![[AWS Glue]DynamoDBに登録した祝日テーブルでデータの祝日判定をするジョブを作ってみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/aws-glue.png)
[AWS Glue]DynamoDBに登録した祝日テーブルでデータの祝日判定をするジョブを作ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
前回の記事では下記のような構成を作ってみました。
今回は、その応用として、DynamoDBに登録した祝日テーブルでデータの祝日判定をするGlueジョブ(Spark)を作ってみました。
作ってみた
以下のような構成の、デバイスからIoT Core経由で送信される生データ(devices_raw_data)と、DynamoDBにて定義した祝日テーブル(public_holidays)のデータを、GlueジョブでデバイスIDを元にして結合して分析用データ(devices_integrated_data)を作成する仕組みを作成します。
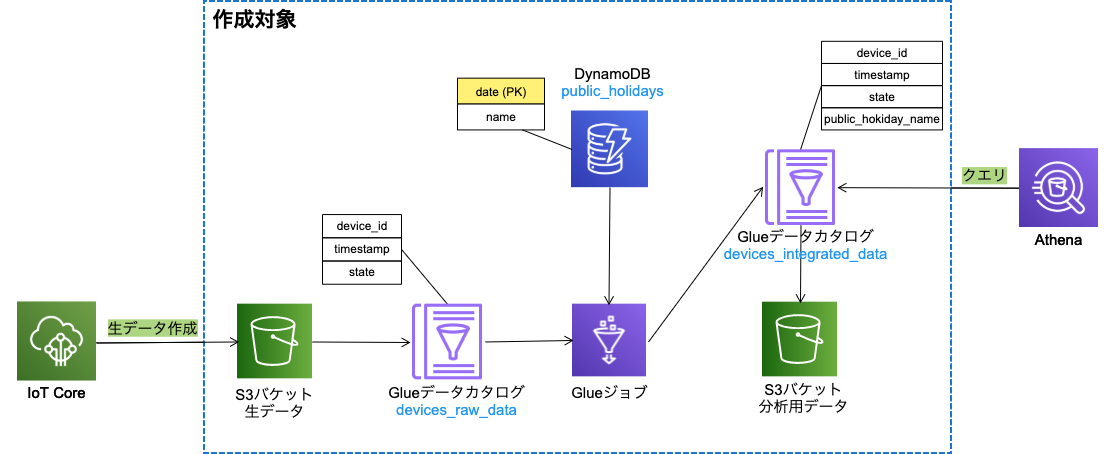
CloudFormationテンプレート
前述の構成の作成対象となるリソースをCloudFormationテンプレートで定義します。
※本来なら、祝日テーブル(PublicHolidaysDynamoDBTable)と生データのバケット(DevicesRawDataBucket)のリソースは別スタックで作成したい所ですが、今回は簡単のため同じスタックで作成してしまいます。
AWSTemplateFormatVersion: '2010-09-09'
Resources:
PublicHolidaysDynamoDBTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: public_holidays
AttributeDefinitions:
- AttributeName: date
AttributeType: S
KeySchema:
- AttributeName: date
KeyType: HASH
BillingMode: PAY_PER_REQUEST
DevicesRawDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-raw-data-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-data-analytics-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: devices_data_analystics
RawDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_raw_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesRawDataBucket}/raw-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
IntegratedDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_integrated_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
- Name: public_holiday_name
Type: string
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesDataAnalyticsBucket}/integrated-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state, public_holiday_name"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
ExecuteETLJobRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Principal:
Service:
- glue.amazonaws.com
Action:
- sts:AssumeRole
Policies:
- PolicyName: devices-data-etl-glue-job-policy
PolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Action:
- glue:StartJobRun
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:job/devices-data-etl
-
Effect: Allow
Action:
- glue:GetPartition
- glue:GetPartitions
- glue:GetTable
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:catalog
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:database/${DevicesDataAnalyticsGlueDatabase}
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesDataAnalyticsGlueDatabase}/${RawDataGlueTable}
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesDataAnalyticsGlueDatabase}/${IntegratedDataGlueTable}
-
Effect: Allow
Action:
- glue:GetJobBookmark
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesDataAnalyticsGlueDatabase}/${RawDataGlueTable}
-
Effect: Allow
Action:
- s3:ListBucket
- s3:GetBucketLocation
Resource:
- arn:aws:s3:::*
-
Effect: Allow
Action:
- logs:CreateLogStream
- logs:CreateLogGroup
- logs:PutLogEvents
Resource: !Sub arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws-glue/jobs/*
-
Effect: Allow
Action:
- s3:GetObject
Resource:
- !Sub arn:aws:s3:::${DevicesRawDataBucket}/raw-data/*
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-script/devices-data-etl.py
-
Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-temp-dir/*
-
Effect: Allow
Action:
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/integrated-data/*
-
Effect: Allow
Action:
- dynamodb:ListTables
Resource:
- !Sub arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/*
-
Effect: Allow
Action:
- dynamodb:DescribeTable
- dynamodb:Scan
Resource:
- !Sub arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/${PublicHolidaysDynamoDBTable}
DevicesDataETLGlueJob:
Type: AWS::Glue::Job
Properties:
Name: devices-data-etl
Command:
Name: glueetl
PythonVersion: 3
ScriptLocation: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-script/devices-data-etl.py
DefaultArguments:
--job-language: python
--job-bookmark-option: job-bookmark-enable
--TempDir: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-temp-dir
--GLUE_DATABASE_NAME: !Sub ${DevicesDataAnalyticsGlueDatabase}
--SRC_GLUE_TABLE_NAME: !Sub ${RawDataGlueTable}
--DEST_GLUE_TABLE_NAME: !Sub ${IntegratedDataGlueTable}
--PUBLIC_HOLIDAYS_TABLE_NAME: !Sub ${PublicHolidaysDynamoDBTable}
GlueVersion: 2.0
ExecutionProperty:
MaxConcurrentRuns: 1
MaxRetries: 0
Role: !Ref ExecuteETLJobRole
Glueジョブスクリプト
GlueジョブのPySparkスクリプトは下記のようになります。
public_holidays_df
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import to_timestamp, from_unixtime, col
from pyspark.sql.types import DateType
args = getResolvedOptions(
sys.argv,
[
'JOB_NAME',
'GLUE_DATABASE_NAME',
'SRC_GLUE_TABLE_NAME',
'DEST_GLUE_TABLE_NAME',
'PUBLIC_HOLIDAYS_TABLE_NAME'
]
)
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
df = glueContext.create_dynamic_frame.from_catalog(
database = args['GLUE_DATABASE_NAME'],
table_name = args['SRC_GLUE_TABLE_NAME'],
transformation_ctx = 'datasource'
).toDF()
df.show()
df = df.withColumn('parsed_timestamp_date',
from_unixtime(df.timestamp).cast(DateType())
)
df.show()
public_holidays_df = glueContext.create_dynamic_frame_from_options(
'dynamodb',
connection_options={
'dynamodb.input.tableName': args['PUBLIC_HOLIDAYS_TABLE_NAME']
}
).toDF()
public_holidays_df.show()
public_holidays_df = public_holidays_df.withColumn('parsed_date',
to_timestamp(col('date'), 'yyyy/MM/dd').cast(DateType())
)
public_holidays_df.show()
df = df.join(public_holidays_df,
df.parsed_timestamp_date == public_holidays_df.parsed_date,
'left'
)
df.show()
df = df.withColumnRenamed('name',
'public_holiday_name'
)
df = df.select(
'device_id',
'timestamp',
'state',
'public_holiday_name'
)
df.show()
dyf = DynamicFrame.fromDF(df,
glueContext,
'integrated_data'
)
glueContext.write_dynamic_frame.from_catalog(
frame = dyf,
database = args['GLUE_DATABASE_NAME'],
table_name = args['DEST_GLUE_TABLE_NAME'],
transformation_ctx = 'datasink'
)
job.commit()
スクリプトの解説
※ここでのshow()メソッドの表示結果は、後述の動作確認で使用した生データの場合の結果です。
生データをデータカタログを介してS3バケットから取得しています。
df = glueContext.create_dynamic_frame.from_catalog(
database = args['GLUE_DATABASE_NAME'],
table_name = args['SRC_GLUE_TABLE_NAME'],
transformation_ctx = 'datasource'
).toDF()
取得した生データのDataFrameは次のようになります。
>> df.show()
+---------+----------+-----+
|device_id| timestamp|state|
+---------+----------+-----+
| 3ff9c44a|1609348014| true|
| e36b7dfa|1609375822| true|
| 7d4215d0|1609497057|false|
| e36b7dfa|1609565442| true|
| 3ff9c44a|1609618552| true|
| 7d4215d0|1609741678|false|
| dfa6932c|1609777371|false|
| dfa6932c|1609858800|false|
+---------+----------+-----+
生データのtimestamp列を日付型としたparsed_timestamp_date列を作成しています。この列は祝日テーブルとの結合時に使用します。
df = df.withColumn('parsed_timestamp_date',
from_unixtime(df.timestamp).cast(DateType())
)
parsed_timestamp_dateを追加したDataFrameは次のようになります。
>> df.show()
+---------+----------+-----+---------------------+
|device_id| timestamp|state|parsed_timestamp_date|
+---------+----------+-----+---------------------+
| 3ff9c44a|1609348014| true| 2020-12-30|
| e36b7dfa|1609375822| true| 2020-12-31|
| 7d4215d0|1609497057|false| 2021-01-01|
| e36b7dfa|1609565442| true| 2021-01-02|
| 3ff9c44a|1609618552| true| 2021-01-02|
| 7d4215d0|1609741678|false| 2021-01-04|
| dfa6932c|1609777371|false| 2021-01-04|
| dfa6932c|1609858800|false| 2021-01-05|
+---------+----------+-----+---------------------+
祝日テーブルをDynamoDBから取得しています。
public_holidays_df = glueContext.create_dynamic_frame_from_options(
'dynamodb',
connection_options={
'dynamodb.input.tableName': args['PUBLIC_HOLIDAYS_TABLE_NAME']
}
).toDF()
取得した祝日テーブルのDataFrameは次のようになります。
>> public_holidays_df.show()
+----------+--------------------------+
| date| name|
+----------+--------------------------+
| 2021/5/3| 憲法記念日|
| 2021/2/23| 天皇誕生日|
| 2021/7/22| 海の日|
| 2021/3/20| 春分の日|
| 2021/8/9|祝日法第3条第2項による休日|
| 2021/11/3| 文化の日|
|2021/11/23| 勤労感謝の日|
| 2021/1/11| 成人の日|
| 2021/4/29| 昭和の日|
| 2021/2/11| 建国記念日|
| 2021/5/4| みどりの日|
| 2021/8/8| 山の日|
| 2021/9/23| 秋分の日|
| 2021/9/20| 敬老の日|
| 2021/7/23| スポーツの日|
| 2021/1/1| 元日|
| 2021/5/5| こどもの日|
+----------+--------------------------+
祝日テーブルのdate列を日付型としたparsed_date列を作成しています。この列は生データとの結合時に使用します。
public_holidays_df = public_holidays_df.withColumn('parsed_date',
to_timestamp(col('date'), 'yyyy/MM/dd').cast(DateType())
)
parsed_dateを追加したDataFrameは次のようになります。
>> public_holidays_df.show()
+----------+--------------------------+-----------+
| date| name|parsed_date|
+----------+--------------------------+-----------+
| 2021/5/3| 憲法記念日| 2021-05-03|
| 2021/2/23| 天皇誕生日| 2021-02-23|
| 2021/7/22| 海の日| 2021-07-22|
| 2021/3/20| 春分の日| 2021-03-20|
| 2021/8/9|祝日法第3条第2項による休日| 2021-08-09|
| 2021/11/3| 文化の日| 2021-11-03|
|2021/11/23| 勤労感謝の日| 2021-11-23|
| 2021/1/11| 成人の日| 2021-01-11|
| 2021/4/29| 昭和の日| 2021-04-29|
| 2021/2/11| 建国記念日| 2021-02-11|
| 2021/5/4| みどりの日| 2021-05-04|
| 2021/8/8| 山の日| 2021-08-08|
| 2021/9/23| 秋分の日| 2021-09-23|
| 2021/9/20| 敬老の日| 2021-09-20|
| 2021/7/23| スポーツの日| 2021-07-23|
| 2021/1/1| 元日| 2021-01-01|
| 2021/5/5| こどもの日| 2021-05-05|
+----------+--------------------------+-----------+
生データと祝日テーブルをparsed_timestamp_date列とparsed_date列をもとに結合します。
df = df.join(public_holidays_df,
df.parsed_timestamp_date == public_holidays_df.parsed_date,
'left'
)
結合後のDataFrameは次のようになります。2021-01-01のレコードが祝日と判定されて元日となっています。
>> df.show()
+---------+----------+-----+---------------------+--------+----+-----------+
|device_id| timestamp|state|parsed_timestamp_date| date|name|parsed_date|
+---------+----------+-----+---------------------+--------+----+-----------+
| e36b7dfa|1609565442| true| 2021-01-02| null|null| null|
| 3ff9c44a|1609618552| true| 2021-01-02| null|null| null|
| 7d4215d0|1609497057|false| 2021-01-01|2021/1/1|元日| 2021-01-01|
| dfa6932c|1609858800|false| 2021-01-05| null|null| null|
| 7d4215d0|1609741678|false| 2021-01-04| null|null| null|
| dfa6932c|1609777371|false| 2021-01-04| null|null| null|
| e36b7dfa|1609375822| true| 2020-12-31| null|null| null|
| 3ff9c44a|1609348014| true| 2020-12-30| null|null| null|
+---------+----------+-----+---------------------+--------+----+-----------+
カラムをRenameおよびSelectして分析用データとして必要なカラムのみとします。
df = df.withColumnRenamed('name',
'public_holiday_name'
)
df = df.select(
'device_id',
'timestamp',
'state',
'public_holiday_name'
)
RenameおよびSelect後のDataFrameは次のようになります。
>> df.show()
+---------+----------+-----+-------------------+
|device_id| timestamp|state|public_holiday_name|
+---------+----------+-----+-------------------+
| e36b7dfa|1609565442| true| null|
| 3ff9c44a|1609618552| true| null|
| 7d4215d0|1609497057|false| 元日|
| dfa6932c|1609858800|false| null|
| 7d4215d0|1609741678|false| null|
| dfa6932c|1609777371|false| null|
| e36b7dfa|1609375822| true| null|
| 3ff9c44a|1609348014| true| null|
+---------+----------+-----+-------------------+
デプロイ
CloudFormationスタックをデプロイします。
% aws cloudformation deploy \
--template-file template.yaml \
--stack-name devices-data-analytics-stack \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset
GlueジョブのスクリプトをS3バケットにアップロードします。
% ACCOUNT_ID=<Account ID>
% AWS_REGION=<AWS Region>
% aws s3 cp devices-data-etl.py s3://devices-data-analytics-${ACCOUNT_ID}-${AWS_REGION}/glue-job-script/devices-data-etl.py
DynamoDBへの祝日データ登録
下記の内閣府のサイトを参考に祝日を確認します。
登録はAWS CLIのbatch-write-itemで行うので、下記に従い登録用のデータを作成します。
js
{
"public_holidays": [
{
"PutRequest": {
"Item": {
"date": {"S": "2021/1/1"},
"name": {"S": "元日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/1/11"},
"name": {"S": "成人の日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/2/11"},
"name": {"S": "建国記念日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/2/23"},
"name": {"S": "天皇誕生日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/3/20"},
"name": {"S": "春分の日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/4/29"},
"name": {"S": "昭和の日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/5/3"},
"name": {"S": "憲法記念日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/5/4"},
"name": {"S": "みどりの日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/5/5"},
"name": {"S": "こどもの日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/7/22"},
"name": {"S": "海の日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/7/23"},
"name": {"S": "スポーツの日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/8/8"},
"name": {"S": "山の日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/8/9"},
"name": {"S": "祝日法第3条第2項による休日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/9/20"},
"name": {"S": "敬老の日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/9/23"},
"name": {"S": "秋分の日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/11/3"},
"name": {"S": "文化の日"}
}
}
},
{
"PutRequest": {
"Item": {
"date": {"S": "2021/11/23"},
"name": {"S": "勤労感謝の日"}
}
}
}
]
}
DynamoDBの祝日テーブルに先程のデータを一括登録します。
% aws dynamodb batch-write-item \
--request-items file://request-items.json
動作確認
生データをS3バケットにアップロードします。
{"device_id": "3ff9c44a", "timestamp": 1609348014, "state": true}
{"device_id": "e36b7dfa", "timestamp": 1609375822, "state": true}
{"device_id": "7d4215d0", "timestamp": 1609497057, "state": false}
{"device_id": "e36b7dfa", "timestamp": 1609565442, "state": true}
{"device_id": "3ff9c44a", "timestamp": 1609618552, "state": true}
{"device_id": "7d4215d0", "timestamp": 1609741678, "state": false}
{"device_id": "dfa6932c", "timestamp": 1609777371, "state": false}
{"device_id": "dfa6932c", "timestamp": 1609858800, "state": false}
% aws s3 cp raw-data.json s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}/raw-data/raw-data.json
ジョブを実行します。
% aws glue start-job-run --job-name devices-data-etl
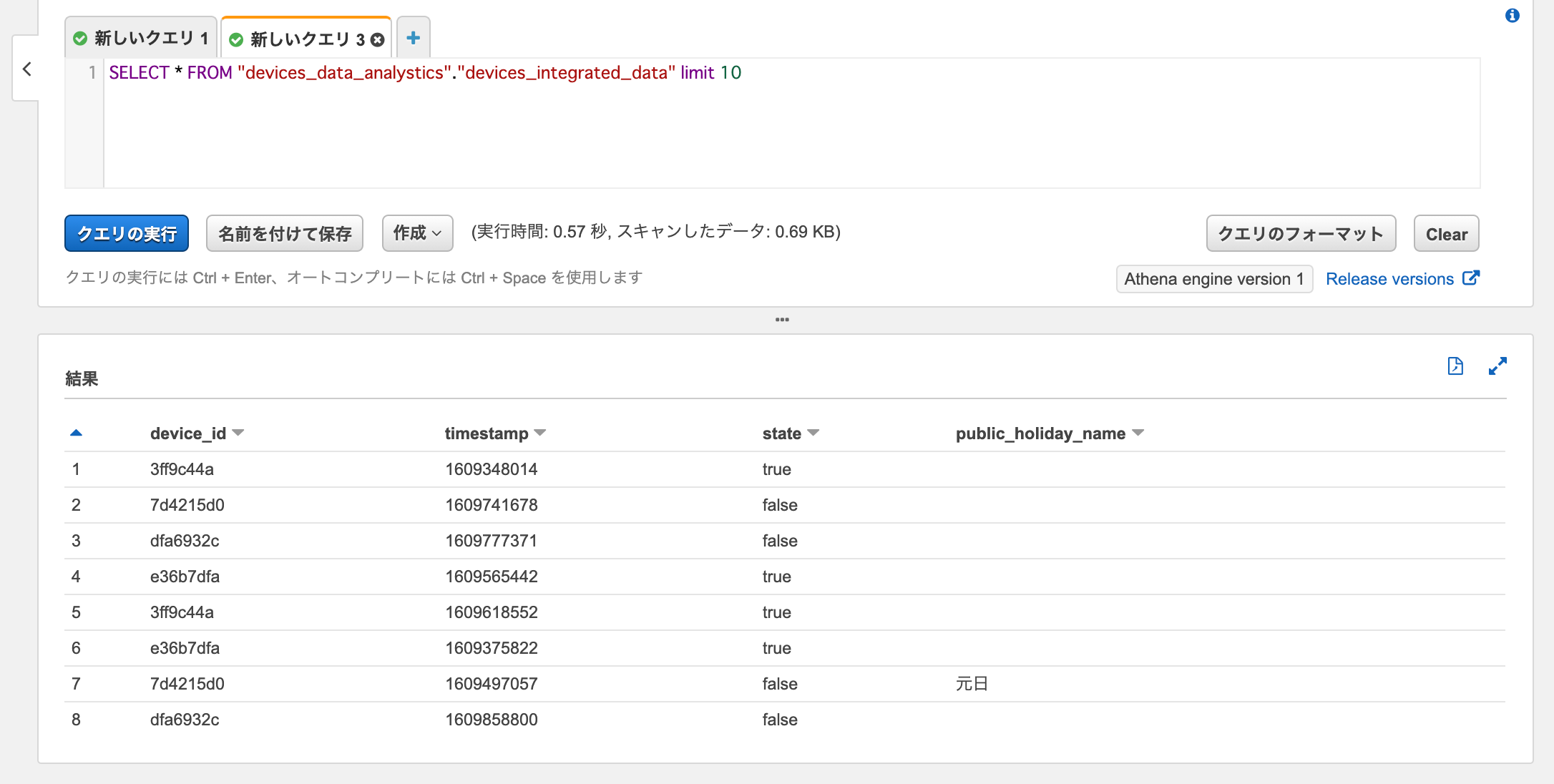
ジョブが正常に完了したら、Athenaで作成された分析用データに対してSelectクエリを実行すると、データが取得できました。
sql
SELECT * FROM "devices_data_analystics"."devices_integrated_data" limit 10
timestampが1609497057(2021/1/1)のレコードがちゃんと祝日判定されて元日となっていますね。
祝日判定に外部ライブラリやAPIを使わなかったのはなぜ?
Python向けですと下記のような便利なライブラリが公開されています。
ただし下記のような理由によりDynamoDBなどで自分でメンテナンスした方が良さそうだとなりました。
- Glueジョブで外部ライブラリを使うのは少しめんどうである
- オリンピック期間や前後には祝日が例年通りにならない可能性があるため、逆にメンテナンスコストが掛かりそう
おわりに
DynamoDBに登録した祝日テーブルでデータの祝日判定をするGlueジョブ(Spark)を作ってみました。
データ分析においてデータ発生日などが土日だけでなく祝日であるかどうかを軸に分析を行いたい事例があり、今回この構成が役に立ちました。
参考
- pyspark - Convert timestamp to date in spark dataframe - Stack Overflow
- PySpark: 時刻と文字列を相互に変換する (DataFrame / Spark SQL) - CUBE SUGAR CONTAINER
- Apache Spark: SparkSQLリファレンス〜関数編・日付・時刻関数〜
以上










