
DockerでローカルにIceberg + Spark環境を構築し、DBeaverで接続してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のueharaです。
今回は、DockerでローカルにIceberg + Spark環境を構築し、DBeaverで接続してみたいと思います。
はじめに
re:Invent 2024でフルマネージドなApache Iceberg tablesであるといえる S3 Tables が発表されるなど、大量のデータを効率よく扱うためのオープンソースのテーブルフォーマットであるIcebergがより勢いづいている印象を受けます。
AWS上ではIcebergを扱うためにS3 + Athenaという構成が取れたりするのですが、今回は手軽に試すためにローカル環境で構築してみたいと思います。
(簡単に)Icebergについて
Icebergはあくまで「Table Spec」の1つになります。

(引用元)
すなわち、「データへの効率的なアクセスをするためにこういう風にデータファイルを管理します」という枠組みであり、Icebergそのものがコンピューティング能力やストレージ機能を有しているといったものではありません。
実際にIcebergテーブルを扱うのはSparkやTrinoといったクエリエンジンになります。
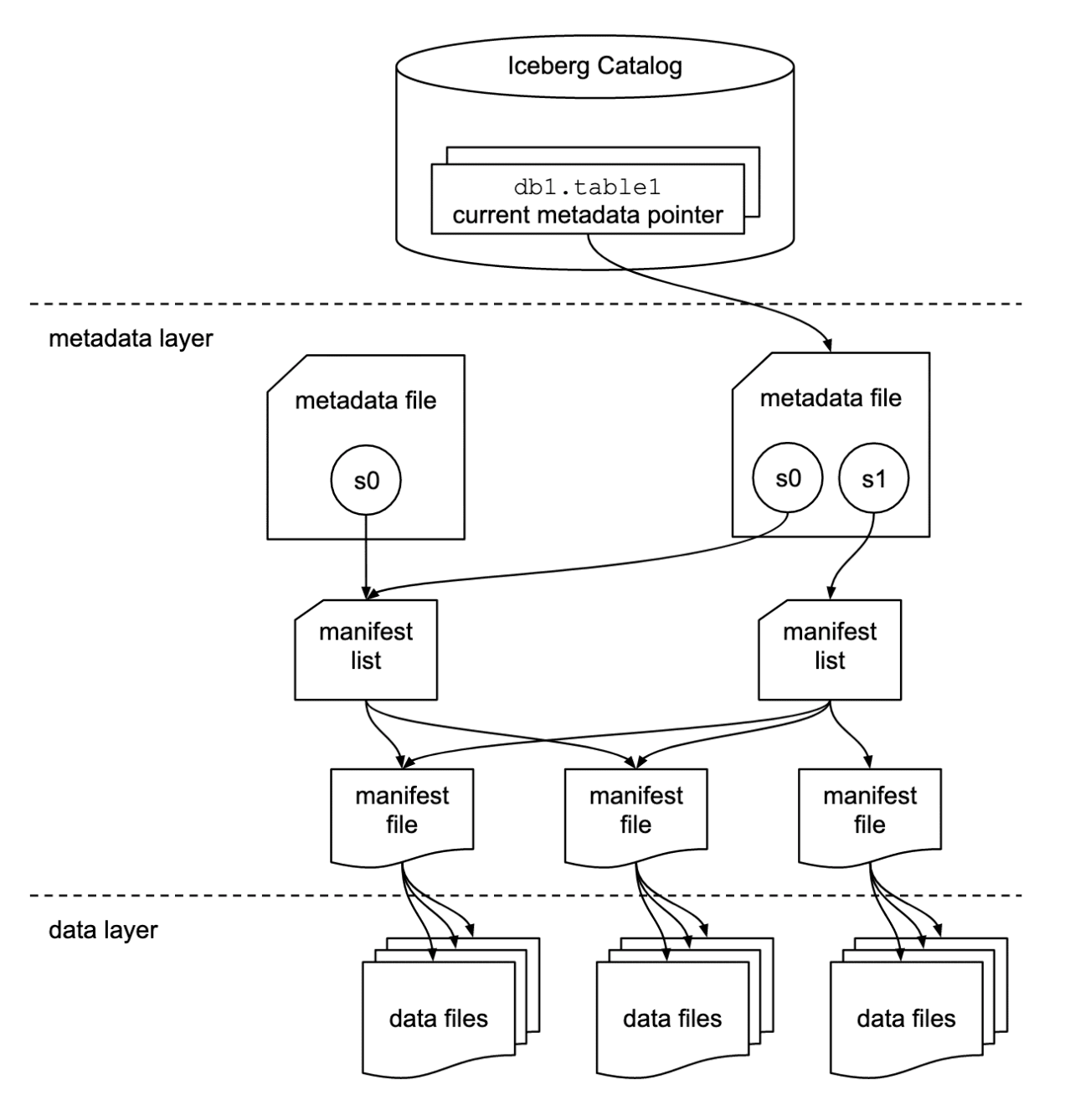
補足ですが、Icebergのアーキテクチャは以下のようになっています。
環境構築
docker-compose.ymlの作成
公開されているIceberg + SparkのDockerイメージはいくつかありますが、今回は公式でもサンプルとして利用されているtabulario/spark-icebergのものを利用します。
公式サンプルではストレージとしてMinIO(S3互換のオブジェクトストレージ)を利用しているようで、これもそのまま使わせてもらいます。
作成したdocker-compose.ymlは以下の通りです。
version: "3"
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: apache/iceberg-rest-fixture
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
volumes:
- ./data:/data
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"
networks:
iceberg_net:
マウント用ディレクトリの作成
docker-compose.ymlの作成が完了したら、同じ階層にdata, notebooks, warehouse というディレクトリを作成し、アクセス権限の設定をしておきます。
$ mkdir data notebooks warehouse
$ chmod 755 data notebooks warehouse
この段階で、ディレクトリ構成は以下のようになっていると思います。
.
├── data
├── docker-compose.yml
├── notebooks
└── warehouse
Dockerコンテナの起動とデータベースの作成
Dockerコンテナの起動は以下のコマンドで実行可能です。
$ docker-compose up
各サービスの立ち上げが完了したら、以下コマンドでSparkのセッションを開始します。
$ docker exec -it spark-iceberg spark-sql
セッションが開始されたら default というデータベースを作成しておきます。
spark-sql ()> CREATE DATABASE IF NOT EXISTS default;
これで一旦準備は完了です。
DBeaverでアクセス
接続設定
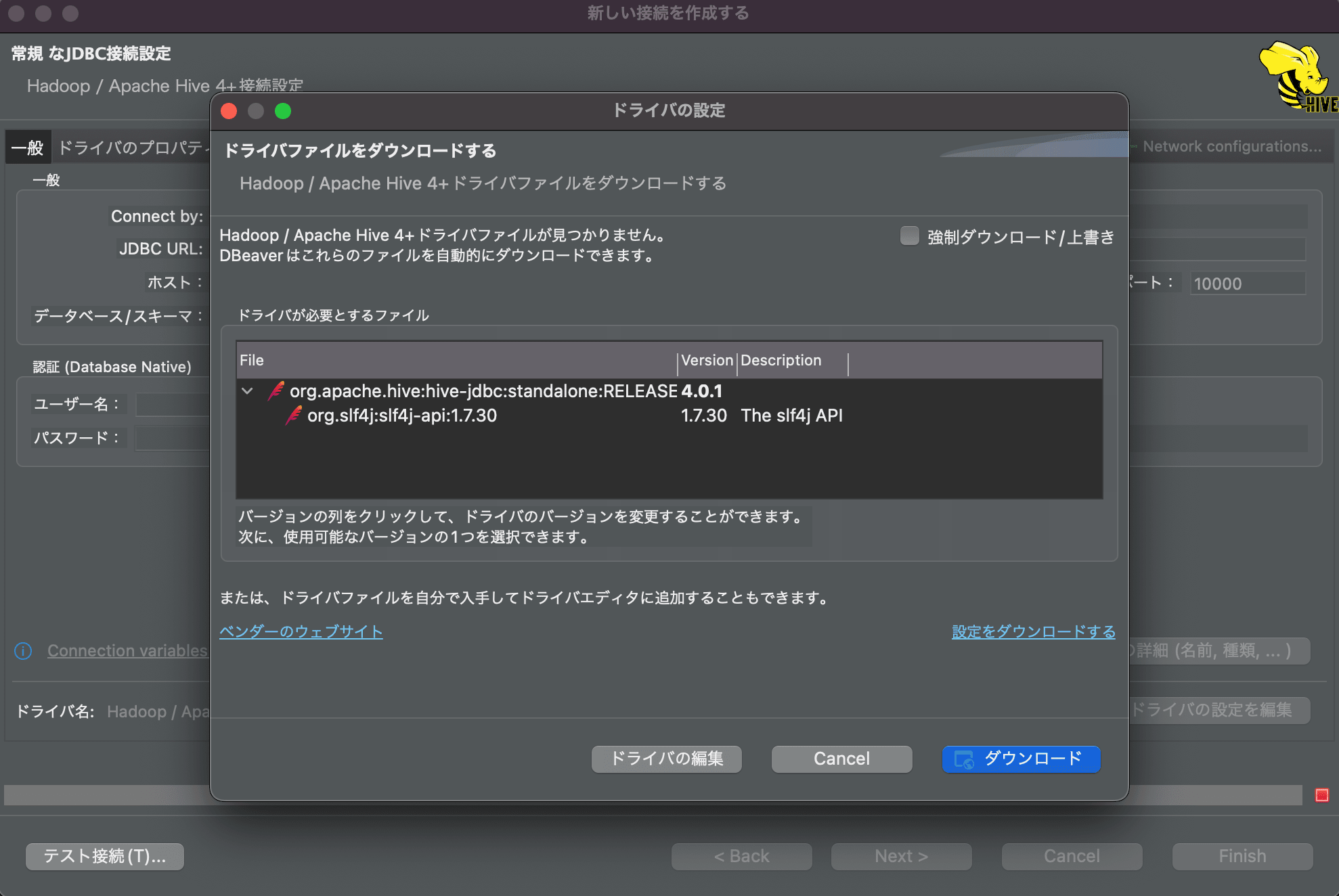
DBeaverを開き、「新しい接続の作成」を行います。接続タイプは「Apache Hive 4+」を選択します。

ドライバのダウンロードがされていなければ以下の通り「ドライバの設定」の画面が立ちあがるので、ダウンロードしておきます。
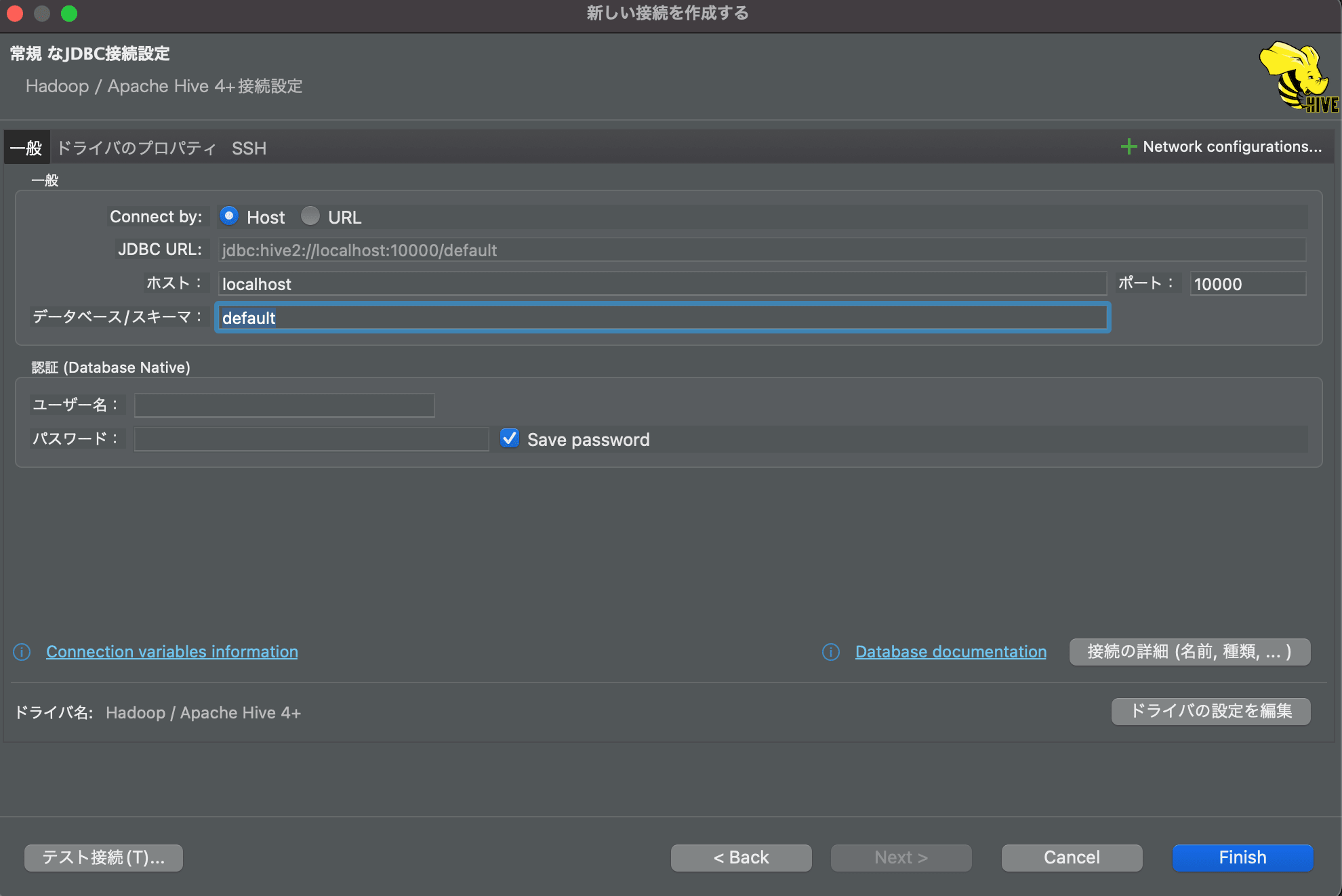
データベースは先に作成した「default」を指定します。ユーザ名とパスワードは空欄で問題ありません。
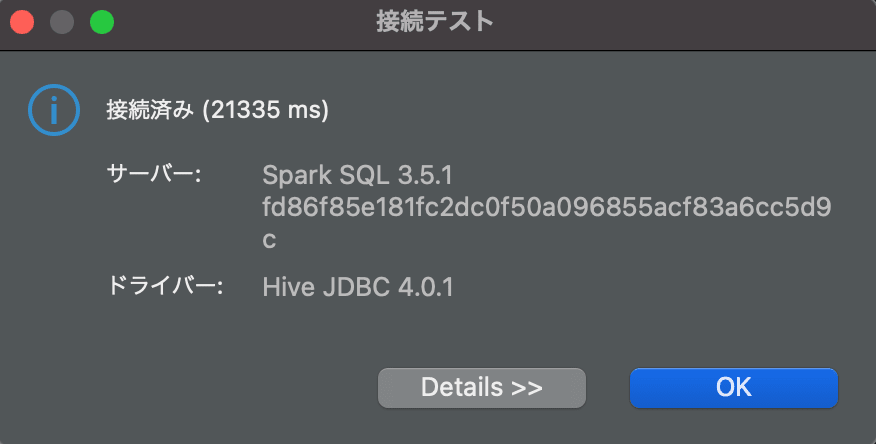
左下の「テスト接続」ボタンを押して接続が成功すれば接続設定は完了です。
クエリの実行
DBeaverで接続ができたら、適当にテーブルを作成しデータを挿入してみます。
-- テーブルの作成
CREATE TABLE default.test_table
(
location_id STRING,
user_id INT,
name STRING
)
USING iceberg
PARTITIONED BY (location_id);
-- データの挿入
INSERT INTO default.test_table
VALUES ('aaa-111', 1, 'Alice'), ('bbb-222', 2, 'Bob');
パーティションを確認したいので、テーブル作成時にlocation_idというカラムをパーティションに指定しています。
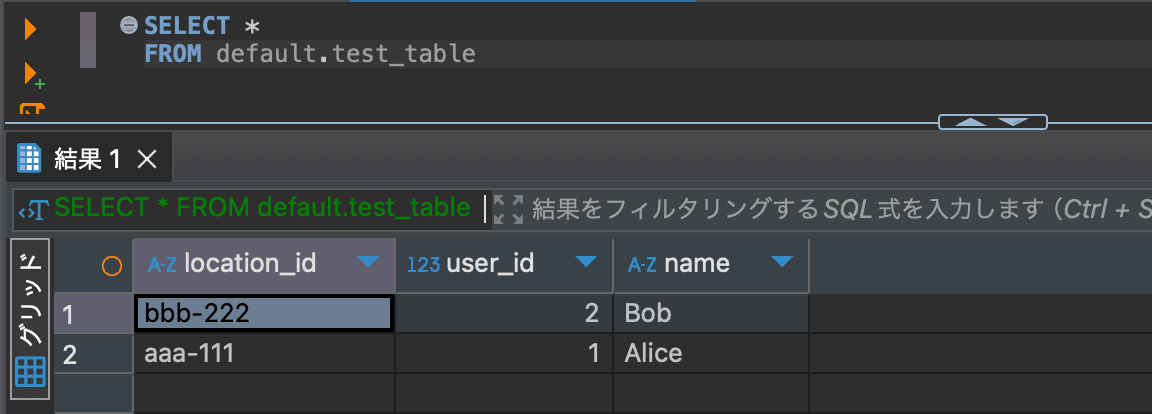
データの挿入が完了したら、SELECTクエリでデータが取得できるか確認します。
SELECT *
FROM default.test_table
取得できました!
ファイルの確認
ここまで完了したら、MinIOにマウントしている data フォルダを確認します。
$ tree data
data
└── warehouse
└── default
└── test_table
├── data
│ ├── location_id=aaa-111
│ │ └── 00000-9-e6eca642-bf54-4c83-ba93-a5737dcfe3fd-0-00001.parquet
│ │ └── xl.meta
│ └── location_id=bbb-222
│ └── 00000-9-e6eca642-bf54-4c83-ba93-a5737dcfe3fd-0-00002.parquet
│ └── xl.meta
└── metadata
├── 00000-d68c1a54-03f8-4caa-a26a-ed2e44c16a79.metadata.json
│ └── xl.meta
├── 00001-f38636ef-3f70-47ee-af49-cbef2c84cac4.metadata.json
│ └── xl.meta
├── 07de197b-736c-46b9-8e32-748d558cafb8-m0.avro
│ └── xl.meta
└── snap-6608030360858061675-1-07de197b-736c-46b9-8e32-748d558cafb8.avro
└── xl.meta
パーティションに設定した location_id で区切られているデータファイル(.parquet)や、各種メタデータファイルが確認できると思います。(※今回指定したパーティションでディレクトリが別れていますが、Icebergにおけるパーティションという概念はHive形式のようにディレクトリそのものに物理的に依存しているわけではないことにご留意下さい)
MinIOの構造により .parquet ファイルをローカルから直接参照することはできないので、実際にMinIOにアクセスしてデータを取得します。
http://localhost:9001/ にアクセスすると、MinIOのログイン画面が開くので、ユーザ名に admin 、パスワードに password を入力します。
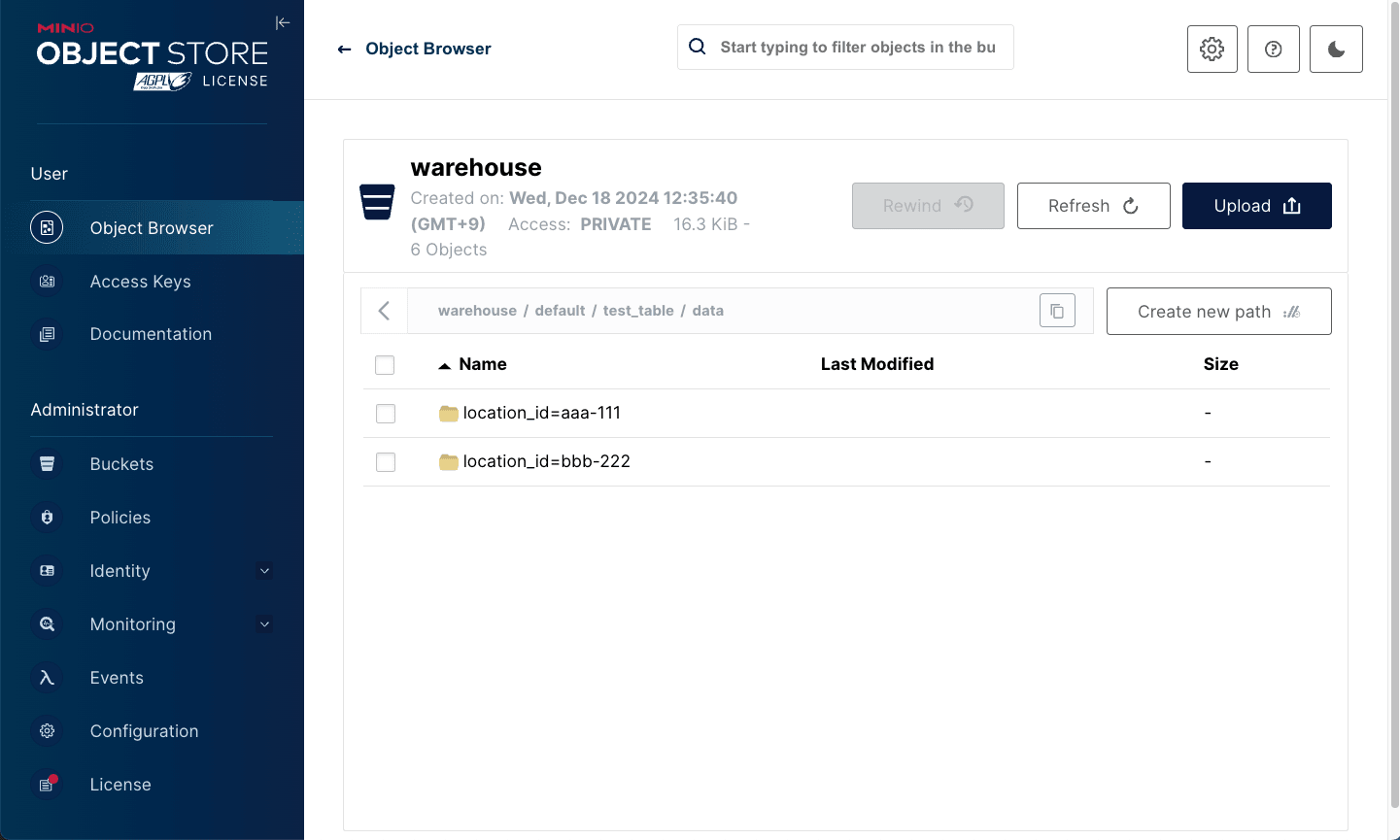
warehouse -> default -> test_table -> data と進むと、パーティションで区切られたフォルダがあるので、どちらかのフォルダにアクセスし .parquet ファイルをダウンロードします。
ダウンロードしたファイルを適当なParquetビューワーで確認すると、以下の通りデータが確認できます。

最後に
今回は、DockerでローカルにIceberg + Spark環境を構築し、DBeaverで接続してみました。
参考になりましたら幸いです。











