
【Databricks】自然言語を用いて分析・可視化ができるAI/BI Genieを試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のueharaです。
今回は、DatabricksのAI/BI Genieを試してみたいと思います。
AI/BI Genieとは
AI/BI Genieは、Databricks上のデータに対して自然言語を用いて検索、分析、可視化を行うことができる機能です。
生成AIと大規模言語モデル(LLM)を活用することで、ユーザーはBIツールやSQLの扱いを学んでいなくても、データからインサイトを得ることができます。
検証データの用意
データセットの用意
今回の検証では『MovieLens』というデータセットを使いたいと思います。
MovieLensデータセットは映画作品レビューサイトの作品評価データで、今回はその中でも開発用の規模の小さいデータを利用します。
まず、こちらのページから「MovieLens Latest Datasets」の「ml-latest-small.zip」をダウンロードします。

ダウンロードしたファイルを展開すると movies.csv と ratings.csv があると思うので、今回はこちらを利用します。
私はUnity Catalogと連携しているS3バケットに上記2ファイルを配置しました。
テーブルの作成
movies.csv と ratings.csv を利用し、 movielens というスキーマ配下にそれぞれテーブルを作成しました。

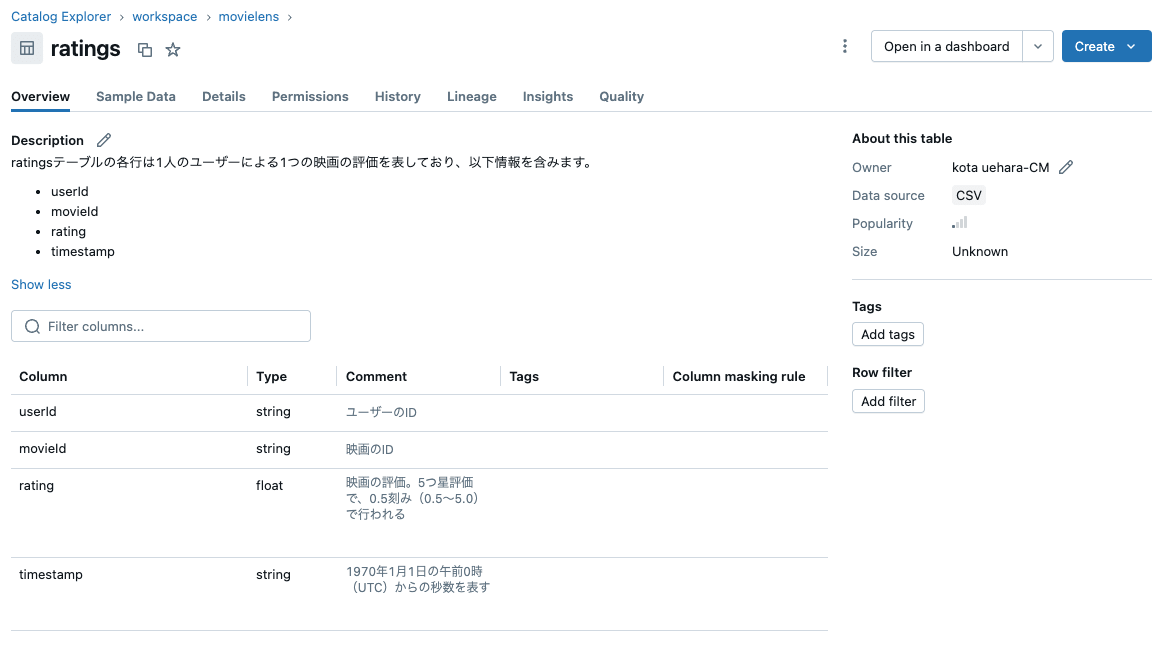
Genieではカタログのメタデータを利用してクエリを生成するため、Catalog Explorerでテーブルの説明やカラムの説明を追記します。(こちらはMovieLensのデータセットの README.txt をベースに記載しています)
( movies は以下の通り)

( ratings は以下の通り)
AI/BI Genieを起動
データの用意ができたので、実際に動かしてみます。
Databricksトップの左側のタブから『Genie』を選択し、新しくスペースを作成します。
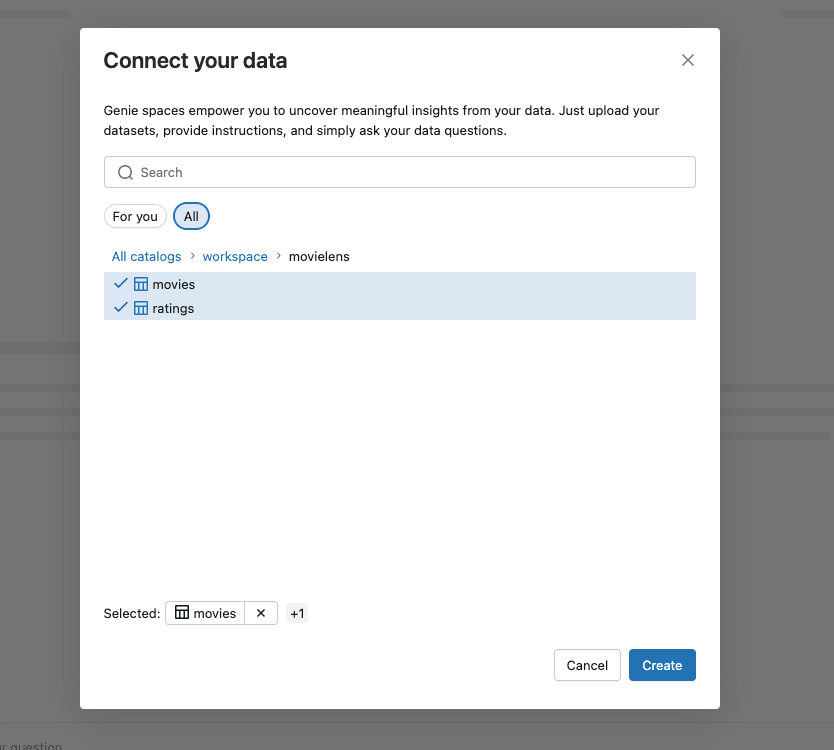
利用するスキーマやテーブル等の確認のダイアログが表示されるので、以下の通り先に作成した movielens スキーマ配下の2つのテーブルを選択します。
トップ画面は以下のようになっています。(スペース名はデフォルトのものから MovieLens Test Space に変更しています)
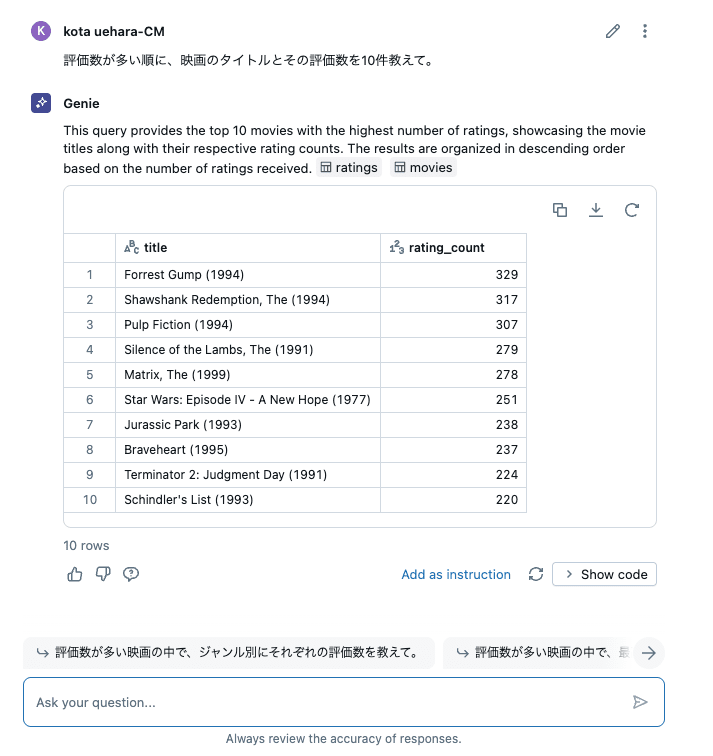
まず、以下のような質問をしてみました。
評価数が多い順に、映画のタイトルとその評価数を10件教えて。
上記は movies テーブルと ratings テーブルのJOINが必要な内容になります。
結果は次の通りで、回答文が英語にはなっていますが正しい結果が返ってきました!
『Show code』ボタンを押せば実際に作成して実行したクエリを確認できます。
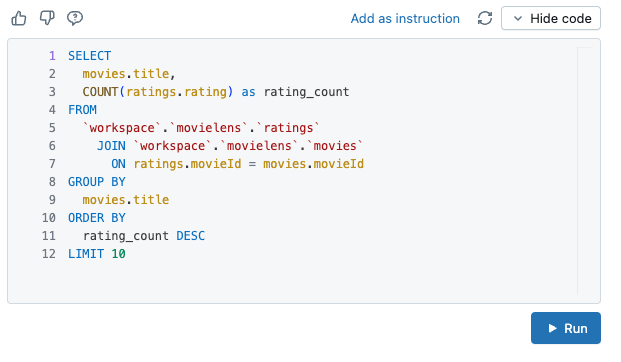
ここでクエリを一部修正して再実行などもできるので、かなり便利です。
次に可視化も試してみます。
以下のような質問をしてみました。
評価毎の件数のヒストグラムが見たい
結果は次の通りで、こちらもしっかり確認したい情報が提示されました。
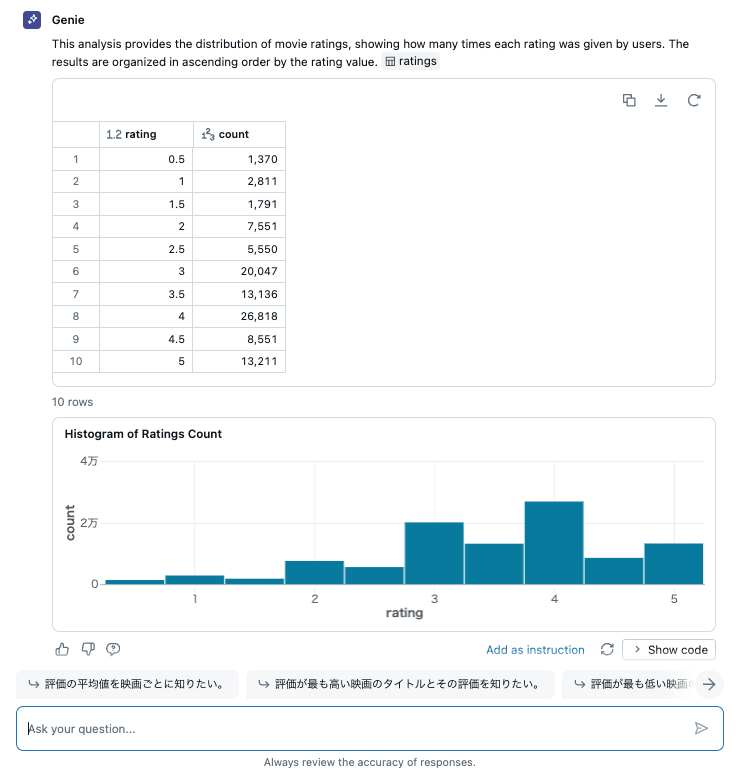
今度は別のグラフを作成するため、以下のような質問をしてみました。
映画ジャンル全体に占める各ジャンルの割合を円グラフで教えて
結果は次の通りで、こちらも期待するグラフが出力されました。
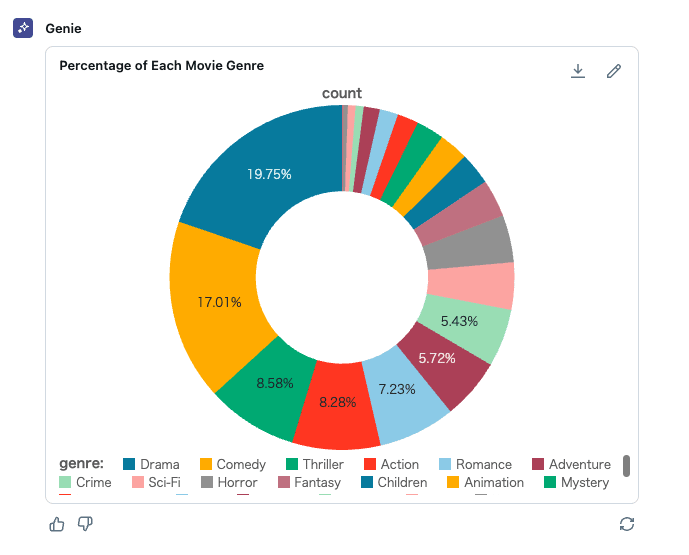
今回試したのは比較的簡単なデータセットでしたが、エンジニア目線でもパッとデータの特性を確認したりするのに便利だなと感じました。
別画面で生成AIのプロンプトを立ち上げて似たような作業をすることもできますが、その場合
- テーブル情報を伝える
- 生成したいクエリを伝える
- 作成されたクエリを画面に貼り付ける
- ダッシュボードを作成して確認する
という作業手順を通常踏まなければならないので、このようにDatabricks上だけで簡潔に作業がまとまるのはとても良いなと感じました。
最後に
今回は、DatabricksのAI/BI Genieを試してみました。
参考になりましたら幸いです。








