
TurboQuant と RotorQuant を DGX Spark で試してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
2026 年 3 月 24 日、Google Research が TurboQuant を発表しました(ICLR 2026)。LLM の推論中に蓄積される KV キャッシュ(過去のトークン情報を保持するメモリ領域)を 3 ビットに圧縮して、そのメモリ使用量を最大 6 分の 1 に削減する手法です。モデル本体の VRAM が減るわけではなく、あくまで推論時のキャッシュ部分に効く技術ですが、キャリブレーション不要、ファインチューニング不要、どんな Transformer にも後付けできるという点が目を引きます。
LLM の推論では、コンテキストが長くなるほど KV キャッシュがメモリを圧迫します。大きなモデルを載せているとなおさらで、KV キャッシュに使える余裕が限られるのは多くの環境に共通する悩みです。ここを 6 分の 1 に圧縮できるなら、コンテキスト長や同時リクエスト数がかなり改善できるはず。自分の DGX Spark でも早速試してみたくなりました。
発表翌日には DGX Spark ユーザーフォーラムでも大きな話題になり、さらに 2 日後には RotorQuant という代替実装まで登場しました。Clifford 代数という幾何学の理論を使って、TurboQuant と同等の圧縮品質をより少ないパラメータで実現しています。
この記事では、TurboQuant と RotorQuant を DGX Spark で実際に動かしてみた結果を紹介します。
TurboQuant とは
KV キャッシュがなぜボトルネックになるのか
Transformer の推論では、過去のトークンの Key と Value をキャッシュに保持して再計算を避けます。このキャッシュのサイズはコンテキスト長に比例して増えていくため、長文を扱うほどメモリを圧迫します。
たとえば 8B パラメータのモデルで 32K トークンのコンテキストを処理する場合、BF16 の KV キャッシュだけで数 GB を消費します。128K トークンに伸ばせば単純計算で 4 倍。モデル本体のメモリと合わせると、DGX Spark の 128GB でもあっという間に上限に達します。
既存の対策としては FP8 への量子化がありますが、これはビット幅を半分にするだけなので圧縮率は 2 倍止まりです。
PolarQuant + QJL の 2 段階圧縮
TurboQuant は 2 つの手法を組み合わせています。ざっくり言うと「データをかき混ぜてから圧縮し、誤差を 1 ビットで補正する」という流れです。
まず PolarQuant(AISTATS 2026)が Key ベクトルをランダムに回転させてから量子化します。回転することで情報の偏りがなくなり、少ないビット数でも効率よく符号化できるようになります。ブロックごとにスケール値を持つ必要がないため、追加のメモリオーバーヘッドもほぼゼロです。
次に QJL(AAAI 2025)が PolarQuant の量子化誤差を 1 ビットで補正します。Attention 計算で使う内積の精度を保つための仕組みで、量子化した後でも元のベクトル同士の類似度が正しく計算できるようにしています。
気になる品質ですが、3.5 ビットの量子化でも LongBench や Needle-in-a-Haystack のスコアが FP32 と統計的に区別できないレベルを維持しています。論文では、情報理論上の圧縮限界に対して 2.7 倍以内の歪みに収まっていると報告されています。
既存手法との比較
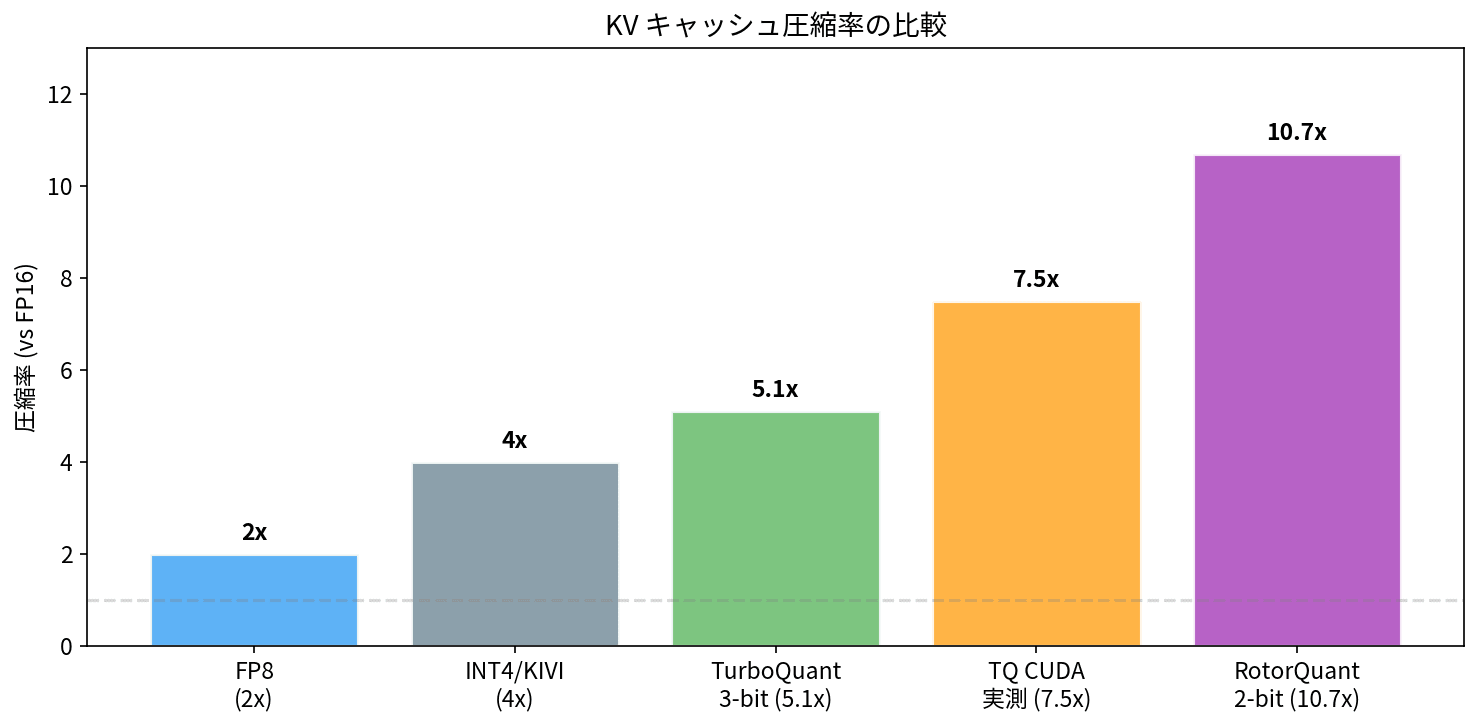
| 手法 | ビット幅 | 圧縮率(vs FP16) | キャリブレーション | 精度ロス |
|---|---|---|---|---|
| FP8 | 8 | 2x | 不要 | わずか |
| INT4(KIVI 等) | 4 | 4x | 必要 | あり |
| TurboQuant | 3-4 | 4.9-5.1x | 不要 | 統計的にゼロ |
DGX Spark にとって何がうれしいのか
統合メモリの特性 — "saves DGX twice"
DGX Spark の GB10 は CPU と GPU が LPDDR5x メモリを共有する統合メモリアーキテクチャです。ディスクリート GPU のように VRAM と RAM が分離していないため、KV キャッシュを圧縮すると容量だけでなくメモリ帯域も空きます。NVIDIA Developer Forum では "saves DGX twice" という表現で話題になっています。
メモリギリギリに攻めたモデルほど効果が大きい
ここで注意が必要なのは、TurboQuant はモデルウェイトには効かないという点です。128GB に収まらないモデルが載るようになるわけではありません。効くのは推論時の KV キャッシュだけです。
逆に言えば、メモリギリギリまで攻めたモデルほど恩恵が大きくなります。Nemotron 3 Super 120B-A12B を NVFP4 で載せると約 87GB を消費し、残り 41GB が KV キャッシュ領域です。ここに TurboQuant を適用すれば、実質的に 200GB 相当の KV キャッシュ容量が確保できる計算になります。
小さいモデルは元々 KV キャッシュに余裕があるので、圧縮の恩恵は相対的に薄くなります。
MoE モデルとの相性
MoE(Mixture of Experts)モデルは、この構図がさらに極端になります。MoE は多数の「エキスパート」サブネットワークを持ちながら、1 トークンあたりはその一部だけを使って推論するアーキテクチャです。
たとえば Qwen3.5-35B-A3B は総パラメータ 35B ですが、1 トークンの推論に使う active parameters は 3B だけです。INT4 量子化ならウェイトは数 GB に収まるため、128GB のうちほとんどが KV キャッシュに使えます。ところが 262K トークンのコンテキストを FP16 で扱うと KV キャッシュだけで数十 GB に達するため、せっかくのメモリ効率が台無しになります。
TurboQuant / RotorQuant で KV キャッシュを 5 倍に圧縮すれば、MoE モデルの「ウェイトは軽いのに KV キャッシュが重い」というアンバランスを解消できる計算です。
ただし、これはあくまで理論的な試算です。実際に DGX Spark 上で MoE モデル + KV キャッシュ圧縮の組み合わせを動かした公開データはまだ少なく、vLLM への本格統合後に改めて実測してみたいところです。
コミュニティの動き
論文公開から 3 日で、vLLM(Draft PR #38280)、llama.cpp(Issue #20977)、MLX と主要な推論フレームワークすべてに Feature Request や PoC が出ています。DGX Spark コミュニティでは vLLM のコミュニティ fork を使って GLM-4.7-Flash で FP8 比 +22% の速度向上が報告されるなど、フォーラムで活発な議論が続いています。
3 月 27 日には vLLM に RotorQuant の Feature Request(Issue #38291)も立ち、同じコミュニティ fork の multiquant ブランチには RotorQuant の統合と 2-bit 版の追加も済んでいます。
こうした動きの中で、RotorQuant(scrya-com/rotorquant)という代替実装も登場しました。TurboQuant が 128x128 の回転行列(16,384 パラメータ)を使うのに対し、RotorQuant は Clifford 代数の rotor で 356 パラメータまで圧縮しながら同等の品質を維持しています。Triton(GPU 向け JIT コンパイラ)で実装されているため、CUDA C++ のビルド問題を回避できるのが実用上の大きな利点です。
DGX Spark で動かしてみる
検証環境
| 項目 | 値 |
|---|---|
| デバイス | NVIDIA DGX Spark (GB10, SM121) |
| メモリ | 128GB LPDDR5x (UMA) |
| CUDA | 13.0 / 13.2 |
| OS | Ubuntu 24.04 aarch64 |
| Driver | 580.142 |
vLLM への統合はまだ道半ば
まずフォーラムで話題になっていた vLLM のコミュニティ fork(turboquant ブランチ)を DGX Spark でビルドすることを試みました。eugr/spark-vllm-docker をベースにパッチを当てる方法で、vLLM の起動と推論自体は成功したものの、KV キャッシュの圧縮が実際に効いている状態にはなりませんでした。カスタム Attention バックエンドの実装が開発途上であること、ビルドシステムの互換性問題などが重なり、3 月 27 日時点ではフル機能の再現には至っていません。
fork の開発者は GLM-4.7-Flash で FP8 比 +22% の速度向上と 2.3 倍の KV キャッシュ圧縮をフォーラムで報告しており、実装自体は動作しています。vLLM 本家への Draft PR(#38280)も進行中なので、公式統合を待つのが現実的です。
RotorQuant なら pip install で動く
vLLM fork のビルドで苦戦する一方、RotorQuant は驚くほど簡単に動きました。
git clone https://github.com/scrya-com/rotorquant
cd rotorquant
pip install -e .
pip install triton
NGC PyTorch コンテナの中でこれだけです。CUDA C++ カーネルのビルドは不要で、Triton が JIT でカーネルを生成してくれます。
Triton ベンチマーク — 最大 188 倍の高速化
まずは RotorQuant の Triton カーネルが DGX Spark でどの程度の性能を出すか、ベンチマークを取りました。
| ベンチマーク | PyTorch (ms) | Triton (ms) | Speedup |
|---|---|---|---|
| Rotor Sandwich (16K vecs) | 16.8 | 0.138 | 122x |
| Full Pipeline (16K vecs) | 36.9 | 0.196 | 188x |
| Fused Attention Score (4K kv_len) | 0.247 | 0.021 | 11.6x |
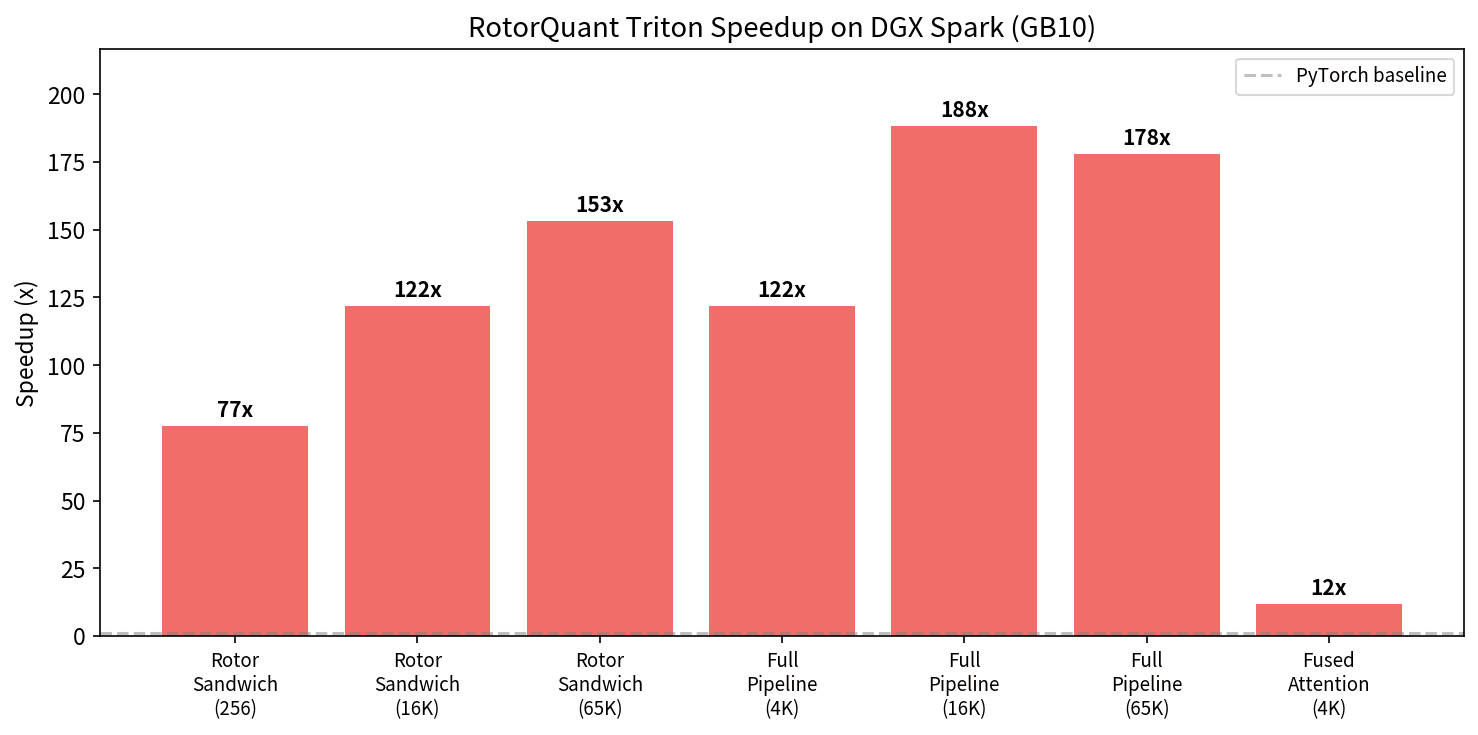
Triton の JIT コンパイルが GB10 のマイクロアーキテクチャに合わせて最適化してくれるため、手書き CUDA カーネルの互換性問題を回避しつつ高い性能が出ています。
TurboQuant vs RotorQuant — 圧縮品質の比較
同じリポジトリに TurboQuant と RotorQuant の両方の実装が含まれているため、GB10 上で直接比較できます。
| 項目 | TurboQuant | RotorQuant |
|---|---|---|
| MSE (3-bit, d=128) | 0.0341 | 0.0338 |
| Inner Product 相関 (3-bit) | 0.914 | 0.923 |
| Needle-in-Haystack (2-4 bit) | 9/9 EXACT | 9/9 EXACT |
| パラメータ数 | 16,399 | 356 (46x 少ない) |
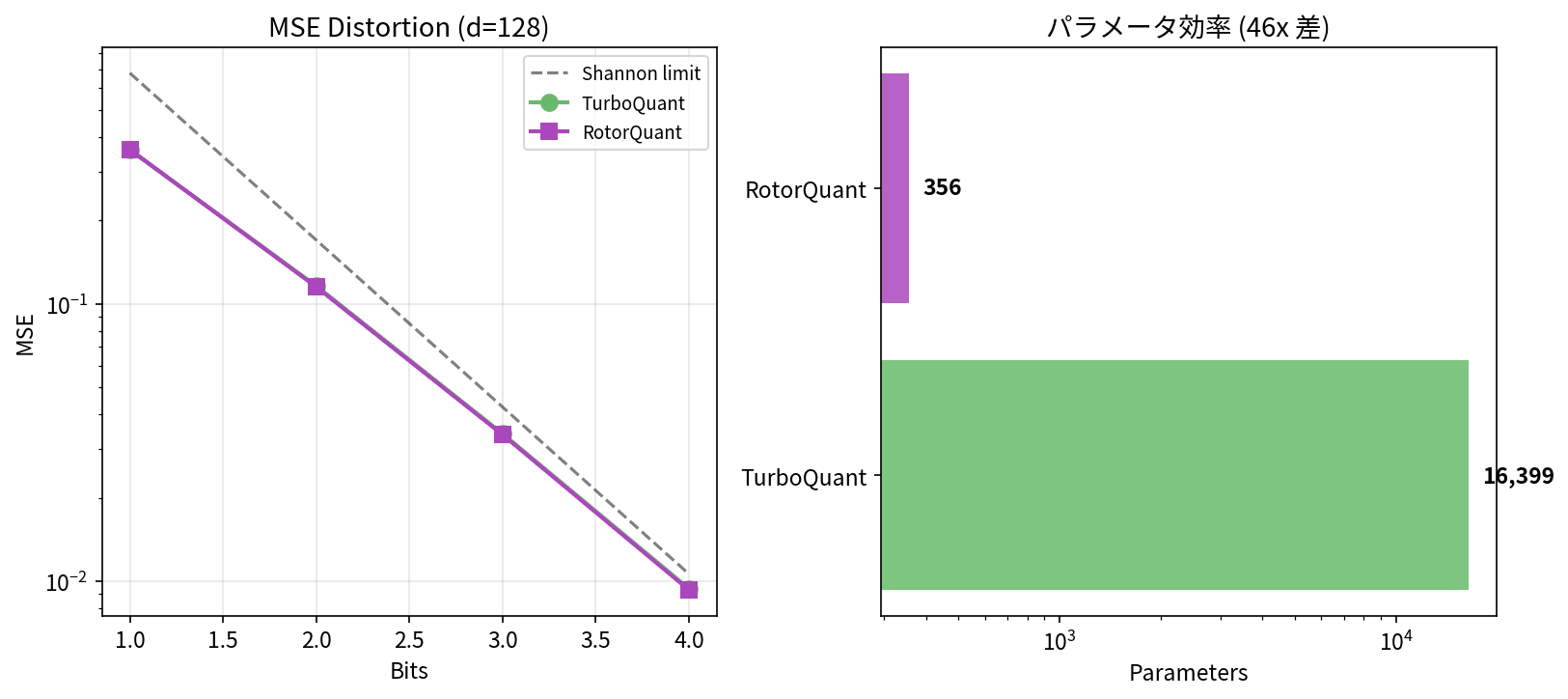
圧縮品質はほぼ同等で、どちらも Needle-in-a-Haystack を全問正解しています。RotorQuant はパラメータ数が 46 分の 1(16,399 → 356)と桁違いに少ないのが特徴です。
TurboQuant CUDA カーネルも GB10 で動作確認
TurboQuant の QJL CUDA カーネルも、vllm-ng17e イメージ(PyTorch 2.12、CUDA 13.0)の中で JIT ビルドに成功しました。NGC 25.03(PyTorch 2.7)では SM121 が未サポートでビルドできなかったため、新しい PyTorch が必要です。
| ベンチマーク | 結果 |
|---|---|
| メモリ圧縮(8K seq, 3-bit) | 7.5x |
| Attention 速度(8K seq) | FP16 の 1.1x(ほぼ同等) |
| Cosine Similarity(CUDA vs PyTorch) | 0.899 |
メモリ圧縮は 7.5 倍と効果的ですが、CUDA カーネルの速度は PyTorch 版と大差ありません。これは QJL カーネルが GB10 の SM121 に最適化されていないためで、フォーラムでも既知の課題として認識されています。
実際のモデルで推論してみる
Qwen2.5-3B — Needle-in-Haystack
RotorQuant の推論デモ(poc_high_context.py)を使って、Qwen2.5-3B-Instruct で Needle-in-a-Haystack テストを実施しました。
| ビット | 2K 速度 | 4K 速度 | 8K 速度 | Needle (全長) |
|---|---|---|---|---|
| 2-bit | 11.0 tok/s | 2.7 tok/s | 1.4 tok/s | 3/3 FOUND |
| 3-bit | 5.3 tok/s | 3.5 tok/s | 1.4 tok/s | 3/3 FOUND |
| 4-bit | 8.6 tok/s | 3.6 tok/s | 2.3 tok/s | 3/3 FOUND |
| FP16 | 7.0 tok/s | — | — | FOUND |
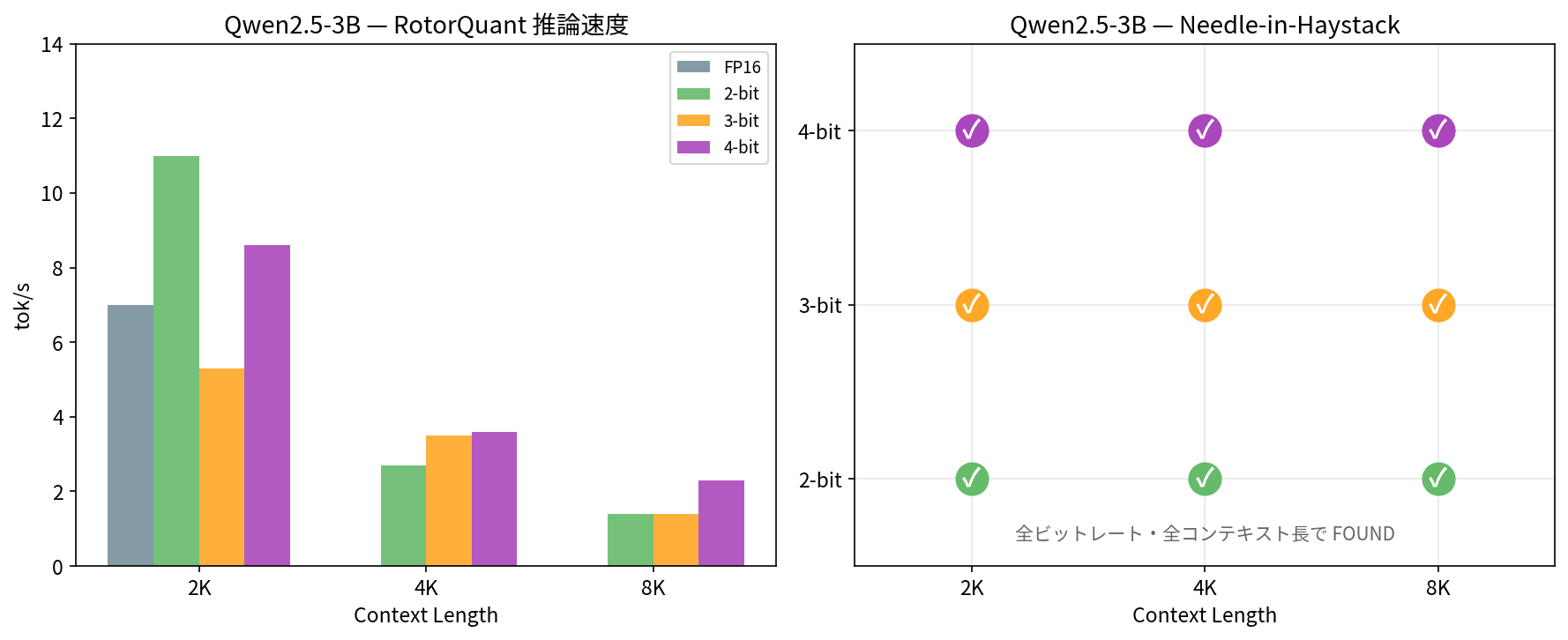
全ビットレート、全コンテキスト長で Needle を正しく検出できています。3-bit での Attention Fidelity(Cosine Similarity)は 0.991〜0.995 で、FP16 とほとんど区別がつきません。
Qwen3.5 や Gemma 3 でも試みましたが、これらのモデルは KV キャッシュの内部実装が RotorQuant の検証スクリプトと互換性がなく、正常な結果が得られませんでした。純粋な Transformer アーキテクチャの Qwen2.5 系であれば問題なく動作しています。
現時点の制約
検証していく中で、いくつかの制約も見えてきました。
まず、TurboQuant / RotorQuant はあくまで Transformer の Attention レイヤーにある KV キャッシュを圧縮する技術です。Nemotron 9B-v2-JP のように Mamba レイヤーを含むハイブリッドモデルでは、Mamba 側のキャッシュには効かず、今回の検証でも vLLM 経由・RotorQuant 経由ともに圧縮効果を確認できませんでした。純粋な Transformer モデル(Qwen2.5 系や Gemma 系など)が現時点では対象になります。
また、vLLM や llama.cpp への本格統合はまだこれからです。公式コードは Q2 2026 リリース予定(turboquant.net)で、vLLM の Draft PR も Phase 1(アルゴリズム検証)が終わった段階です。コミュニティ fork は動いていますが、今の段階では再現に手間がかかります。
一方で、TurboQuant の発表から 2 日で RotorQuant が登場し、フォーラムでは「Why MultiQuant…」という声も出ているように、複数の量子化手法を組み合わせる方向に進みそうな気配もあります。この領域の動きは非常に速いので、引き続きウォッチしていきたいところです。
公開後のアップデート(2026-03-29 追記)
記事公開後もコミュニティの動きが続いているので、実際に手元で試した結果も含めて補足しておきます。
RotorQuant の aarch64 対応 PR を検証
RotorQuant に DGX Spark(aarch64)ネイティブ対応の PR #2 が提出されました。setup.py に GPU アーキテクチャの自動検出が追加され、Blackwell 世代(compute capability 12.x)では PTX フォールバック付きでビルドされるようになっています。
この PR の変更と、別途提出された PR #4(trivector ストレージ削除後のバグ修正)を main に手動で適用し、NGC PyTorch 25.03 コンテナで動かしてみました。
=== verify_correctness ===
Rotor sandwich: Cosine sim 1.00000000 PASS
Inverse sandwich: Cosine sim 1.00000000 PASS
Full fused pipeline: MSE 0.033747 PASS
=== benchmark_full_fused ===
n_vecs PyTorch (ms) Triton (ms) Speedup
256 1.905 0.033 57.9x
1024 1.986 0.031 63.3x
4096 3.655 0.031 117.8x
16384 36.996 0.197 187.6x
65536 169.020 0.986 171.4x
Triton ベンチマークは記事公開時とほぼ同じ数値(Full Pipeline 16K で 187.6x)で、trivector 削除後も圧縮品質に影響がないことを確認できました。
なお、CUDA C++ カーネルのビルドは NGC 25.03(PyTorch 2.7)の _get_cuda_arch_flags が SM 12.1 を認識しないため失敗します。これは記事本文で書いた「NGC 25.03 では SM121 未サポート」と同じ制約で、PyTorch 2.12 以降が必要です。Triton パスは問題なく動くので、RotorQuant の実用上の影響はありません。
DGX Spark 専用の vLLM フォーク
mitkox/vllm-turboquant という vLLM フォークも見つけました。コードを読んでみると、SM121(DGX Spark)を明示的にターゲットとした TurboQuant 統合フォークで、CacheConfig のバリデーションで (major, minor) != (12, 1) の場合はエラーにする処理が入っています。文字通り DGX Spark 専用です。
vllm serve <model> --kv-cache-dtype turboquant25 --enable-turboquant
Triton と FlashInfer のハイブリッド構成で、記事で紹介した flash7777/vllm とは別のアプローチを取っています。2.5 ビットと 3.5 ビットの 2 段階が選べて、メタデータ JSON でレイヤーごとの量子化パラメータを制御する設計になっていました。vLLM のフルビルドが必要なため今回は動作確認までは至っていませんが、構成としてはかなり作り込まれている印象です。
vLLM 本家 PR と llama.cpp の進捗
vLLM 本家の Draft PR #38280 は活発にレビューが進んでいる一方で、Qwen3.5-27B-FP8 でのエラーや Qwen2.5-7B でのガベージ出力といったバグ報告も上がっています。Phase 1 時点でスループットが BF16 の 0.6 倍程度とまだ遅いこともあり、本番利用にはもう少し時間がかかりそうです。
llama.cpp 方面では、ik_llama.cpp で CPU 版の tq3_0 実装が動作確認されています。GPU ではなく CPU での実装ですが、RoPE と Hadamard 変換の非可換性(20.8% の RMSE 偏差)といった技術的な発見もあり、今後の改善につながりそうです。
まとめ
TurboQuant と RotorQuant を DGX Spark で検証してみて、いくつかのことがわかりました。
KV キャッシュの 3 ビット圧縮は理論だけでなく実際に動作し、Needle-in-a-Haystack のような厳密なテストもパスします。RotorQuant の Triton カーネルは pip install だけで DGX Spark 上で動き、最大 188 倍の高速化と 7.5 倍以上のメモリ圧縮を実証できました。
一方、vLLM への本格統合にはまだ時間がかかりそうです。コミュニティ fork は活発に開発されていますが、再現ビルドにはそれなりのハードルがあります。
DGX Spark の統合メモリ環境では、KV キャッシュ圧縮が容量と帯域の両方に効くため、ディスクリート GPU 以上にインパクトが大きいと感じています。公式統合を待ちつつ、RotorQuant のような pip install で試せるツールで事前検証を進めておくのがよさそうです。
参考リンク
- TurboQuant 論文 (arXiv:2504.19874)
- Google Research Blog: TurboQuant
- turboquant.net(公式プロジェクトサイト)
- PolarQuant 論文 (arXiv:2502.02617)
- QJL 論文 (arXiv:2406.03482)
- QJL 公式コード (GitHub)
- RotorQuant (GitHub)
- vLLM Issue #38171: TurboQuant Support
- NVIDIA Forum: Why TurboQuant saves DGX twice
- flash7777/vllm turboquant ブランチ
- eugr/spark-vllm-docker
- llama.cpp Issue #20977: TurboQuant support
- vLLM Issue #38291: RotorQuant Support
- flash7777/vllm multiquant + RotorQuant リリース
- MLX TurboQuant (Blaizzy/mlx-vlm PR #858)









