![[アップデート] Hpc8a インスタンスの一般提供開始と AVX-512 最適化の価値を考える](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-bac3d29aa65f45576f73094798087ee5/039ad6f8a7d8f18da47986d21c447f48/amazon-ec2?w=3840&fm=webp)
[アップデート] Hpc8a インスタンスの一般提供開始と AVX-512 最適化の価値を考える
はじめに
HPC 専用インスタンス hpc8a が一般提供されました。細かいスペックや機能の詳細は AWS 公式ブログに譲るとして、個人的に気になった Zen 5 の AVX-512 実装と、HPC インスタンスのコストパフォーマンスについて調べたことを紹介します。
3行まとめ
- m8a インスタンスと同じ AMD CPU を搭載した HPC 専用インスタンスがリリース
- 同じ CPU の m8a より物理コアあたり単価が約 32% 安い
- HPC ワークロードでは CPU の性能を引き出すためにはアプリケーション側の対応が重要
hpc8a インスタンスの概要
スペック
サイズは hpc8a.96xlarge のみ提供されています。1 vCPU = 1 物理コアです。従来の HPC インスタンスと同様に SMT(同時マルチスレッディング)は無効化されています。
| 項目 | 値 |
|---|---|
| CPU | AMD EPYC 9R45(Zen 5、4.5 GHz) |
| vCPU | 192(物理コア、SMT 無効) |
| メモリ | 768 GiB |
| ネットワーク | 300 Gbps EFA |
| ストレージ | EBS のみ(インスタンスストアなし) |
| Nitro | 第 6 世代 |
提供リージョンと購入オプション
- リージョン: US East (Ohio)、Europe (Stockholm)
- 購入オプション: オンデマンド、Savings Plans
AWS ParallelCluster、AWS Parallel Computing Service からも利用可能です。スポットインスタンスには対応していないのでご注意ください。こちらも従来の HPC インスタンスと同様です。
似たスペックのインスタンスと比較
hpc8a と m8a は同じ CPU、同じ物理コア数、同じメモリ容量です。違いは HPC ワークロード向けにノード間通信速度を上げるためネットワークが強化されています。
m8i は Intel CPU で SMT 有効、メモリが 2 倍の汎用インスタンスです。メモリが約 1.5TB あることもあり、他と比べると割高です。仕方がない。
| 項目 | hpc8a.96xlarge | m8a.48xlarge | m8i.96xlarge |
|---|---|---|---|
| vCPU | 192 | 192 | 384(SMT 有効) |
| 物理コア | 192 | 192 | 192 |
| メモリ | 768 GiB | 768 GiB | 1,536 GiB |
| CPU | AMD EPYC 9R45 (4.5 GHz) | AMD EPYC 9R45 (4.5 GHz) | Intel Xeon Granite Rapids (3.9 GHz) |
| ストレージ | EBS のみ | EBS のみ | EBS のみ |
| ネットワーク | 300 Gbps EFA(2 NIC) | 75 Gbps EFA(1 NIC) | 100 Gbps |
| 時間単価 | $7.92 | $11.69 | $20.32 |
※ 価格は 2026 年 2 月 25 日時点の US East (Ohio) リージョン、Linux オンデマンド料金です。
物理コアあたり単価比較
HPC インスタンスは m8a.48xlarge と同じ CPU なのにコスパ良好ですね。
| インスタンス | 物理コア数 | 時間単価 | コアあたり単価 |
|---|---|---|---|
| hpc8a.96xlarge | 192 | $7.92 | ~$0.041 |
| m8a.48xlarge | 192 | $11.69 | ~$0.061 |
| m8i.96xlarge | 192 | $20.32 | ~$0.106 |
選定の観点
オンデマンドで安定して利用するなら hpc8a が最安です。ただし m8a と m8i はスポットインスタンスに対応しています。とくに ParallelCluster や PCS でスポット前提の運用であれば、コストが逆転する可能性があります。
リージョンも選定のポイントです。hpc8a はオハイオとストックホルムのみの提供です。東京リージョンには対応していません。東京リージョンで起動が必要な場合は同じ CPU の m8a が候補になります。
ノード間通信が必要なクラスター計算では EFA 300 Gbps を持つ hpc8a 一択です。
行列演算で使われる AVX-512 が気になる
HPC ワークロードでは計算時間の短縮がコスト削減に直結します。計算が速いに越したことはありません。
AVX-512 は 1 回の命令で 512 ビット幅のデータをまとめて処理できる SIMD 拡張です。行列演算やシミュレーションなど、大量の数値を繰り返し処理する HPC ワークロードで効果を発揮します。
Zen 4 と Zen 5 の違い
hpc8a インスタンスで使われている CPU は Zen5 アーキテクチャです。Zen 4 と Zen 5 では AVX-512 の物理的なデータバス幅が改善されています。
| 項目 | Zen 4 | Zen 5 |
|---|---|---|
| データパス幅 | 256 ビット | 512 ビット |
| 512 ビット命令の実行 | 2 サイクル(ダブルポンプ) | 1 サイクル(ネイティブ) |
Zen 4 は 256 ビット幅のデータパスで、512 ビット命令を 2 サイクルで処理するダブルポンプ方式でした。Zen 5 ではネイティブ 512 ビット幅に拡張され、1 サイクルで処理できるようになりスループットが向上しています。
AVX-512 を活用できるアプリケーションであれば Zen 5 世代の hpc8a で性能向上の恩恵を受けやすくなっています。
ちなみに、hpc8a の AMD EPYC 9R45 は avx512_bf16 や avx512_vnni といった AI 推論向けの命令セットにも対応しています。同じ CPU を搭載した R8a/M8a インスタンスの紹介記事で対応命令セットを確認できますのでご興味あればどうぞ。
AVX-512 を活かせるかが鍵ではないか
そこで気になるのが、アプリケーションが AVX-512 を実際に使えているかという点です。AMD が公式ブログで興味深い記事をポストしていました。
AMD の公式ブログでは以下のポイントが指摘されていました。わかりみが深い。
- CPU が AVX-512 をサポートしていても、実際に使っているとは限らない
- レガシーバイナリや未最適化ライブラリは AVX2 や SSE にフォールバックする
- 重要なのは AVX-512 を「使えるか」ではなく「実際に使っているか」
確認方法としては、perf stat の fp_ops_retired_by_width.pack_512_uops_retired カウンターで使用状況を検証できるとのことです。
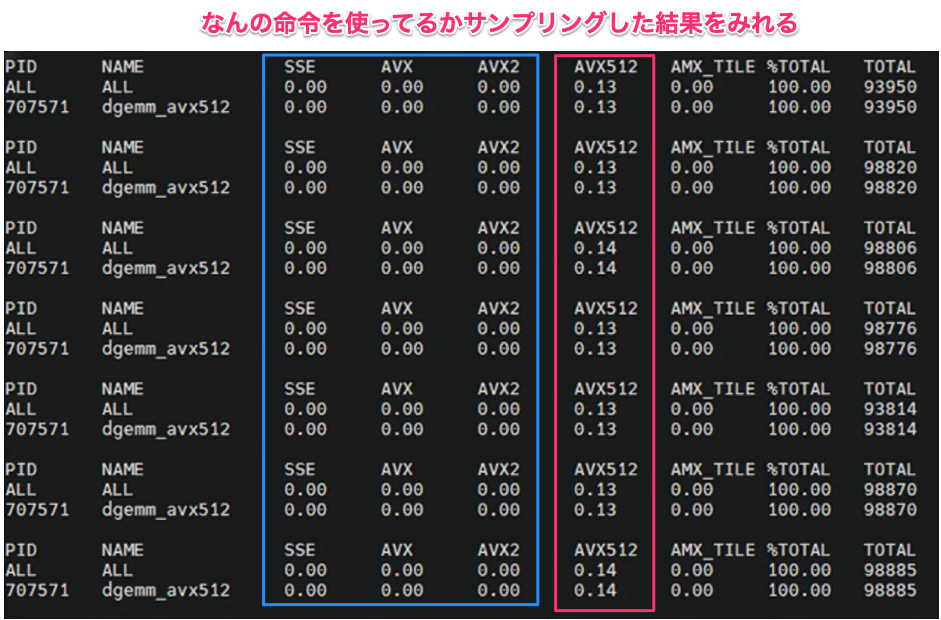
画像引用: Understanding AVX-512 & Validating Usage on AMD EPYC
私の行列演算の検証
以下のブログは Zen 4 環境でコンパイラ最適化を試した記事です。 OpenBLAS の行列演算を試した際、-march=native などの最適化フラグを適用しても性能改善は約 0.8% でした。計算時間の大部分が事前コンパイル済みの OpenBLAS で消費され、コンパイラフラグだけでは効果が限定的でした。この場合は OpenBLAS をソースからビルドして最適化を試さないパフォーマンスの改善できるかわからないというオチでした。ここがまさに AMD の記事のご指摘の点です。
まとめ
m8a インスタンスと同じ AMD CPU を搭載した HPC 専用インスタンス hpc8a がリリースされました。同じ CPU の m8a と比べて物理コアあたり単価が約 32% 安く、コストパフォーマンスに優れています。ただし、HPC ワークロードでは CPU の性能を引き出し、より計算効率を上げるためにはアプリケーション側の対応が肝です。
おわりに
行列計算が多い HPC ワークロードではアプリケーションが AVX-512 を実際に活用できているかの検討も重要だと感じました。HPC インスタンスはスペックで選びがちです。アプリ側が AVX-512 を活用できているか確認する価値があるのではないでしょうか。Zen 5 ではネイティブ 512 ビット幅になり、CPU の性能を発揮するのにはアプリ側の対応が重要です。最適化への投資対効果は十分に高いと思います。もちろん、マシンパワーで解決でもよいのでアプリの改修に時間をかけられるか次第でしょうか。
参考
- Amazon EC2 Hpc8a Instances powered by 5th Gen AMD EPYC processors are now available | AWS News Blog
- Amazon EC2 Hpc8a instances
- 第5世代 AMD EPYC (Turin) 搭載「R8a」がリリース、東京リージョンでも「M8a」が利用可能になりました | DevelopersIO
- Understanding AVX-512 & Validating Usage on AMD EPYC | AMD
- AMD EPYC (Zen 4) 向けの C++ ビルド環境を作成して OpenBLAS で行列計算を試してみた | DevelopersIO
- Amazon EC2 の各インスタンスの物理コア数と 1 コアあたりの単価を一覧で確認する方法 | DevelopersIO
- AMD Zen 5 における AVX-512 命令の実行方式と並列性に関する詳細解説 #Zen5 - Qiita









