
Discord のカスタムコマンドを Amazon Transcribe を使って音声入力で実行できるようにしてみた
はじめに
Discord Bot にスラッシュコマンドを実装すると、テキスト入力でさまざまな操作を実行できます。しかしスマートフォンから操作する場合、コマンドの選択やパラメータの入力が手間になりがちです。
特定のボイスチャンネルに入って喋るだけでコマンドが実行できたら、もっと手軽に使えるのではないか。 そう考え、Amazon Transcribe による音声認識と Amazon Bedrock 上の Claude による自然言語の構造化を組み合わせて、音声入力からカスタムコマンドを実行する仕組みを構築してみました。
Amazon Transcribe とは
Amazon Transcribe は AWS が提供する自動音声認識 (ASR) サービスです。音声ファイルを入力すると、機械学習モデルによってテキストに変換されます。日本語 (ja-JP) を含む 100 以上の言語に対応しています。
検証環境
- Node.js 22 / TypeScript
- discord.js v14 / @discordjs/voice
- AWS Lambda (Node.js 22 ランタイム)
- Amazon Transcribe
- Amazon Bedrock (Claude Sonnet 4.5)
- AWS CDK (TypeScript)
対象読者
- Discord Bot のスラッシュコマンドを実装したことがある方
- Amazon Transcribe や Amazon Bedrock の実践的なユースケースに興味がある方
- 音声入力による操作の UX 改善を検討している方
参考
- Amazon Transcribe — AWS
- Amazon Bedrock — AWS
- Amazon Bedrock で日本リージョンのクロスリージョン推論がサポートされました — AWS ブログ
- @discordjs/voice — GitHub
アーキテクチャ
全体の処理フローは次のとおりです。
大きく分けて 3 つのフェーズがあります。
- Bot が音声をキャプチャし、WAV ファイルとして S3 に保存
- Lambda 上で Transcribe と Amazon Bedrock のパイプラインを実行し、構造化データを取得
- 結果を Discord に投稿し、ユーザーの確認を経てコマンドを実行
以降、各フェーズを順に解説します。
音声キャプチャ: @discordjs/voice
Discord Bot でボイスチャンネルの音声を取得するには、@discordjs/voice を使います。
Bot はユーザーの入退室を監視し、人間のユーザーがボイスチャンネルに入ると自動的に参加します。接続が確立すると receiver.speaking イベントで発話の開始を検知し、ユーザーごとの音声ストリームを購読します。
const audioStream = receiver.subscribe(userId, {
end: {
behavior: EndBehaviorType.AfterSilence,
duration: 1500, // 1.5 秒の無音で録音終了
},
});
Discord の音声は Opus コーデックでエンコードされています。@discordjs/opus で PCM にデコードし、発話終了後に WAV ヘッダーを付与して S3 にアップロードします。
Amazon Transcribe: 音声をテキストに変換
S3 に保存した WAV ファイルを Amazon Transcribe で文字起こしします。処理の流れは、ジョブ作成・ポーリング・結果取得の 3 ステップです。
// 1. ジョブ作成
await transcribeClient.send(
new StartTranscriptionJobCommand({
TranscriptionJobName: jobName,
LanguageCode: 'ja-JP',
MediaFormat: 'wav',
Media: { MediaFileUri: `s3://${bucket}/${s3Key}` },
OutputBucketName: bucket,
OutputKey: `transcribe-output/${jobName}.json`,
}),
);
// 2. ポーリング (1 秒間隔、最大 60 回)
for (let i = 0; i < 60; i++) {
await sleep(1000);
const { TranscriptionJob: job } = await transcribeClient.send(
new GetTranscriptionJobCommand({ TranscriptionJobName: jobName }),
);
if (job?.TranscriptionJobStatus === 'COMPLETED') break;
if (job?.TranscriptionJobStatus === 'FAILED') throw new Error('Transcription failed');
}
// 3. S3 から結果 JSON を取得してパース
const result = await s3Client.send(
new GetObjectCommand({ Bucket: bucket, Key: outputKey }),
);
const body = await result.Body?.transformToString();
const parsed = JSON.parse(body!) as {
results: { transcripts: { transcript: string }[] };
};
const transcript = parsed.results.transcripts[0].transcript;
LanguageCode: 'ja-JP' を指定することで、日本語の音声認識モデルが使われます。短い発話 (数秒程度) であれば通常 10〜20 秒ほどで文字起こしが完了します。
Amazon Bedrock (Claude): テキストを構造化データに変換
Transcribe で得られるのは自然言語のテキストです。「ミルク 160 飲みました」というテキストをそのままコマンドとして扱うことはできません。これを { eventType: "milk", details: { amount: 160 } } のような構造化データに変換する必要があります。
ここで Amazon Bedrock 上の Claude を使います。今回は 日本リージョンのクロスリージョン推論 に対応したモデル jp.anthropic.claude-sonnet-4-5-20250929-v1:0 を使用しました。
const response = await bedrockClient.send(
new InvokeModelCommand({
modelId: 'jp.anthropic.claude-sonnet-4-5-20250929-v1:0',
contentType: 'application/json',
accept: 'application/json',
body: JSON.stringify({
anthropic_version: 'bedrock-2023-05-31',
max_tokens: 1024,
system: systemPrompt,
messages: [{ role: 'user', content: transcript }],
}),
}),
);
システムプロンプトには、対応するコマンドの種別とパラメータの型を定義しておきます。
システムプロンプトの例
あなたはコマンドの音声入力アシスタントです。
ユーザーの発話テキストから、以下のコマンド種別に対応する構造化データを抽出してください。
## 対応コマンド
- milk: ミルク — { amount: number (ml) }
- meal: 離乳食 — { menu: string, memo?: string }
- sleep: 寝る — {}
- wake: 起きる — {}
## ルール
- 1 つの発話から複数のコマンドを抽出してよい
- 時刻が明示されている場合は time フィールドに "HH:MM" 形式で含める
- 時刻が不明な場合は time を null にする
- 必ず JSON 配列のみを返すこと (説明文は不要)
たとえば「10 時半にミルク 160 飲んで、そのあと離乳食も食べました」という入力に対しては、次のような JSON が返ります。
[
{ "eventType": "milk", "time": "10:30", "details": { "amount": 160 } },
{ "eventType": "meal", "time": null, "details": { "menu": "離乳食" } }
]
ひとつの発話から複数のコマンドを抽出できるのが LLM を使う大きな利点です。ルールベースのパーサーでは複合的な発話への対応が難しくなりがちですが、Claude であれば自然言語のニュアンスを汲み取って適切に分割してくれます。
なお、Claude のレスポンスには説明文が混入することがあるため、正規表現 /\[[\s\S]*\]/ で JSON 配列部分のみを抽出するようにしています。
ユーザー確認フロー
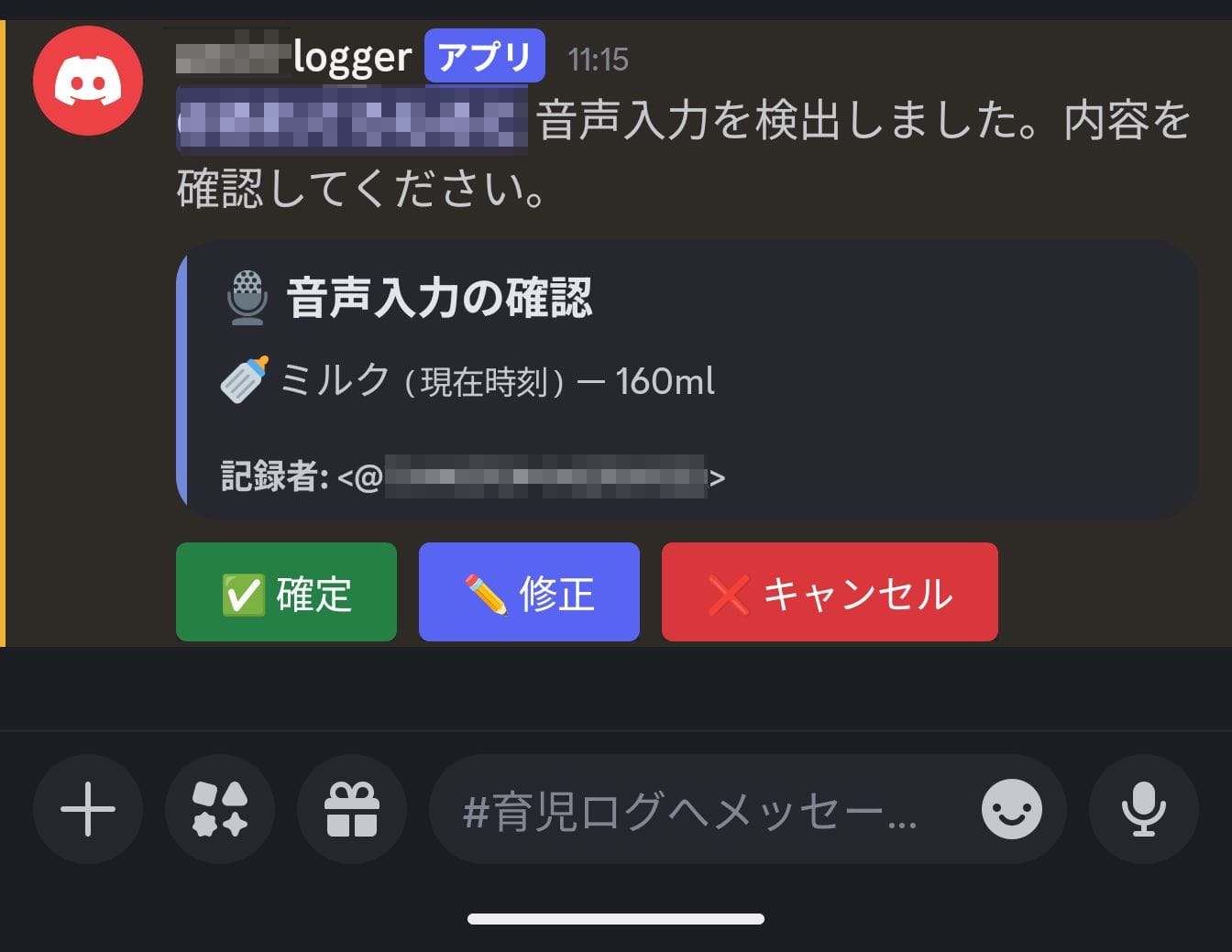
音声認識も LLM も 100% 正確ではありません。構造化の結果をそのまま確定するのではなく、ユーザーに確認を求める UI を挟むことが重要です。
Lambda が構造化を終えると、Discord のボタンコンポーネントを使った確認メッセージを投稿します。ユーザーは内容を確認したうえで、3 つのアクションから選択します。
- 確定: 構造化された内容をそのままコマンドとして実行する
- 修正: モーダルで JSON を直接編集してから実行する
- キャンセル: 処理を中止する
特に数値 (ミルクの量など) の誤認識はそのまま記録されると厄介です。確認ステップを設けることで、実行前に誤りを修正できます。
実際に使ってみて
処理時間のばらつき
発話してから確認メッセージが投稿されるまでの時間には、短い場合で約 10 秒、長い場合で 1 分程度とばらつきがあります。Transcribe のジョブ完了を待つポーリングが主な原因です。
現状の実装では処理中であることを示す UI がないため、ユーザーからは動いているのかどうか判別しにくいという課題があります。発話直後に「処理中...」のようなメッセージを投稿し、完了時に差し替えるといった改善が考えられます。また、Transcribe のジョブ完了通知を EventBridge や SNS で受け取る構成にすれば、ポーリングによる Lambda 実行時間も削減できます。
音声認識の精度
Transcribe の日本語認識精度はかなり良好でした。「軟飯(なんめし)」のような専門的な語彙も正しく認識されます。
ただし、発話内容が自動的に括弧付きの表現へ正規化されるケースが見られました。たとえば「煮物、レンコン、人参」と発話すると、Transcribe の出力が「煮物 (レンコン、人参)」のように整形されることがあります。この場合、Claude の構造化結果にも括弧付きの文字列がそのまま含まれます。
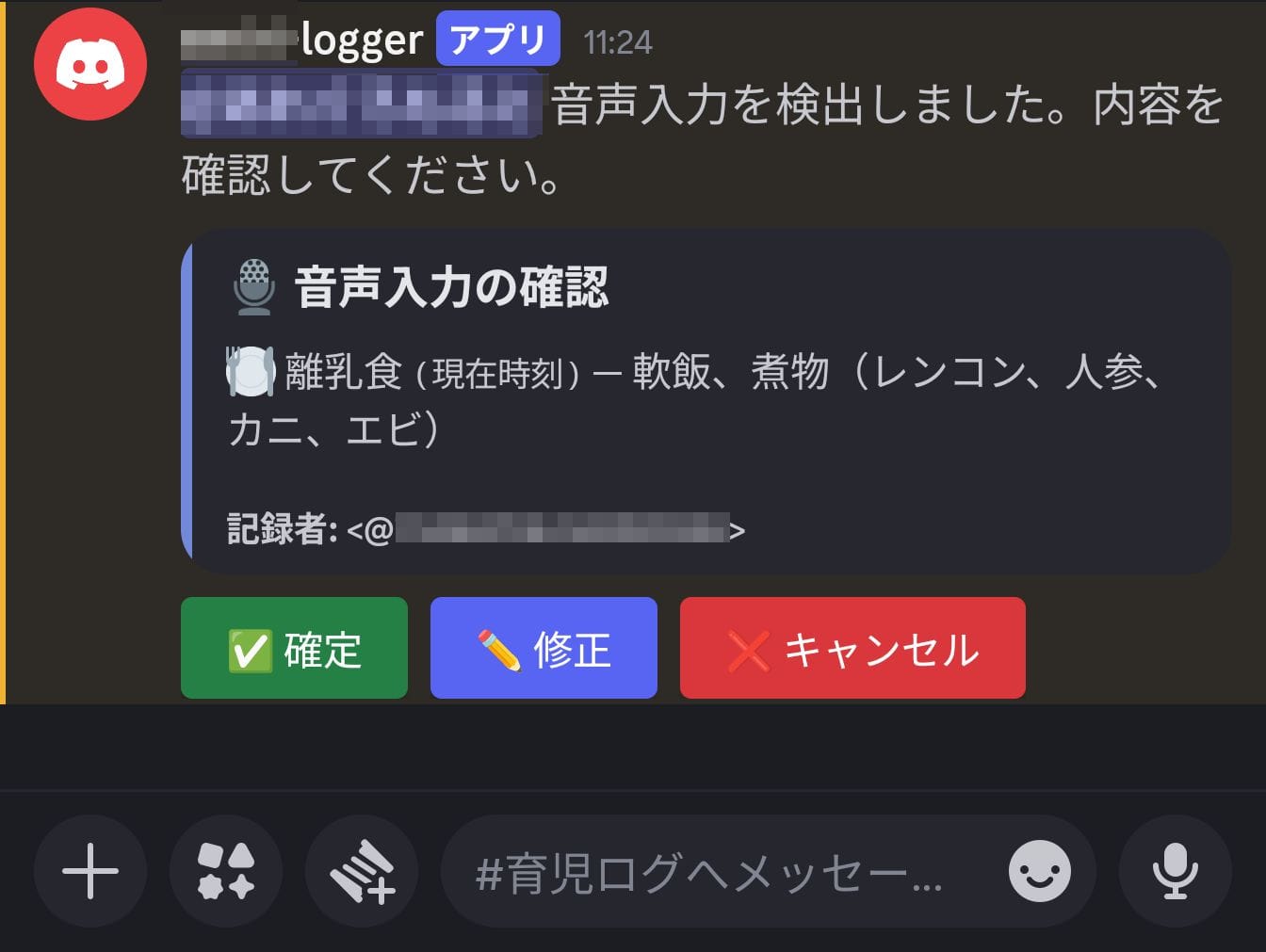
とはいえ、前述の確認フローがあるおかげで、多少の誤りがあっても致命的にはなりません。修正ボタンから該当箇所だけ直せば済むため、一からコマンドを手入力するよりは手軽です。
まとめ
Amazon Transcribe と Amazon Bedrock を組み合わせることで、Discord のボイスチャンネルでの発話をカスタムコマンドの実行に変換する仕組みを構築しました。音声認識と構造化の間に LLM を置くことで、抽出するコマンドの種別やパラメータはシステムプロンプトの変更だけで拡張できます。
今回は育児ログの記録を題材にしましたが、定型的なデータ入力が必要な場面であれば同様のアプローチが適用できるでしょう。









