
DGX Spark × Continue.dev で VS Code にローカルコード補完環境を構築してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
前回の記事では、DGX Spark の 128GB メモリで Claude Code + Ollama のローカル実行を検証しました。結果は「だいぶ使えるけど、まだ横で見ていないと怖い」というもの。それとは別に、エディタのコード補完もローカルで動かせないかと気になっていました。
この Playbook は VS Code + Continue.dev + Ollama の構成で、ローカル LLM によるコード補完環境を構築する手順を紹介しています。しかも Continue.dev の開発者自身が DGX Spark をメインの開発マシンとして使っている という記事まであり、「これは試してみるしかない」と思った次第です。
この記事では、MacBook Pro の VS Code から Tailscale VPN 経由で DGX Spark の Ollama に接続し、「リモートローカル」なコード補完環境を構築した手順と体感を紹介します。
Continue.dev と Vibe Coding Playbook
Continue.dev とは
Continue.dev は、VS Code や JetBrains IDE にローカル LLM やクラウド API を統合できるオープンソースの AI コーディングアシスタントです。GitHub Copilot の代替として注目されており、自分で選んだモデルを自由に組み合わせられます。
主な機能は 3 つ。コードを書いている途中にインラインで候補を提示する Tab 補完、サイドバーでコードについて質問や生成を依頼する Chat、コードを選択して自然言語で修正指示を出す Edit です。GitHub Copilot と同じような体験を、自前のモデルで実現できます。
config.yaml でモデルごとに roles(chat, autocomplete, embed, edit 等)を割り当てる仕組みで、Tab 補完には応答速度重視の小さなモデル、Chat には推論力重視の大きなモデル、という使い分けが 1 つの設定ファイルで完結します。
NVIDIA Vibe Coding Playbook の構成
NVIDIA が公開している Vibe Coding Playbook では、gpt-oss:120b 1 つに chat / edit / autocomplete の全ロールを割り当てるシンプルな構成を推奨しています。128GB メモリがあるからこそ、120B の大型モデル 1 つで全部まかなうという DGX Spark らしい割り切りです。
ただ、Tab 補完は入力のたびに呼ばれるため、応答速度が体感に直結します。Playbook でも 500ms 未満のレスポンスを推奨しており、120B モデルだと補完のたびに待たされる場面が出てきそうです。そこで今回は、Tab 補完だけ軽量な専用モデルに分離するアレンジを加えました。
今回の構成
Playbook をベースに、Tab 補完を qwen2.5-coder:1.5b に分離し、Chat には前回の Claude Code 検証で好成績だった Qwen3-Coder-Next を採用しました。MacBook Pro と DGX Spark を Tailscale VPN で接続する「リモートローカル」構成です。
| 機能 | モデル | パラメータ | 選定理由 |
|---|---|---|---|
| Tab 補完 | qwen2.5-coder:1.5b | 1.5B | 500ms 未満の応答速度を確保 |
| Chat | Qwen3-Coder-Next | 80B MoE(稼働 3B) | SWE-bench 70.6%、前回記事で実績あり |
| Embeddings | nomic-embed-text | — | @Codebase コンテキスト用 |
qwen2.5-coder:1.5b は 5.5 兆トークンで学習されたコーディング特化モデルで、92 言語をサポートしています。1.5B ながら Codestral(22B)の 80〜90% の性能を出せるという報告もあり、Tab 補完にはコスパの良い選択肢ですね。Qwen3-Coder-Next は 80B MoE で稼働パラメータは 3B のみ。メモリ消費は約 51GB で、1.5B モデルと合わせても 128GB に余裕をもって収まります。
MacBook Pro 側にはモデルを置かず、推論はすべて DGX Spark で処理します。Mac の入力環境はそのまま、推論だけ DGX の 128GB メモリに任せる構成です。
今回の検証環境
| 項目 | スペック |
|---|---|
| DGX Spark | 128GB LPDDR5x、GB10(Grace Blackwell) |
| MacBook Pro | M4 32GB |
| ネットワーク | Tailscale VPN(同一ネットワーク内、direct 接続) |
| VS Code | 1.109.2 |
| Continue.dev | v1.2.14 |
| Ollama | v0.15.5 |
前回の記事(Claude Code)との違い
前回の記事との違いを整理しておきます。
| 項目 | 記事 1.5(Claude Code) | 今回(Continue.dev) |
|---|---|---|
| ツール | Claude Code(CLI) | Continue.dev(VS Code 拡張) |
| 操作形態 | ターミナルでプロンプト入力 | エディタ内で Tab 補完 + Chat |
| 得意なこと | マルチファイル編集、テスト実行、エージェント的な自律動作 | インラインのコード補完、選択範囲の修正、対話的なコード生成 |
| モデルとの関係 | 1 つのモデルが全機能を担当 | 機能ごとに最適なモデルを割り当て |
| 待ち時間の感覚 | 数十秒〜数分(バックグラウンドで完了を待つ) | Tab 補完は 1 秒未満が理想(打鍵のリズムに影響) |
Claude Code が「指示を出して待つ」エージェント型なら、Continue.dev は「自分で書きながらアシストを受ける」補完型。用途が違うので、優劣の話ではありません。
DGX Spark 側のセットアップ
Ollama のリモートアクセス設定
Ollama はデフォルトで localhost:11434 のみをリッスンしています。MacBook Pro から Tailscale 経由でアクセスするには、OLLAMA_HOST を 0.0.0.0 に変更します。
# systemd のオーバーライドファイルを作成
sudo mkdir -p /etc/systemd/system/ollama.service.d
sudo tee /etc/systemd/system/ollama.service.d/override.conf <<'EOF'
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
EOF
# サービスを再起動
sudo systemctl daemon-reload
sudo systemctl restart ollama
MacBook Pro から疎通確認をしましょう。
# Tailscale IP 経由でアクセス
curl http://100.x.x.x:11434/api/tags
JSON でモデル一覧が返ってくれば成功です。
モデルのダウンロード
今回使う 3 つのモデルをダウンロードします。
# Tab 補完用(1.5B、軽量高速)
ollama pull qwen2.5-coder:1.5b
# Chat 用(80B MoE、コーディング特化)
ollama pull qwen3-coder-next
# Embeddings 用
ollama pull nomic-embed-text
Qwen3-Coder-Next は約 51GB あるため、回線状況によってはしばらく待ちます。ダウンロードが終われば、qwen2.5-coder:1.5b と合わせても 55GB 程度。128GB メモリに余裕をもって収まります。
MacBook Pro 側のセットアップ
Continue.dev のインストール
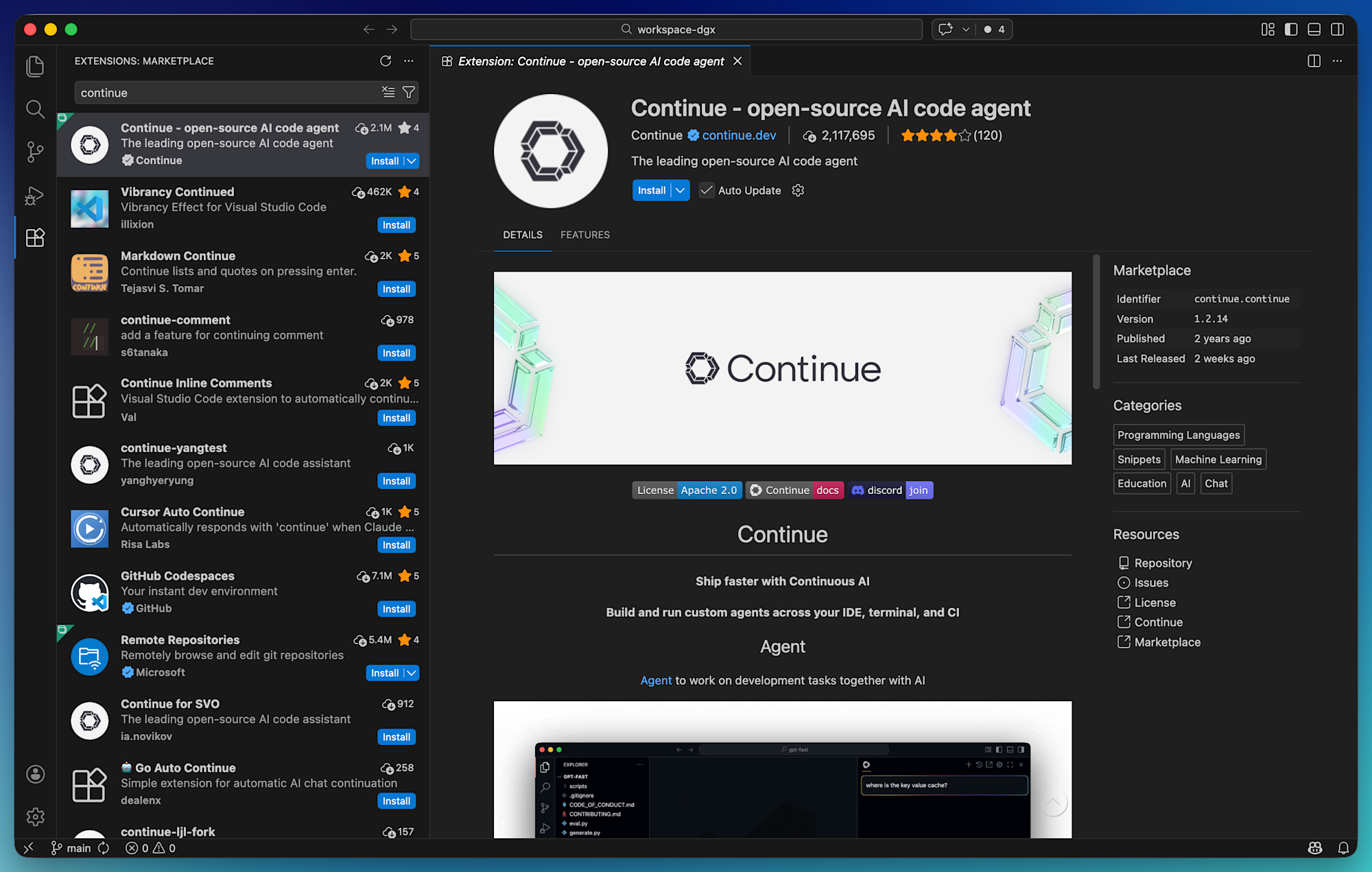
VS Code の拡張機能マーケットプレイスから「Continue」を検索してインストールします。
インストール後、サイドバーに Continue のアイコンが表示されます。
config.yaml の設定
Continue.dev の設定ファイルは ~/.continue/config.yaml です。以前の config.json は非推奨になっており、YAML 形式に移行されています。以下のように、DGX Spark の Ollama をリモートプロバイダーとして設定します。
name: DGX Spark Remote
version: 0.0.1
models:
# Chat 用(80B MoE — コーディング特化)
- name: qwen3-coder-next 80b
provider: ollama
model: qwen3-coder-next
apiBase: http://100.x.x.x:11434
capabilities:
- tool_use
contextLength: 65536
roles:
- chat
- edit
# Tab 補完用(1.5B — 高速レスポンス重視)
- name: qwen2.5-coder 1.5b
provider: ollama
model: qwen2.5-coder:1.5b
apiBase: http://100.x.x.x:11434
roles:
- autocomplete
# Embeddings 用(@Codebase コンテキストで利用)
- name: nomic-embed-text
provider: ollama
model: nomic-embed-text
apiBase: http://100.x.x.x:11434
roles:
- embed
apiBase に Tailscale の IP を指定しているので、Mac 側で Ollama を動かす必要はありません。Mac のリソースは VS Code と他のアプリに集中できます。roles の指定で Tab 補完には軽量モデル、Chat には大型モデルと、機能ごとの使い分けが 1 つの設定ファイルで済みます。Qwen3-Coder-Next には capabilities: [tool_use] を明示しています。Continue.dev の自動検出では Qwen3 系の tool_use が認識されないため、手動で指定します。
なお、v1.2.14 時点では config.yaml にトップレベルの name と version が必須です。また、gpt-oss:120b のようにデフォルトのコンテキスト長が短いモデルでは contextLength を明示しておかないと、少し長いファイルを扱うときにトークン上限のエラーが出ることがありました。
なお、DGX Spark にローカル接続する場合(リモートではなく)は、Hub Model Blocks という省略記法も使えます。
models:
- uses: ollama/gpt-oss-120b
- uses: ollama/qwen2.5-coder-1.5b
今回は Tailscale 越しのリモート接続なので apiBase を明示していますが、DGX Spark に直接キーボードを繋いで使っている方は Hub Model Blocks の方が手軽です。
実際に使ってみた
検証には Express + TypeScript で書いた Todo API(約 100 行)を使いました。GitHub Copilot を無効にした状態で、Continue.dev の各機能を試しています。
import express, { Request, Response } from "express";
// --- Types ---
interface Todo {
id: number;
title: string;
completed: boolean;
createdAt: Date;
}
// --- In-memory store ---
let todos: Todo[] = [];
let nextId = 1;
// --- Helper functions ---
// Test point 1: Write "function createTodo(" and wait for Tab completion
function createTodo(title: string): Todo {
const todo: Todo = {
id: nextId++,
title,
completed: false,
createdAt: new Date(),
};
todos.push(todo);
return todo;
}
// Test point 2: Start typing "function findTodoBy" and see what it suggests
function findTodoById(id: number): Todo | undefined {
return todos.find((todo) => todo.id === id);
}
function toggleComplete(id: number): Todo | undefined {
const todo = findTodoById(id);
if (todo) {
todo.completed = !todo.completed;
}
return todo;
}
// Test point 3: Start typing "function deleteTodo" and let Tab complete the body
function deleteTodo(id: number): boolean {
const index = todos.findIndex((todo) => todo.id === id);
if (index === -1) return false;
todos.splice(index, 1);
return true;
}
// --- Express routes ---
const app = express();
app.use(express.json());
// Test point 4: Type "app.get" and wait — does it suggest the route pattern?
app.get("/api/todos", (_req: Request, res: Response) => {
res.json(todos);
});
app.post("/api/todos", (req: Request, res: Response) => {
const { title } = req.body;
if (!title) {
res.status(400).json({ error: "title is required" });
return;
}
const todo = createTodo(title);
res.status(201).json(todo);
});
// Test point 5: Type "app.put" and see if it generates the update route
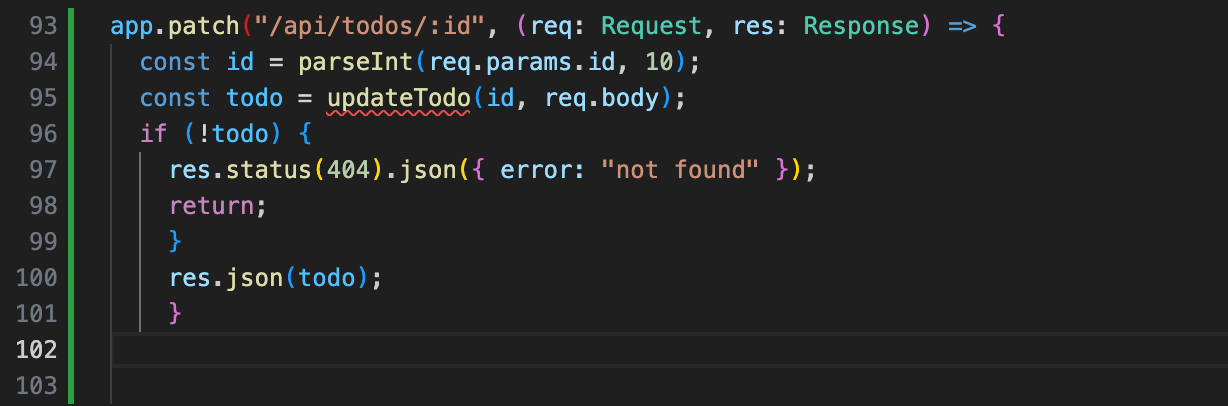
app.put("/api/todos/:id", (req: Request, res: Response) => {
const id = parseInt(req.params.id, 10);
const todo = toggleComplete(id);
if (!todo) {
res.status(404).json({ error: "not found" });
return;
}
res.json(todo);
});
app.delete("/api/todos/:id", (req: Request, res: Response) => {
const id = parseInt(req.params.id, 10);
const success = deleteTodo(id);
if (!success) {
res.status(404).json({ error: "not found" });
return;
}
res.status(204).send();
});
// --- Stats endpoint ---
// Test point 6: Type "app.get("/api/stats"" and let it complete the handler
app.listen(3000, () => {
console.log("Server running on http://localhost:3000");
});
Tab 補完の体感
Playbook が目標とする 500ms 未満のレスポンス、Tailscale VPN 越しでもクリアできるのか。モデル選定にあたって、DGX Spark 上で FIM(Fill-in-the-Middle)のベンチマークを計測しました。
| モデル | サイズ | 生成速度 | 応答時間 | FIM 対応 |
|---|---|---|---|---|
| qwen2.5-coder:1.5b | 986MB | 189 tok/s | 290〜360ms | OK |
| qwen2.5-coder:7b | 4.7GB | 40.5 tok/s | 約 1.4 秒 | OK |
| Qwen3-Coder-Next | 51GB | 37.0 tok/s | 数秒〜 | OK |
| gpt-oss:120b | 61GB | — | — | NG |
qwen2.5-coder:7b は補完の質こそ上がりますが、応答 1.4 秒だとタイピングのテンポが崩れます。Qwen3-Coder-Next はさらに遅い。gpt-oss:120b は推論モデル(thinking トークンを先に生成する構造)のため、そもそも FIM に対応していませんでした。Playbook では gpt-oss を autocomplete にも割り当てていますが、実際に使うなら Tab 補完は別モデルに分離した方がよさそうです。
結果、500ms 未満を安定してクリアできる qwen2.5-coder:1.5b を採用しました。Tailscale の direct 接続(往復 10〜30ms 程度)を足しても余裕がある計算です。
実際に TypeScript のコードを書いてみると、Copilot と比べてワンテンポ遅い印象はあるものの、打鍵のリズムを崩すほどではありませんでした。autocomplete の初期設定値を変えたくらいの差です。
補完候補の質はどうか。Express のルートハンドラを書いている途中で app.patch と入力すると、既存の app.delete や app.put のパターンを見て ("/api/todos/:id", (req: Request, res: Response) => { というルーティングのシグネチャまで提案してきます。関数の引数推定もなかなかで、function filterTodos( と書き始めると query: string): Todo[] と型まで補完してくれました。
一方で、Copilot に比べると粒度の粗さは感じます。Copilot が関数の中身まで丁寧にインラインで展開してくれるのに対して、qwen2.5-coder:1.5b は存在しない関数(getStats() や updateTodo())を呼ぶコードを生成することがありました。1.5B のモデルにインラインの実装詳細まで求めるのは酷で、ここは「自分で中身を書く前提のヒント」として受け取るのがちょうどいいかなと思っています。
雑な感想としては「1 年前の Copilot」。過剰なくらいに補完してくる最近の Copilot に比べると控えめですが、そのぶん意図しない補完に邪魔されることも少なく、自分のペースで書ける心地よさがあります。
Chat でのコード生成
Chat では Qwen3-Coder-Next を使います。前回の記事で Claude Code との組み合わせでも好成績だったモデルです。
「この Todo API にバリデーションミドルウェアを追加して」と聞いてみたところ、最初のトークンは 1〜2 秒で出てきて、そこからストリーミングでスムーズに出力されました。生成されたのは Express ミドルウェアパターンの validateTodoInput 関数で、null チェック、型チェック、空文字チェック、文字長の上限(255 文字)、trim 処理まで入った実用的な内容です。
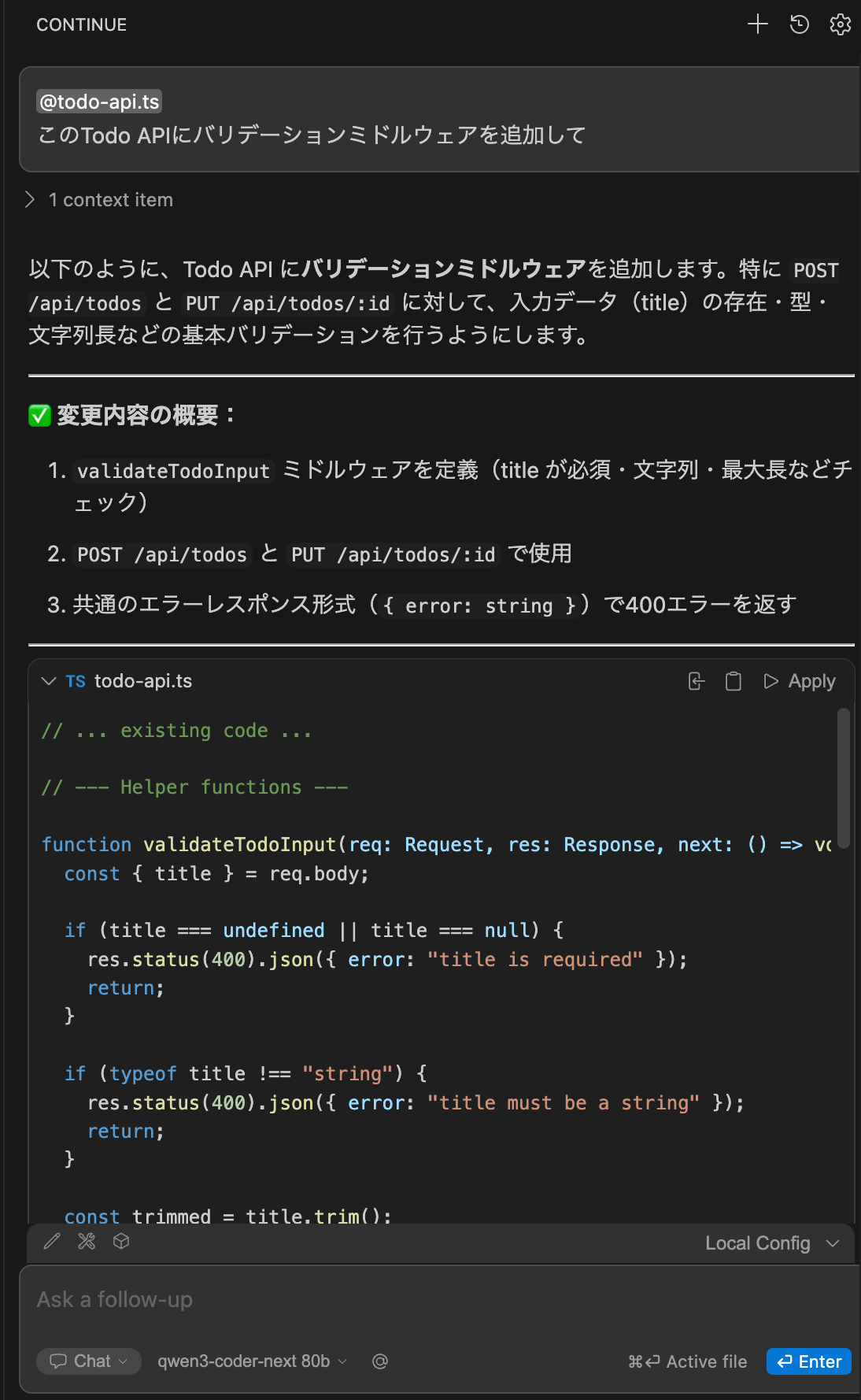
元のファイルが TypeScript なので、生成コードもちゃんと TypeScript で出てきます。既存のルート定義にミドルウェアを差し込む形を提案しており、存在しないモジュールを前提にすることもありませんでした。Chat の「Insert Code」ボタンはファイル末尾への追記なので、既存コードへの統合は自分で行う必要がありますが、コードの質が高いぶん組み込みの手間は少なく済みます。
Edit モードと Agent モード
Continue.dev には、コードを選択して自然言語で修正指示を出す Edit モードや、自律的にタスクを進める Agent モードもあります。Qwen3-Coder-Next や gpt-oss:120B で試したところ、Edit は動くこともありますが、Apply 時にコードが壊れたり指示外の関数まで書き換えたりと挙動が安定しません。Agent モードもコード提案までは出るものの、ファイルへの反映で失敗するパターンが多い状況です。
Chat が安定するのに Edit / Agent が不安定なのは、diff 適用やツール呼び出しのフォーマットにモデルが追いついていないためで、Continue.dev 側の問題ではなくモデル側の課題です。前回の Claude Code 検証でも同じ傾向が出ており、ローカル LLM の構造化出力の精度が上がれば自然と解消されていくでしょう。
Claude Code との使い分け
前回の記事で検証した Claude Code(Ollama ローカル実行)と、今回の Continue.dev。両方とも DGX Spark のローカル LLM を使いますが、得意な場面が違います。
| 場面 | Claude Code | Continue.dev |
|---|---|---|
| 新規ファイルをゼロから作りたい | ○ プロンプト一発で生成 | △ Chat で生成して手動で組み込み |
| 既存コードに数行追加したい | △ Edit ツールの精度に依存 | ○ Tab 補完でスムーズに |
| バグを見つけて直したい | ○ Read → 分析 → Edit を自律実行 | △ Edit は動くが挙動が不安定 |
| テストを書いて実行したい | ○ ファイル作成 → テスト実行まで一貫 | × テスト実行はターミナルで手動 |
| リファクタリング | ○ 複数ファイルを横断して変更 | △ Edit 不安定、Chat は文脈に弱い |
| 日常的なコーディング | × 毎回プロンプトを書くのは面倒 | ○ 書きながらアシストを受ける |
Edit / Agent はモデルによって動いたり動かなかったりするため、現時点では Tab 補完と Chat が Continue.dev の主戦場です。それでも、普段のコーディングは Continue.dev の Tab 補完でリズムよく進めて、まとまった作業やリファクタリングは Claude Code に任せる、という棲み分けは十分成り立つかなと思っています。ちょっとした質問を Continue.dev の Chat でサイドバーから聞けるのも、ターミナルに切り替えなくて済むぶん便利かも。
どちらも DGX Spark の Ollama に繋いでいるため、マシンもモデルも共有できます。Continue.dev の開発者によるレビュー記事でも、「開発作業と AI モデルの推論を 1 台のマシンでこなせることで、ワークフローの考え方自体が変わった」と書かれていました。推論専用アプライアンスではなく、日常の開発マシンとして使っているという視点が面白いですね。
まとめ
NVIDIA 公式の Vibe Coding Playbook を参考に、MacBook Pro の VS Code + Continue.dev から Tailscale VPN 経由で DGX Spark の Ollama に接続するローカルコード補完環境を構築しました。
Tab 補完は「1 年前の Copilot」くらいの体感で、ルーティンなコーディングには十分実用的でした。Tailscale VPN 越しでもレスポンスの遅延はほとんど気にならず、Playbook が目標とする 500ms 未満を余裕でクリアしています。Chat は Qwen3-Coder-Next のおかげで応答も速く、TypeScript のコードを正しく生成してくれました。Edit や Agent は動くときと壊れるときがあり、まだ安定しません。
Claude Code が「AI に任せて待つ」エージェント型なら、Continue.dev は「自分で書きながらアシストを受ける」補完型。Edit / Agent はローカル LLM の構造化出力がもう少し進化すれば使えるようになりそうで、モデルの進化速度を考えると近い将来に期待しています。
それでも Tab 補完だけで日常のコーディングはだいぶ楽になるので、同じ構成を試してみたい方の参考になれば幸いです。








