
GitHub ActionsからGemini File Search Toolを自動実行する
Gemini APIのファイル検索ツールを使用して検索拡張生成(RAG)が低コストでできるようになりました。
今回はこのAPIの実行をGithub Actions経由で行わせてみます。
背景
BigQueryのテーブルのメタデータ(テーブル定義、カラム説明、ドメイン知識)をマークダウンにして参照できるようにしているのですが、このファイルをGithubで管理しています。
Github上のブランチにファイルがマージされたら自動的に最新の情報をGeminiのファイル検索に反映させれるのでは?と思ったのでやってみます。
社内データを扱うデータアナリストやバックオフィス業務を行うユーザーが「営業チーム別の月次売上」「部署別の予算」といったビジネス用語で検索する際、適切なBigQueryテーブルやカラムを見つけやすくなるのではないか、さらに将来的にはSQLの実行とそのデータの解析までも目論んでおります。
アーキテクチャ
GitHub Repository
↓ (git push)
GitHub Actions
↓ (検出: metadata/docs/* 変更)
gemini_file_search_tool.js
↓ (複数ファイル並列アップロード)
Gemini File Search Store
↓
ユーザークエリ(自然言語)
↓
Gemini + File Search Tool
↓
回答(該当テーブル・カラム情報など) + 引用元ファイル表示
ユーザーがメタデータから「適切なテーブル」「必要なカラム」を見つけるまでのフローを自動化を目標にしています。
実装のポイント
1. ディレクトリ別Store割り当て
複数のBigQueryデータセット(Salesforce、HubSpot、AWSなど)があり、それぞれ対応するGemini File Search Storeに同期する必要がありました。
検索する際、最大5つまでしかStoreを検索できなかったため、以下のようにBigQueryデータセットとStoreのマッピング情報を設定としてとりあえずおいておくことにしました
{
"salesforce-store": {
"datasets": ["データセット1", "データセット11"]
},
"hubspot-store": {
"datasets": ["データセット2", "データセット22", "データセット2222"]
},
"aws-store": {
"datasets": ["データセット3"]
},
"core-store": {
"datasets": ["domain"]
}
}
2. 再帰的ディレクトリスキャン
階層構造を持つディレクトリがあったため、再帰的にマークダウンファイルを取得する機能を追加しました。
function getMarkdownFiles(dir, recursive = false) {
try {
const files = [];
const entries = fs.readdirSync(dir, { withFileTypes: true });
for (const entry of entries) {
if (entry.isFile() && entry.name.endsWith('.md')) {
files.push(path.join(dir, entry.name));
} else if (recursive && entry.isDirectory()) {
// domain ディレクトリの配下を再帰的に取得
files.push(...getMarkdownFiles(path.join(dir, entry.name), true));
}
}
return files;
} catch (error) {
console.error(`Error reading directory ${dir}:`, error.message);
return [];
}
}
利用時:
const isRecursive = datasetName === 'domain';
const files = getMarkdownFiles(datasetPath, isRecursive);
3. 並列アップロード
複数ファイルを効率的にアップロードするため、Promise.all()で並列処理しました。
const uploadPromises = files.map(file =>
(async () => {
try {
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: file.path,
fileSearchStoreName: storeId,
config: {
displayName: file.name,
mimeType: 'text/markdown'
}
});
// Wait until import is complete
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, POLL_INTERVAL_MS));
operation = await ai.operations.get({ operation });
}
console.log(`✓ ${file.name}`);
return { file: file, status: 'success' };
} catch (error) {
console.log(`✗ ${file.name}: ${error.message}`);
return { file: file, status: 'error', error: error.message };
}
})()
);
const uploadResults = await Promise.all(uploadPromises);
GitHub Actions統合
変更されたファイルの検知方法
GitHub Actionsで変更ファイルを検知する方法ですが、以下のような方法に指定みました:
1. paths フィルター
特定ディレクトリへの変更でのみワークフローを実行します。
on:
push:
branches:
- main
paths:
- 'metadata/docs/**'
メリット:
- ✅ 不要なワークフロー実行を削減
- ✅ GitHub Actions の実行時間と請求額を削減
- ✅ 設定がシンプル
動作例:
✅ metadata/docs/domain/knowledge.md 更新 → ワークフロー実行
✅ metadata/docs/domain/sub/file.md 追加 → ワークフロー実行
❌ metadata/json/salesforce/table.json 更新 → ワークフロー実行しない
❌ README.md 更新 → ワークフロー実行しない
2. Workflow ステップ内で検知(より詳細な制御が必要な場合)
ワークフロー内で git diff を使用して、変更ファイルを動的に検知。
※ 変更されたファイルだけFile Search Toolを使ってStoreにインポートしたかった。
例:
- name: Get changed files
id: changed-files
run: |
CHANGED_FILES=$(git diff --name-only HEAD~1 HEAD)
echo "files=$CHANGED_FILES" >> $GITHUB_OUTPUT
- name: Check domain files changed
run: |
if echo "${{ steps.changed-files.outputs.files }}" | grep -q "metadata/docs"; then
echo "Domain metadata changed - syncing to Gemini"
else
echo "No domain metadata changes - skipping sync"
fi
変更があったファイルリストを GITHUB_OUTPUT に保存し、Storeにインポートするためのスクリプトファイルに渡すようにしてみました。
ワークフロー実装
.github/workflows/sync-gemini.ymlの完全な設定:
name: Sync Metadata to Gemini File Search
on:
push:
paths:
- 'google-bigquery/metadata/docs/**'
branches:
- main
jobs:
sync:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: '18'
cache: 'npm'
- name: Install dependencies
run: npm install
- name: Get changed files
id: changed_files
run: |
if [ "${{ github.event.before }}" = "0000000000000000000000000000000000000000" ]; then
# Initial push (new branch)
CHANGED=$(git diff --name-only HEAD~1..HEAD 2>/dev/null || echo "")
else
# Regular push
CHANGED=$(git diff --name-only ${{ github.event.before }} ${{ github.sha }})
fi
# メタデータディレクトリ配下のファイルのみフィルタ
METADATA_FILES=$(echo "$CHANGED" | grep "^google-bigquery/metadata/docs/" || echo "")
echo "files<<EOF" >> $GITHUB_OUTPUT
echo "$METADATA_FILES" >> $GITHUB_OUTPUT
echo "EOF" >> $GITHUB_OUTPUT
if [ -z "$METADATA_FILES" ]; then
echo "No metadata files changed"
else
echo "Changed files:"
echo "$METADATA_FILES"
fi
- name: Sync to Gemini File Search
if: steps.changed_files.outputs.files != ''
env:
GOOGLE_API_KEY: ${{ secrets.GOOGLE_API_KEY }}
GEMINI_FILE_SEARCH_STORES: ${{ secrets.GEMINI_FILE_SEARCH_STORES }}
CHANGED_FILES: ${{ steps.changed_files.outputs.files }}
run: |
echo "🚀 Syncing files to Gemini..."
node .github/workflows/gemini_file_search_tool.js
環境変数の設定
GitHub Secrets に以下を登録します:
GOOGLE_API_KEY: Gemini APIキーGEMINI_FILE_SEARCH_STORES: 同期先のストア情報。JSON形式でStore Nameを保存していました。
本記事でのStoreは前もって作っておいたものを使っています。
例:
{
"salesforce-store": "fileSearchStores/salesforce-store-****",
"hubspot-store": "fileSearchStores/hubspot-store-****",
"aws-store": "fileSearchStores/aws-store-****",
"core-store": "fileSearchStores/core-store-****"
}
設定方法:
- GitHub リポジトリの Settings → Secrets and variables → Actions
- "New repository secret" をクリック
- Name:
GOOGLE_API_KEY, Secret: [APIキー] - Name:
GEMINI_FILE_SEARCH_STORES, Secret: [JSON]
実行してみた結果
ワークフロー起動
実際にActionsが動いてStoreに保存できたときの画面です。
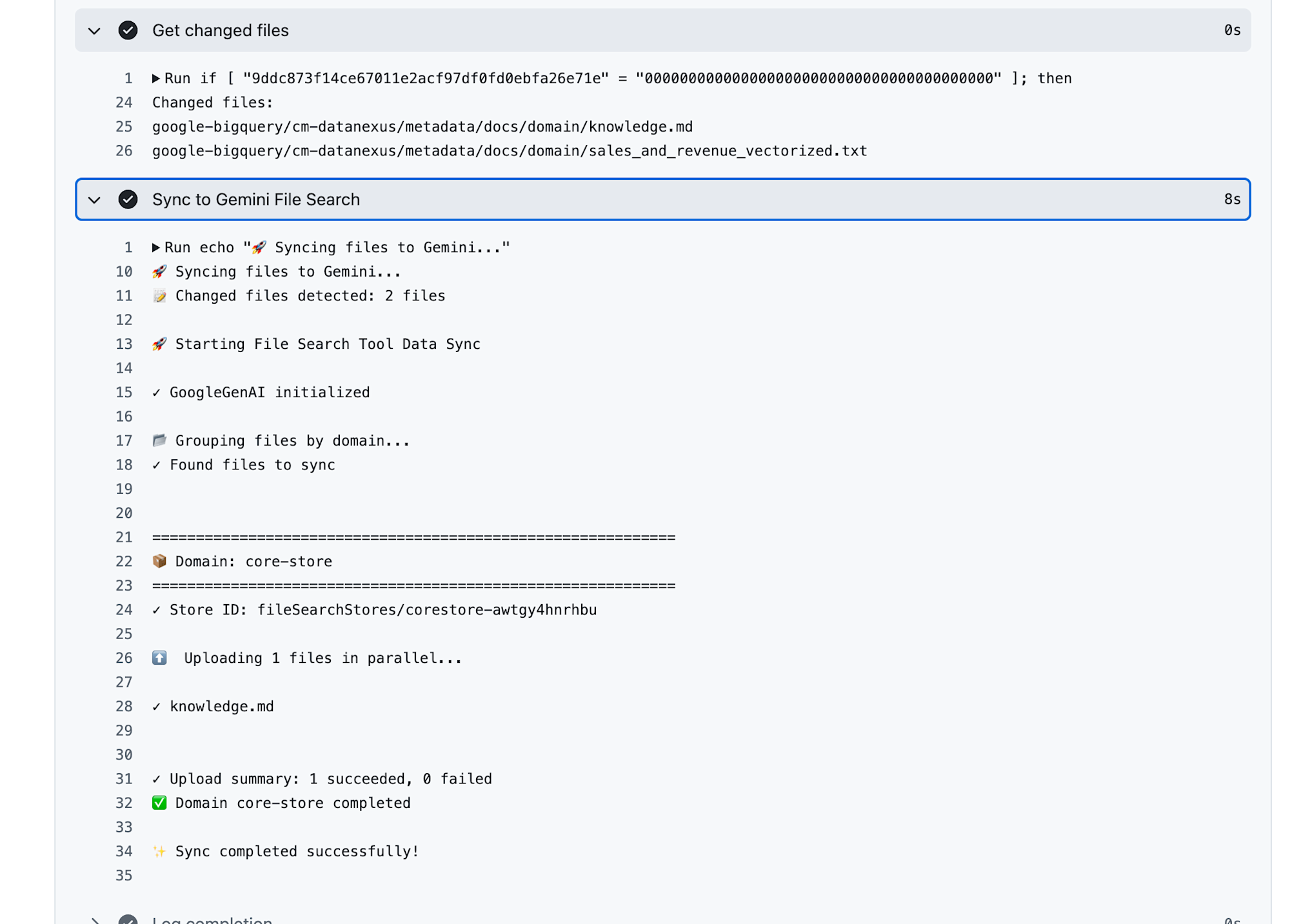
2ファイル変更検知しているけど、同期のスクリプトの方でマークダウンファイルしか対象にしていなかったためインポートされたのは1つでした。
これはActionsのワークフロー定義でフィルタリングする方が良いかも。。。
実際の検索
ドキュメントのサンプルコードを参考にして試してみました。
例:
// Ask a question about the file
const response = await ai.models.generateContent({
model: "gemini-2.5-flash",
contents: "AWSマーケットプレイスで販売している製品を調べるには?",
config: {
tools: [
{
fileSearch: {
fileSearchStoreNames: [ストアの一覧]
}
}
]
}
});
console.log(response.text);
引用元の表示
Gemini APIのレスポンスからgroundingChunksを抽出して、どのファイルから情報が取得されたかを表示します。
function extractCitations(response) {
const citations = [];
if (response.candidates && response.candidates.length > 0) {
const candidate = response.candidates[0];
if (candidate.groundingMetadata?.groundingChunks) {
for (const chunk of candidate.groundingMetadata.groundingChunks) {
if (chunk.retrievedContext) {
const context = chunk.retrievedContext;
citations.push({
title: context.title || 'Unknown',
fileSearchStore: context.fileSearchStore || ''
});
}
}
}
}
return citations;
}
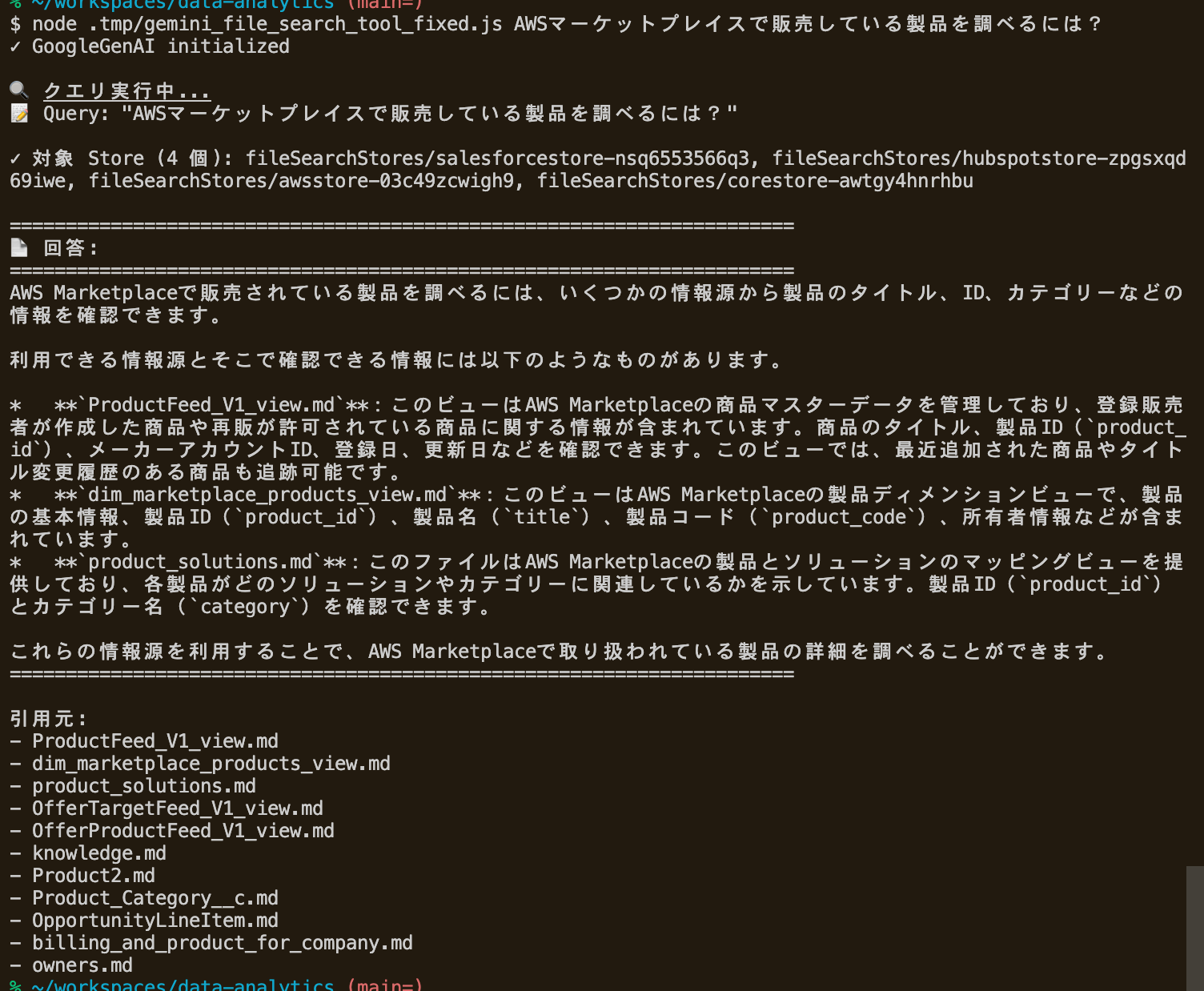
GitHub Actions + Gemini File Search Storeで、メタデータの自動同期し、メタデータの検索ができないか試してみました。
この仕組みにより、自然言語で検索し、Geminiが適切なテーブルやカラムの情報を見つけて提示できるようになりました。
今後の目標:
- メタデータ検索の精度向上 - ドメイン知識の充実化、RAG用チャンク構造の改善
- SQL生成機能 - Geminiが見つけたテーブル・カラム情報からSQLクエリを自動生成
- SQL実行・結果表示 - BigQueryへの自動クエリ実行と結果表示
GitHub Actions,あんまり触ったことなかったけど面白いですな。










