
DuckDB 1.4のIceberg書き込み機能をAWS Lambdaで試してみた
はじめに
データ事業本部のkasamaです。今回はDuckDB 1.4.0から新たにサポートされたIceberg write機能をAWS Lambdaで試してみました。
DuckDB 1.4.0でIcebergテーブルへの書き込み機能が追加され、1.4.2ではmerge-on-read方式のDELETEとUPDATE機能も実装されました。なお、2025年11月30日時点では、copy-on-write方式はまだサポートされていません。また、パーティションされたIcebergテーブルへのDELETE/UPDATE操作もサポートされていません。
従来、Icebergテーブルへのデータ書き込みにはPyIcebergなどのライブラリが必要でしたが、DuckDBがサポートしたことによりシンプルな構成で実装できます。
CoW(Copy-on-Write)とMoR(Merge-on-Read)の違いは以下の記事が参考になります。Athenaの場合はデフォルトでMoRです。今回もAthenaでIceberg tableをcreateするので、MoR形式を使用します。
概要
今回実装するアーキテクチャは以下の通りです。
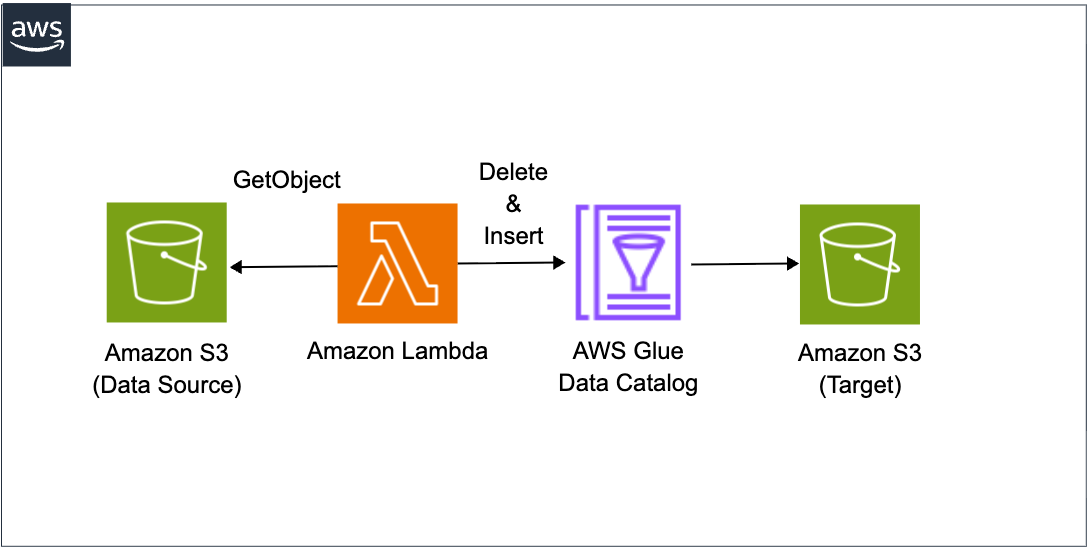
Lambda Layerを使用してDuckDBをデプロイし、DuckDBのIceberg拡張機能でGlue Catalogに接続します。Delete Insertパターンで冪等性を確保しつつ、S3上のCSVデータをIcebergテーブルに書き込みます。
実装
実装したソースコードは以下になります。
62_duckdb_iceberg_lambda_py
├── README.md
├── cdk
│ ├── bin
│ │ └── app.ts
│ ├── cdk.json
│ ├── layers
│ │ └── requirements.txt
│ ├── lib
│ │ ├── main-stack.ts
│ │ └── parameter.ts
│ ├── package-lock.json
│ ├── package.json
│ └── tsconfig.json
├── resources
│ ├── data
│ │ ├── sample_data_2025-11-18.csv
│ │ ├── sample_data_2025-11-19.csv
│ │ └── sample_data_2025-11-20.csv
│ └── lambda
│ └── iceberg_copy.py
└── sql
└── create_iceberg_tables.sql
#!/usr/bin/env node
import * as cdk from "aws-cdk-lib";
import { MainStack } from "../lib/main-stack";
import { devParameter } from "../lib/parameter";
const app = new cdk.App();
new MainStack(app, `${devParameter.projectName}-stack`, {
env: devParameter.env,
description: "Iceberg data copy using Lambda and DuckDB",
parameter: devParameter,
});
CDKのエントリーポイントです。parameterファイルから設定を読み込み、MainStackをインスタンス化しています。
import type { Environment } from "aws-cdk-lib";
export interface AppParameter {
env?: Environment;
envName: string;
projectName: string;
}
export const devParameter: AppParameter = {
envName: "dev",
projectName: "my-iceberg-duckdb-lambda",
env: {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: process.env.CDK_DEFAULT_REGION,
},
};
プロジェクトの設定を定義しています。projectNameはS3バケット名やLambda関数名のプレフィックスとして使用されるため、デプロイ前に必ず変更してください。
import * as path from "node:path";
import { PythonLayerVersion } from "@aws-cdk/aws-lambda-python-alpha";
import * as cdk from "aws-cdk-lib";
import * as iam from "aws-cdk-lib/aws-iam";
import * as lambda from "aws-cdk-lib/aws-lambda";
import * as s3 from "aws-cdk-lib/aws-s3";
import * as s3deploy from "aws-cdk-lib/aws-s3-deployment";
import type { Construct } from "constructs";
import type { AppParameter } from "./parameter";
interface MainStackProps extends cdk.StackProps {
parameter: AppParameter;
}
export class MainStack extends cdk.Stack {
constructor(scope: Construct, id: string, props: MainStackProps) {
super(scope, id, props);
const { parameter } = props;
// リソース名の構築
const sourceBucketName = `${parameter.projectName}-${parameter.envName}-source`;
const targetBucketName = `${parameter.projectName}-${parameter.envName}-target`;
const targetDatabase = `${parameter.projectName.replace(/-/g, "_")}_${parameter.envName}`;
// ========================================
// S3 Bucket: ソースバケット作成
// ========================================
const sourceBucket = new s3.Bucket(this, "SourceBucket", {
bucketName: sourceBucketName,
encryption: s3.BucketEncryption.S3_MANAGED,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
// サンプルCSVファイルをアップロード
new s3deploy.BucketDeployment(this, "DeploySourceData", {
sources: [
s3deploy.Source.asset(path.join(__dirname, "../../resources/data")),
],
destinationBucket: sourceBucket,
destinationKeyPrefix: "data/sales_data",
});
// ========================================
// S3 Bucket: ターゲットバケット作成
// ========================================
const targetBucket = new s3.Bucket(this, "TargetBucket", {
bucketName: targetBucketName,
encryption: s3.BucketEncryption.S3_MANAGED,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
versioned: true,
lifecycleRules: [
{
id: "DeleteOldVersions",
noncurrentVersionExpiration: cdk.Duration.days(30),
},
],
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
// ========================================
// IAM Role: Lambda関数用
// ========================================
const lambdaRole = new iam.Role(this, "LambdaRole", {
roleName: `${parameter.projectName}-${parameter.envName}-lambda-role`,
assumedBy: new iam.ServicePrincipal("lambda.amazonaws.com"),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName(
"service-role/AWSLambdaBasicExecutionRole",
),
],
});
// Glue Catalog書き込み権限(最小権限)
lambdaRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: [
"glue:GetCatalog",
"glue:GetDatabase",
"glue:GetTable",
"glue:UpdateTable",
],
resources: [
`arn:aws:glue:${this.region}:${this.account}:catalog`,
`arn:aws:glue:${this.region}:${this.account}:database/${targetDatabase}`,
`arn:aws:glue:${this.region}:${this.account}:table/${targetDatabase}/*`,
],
}),
);
// S3読み取り権限(ソースバケット)
sourceBucket.grantRead(lambdaRole);
// S3読み書き権限(ターゲットバケット)
targetBucket.grantReadWrite(lambdaRole);
// STS権限(アカウントID取得用)
lambdaRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ["sts:GetCallerIdentity"],
resources: ["*"],
}),
);
// ========================================
// Lambda Layer: DuckDB
// ========================================
const duckdbLayer = new PythonLayerVersion(this, "DuckdbLayer", {
entry: path.join(__dirname, "../layers"),
compatibleRuntimes: [lambda.Runtime.PYTHON_3_13],
compatibleArchitectures: [lambda.Architecture.ARM_64],
bundling: {
assetHashType: cdk.AssetHashType.SOURCE,
outputPathSuffix: "python",
},
});
// ========================================
// Lambda Function
// ========================================
new lambda.Function(this, "IcebergCopyFunction", {
functionName: `${parameter.projectName}-${parameter.envName}-function`,
runtime: lambda.Runtime.PYTHON_3_13,
code: lambda.Code.fromAsset(
path.join(__dirname, "../../resources/lambda"),
),
handler: "iceberg_copy.lambda_handler",
role: lambdaRole,
layers: [duckdbLayer],
architecture: lambda.Architecture.ARM_64,
timeout: cdk.Duration.minutes(5),
memorySize: 3008,
environment: {
SOURCE_BUCKET: sourceBucketName,
SOURCE_PREFIX: "data/sales_data",
TARGET_DATABASE: targetDatabase,
TARGET_TABLE: "sales_data_iceberg",
},
});
}
}
duckdb==1.4.2
pyarrow==19.0.0
このスタックでは、以下のリソースを作成します。
Source BucketとTarget Bucketを作成し、サンプルCSVデータを自動でアップロードします。IAMロールは最小権限の原則に従い、必要な権限のみを付与しています。Lambda Layerには、DuckDB 1.4.2とPyArrow 19.0.0を含めています。PythonLayerVersionを使用することで、requirements.txtから自動的にパッケージをビルドしてLayerを作成できます。Lambda関数はPython 3.13ランタイム、ARM64アーキテクチャで構成し、DuckDBの処理に十分なメモリを割り当てています。
import json
import os
import boto3
import duckdb
def lambda_handler(event, _context):
"""
Lambda handler for cross-account Iceberg data copy using DuckDB
"""
# パラメータ取得(環境変数から)
source_bucket = os.environ["SOURCE_BUCKET"]
source_prefix = os.environ["SOURCE_PREFIX"]
target_database = os.environ["TARGET_DATABASE"]
target_table = os.environ["TARGET_TABLE"]
# パラメータ取得(実行時入力から)
target_date = event["TARGET_DATE"]
print("Lambda started")
print(f"Target: {target_database}.{target_table} (date={target_date})")
try:
# DuckDB初期化
con = duckdb.connect(":memory:")
con.execute("SET home_directory='/tmp';")
con.execute("SET extension_directory='/tmp/duckdb_extensions';")
print("DuckDB初期化完了")
# AWS認証情報を設定
con.execute("""
CREATE SECRET (
TYPE S3,
PROVIDER CREDENTIAL_CHAIN
);
""")
print("S3 SECRET作成完了")
# S3 データ読み取り
source_path = (
f"s3://{source_bucket}/{source_prefix}/sample_data_{target_date}.csv"
)
print(f"Reading: {source_path}")
# CSVを読み取り、updated_atカラムを追加
query = f"""
SELECT
*,
CURRENT_TIMESTAMP AS updated_at
FROM read_csv_auto('{source_path}')
"""
df = con.execute(query).fetch_arrow_table()
row_count = len(df)
print(f"Rows read: {row_count:,}")
if row_count == 0:
print("No data found")
con.close()
return {
"statusCode": 200,
"body": json.dumps({"message": "No data found", "rows_inserted": 0}),
}
# Glue カタログ接続(アカウントIDを使用)
account_id = boto3.client("sts").get_caller_identity()["Account"]
con.execute(
f"""
ATTACH '{account_id}' AS glue_catalog (
TYPE iceberg,
ENDPOINT_TYPE 'glue'
);
"""
)
print(f"Glue カタログ接続完了: Account={account_id}")
# Iceberg テーブルに対する処理
table_identifier = f"glue_catalog.{target_database}.{target_table}"
# 既存のデータを削除(重複防止)
delete_query = f"DELETE FROM {table_identifier} WHERE date = '{target_date}'"
print(f"Deleting existing data for date={target_date}...")
con.execute(delete_query)
print("DELETE完了")
# データを insert
print(f"Inserting into {table_identifier}...")
con.execute(f"INSERT INTO {table_identifier} SELECT * FROM df")
print("INSERT完了")
con.close()
print(f"Lambda completed: {row_count:,} rows inserted")
return {
"statusCode": 200,
"body": json.dumps(
{
"message": "Data copy completed successfully",
"rows_inserted": row_count,
"target_table": f"{target_database}.{target_table}",
"target_date": target_date,
}
),
}
except Exception as e:
error_message = f"Lambda failed: {str(e)}"
print(error_message)
raise
Lambda関数の実装では、DuckDBのIceberg拡張機能を活用しています。S3からのCSV読み取りには、read_csv_auto関数を使用します。この関数はスキーマを自動推論するため、カラム定義を明示する必要がありません。CURRENT_TIMESTAMPを使用してupdated_atカラムを追加し、実際にDeleteされたか確認できるようにしています。Glue Catalogへの接続は、ATTACHステートメントでTYPE icebergとENDPOINT_TYPE glueを指定します。データの書き込みでは、Delete Insertパターンを採用しています。まず、該当日付の既存データをDeleteで削除し、その後Insertで新しいデータを追加します。この方法により、Lambda関数を複数回実行してもデータが重複しない冪等性が保証されます。
Glue CatlogのIcebergへのAttach方式は公式ドキュメントを参考にしました。
INSTALL iceberg;などの拡張機能installの明示的な指定がないのは、DuckDBの拡張機能自動で読み込んでいるためです。以下ドキュメントのAutoloading Extensionsにも記載がある通り、クエリで使用されるとすぐにコア拡張機能をインストールおよびロードする自動ロードメカニズムが搭載されています。
デプロイ
package.jsonがあるディレクトリで依存関係をインストールします。
cd cdk
npm install
次にcdk.jsonがあるディレクトリで、CDKで定義されたリソースのコードをAWS CloudFormationテンプレートに合成するプロセスを実行します。
npx cdk synth --profile <YOUR_AWS_PROFILE>
同じくcdk.jsonがあるディレクトリでデプロイコマンドを実行します。--allはCDKアプリケーションに含まれる全てのスタックをデプロイするためのオプションです。--require-approval neverはセキュリティ的に敏感な変更やIAMリソースの変更を含むデプロイメント時の承認を求めるダイアログ表示をスキップします。検証用途では便利ですが、本番環境では慎重に使用してください。
npx cdk deploy --all --require-approval never --profile <YOUR_AWS_PROFILE>
デプロイが完了したら、Athenaで以下のDDLを実行してGlue DatabaseとIcebergテーブルを作成します。ファイルを編集して、プレースホルダーを実際の値に置き換えてください。
CREATE DATABASE IF NOT EXISTS my_iceberg_duckdb_lambda_dev;
CREATE TABLE my_iceberg_duckdb_lambda_dev.sales_data_iceberg (
id STRING,
date DATE,
sales_amount DOUBLE,
quantity BIGINT,
region STRING,
updated_at TIMESTAMP
)
LOCATION 's3://my-iceberg-duckdb-lambda-dev-target/iceberg/sales_data_iceberg/'
TBLPROPERTIES (
'table_type' = 'ICEBERG',
'format' = 'parquet',
'write_compression' = 'snappy'
);
デプロイ後の確認
CloudFormationコンソールで、スタックが正常にデプロイされていることを確認します。
Lambda コンソールでテストタブから以下のJSONでテスト実行します。
{"TARGET_DATE": "2025-11-19"}
ログから正常に処理が終了していることを確認できました。

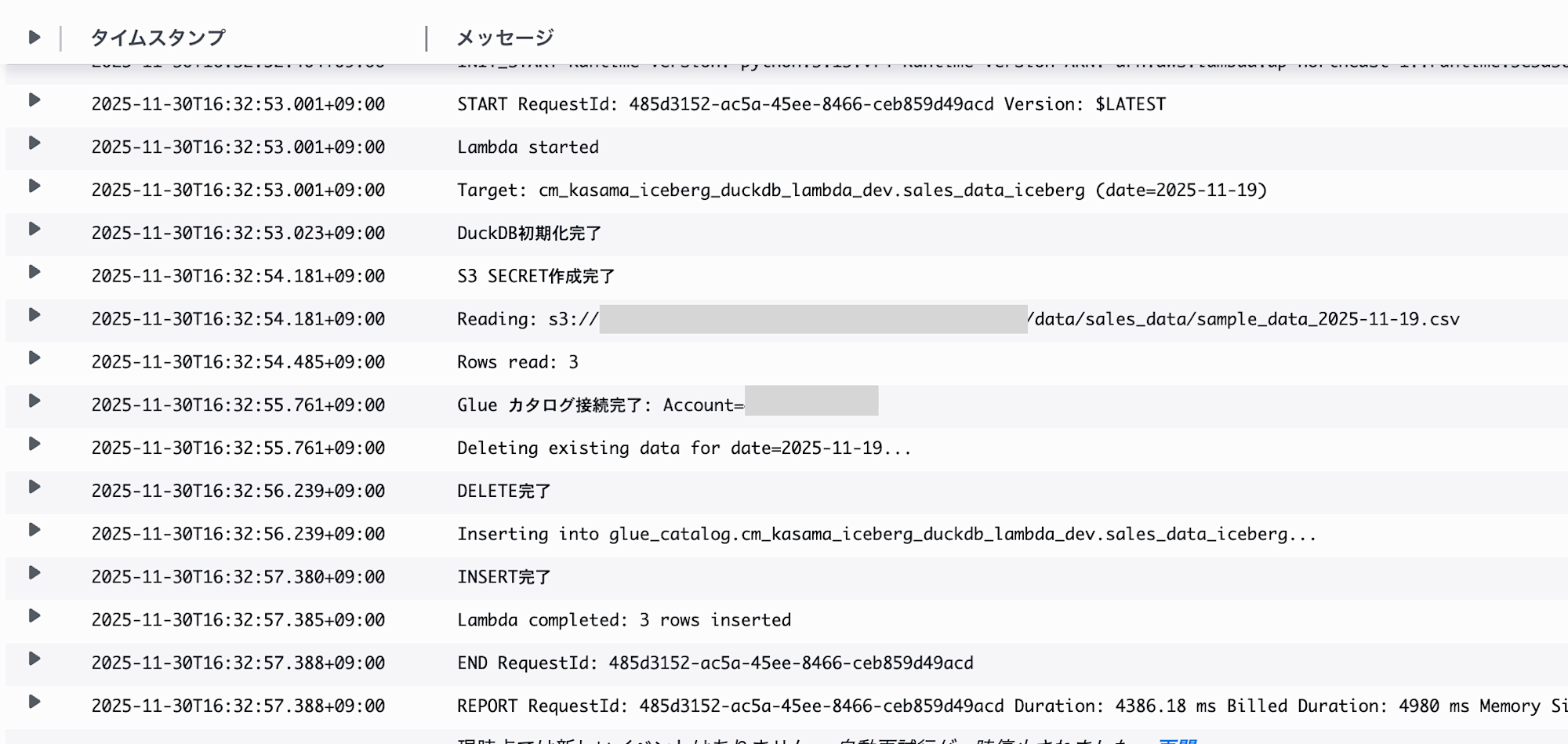
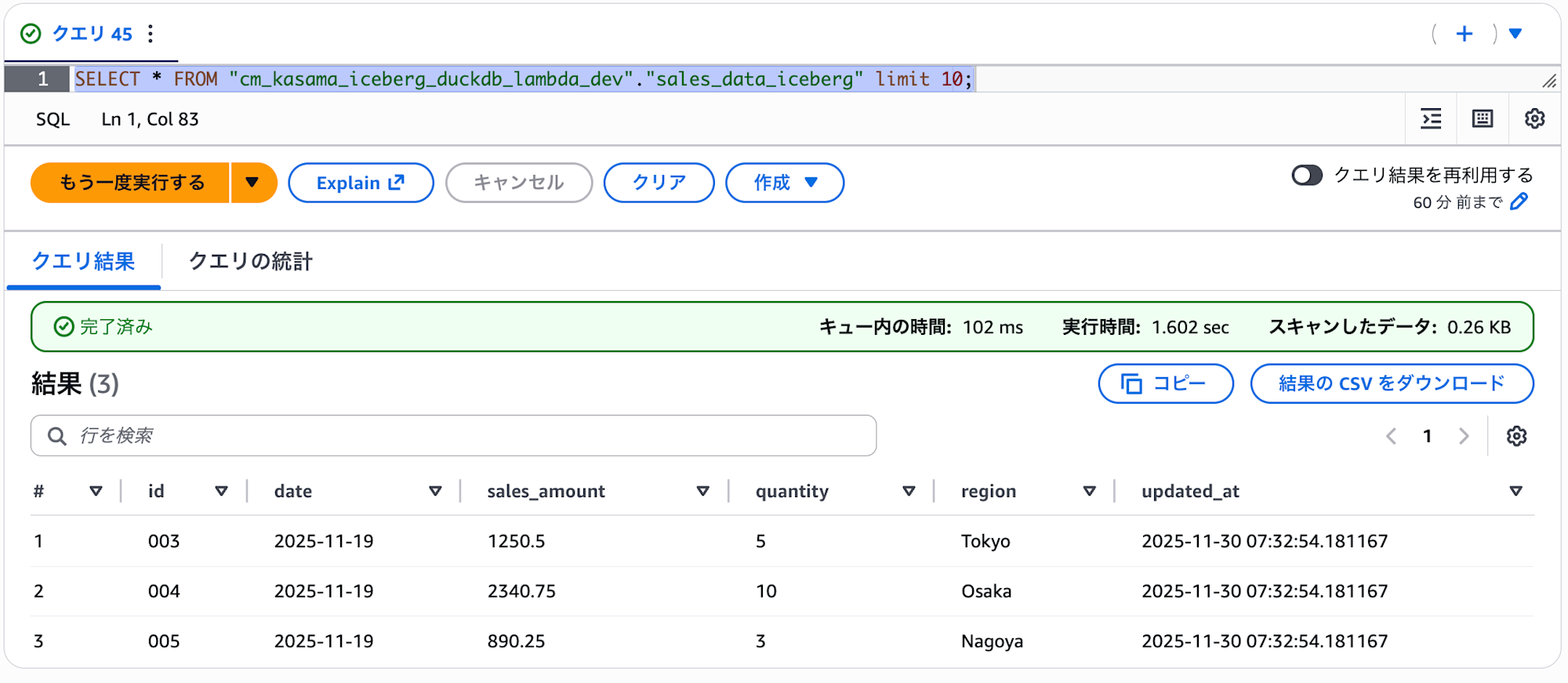
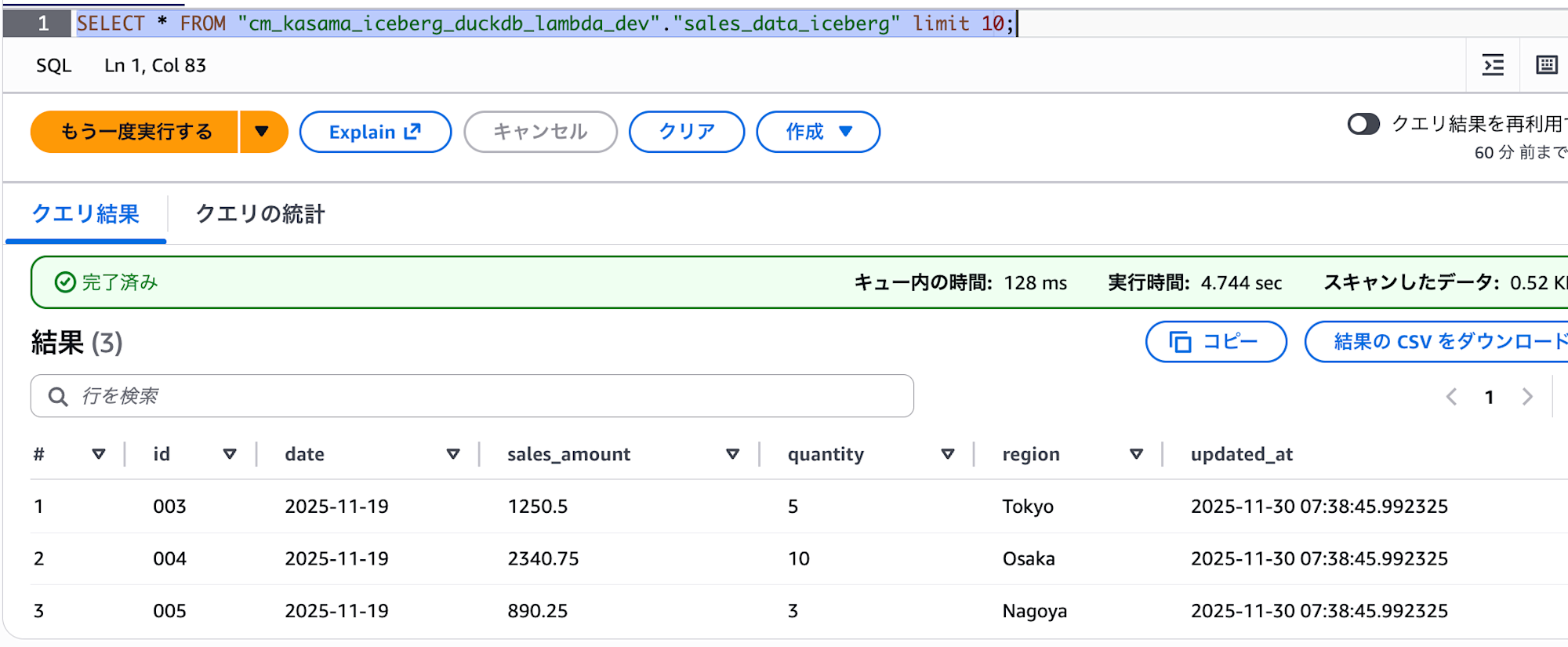
Athenaで正常にデータが書き込まれていることが確認できます。
Deleteの検証のために、先ほどと同じ引数でLambdaを再度実行しました。
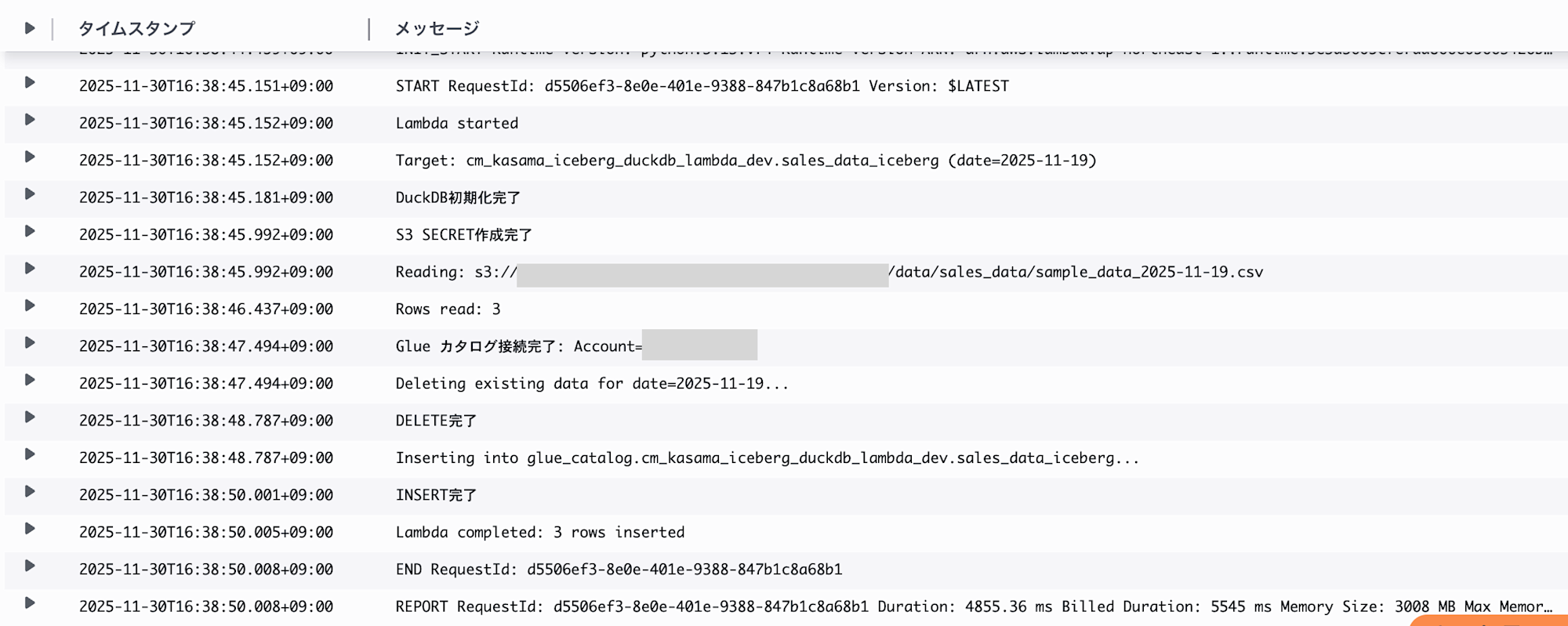
update_atカラムの日付が07:32→ 07:38に更新されているので、一度DeleteされてからInsertされていることが確認できます。
最後に
DuckDB 1.4.2のIceberg write機能により、Lambdaで効率的にIcebergデータを扱えることを確認しました。従来はPyIcebergライブラリなどが必要でしたが、DuckDBだけでSQL Likeな実装で済むようになったため、より簡単に処理ができるようになりました。今後、Icebergテーブルへの書き込みの際の選択肢の一つになりそうです。










