
GKE の Observability 関連の機能についてまとめてみた
本ブログの趣旨
GKE の Ovservability 関連の機能が複数あって全体像を掴み辛く感じたため、まとめてみました。
「GKE の Observability 関連の機能」と言うと若干範囲が曖昧ですが、公式ドキュメントの GKE のオブザーバビリティ で言及されている、今回は下記機能について取り扱います。
- Cloud Monitoring (連携)
- (Cloud) Logging (連携)
- Managed Service for Prometheus (マネージドコレクション)
- Dataplane V2 メトリクス/Observability
Cloud Monitoring (連携)
GKE の各種メトリクスを Cloud Monitoring に送信できる機能です。
大きく「システムメトリクス」と「その他のオブザーバビリティメトリクス」に分かれ、システムメトリクスだけであれば追加コスト不要で利用できます。
Cloud Monitoring は、GKE のシステム指標の取り込みに対して課金しません。
https://cloud.google.com/kubernetes-engine/docs/how-to/configure-metrics?hl=ja#pricing
Autopilot クラスタでは無効にできない、基本の監視機能と言えます。
GKE Autopilot クラスタでは、システム指標の収集を無効にすることはできません。
https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-metrics?hl=ja#enable-system-metrics
Standard モードのクラスタにおいても、システムメトリクスを出力しない場合はカスタマーサポートが限定的になることに注意が必要です。
警告: Cloud Logging または Cloud Monitoring を無効にするか、除外フィルタを適用している場合、GKE のカスタマーサポートはベスト エフォートで提供されるため、自社のエンジニアリング チームで別途対応する必要が生じる場合があります。
https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-metrics?hl=ja#enable-system-metrics
そのため、システムメトリクスの Cloud Monitoring 連携に関しては有効化しない理由が無いと言えるでしょう。
Managed Service for Prometheus と Node Exporter などで同等の情報を取得できる場合においても、合わせて有効化すべきです。
「その他のオブザーバビリティメトリクス」はシステムメトリクスに留まらないより詳細な情報を取得したい場合に利用します。
その他のオブザーバビリティ指標
1 つ以上のオブザーバビリティ指標パッケージを有効にすると、追加のオブザーバビリティ指標を収集できます。
コントロール プレーンの指標: Kubernetes API サーバー、スケジューラ、コントローラ マネージャーの指標を収集して、Kubernetes コンポーネントの状態をモニタリングします。これらの指標は、サービスレベル目標(SLO)を定義する際にサービスの状態を把握するのに有用なシグナルです。
Kube 状態指標: Deployment、ノード、Pod などの Kubernetes オブジェクトの状態をモニタリングします。
cAdvisor / kubelet 指標: コンテナと kubelet の健全性をモニタリングします。
https://docs.cloud.google.com/kubernetes-engine/docs/concepts/observability?hl=ja#metrics-packages
Kubernetes リソースごとなどでパッケージ化されており、選択して有効化することが可能です。
| 種別 | メトリクス名 | 内容 |
|---|---|---|
| Control Plane | API Server | API Server に関するメトリクス |
| Control Plane | Scheduler | Scheduler に関するメトリクス |
| Control Plane | Controller Manager | Controller Manager に関するメトリクス |
| Kube State Metrics | Persistent Volume | PV, PVC に関する詳細情報 (クレームの状態等) |
| Kube State Metrics | Pods | Pod に関する詳細情報 (Pod のフェーズ等) |
| Kube State Metrics | Deployment | Deployment に関する詳細情報 (Deployment 内のレプリカ数等) |
| Kube State Metrics | StatefulSet | StatefulSet に関する詳細情報 (StatefulSet 内のレプリカ数等) |
| Kube State Metrics | DaemonSet | DaemonSet に関する詳細情報 (DaemonSet 内のレプリカ数等) |
| Kube State Metrics | Horizontal Pod Autoscaler | Horizontal Pod Autoscaler に関する詳細情報 (Autoscaler が管理している Pod の数等) |
| Kube State Metrics | JobSet | JobSet に関する詳細情報 (JobSet 内のレプリカ数等) |
| cAdvisor and Kubelet Metrics | cAdvisor | ノード上の cAdvisor に関するメトリクス |
| cAdvisor and Kubelet Metrics | Kubelet | ノード上の Kubelet に関するメトリクス |
| GPUs | NVIDIA DCGM | NVIDIA Datacenter GPU に特化したメトリクス |
「その他のオブザーバビリティメトリクス」を Cloud Monitoring へ連携する際は取り込んだサンプル数に応じた追加コストが発生します。
また、Pod や Node、名前空間ごとの CPU/メモリ利用率程度であればシステムメトリクスで十分閲覧可能です。
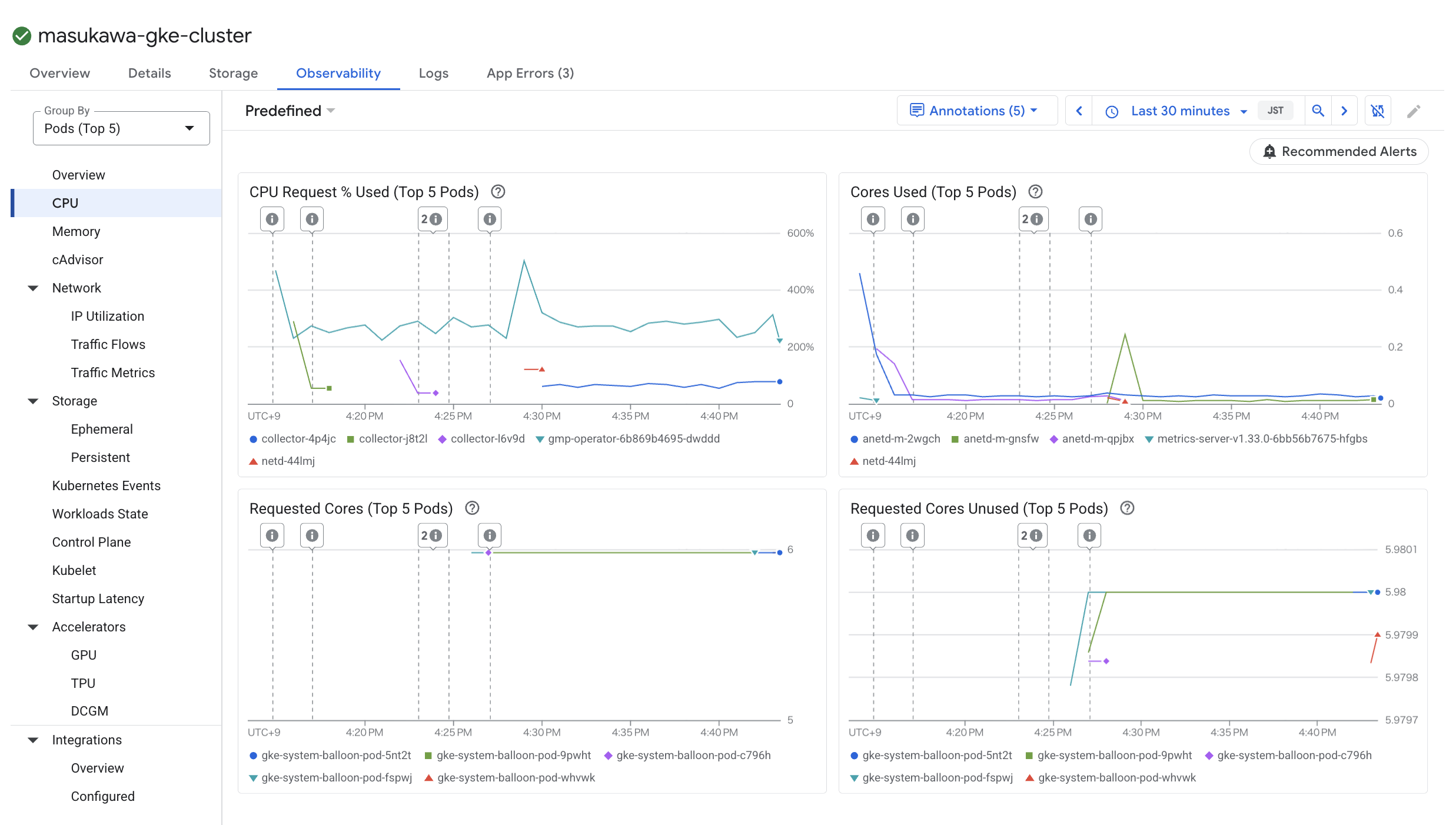
コントロールプレーン側のメトリクスや各 Kubernetes の状態なども踏まえた詳細なメトリクスを確認したい際に有効化すると良いです。
特に、コントロールプレーン側のメトリクスについてはこちらの機能を利用しないと取得できないことに注意が必要です。
コントロールプレーンは Google Cloud 管理ではあるものの、トラブルシューティング時に役立つ場面はあるかもしれません。
取得できるメトリクス一覧は下記から確認できます。
システムメトリクス
Control Plane
Kube State
cAdvisor and Kubelet
GPUs
(Cloud) Logging (連携)
GKE の各種ログを Cloud Logging に送信できる機能です。
もちろん GKE クラスタ内にもログは出力されますが、Pod の削除時やディスク不足時などに削除されてしまいます。
Cloud Logging に保存しておくことで、Kubernetes リソースのライフサイクルやディスク容量に関係無くログを長期保存することが可能です。
出力可能なログは下記になります。
| ログ名 | 内容 |
|---|---|
| 監査ログ | Kubernetes API に対しての操作証跡 |
| システムログ | kube-system で実行されているコンテナのログなど |
| アプリケーション ログ | システム以外のコンテナで生成されたログ |
| API サーバーログ | kube-apiserver の動作ログ |
| Scheduler ログ | kube-scheduler の動作ログ |
| Controller Manager ログ | kube-controller-manager の動作ログ |
| Horizontal Pod Autoscaler ログ | Horizontal Pod Autoscaler がスケーリングする際の意思決定プロセスに関するログ |
Managed Service for Prometheus (マネージドコレクション)
そもそも Managed Service for Prometheus 自体は、Prometheus 形式のメトリクスを保存して PromQL でクエリするためのマネージドサービスです。
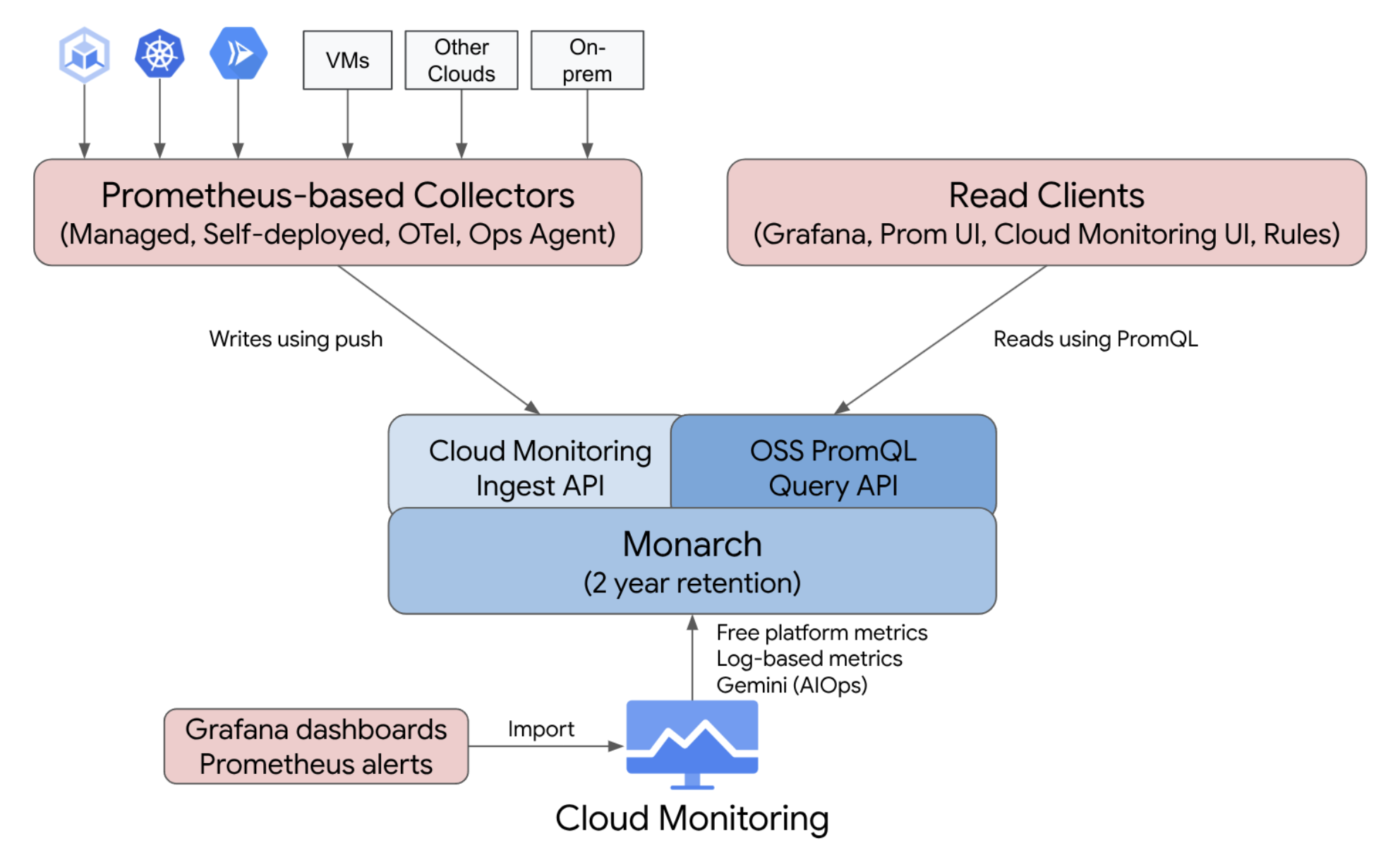
Google Cloud Managed Service for Prometheus
GKE の Managed Service for Prometheus 機能は、Managed Service for Prometheus に Prometheus ベースのメトリクスを転送する部分をマネージドで行ってくれる機能です。
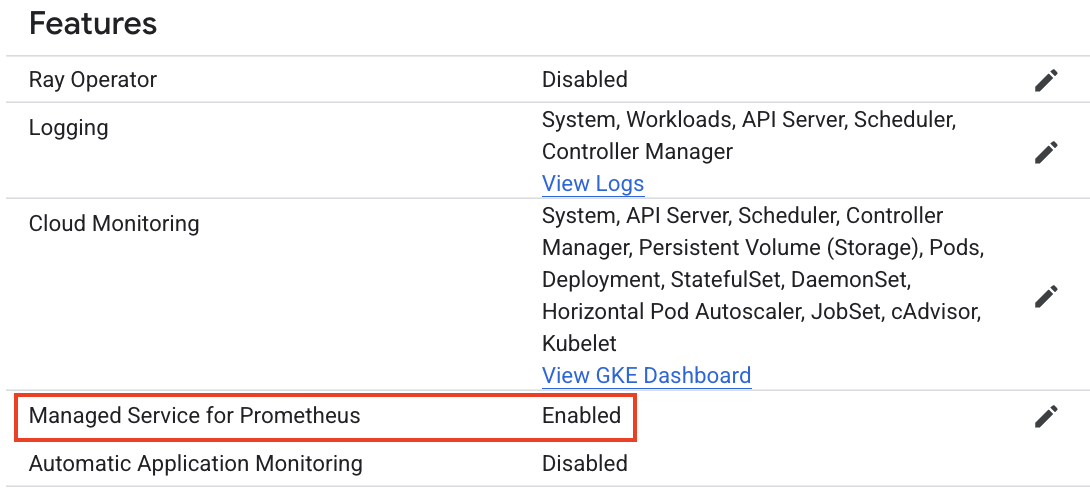
専用リソースである PodMonitoring を作成することで、特定の Pod からメトリクスを収集して、Managed Service for Prometheus に転送することが可能です。
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-nginx
spec:
selector:
matchLabels:
app.kubernetes.io/name: nginx
endpoints:
- port: metrics
path: /metrics
interval: 30s
例えば、上記リソースを作成することで Prometheus エージェント不要で Nginx Exporter 経由のメトリクスを取得できます。
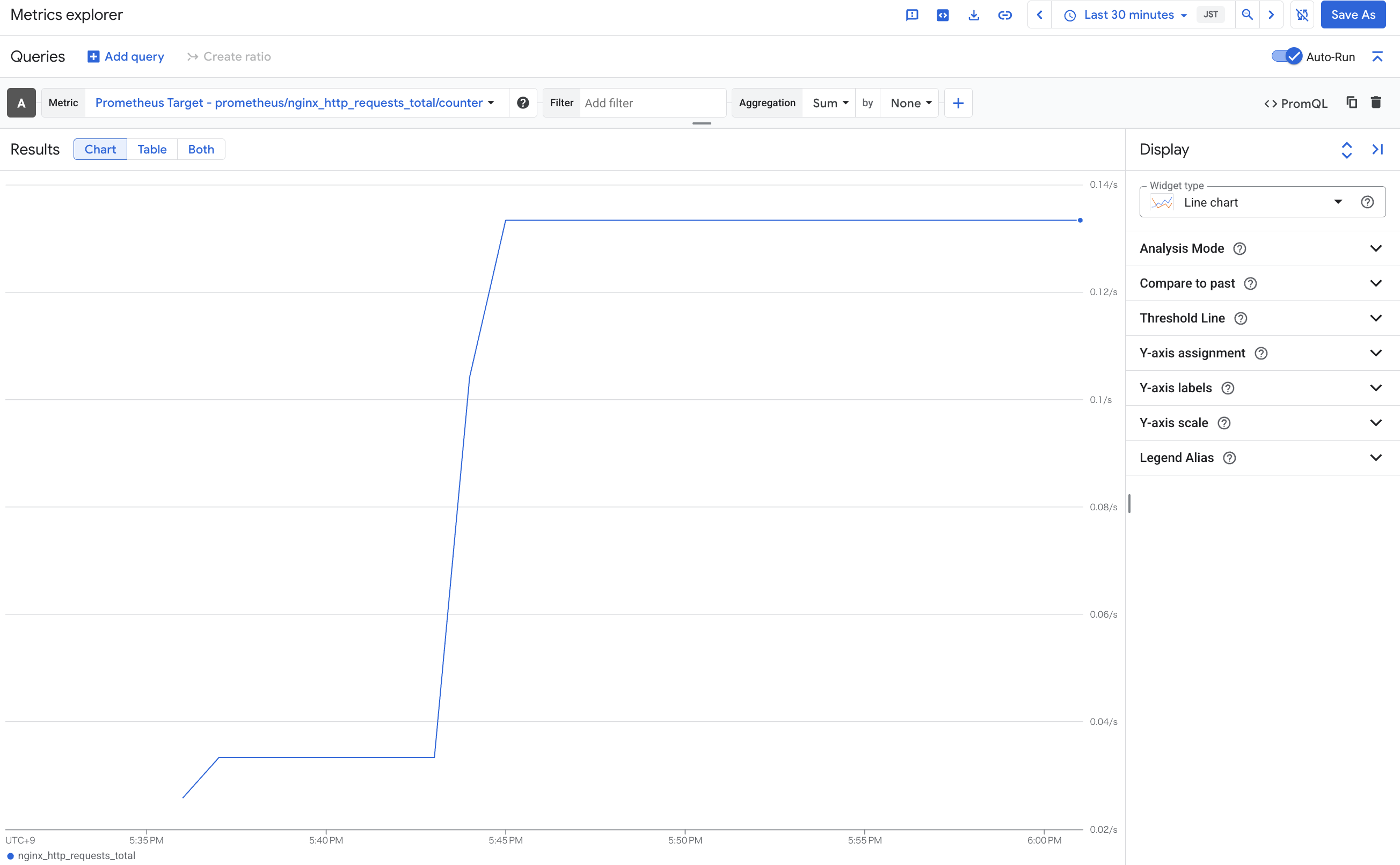
Managed Service for Prometheus という名称ではありますが、Cloud Monitoring の一機能として扱われており、Cloud Monitoring 連携で取得したメトリクス群と同じように扱うことが可能です。
また、Automatic Application Monitoring という機能も存在しており、特定のワークロードに対して PodMonitoring 不要でメトリクスを収集することが可能です。
現状対応しているリソースは多くないですが、場合に依っては有用かもしれません。
Automatic application monitoring supports the following workloads:
・Apache Airflow
・Istio
・RabbitMQ
・AI model servers:
・JetStream
・NVIDIA Triton
・TensorFlow Serving
・Text Generation Inference
・TorchServe
・vLLM
https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-automatic-application-monitoring?hl=en&_gl=1*98gk23*_ga*MTc5MjMxMTQ0OS4xNzQxNzU2MjA2*_ga_WH2QY8WWF5*czE3Njc0MjQ0MDYkbzExMiRnMSR0MTc2NzQyODQ0OSRqMzckbDAkaDA.
Dataplane V2 メトリクス/Observability
前提となる話として、Dataplane V2 は eBPF を活用した GKE のネットワーク制御の仕組みです。
こちらが登場する前は Calico をベースにしたネットワーク制御を行っていましたが、Dataplane V2 では Cilium をベースで実装されています。
kube-proxy や iptables への依存が無くなっていてパフォーマンスの向上が見込める他、ネットワークポリシーロギング (Network Policy による Allow/Deny を記録) を利用できます。
こちらを利用している際、GKE の機能として「Dataplane V2 メトリクス」を有効化することで、ネットワーク関連のメトリクスを取得できます。
また、Dataplane V2 Observability を有効化すると、下記 2 つのコンポーネントをマネージドな形でインストール可能です。
- Hubble Relay: ポッドとノードに関するネットワークテレメトリデータを収集するサービス
- Hubble CLI: クラスタ内のネットワークトラフィックを確認するための CLI ツール
Hubble は Cilium を基盤に構築されたネットワーク監視や Observability 用のツールであり、それらの一部をインストールできることになります。
Hubble is a fully distributed networking and security observability platform. It is built on top of Cilium and eBPF to enable deep visibility into the communication and behavior of services as well as the networking infrastructure in a completely transparent manner.
https://docs.cilium.io/en/stable/overview/intro/#what-is-hubble
つまり、Dataplane V2 メトリクス/Observability を有効化することで、Hubble と Cilium を活用した eBPF ベースのネットワーク監視基盤を簡単にセットアップ可能です。
ただし、Hubble UI を利用したい場合は別途インストールが必要です。
Hubble UI さえインストールすれば下記のような形で、トラフィックの可視化が可能です(トラフィックが少なくてあまり優位性が分かり辛いですが...)。
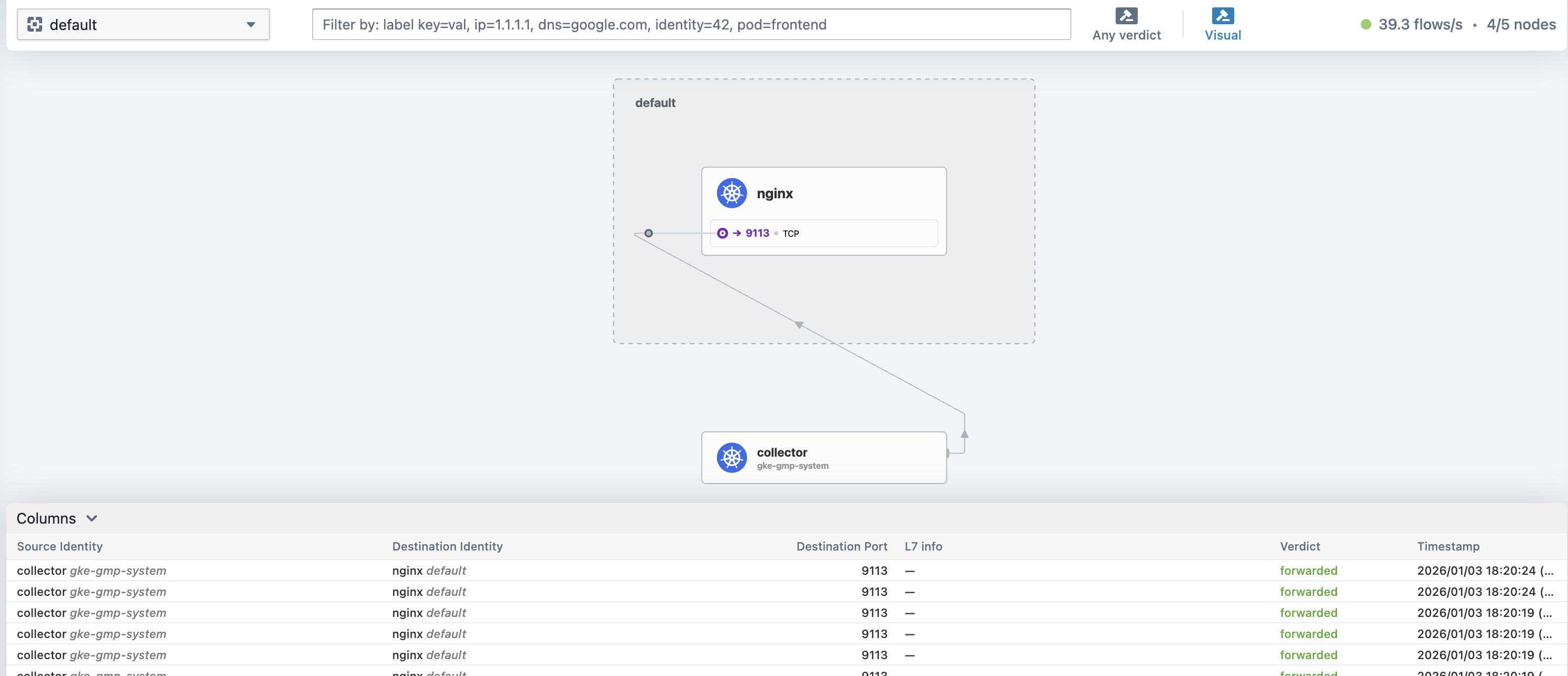
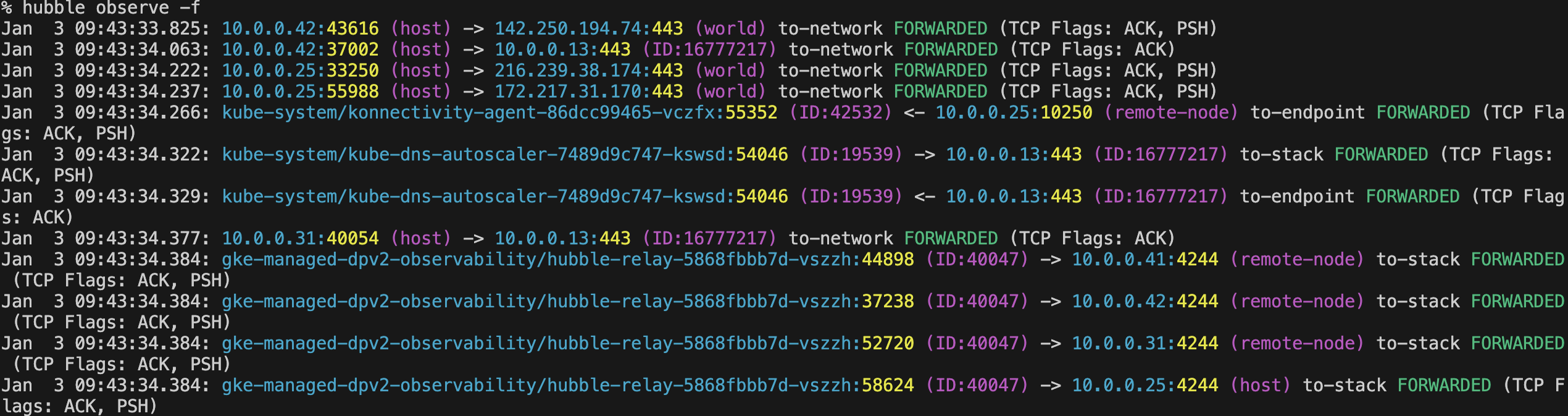
Hubble CLI はインストールされているため、CLI ベースの分析は追加コンポーネント不要で可能です。
alias hubble="kubectl exec -it deployment/hubble-relay -c hubble-cli -n gke-managed-dpv2-observability -- hubble"
hubble observe -f
まとめ
ざっくりとまとめると下記のようになります。
| 機能 | 概要 |
|---|---|
| Cloud Monitoring (連携) | GKE の各種メトリクスを Cloud Monitoring に連携する |
| (Cloud) Logging (連携) | 各種コンポーネントのログを Cloud Logging に連携する |
| Managed Service for Prometheus (マネージドコレクション) | Prometheus 形式で公開されたメトリクスをマネージドな形で Managed Service for Prometheus に連携する |
| Dataplane V2 メトリクス/Observability | ネットワーク周りのメトリクスを取得したり、分析するためのツールをインストールする |
コンソールから見ると単に Cloud Monitoring とか Managed Service for Prometheus とか記載してあって分かり辛かったのでまとめてみました。
この記事がどなたかの参考になれば幸いです。










