FivetranのActivationsを利用してSnowflakeのデータをDatabricksに連携してみた
かわばたです。
2025年5月にFivetranはCensusの買収を発表しました。
そこから、FivetranとCensusは統合され、新しくActivationsの機能が追加されました。
今回はこの機能を活用しSnowflakeからDatabricksにデータを連携していきます。
【公式ドキュメント】
Activations
対象読者
- FivetranのActivationsについて確認したい方
検証環境
- SnowflakeトライアルアカウントEnterprise版
- Databricks Free Edition
- Fivetran アカウント
概要
Activationsは、コードを記述することなく、マネージドかつ自動化されたリバースETLパイプラインを構築できるクラウドベースの製品です。データウェアハウスなどの一元化された信頼できる情報源からデータをアクティベートし、チームの意思決定に活用されるビジネスツールに直接インサイトを提供します。FivetranのELT機能と組み合わせることで、Activationsは双方向のエンドツーエンドのデータパイプラインを実現します。
上記のとおり、Activationsはデータストア(DWH/レイク等)から業務ツールへデータを同期することができます。
※いわゆるReverse ETLで中央集約データをCRMやマーケティングツール等へ同期するプロセスで、従来のETL/ELTと逆方向の流れとなります。
Activations
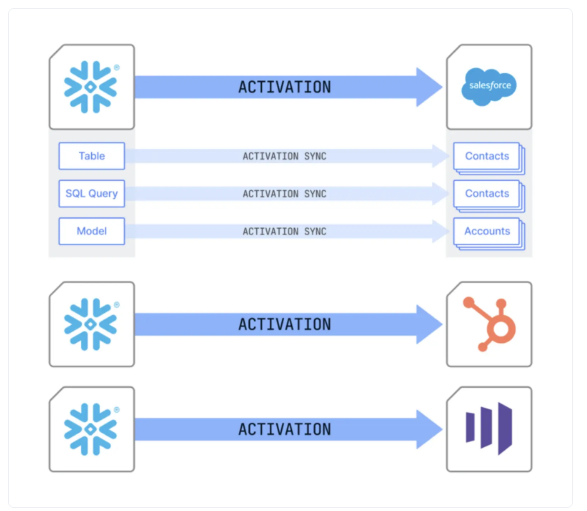
双方向のデータ移動イメージ

【参考ドキュメント】
事前準備
使用するデータ
今回はdbtのサンプルデータjaffle-shopを活用しています。
データベース:KAWABATA_MART_DB
スキーマ:DBT_TKAWABATA
テーブル:CUSTOMERS
にデータを格納しています。
Snowflakeの各種設定
Snowflakeに関する権限設定を行います。
ドキュメントに記載されている権限設定で試します。
※こちらはCENSUSの文言のままですね。
-- census ユーザー用のロールを作成
CREATE ROLE CENSUS_ROLE;
-- sysadmin ロールが、census ロールに付与された権限を継承できるようにする
-- ※これは sysadmin 権限を census ロールに付与するものではありません
GRANT ROLE CENSUS_ROLE TO ROLE SYSADMIN;
-- census ロール用のウェアハウスを作成(パフォーマンスよりコスト最適化)
CREATE WAREHOUSE CENSUS_WAREHOUSE
WITH WAREHOUSE_SIZE = XSMALL
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE;
GRANT USAGE ON WAREHOUSE CENSUS_WAREHOUSE TO ROLE CENSUS_ROLE;
GRANT OPERATE ON WAREHOUSE CENSUS_WAREHOUSE TO ROLE CENSUS_ROLE;
GRANT MONITOR ON WAREHOUSE CENSUS_WAREHOUSE TO ROLE CENSUS_ROLE;
-- census ユーザーを作成
CREATE USER CENSUS
WITH DEFAULT_ROLE = CENSUS_ROLE
DEFAULT_WAREHOUSE = CENSUS_WAREHOUSE
PASSWORD = '<strong, unique password>';
GRANT ROLE CENSUS_ROLE TO USER CENSUS;
-- 同期したいデータの読み取り権限を census ユーザーに付与
-- ※この database と schema は CENSUS とは別名である必要があります
GRANT USAGE ON DATABASE "<your database>" TO ROLE CENSUS_ROLE;
GRANT USAGE ON SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
GRANT SELECT ON ALL TABLES IN SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
GRANT SELECT ON FUTURE TABLES IN SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
GRANT SELECT ON ALL VIEWS IN SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
GRANT SELECT ON FUTURE VIEWS IN SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
GRANT USAGE ON ALL FUNCTIONS IN SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
GRANT USAGE ON FUTURE FUNCTIONS IN SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
GRANT SELECT ON ALL DYNAMIC TABLES IN SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
GRANT SELECT ON FUTURE DYNAMIC TABLES IN SCHEMA "<your database>"."<your schema>" TO ROLE CENSUS_ROLE;
-- Advanced Sync Engine の場合に必要(Basic Sync Engine では不要):
-- Activations が同期状態を保存し、より高速なアンロードや、
-- Warehouse Writeback ログを保持するためのプライベートなブックキーピング DB を作成
CREATE DATABASE "CENSUS";
GRANT ALL PRIVILEGES ON DATABASE "CENSUS" TO ROLE CENSUS_ROLE;
-- GRANT ALL の代わりに必要権限を明示的に付与する場合は以下を使用可能:
--GRANT CREATE SCHEMA, USAGE, MODIFY, MONITOR ON DATABASE "CENSUS" TO ROLE CENSUS_ROLE
CREATE SCHEMA "CENSUS"."CENSUS";
GRANT ALL PRIVILEGES ON SCHEMA "CENSUS"."CENSUS" TO ROLE CENSUS_ROLE;
-- GRANT ALL の代わりに必要権限を明示的に付与する場合は以下を使用可能:
--GRANT CREATE TABLE, CREATE VIEW, MODIFY, MONITOR, CREATE STAGE ON SCHEMA "CENSUS"."CENSUS" TO ROLE CENSUS_ROLE
GRANT CREATE STAGE ON SCHEMA "CENSUS"."CENSUS" TO ROLE CENSUS_ROLE;
Databricksの各種設定
アクセス資格情報の形式ですが、サービスプリンシパルまたはパーソナルアクセストークンの2つの方式があります。
今回はFree Editionのためパーソナルアクセストークンの方式を採用します。
- パーソナルアクセストークンの作成
- 右上側の赤枠を選択します。
- メニュー内の設定を選択します。
- 開発者を選択します。
- 新規トークンを生成を選択し、パーソナルアクセストークンを作成します。
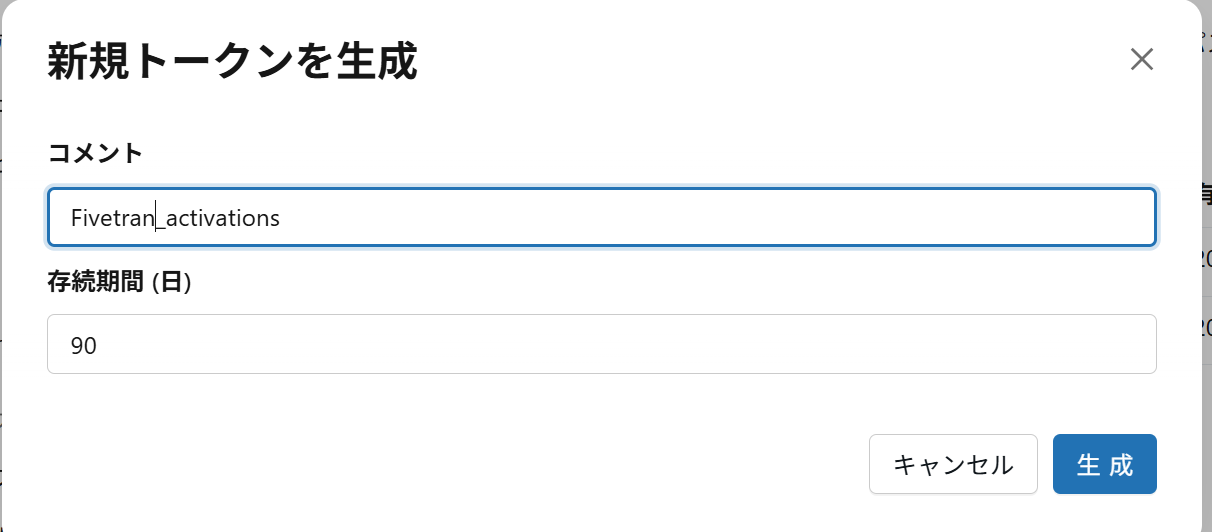
パーソナルアクセストークンの名称を記載します。
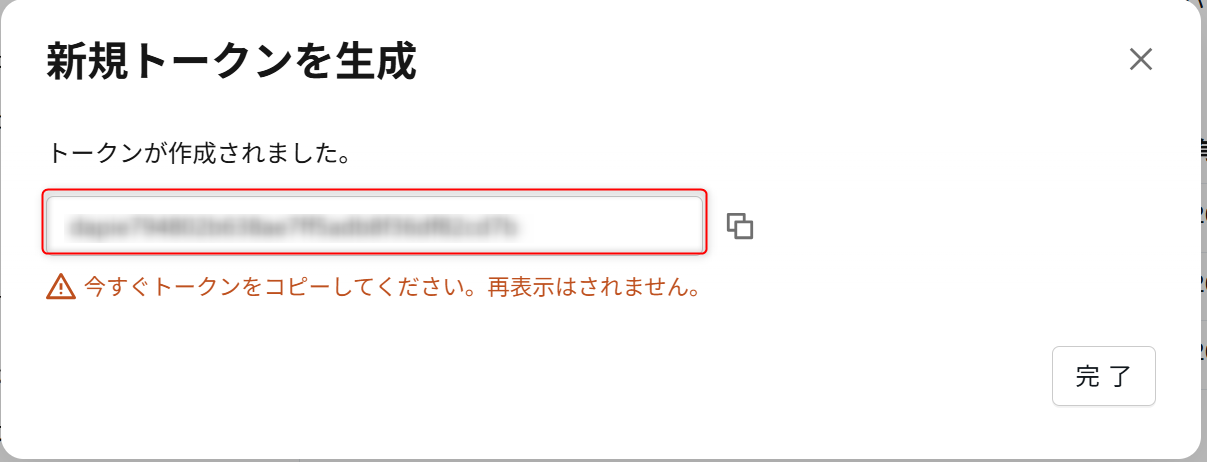
生成されたパーソナルアクセストークンをメモしておきます。
【公式ドキュメント】
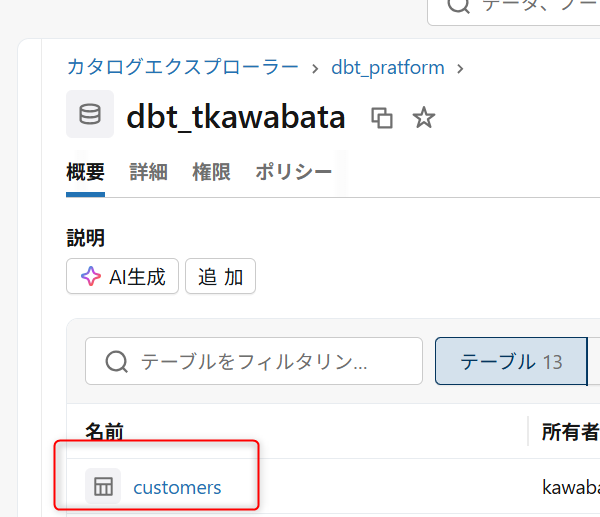
- 連携先のテーブル作成
下記のような形でSnowflakeから連携されるデータを格納するテーブルを作成しています。
実際に試してみた
Activation Sources
Snowflakeの接続設定を行います。
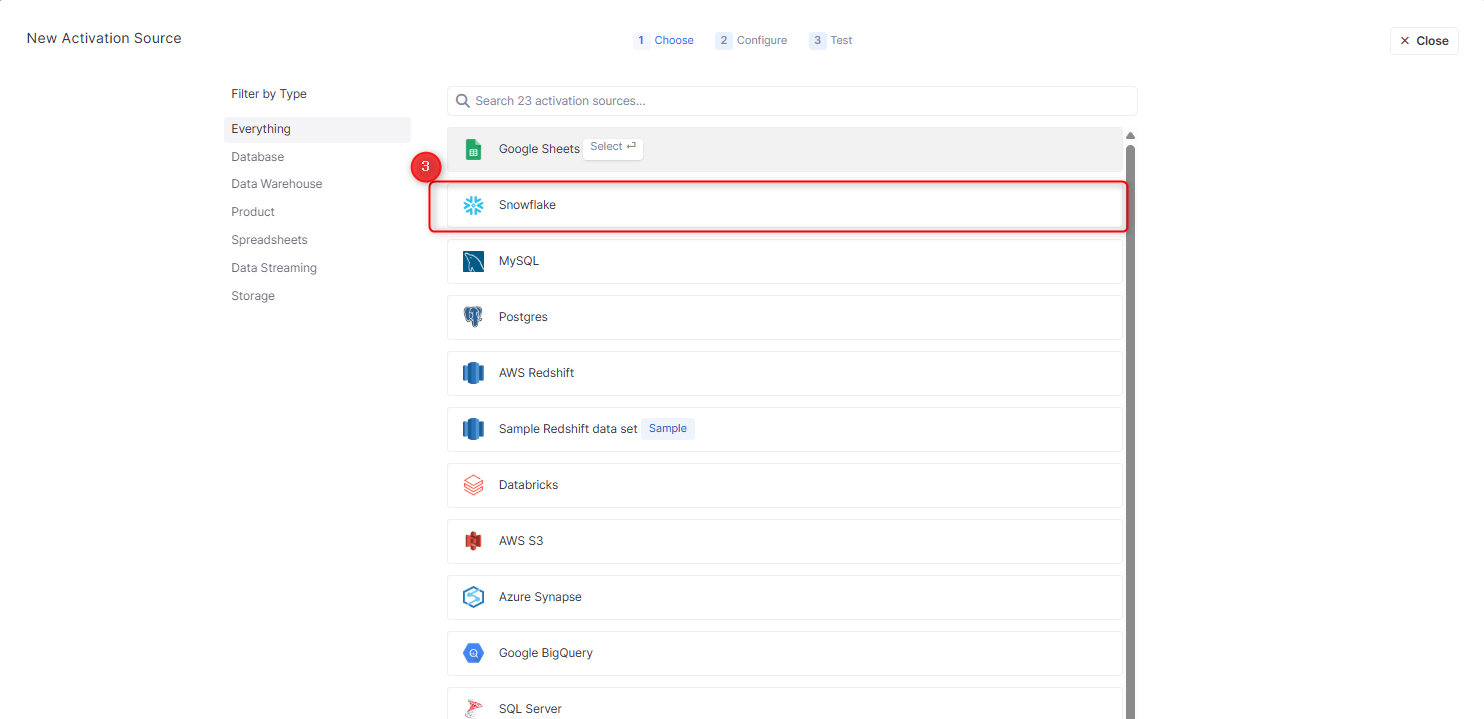
- ActivationsのActivation Sources セクションを選択します。
- New Activation Sourceを選択します。

- 画面遷移し、一覧からSnowflakeを選択します。
Configureの設定画面に遷移します。
- データウェアハウス向け同期エンジンの選択
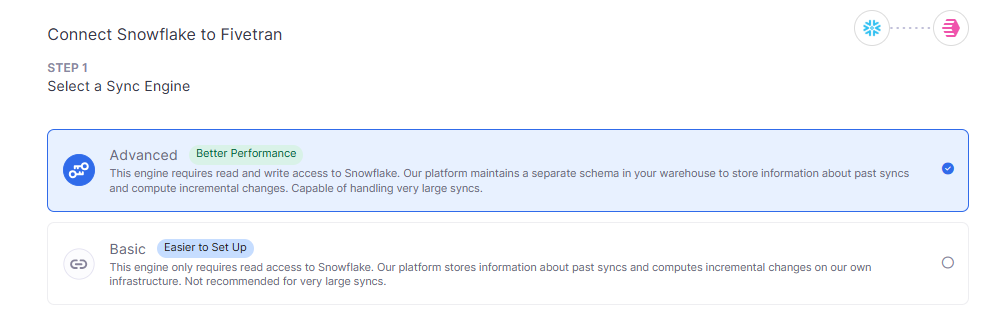
2つのオプションにおける差異は下記のとおりです。
| 項目 | Basic Sync Engine | Advanced Sync Engine |
|---|---|---|
| State tracking location | アクティベーションインフラストラクチャ | データウェアハウス |
| Sync performance | ゆっくり | 早い |
| Ease of setup | とても簡単 | 少し複雑 |
| Warehouse permissions | 読み取り専用アクセス | 読み取り/書き込みアクセス |
| Ability to switch | 上級レベルへのアップグレードが可能(近日公開予定) | ベーシックにダウングレードすることはできません |
Warehouseに対する権限が、読み取り専用か、書き込みを含むかが大きな違いです。
今回は設定項目でログが書き込めると記載があったので、Advancedを試していきます。
- 認証情報の入力
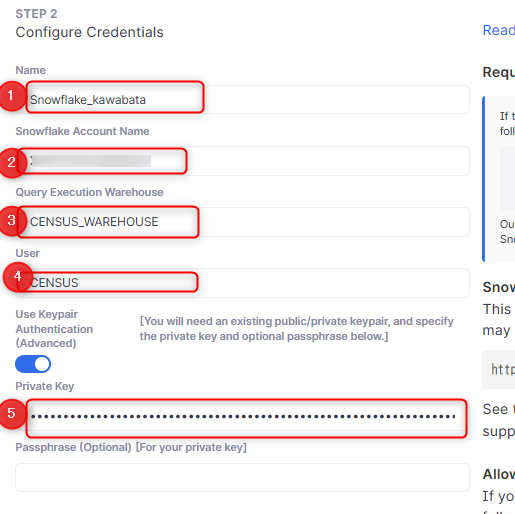
- Name:Activation Sourceの名称。任意の名称を入力
-
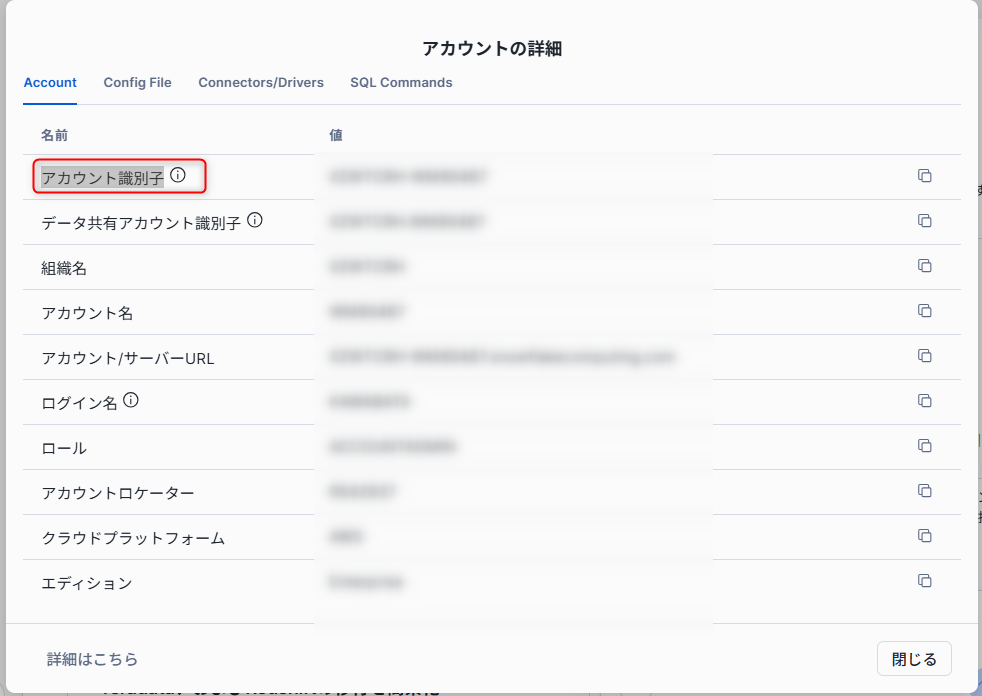
Snowflake Account Name:アカウント識別子を入力
-
Query Execution Warehouse:Snowflakeのウェアハウスを入力
-
User:ユーザー名を入力
-
Private Key:Private Keyを入力
-----BEGIN PRIVATE KEY----- <-- ここから
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAy0CvVbL5...
...
...
...Rk3f8pGg1GZ5oXgQIDAQAB
-----END PRIVATE KEY----- <-- ここまでをコピー
Snowflakeのキーペアについて確認したい方
こちらのブログをご確認ください。
-
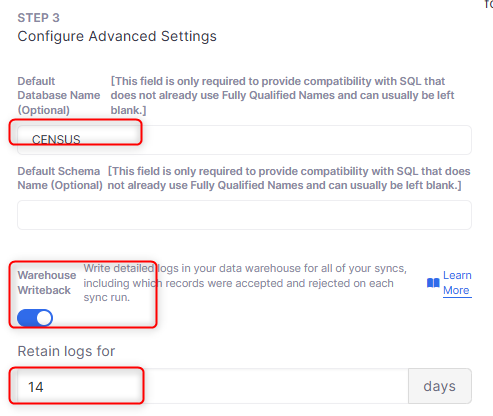
Advanced Settings
-
Default Database Name:ログイン時のデフォルトデータベース
-
Default Schema Name:ログイン時のデフォルトスキーマ
-
Warehouse Writeback:ログを記録有無
-
Retain logs for:ログを保持する期間
各種入力し進むと、Testが実行されます。
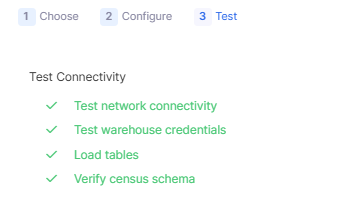
問題なければ下記のようにActivation Sourceが作成されています。
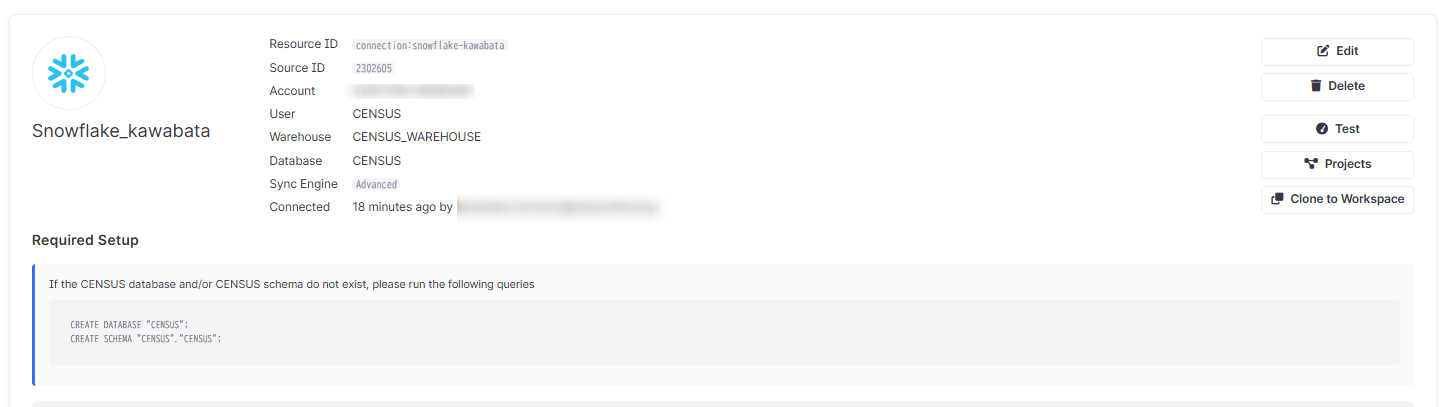
Activation Destinations
Activation DestinationsはSaaSアプリ、分析プラットフォーム、データベース、ストレージ、広告ネットワークなどのデータの送信先を指します。
今回はDatabricksをDestinationとします。
- ActivationsのActivation Destinationsセクションを選択します。
- New Activation Destinationsを選択します。
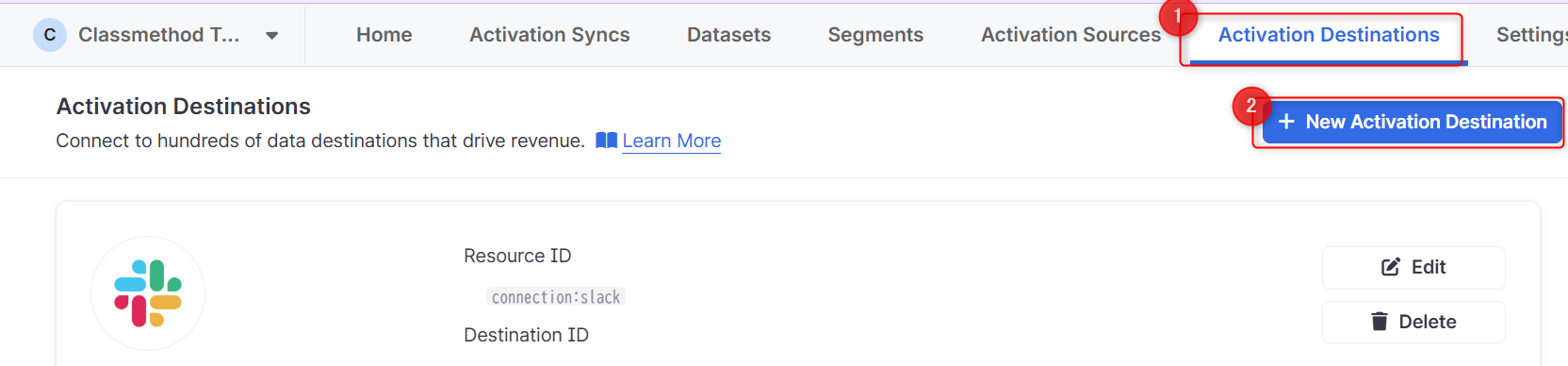
- 画面遷移し、一覧からDatabricksを選択します。
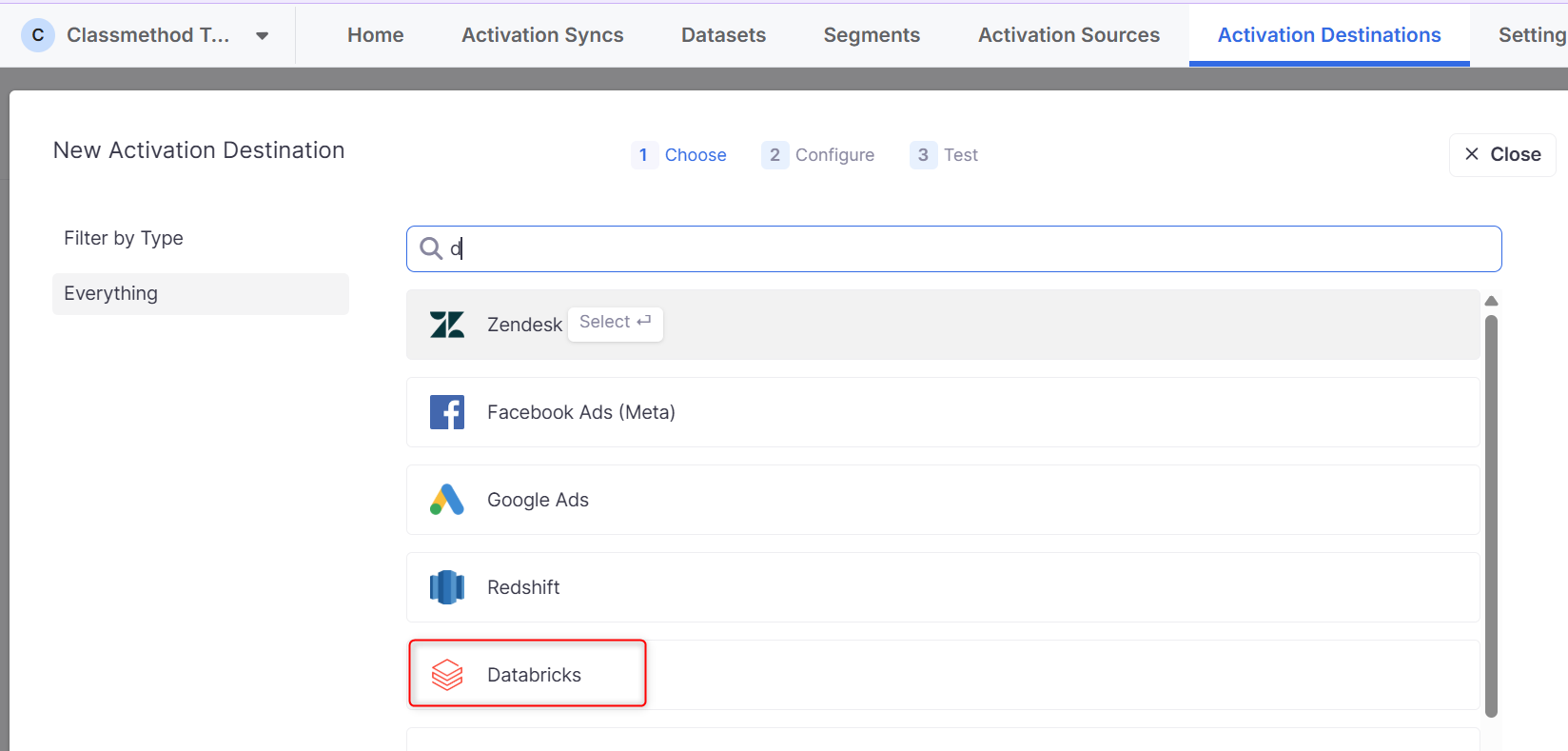
Configureの設定画面に遷移します。
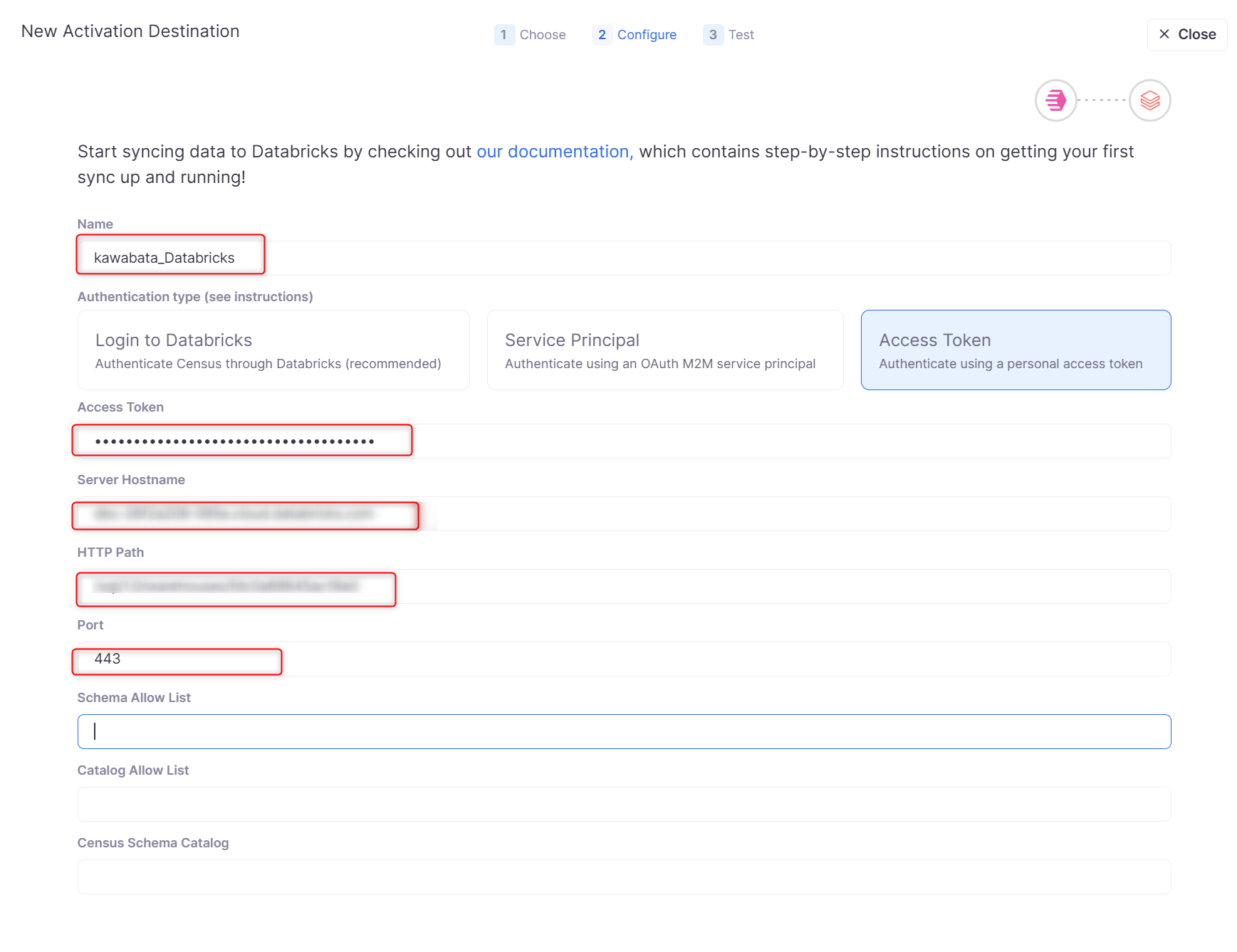
- Name:Destinationの名称を記載します。
- Authentication type:認証方式を選択します。(今回はパーソナルアクセストークンを使用)
- Access Token:保存しておいたパーソナルアクセストークンを記載します。
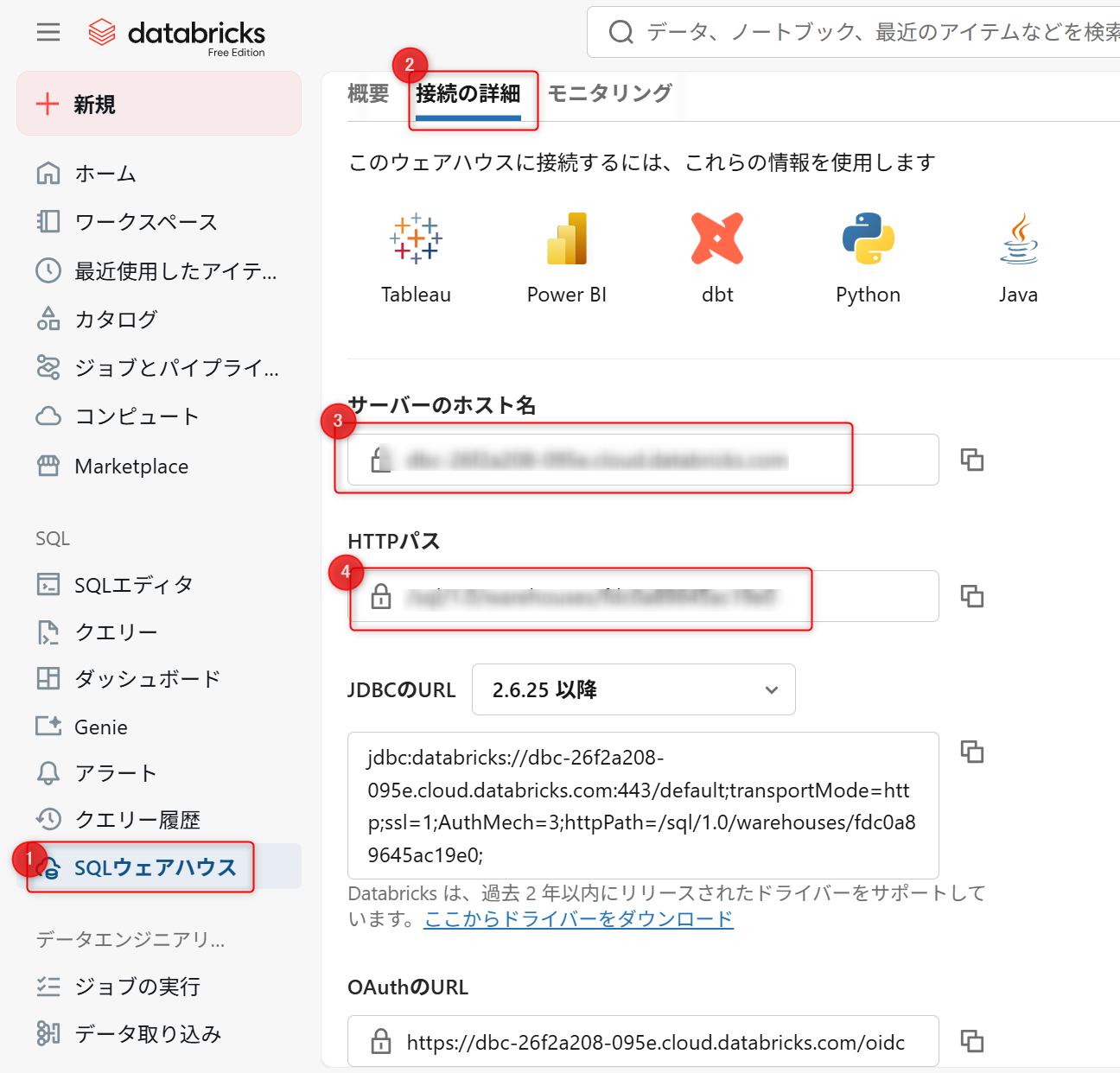
- Server Hostname:下記に記載。
- HTTP Path:下記に記載。
上記4,5については、DatabricksのSQLウェアハウスの接続詳細タブから引用します。
各種入力し進むと、Testが実行されます。
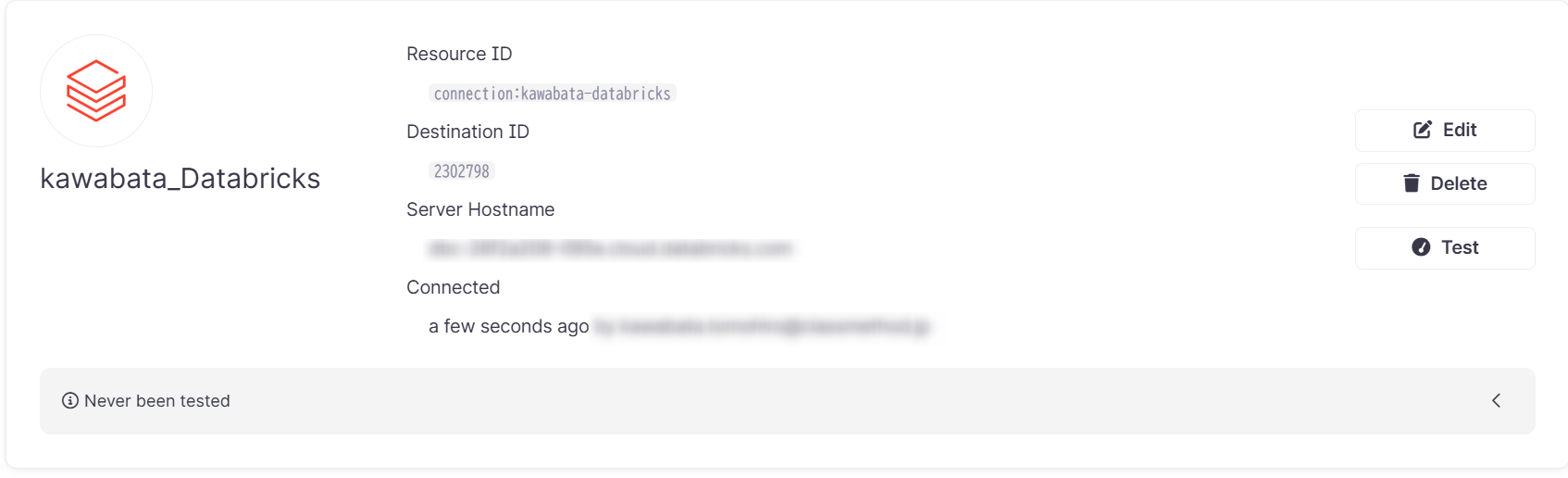
問題なければ下記のようにActivation Destinationsが作成されています。
Activation Syncs
Activation Syncsは選択したActivation SourcesからActivation Destinationsへのデータの流れを定義します。
- ActivationsのActivation Syncsセクションを選択します。
- New Activation Syncsを選択します。

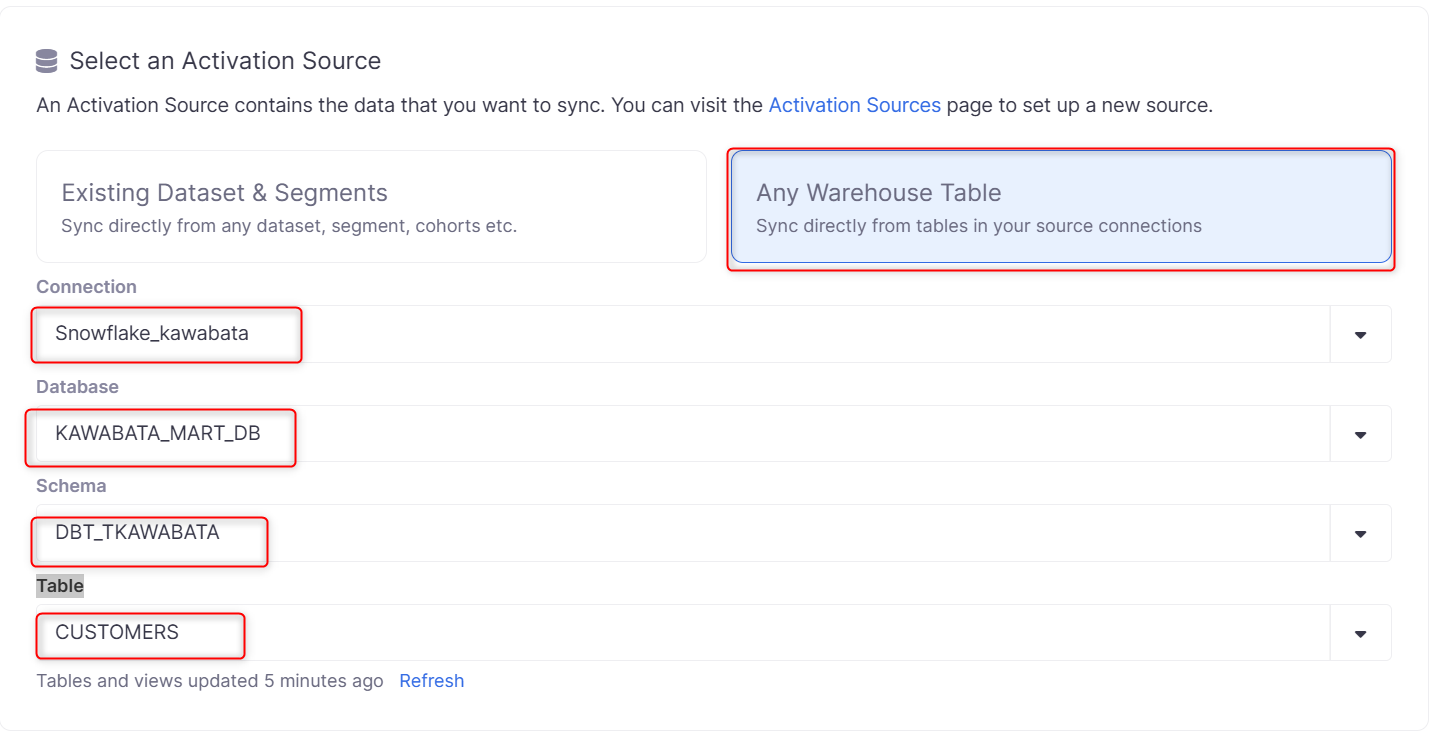
Select an Activation Source
先ほど作成したSourceを選択し、同期したいDatabase、Schema、Tableも合わせて選択します。
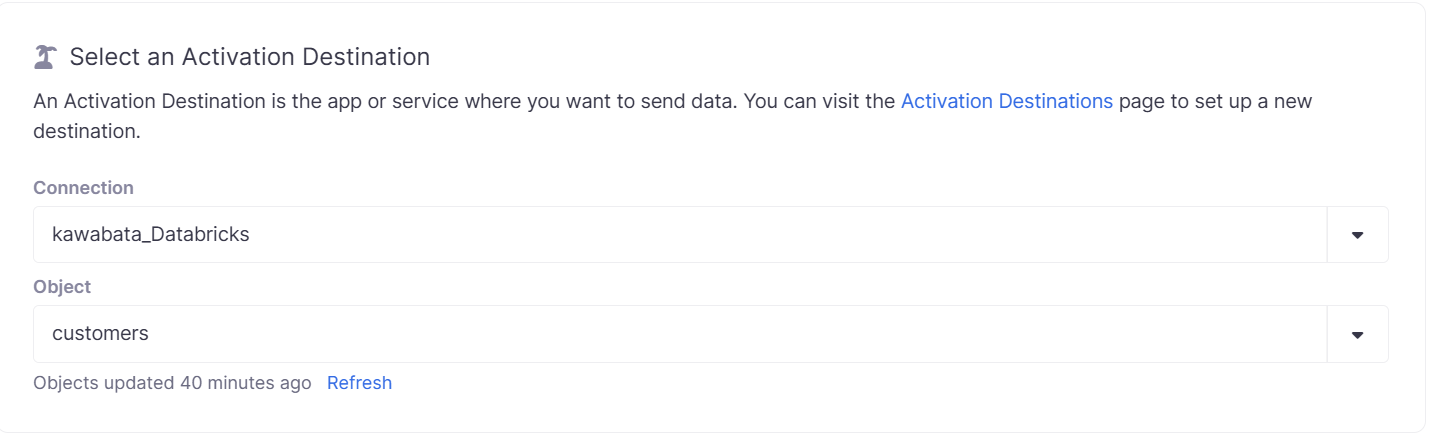
Select an Activation Destination
同様に作成したDestinationを選択し、同期先のObjectを選択します。
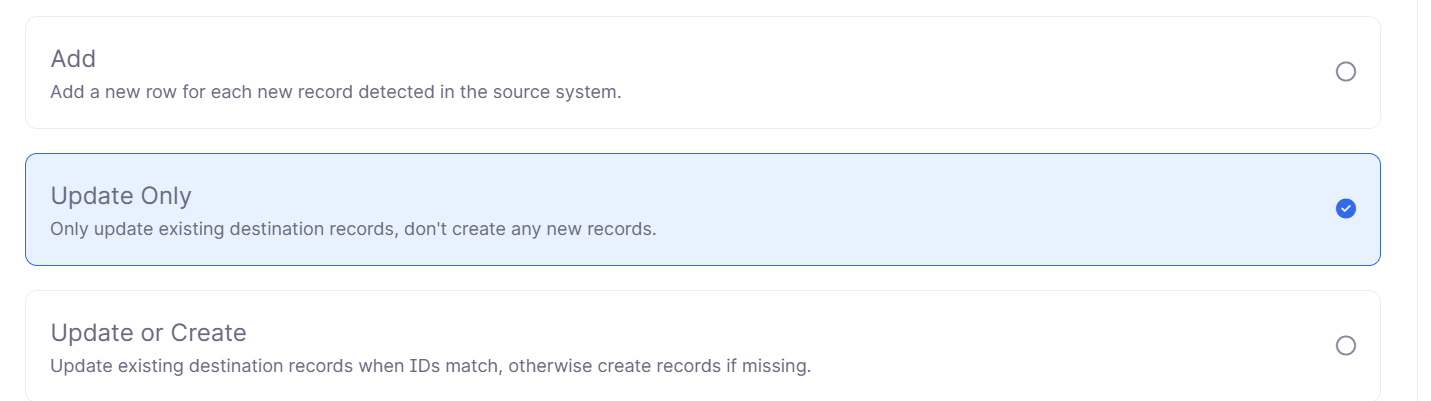
Select a Sync Behavior
同期動作を選択します。
- Add:ソースシステムで検出された新しいレコードごとに、新しい行を追加します。
- Update Only:既存の宛先(保存先)レコードのみを更新し、新しいレコードは作成しません。
- Update or Create:ID が一致する場合は既存の宛先(保存先)レコードを更新し、一致しない・存在しない場合は新しくレコードを作成します。
今回はUpdate Onlyを選択します。
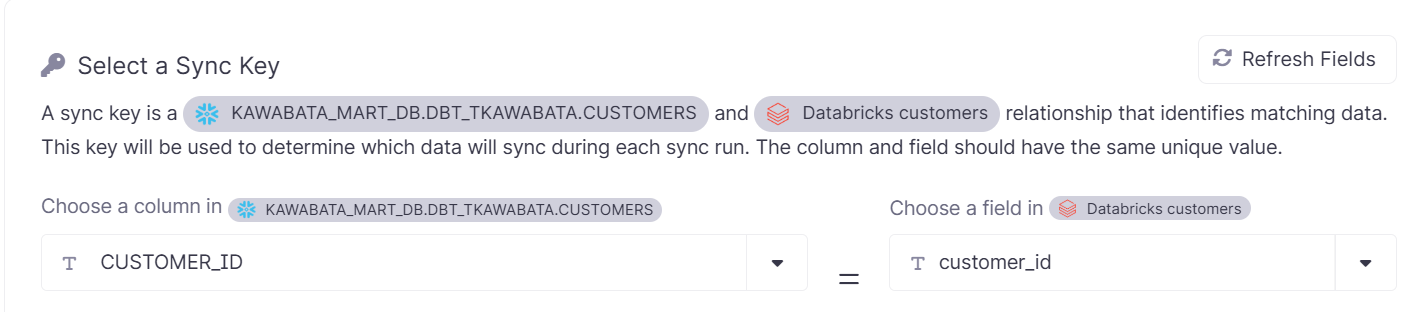
Select a Sync Key
各同期実行時にどのデータを同期するかを決定するために使用されるキーとなります。
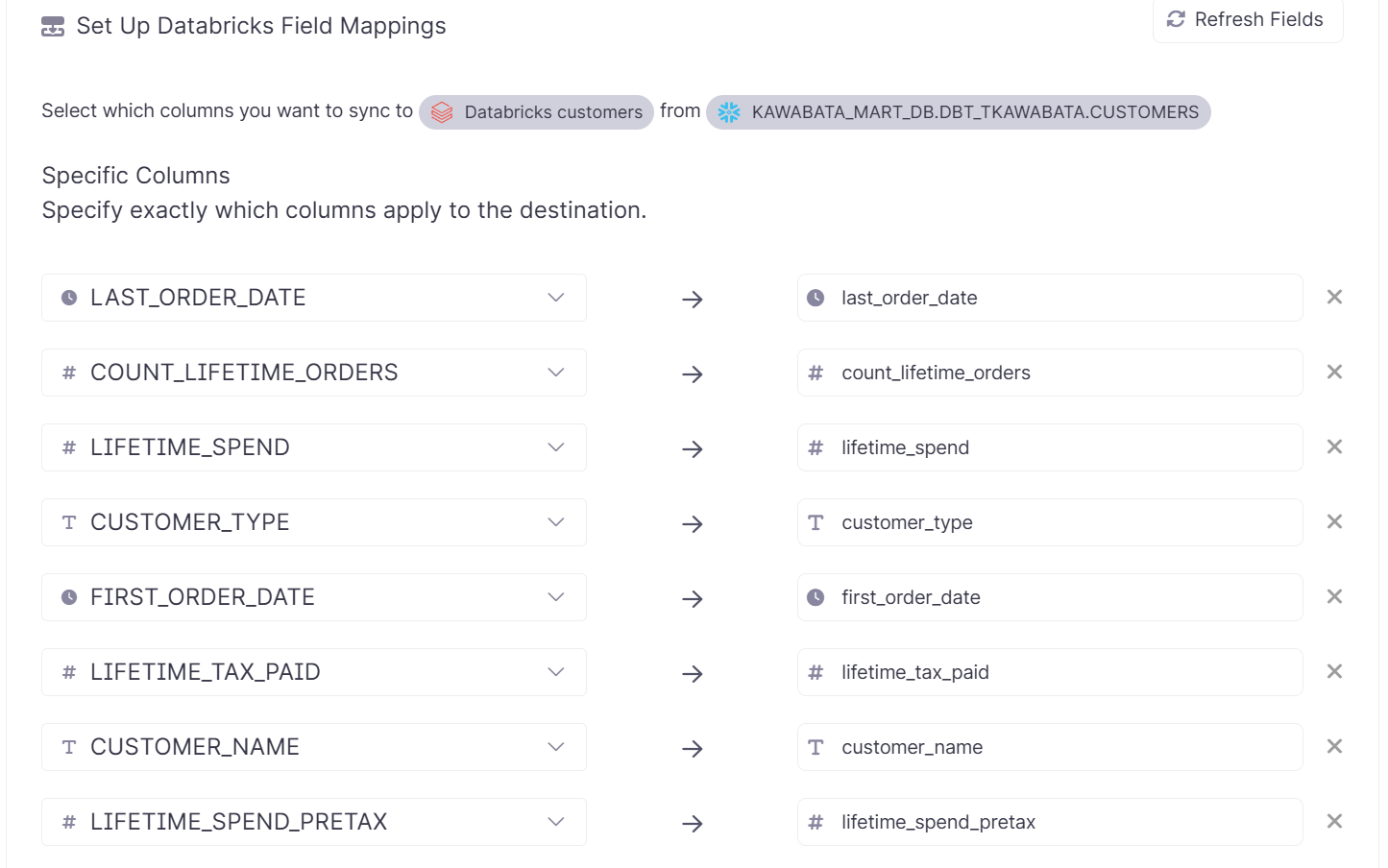
Set Up Databricks Field Mappings
Destinationに適用する列を指定します。Generate Mappingsを選択すると対応する全てのカラムを指定できます。
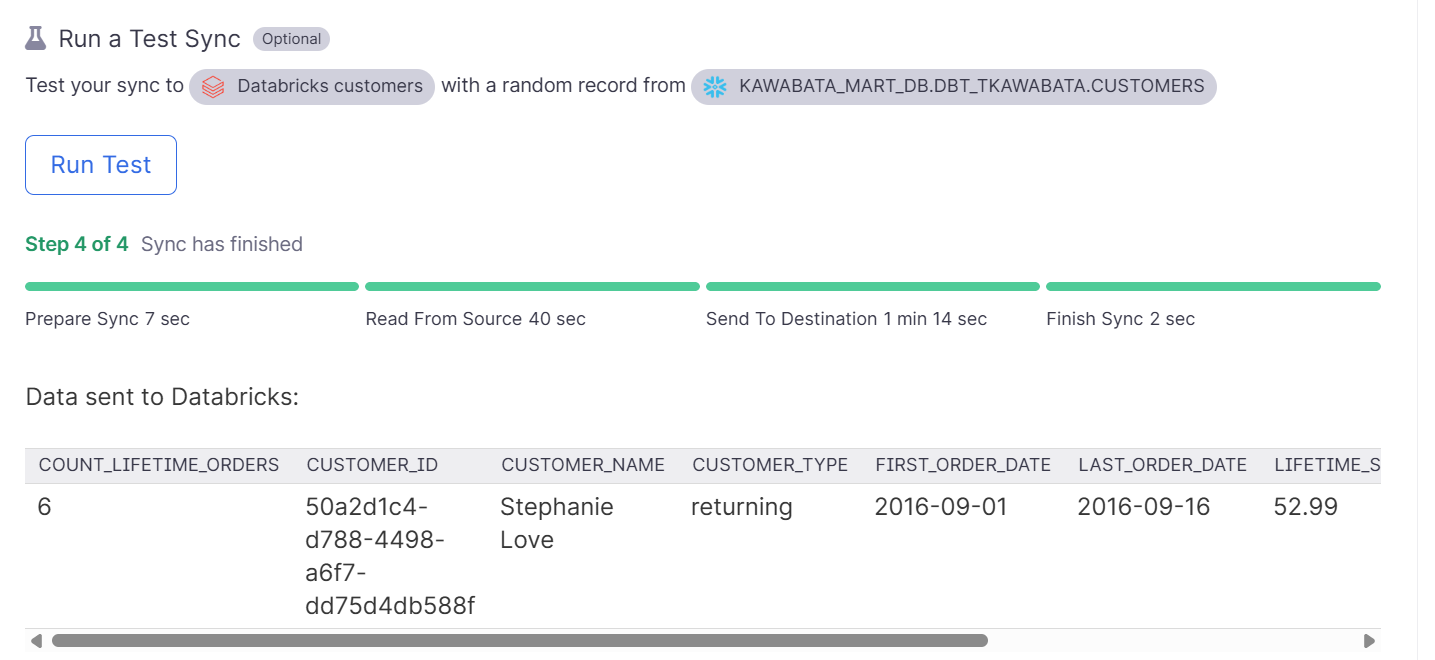
Run a Test Sync
ここでテストを実行することができます。
Summary
テストが完了したら、最後にトリガーをセットアップします。
- Scheduled:この同期(sync)を実行するタイミングのカスタムスケジュールを設定
- Sequence:別の同期(sync)の後に、この同期(sync)を順番に実行
- Manual:手動
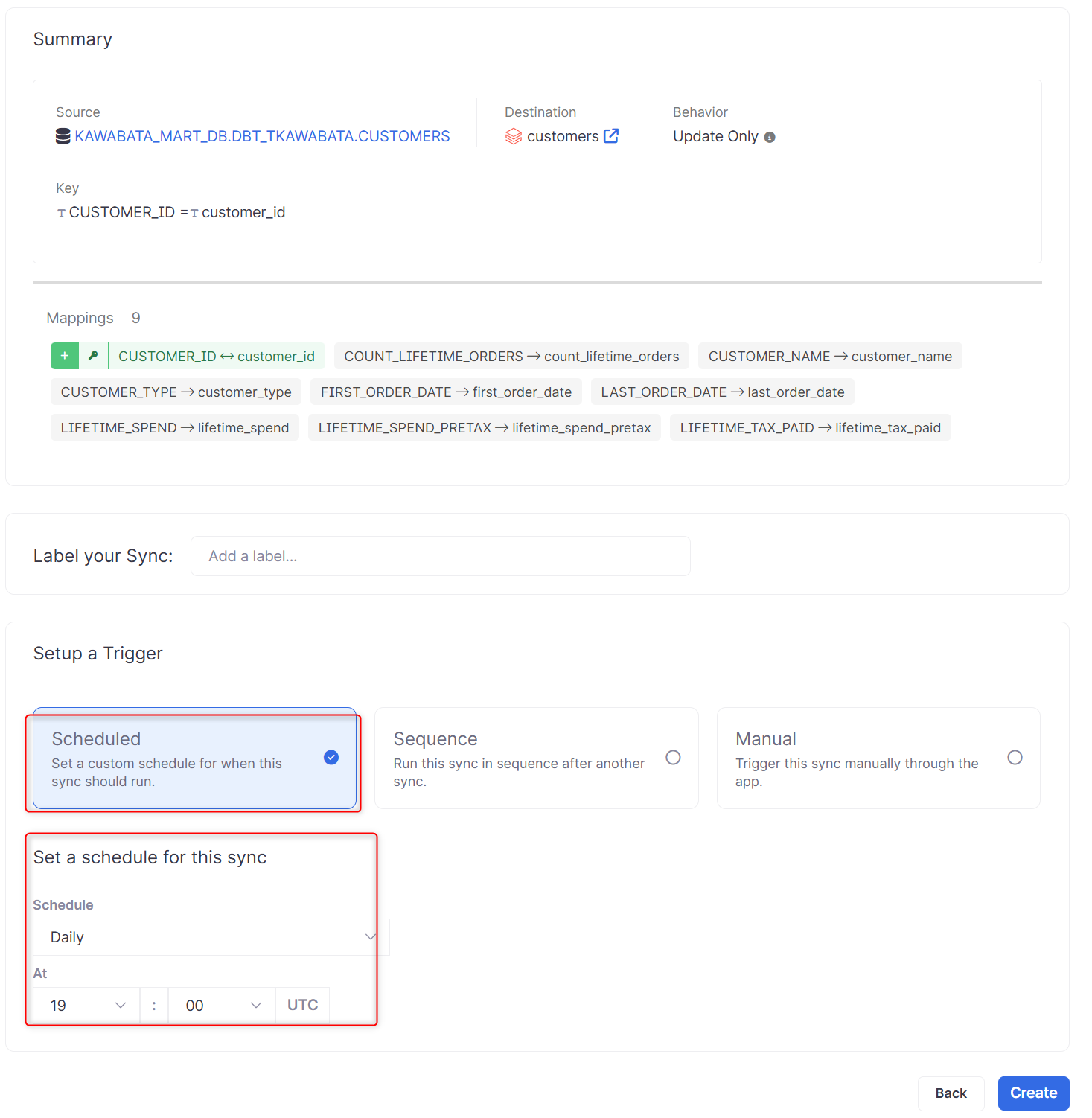
これにて一連の設定が完了しました。
最後に手動実行してみます。
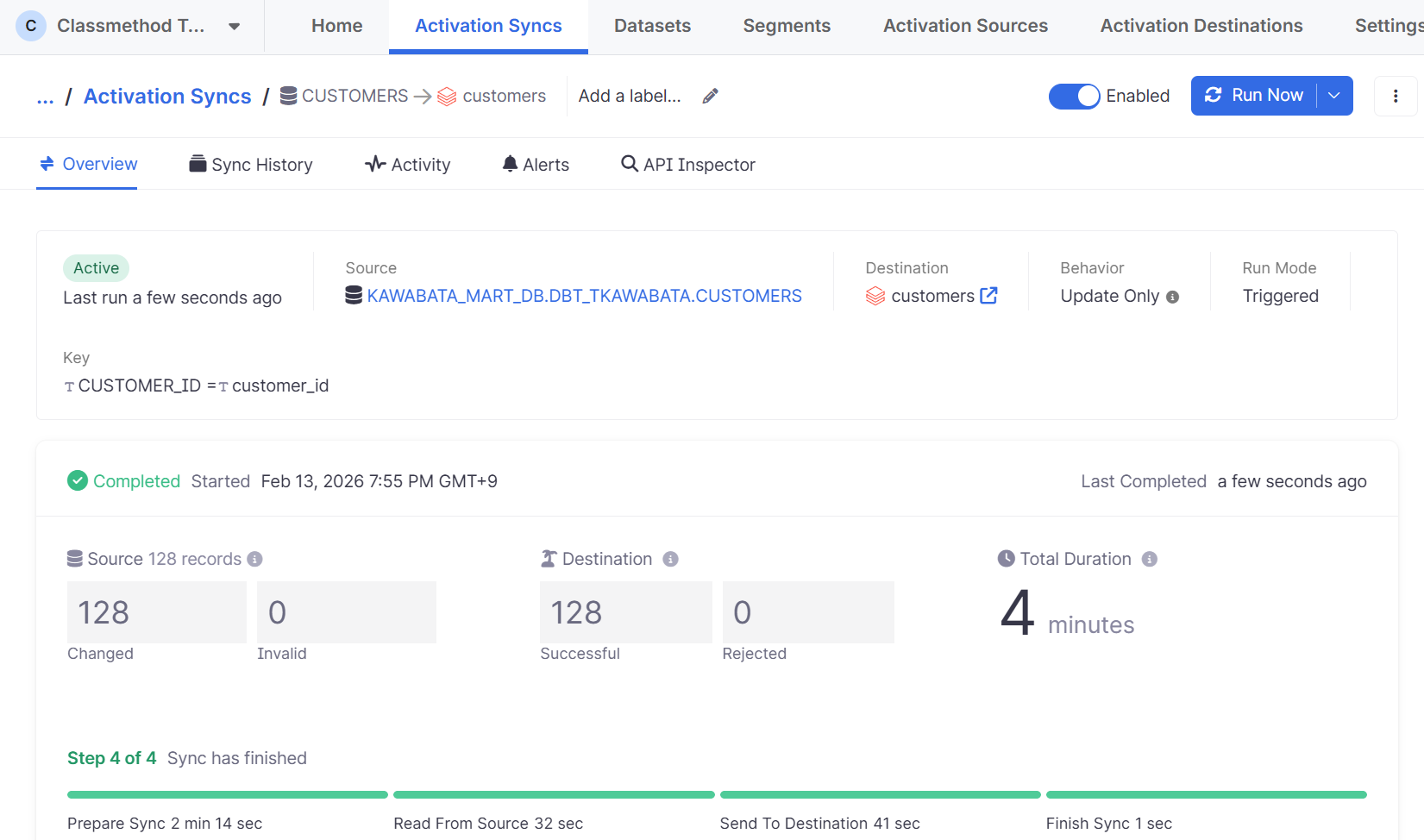
成功しました。
Databricks側も確認してみます。
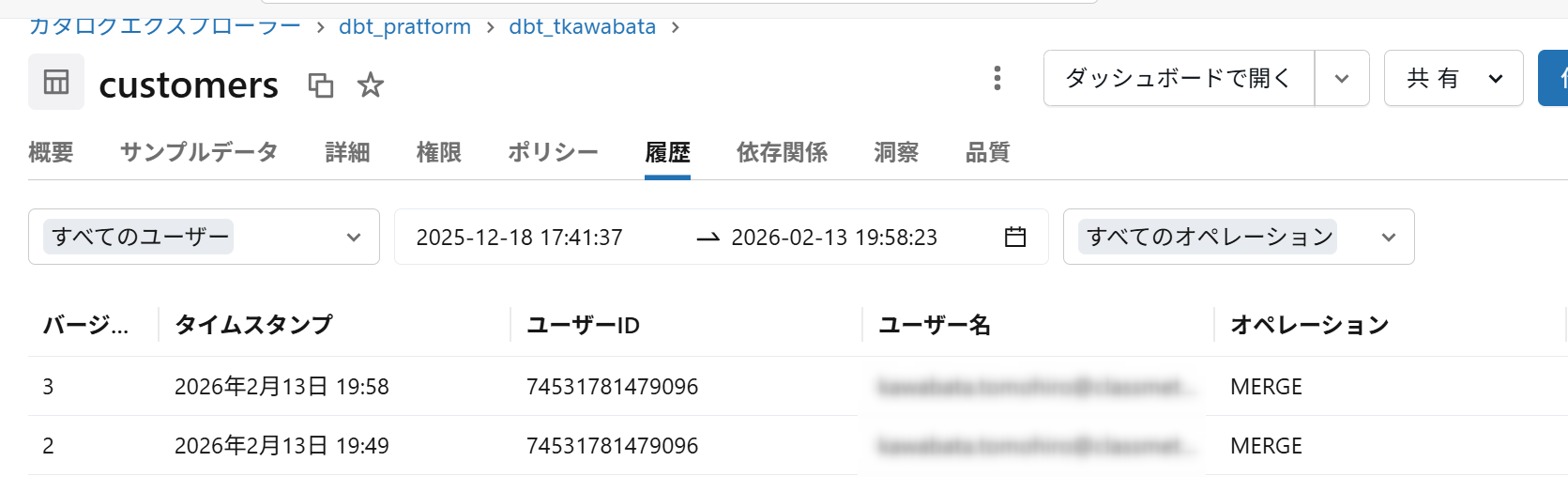
対象のテーブルにMERGE処理されていることが分かります。
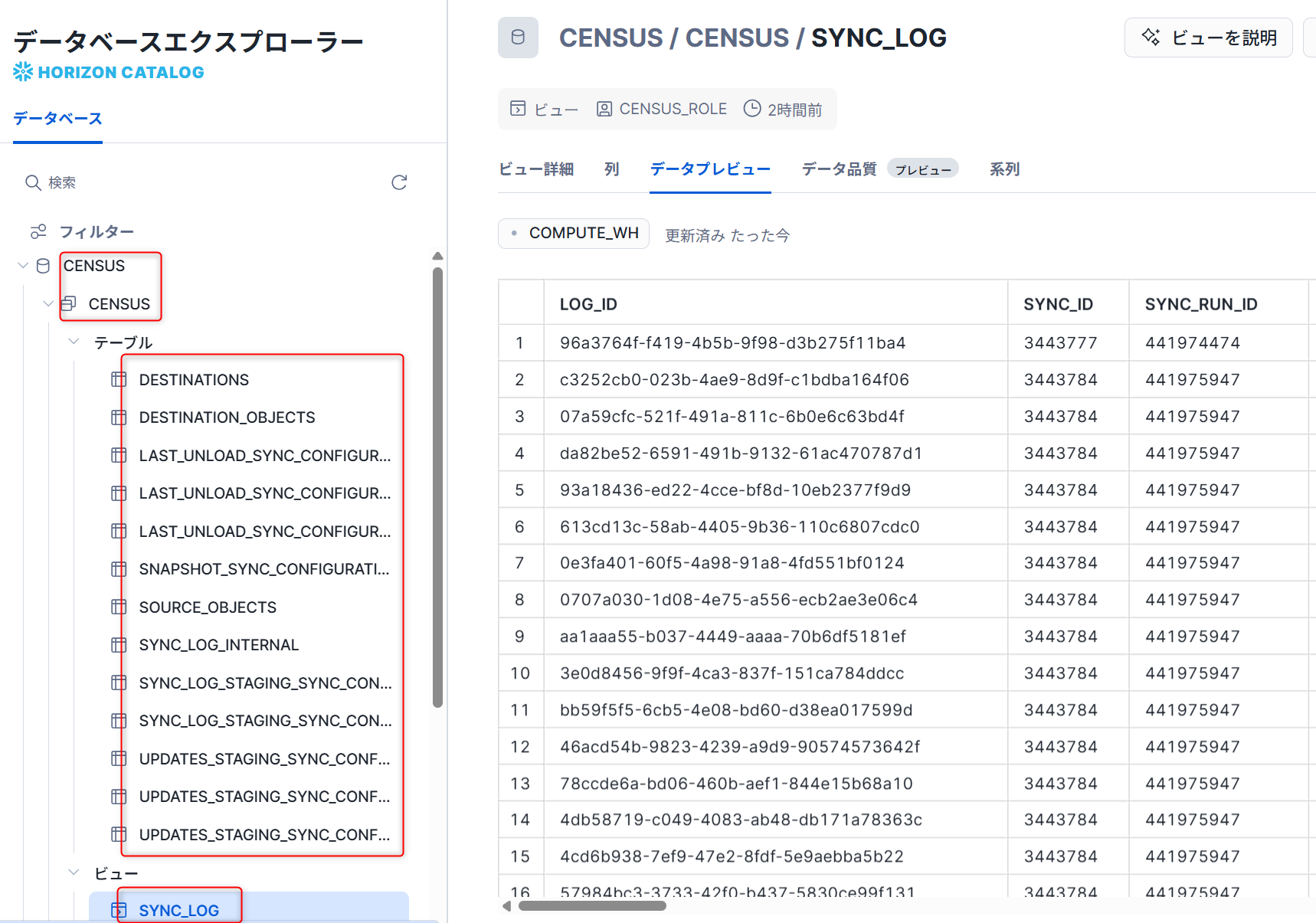
SnowflakeのCENSUSデータベースを確認すると各種ログが作成されていることが確認できました。
コストについて
コストについて、通常のFivetranと同様の形式でMARベースで算出されます。
【参考ドキュメント】
FivetranのPricing Estimatorでも算出可能なのでご確認下さい。
最後に
Fivetranでデータのパイプラインを簡潔に構築できるのでぜひ試してみてください。特に今回の統合でReverse ETLが可能になったのでより利便性が高まったと感じました。
この記事が何かの参考になれば幸いです!








