
DwarfStar 4 で DeepSeek V4 Flash 284B を DGX Spark に載せてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
Redis 作者の antirez さんが、DeepSeek V4 Flash 専用に書いた小さな推論エンジン ds4.c。汎用の GGUF ランナーでも llama.cpp のラッパーでもなく、「特定のモデル一つを、ローカルで端から端まで完成された形で動かす」ことだけを狙った C 製のエンジンです。これがつい先日「DwarfStar 4」に改名され、CUDA バックエンドが正式にマージされました。これまで Mac の Metal 専用だったものが、Linux + NVIDIA でも make 一発でビルドできるようになっています。
DeepSeek V4 Flash は 284B パラメータの MoE モデルです。このモデルでは合計 284B のうち実際に動くのは 13B 前後(DeepSeek の発表値)。扱えるコンテキストは 100 万トークンです。DwarfStar 4 はこれを 2-bit 量子化で 128GB クラスのマシンに載せ、生成中に使い回す内部メモリ(KV キャッシュ)をディスクに永続化する設計を持っています。手元に DGX Spark(GB10、128GB 統合メモリ、メモリ帯域 273 GB/s)があるので、CUDA 対応マージ直後のタイミングで実際に動かしてみました。
個人的に気になったのは、次の 3 点でした。
- 284B の MoE が 128GB の DGX Spark に「どう」載るのか。重みもディスクからストリームしているのか
- コミュニティ報告にあった「DGX Spark の生成速度は約 12 トークン/秒で、M3 Max(約 27 トークン/秒)より遅い」は実機で再現するのか
- KV キャッシュをディスクに逃がす仕組みは、長文コンテキストや繰り返しのプロンプトで実際に効くのか
結論を先に書いておくと、ビルドは make だけであっさり通り、284B が 81GiB ほどで 128GB に収まりました。生成は 8〜15 トークン/秒とメモリ帯域なりの遅さですが、prefill(プロンプト読み込み)は増分で 80〜250 トークン/秒と速く出ます。ディスク KV キャッシュは約 3.2 万トークンのプロンプト再送を 115 秒から 7.7 秒に縮めてくれました。「対話チャットには遅いが、長文を一括で処理する用途なら現実的」という、DGX Spark らしい結果でした。
DwarfStar 4 と DeepSeek V4 Flash の仕組み
DeepSeek V4 Flash というモデル
DeepSeek V4 Flash は、アクティブパラメータが少ない分、284B という規模の割には軽く動く MoE です。長文の指示を出しても、思考過程の出力が他のモデルより短く済む(最大思考を避ければ 1/5 程度)、というのが antirez さんの考察だそうです。
DwarfStar 4 が配布する GGUF は専用品で、任意の DeepSeek/GGUF ファイルが動くわけではありません。今回使った q2-imatrix は、ディスク上で約 81GiB。量子化のかけ方が非対称になっていて、モデルの大半を占める専門家ネットワークだけを 2-bit まで荒く潰し、品質に効く中核部分(attention や出力層など)は精度を落とさずに残しています。256GB 以上のマシン向けには q4-imatrix(約 153GB)もありますが、128GB の DGX Spark では q2-imatrix 一択です。
KV キャッシュをディスクに置くという発想
DeepSeek V4 Flash は、KV キャッシュを学習で得た変換で小さく押し込めて持ち、しかも層によって圧縮の強さを変えています(強く圧縮する層では 1/128 まで縮める)。さらに、過去の全トークンを毎回見る代わりに関連の強い一部(各トークンで上位 512 個)だけに注目する仕組みを組み合わせていて、これが KV を極端に小さくしています。
DGX Spark で測った値で 1 トークンあたり約 14KB。100 万トークンでも十数 GiB 程度の外挿で、コンテキスト用にあらかじめ確保されるバッファまで含めても 26GB ほどに収まります(README の見積もりでは、そのうち 22GB ほどが「関連トークンに注目する仕組み」の索引用)。
README には The KV cache is actually a first-class disk citizen. という一文があります。これだけ圧縮された KV と最近の SSD の速さがあるなら、KV キャッシュが RAM に居なければならないという前提を変えていい、という発想ですね。実際 ds4-server は、プロンプトの先頭部分をハッシュにして <sha1>.kv というファイルに保存し、後で同じプロンプトの続きが来たときに、トークン 0 から prefill し直さずにそのチェックポイントを読み戻します。ファイルは普通の read/write で書くので、すでに 81GiB をメモリ上に展開しているプロセスに余計なメモリマップを増やさずに済みます。
llama.cpp への統合が難航していると言われるのは、こういう DeepSeek V4 専用の KV まわりの構造と、ディスク KV 永続化を前提にした設計が、汎用 GGUF ランナーの作りとは根本的に噛み合わないためです。「一モデル専用エンジン」という割り切りだからこそできている、とも言えますね。
prefill は計算力勝負、生成はメモリ帯域勝負
DGX Spark の話をするときに毎回出てくる構図ですが、ここでも同じです。プロンプトを読む prefill はまとめて並列に計算できるので GPU の計算力がボトルネックになり、GB10 の計算性能が効きます。一方、1 トークンずつ作る生成(decode)は毎ステップでパラメータをメモリから読み直すため、メモリ帯域がボトルネックになります。DGX Spark のメモリ帯域は 273 GB/s で、M3 Max(約 400 GB/s)や M3 Ultra(約 819 GB/s)より低いので、生成では Apple Silicon に分があるはず、という予測になります。
実際にどうだったかを見ていきましょう。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | DGX Spark(GB10、sm_121、aarch64) |
| メモリ | 128 GB LPDDR5X 統合メモリ(帯域 273 GB/s) |
| ストレージ | 4 TB NVMe SSD |
| OS | DGX OS / Ubuntu 24.04 aarch64(kernel 6.17.0-1014-nvidia) |
| CUDA / Driver | CUDA 13.0(V13.0.88)/ Driver 580.142 |
| コンパイラ | gcc 13.3.0 |
| DwarfStar 4 | commit a97e7a3(2026-05-12 取得) |
| モデル | DeepSeek-V4-Flash-IQ2XXS-w2Q2K-AProjQ8-SExpQ8-OutQ8-chat-v2-imatrix.gguf(約 81GiB) |
CUDA 対応がマージされてまだ数日のタイミングなので、commit ハッシュは明記しておきます。
DGX Spark でビルドして動かす
make 一発でビルドできた
セットアップは拍子抜けするほど素直でした。
git clone https://github.com/antirez/ds4 ~/works/dwarfstar4/ds4
cd ~/works/dwarfstar4/ds4
export PATH=/usr/local/cuda/bin:$PATH
make
make の中身を見ると、Linux では自動的に CUDA バックエンド(ds4_cuda.cu)をビルドし、CUDA_ARCH ?= native で nvcc が見えている GPU に合わせてくれます。aarch64 + CUDA 13.0 の組み合わせで、パッチも環境変数いじりも不要、約 16 秒で ds4(CLI)・ds4-server(HTTP API)・ds4-bench(ベンチ)の 3 バイナリができました。-arch=native が GB10(sm_121)を正しく拾っていて、Mac 固有のコードや依存ライブラリで詰まる場面もありませんでした。
モデルは付属のスクリプトで取得します。128GB マシン向けの q2-imatrix を選びました。
./download_model.sh q2-imatrix # 約 81GiB を Hugging Face から取得 → ./ds4flash.gguf にリンク
起動とメモリの様子
短いプロンプトを 1 回投げてみます。
./ds4 -p "In one short paragraph, what is Redis?" --cuda --nothink -n 64
ds4: context buffers 751.71 MiB (ctx=32768, backend=cuda, prefill_chunk=2048, raw_kv_rows=2304, compressed_kv_rows=8194)
ds4: CUDA backend initialized on NVIDIA GB10 (sm_121)
ds4: CUDA host registration skipped: operation not supported
ds4: CUDA loading model tensors into device cache
ds4: CUDA loading model tensors 16.02 GiB cached
...
ds4: CUDA startup model cache prepared 80.76 GiB of tensor spans in 26.432s
ds4: CUDA q8 fp16 cache budget exhausted; using q8 kernels (request=8.00 MiB cached=0.00 GiB free=3.54 GiB reserve=6.08 GiB total=121.69 GiB)
**Redis** is an open-source, in-memory data structure store that is commonly used as a high-speed cache, message broker, and database. ...
ds4: prefill: 17.29 t/s, generation: 14.81 t/s
出力はちゃんとした文章になっています。気づいた点を 2 つ。
1 つ目は、80.76 GiB の重みを「device cache」に取り込むのに、初回は約 26 秒かかること。ファイルがページキャッシュに乗っている状態だと、2 回目以降は約 10 秒に縮みます。GB10 は統合メモリなので、ここは物理的には同じ RAM の中でのコピーですね。
2 つ目は CUDA q8 fp16 cache budget exhausted; using q8 kernels という行。重み 81GiB + 予約領域約 6GiB + コンテキスト用のバッファで、122GiB のシステムメモリのうち空きが 3.5〜6GiB しかなく、計算を少し速くするための 16bit 展開キャッシュを置く余裕がないので、8bit のまま計算する経路に切り替えています。「128GB の限界」が、起動した瞬間からログに出ているわけですね。CUDA host registration skipped: operation not supported も GB10 の統合メモリ環境ならではのメッセージで、こちらは動作に影響しません。
結果 1: コンテキスト長とスループット
付属の ds4-bench を使うと、コンテキストを少しずつ伸ばしながら「その時点での」prefill と生成スループットを測れます。2048、4096、…と区切り点を置いて、各点で「直前から増えた分の prefill」と「128 トークンを毎回いちばん確率の高い候補で生成(途中で止めない)」を計測する作りです。
./ds4-bench -m ds4flash.gguf --prompt-file speed-bench/promessi_sposi.txt \
--ctx-start 2048 --ctx-max 65536 --step-incr 2048 --gen-tokens 128 \
--csv results/dgx-spark-q2-sweep.csv
これに、65536 → 262144 までを倍々で伸ばした粗いスイープ(生成 64 トークン)を継ぎ足したのが次のグラフです。
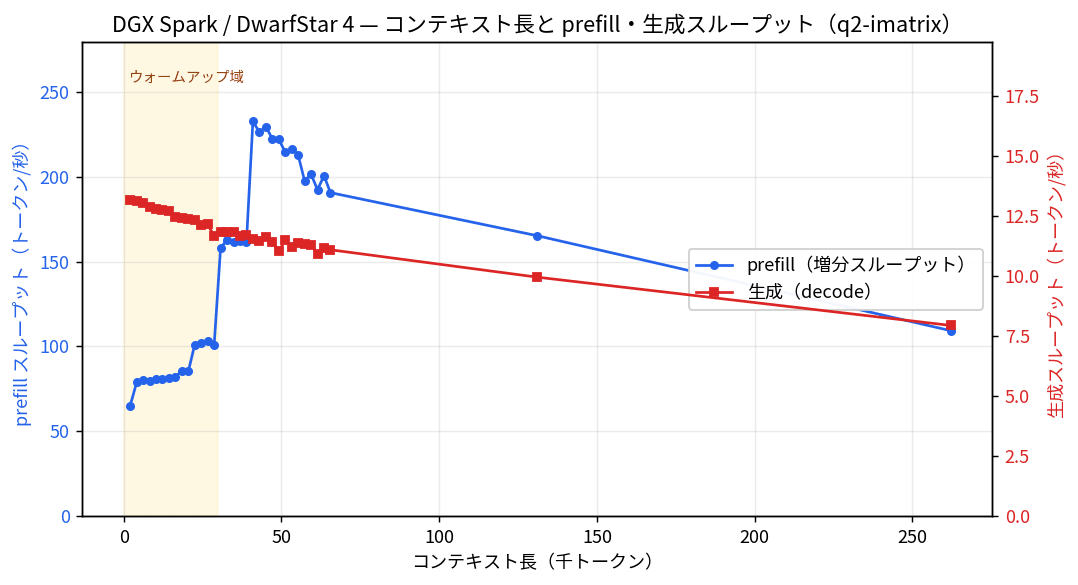
生成(赤)は 13 トークン/秒あたりから始まって 26 万トークンで 8 トークン/秒へ緩やかに低下。prefill(青)は冷えた序盤の 65 トークン/秒から階段状に立ち上がり、200 トークン/秒前後で落ち着く。
生成スループットは、コンテキストが短いと約 13 トークン/秒、26 万トークンまで伸ばすと約 8 トークン/秒まで下がります。コミュニティ報告にあった「DGX Spark で約 12 トークン/秒」と整合する範囲で、メモリ帯域律速の予測どおりですね。README の公式ベンチ表では DGX Spark GB10(128GB、q2、7047 トークン)が prefill 343.81 トークン/秒・生成 13.75 トークン/秒となっていて、生成側はほぼ同じ、prefill 側は自分の増分計測(おおむね 200 トークン/秒前後)よりやや高い数字です。README は 7000 トークン程度の短めのコンテキストでの単発 prefill を測っていて、こちらは増分で長いコンテキストまで歩いているので、計測のしかたの違いと見ています。
prefill が序盤に低く出るのは、81GiB の重みのうち、入力に応じて呼び出される専門家ネットワークのページが少しずつメモリ上で温まっていくためだと思っています。3 万トークンあたりまで階段状に上がっていく様子が、ちょうどグラフのウォームアップ域に出ていますね。
| コンテキスト | prefill(増分) | 生成 | 圧縮 KV キャッシュ |
|---|---|---|---|
| 2,048 | 64.9 トークン/秒 | 13.2 トークン/秒 | 52 MB |
| 32,768 | 162.6 トークン/秒 | 11.8 トークン/秒 | 475 MB |
| 65,536 | 247.1 トークン/秒(単発) | 11.4 トークン/秒 | 926 MB |
| 131,072 | 165.2 トークン/秒(増分 +64k) | 9.95 トークン/秒 | 1.83 GB |
| 262,144 | 109.3 トークン/秒(増分 +128k) | 7.94 トークン/秒 | 3.63 GB |
26 万トークンまで伸ばしたときのピークメモリは約 115GiB(空き約 7GiB)。ds4-bench のログによると、コンテキストバッファだけで約 4.5GiB 取られていました。README も「128GB なら 10 万〜30 万トークンが現実的」と書いていて、26 万トークンあたりが DGX Spark での実用上の上限という感触です。
結果 2: 圧縮 KV キャッシュは本当に小さい
ここからは、その「KV キャッシュはディスクに置いて構わない」という発想を実際に確かめます。先ほどの表の右端、kvcache_bytes の伸び方を見ると、1 トークンあたり約 14KB(傾きで約 13.8KB)で線形に増えていきます。これを 100 万トークンまで増やそうとすると、以下のようになります。
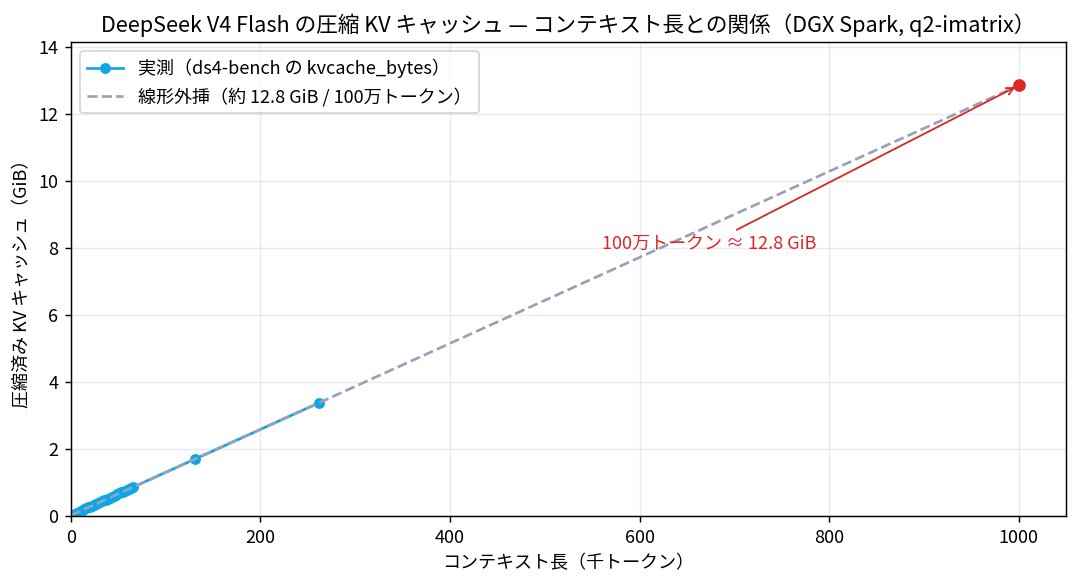
実測点はほぼ完全な直線。線形外挿しても 100 万トークンで約 12.8 GiB にしかならず、81GiB の重みと合わせても 128GB に余裕で収まる。
26 万トークンの時点でも、圧縮済み KV は 3.6GB しかありません。つまり、DGX Spark 128GB で扱える範囲のコンテキストでは、KV はすべて RAM に収まってしまいます。ここで触ってみて一番腑に落ちたのは、ディスク KV キャッシュは「RAM に収まらない分をあふれさせる仕組み」ではなく、「一度払った高い prefill コストを後で再利用するための仕組み」だという点でした。TurboQuant / RotorQuant が「KV を圧縮で小さくする」アプローチだったのに対して、こちらは「圧縮 + プレフィックスをディスクに永続化」という別の攻め方ですね。
では、その「再利用」がどれくらい効くのか。ds4-server をディスク KV キャッシュ有効で起動し、約 100KB(約 3.2 万トークン)のテキストを質問付きで投げて、いったん別の小さなリクエストでセッションを追い出し、もう一度同じ大きなプロンプトを投げてみました。
./ds4-server --ctx 200000 --kv-disk-dir /tmp/ds4-kv --kv-disk-space-mb 24576 --port 8000
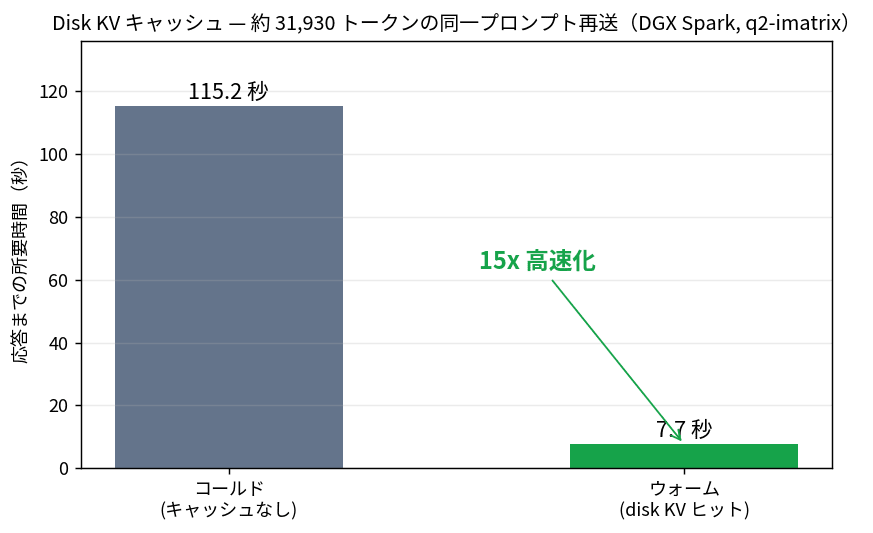
コールド(キャッシュなし)は 31,930 トークンの prefill + 24 トークン生成で 115.2 秒。同じプロンプトを再送したウォーム時は、ディスク KV キャッシュにヒットして 7.7 秒。約 15 倍の高速化。
トレースを見ると、ウォーム時は cache_source: disk-text で cached_tokens: 30720 ――31,930 トークンのうち 30,720 トークン分(きりのいい 2048 の倍数まで切り下げて保存される)をディスクのチェックポイントから読み戻し、残りの 1,200 トークン弱と生成だけをやり直しています。/tmp/ds4-kv/ には数百 MB の .kv ファイルが並んでいて、これは先ほど見た 3 万トークン分の KV サイズ(約 475MB)とだいたい一致します。
これは README に書かれている「Claude Code は本格的に動き出す前に 2.5 万トークンくらいの大きな初期プロンプトを送ってくることがある。--kv-disk-dir を有効にしておけば、最初の高い prefill のあと、続きやセッション再開でその保存済みプレフィックスを再利用できる」という話そのものです。実際、115 秒が 7.7 秒になりました。
結果 3: エージェント用途で実用になるか
次に、エージェント用途で実用になるかを見ていきます。ds4-server は OpenAI 互換と Anthropic 互換の API を両方喋るので、README には Claude Code の接続先を ds4-server に向けるだけのラッパースクリプトまで載っています。284B 級のモデルがローカルで生成 12〜15 トークン/秒で動く、というのが実際どういう体感なのかを、長文コンテキストのタスクで測ってみました。
まずは生成スループットの目安として、「1 から 120 まで空白区切りで出力して」というプロンプトを投げると、24 トークンのプロンプト + 239 トークン生成で 16.1 秒。生成は約 14.9 トークン/秒です。対話チャットとしては、確かにもどかしい速さですね。
次に、長文一括処理を 2 つ。1 つ目は DwarfStar 4 自身の C ソース(ds4.h / ds4_gpu.h / ds4_bench.c / ds4_cli.c ほか)を連結して「5 点でバグや危ない前提を指摘して」と投げたコードレビュー。2 つ目は、自分の DGX Spark 関連の公開記事 9 本を連結して「日本語で全体を 1 段落要約して、繰り返し出てくるテーマを 5 個挙げて」と投げた要約です。
| タスク | プロンプト | 生成 | 所要時間 | prefill 換算 |
|---|---|---|---|---|
| コードレビュー(C ソース) | 35,088 トークン | 498 トークン | 166.0 秒 | 約 264 トークン/秒 |
| 連載記事 9 本の要約 | 56,662 トークン | 900 トークン | 298.7 秒 | 約 238 トークン/秒 |
コードレビューの出力は、fseek(SEEK_END) + ftell で Windows のテキストモードだとバイト数がずれる話、fread でバッファに埋め込みの NUL バイトを想定していない話、生ポインタを返す API でビュー生存中の解放を防ぐ仕組みがない(use-after-free のリスク)話、ベンチのループでスナップショット保存が失敗したときに未初期化のまま使ってしまう話など、C コードのレビューとして実際に筋の通った指摘が並びました(ファイル名や行番号を添えてくるものの、行番号は与えていないので一部は推測です)。35,088 トークンを読んで返すのに約 2 分 45 秒。
要約の方は、56,662 トークン――連載記事 9 本分――を読んで「DGX Spark の性能限界と MoE モデルの優位性 ―― 128GB 統合メモリで実現するローカル AI ワークフロー」というタイトルから始まる、メモリ帯域 273 GB/s が長文生成の上限になっていること、アクティブパラメータの少ない MoE モデルとの相性、LoRA SFT・MTP・NVFP4 量子化といった軽量化技術の話、Continue.dev + Ollama でのローカル補完まで拾った、正直なところかなり的を射た日本語要約を返してきました。2-bit 量子化の 284B が、ここまで日本語の技術文章をまとめられるのは素直に面白いですね。所要時間は約 5 分。
つまり、対話のキャッチボールには遅すぎますが、「大きな入力を一度読ませて、まとまった答えを一発で返してもらう」用途――コードレビュー、長文要約、検索した文書を読ませて答えさせる構成の最終回答など――なら、prefill が速い DGX Spark の得意ゾーンに収まります。しかも --kv-disk-dir を併用すれば、2 回目以降は最初の prefill コストを払い直さずに済むので、システムプロンプトやツール定義一式が毎回先頭にくっつくエージェント用途とは相性が良さそうですね。
可否マトリクス
ここまでの結果を 1 つの表にまとめると、こうなります。
| 項目 | 判定 | メモ |
|---|---|---|
make 一発で CUDA ビルド |
○ | aarch64 + CUDA 13.0、-arch=native で GB10 を自動認識、約 16 秒 |
| 284B の q2-imatrix が 128GB に載る | ○ | 重み約 81GiB + コンテキスト・KV で動作中 110〜115GiB |
| 生成(decode)スループット | △ | 約 8〜15 トークン/秒(メモリ帯域 273 GB/s が上限) |
| prefill スループット | ○ | 増分で 80〜250 トークン/秒、GB10 の計算性能が効く |
| 長文コンテキスト(〜26 万トークン) | ○ | 圧縮 KV が小さく RAM 内で完結、prefill 時間は分単位 |
| ディスク KV キャッシュで再 prefill 省略 | ○ | 約 3.2 万トークンの再送が 115 秒 → 7.7 秒(約 15 倍) |
| Claude Code / エージェント用途 | △ | 長文一括(レビュー・要約)は実用、対話チャットは遅い |
まとめ
- CUDA 対応がマージされてまだ数日(commit
a97e7a3、2026-05-12)の DwarfStar 4 が、DGX Spark でmakeだけであっさりビルドできた。aarch64 + CUDA 13.0 で詰まる場面はなし - 284B の DeepSeek V4 Flash が、専門家ネットワークだけを 2-bit に潰した q2-imatrix(約 81GiB)で 128GB に収まった。動作中は 110〜115GiB を使い、起動直後から「128GB の限界」がログに出る
- 生成は約 8〜15 トークン/秒でメモリ帯域 273 GB/s 律速。Apple Silicon(M3 Max の 4 割、M3 Ultra の 3 割ほど)に分があるという予測どおり。一方 prefill は増分で 80〜250 トークン/秒と速く、計算側では戦える
- 圧縮 KV キャッシュは 1 トークンあたり約 14KB と非常に小さく、扱える範囲のコンテキストでは RAM に収まる。ディスク KV キャッシュは「あふれた分を逃がす」のではなく「高い prefill を再利用する」仕組みで、約 3.2 万トークンの再送を約 15 倍速くしてくれた
- Claude Code やエージェント用途は、対話チャットには遅すぎるが、長文を一括で読ませる用途(コードレビュー・要約・RAG の最終回答)なら現実的。
--kv-disk-dir併用で定型プロンプトの再 prefill も省ける
「一モデル専用エンジン」という割り切りが、ここまできれいに動くのは気持ちがいいですね。DeepSeek が V4 Flash の更新版を出したら、また試してみたいところです。
参考リンク
- DwarfStar 4(旧 ds4 / ds4.c)リポジトリ: https://github.com/antirez/ds4
- DeepSeek V4 Flash 専用 GGUF: https://huggingface.co/antirez/deepseek-v4-gguf
- 検証スクリプトと生データ: https://github.com/himorishige/dgx-spark-blog (
dwarfstar4-deepseek-v4-flash-bench/)
Mac(M3 Max / M3 Ultra)の数値は、本検証では取得しておらず、DwarfStar 4 README のベンチ表からの引用です。










