
dbt CloudでDev/QA/Prodで環境分離した開発プロセスを考えてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
さがらです。
dbt CloudでDev/QA/Prodで環境分離した開発プロセスを考えてみたので、本記事でまとめてみます。
2025年3月11日追記
QA EnvironmentのSet deployment typeをStagingではなくGeneralにすることで、IDEからdbt cloneをする際にProd環境を参照できるようになったため、その内容に併せて修正しています。
これにより、QA EnvironmentでProd EnvironmentをCloneするDeploy Jobが不要となり、よりスムーズな開発プロセスとなりました!
前提条件
まず、Dev/QA/Prodという環境分離を行って、どのようなユースケースにデータを使いどのように環境を使い分けるのか、前提を定義しておきます。(あくまで本記事を書く上での一例です。)
- このデータのユースケース
- データアプリ上でこのデータを用いて可視化しており、外部ユーザーに提供している
- 各環境の用途
- Dev
- 各ユーザーが新しいデータを開発する環境
- データアプリと繋いでの可視化検証まで行いたい場合は、ローカルのDocker等でアプリを立ち上げて検証する。この際、Dev用のスキーマにも全テーブル・ビューの用意が必要
- QA
- ローカル環境だと検証が難しい負荷試験や脆弱性診断などを行う環境。アプリはAWS等のクラウド上で動作しているため、アプリから参照させるためにQA用のスキーマにも全テーブル・ビューの用意が必要
- Prod
- 実際に外部ユーザーに参照させる本番環境
- Dev
また、データベースとスキーマの構成は下記のように考えるとします。
- 使用するDWH
- Snowflake
- データベース構成:以下の2つのデータベースを用意
- dbt用のデータベース
- Rawデータ管理用のデータベース
- dbt用データベースのスキーマ構成:以下の構成でスキーマを用意
- prod_(staging/dwh/mart)_(データ種別など)
- 実際に外部ユーザーに参照させる本番環境
- qa_(staging/dwh/mart)_(データ種別など)
- データアプリのQA環境と紐づけて、QA環境での各検証・試験を行う
- dbt_(各ユーザー名)
- dbt CloudのIDEで開発した各ユーザーのビルドしたテーブルなどを保持する
- prod_(staging/dwh/mart)_(データ種別など)
generate_schema_nameマクロとdbt_project.ymlの構成
先に、これらの構成を実現するためのdbt_project.ymlとgenerate_schema_nameマクロの構成について記します。
generate_schema_nameマクロ
-- Dev/QA/Prodの3環境で考える場合
-- 以下、dbt Cloud上で設定をするdefault_schema
-- Devのdefault_schema:dbt_<ユーザー名>
-- QAのdefault_schema:invalid_schema
-- Prodのdefault_schema:invalid_schema
{% macro generate_schema_name(custom_schema_name, node) %}
{% set default_schema = target.schema %}
{# targetが「prod」か「qa」の場合、「prod」か「qa」をprefixにつけた「custom_schema」に #}
{% if target.name in ['prod','qa'] and custom_schema_name is not none %}
{{ target.name }}_{{ custom_schema_name | trim }}
{# custom_schemaの定義なしの場合、「default_schema」に #}
{% elif custom_schema_name is none %}
{{ default_schema }}
{# 上述の条件に合致しない(targetが「prod」でも「qa」でないがcustom_schemaの定義あり、など)の場合、「default_schema」に #}
{% else %}
{{ default_schema }}
{% endif %}
{% endmacro %}
dbt_project.yml ※seedsとmodelsのみ
seeds:
dbt_4layer_datastack_test:
+database: sagara_4layer_test_onedb
+schema: seed_data
models:
dbt_4layer_datastack_test:
+database: sagara_4layer_test_onedb
+materialized: view # 下記以外のフォルダでModelを定義してしまった場合に、テーブルを作らないように
staging:
+materialized: view
jaffle_shop:
+schema: stg_jaffle_shop
dwh:
+materialized: table
finance:
+schema: dwh_finance
mart:
+materialized: table
finance:
+schema: mart_finance
intermediate:
+materialized: ephemeral
各Environmentとジョブの設定
次に、各Environmentとジョブの設定をしていきます。
ProdのEnvironment
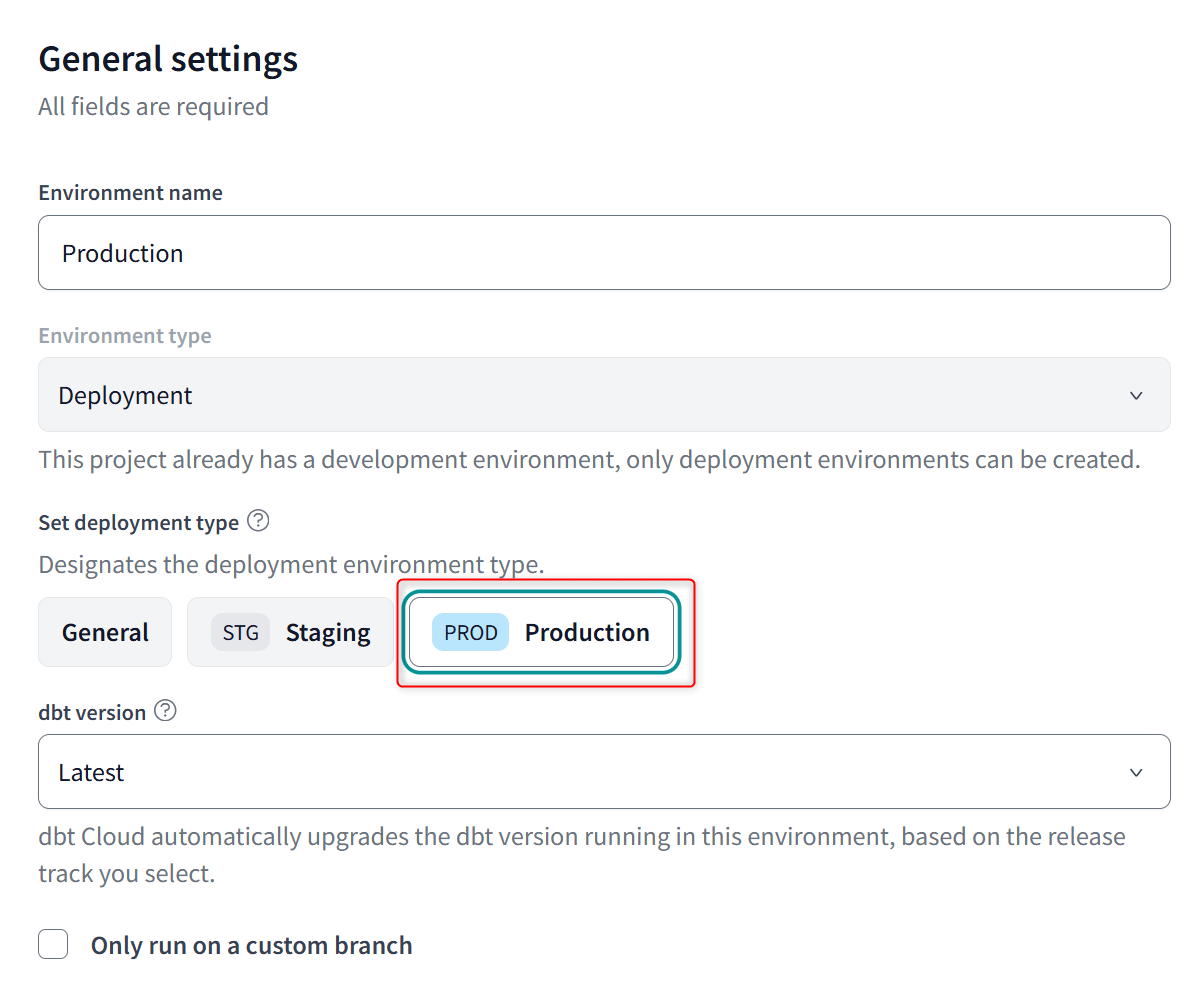
ProdのEnvironmentについてですが、以下の2点に注意して設定します。
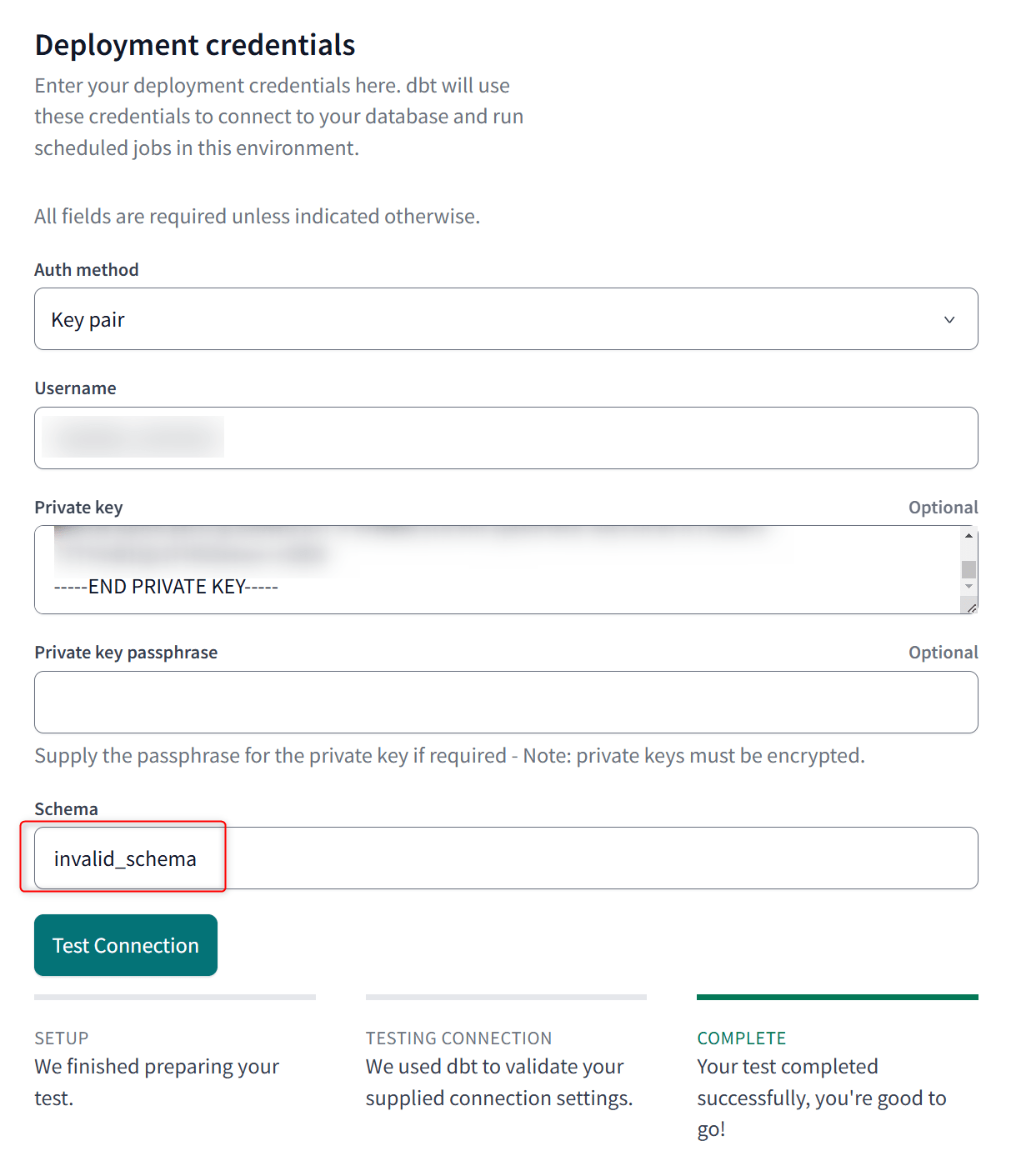
Set deployment type:ProductionDeployment credentialsのSchema:invalid_schema- 基本カスタムスキーマで出力先を定義するため、カスタムスキーマを定義していない場合は不適切なスキーマであることが明示的な
invalid_schemaスキーマに格納されるようにする
- 基本カスタムスキーマで出力先を定義するため、カスタムスキーマを定義していない場合は不適切なスキーマであることが明示的な
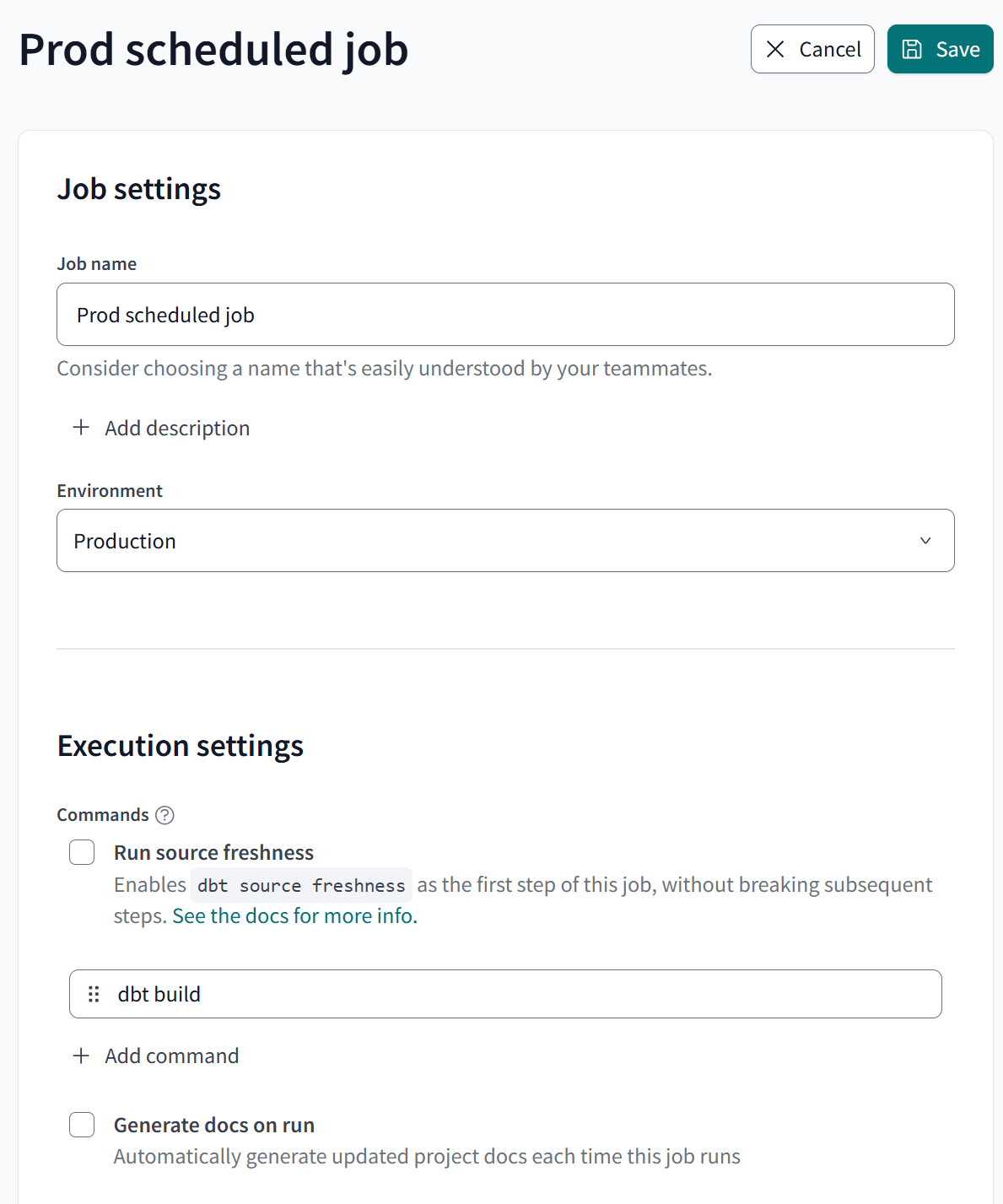
Prodのジョブ(定期実行してProd環境のデータを最新にするためDeploy job)
Prodのジョブについてですが、以下の2点に注意して設定します。このProdのジョブは、「Prod環境に定期的なスケジュールでデプロイする」という前提のジョブとなります。
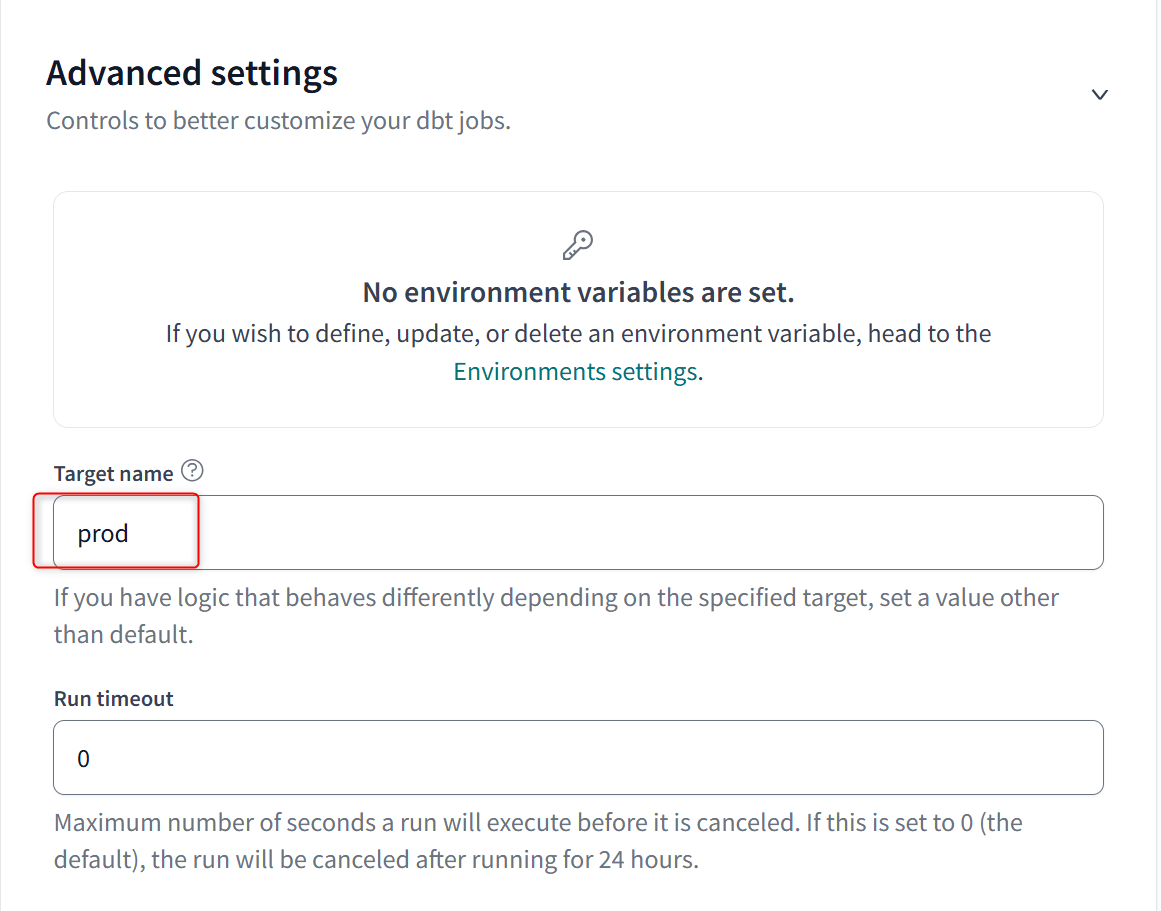
- 作成するジョブの種類:
Deploy job Execution settings:dbt buildを行うTarget name:prod
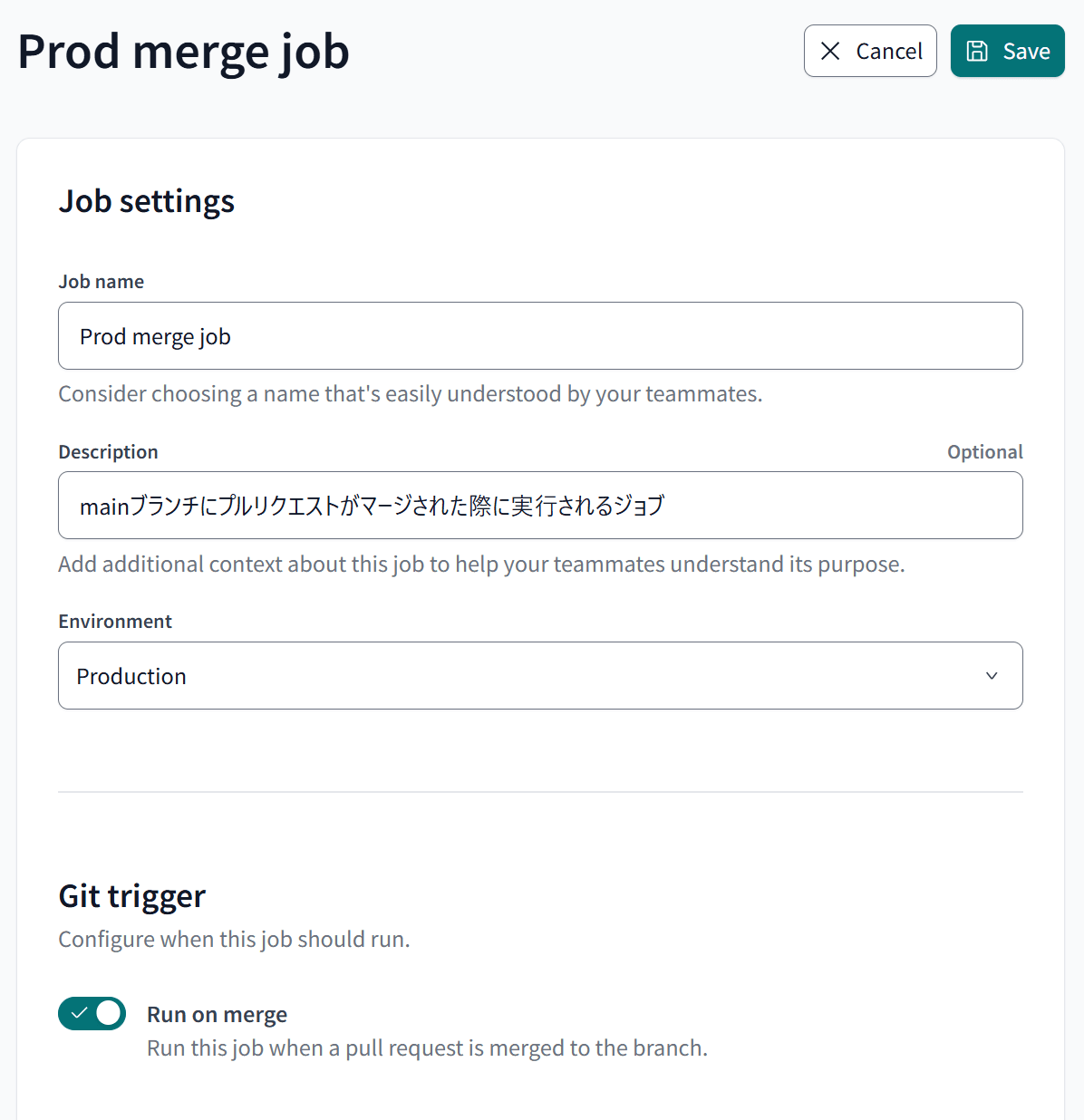
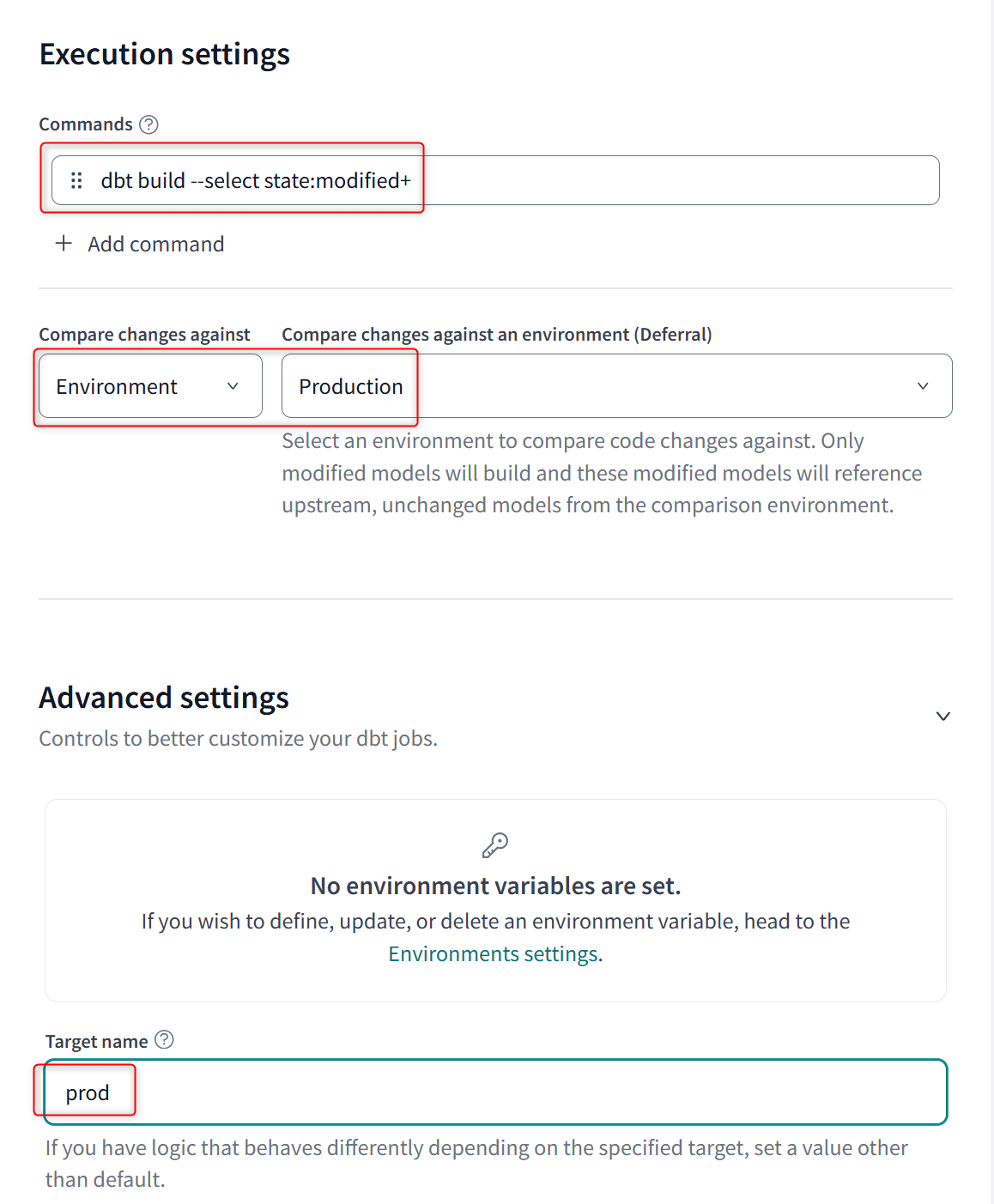
Prodのジョブ(プルリクエストをマージした際のMerge job)
Prodのジョブについてもう1つ別のジョブを、以下の3点に注意して設定します。このジョブは、「Prod環境のスキーマへ開発したデータをデプロイする」という前提のジョブとなります。そのため、スケジュール実行の設定は不要で、mainブランチへマージが行われた際に実行出来れば良いジョブとなります。
- 作成するジョブの種類:
Merge job Execution settings:dbt build --select state:modified+を行うCompare changes against an environment:Prodに設定したEnvironmentTarget name:prod
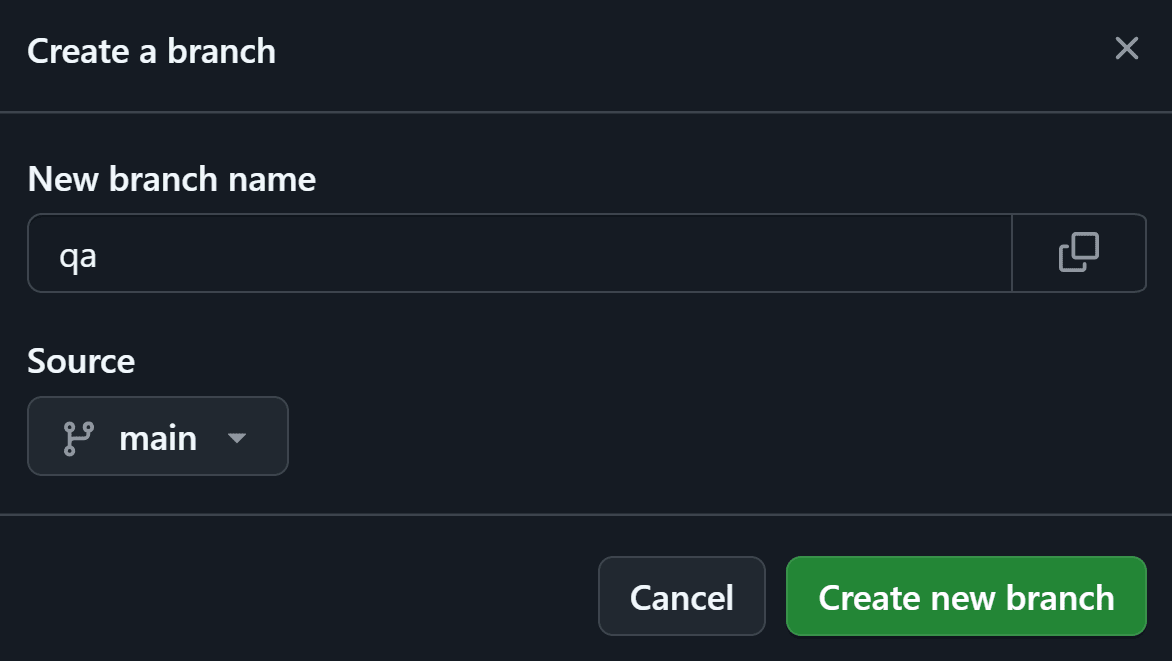
QAのブランチ作成
QA環境に該当するqaブランチをGitHub上で作成しておきます。
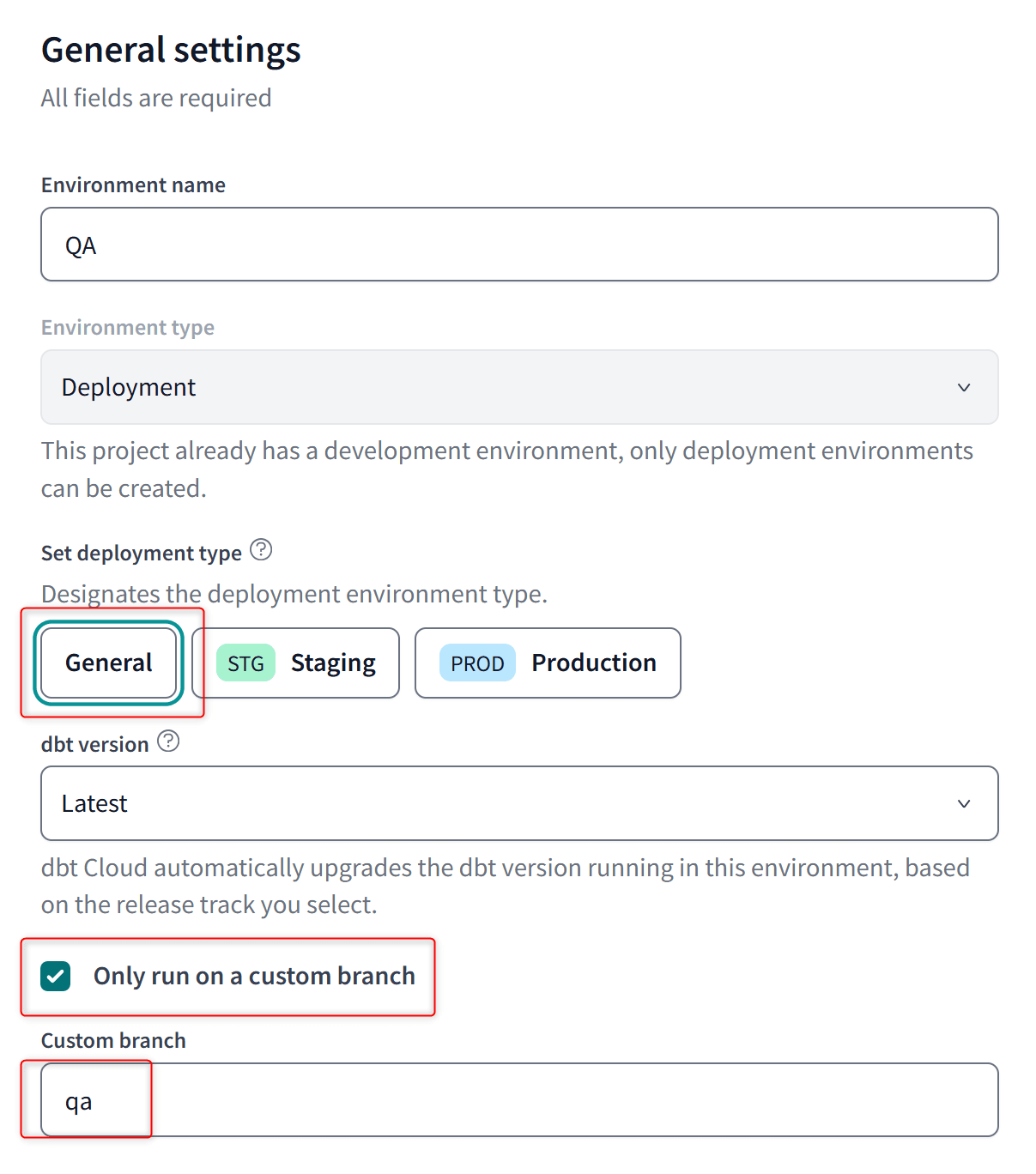
QAのEnvironment
QAのEnvironmentについてですが、以下の3点に注意して設定します。
Set deployment type:GeneralStagingにしないことがポイントです。Stagingにすると、IDEからのDefer先がこのEnvironmentになってしまい、dbt cloneなどstate比較が必要処理においてProd Environmentと比較できなくなってしまいます。
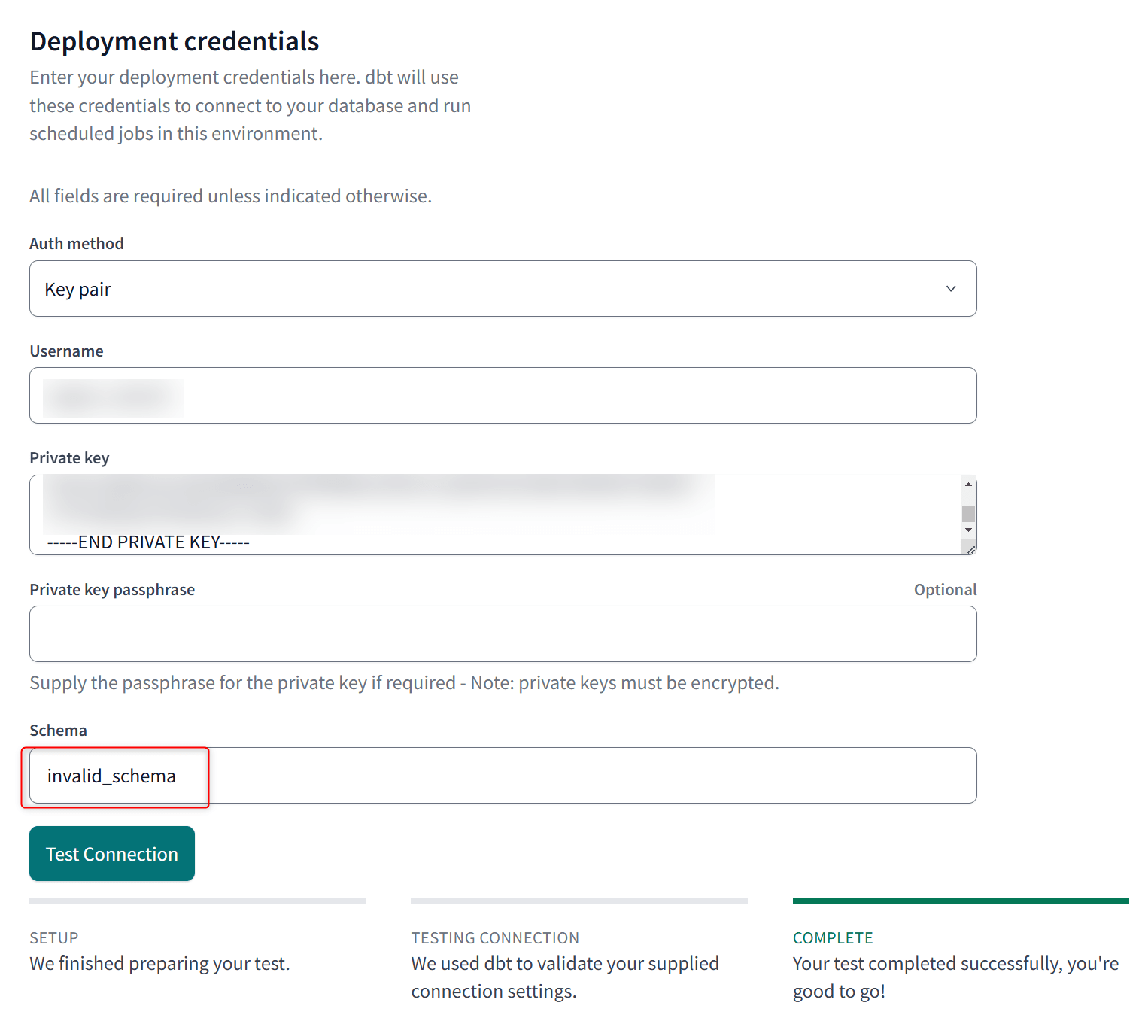
Custom branch:qaDeployment credentialsのSchema:invalid_schema- 基本カスタムスキーマで出力先を定義するため、カスタムスキーマを定義していない場合は不適切なスキーマであることが明示的な
invalid_schemaスキーマに格納されるようにする
- 基本カスタムスキーマで出力先を定義するため、カスタムスキーマを定義していない場合は不適切なスキーマであることが明示的な
QAのジョブ(プルリクエストをマージした際のMerge job)
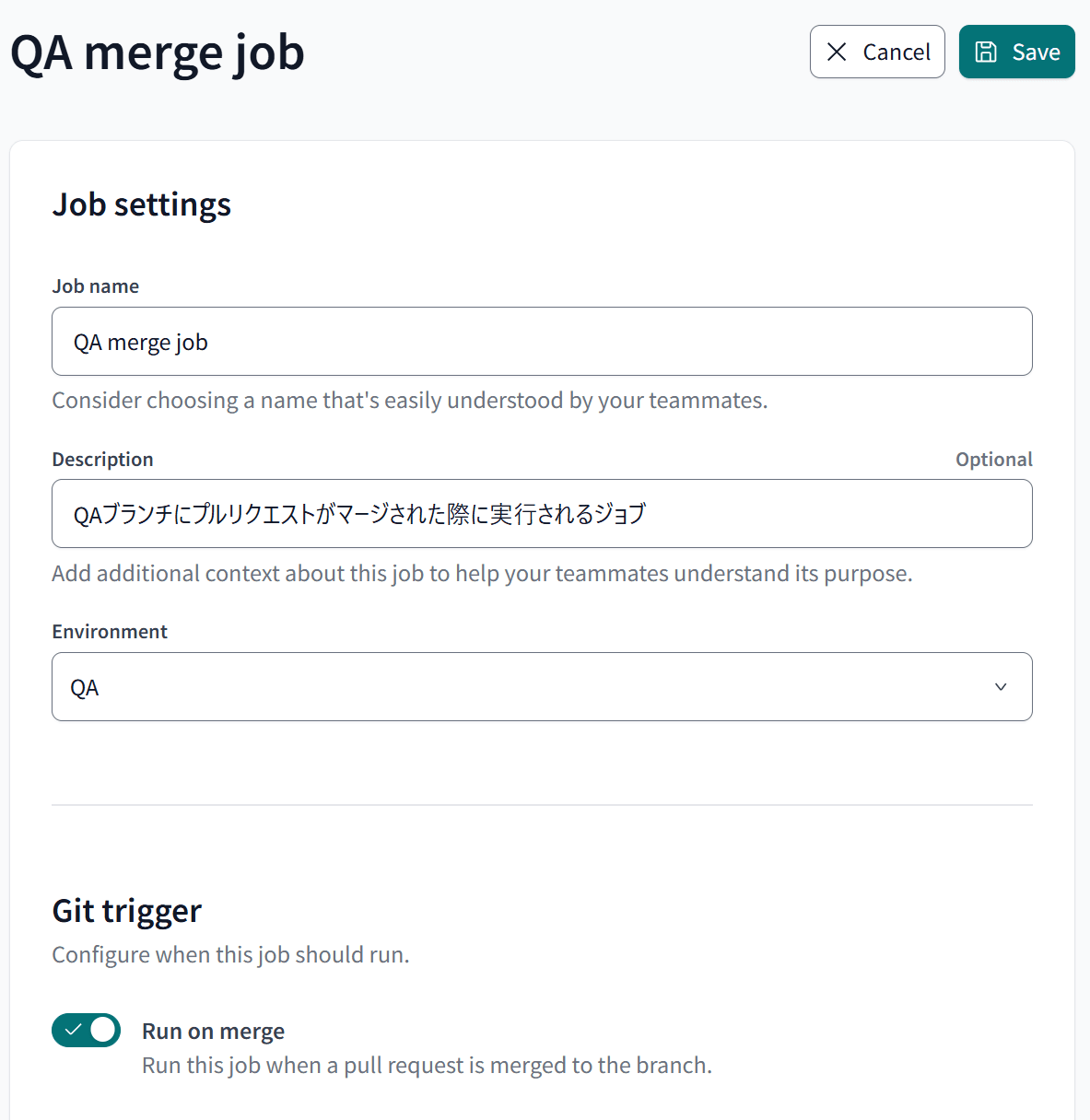
QAのジョブについてですが、以下の3点に注意して設定します。このQAのジョブは、「QA環境のスキーマへ開発したデータをテストするためデプロイする」という前提のジョブとなります。そのため、スケジュール実行の設定は不要で、qaブランチへマージが行われた際に実行出来れば良いジョブとなります。
- 作成するジョブの種類:
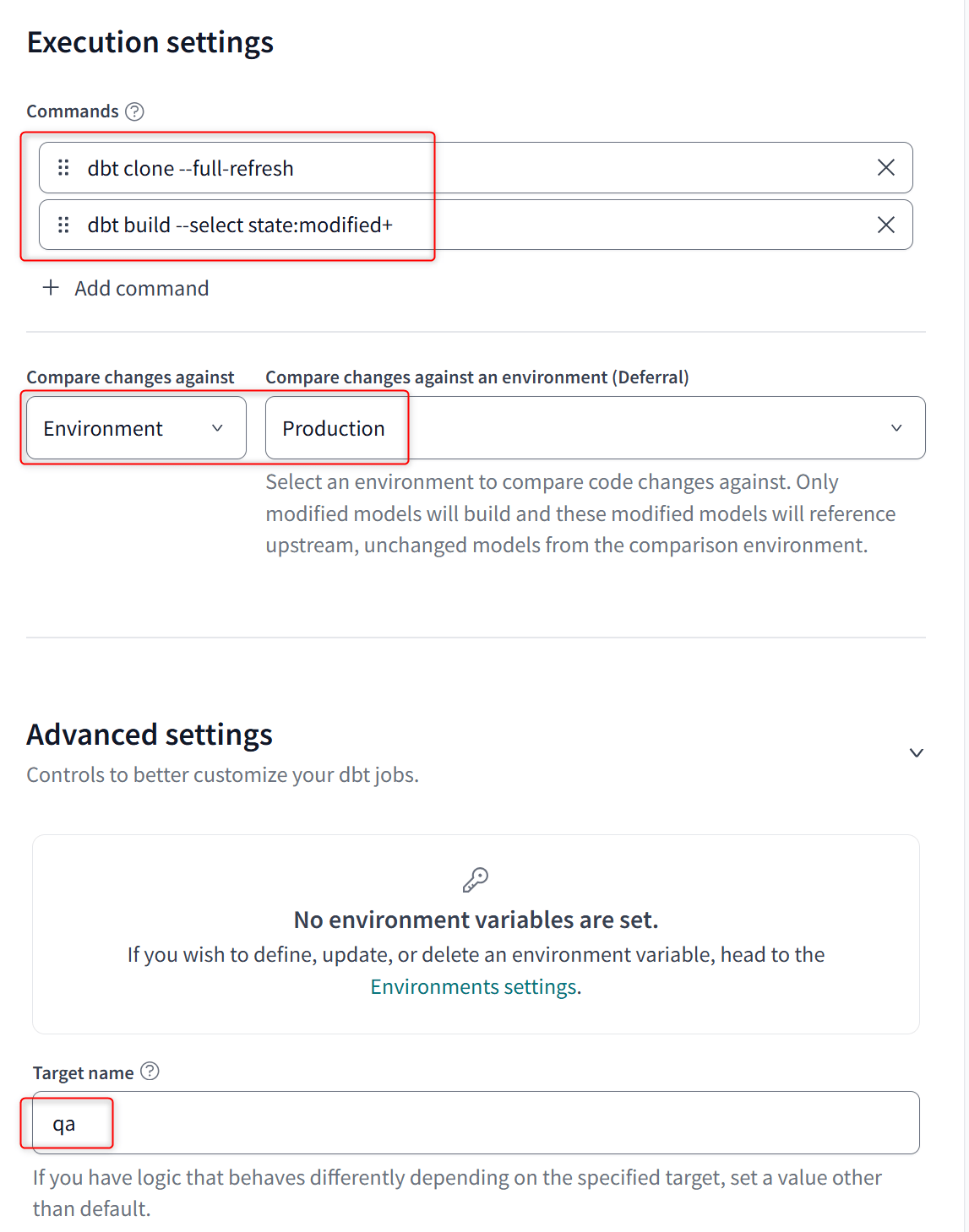
Merge job Execution settings:dbt clone --full-refreshのあとにdbt build --select state:modified+を行うCompare changes against an environment:Prodに設定したEnvironmentTarget name:qa
QAのジョブ(プルリクエスト発行時のCI job) ※任意
今回は割愛しますが、QA環境に対してはプルリクエスト発行時のCI jobを設定しても良いと思います。QA環境上でも各種テストをしますが、「そもそもdbtの各Modelは問題ないよね」ということを事前に確認するためにCIとしてビルド・テストを行うイメージです。
上述した「プルリクエストをマージした際のMerge job」と同じように、dbt clone --full-refreshのあとにdbt build --select state:modified+を行うようにすれば基本的には問題ないと思います。
CI jobの設定については下記のブログが参考になると思います。
実際の開発の流れを試してみた
事前準備:Prod Environmentで「定期実行してProd環境のデータを最新にするためDeploy job」を実行
実際に開発の流れを試す前に、一度Prod Environmentで「定期実行してProd環境のデータを最新にするためDeploy job」を実行しておきます。この理由は、既にProd環境にデータが存在する前提で開発の流れを試したいからです。
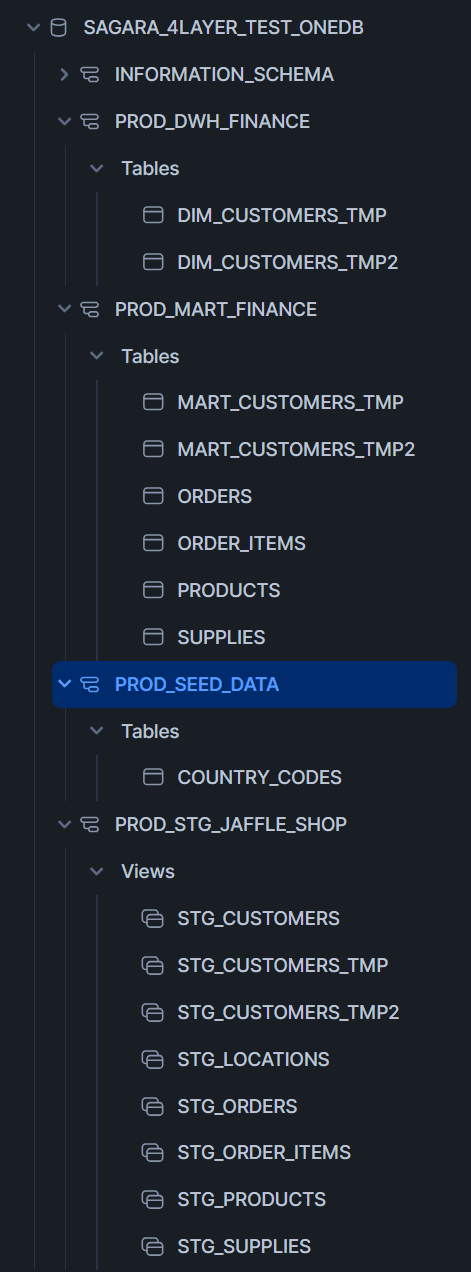
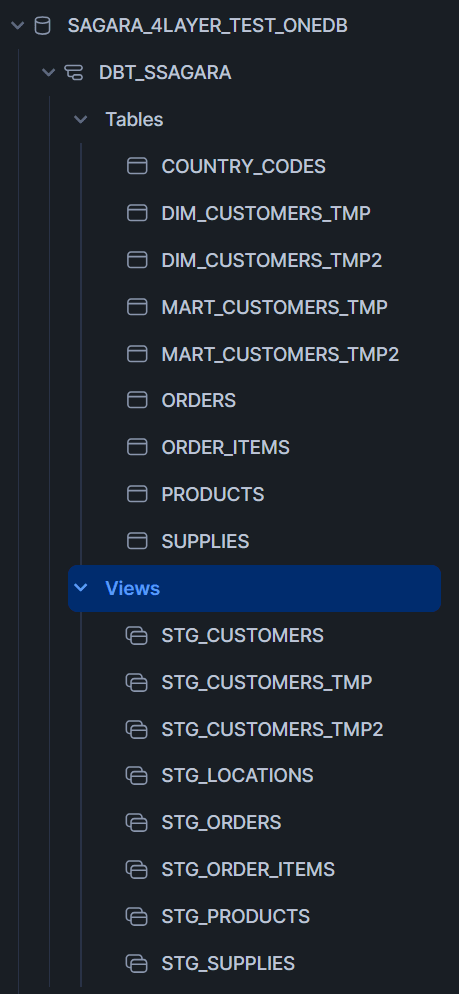
一度ジョブを実行すると、下図のようにPROD_のprefix付きで、seed・staging・dwh・martの各スキーマとテーブル・ビューが作られました。
IDEでブランチを切って開発
実際にブランチを切ってIDEで開発をしてみます。
ブランチを切った後に、dbt cloneを実行することで、Prod環境のスキーマに存在する各テーブル・ビューを自分専用のスキーマにクローンすることが出来ます。(もし既存のテーブル・ビューがあってそれも含めてcloneで置き換えたい場合は、dbt clone --full-refreshを実行しましょう。)
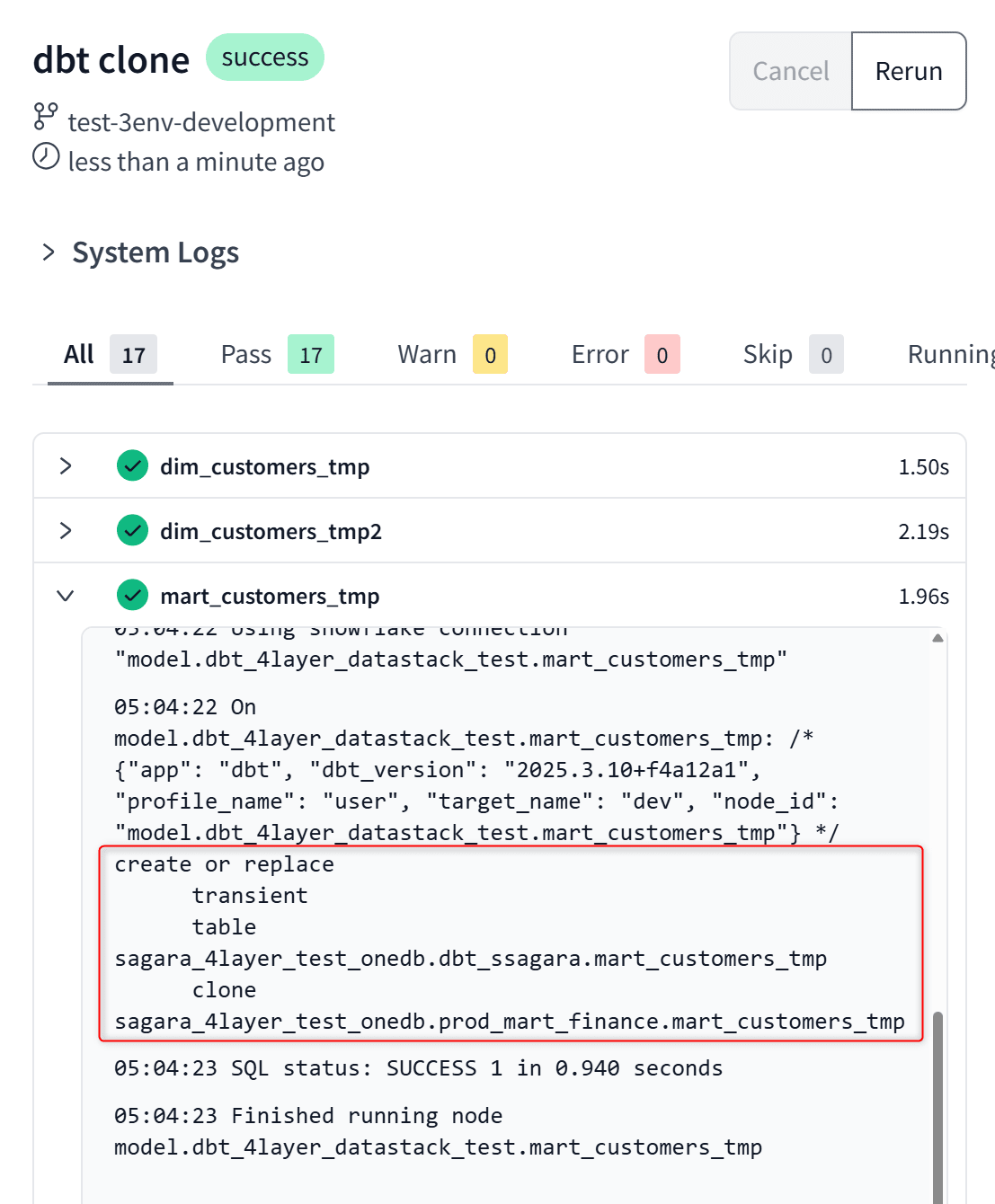
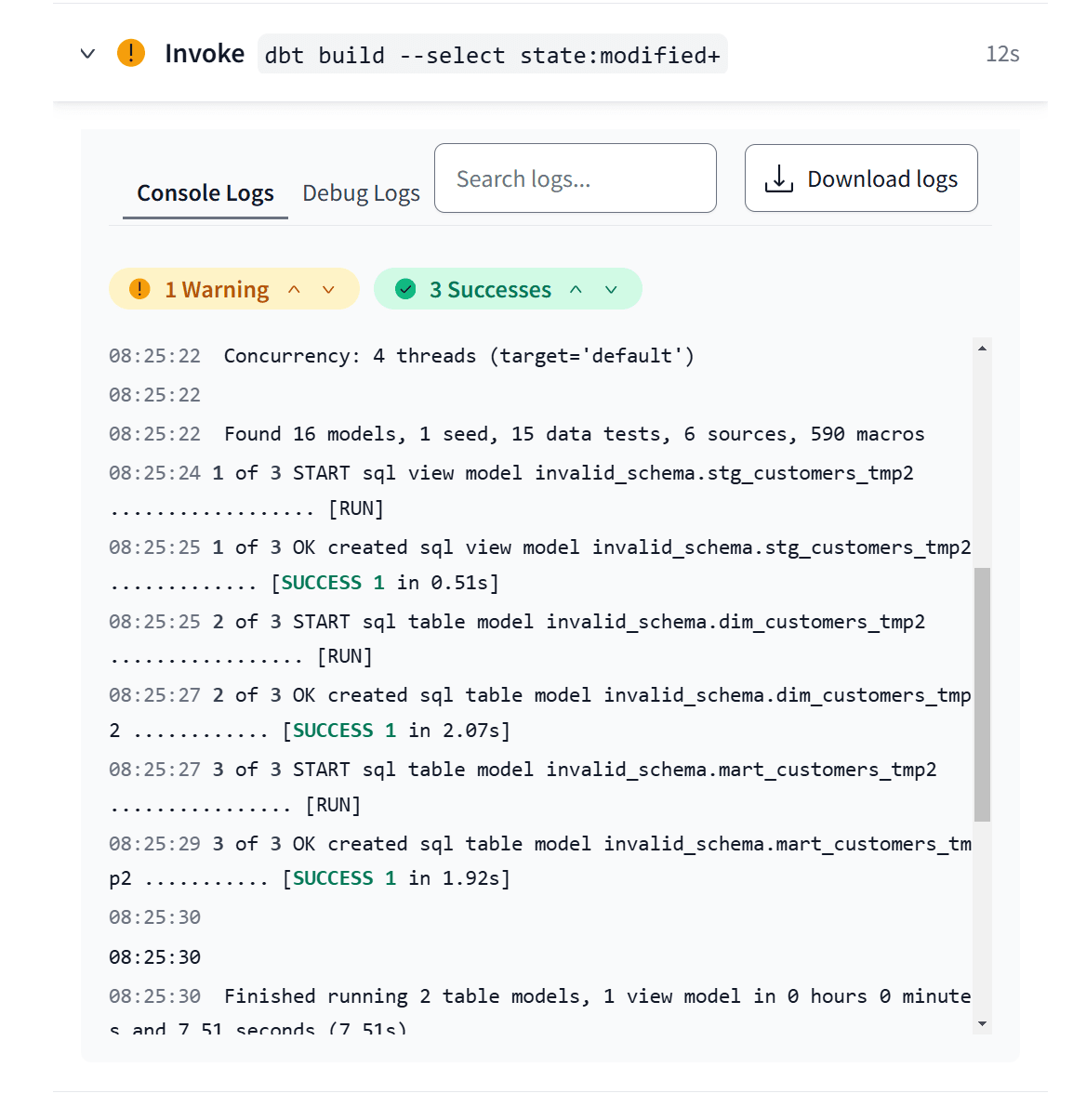
あとは通常通りの開発を行います。今回は既存のModelであるstg_customers_tmp2.sqlを少し書き換えて、IDE上でdbt build --select state:modified+を実行します。
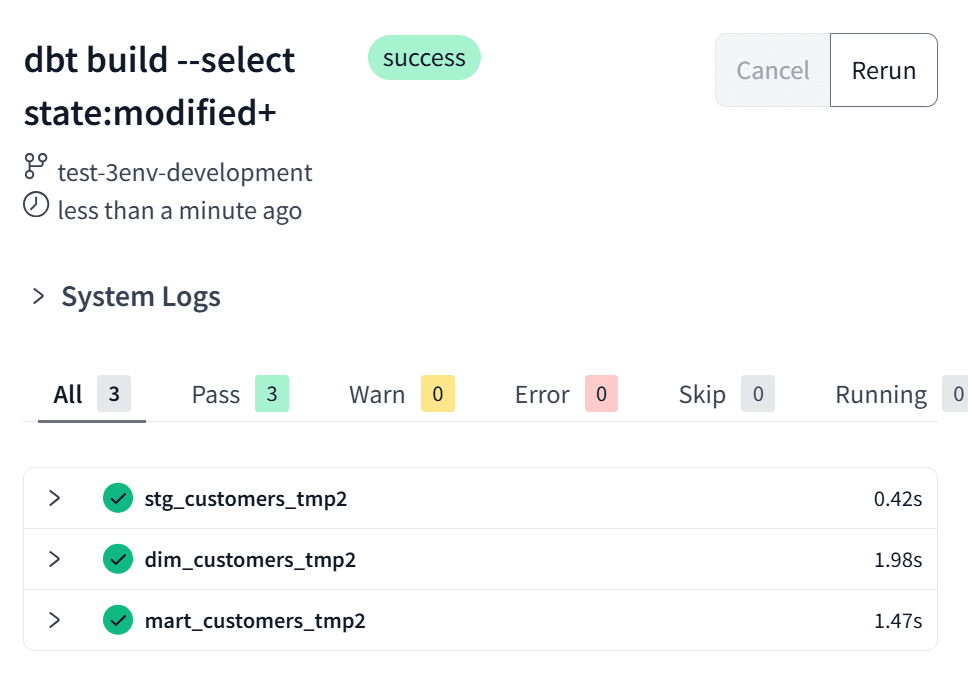
この後、自分専用のスキーマを参照させて、データアプリからの挙動確認も可能です。
プルリクエストを発行しQAブランチにマージ
次に、コミットしてQAブランチに対するプルリクエストを発行して、マージします。
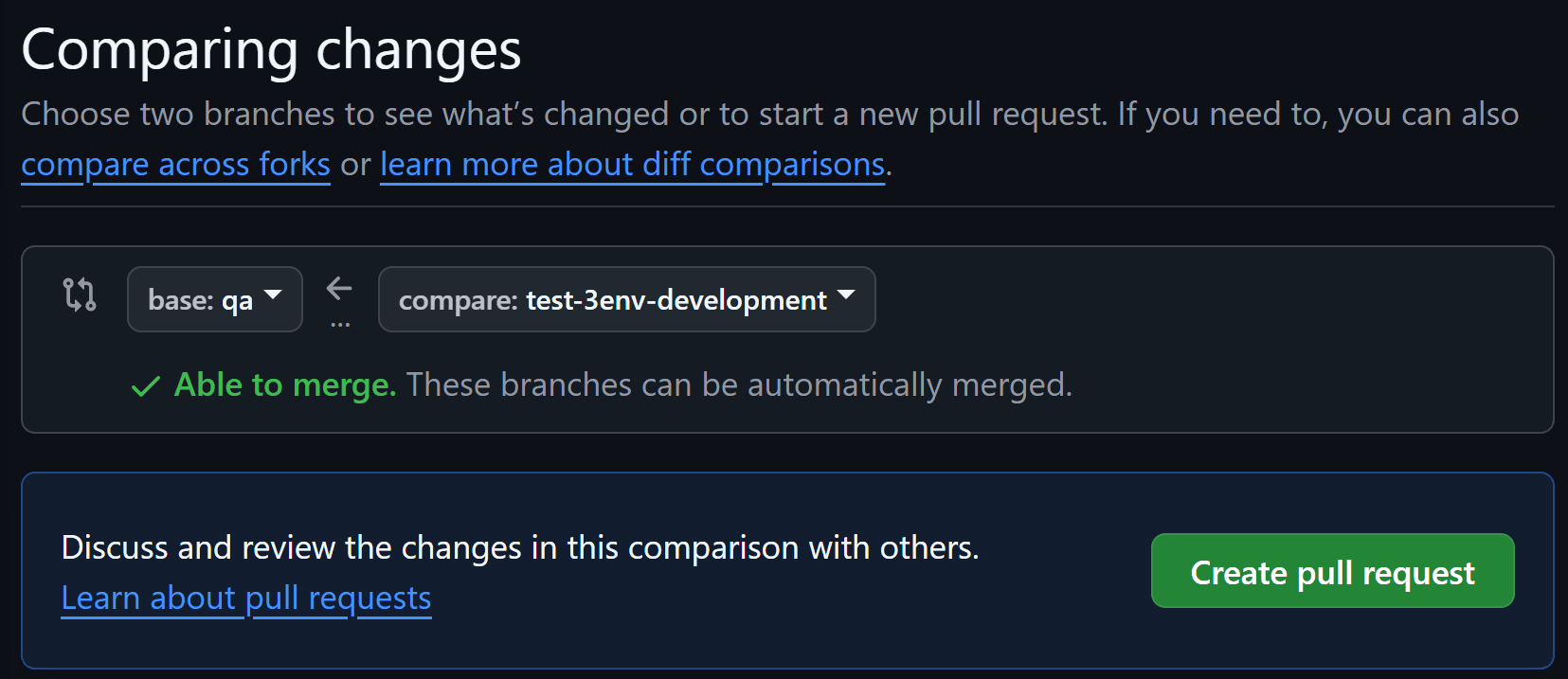
すると、QA Environmentで設定したMerge jobが実行されます。Prod EnvironmentのスキーマのCloneを行って、差分があるModelだけがQA Environmentのスキーマにビルドされます。
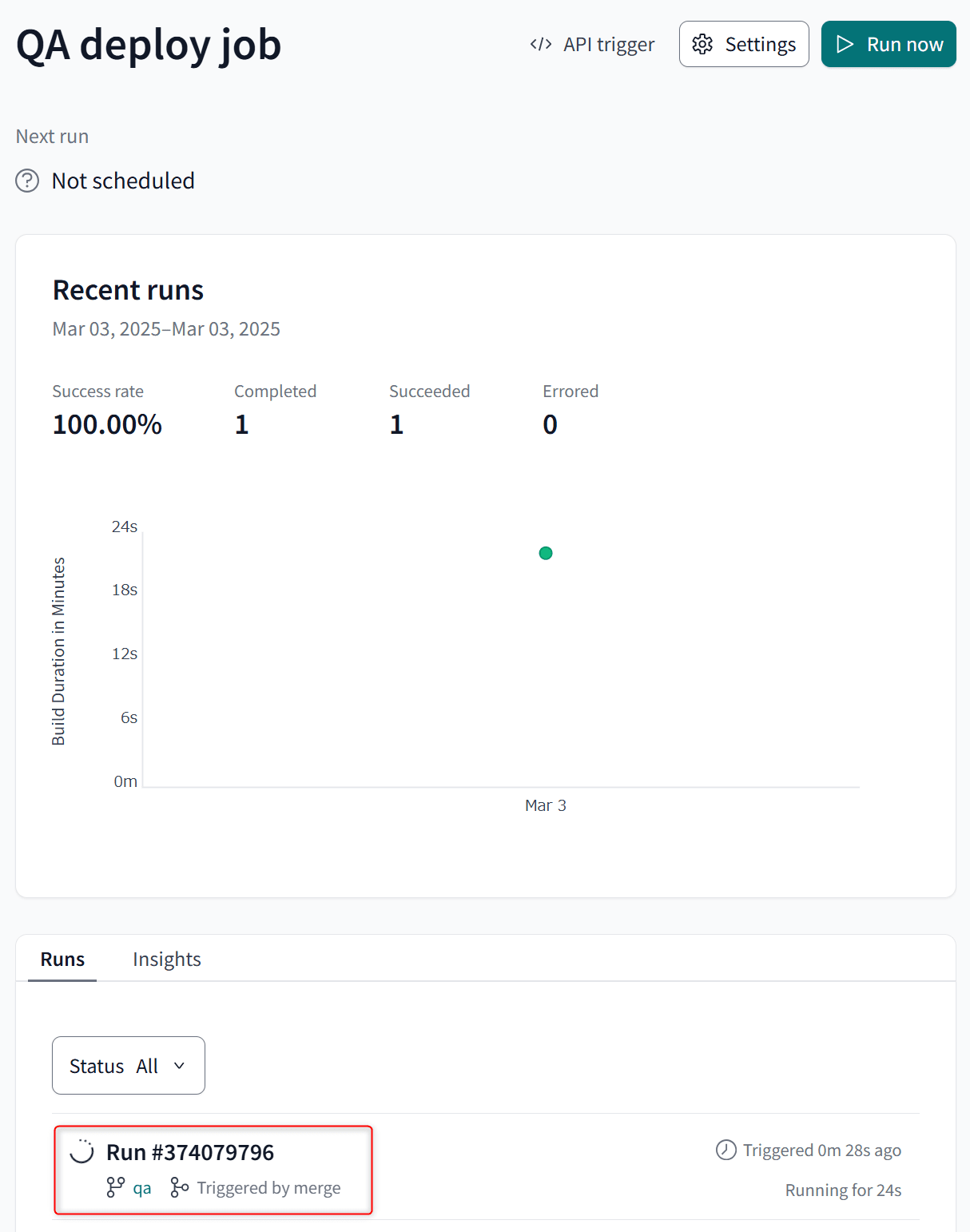
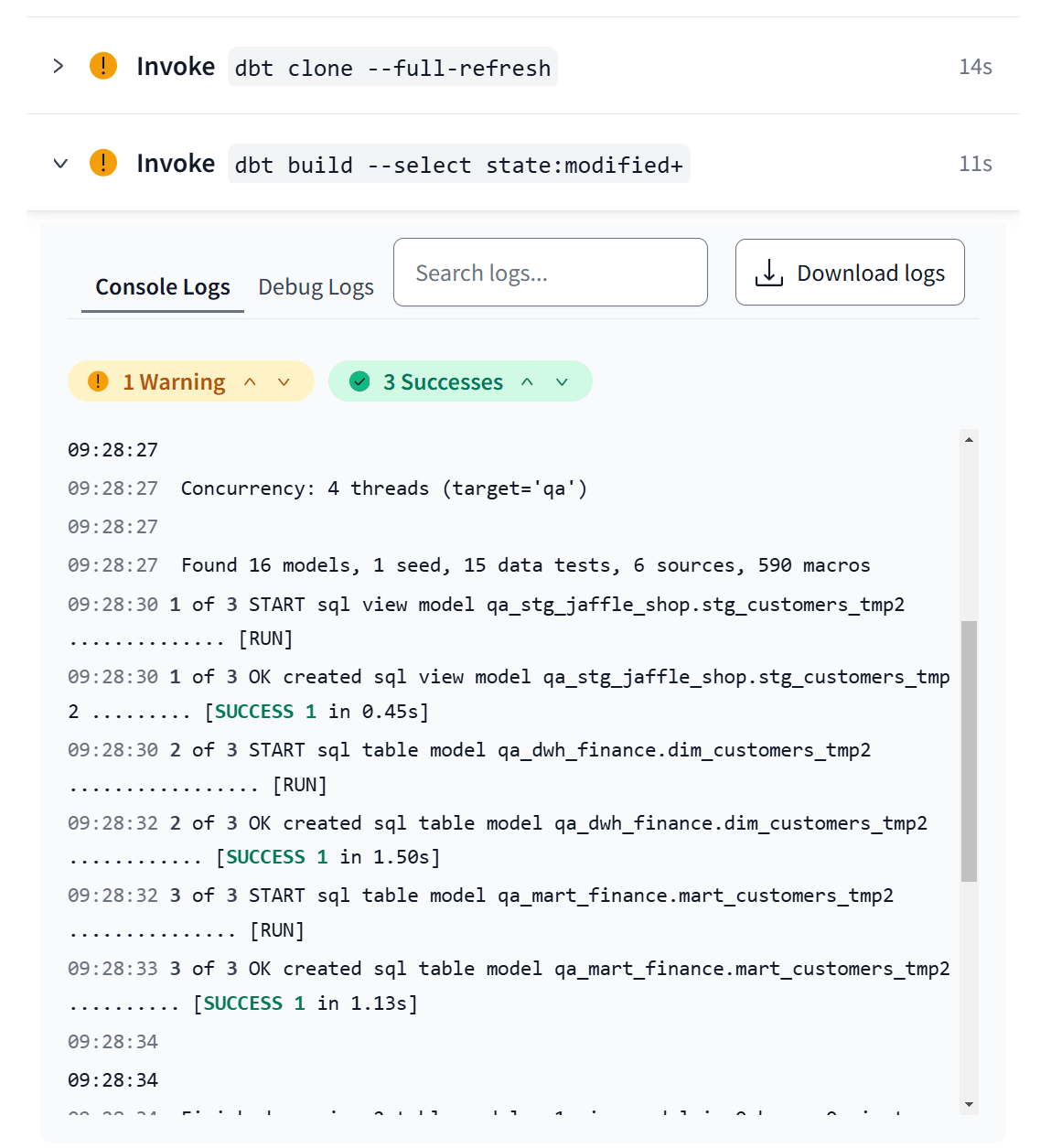
この後、QA EnvironmentのスキーマをデータアプリのQA環境から参照させて、各種検証を行います。
QAブランチからプルリクエストを発行しmainブランチにマージ
QA Environmentでの検証を終えたら最後に、QAブランチからプルリクエストを発行しmainブランチにマージします。
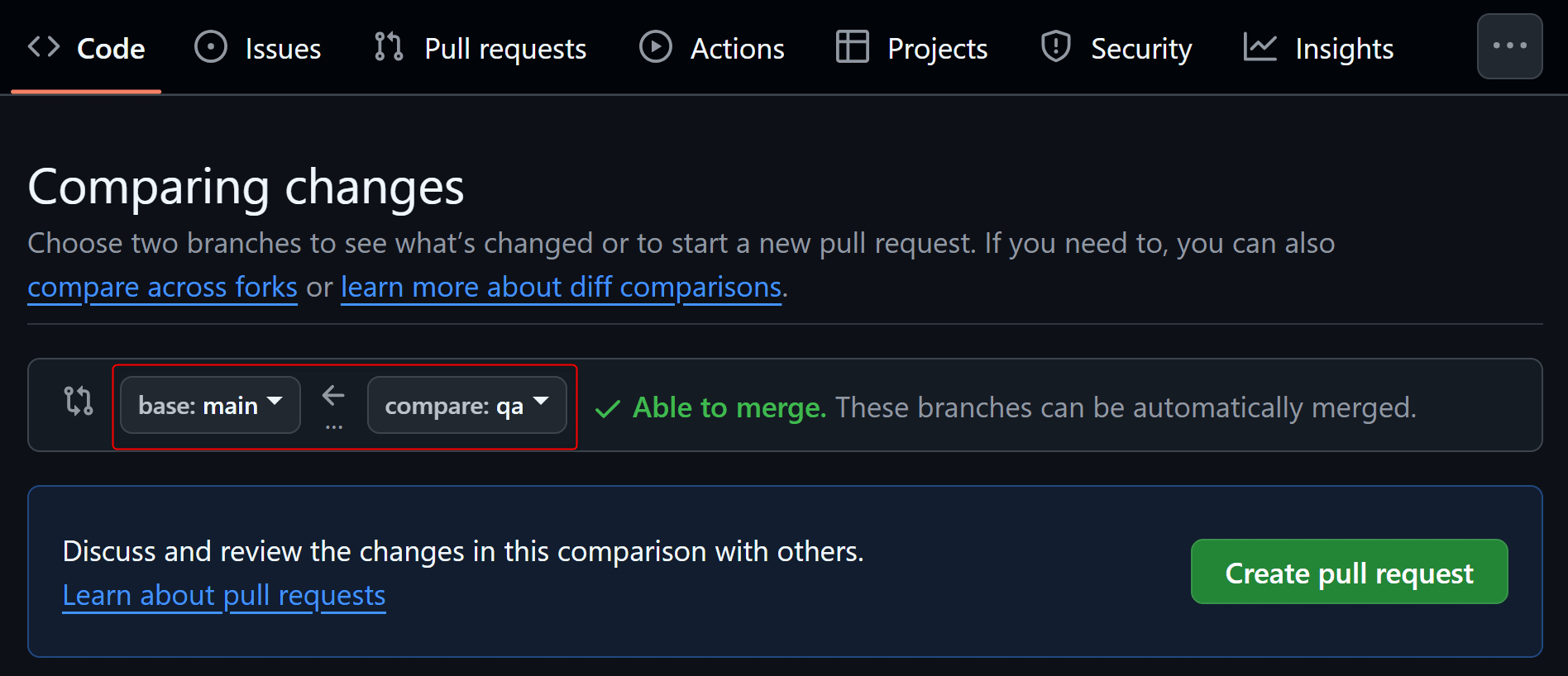
すると、Prod Environmentで設定したMerge jobが実行されます。新しく開発した差分があるModelだけがProd Environmentのスキーマにビルドされます。
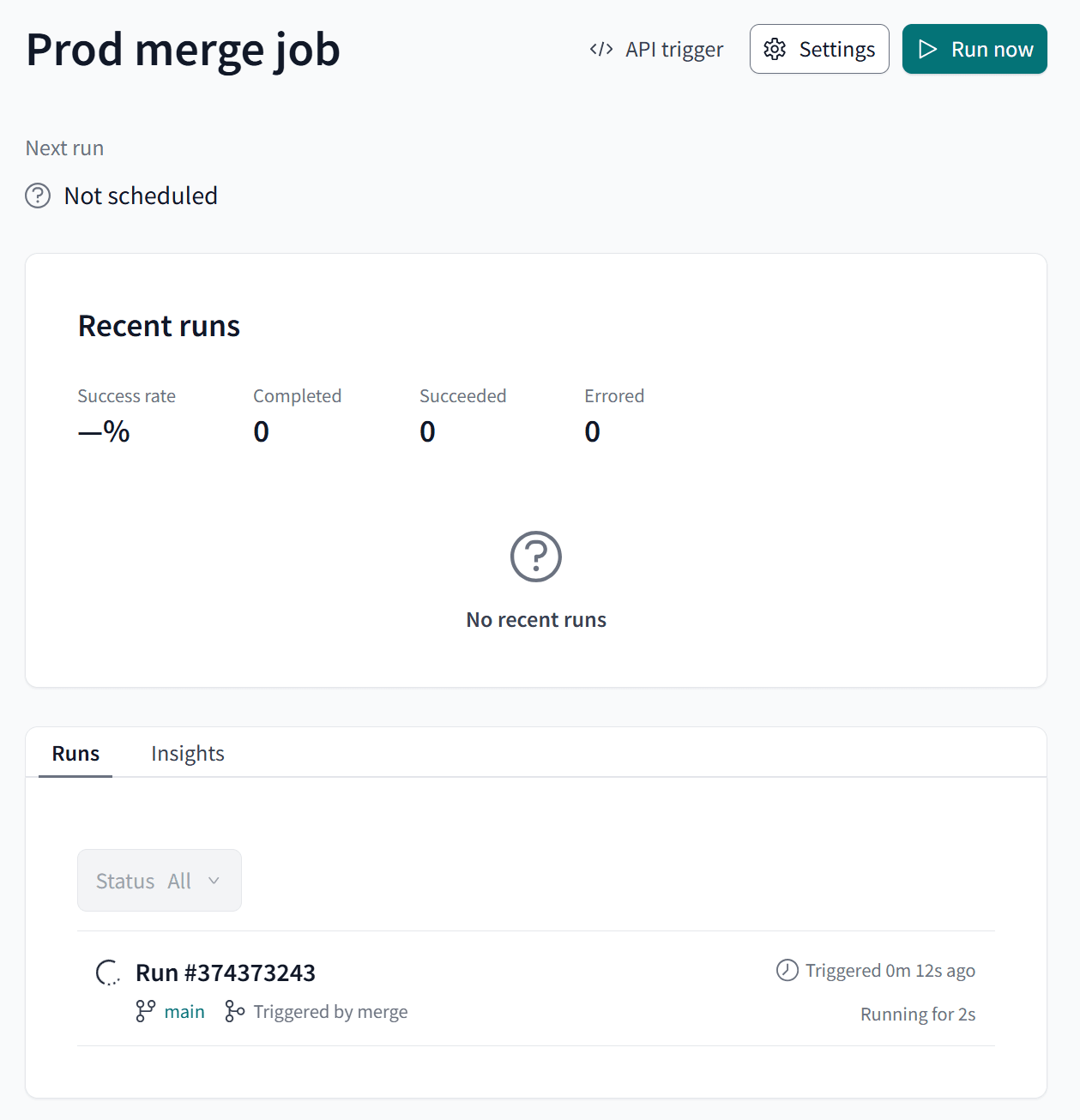
これで、一通りの開発は完了です!
最後に
dbt CloudでDev/QA/Prodで環境分離した開発プロセスを考えてみたので、その内容をまとめてみました。
今回のユースケース上、「各環境のスキーマに全テーブル・ビューの用意が必要」という要件を追加していたこともあり、dbt cloneも用いたプロセスを考えてみました。
参考になると嬉しいです!









