
NVIDIA RTX PRO 6000 Blackwell で Gemma4 を動かしてみる #GoogleCloudNext
はじめに
こんにちは、すらぼです。
Google Cloud Next' 26 で、 Cloud Run で利用できる GPU "NVIDIA RTX PRO™ 6000 Blackwell Server Edition GPU" が GA されました。
今回は Blackwell を実際に触ってみました。また、せっかくなので同時 Next でリリースされた Gemma4 をデプロイして動作を確認してみました。
NVIDIA RTX PRO 6000 Blackwell Server Edition GPU とは
NVIDIA RTX PRO 6000 Blackwell Server Edition GPU(以下 Blackwell)は、従来から Cloud Run で利用できていた NVIDIA L4 GPU よりもさらに高性能なGPUです。
NVIDIA RTX PRO 6000 Blackwell GPU は、NVIDIA L4 GPU と比べて大幅な性能向上を実現しており、96 GB の vGPU メモリ、1.6 TB/秒の帯域幅に加え、FP4 および FP6 をサポートしています。これにより、基盤となるインフラストラクチャを自ら管理することなく、70B 超のパラメータを持つ大規模モデルを提供できます。Cloud Run では、NVIDIA RTX PRO 6000 Blackwell GPU を Cloud Run サービス、ジョブ、またはワーカープールに、予約不要でオンデマンドにアタッチできます。
https://cloud.google.com/blog/ja/products/serverless/cloud-run-supports-nvidia-rtx-6000-pro-gpus-for-ai-workloads
L4 は vGPU が 24 GB だったため、この部分だけでも大きな性能の向上が見て取れます。
大まかな仕様
Cloud Run で Blackwell GPU の大まかな仕様は以下の通りです。
| 項目 | 内容 |
|---|---|
| GPU 種別 | nvidia-rtx-pro-6000(NVIDIA RTX PRO 6000 Blackwell Server Edition) |
| GPU メモリ(VRAM) | 96 GB |
| vCPU(最小〜最大) | 20〜44* vCPU |
| インスタンス RAM(最小〜最大) | 80〜176* GiB |
| 課金 | 起動中のインスタンスに対して CPU・メモリ・GPU を秒単位で課金 |
| 利用リージョン(Blackwell) | asia-southeast1(シンガポール)、europe-west4、us-central1 など |
参考として、従来の L4 は VRAM 24 GB・最小 4 vCPU / 16 GiB です。
※ vCPU と RAM の最大値は、どちらもブログによる表記です。デフォルトでコンソールから選択できる上限値は、 30 vCPU、 120GiB となっています。
料金の目安(1 インスタンスが起動している間)
今回の構成(20 vCPU・80 GiB・GPU 1 枚・ゾーン冗長なし)で、おおよそ以下のイメージです。
| リソース | 単価(秒あたり) | 1 時間あたりの目安 |
|---|---|---|
| vCPU | $0.0000216 / vCPU秒 | 20 vCPU で 約 $1.55 |
| メモリ | $0.0000024 / GiB秒 | 80 GiB で 約 $0.69 |
| GPU(RTX PRO 6000、冗長なし) | $0.00036522 / 秒 | 約 $1.31 |
| 合計 | 約 $3.55 / 時間(1 インスタンス) |
アイドル状態によって 0 台にスケールインしたときは、インスタンス課金はかかりません。
今回やること
Gemma4 を Cloud Run の Blackwell インスタンスで動かしてみます。
今回は 2B デプロイしてコールドスタートの時間などを計測してみました。
全体の流れ
大まかな流れとして、以下の流れで進んでいきます。
- 必要な設定やリソースを準備(環境変数、API有効化、SA など)
- GCS バケットを作成する
- Cloud Build でモデルをバケットに保存する
- VPC を作成し、Direct VPC Egress を有効化
- Cloud Run に、Gemma4 on Blackwell をデプロイ
- リクエストを送って、動作を確認
デプロイしてみる
実際にデプロイしていきます。
事前準備以外は、全て Cloud Shell 上で実施していきます。
事前準備(Hugging Face)
まず。モデルをダウンロードするために Hugging Face からトークンを取得します。
Hugging Face にサインアップし、メール認証などを済ませます。
Hugging Face で、以下からトークンを取得します。
Read 権限で [Create token] し、発行したトークンを控えておきます。
環境変数
必要な変数を、先にすべて定義しておきます。一番上の HF_TOKEN に、先ほど取得したトークンをセットしてください。
なお、リージョンはシンガポールリージョン(asia-southeast1)を指定する必要があるため注意してください。(東京リージョンではまだ GPU はサポートされていません。)
export HF_TOKEN="<先ほど取得したトークン>"
# 2B モデルの場合は以下
export MODEL_NAME="google/gemma-4-E2B-it"
export SERVICE_NAME="gemma-rtx-vllm-2b"
# 31B の場合は以下
# export MODEL_NAME="google/gemma-4-31B-it"
# export SERVICE_NAME="gemma-rtx-vllm-31b"
export GOOGLE_CLOUD_REGION="asia-southeast1"
export SERVICE_ACCOUNT="vllm-service-sa"
export SERVICE_ACCOUNT_EMAIL="${SERVICE_ACCOUNT}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com"
export MODEL_CACHE_BUCKET="${GOOGLE_CLOUD_PROJECT}-${GOOGLE_CLOUD_REGION}-hf-model-cache"
export GCS_MODEL_LOCATION="gs://${MODEL_CACHE_BUCKET}/model-cache/${MODEL_NAME}"
export VPC_NETWORK="vllm-${GOOGLE_CLOUD_REGION}-net"
export VPC_SUBNET="vllm-${GOOGLE_CLOUD_REGION}-subnet"
export SUBNET_RANGE="10.8.0.0/26"
gcloud config set run/region "${GOOGLE_CLOUD_REGION}"
API 有効化(初回のみ)
必要なAPIを事前に有効化しておきます。既に有効化済みの場合は不要です。
gcloud services enable --project "${GOOGLE_CLOUD_PROJECT}" \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
vpcaccess.googleapis.com \
storage.googleapis.com
サービスアカウント作成
後でリソース削除など行いやすいように、自前でサービスアカウントを作成します。
gcloud iam service-accounts create "${SERVICE_ACCOUNT}" \
--project "${GOOGLE_CLOUD_PROJECT}" \
--display-name "vLLM Service Account"
GCS バケット作成
モデルを配置するためのバケットを作成します。
gcloud storage buckets create "gs://${MODEL_CACHE_BUCKET}" \
--uniform-bucket-level-access --public-access-prevention \
--project "${GOOGLE_CLOUD_PROJECT}" --location "${GOOGLE_CLOUD_REGION}"
Cloud Build でモデルを GCS に配置
今回は Cloud Build を使って、Hugging Face から事前に GCS バケットにモデルを保存しておきます。
gcloud builds submit --project="${GOOGLE_CLOUD_PROJECT}" --region="${GOOGLE_CLOUD_REGION}" --no-source \
--substitutions="_MODEL_NAME=${MODEL_NAME},_HF_TOKEN=${HF_TOKEN},_GCS_MODEL_LOCATION=${GCS_MODEL_LOCATION}" \
--config=/dev/stdin <<'EOF'
steps:
- name: 'gcr.io/google.com/cloudsdktool/google-cloud-cli:slim'
entrypoint: 'bash'
args:
- '-c'
- |
set -e
pip3 install --root-user-action=ignore --break-system-packages huggingface_hub[cli]
echo "Downloading the model..."
if [[ "$_HF_TOKEN" != "" ]]; then
hf download "$_MODEL_NAME" --token $_HF_TOKEN --local-dir "./model-cache/$_MODEL_NAME"
else
hf download "$_MODEL_NAME" --local-dir "./model-cache/$_MODEL_NAME"
fi
echo "Uploading the model..."
gcloud storage cp -r "./model-cache/$_MODEL_NAME" "$_GCS_MODEL_LOCATION"
options:
machineType: 'E2_HIGHCPU_32'
diskSizeGb: 500
EOF
Direct VPC Egress 用ネットワーク
GCS からの高速でモデルを取得するために、 Direct VPC Egress の準備をします。
gcloud compute networks create "${VPC_NETWORK}" \
--subnet-mode=custom \
--bgp-routing-mode=regional \
--project "${GOOGLE_CLOUD_PROJECT}"
gcloud compute networks subnets create "${VPC_SUBNET}" \
--network="${VPC_NETWORK}" \
--region="${GOOGLE_CLOUD_REGION}" \
--range="${SUBNET_RANGE}" \
--enable-private-ip-google-access \
--project "${GOOGLE_CLOUD_PROJECT}"
バケット IAM
バケットのIAMも作っておきます。
gcloud storage buckets add-iam-policy-binding "gs://${MODEL_CACHE_BUCKET}" \
--member "serviceAccount:${SERVICE_ACCOUNT_EMAIL}" \
--role "roles/storage.admin" \
--project "${GOOGLE_CLOUD_PROJECT}"
vLLM / Cloud Run 変数
vLLM や Cloud Run のパラメータを準備します。
Cloud Run のパラメータについては、検証を目的としているので最小限の値に設定しています。
export MAX_MODEL_LEN="32767"
export QUANTIZATION_TYPE="fp8"
export KV_CACHE_DTYPE="fp8"
export GPU_MEM_UTIL="0.95"
export TENSOR_PARALLEL_SIZE="1"
export MAX_NUM_SEQS="1"
export CLOUD_RUN_CPU_NUM=20
export CLOUD_RUN_MEMORY_GB=80
export CLOUD_RUN_MAX_INSTANCES=1
export CLOUD_RUN_CONCURRENCY=1
vLLM コンテナ引数
コンテナ引数を1つに集約しておきます。変更する場合は、ここを事前に書き換えてください。
CONTAINER_ARGS=(
"vllm"
"serve"
"${GCS_MODEL_LOCATION}"
"--served-model-name" "${MODEL_NAME}"
"--enable-log-requests"
"--enable-chunked-prefill"
"--enable-prefix-caching"
"--generation-config" "auto"
"--enable-auto-tool-choice"
"--tool-call-parser" "gemma4"
"--reasoning-parser" "gemma4"
"--dtype" "bfloat16"
"--quantization" "${QUANTIZATION_TYPE}"
"--kv-cache-dtype" "${KV_CACHE_DTYPE}"
"--max-num-seqs" "${MAX_NUM_SEQS}"
"--gpu-memory-utilization" "${GPU_MEM_UTIL}"
"--tensor-parallel-size" "${TENSOR_PARALLEL_SIZE}"
"--load-format" "runai_streamer"
"--port" "8080"
"--host" "0.0.0.0"
)
if [[ "${MAX_MODEL_LEN}" != "" ]]; then
CONTAINER_ARGS+=("--max-model-len" "${MAX_MODEL_LEN}")
fi
export CONTAINER_ARGS_STR="${CONTAINER_ARGS[*]}"
echo "Deployment string: ${CONTAINER_ARGS_STR}"
Cloud Run へデプロイ
ようやく準備が整ったので、Cloud Run にデプロイをしていきます。
Gemma4 用のイメージを使うことで、そのまま動かすことができます。
gcloud beta run deploy "${SERVICE_NAME}" \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project "${GOOGLE_CLOUD_PROJECT}" \
--region "${GOOGLE_CLOUD_REGION}" \
--service-account "${SERVICE_ACCOUNT_EMAIL}" \
--execution-environment gen2 \
--no-allow-unauthenticated \
--cpu="${CLOUD_RUN_CPU_NUM}" \
--memory="${CLOUD_RUN_MEMORY_GB}Gi" \
--gpu=1 \
--gpu-type=nvidia-rtx-pro-6000 \
--no-gpu-zonal-redundancy \
--no-cpu-throttling \
--max-instances "${CLOUD_RUN_MAX_INSTANCES}" \
--concurrency "${CLOUD_RUN_CONCURRENCY}" \
--network "${VPC_NETWORK}" \
--subnet "${VPC_SUBNET}" \
--vpc-egress all-traffic \
--set-env-vars "MODEL_NAME=${MODEL_NAME}" \
--set-env-vars "GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT}" \
--set-env-vars "GOOGLE_CLOUD_REGION=${GOOGLE_CLOUD_REGION}" \
--port=8080 \
--timeout=3600 \
--cpu-boost \
--startup-probe tcpSocket.port=8080,initialDelaySeconds=240,failureThreshold=40,timeoutSeconds=10,periodSeconds=15 \
--command "bash" \
--args="^;^-c;${CONTAINER_ARGS_STR}"
認証(invoker とトークン)
制限をかけているため、認証をパスできるように権限やトークンの設定をします。
まず、認証して ADC を取得します。
gcloud auth application-default login
その後、権限付与やトークンを環境変数にセットします。
export SERVICE_URL=$(gcloud run services describe "${SERVICE_NAME}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--format='value(status.url)')
gcloud run services add-iam-policy-binding "${SERVICE_NAME}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--member="user:$(gcloud config get-value account)" \
--role="roles/run.invoker"
export TOKEN=$(python3 -c "
import google.oauth2.id_token
import google.auth.transport.requests
print(google.oauth2.id_token.fetch_id_token(
google.auth.transport.requests.Request(),
'${SERVICE_URL}'))
")
呼び出してみる
デプロイが済んだので、実際に呼び出してみます。
推論 API の動作確認
以下の curl コマンドでレスポンスを確認してみます。
curl -s "${SERVICE_URL}/v1/chat/completions" \
-H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"model": "'${MODEL_NAME}'",
"messages": [{"role": "user", "content": "空が青いのはなぜですか。"}],
"max_tokens": 1024,
"chat_template_kwargs": {"enable_thinking": false},
"skip_special_tokens": true
}' | jq -r '.choices[0].message.content'
初回はコールドスタートになるため、レスポンスが返ってくるまでに数分単位で待ちますが、以下の様にレスポンスが返ってきました。
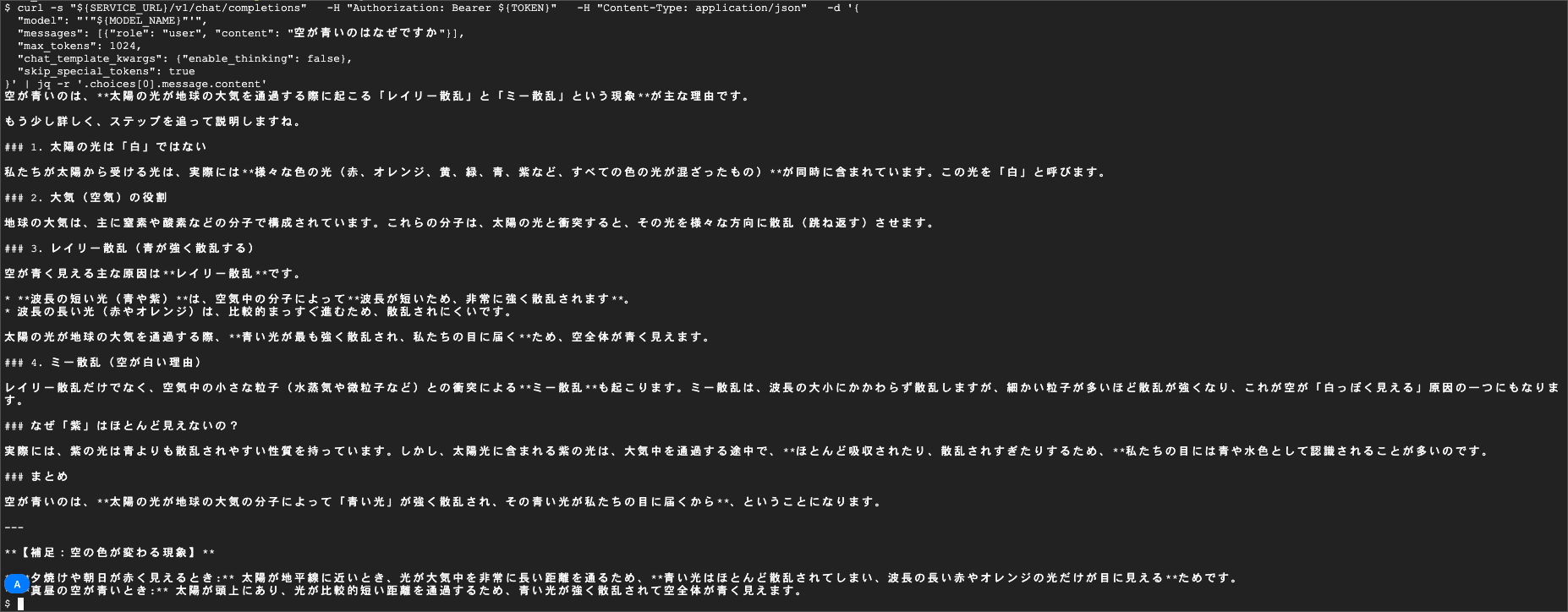
コールドスタートとウォームの比較
レスポンスまでがかなり時間がかかったので、コールドスタートによってどのくらい時間がかかるのかも確認してみました。
リクエストをシンプルにして、推論にかかる時間を極力短くし、0台状態から以下のスクリプトを実行してみました。
初回のリクエストはコールドスタートになりますが、直後にもう一度同じリクエストをすることでコールドスタートを避けてリクエストを行っています。
read -r -d '' REQUEST_BODY <<'EOF' || true
{
"model": "google/gemma-4-31B-it",
"messages": [{"role": "user", "content": "空が青いのはなぜですか。2文で答えて。"}],
"max_tokens": 512,
"chat_template_kwargs": {"enable_thinking": false},
"skip_special_tokens": true
}
EOF
measure() {
local label="$1"
local outfile="$2"
echo ""
echo "=== ${label} ==="
local start end
start=$(date +%s.%N)
local http_code
http_code=$(curl -sS "${SERVICE_URL}/v1/chat/completions" \
-H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
-d "${REQUEST_BODY}" \
-o "${outfile}" \
-w "%{http_code}" \
--max-time 3600)
end=$(date +%s.%N)
echo "HTTP=${http_code} WALL_CLOCK=$(python3 -c "print(round(${end} - ${start}, 2))")s"
if [[ "${http_code}" == "200" ]]; then
jq -r '.choices[0].finish_reason' "${outfile}"
jq -r '.choices[0].message.content' "${outfile}" | head -5
else
head -5 "${outfile}"
fi
}
# インスタンス 0 台のとき
measure "COLD" "/tmp/gemma_cold.json"
sleep 10
# コールド完了直後
measure "WARM" "/tmp/gemma_warm.json"
1回のみの検証ですが、実施した結果は以下の様になりました。
差分は 約250秒 となっており、インスタンスを起動するまでに4分以上かかることがわかりました。
=== COLD ===
HTTP=200 WALL_CLOCK=252.37s
stop
太陽光が地球の大気にある空気分子に当たり、四方八方に散乱するためです。特に波長の短い青い光が散乱しやすいため、空は青く見えます。
=== WARM ===
HTTP=200 WALL_CLOCK=1.52s
stop
太陽の光が地球の大気にある空気の分子に当たり、あらゆる方向に散乱するためです。その際、波長の短い青い光が特に強く散乱されるため、空は青く見えます。
この長い起動時間は、主にモデルのロード(起動するたびに GCS から取得している)に大きな時間がかかっていることが考えられます。
今回はコールドスタートで検証しましたが、負荷上昇によるスケールアウトでも同様の時間がかかります。
スケールインまでの時間
検証中に度々スケールインが発生していたので、スケールインまでの時間も確認してみました。
一般的な Cloud Run と同様に、10分程度アイドル状態になるとスケールインされるようです。
以下の画像の場合だと、 23:56 にアイドル状態に入ったのち、 0:06 にスケールインイベントが発生していることがわかります。
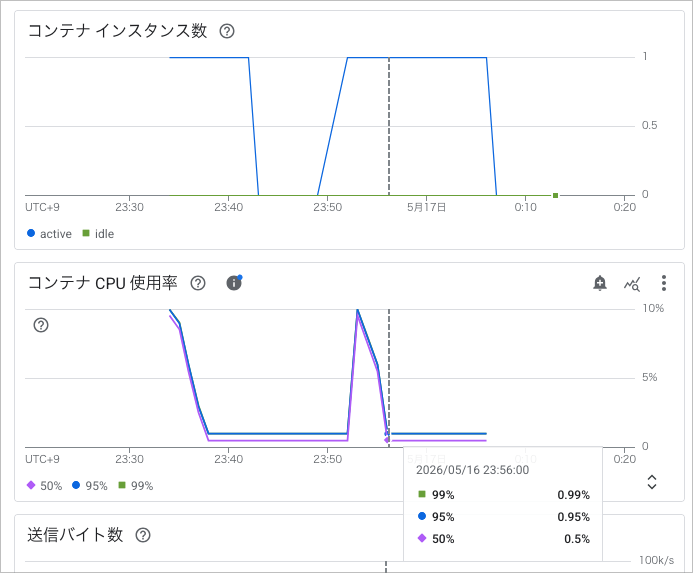
処理が完了し、アイドル状態に入ったタイミング
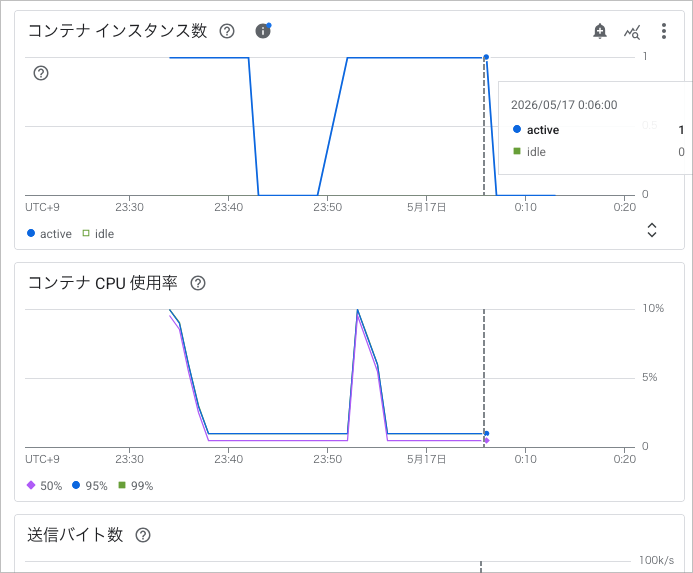
10分後にスケールイン
呼び出してみた結果
呼び出しや動作確認をしてみた結果、以下の様なことがわかりました。
- Blackwell に Gemma4 をデプロイすると、シンプルなプロンプトだと1秒程度でレスポンスが返ってくる
- 約10分程度アイドル時間が発生するとスケールインされる
- インスタンスの追加には4分以上必要(コールドスタートやスケールアウト時)
Cloud Run の強力な Scale to Zero ですが、Gemma4 をホストする場合は約4分のコールドスタートを許容する必要があります。
やってみた感想
NVIDIA RTX PRO 6000 Blackwell Server Edition GPU に Gemma4 を乗せて実際に動作を確認するところまで試してみました。
コンテナの事前ビルドなどは一切不要で、既存のイメージを使ってデプロイするだけでLLMをセルフホストできる点は非常に魅力的と感じました。
一方で、インスタンスの起動には非常に長い時間(今回のケースでは4分以上)がかかるため、少ないインスタンスでスケーリングをするにはパフォーマンスがかなり不安定になりそうといった印象も受けました。
ある程度負荷の上下が少ないワークロードや、起動時間を許容できるワークロードであれば自動スケーリングを用いることでコスト最適化が期待できそうですが、リクエストに応じて素早くスケーリングが必要なワークロードでは最低インスタンス数や手動・スケジュールによるスケーリングなど運用面での調整が必要そうです。
というわけで、Blackwell の検証記事でした。この記事が皆さんの役に立てれば幸いです。
以上、すらぼでした!
参考資料









