
NVIDIA Nemotron 3 Nano Omni を DGX Spark で動かしてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
NVIDIA から Nemotron 3 Nano Omni が 2026 年 4 月 28 日にリリースされました。テキスト・画像・音声・動画の 4 つの入力を一つのモデルで扱える Omni モデルで、30B-A3B の Mamba+Transformer ハイブリッド MoE 構成です。NVIDIA の公式ブログでは「他オープン Omni モデル比でマルチドキュメント 7.4×、動画 9.2× のスループット」「マルチモーダル知能が 20% 向上」とアピールされていて、リリース当日に Hugging Face / OpenRouter / build.nvidia.com / Ollama 0.22 / SageMaker JumpStart まで一気に対応するという畳みかけぶりでした。
DGX Spark や DGX Station が vLLM 公式 blog で正式サポート対象 GPU として明記されているので、早速手元の DGX Spark で動かしてみました。NVFP4(~21 GB)/ FP8(~33 GB)/ BF16(~62 GB)の 3 量子化バリアントが同時公開されているので、それぞれの起動・レイテンシ・出力品質を比較しつつ、テキスト・画像・音声・動画を順に投入して動作確認しています。
手元で実測した手応えだけ先に書いておきます。NVFP4 バリアント(~21 GB)は DGX Spark で 4 つの modality をすべて短時間で返す仕上がりで、画像(PPE 検出 2 秒)・音声("Mary had a little lamb" の transcribe 0.85 秒)・動画(コンベア 15 秒の状況把握 0.64 秒)が普通に動きました。同じ PPE 画像を、量子化とバックエンドを揃えた Gemma 4 31B IT NVFP4(vLLM 0.20.0)にも投げてみたところ、こちらは 9.78 秒で返ってきています。同じ NVFP4 同士でも 0.67 秒 vs 9.78 秒と大きく差がつくのが、Omni のサイズ感を体感できる速報のキモです。
Nemotron 3 Nano Omni の概要
モデルファミリー
| バリアント | 総パラメータ | Active | サイズ目安 | 推奨ランタイム |
|---|---|---|---|---|
| BF16 | 30B-A3B MoE | 3B | ~62 GB | vLLM 0.20+, TensorRT-LLM |
| FP8 | 30B-A3B MoE | 3B | ~33 GB | vLLM 0.20+, NIM, SageMaker JumpStart |
| NVFP4 | 30B-A3B MoE | 3B | ~21 GB | vLLM 0.20+ + --moe-backend flashinfer_cutlass |
3 バリアントとも入力はテキスト + 画像 + 音声 + 動画、出力はテキスト。256K コンテキストです。Mamba2 + Transformer ハイブリッドで、画像エンコーダに CRADIO v4-H、音声エンコーダに Parakeet を統合しています。エンコーダ部分は量子化を避けて BF16 のまま維持されているので、入力品質は落ちません。
アーキテクチャの要点
ハイブリッド MoE は 30B 規模の総パラメータのうち推論時にアクティブなのは 3B だけで、スループットを稼ぎつつ表現力を保つ作りです。動画は Conv3D + EVS(Efficient Video Sampling)で冗長フレームを間引きしていて、--video-pruning-rate 0.5 がデフォルト推奨でした。生成側は Reasoning モードがデフォルト ON で、--reasoning-parser nemotron_v3 を渡すと <think>...</think> で reasoning content と最終回答を分離できます。tool calling は --tool-call-parser qwen3_coder を指定する形になっていて、Qwen3 系互換のフォーマットで返ってきます。
ライセンス
NVIDIA Nemotron Open Model License。商用利用可能で、weights / datasets / training techniques がオープンに公開されています。
デプロイ先の選択肢
リリース当日から下記のようにほぼ揃っています。今回は DGX Spark + vLLM 0.20+ に絞りますが、選択肢の全体像を整理しておきます。
| デプロイ先 | バリアント | 4 modality | 用途 |
|---|---|---|---|
| DGX Spark + vLLM 0.20+ | NVFP4 / FP8 / BF16 | 全対応 | 本記事。ローカル完結、量子化を選べる |
| DGX Spark + Ollama 0.22 | GGUF(テキスト+画像) | 一部対応 | 最短で動かす用途。音声・動画は未対応 |
| AWS SageMaker JumpStart | FP8 | 全対応 | AWS 環境での利用 |
| build.nvidia.com / NIM クラウド | NVFP4 / FP8 | 全対応 | PoC や試運転、課金は AWS Marketplace 等経由 |
SageMaker JumpStart 側は huggingface-vlm-nvidia-nemotron3-nano-omni-30ba3b-reasoning-fp8 という model_id で、推奨インスタンスは ml.p4d.24xlarge / ml.p5.48xlarge。JumpStartModel(...).deploy(accept_eula=True) の数行で立ち上がります。詳細は AWS Machine Learning Blog の記事 が分かりやすいです。データガバナンスを社内で完結したい・ライセンス的に外に出せないデータを扱う場合は DGX Spark のローカル経路が、ピーク時のスケールやマルチテナント運用が必要な場合は JumpStart 経路が、それぞれ向いていそうです。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | NVIDIA DGX Spark |
| GPU | NVIDIA GB10(128 GB 統合メモリ、sm_121) |
| OS | Ubuntu 22.04(ARM64/SBSA) |
| CUDA | 13.0 |
| Python | 3.12.12 |
| vLLM | 0.20.0(vllm[audio] extras) |
| torch | 2.11.0+cu130 |
| transformers | 5.7.0 |
DGX Spark での立ち上げ手順
vLLM 0.20.0 のインストール
vLLM 公式 blog で vllm[audio]==0.20.0 が明示されています。audio extras を入れないと /v1/chat/completions に音声を流したときに ValidationError になるので、extras 込みで指定しておきます。
mkdir -p ~/works/nemotron3-omni && cd ~/works/nemotron3-omni
uv venv --python 3.12
source .venv/bin/activate
uv pip install "vllm[audio]==0.20.0"
NVFP4 を起動する
NVFP4 は ~21 GB で DGX Spark 128 GB UMA に余裕で収まります。NVFP4 は --moe-backend flashinfer_cutlass を指定するのが Hugging Face モデルカード推奨です。
vllm serve nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-NVFP4 \
--served-model-name nemotron-omni \
--max-model-len 32768 \
--gpu-memory-utilization 0.5 \
--media-io-kwargs '{"video":{"num_frames":256,"fps":2}}' \
--video-pruning-rate 0.5 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser nemotron_v3 \
--moe-backend flashinfer_cutlass \
--trust-remote-code
FP8 を切り替えて起動する
--moe-backend flashinfer_cutlass は NVFP4 専用なので外し、モデル ID とメモリ設定を変えます。
# FP8(バランス型、~33 GB)
vllm serve nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-FP8 \
--served-model-name nemotron-omni \
--gpu-memory-utilization 0.6 \
--max-model-len 32768 \
--media-io-kwargs '{"video":{"num_frames":256,"fps":2}}' \
--video-pruning-rate 0.5 \
--enable-auto-tool-choice --tool-call-parser qwen3_coder \
--reasoning-parser nemotron_v3 \
--trust-remote-code
BF16 は今回スコープアウト
BF16 バリアントは ~62 GB のモデル本体に加え、画像エンコーダ(CRADIO v4-H, BF16 維持)と音声エンコーダ(Parakeet, BF16 維持)が乗ります。それに対して KV cache(max_model_len 32768 で fp8_e4m3 でも 10 GB 級)も必要で、DGX Spark の 128 GB UMA から OS やキャッシュを引いた残量を考えると、--cpu-offload-gb 16 を組んでも実用域に入りにくい構成です。
量子化バリアント比較ベンチ
同一プロンプト("Explain in 3 short paragraphs how a hybrid Mamba+Transformer mixture-of-experts architecture differs from a dense Transformer LLM, focusing on inference efficiency.")を 5 ラウンドずつ流して、レイテンシと出力スループットを揃えました。Reasoning モードはデフォルト ON のまま回しています。
| バリアント | サイズ | 推論レイテンシ(中央値) | スループット(tokens/s 中央値) |
|---|---|---|---|
| NVFP4 | ~21 GB | 6.63 秒 | 56.94 |
| FP8 | ~33 GB | 7.88 秒 | 50.70 |
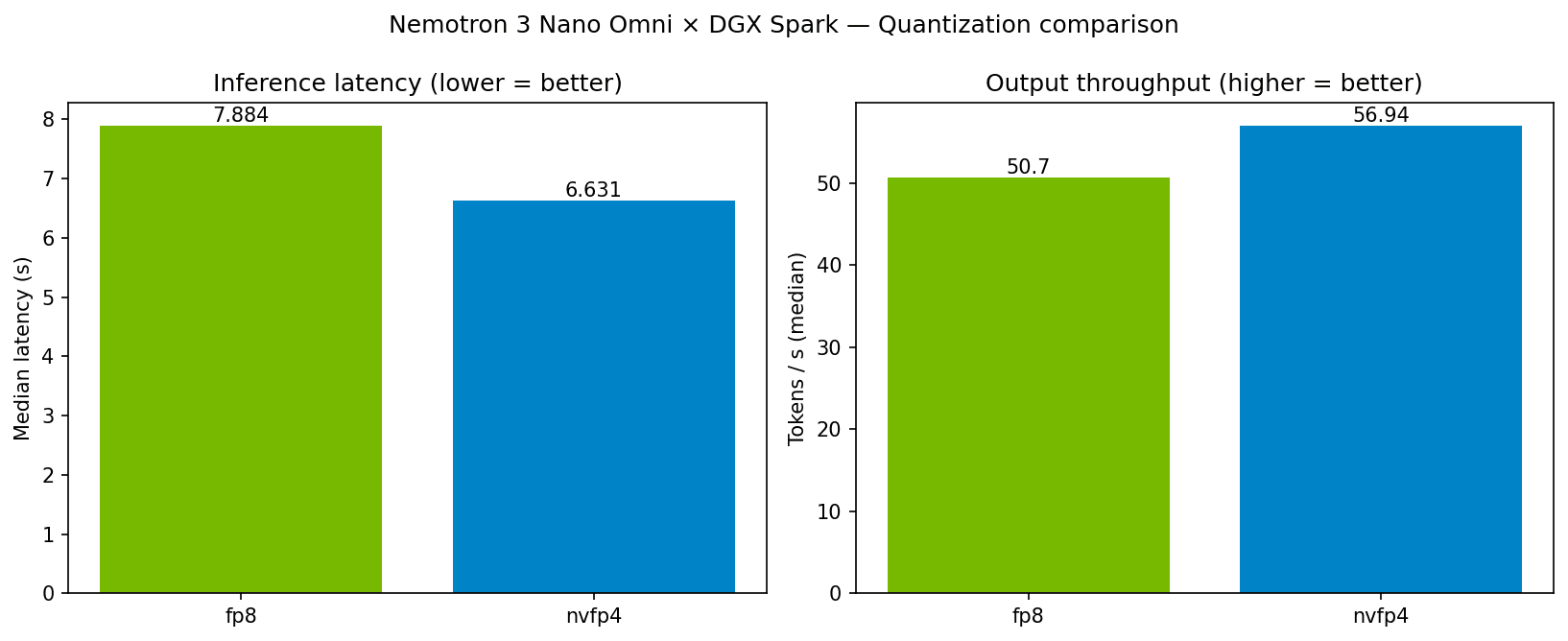
NVFP4 は DGX Spark の Blackwell GB10(sm_121)でネイティブに動く 4 bit 形式で、出力品質を維持しつつ最も小さなメモリで動きます。FP8 比でレイテンシが約 16% 短く、スループットが約 12% 出る数字が出ました。エンコーダ部分は BF16 のまま維持されているので、画像・音声・動画の入力品質は落ちません。
マルチモーダル動作確認
NVFP4 を相手に、OpenAI 互換 /v1/chat/completions の messages[].content 配列に image_url / input_audio / video_url を混在させる形で 4 つの modality を順に投入しました。Reasoning モードは応答が長くなりやすいので、数値比較や transcribe のような短文タスクでは chat_template_kwargs.enable_thinking=false を渡す運用が現実的でした。
たとえば画像を base64 で送信する場合は次のような curl になります。
IMG=$(base64 -w0 ppe-sample.jpg)
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d "{
\"model\": \"nemotron-omni\",
\"messages\": [{\"role\": \"user\", \"content\": [
{\"type\": \"image_url\", \"image_url\": {\"url\": \"data:image/jpeg;base64,$IMG\"}},
{\"type\": \"text\", \"text\": \"List the personal protective equipment visible in this image.\"}
]}],
\"max_tokens\": 800,
\"chat_template_kwargs\": {\"enable_thinking\": false}
}"
type を input_audio(format に wav などを指定)、または video_url(data:video/mp4;base64,...)に変えるだけで音声・動画にも対応できます。
テキスト
Briefly describe what makes a multimodal omni model different from a text-only LLM.
応答 4.87 秒(277 tokens)。冒頭の抜粋は次のような感じです。
A multimodal omni model differs from a text-only LLM in several key ways:
1. Multimodal Input/Output: Unlike text-only LLMs that only process and generate text,
multimodal omni models can handle various data types, such as images, audio, video, and text.
2. Contextual Understanding: Multimodal omni models can better understand context by integrating
information from different modalities. ...
画像(PPE 検出)
過去の Cosmos-Reason2 構造化推論記事 でも利用した以下の画像を投げました。

応答 2.04 秒(108 tokens)。
Based on the image provided, the following personal protective equipment (PPE) is visible:
- Hard hats: Both individuals are wearing hard hats. The woman is wearing a white hard hat, and the man is wearing a yellow one.
- High-visibility vest: The woman is wearing a bright, lime-green high-visibility vest over her shirt.
- Safety glasses: The woman is wearing safety glasses, which are visible under her hard hat. The man is also wearing safety glasses, though they are less distinct.
色や着用状況まで踏み込んで描写してきました。
音声(英語、約 16 秒)
vLLM 公式アセット(mary_had_lamb.ogg)を 16 kHz mono の WAV に変換して送信しました。
応答 0.85 秒(43 tokens)。
A man speaks in the original phonograph a little piece of practical poetry, Mary had a little lamb,
its fleece was white as snow, and everywhere that Mary went, the lamb was sure to go.
蓄音機の歴史的録音という背景まで含めて文字起こしと要約が同時に出ました。
動画(コンベア 15 秒)
過去の VSS Event Reviewer 検証記事 で使ったコンベアライン上のダンボール箱の動画を投げました。

応答 0.64 秒(15 tokens)。
A cardboard box is moving on a conveyor belt that is curved.
短い動画 2 文要約という指示にちゃんと収まる範囲で簡潔に返してきます。
Gemma 4 31B との比較
そもそもモデル構造が違うという前提がありますが、「DGX Spark で同じバックエンド・同じ量子化で動く別系統の VLM と並べたら、Omni のサイズ感とレイテンシはどう感じるか」を見たかったので、PPE サンプル画像 + 同一プロンプト(JSON で ppe_items と overall_compliance を返す指示)を Nemotron 3 Nano Omni(NVFP4) と Gemma 4 31B IT NVFP4 に投げてみました。
Gemma 4 31B IT NVFP4 用の vLLM 起動には --reasoning-parser gemma4 --tool-call-parser gemma4 --max-num-batched-tokens 4096 を渡しています。画像エンコーダの token 数が大きいので max_num_batched_tokens を 2048 → 4096 に上げないと初期化時に弾かれる注意点があります(vLLM 公式 Gemma 4 レシピ 参照)。
速度・サイズ
| 観点 | Nemotron 3 Nano Omni(NVFP4) | Gemma 4 31B IT(NVFP4) |
|---|---|---|
| アーキテクチャ | 30B-A3B Mamba+Transformer MoE | 31B Dense Transformer |
| Active パラメータ | 3B | 31B |
| モデルサイズ | ~21 GB | ~31 GB |
| 量子化 | NVFP4 | NVFP4 |
| 推論バックエンド | vLLM 0.20.0 | vLLM 0.20.0 |
| 実推論時間 | 0.67 秒 | 9.78 秒 |
| 出力トークン数 | 29 | 57 |
実推論時間で約 15 倍の差がつきました。両方とも NVFP4 + vLLM で条件は揃っているので、この差はほぼモデル構造そのものの違いに由来します。Omni は MoE(Mixture-of-Experts)構造で、30B のパラメータを抱えていても、1 トークン生成のときに実際に通すのは 3B 分だけです。一方の Gemma 4 31B は Dense なので、1 トークンごとに 31B 全体を毎回通します。1 トークン生成あたりの「動くパラメータ量」がそのまま 10 倍違うので、レイテンシで 15 倍前後の差がつくのは無理のない結果ですね。MoE が狙う「モデル容量は大きいまま、推論コストは小さく」の効果が、ベンチ数値ではっきり出てきた形です。
出力
両者とも JSON は返してきましたが、絞り込みとフォーマットが少し違います。
// Nemotron 3 Nano Omni(NVFP4、29 tokens、0.67 秒)
{ "ppe_items": ["hard hat", "safety vest"], "overall_compliance": "compliant" }
// Gemma 4 31B IT NVFP4(57 tokens、9.78 秒)
{
"ppe_items": ["hard hat (white)", "hard hat (yellow)", "high-visibility safety vest"],
"overall_compliance": "non_compliant"
}
Gemma 4 は Markdown のコードフェンス込みで返してきて、ヘルメットを色まで分けてリスト化しています。Omni は指示通りに JSON だけ素直に返してきます。
判定が compliant / non_compliant で分かれているのは、画像の解釈の違いです。Omni は「写っている PPE は揃っている → compliant」、Gemma 4 は「safety glasses など写っていない装備まで含めて non_compliant」と見ています。どちらも合理的な判断で、業務に組み込むときには「何をもって compliant とするか」をプロンプトで明示しないと VLM ごとに判定が割れる類の差ですね。
使い分けの目安
| 想定ユース | 向いていそうな選択肢 |
|---|---|
| 大量画像のリアルタイム JSON 構造化出力(短文、低レイテンシ重視) | Nemotron 3 Nano Omni(NVFP4) |
| 音声・動画まで含めたマルチモーダル一機完結 | Nemotron 3 Nano Omni |
| 詳細な色分けや日本語キャプションを丁寧に書かせたい | Gemma 4 31B(NVFP4 / BF16) |
| GGUF をローカルで気軽に差し替えたい | Gemma 4(Ollama 経路) |
日本語環境での扱い
Hugging Face モデルカードを見ると Nemotron 3 Nano Omni は学習言語が英語のみで、Japanese 派生版(過去の nvidia/Nemotron-Nano-9B-v2-Japanese のようなもの)は今回公開されていません。ベンチマーク表にも日本語タスクは含まれていないので、日本語特化のスコアは過去の Gemma 4 ベンチマーク や Nemotron 9B-v2-Japanese ハンズオン の方が参考になりそうです(具体値は後段の表で並べます)。
ただし、試しに日本語プロンプトを叩いてみると応答自体は日本語で普通に返してきます。同じ NVFP4 にテキストと画像で 2 件流してみました(enable_thinking=false)。
テキスト(25.08 秒、279 tokens)
「Nemotron 3 Nano Omni のようなマルチモーダル統合モデルが、テキストのみの LLM と異なる点を簡潔に教えてください。」という投げかけに対する応答(冒頭抜粋)。
Nemotron 3 Nano Omni のようなマルチモーダル統合モデルは、テキストのみの LLM と以下の点で異なります:
1. 多様な入力モードの処理:テキスト以外の入力(画像、音声、動画など)を理解・生成できる。
2. 統合的推論:テキストと他のモードを同時に処理し、文脈に応じた回答や生成が可能(例:画像の説明+テキスト生成)。
3. 文脈の豊かさ:視覚・聴覚情報を組み込むことで、より豊かで正確な文脈理解が可能。
4. 応用領域の拡大:視覚的質問回答、動画解説、音声認識連携など、テキストLLMでは不可能なタスクを実行。
簡潔に:テキストLLMは「言葉だけ」の世界、マルチモーダルモデルは「言葉+視覚・聴覚」の世界を扱う点が主な違いです。
固有名詞は英語のまま、説明部は日本語で構造化されて返ってきました。
画像(PPE 検出、1.17 秒、31 tokens)
同じ PPE サンプル画像に「この画像に写っている個人用保護具(PPE)を、箇条書きで日本語で教えてください。」を添えて投げると、こうなりました。
- 白い安全ヘルメット
- 緑色の安全ベスト
- 黄色い安全ヘルメット
色も含めて日本語で素直に列挙してくれます。英語応答("hard hat / safety vest")と比べても粒度はそれほど落ちていない印象です。
英語ベンチ向けに学習されたモデルなのでスコア上の正式な日本語性能は計測されていませんが、プロンプトを日本語に切り替えるだけで応答が普通に日本語で返るのは、英語前提で書かれたチュートリアルをそのまま日本語ユースに流用するときの安心材料になりそうですね。
参考: JCommonsenseQA でスコアを取ってみる
「英語専用モデルなのに日本語で返ってきた」というだけだと体感頼みなので、過去の Gemma 4 連載と揃えた 3-shot プロンプトで JCommonsenseQA v1.1 の validation 1,119 問を Omni と Gemma 4 31B IT NVFP4 にも投げてみました。両方とも今回の vLLM 0.20.0 + NVFP4 のままです。
| モデル | バックエンド | 正答率 | 平均レイテンシ |
|---|---|---|---|
| Nemotron 3 Nano Omni(NVFP4) | vLLM 0.20.0 | 88.03%(985/1119) | 0.16 秒/問 |
| Gemma 4 31B IT(NVFP4) | vLLM 0.20.0 | 97.77%(1094/1119) | 0.46 秒/問 |
| 参考: Gemma 4 31B BF16 | Ollama | 97.9% | - |
| 参考: Nemotron-Nano-9B-v2-Japanese | Ollama | 91.2% | - |
Gemma 4 31B IT は NVFP4 にしても精度が 97.9% → 97.77% とほぼ落ちないことが確認できました。Omni は学習言語が英語のみ・パラメータも小さめ(Active 3B)にもかかわらず 88% 出ていて、日本語の常識推論もそれなりに通せるレベルでした。Nemotron-Nano-9B-v2-Japanese(91.2%)には届かないものの、テキスト + 画像 + 音声 + 動画を一機完結で扱える Omni がここまで出るのは正直驚きでした。日本語マルチモーダルの本格的な評価(Heron-Bench / JMMMU 等)は改めて別記事でまとめたいと思います。
ハマりポイント
--media-io-kwargs の値が情報源で違う
vLLM 公式 blog は num_frames=512, fps=1、Hugging Face モデルカードは num_frames=256, fps=2 と、推奨値が情報源によって食い違っています。動画 1 本あたりに何フレーム取り込むか × どの fps でサンプリングするかはそのまま VRAM 使用量と推論レイテンシに跳ね返るので、ハードウェア事情に合わせて最初に決め打ちしておくとよさそうです。今回は HF カード側の 256 / fps=2 を採用して、コンベア 15 秒の動画も VRAM を圧迫せずに動かせました。
Reasoning モードで max_tokens 不足だと content が空になる
Nemotron 3 系は <think>...</think> で reasoning content を生成し、その後に最終回答を出します。ところが max_tokens=300 で動画記述(2 文)を頼んだら、reasoning に 300 トークン使い切って content が空(null)になりました。chat_template_kwargs.enable_thinking=false を渡すと 13 トークンで A cardboard box is moving on a conveyor belt that is curved. と即返してきます。短文の動作確認や transcribe では thinking を切る、推論能力を見たいケースでは thinking を効かせて max_tokens を 1500 くらい用意する、という使い分けが現実的でした。
まとめ
リリース当日に DGX Spark で 4 modality すべて動作することを確認できました。NVFP4 が ~21 GB に収まるので、3 つの量子化バリアントの中で起動・レイテンシ・スループットのバランスが日常運用に一番フィットしそうな印象です。同じ NVFP4 + vLLM で並べた Gemma 4 31B IT との 0.67 秒 vs 9.78 秒という差からは、30B 級のモデル容量を持ちつつ推論コストは Active 3B 分に抑える MoE の特性が、ベンチ数値ではっきり可視化されました。JCommonsenseQA でも Omni が 88%、Gemma 4 31B IT が NVFP4 で 97.77%(BF16 比 0.13 ポイント差)と、量子化による精度低下もほぼ気にならないレベルで、日本語常識推論をそこそこ通せるところまで来ているのはうれしい発見でした。
参考情報:









