
ゲーム開発のデータ配置戦略: ノードベースから SoA へ切り替えて更新処理を 3 倍速くした
はじめに
ゲームや物理シミュレーションで画面上のオブジェクトを数百、数千と増やしていくと、ある時点からフレームレートが急激に落ちます。
オブジェクト指向に沿った素直な設計では、各オブジェクトをクラスのインスタンスとして生成し、それぞれに更新処理と描画処理を持たせます。コードの見通しはよいのですが、この設計は大量のオブジェクトを毎フレーム処理する用途には向いていません。 原因はアルゴリズムの計算量ではなく、メモリ上のデータ配置にあります。
本記事ではデータ指向設計 (Data-Oriented Design) の観点からこの問題を分析し、SoA (Structure of Arrays) パターンによる改善手法を解説します。後半では Godot Engine 4.6 で実際に計測し、効果を数値で確認します。
対象読者
- ゲームや物理シミュレーションで大量のオブジェクトを扱う必要があるエンジニア
- オブジェクト指向的な設計でパフォーマンスの壁にぶつかった経験がある方
- Data-Oriented Design (データ指向設計) に興味がある方
参考
- Richard Fabian, Data-Oriented Design — データ指向設計の解説書 (オンライン版無料)
- Godot Engine Documentation, PackedFloat32Array / PackedVector2Array
- Unity Technologies, Unity DOTS / Entities overview
CPU キャッシュとメモリレイアウト
パフォーマンスの問題を理解するには、CPU がメモリからデータを読む仕組みを知る必要があります。
キャッシュラインの仕組み
CPU はメインメモリから 1 バイト単位ではなく、キャッシュラインという固定サイズのブロック (多くの CPU で 64 バイト) 単位でデータを読み込みます。一度読み込んだキャッシュラインに含まれるデータへのアクセスは高速です。逆に、キャッシュラインに載っていないアドレスへアクセスすると、メインメモリからの読み込みが発生し、数十〜数百サイクルの待ちが生じます。 これがキャッシュミスです。
つまり、連続したメモリ領域を順番にアクセスする処理は速く、メモリ上で離れたアドレスを飛び飛びにアクセスする処理は遅くなります。
AoS: オブジェクト指向の自然なレイアウト
オブジェクト指向的に設計すると、ひとつのオブジェクトに位置、速度、色、HP といった全フィールドがまとまります。この構造を配列にしたものが AoS (Array of Structures) です。
移動処理が位置と速度だけを使う場合でも、キャッシュラインには色や HP のデータまで載ります。オブジェクトのサイズが大きいほど、1 本のキャッシュラインに収まるオブジェクト数が減り、キャッシュ効率が悪化します。
SoA: フィールドごとに配列を分ける
同じフィールドを連続した配列にまとめるのが SoA (Structure of Arrays) です。
移動処理は位置配列と速度配列だけを走査します。キャッシュラインには同じフィールドの値が詰まるため、キャッシュミスが大幅に減ります。
ゲームエンジンのノードベース設計で起きること
一般的なゲームエンジンでは、各オブジェクトをシーングラフ上のノードとして管理します。Unity なら GameObject、Godot なら Node2D がこれに当たります。
ノードベースの設計は、ゲームの構造を直感的に表現できるという点で優れています。しかし、同じ種類のオブジェクトを 1000 個生成するような場面では次のオーバーヘッドが無視できなくなります。
- 仮想関数呼び出しの繰り返し
エンジンが毎フレーム、全ノードの更新関数をひとつずつ呼び出す。呼び出し自体のコストに加え、各ノードのメモリ位置が離れているためキャッシュミスを誘発する - シーンツリーの管理コスト
親子関係の維持、座標変換の伝搬といったエンジン内部の処理が、ノード数に比例して増える - メモリの断片化
ノードはヒープ上に個別に確保されるため、連続したメモリ配置が保証されない
プレイヤーやボスのように少数で種類が異なるオブジェクトにはノードが適しています。弾丸やパーティクルのように同質のオブジェクトを大量に扱う場合は、SoA による一括管理のほうが効率的です。
SoA + バッチ処理の設計パターン
SoA でデータを管理する場合の設計パターンを具体的に見ていきます。
データ構造
位置、速度、色をそれぞれ独立した配列として持ちます。
positions: [pos₀, pos₁, pos₂, ...] # Vector2 配列
velocities: [vel₀, vel₁, vel₂, ...] # Vector2 配列
colors: [c₀, c₁, c₂, ...] # 色配列
count: int # 有効なエンティティ数
バッチ更新
ノードベースではエンジンが N 個のノードに対してそれぞれ更新関数を呼び出します。
一方、SoA では単一のループですべてのエンティティを更新します。
for i in range(count):
positions[i] += velocities[i] * delta
配列の先頭から末尾まで連続アクセスするため、キャッシュ効率が高くなります。関数呼び出しのオーバーヘッドも 1 回で済みます。
バッチ描画
描画も同様に、ひとつの描画関数内でループして全エンティティを描画します。
for i in range(count):
draw_circle(positions[i], radius, colors[i])
ノードベースではエンジンが N 個のノードそれぞれの描画関数を呼び出しますが、SoA ではひとつの描画関数内のループで N 個の図形をまとめて描画します。
Godot Engine 4.6 で計測してみる
概念を踏まえ、実際にどの程度の差が出るのかを Godot Engine 4.6 で検証しました。
ベンチマークの設計
N 個の円がランダムな方向に移動し、画面端で反射する最小限のシーンを作成しました。
比較対象は次の 2 パターンです。
- Node-based
各円を Node2D の子ノードとして生成し、各ノードが自身の_process()と_draw()を持つ。Godot の_draw()はqueue_redraw()で再描画を要求したときだけ呼ばれるため、本検証では毎フレームqueue_redraw()を呼んでいる - SoA
すべての位置、速度、色を PackedArray で管理し、単一の_process()と_draw()でバッチ処理する
ウォームアップ 60 フレームの後、180 フレームの算術平均を記録しました。全フレーム時間 (frame_ms)、更新処理時間 (update_ms)、描画処理時間 (draw_ms) を分離して計測しています。計測環境は Windows、Godot 4.6.1 (GL Compatibility レンダラー)、VSync OFF としました。

Node-based / エンティティ数: 5000 のキャプチャ

SoA / エンティティ数: 5000 のキャプチャ
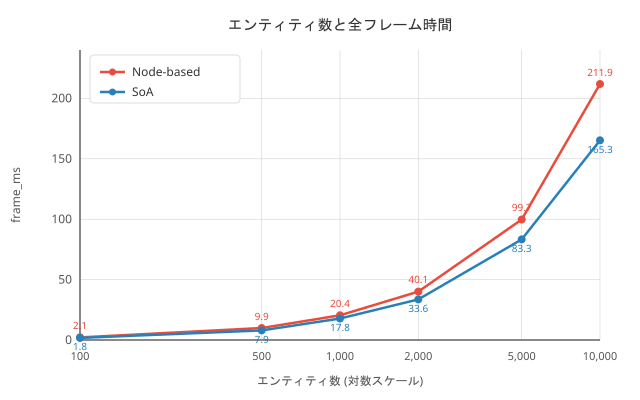
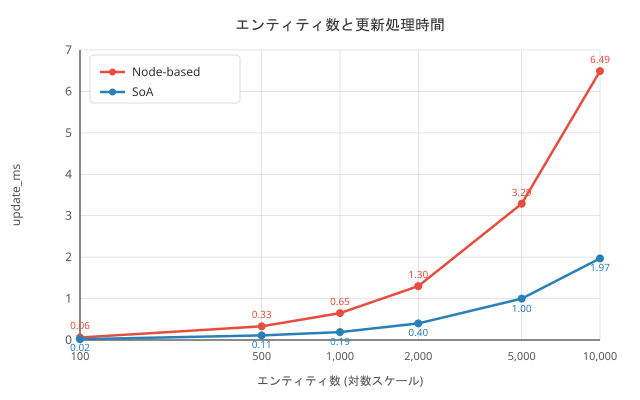
計測結果
| エンティティ数 | Node FPS | SoA FPS | Node frame (ms) | SoA frame (ms) | Node 更新 (ms) | SoA 更新 (ms) |
|---|---|---|---|---|---|---|
| 100 | 468 | 566 | 2.14 | 1.77 | 0.06 | 0.02 |
| 500 | 101 | 126 | 9.90 | 7.92 | 0.33 | 0.11 |
| 1,000 | 49 | 56 | 20.43 | 17.78 | 0.65 | 0.19 |
| 2,000 | 25 | 30 | 40.10 | 33.58 | 1.30 | 0.40 |
| 5,000 | 10 | 12 | 99.71 | 83.28 | 3.29 | 1.00 |
| 10,000 | 5 | 6 | 211.91 | 165.30 | 6.49 | 1.97 |
検証で分かったこと
-
更新処理は SoA が約 3.3 倍高速
10,000 エンティティで Node-based の 6.49 ms に対し、SoA は 1.97 ms でした。PackedArray の連続走査によるキャッシュ効率の向上と、関数呼び出しオーバーヘッドの削減が寄与しています。 -
描画処理がフレーム時間の大部分を占める
描画時間はフレーム全体の 42〜48% を占めていました。描画処理には GPU への描画コマンド発行が含まれるため、CPU 側のデータ配置による改善幅には限界があります。ただし、Node-based では個別の_draw()呼び出しオーバーヘッドがある分だけ遅くなっています。 -
全体の FPS 改善は約 1.2 倍にとどまる
更新処理の改善率は大きいものの、フレーム時間の大部分を描画処理とエンジンのオーバーヘッドが占めているため、全体としては 1.2 倍程度の改善です。SoA はあくまで CPU 側のデータアクセス最適化であり、描画パイプラインのボトルネックに対しては GPU インスタンシングなど別のアプローチが必要です。
どちらを使うべきか
SoA が常に正解というわけではありません。SoA が有効なのは、同じ種類のオブジェクトが数百〜数千以上あり、毎フレーム全エンティティを走査する処理です。弾丸、パーティクル、群衆シミュレーションが典型例です。一方、個数が少なく種類が多いオブジェクトでは、ノードベースが適しています。プレイヤー、UI 要素、ボス敵などはノードの恩恵 (エンジンの物理演算やアニメーション機能の利用) を受けやすく、SoA にする動機がありません。同じゲーム内でも、プレイヤーはノードベース、弾丸は SoA のように混在させる設計が現実的です。
まとめ
データ配置を AoS から SoA に変えることで、大量オブジェクトの更新処理を大幅に高速化できます。ゲームエンジンのノードシステムはコードの見通しをよくしてくれますが、同質のオブジェクトを大量に扱う場面ではデータ指向の設計に切り替える価値があります。本記事の計測では、更新処理で約 3.3 倍、全体フレームで約 1.2 倍の改善を確認しました。描画がボトルネックになる場合は、GPU インスタンシングなど別の手法と組み合わせることでさらなる改善が見込めます。








