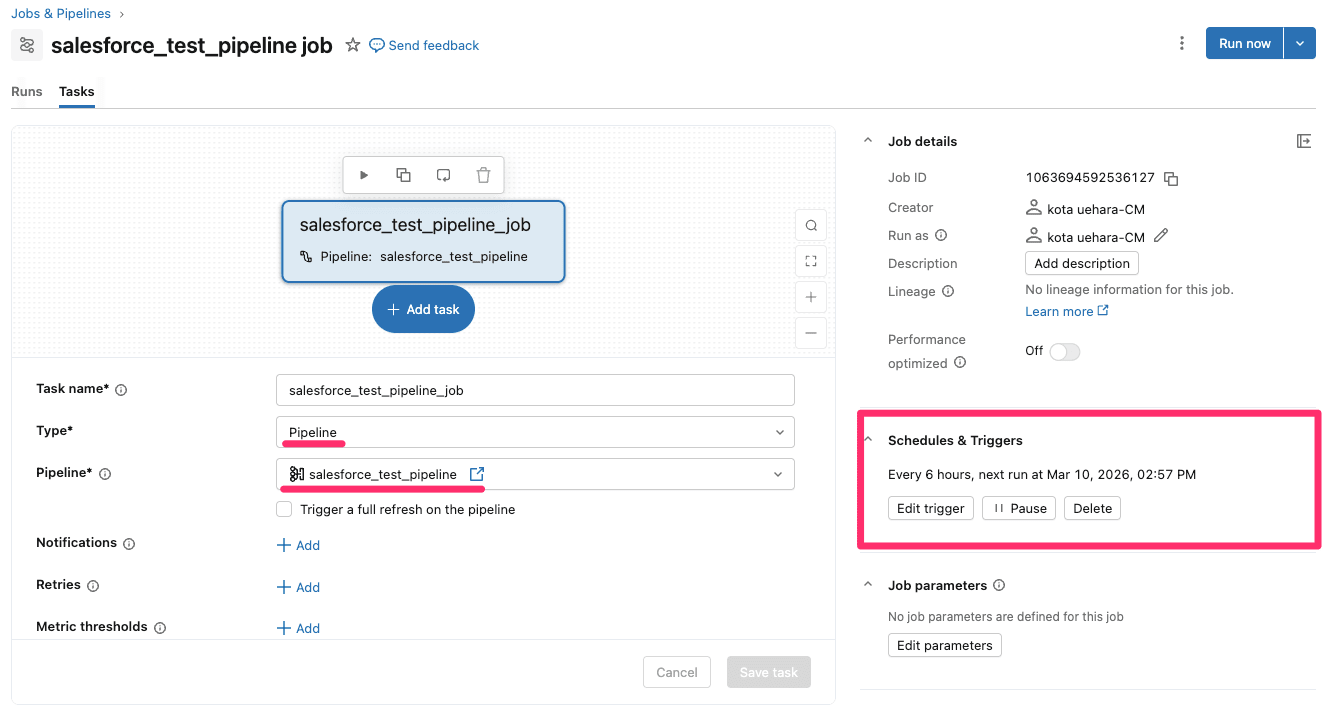
上記の『Schedules & Triggers』をみると6時間毎の実行になっていることが分かります。
『Pause』を押すとジョブの定期実行は停止されるので、このあたりは実行要件に従い設定してください。
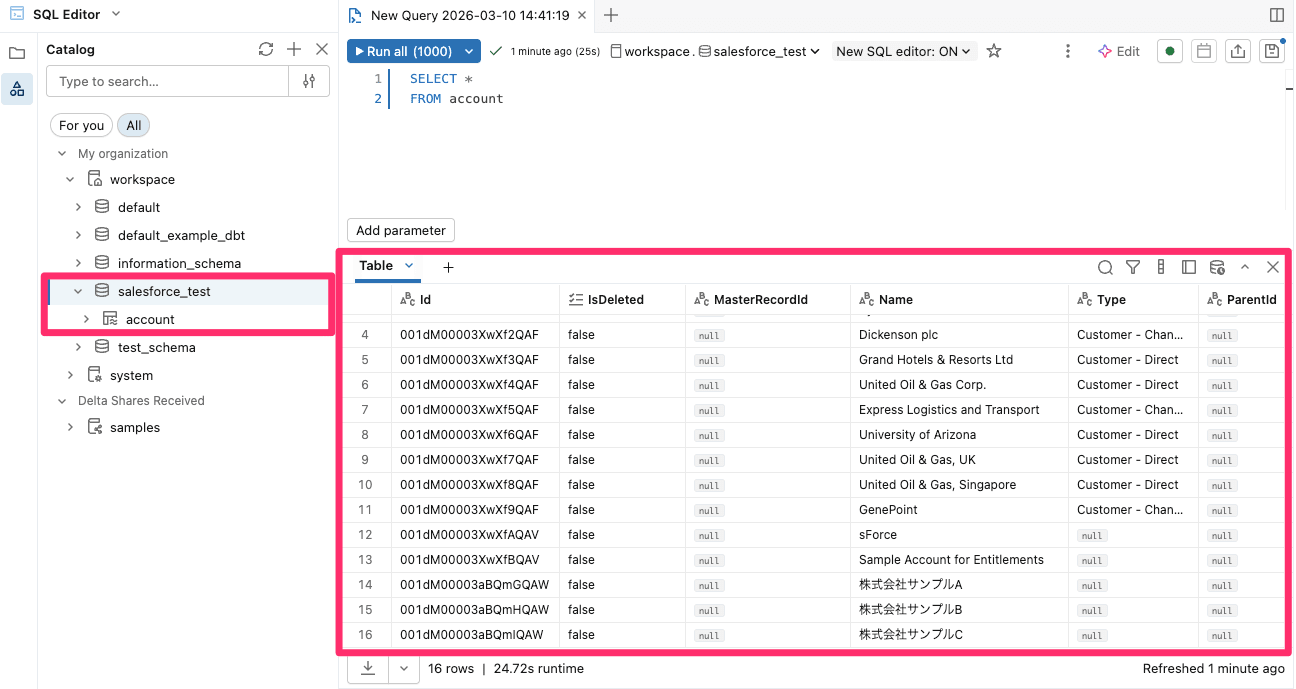
テーブル確認
今回連携したテーブルを確認すると、以下の通り無事データを確認することができました。
補足:Salesforceからの増分取り込み(増分更新)について
Salesforceからの増分取り込みの方法として、Databricksの公式ドキュメントでは「カーソル列」に依存してレコードの変更を検出すると説明されています。
具体的には、コネクターは SystemModstamp, LastModifiedDate, CreatedDate, LoginTime の順に、カーソル列を優先順に選択するようです。
したがって、上記の列の少なくとも1つを持たないオブジェクトは、増分更新で取り込むことはできないようです。
最後に
今回は、DatabricksのLakeflow Connectを利用してSalesforceからデータを取り込んでみました。
参考になりましたら幸いです。










