
DatabricksでS3に外部テーブルとして作成したDeltaテーブルにローカル環境のPythonからアクセスしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のueharaです。
今回は、DatabricksでS3に外部テーブルとして作成したDeltaテーブルにローカル環境のPythonからアクセスしてみたいと思います。
前提
私の手元環境では、以下のように workspace.default.sample_data_delta という外部テーブルを作成してあります。
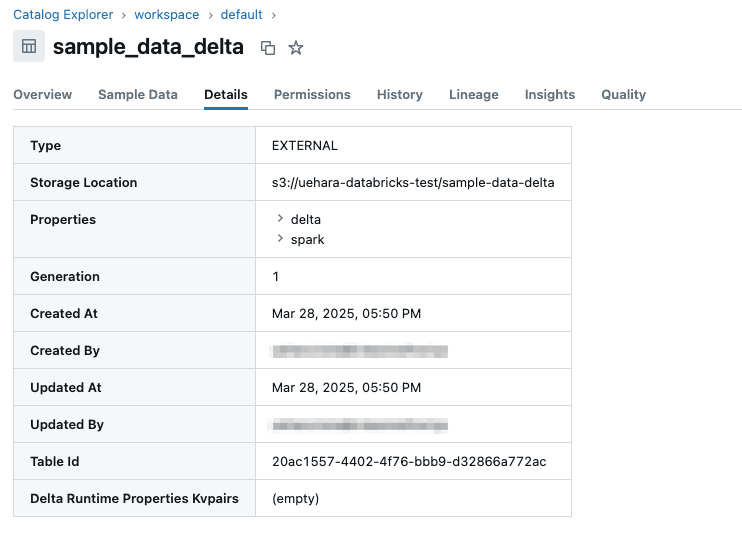
指定されているS3バケットにはDeltaフォーマットで以下のようにデータが格納されています。
sample-data-delta/
├── _delta_log/
│ ├── 00000000000000000000.crc
│ ├── 00000000000000000000.json
│ ├── _autostats/
│ │ └── 00000000000000000000.0000000000.stats.json
│ └── _commits/
├── yyyymmdd=20250327/
│ └── part-00001-71449f89-62b4-4d5e-95c9-77df7bd159e6.c000.snappy.parquet
└── yyyymmdd=20250328/
└── part-00000-6b34c5c2-962b-483b-9310-d11a533bf187.c000.snappy.parquet
アクセス方法について
Unity Catalogを利用している前提で、Unity Catalogオブジェクトとそのアクセスパターンは以下の通りです。(参考)

この内、外部テーブル(External tables)の場合は以下の選択肢があります。
- Unity REST API
- Iceberg REST catalog
- Delta Sharing
- cloud URIs
今回は特に cloud URIs と Unity REST API を利用してローカル環境のPythonからDeltaテーブルのデータにアクセスしてみたいと思います。
cloud URIsの利用
cloud URIsの利用とは、すなわちS3のエンドポイントを利用して "Databricksを介さずに" 直接Deltaテーブルにアクセスする形になります。
今回はPythonからDuckDBを利用してアクセスしようと思います。
DuckDBは pip を利用して、以下でインストール可能です。
$ pip install duckdb
duckdbではDelta Lakeがサポートされており、S3からデータを読み込むこともできます。
こちらを利用し、今回は以下のようなスクリプトを作成しました。
import duckdb
# DuckDB接続を作成
con = duckdb.connect()
create_secret_query="""
CREATE OR REPLACE SECRET s3_secret (
TYPE s3,
PROVIDER credential_chain,
CHAIN env
);
"""
# DeltaテーブルがあるS3のパス
s3_path = "s3://uehara-databricks-test/sample-data-delta/"
try:
# シークレットの作成
con.execute(create_secret_query)
# S3上のDeltaテーブルを読み込む
query = f"SELECT * FROM delta_scan('{s3_path}')"
print(f"SQL: {query}")
# クエリを実行してpandas DataFrameに変換
df = con.execute(query).fetchdf()
print(df.to_string(index=False))
except Exception as e:
print(f"Error accessing Delta table at {s3_path}: {e}")
finally:
# 接続を閉じる
con.close()
delta_scan('{s3_path}') としている部分では CREATE OR REPLACE SECRET s3_secret... で指定している通り、環境変数に設定したアクセスキーとシークレットアクセスキーが必要となります。
今回は以下のようにAWS STSを利用し一時認証情報を取得して環境変数に設定し、作成したPythonスクリプトを実行するBashスクリプトを用意しました。(IAMロールには自己信頼ポリシーを追加しておく必要があります)
#!/usr/bin/env bash
set -euo pipefail
PROFILE=$1
unset AWS_PROFILE
export AWS_SDK_LOAD_CONFIG=true
ROLE_ARN=$(aws --profile ${PROFILE} configure get role_arn)
STS_RESULT=$(aws --profile ${PROFILE} sts assume-role --role-arn ${ROLE_ARN} --role-session-name sls-deploy-session --duration-seconds 3600)
export AWS_ACCESS_KEY_ID=$(echo ${STS_RESULT} | jq -r '.Credentials.AccessKeyId')
export AWS_SECRET_ACCESS_KEY=$(echo ${STS_RESULT} | jq -r '.Credentials.SecretAccessKey')
export AWS_SESSION_TOKEN=$(echo ${STS_RESULT} | jq -r '.Credentials.SessionToken')
export AWS_REGION='ap-northeast-1'
python sample_1.py
実行コマンドは次のようになります。
$ bash get_secret_and_execute_py.sh <YOUR-AWS-PROFILE>
結果は以下の通りで、無事テーブルのデータを読み込むことができました。

【重要】注意点
Deltaテーブルを読み込むためのPythonライブラリとして、有名なものに deltalake というものがあります。
当初はこちらのライブラリを使用しようと思っていたのですが、いざ実行してみると次のようなエラーが表示されました。
The table has set these reader features: {'deletionVectors'} but these are not yet supported by the deltalake reader.
このエラー、どうやら deltalake ライブラリでは裏側で delta-rs というRust製のライブラリを利用しているようなのですが、こちらが削除ベクトルに対応していないことに起因するもののようです。
以下のようにGitHubでissueも上がっていました。
Databricksで新規作成するテーブルは、SQL warehouse/Databricks Runtime 14.1以上では削除ベクトルがデフォルトで有効になっているため、私がサンプルで作成したテーブルについてもこの機能が有効になっているようでした。
どうしても deltalake ライブラリを利用したい、という方は、いまいまはこの削除ベクトル機能を無効化してテーブルを作成しておく必要がありそうです。
なお、DuckDBでは delta-kernel-rs という削除ベクトルにも対応しているライブラリを利用しているので読み取りはできるのですが、こちらはまだ開発途中のライブラリのようで記事執筆時点では書き込みには対応していないことに注意して下さい。
※DuckDBでも read support と明言されています。
また、削除ベクトルが有効になっているテーブルではIceberg読み取りができませんので、そちらもご注意下さい。(参考)
Unity REST APIの利用
今度はUnity REST APIを利用します。すなわち、 "Databricksを介した" アクセス方法になります。
Unity REST APIを利用するために便利なライブラリとしてDatabricks SDK for Pythonがあるのでこちらを利用して実装します。
SDKは pip を利用して、以下コマンドでインストール可能です。
$ pip install databricks-sdk
実行の前段階として、以下の通りDatabricksのHost名とアクセストークンを環境変数に設定しておきます。
$ export DATABRICKS_HOST=dbc-xxxxxxxx-xxxx.cloud.databricks.com
$ export DATABRICKS_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
import time
import pandas as pd
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.sql import StatementState
# SQL warehouseのID
WAREHOUSE_ID = "<YOUR WAREHOUSE ID>"
# Databricks SDKクライアント初期化
w = WorkspaceClient()
try:
# SQLの実行
sql_query = "SELECT * FROM workspace.default.sample_data_delta"
print(f"SQL: {sql_query}")
resp = w.statement_execution.execute_statement(
statement=sql_query,
warehouse_id=WAREHOUSE_ID,
wait_timeout='50s' # タイムアウト設定 (例: 50秒)、 '0s' で非同期実行
)
# 実行ステータスの確認
statement_id = resp.statement_id
print(f"Statement ID: {statement_id}")
print(f"Current state: {resp.status.state}")
if resp.status.state in (StatementState.SUCCEEDED, StatementState.FAILED, StatementState.CANCELED, StatementState.CLOSED):
print("Statement execution finished.")
else:
# 通常wait_timeoutを設定すれば完了を待つが、指定時間内で処理が完了せずポーリングが必要な場合
# (非同期実行でも同様の処理となる)
while resp.status.state in (StatementState.PENDING, StatementState.RUNNING):
print("Waiting for statement execution to complete...")
time.sleep(5)
resp = w.statement_execution.get_statement(statement_id=statement_id)
print(f"Current state: {resp.status.state}")
# 結果の取得
if resp.status.state == StatementState.SUCCEEDED:
print("Fetching results...")
# ステートメント情報を取得して列名を抽出
statement_info = w.statement_execution.get_statement(statement_id=statement_id)
column_names = [col.name for col in statement_info.manifest.schema.columns]
# 最初のチャンクのデータを取得(すでにstatement_infoに含まれている)
data = statement_info.result.data_array
df = pd.DataFrame(data, columns=column_names)
# 次のチャンクのデータがあるのであれば取得
next_chunk_index = statement_info.result.next_chunk_index
while next_chunk_index is not None:
print(f"Fetching chunk {next_chunk_index}...")
chunk_result = w.statement_execution.get_statement_result_chunk_n(
statement_id=statement_id,
chunk_index=next_chunk_index
)
if chunk_result.data_array:
# 追加データをDataFrameに追加
next_df = pd.DataFrame(chunk_result.data_array, columns=column_names)
df = pd.concat([df, next_df], ignore_index=True)
next_chunk_index = chunk_result.next_chunk_index
# 結果の表示
print(df.to_string(index=False))
elif resp.status.state in (StatementState.FAILED, StatementState.CANCELED, StatementState.CLOSED):
print(f"Statement execution did not succeed: {resp.status.state}")
if resp.status.error:
print(f"Error message: {resp.status.error.message}")
except Exception as e:
print(f"An error occurred: {e}")
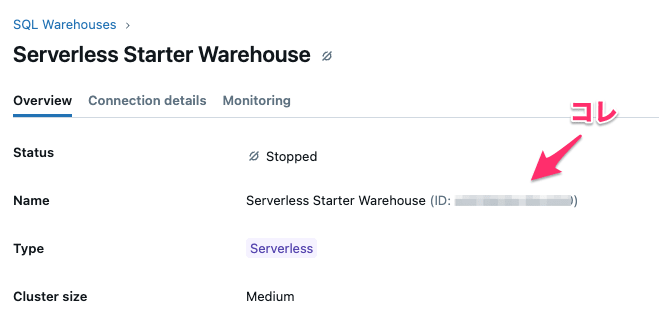
<YOUR WAREHOUSE ID>となっている部分については、ご自身の環境を確認して下さい。
※Databricksのトップ画面から左側タブにある『Compute』に遷移して確認可能です。
プログラムを簡単に説明すると、まず wait_timeout でクエリ実行をリクエストしてからの待機秒数を指定しています。
この wait_timeout を設定すると、呼び出しは指定されたタイムアウトまで結果を待機します。
コメントにも書いてますが、これを 0s で設定すると非同期実行になります。
wait_timeout で指定した秒数が過ぎた後や、非同期実行の場合は返される statement_id の実行状態をポーリングして確認する形になります。(クエリが実行中であれば数秒待って、再度実行状態を確認しにいく)
※状態には以下の6つがあります。
- CANCELED
- CLOSED
- FAILED
- PENDING
- RUNNING
- SUCCEEDED
なお、オプションの設定で wait_timeout の時間が過ぎたらクエリをキャンセルする、といった動きも指定できます。(詳しくはSDKのドキュメントをご確認下さい)
また、結果についても必ずしも一度で取得できるわけではなく、量が多ければチャンク毎に処理をする必要があります。
したがって、レスポンスの next_chunk_index を確認しながら、次のデータがあるようであれば取得しにいくという動作を入れています。
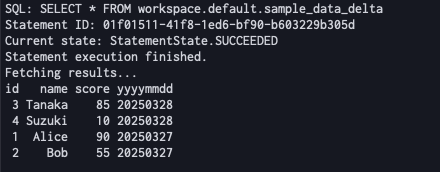
本スクリプトを実行すると、以下のように結果が得られました。
最後に
今回は、DatabricksでS3に外部テーブルとして作成したDeltaテーブルにローカル環境のPythonからアクセスしてみました。
参考になりましたら幸いです。










