
DuckDBでS3のCSVとBigQueryデータの差分を比較してみた
はじめに
データ事業本部ビッグデータチームのkasamaです。
今回はDuckDBを使って、S3に格納されているCSVファイルとBigQueryのテーブルデータをExcept句で比較してみたいと思います。例えば、S3にデータレイクとしてCSVファイルを格納しており、何かしらのデータロードサービスでBigQueryにデータをロードした際のデータ比較に有効かと思います。DuckDBを使用することで、S3とBigQueryという異なるクラウドサービスのデータを、ローカルにダウンロードすることなく直接比較できます。
前提条件
必要なツール
- DuckDB
- AWS CLI
前提としてDuckDBやAWS CLIコマンドの設定が完了していることとします。DuckDBのVersionは1.4.0で実施しました。
Google Cloud CLIのインストールと認証設定
Google Cloud CLIを初めて使用するので手順を記載しておきます。
MacOSの公式の手順に沿って進めます。基本的には、公式情報を参照して進めていただければ問題ないです。
手順に記載されている通り、tarファイルをdownloadし、展開し、スクリプトを実行します。
tar -xf google-cloud-cli-darwin-arm.tar.gz
./google-cloud-sdk/install.sh
gcloud CLI を初期化します。
source ~/.zshrc
gcloud init
次にApplication Default Credentialsを設定します。アプリケーション(今回で言うとDuckDB)が Google Cloud 上のリソースにアクセスする際のクライアント認証情報を取得するための仕組みです。
gcloud auth application-default login
インストールが完了したら以下のコマンドで設定情報を確認できます。
# 現在のアカウント確認
gcloud auth list
# 現在のプロジェクト確認
gcloud config get-value project
# アクセス可能なプロジェクト一覧
gcloud projects list
# 認証ファイルの確認
cat ~/.config/gcloud/application_default_credentials.json
テストデータの準備
テスト用CSVファイルの作成
ローカルのVS CodeなどでCSVファイルを生成します。
id,name,age,email
1,Taro Yamada,25,taro@example.com
2,Hanako Sato,30,hanako@example.com
3,Jiro Tanaka,28,jiro@example.com
このCSVファイルを任意のS3バケットにアップロードします。
aws s3 cp test_data.csv s3://<your-bucket>/bq_test/test_data.csv
BigQueryのテストデータセットとテーブル作成
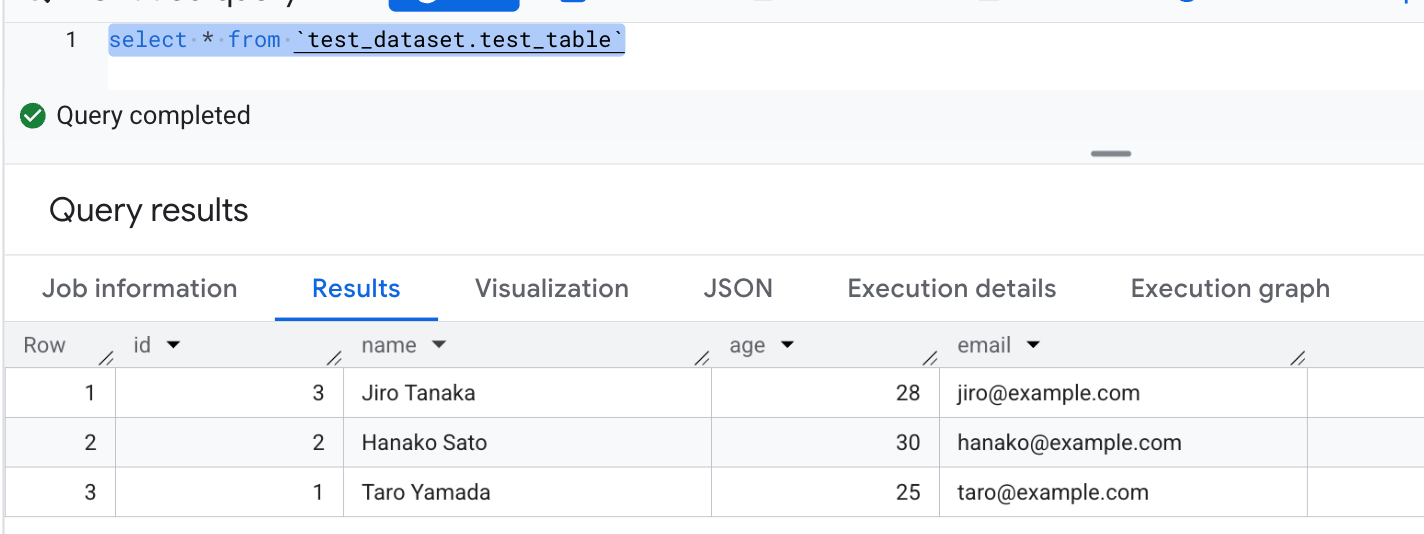
BigQueryコンソールからSQLを実行します。
-- データセット作成
CREATE SCHEMA IF NOT EXISTS `your-project-id.test_dataset`
OPTIONS(
description="テスト用データセット"
);
-- テーブル作成
CREATE OR REPLACE TABLE `your-project-id.test_dataset.test_table` (
id INT64,
name STRING,
age INT64,
email STRING
);
-- テストデータ挿入
INSERT INTO `your-project-id.test_dataset.test_table` VALUES
(1, 'Taro Yamada', 25, 'taro@example.com'),
(2, 'Hanako Sato', 30, 'hanako@example.com'),
(3, 'Jiro Tanaka', 28, 'jiro@example.com');
DuckDBでの比較手順
接続設定
まず、以下のコマンドでAccessKeyId, SecretAccessKey, SessionTokenを取得します。
aws configure export-credentials --profile <your-profile>
次にDuckDB Local UIを立ち上げます。
duckdb --ui
立ち上がったら、セルで以下のコマンドを実行します。
trueで返ってきたらS3の接続成功です。
CREATE OR REPLACE SECRET secret_c (
TYPE s3,
PROVIDER config,
KEY_ID '<取得したAccessKeyId>',
SECRET '<取得したSecretAccessKey>',
SESSION_TOKEN '<取得したSessionToken>'
REGION 'ap-northeast-1'
);
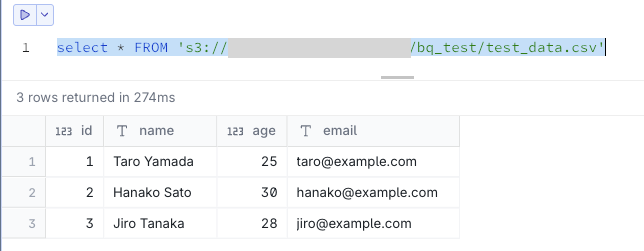
S3データを参照できる状態です。
select * FROM 's3://<your-bucket>/bq_test/test_data.csv'
次にBigQueryの接続です。以下を参考に実施します。
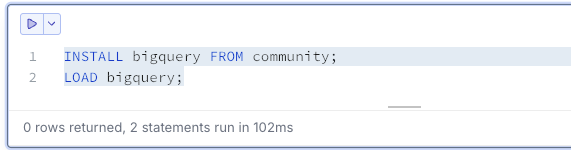
セルで以下のコマンドを実行します。
-- BigQuery拡張機能のインストール
INSTALL bigquery FROM community;
LOAD bigquery;
BigQueryプロジェクトに接続します。
ATTACH 'project=your-project-id' AS bq (TYPE bigquery, READ_ONLY);

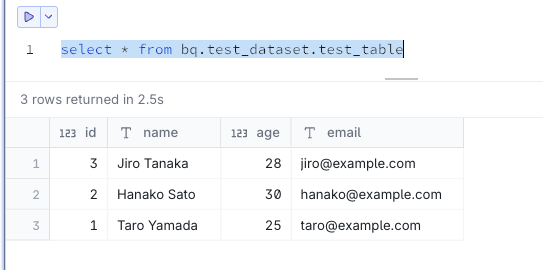
BigQueryを参照できる状態です。
select * from bq.test_dataset.test_table
EXCEPT句でデータ比較
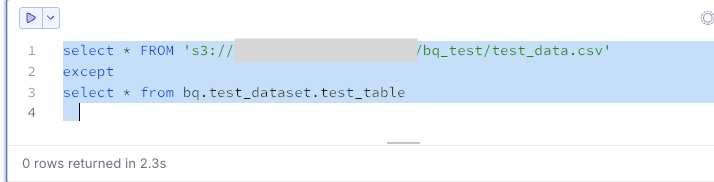
S3にあってBigQueryにないデータを抽出します。今回は0件です。
select * FROM 's3://<your-bucket>/bq_test/test_data.csv'
except
select * from bq.test_dataset.test_table
BigQueryにあってS3にないデータを抽出します。今回は0件です。
select * from bq.test_dataset.test_table
except
select * FROM 's3://<your-bucket>/bq_test/test_data.csv'
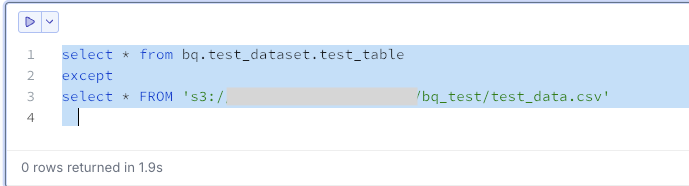
両方のクエリ結果が0件であれば、データは完全に一致しています。
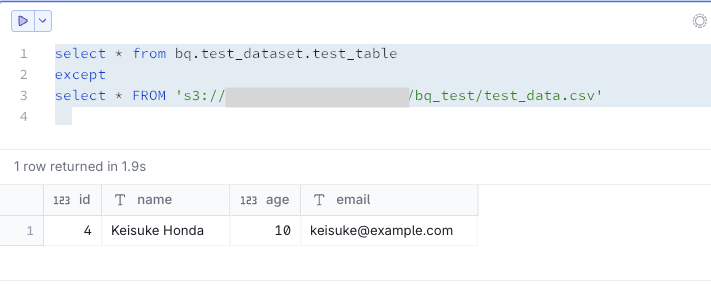
試しにBigQueryのみにデータを挿入して再度確認してみます。
INSERT INTO `your-project-id.test_dataset.test_table` VALUES
(4, 'Keisuke Honda', 10, 'keisuke@example.com');
これは想定通り、BigQueryにあってS3にないデータとして出力されました。
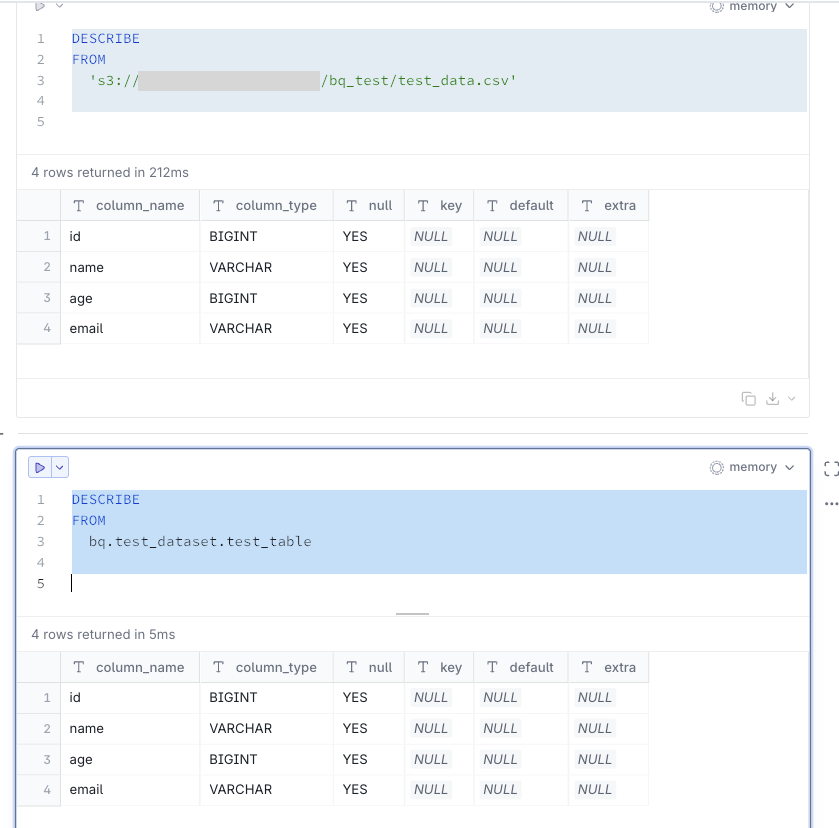
ちなみにスキーマ情報は一致していました。
最後に
DuckDBを使用することでテストが楽になる場面もあるかと思いますので、参考になれば幸いです。
追記
後から以下のブログを拝見していて、UNION ALLで一回のSQLで良さそうだったのでメモとして残しておきます。
SELECT 'S3にのみ存在' as source, *
FROM 's3://<your-bucket>/bq_test/test_data.csv'
EXCEPT
SELECT 'S3にのみ存在' as source, *
FROM bq.test_dataset.test_table
UNION ALL
SELECT 'BigQueryにのみ存在' as source, *
FROM bq.test_dataset.test_table
EXCEPT
SELECT 'BigQueryにのみ存在' as source, *
FROM 's3://<your-bucket>/bq_test/test_data.csv'









